
基于运动姿态描述子特征和词袋模型的行为识别
2018-05-22 03:49姚旭
计算机时代 2018年5期
姚 旭
(河南大学计算机与信息工程学院,河南 开封 475000)
0 引言
人体行为识别是计算机视觉的一项挑战,它在视频监控、人机交互、虚拟现实、体感游戏等领域有广泛应用,受到研究人员的关注[1-3]。人体行为识别中一大难点是数据提取过程中由于受到视角、光照及背景等因素的影响会使得识别的精度大幅度下降。微软Kinect传感器的发布,使得传感器可以从深度图像中精确的估计出人体骨架关节点的信息。因此引起了研究人员的关注。
Wang J[4]等人提出了基于三维人体骨架关节点子集的行为识别方法,MihaiZanfir[5]等人提出了基于运动姿态描述子的三维人体行为识别方法。SharafA[6]等人提出了基于角度描述子协方差特征的三维人体行为识别。虽然基于三维人体骨架序列的研究取得了一定进展,但是在识别精度上依然有很大的提升空间。
本文基于三维骨架序列信息采用词袋模型[7]和运动姿态描述子[5]并运用改进硬向量编码的方式,最后在数据集MSR Action3D上用Lib linear分类器分类,获得了很好的分类精度。实验结果优于其他方法。
1 词袋模型研究
词袋(bag of word)模型最早是文档的一种建模方法,把一个文档表示为向量数据,从而使计算机处理文档数据更加便捷,而后运用到图像和视频处理中。
BOW模型一般分为五个基本步骤。①提取人体特征信息,就是要从图片或者视频去提取有用的信息,这属于底层特征提取.本文用的是提取三维骨架信息。②特征描述,这一步就是为了获得更多信息,属于对步骤1的提纯,本文运用MP描述符来描述特征信息。③生成视觉单词,这一步的主要目的就是获得最能代表动作的信息,通过对从描述符运用K-mean方法去聚类得到视觉单词。④特征编码,输入每帧的特征描述符以及生成的视觉单词,获得编码矩阵。这步会对每个描述符运用视觉单词重新被编码从而得到编码向量,它的长度和视觉单词大小一致。不同的编码方式会得到不同的编码矩阵,本文采用改进的硬向量编码方式。⑤汇聚特征,这个步骤的输入是一个编码矩阵输出,是每个动作的一个集合矢量,常用的方法有两种,分别为average pooling和MAX pooling。本文采用后一种汇聚方法。最后就是训练分类器获得优良的分类精度,本文采用Lib linear线性分类器。
2 运动姿态描述子研究
运动姿态描述子(motion posture descriptor),是一个基于帧的并在其周围的短时间窗口内,帧的动态提取三维人体姿态信息及相关关节速度和加速度的信息的描述符。由于像惯性这样的物理约束,或者在肌肉驱动上的延迟,研究发现人体运动和该运动姿态基于时间上的以用一阶、二阶导数表示的二次函数很接近,由此提出MP描述符。
从视频中提取的每一帧中的每个3D关节位置用pi=(px,py,pz)来表示,i{1,...,N},这里的N表示人体关节总数。每一帧我们计算出一个MP并将3D关节点归一化串联即P=[p1,p2,…,pn],还有其一阶二阶导数δP(t0)和δ2P(t0),导数被当前处理中的5帧时间窗口来估算,δP(t0)≈P(t1)-P(t-1)和δ2P(t0)≈P(t2)P(t-2)-2P(t0)。为了更好的数值近似我们先在时间维度采用5乘1的高斯滤波器(σ=1)平滑每个坐标归一化向量。注意,高斯平滑会产生两帧的滞后,这在实践中不会显着影响整体延迟。
为了抑制估计的输入姿势中的噪声,并补偿不同主体之间的骨骼变化,我们按照以下所述对姿势进行归一化。导数矢量也进行了重新调整,以使它们具有单位范数,这种标准化还消除了不同输入序列间绝对速度和加速度的无关变化,同时保留了不同关节之间的相对分布。时间t处的帧的最终描述符Xt是通过连接时间上的姿态信息及其导数得到的:Xt=[Pt,αδPt,βδ2Pt]。参数α和β加权两个导数的相对重要性,并且在训练集上进行优化。
3 改进硬向量编码研究
从BOW模型中可以看出其第4步就是采用编码方式,由于提取的每一帧描述子中包含了大量的冗余与噪声,为提高特征表示的鲁棒性,需要对描述子进行特征编码,从而获得更具判别能力的特征表示。不同的编码方式会有不同的分类精度,硬向量编码方式在对向量进行编码时,要计算向量和码本中所有码值的欧式距离,以此来寻找符合条件的视觉单词并赋权值。
传统的硬向量编码[8]描述如下:让X=[x1,x2,…,xn]∈RD×N表示N个从视频序列中提取出来的D维特征向量,B=[b1,b2,…,bm]∈RD×M表示有M个视觉单词的字典,V=[v1,v2,…,vn]表示编码后对应的N个特征。公式如下:

从传统的硬向量编码可以看出,在特征编码过程中对最近的那个视觉单词加权值1,其他均标0。因此它只是对局部特征进行很粗糙的重构,这很容易丢失很多重要的信息。
所以在硬向量编码的基础上进行改进,改进的公式如下:

与传统的硬向量编码相比,改进的编码方式给最近的K个视觉单词加权,这样,有效地解决了视觉单词的模糊性问题,提高了识别的精度。
4 实验结果与分析
本文设计的识别系统在BOW的基础上从深度图像中提取出人体骨架信息,用MP描述符描述并用K-means方法聚类出视觉单词,然后用改进的硬向量编码方式编码特征,汇聚出整个动作序列的密码向量最后用lib linear分类器训练分类。整个流程如图:
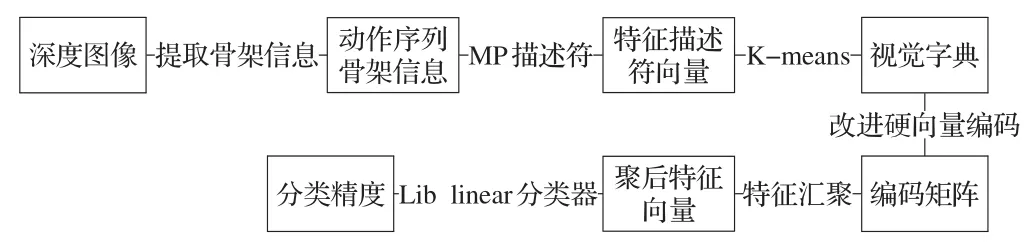
图1 整体流程图
本实验在MSR-Action3D数据集上进行实验,MSR-Action3D数据集由RGB-D相机捕获的时间分段动作序列组成,数据集中有20个动作,有10位实验者,并且每位实验者重复这20个动作2-3次。总共有567个序列其中有些序列严重损坏,所以实验最终选取其中的557个进行实验,本文采取与文献[5]相同的对α,β的设置。设计好系统后发现影响实验的因素有三个分别是视觉字典的大小、距离视觉单词最近的K取值还有训练-测试的分配比例上。为了实验的稳定性,每次实验重复进行5次取均值。
首先分析距离视觉单词最近的K取值对分类精度的影响,与此同时选取视觉字典的大小为4096,训练-测试的比例为1:1即选取(1,3,5,7,9)5人为训练集其余为测试集。得出如图2所示结果。

图2 K对精度的影响
从图2可见,K的取值对分类精度是有影响的,在K=5之前随着K的增大分类精度也逐渐增加,而后出现下降趋势。考虑降低运算量,本文取K=4。
研究完K对精度的影响后,接着研究视觉词典的大小对分类精度的影响。同样的选取K=4,(1,3,5,7,9)5人为训练集其余为测试集。实验结果如图3所示。

图3 字典对精度的影响
从图3可以看出字典大小对精度也是有影响的,当字典在2048之前精度呈上升趋势,而后有回落。故本文采取的字典大小为2048。
最后研究训练-测试比例不同对精度的影响,得出如图4所示结果。

图4 训练-测试比例对精度的影响
从以上实验看出训练-测试集的比例不同对分类精度也是有影响的,但是当过多的数据用于训练是会出现过拟合现象,这样不利于客观分析。所以本实验采用训练-测试比例为1:1。
以上是对影响本文设计的因素的研究,为了说明本设计的实用性还需与相关的实验进行对比,为确保设计的有效性和公平性,本实验参照文献[5,9],选取1、3、5、7、9这五位单号表演者的行为骨架序列数据为训练集,其余表演者的骨架序列数据为测试集。

表1 各种方法在MSR Action3D数据集上的实验结果
从表1中可以看出本文方法在识别精度上要优于其他方法,相比于早期隐马尔科夫模型[10]在精度上提升了将近30%;而且也要比三维点包上的动作图方法[11在精度上提升了约18%;最后相比同样运用运动姿态描述子的文献[8],该文献运用MP描述子和KNN方法也取得了很好的精度,但是本文运用MP描述子与词袋模型相结合的方法使得精度比之提升了0.82%。上述结果表明,本文所提方法能够提高识别精度。
5 结束语
为了提升基于三维骨架序列的人体行为识别的精度,本文选用词袋模型在提取骨架信息后用运动描述子来描述,同时选出一种改进的硬向量编码方式来编码特征,在简化特征向量的同时进一步提炼特征信息。最后在数据集MSR Action3D上实验并在识别精度上取得了很好的成果。但是在识别精度上依然有很大的提升空间,这值得我们去研究,比如在描述子不同或者编码方式不同时,可能会取得更高的识别精度,获得鲁棒性更好的识别方法,这也是我们以后的研究方向。
参考文献(References):
[1]胡琼,秦磊,黄庆明.基于视觉的人体动作识别综述[J].计算机学报,2013.36(12):2512-2524
[2]Presti LL,Cascia ML.3Dskeleton-based humanactionclassification:A survey[J].Pattern Recognition,2016.53(3):130-147
[3]ZhangJ,LiWOgunbonaPO,etal.RGB-D-based actionrecognition datasets:A survey[J].Pattern Recognition,2016.60(12):86-105
[4]Wang J,Liu Z,Wu Y,et al.Miningactionlet ensemble for action recognition withdepth cameras[C].Proceedings of IEEE Conference on Computer Vision and Pattern Recognition,2012:1290-1297
[5]Zanfir M,Leordean M,Sminchisescu C.The moving pose:An efficient3D kinematicsdescriptorforlow-latency action recognition and detection[C]. Proceedings of IEEE Conference on Computer Vision,2013:2752-2759
[6]SharafA,TorkiM,Hussein ME,etal.Real-Time Multi-scale Action Detection from 3D Skeleton Data[C].IEEE Winter Conference on Applications of Computer Vision,2015:998-1005
[7]G.Csurka,C.Bray,C.Dance,and L.Fan,"Visual Categorizationwith BagsofKeypoints,"Proc.ECCV Int'lWorkshop StatisticalLearningin ComputerVision,2004.
[8]Sivic J,Zisserman A.Video Google:A Text Retrieval Approach to Object Matching in Videos[C].IEEE InternationalConference on ComputerVision,2003:1470-1477
[9] VemulapalliR, Arrate F, ChellappaR.Humanaction recognition by representing3dskeletons as points in a liegroup[C]. Proceedings of IEEE Conference on ComputerVision and Pattern Recognition,2014:588-595
[10]F.Lv and R.Nevatia.Recognition andsegmentation of 3-d human action usinghmm and multi-classadaboost.InECCV,2006.
[11]W.Li,Z.Zhang,and Z.Liu.Action recognition based on abag of 3d points.InWCBA-CVPR,2010.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
价值工程(2017年22期)2017-07-15
电脑知识与技术(2016年36期)2017-04-17
系统工程与电子技术(2016年4期)2016-08-24
高中生学习·高三版(2016年9期)2016-05-14
