
用于交通图像识别的改进尺度依赖池化模型
2018-05-21 00:59冯长华
计算机应用 2018年3期
徐 喆,冯长华
(北京工业大学 信息学部,北京 100124)
0 引言
在智能交通系统中,车辆通过摄像头等传感器获取自然场景下的交通标志,用于车辆的辅助驾驶。智能交通标志识别系统需要在较远距离下完成对交通标志的检测与识别,以尽早地规避风险、遵循提示,但是也导致获取到的交通标志尺寸较小、所含信息量不足,再加上背景复杂等原因,对交通标志的检测及识别带来困难[1-3],所以需要对小尺度交通图像作有效地处理,以提高检测识别的准确率。
在小尺度目标体的识别领域中,传统的方法有贝叶斯估计[4]、Top-Hat算子[5]等,这类方法应用范围广,能有效地抑制噪声干扰,增强图像的对比度,但不能直接映射输出小目标体的特征信息。还有一些研究者通过最邻近插值算法、双线性插值法等[6-7]对图像进行放大处理,但是放大的图像存在边缘模糊、锯齿效应明显、图像失真严重等缺点,导致最终的分类识别效果不佳。
近年来,以卷积神经网络为代表的图像处理技术,在目标识别、语义分割领域取得优异的成绩,也成为智能交通领域研究的重点。卷积神经网络各层能对输入图像自适应地提取所需特征,有效提高识别准确率。基于此,许多学者探索有效的卷积层特征应用于小尺度目标的识别。Takeki等[8]将IMageNet[9]比赛中具有优秀分类能力的深度学习模型直接应用于小目标体识别,但较深的网络结构在小目标的处理中易因过多池化(Pooling)操作引发特征丢失问题。Long等[10]提出层间特征融合的思想用于解决小尺寸目标分割问题,输出结果对每一层进行映射采样易导致信息的过冗余,影响最终的分割效果。Yang等[11]提出尺度依赖池化(Scale Dependent Pooling, SDP)模型,实现了基于输入图片的尺度映射输出不同卷积层的特征,对小尺度目标体提取浅卷积层的特征。 这种对小尺度目标体的处理方法,一定程度上避免了特征丢失问题,较多地保留了图像细节,另一方面也不会造成输出特征的过冗余,但是这种做法损失了深卷积层轮廓信息及类别特性。后续的学者在此方向上提出了改进算法,Choi等[12]提出对各个卷积层使用级联分类器,依据各卷积层的权重来决定最终的分类结果,虽然分类结果结合不同卷积层的特征的判定,但每一个分类器的提取特征都是单一特征。
将目前的小目标识别算法应用于小尺度交通图像的识别中,应根据交通图像的特点有针对性地改进。交通图像用特定的字符向驾驶者传达特定的信息,交通图像有着显著的轮廓信息及形状特性[13-14]。Ruta等[15]通过提取方向梯度直方图(Histogram of Oriented Gradients, HOG)特征获得交通图像的形状信息,实现检测识别。Zeiler等[16]通过可视化卷积神经网络各卷积层的特征,发现卷积神经网络随着层数的加深,轮廓结构的完整性及辨别性增强。如果SDP模型直接应用于小尺度交通图像的识别,会因直接提取浅卷积层的特征的做法损失交通图像较好的轮廓特征。基于此,本文提出改进尺度依赖池化模型应用于小尺度交通图像。首先,在原SDP的基础上,提出了补充深卷积层特征信息的改进SDP(Supplementary Deep convolution layer characteristic Scale-Dependent Pooling, SD-SDP);其次,为了补充小尺度交通图像的边缘信息,提出了多尺度滑窗池化(Multi-scale Sliding window Pooling, MSP)将融合后的特征处理到固定的维度;最后,将改进的SDP模型应用于交通标志的识别。实验结果表明,本文算法在增强有效特征的基础上,较好地提高了交通图像的识别准确率。
1 尺度依赖池化
尺度依赖池化方法通过输入图片的大小提取不同卷积层的特征。尤对小目标的处理上,不再局限于按照卷积神经网络的结构提取最后一层特征,而是探索卷积神经网络的中间层,针对不同卷积层的特征,创建对应分支,学习独立的分类器。首先将图像按照尺寸大小分到3个子区间中,划分标准是[0,64)为小尺度图像,[64,128)为中等尺度图像,[128,+∞)为大尺度图像;小尺度图像选取卷积神经网络(Convolution Neural Network, CNN)的第3个卷积层的特征进行Pooling处理(SDP_3),中等尺度图像选取CNN的第4个卷积层的特征进行Pooling处理(SDP_4),大尺度图像选取 CNN的第5个卷积层的特征进行Pooling处理(SDP_5);最后根据提取到的特征在conv3、conv4、conv5的每个独立分支后,连接每个分支特有的全连接层及分类器。
2 改进的尺度依赖池化
在对小尺度的交通标志识别研究中,针对尺度依赖池化模型对小尺度的交通图像只提取浅卷积层的底层特征,而忽略了较好的深卷积层的轮廓信息及辨识度较高的类别信息。为进一步提高交通图像的识别准确率,本文改进的尺度依赖池化模型过程如下:
步骤1 提取卷积神经网络的第3个卷积层的特征,并使用主成分分析(Principal Component Analysis, PCA)对特征进行降维;
步骤2 提取卷积神经网络的第5个卷积层的特征,并与第3个卷积层的特征融合;
步骤3 使用MSP方法将融合后的特征池化固定的维度,完成特征的训练;
2.1 深卷积层特征补足型尺度依赖池化
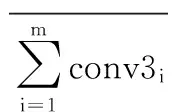
在对小尺度交通图像的处理中,尺度依赖池化模型提取浅卷积层的特征的方式,在一定的程度上,能避免因卷积神经网络层数的加深导致的交通图像特征丢失严重的问题。然而文献[16]通过对ImageNet上的1 000类物体作特征的可视化分析,使CNN的使用者逐渐清晰神经网络的每层提取特征的特点,如浅层的颜色信息及深层的类别信息等。浅卷积层提取简单的颜色、边缘等特征,存在特征信息对目标物体理解不足的问题,而通过增加卷积及Pooling的次数,能逐渐提取复杂的轮廓结构信息,且卷积神经网络的层数越深,信息的完整性及辨别性就较好。本文基于小目标改进的尺度依赖池化模型,结合不同卷积层的特征,使用丰富的特征信息实现交通图像的分类识别。增强后的特征提取结果如下公式表示:
(1)
为了比较特征的增量,表1显示不同尺度的交通图像下,原尺度依赖池化模型与改进的尺度依赖池化模型特征量的对比,关于特征总量的计算是基于本文使用的网络结构如表3所示,每层的特征量是由特征通道数与单层通道的特征量乘积的结果,结果发现改进的SDP模型与原SDP相比特征总量有所增加,且通过映射深卷积层的信息,特征信息更加丰富,而关于增强后特征的有效性将在实验环节的准确率的对比中展示。
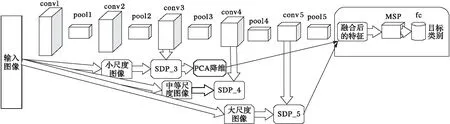
图1 特征增强型尺度依赖池化模型的网络结构 Fig. 1 Network structure diagram of modified feature-enhanced scale-dependent pooling model
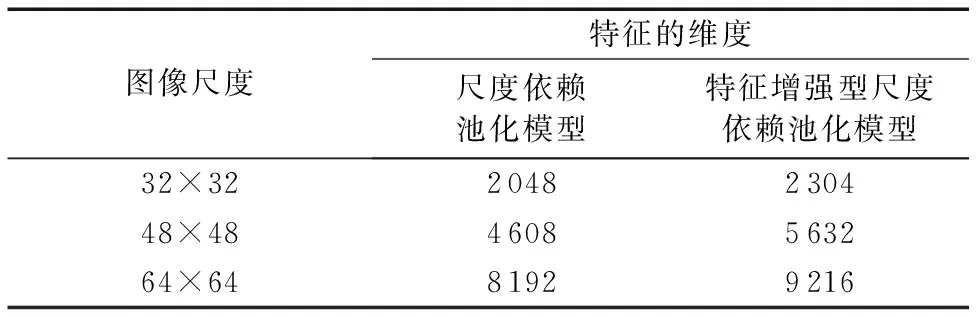
表1 不同算法下交通图像特征量的对比Tab. 1 Comparison of traffic image feature quantities under different algorithms
2.2 多尺度滑窗池化
空间金字塔池化的提出是为了解决输入图片尺度多变性的问题,通常用在网络的倒数几层,也就是我们即将与全连接层连接的时候,使用空间金字塔池化,使得任意大小的特征图都能够转换成固定维度的特征向量 。将特征图划分成22*22个特征区域,然后利用三种不同大小的刻度(22×22,21×21,20×20),对特征区域进行划分,最后总共可以得到16+4+1=21个块,使用最大池化方法求取每个区域的最大值,就可以得到固定的21维的向量。然而选择固定的刻度将特征图划分为不重叠的块区域,会损失图像的边缘信息,导致边缘模糊,还易造成混叠效应,不利用整体轮廓信息的识别,在一定程度上,导致识别准确率的下降。
本文提出了改进的空间金字塔池化算法即MSP方法,用固定刻度对特征图进行划分后,在划分后的特征图上使用多种尺度Pooling核进行滑窗。如图2所示,将特征图划分成4×4 的窗格区域,分别以Pooling 核大小为4×4,3×3,2×2,1×1,Pooling步长为1,1,1,1 对划分后的特征图进行滑窗池化操作,池化方法选择最大值池化, 得到的对应特征维度向量是分别是1,4,9,16,一共获得30维的特征向量。MSP算法在用固定刻度划分的特征图上,使用多种尺度的Pooling核大小进行池化操作,能够有效适应目标物体的尺度多变性,灵活地提取目标物体的边缘信息,且有重叠的池化加强了边界变量与相邻区域的相关性,模糊了块与块之间的边界,使得处在边缘的像素点也能提供特征信息,有利于整体信息轮廓的提取及识别。因此在改进的尺度依赖池化模型的基础上,使用MSP方法,能够进一步补足小尺度交通图像的特征。
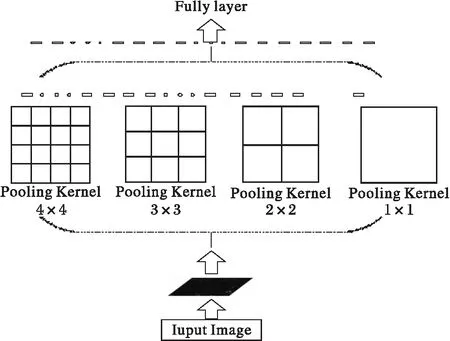
图2 多尺度滑窗池化的结构 Fig. 2 Network structure multi-scale sliding window pooling
3 实验
本文用原SDP模型以及改进的SDP模型对交通标志进行识别,因为改进的SDP有补充深卷积信息的SDP(SD-SDP)及加入多尺度滑窗池化两部分,因此,在原SDP模型基础上分别加入SD-SDP及MSP作对比实验,验证每一部分改进的有效性,而后在相同的数据集上对网络的准确率及耗时作比较。因为网络训练参数的随机性,本文采取对每一类算法做10组实验,并对实验结果求平均值, 且在每次实验时,模型的卷积层共用一组相同的初始化参数,以提高实验的稳定性及增强说服力。
实验中使用的交通标志数据集是德国交通标志识别数据集GTSRB,其中包含39 209张训练集和12 630张测试集,交通标志的种类为43类,包含禁止、指示、警告等各类交通标志,并且按照尺度依赖池化(SDP)模型的尺寸划分准测,交通图像的尺寸大小基本为小尺度图片,图3是数据集中的部分样本。
SDP算法是基于模型VGG16[17]实现的,交通标志识别任务并不像ImageNet数据集的分类那样复杂,所以考虑在参考VGG16网络架构的基础上减小网络框架。本文所采用的网络模型如表2,其中神经网络包含5个卷积,3个全连接,为了降低特征维度,每个卷积后都有相对应的Pooling 层,但由于交通图像多为小尺度图像,卷积及Pooling的核及步长也使用较小的值,第一个全连层的神经元的个数分别是3 072,相比4 096有着更好的识别精度。激活函数采用了Relu函数,避免反向传播中的梯度消失问题,能够有效提高网络训练的精度,因此卷积及Pooling的核大小及步长也调整到一个较小值。为了验证网络模型的有效性,将在接下来的实验中设计改进的SDP算法在几种不同模型下的准确率及实时性的对比实验。为了使网络具有更好的泛化能力。在网络训练中我们使用AdaDelta[18]、Dropout[19]方法来尽量地抑制网络过拟合问题。

图3 GTSRB交通标志数据集中的部分样本 Fig. 3 Part samples of GTSRB traffic sign dataset
表2对比了不同模型及不同方法在GTSRB数据集下准确率及实时性,其中硬件平台CPU:I7-6700,GPU:GTX-TITAN X,可以观察到3种方法在不同模型下的比较结果。

表2 不同模型及不同方法在GTSRB数据集下准确率及实时性的比较Tab. 2 Comparison of accuracy and real-time of different models and different methods in GTSRB dataset
SDP模型是基于模型VGG16实现的,交通标志的识别任务不像ImageNet数据集的分类那样复杂,所以考虑在参考VGG16网络架构的基础上减小网络架构。本文所采用的网络模型如表3,其中神经网络包含5个卷积。
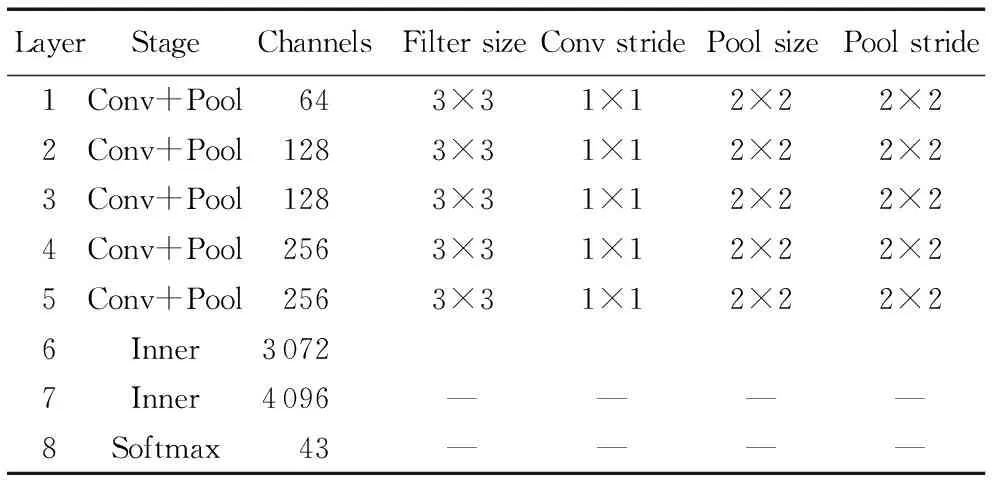
表3 本文使用的网络模型说明Tab. 3 Network model used in this article
一般来讲网络模型的加深会得到较好的分类识别结果,但针对不同的识别任务,应当选择合适的网络模型,以实现准确率及实时性的平衡。如交通标志的识别任务中,本文使用的网络模型与VGG16 相比,准确率也有所下降,但实时性得到很好的提升。且通过改进特征提取方式有效弥补了准确率下降的缺点,使用SD-SDP与原SDP相比,准确率提升约3%,在SD-SDP中使用多尺度滑窗(MSP)又使准确率得到了约1.2%,这种改进通过提取对交通图像分类较为重要的深卷积层的轮廓信息,增加了重要特征信息,使得交通图像分类的准确率得以提升。虽然改进的SDP算法在VGG模型取得最好的分类效果,但综合考虑实时性及准确率的情况下,本文模型的结果相对而言,则更有可取性。
改进的SDP模型也含有3个分支,分别对应不同尺度输入图像的训练识别,GTSRB中的39 209张训练集,依据尺度大小,完成不同分支的参数训练。因改进SDP模型主要改进的是小尺度输入图像的特征提取方式,按照SDP的尺度划分标准,对小尺度交通图像(尺寸为[0,64)及非小尺度的交通图像的识别准确率作了分别统计。表4对比了各种方法在不同尺度的交通图像下分类准确率的比较结果,可以看到小尺度交通图像的准确率得到有效提升,而非小尺度交通图像准确率不变,改进的SD-SDP算法和原SDP算法相比,准确率提升约3.8%,加入MSP方法的改进SD-SDP模型,准确率的提升在1.5%。另外当验证集中部分样本过小,可能使深卷积层的特征量过少。在此种情况下对融合后的特征向量模型的性能也做了独立实验,因此对GTSRB数据集中的宽和高度都小于等于32的这部分样本进行了实验,这部分样本的数量是399,在被划分为小尺度交通图像的10 140张图片中,所占比例不大。 改进的SDP相比原SDP算法中正确识别的正确率由79.7%提升至81.7%,因样本尺寸偏小,所以识别准确率整体偏低,通过改进的SDP模型实验,特征量融合对识别准确率的提升也有限。而测试集总准确率的计算是小尺度交通图像及非小尺寸交通图像占总样本的比重与对应的准确率的相乘再相加的结果。在GTSRB的12 630张测试集中,其中的10 140张图片都可按照SDP尺度划分标准归为小尺度图像,小尺度在影响总准确率时占较大的比重,因此基于小目标改进的SDP模型能较好地提升整体的准确率。
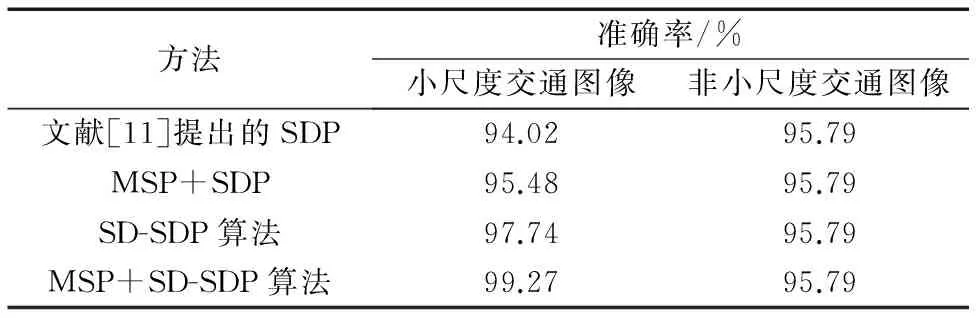
表4 各方法在不同尺度交通图像下准确率对比Tab. 4 Comparison of accuracies of different methods for traffic images with different scales
图4是部分交通标志样本的输出特征图,可以观察到,浅层的特征具有物体的简单边缘信息,而随着层数的加深,特征信息更加地抽象,非人眼可辨别的信息特征。文献[16]在理解及可视化卷积神经网络过程中,通过对大量目标体观察神经网络每一层的输出,分析了每一层提取特征的主要特点,得出深卷积神经网络特征具有更好的类别信息及完整的轮廓特性点。这也是本文作改进的原因。
为了客观对本文算法进行分析,将本文算法与其他交通标志的识别算法进行比较,有文献[15]中使用HOG+SVM的交通标志识别,以及目前在GTSRB数据集上取得最好结果的多列卷积神经网络[20],还对比了人类在交通标志识别中的表现[21]。表5列举了几种不同方法在GTSRB数据集的识别准确率与实时性的比较,可见相对于单一人工特征的识别分类,卷积神经网络自适应特征有着更加优异的表现,尤其针对识别目标,设计一种优秀的网络模型,提取有效的特征层信息,其识别准确率会大大提升。其中:文献[20]使用的多列卷积神经网络是目前唯一超过人类表现的,但是也不可避免地因卷积神经网络的程度过于复杂,造成一张图片的处理时间过长;文献[22]提出一种去除神经网络冗余参数的网络模型来提高交通图像识别准确率及实时性;文献[23]提出二级级联的神经网络进行细微类别信息的提取,来提高分类的准确率;文献[24]提出多任务的卷积神经网络完成交通标志感兴趣区域(Region Of Interest, ROI)的提取及对提取的感兴趣区域分类识别。而SDP作为一种探索不同卷积层的特征的小目标识别算法,本文将其改进应用到小尺度交通图像的识别中,虽然没有人类的识别准确率高,但前面的实验结果已经证明,通过改进的SD-SDP算法,有效完善了交通图像的轮廓信息,提高了交通标志的识别准确率,本文算法在平衡实时性及准确率方面,有一定的实用价值。

图4 卷积网络的各层可视特征图 Fig. 4 Feature map of each layer of convolution network 表5 不同方法在GTSRB数据集识别结果对比 Tab. 5 Results comparison of different methods for traffic sign identification in GTSRB dataset
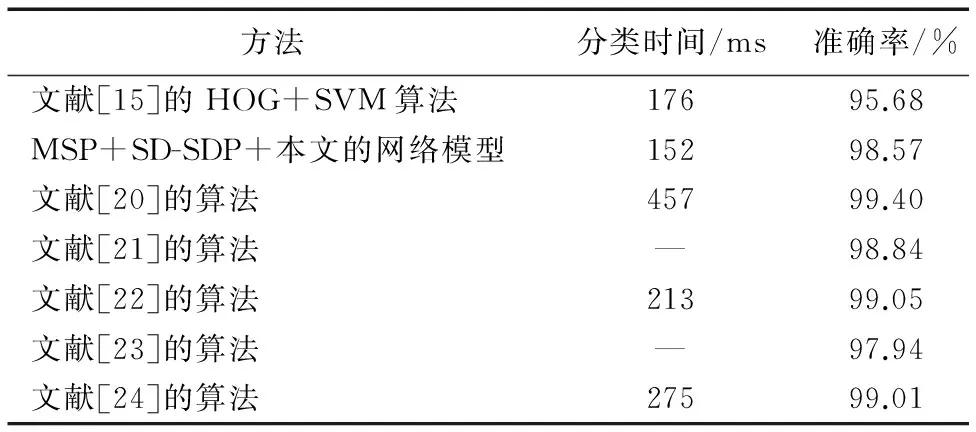
方法分类时间/ms准确率/%文献[15]的HOG+SVM算法17695.68MSP+SD-SDP+本文的网络模型15298.57文献[20]的算法45799.40文献[21]的算法—98.84文献[22]的算法21399.05文献[23]的算法—97.94文献[24]的算法27599.01
图5是未被识别的交通标志,交通标志存在污损严重、运动模糊、过度曝光等因素,导致交通标志的特征提取条件不利,因此不能正确识别交通标志。

图5 未被正确识别的交通标志 Fig. 5 Not properly identified traffic signs
4 结语
将SDP模型直接应用于小尺度交通图像的识别,会损失较好的深卷积层轮廓信息及类别特性,而影响交通标志识别的准确率。本文提出的改进SDP模型:首先,将深卷积层的特征与浅卷积层的特征进行融合,增强特征的表达能力;其次使用MSP算法将融合后的特征向量池化到固定的维度,补充了识别目标的边缘信息;最后理论分析及实验证明,在特征量增加的基础上,有效提高交通标志的识别准确率。但另一方面,小尺度交通图像经过需要更多的卷积及Pooling操作,导致耗时增加。接下来的研究,可以考虑在保证准确率不下降的情况下,减少训练耗时,使算法应用于实时交通序列中。
参考文献(References)
[1] YUAN X, HAO X, CHEN H, et al. Robust traffic sign recognition based on color global and local oriented edge magnitude patterns [J]. IEEE Transactions on Intelligent Transportation Systems, 2014, 15(4): 1466-1477.
[2] ZAKLOUTA F, STANCIULESCU B. Real-time traffic sign recognition in three stages [J]. Robotics and Autonomous Systems, 2014, 62(1): 16-24.
[3] SALTI S, PETRELLI A, TOMBARI F, et al. Traffic sign detection via interest region extraction [J]. Pattern Recognition, 2015, 48(4): 1039-1049.
[4] BRUNO M G S, MOURA J M F. Multiframe detector/tracker: optimal performance [J]. IEEE Transactions on Aerospace and Electronic Systems, 2001, 37(3): 925-945.
[5] HAN J, MA Y, ZHOU B, et al. A robust infrared small target detection algorithm based on human visual system[J]. IEEE Geoscience and Remote Sensing Letters, 2014, 11(12): 2168-2172.
[6] COLLATZ L. An image interpolation-based approach to the detection of small moving target [J]. Energy Procedia, 2011, 13(1): 2152-2157.
[7] 张阿珍,刘政林,邹雪城,等.基于双三次插值算法的图像缩放引擎设计[J].微电子学与计算机,2007,24(1):49-51.(ZHANG A Z, LIU Z L, ZOU X C, et al. Design of image scaling engine based bicubic interpolation algorithm [J]. Microelectronics and Computer, 2007, 24(1): 49-51.)
[8] TAKEKI A, TRINH T T, YOSHIHASHI R, et al. Combining deep features for object detection at various scales: finding small birds in landscape images[J]. IPSJ Transactions on Computer Vision and Applications, 2016, 8(1): 5-13.
[9] DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database [C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2009: 248-255.
[10] LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 3431-3440.
[11] YANG F, CHOI W, LIN Y. Exploit all the layers: fast and accurate CNN object detector with scale dependent pooling and cascaded rejection classifiers [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 2129-2137.
[12] CHOI W, YANG F, LIN Y. Cascaded neural network with scale dependent pooling for object detection: U.S. Patent Application 15/343,017[P]. 2016- 11- 03.
[13] HUANG Z, YU Y, GU J, et al. An efficient method for traffic sign recognition based on extreme learning machine[J]. IEEE Transactions on Cybernetics, 2017, 47(4): 920-933.
[14] LIU H, LIU Y, SUN F. Traffic sign recognition using group sparse coding [J]. Information Sciences, 2014, 266(10): 75-89.
[15] RUTA A, LI Y, LIU X. Real-time traffic sign recognition from video by class-specific discriminative features [J]. Pattern Recognition, 2010, 43(1): 416-430.
[16] ZEILER M D, FERGUS R. Visualizing and understanding convolutional networks [C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8689. Berlin: Springer, 2014: 818-833.
[17] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [J]. Computer Science, 2014, 9(4): 1409-1556.
[18] ZEILER M D. ADADELTA: an adaptive learning rate method [J]. Computer Science, 2012, 11(2): 1212-1221.
[19] SRIVASTAVA N, HINTON G, KRIZHEVSKY A, et al. Dropout: a simple way to prevent neural networks from overfitting [J]. The Journal of Machine Learning Research, 2014, 15(1): 1929-1958.
[20] CIRESAN D, MEIER U, MASCI J, et al. Multi-column deep neural network for traffic sign classification [J]. Neural Networks, 2012, 32: 333-338.
[21] STALLKAMP J, SCHLIPSING M, SALMEN J, et al. Man vs. computer: benchmarking machine learning algorithms for traffic sign recognition [J]. Neural Networks, 2012, 32: 323-332.
[22] AGHDAM H H, HERAVI E J, PUIG D. Toward an optimal convolutional neural network for traffic sign recognition [C]// Proceedings of the 8th International Conference on Machine Vision. Bellingham, WA: SPIE, 2015, 9875: 98750K.
[23] XIE K, GE S, YE Q, et al. Traffic sign recognition based on attribute-refinement cascaded convolutional neural networks [C]// Proceedings of the 17th Pacific-Rim Conference on Multimedia, LNCS 9916. Berlin: Springer, 2016: 201-210.
[24] LUO H, YANG Y, TONG B, et al. Traffic sign recognition using a multi-task convolutional neural network [J]. IEEE Transactions on Intelligent Transportation Systems, 2017, PP(99): 1-12.
XUZhe, born in 1968, Ph. D., associate professor. Her research interests include signal processing, adaptive control and intelligent instrument.
FENGChanghua, born in 1991, M. S.candidate. Her research interests include image processing, pattern recognition.
猜你喜欢
计算机应用(2022年9期)2022-09-25
汽车实用技术(2022年9期)2022-05-20
软件导刊(2022年3期)2022-03-25
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
计算机技术与发展(2019年1期)2019-01-21
智能计算机与应用(2018年2期)2018-05-23
太空探索(2016年5期)2016-07-12
小天使·一年级语数英综合(2016年8期)2016-05-14
时代英语·高三(2014年5期)2014-08-26
小天使·一年级语数英综合(2014年7期)2014-06-26
