
面向智能服务系统的时间语义理解
2018-05-21 00:49贾圣宾
计算机应用 2018年3期
贾圣宾,向 阳
(同济大学 电子与信息工程学院,上海 201804)
0 引言
时间是客观存在的,但在人类日常生活中,时间的表达需要借助自然语言描述出来。时间信息是自然语言表达中必不可少的一种语义信息。时间语义理解是自然语言处理的重要部分。
时间语义[1]即为描述事件发生、发展的时序信息。时间语义理解是将自然语言描述的时间语义信息以计算机可以处理的方式进行量化表示。本文将时间语义理解过程定义为,经过时间信息的抽取、映射和对时间语义的建模等一系列处理后,构建时间语义模型,从而结构化表达时间信息与语义理解结果。时间语义理解过程描述如图1所示。
如何有效地计算和理解自然语言中的时间语义,在人工智能领域,特别是智能服务行业具备重要的研究价值,如个人事务助理、智能聊天机器人等。智能服务系统中的自然语言文本富含时间信息,获取其时间语义,准确理解服务需求的时间语境,对智能服务的制定与提供非常关键。

图1 时间语义理解模型 Fig. 1 Model of temporal semantic understanding
这些时间信息具有如下特点:1)未来倾向性,服务文本中的时间大多是一个未来的时间,是对需求服务的时间条件的表达。2)独立性,服务消息文本一般为短句子,简要明确,几乎不存在句群的联合指代现象。3)实时性,消息文本具有实时特点,参考时间容易确定,一般为系统当前时间。不同于其他类型文本如新闻文本,发布具有滞后性,参考时间难以确定。4)明确性,服务消息中的时间短语表达往往可以明确一个时间点或时间段,但如“每天”“年年”这种表示频率的时间短语因不能明确地表达服务的时间需求,因此很少出现在智能服务系统。本文方法的研究是在上述服务信息文本时间信息特点基础上开展的。
人们的时间概念具有一致性,但对时间概念的描述却因语言表达的多样化而使得时间信息的表现形式具有灵活性和多样性[2],从而使得时间语言理解具有很大难度。目前时间语义理解方面的研究水平较低。文献[3]以概念网络为基础,构建了一种自然语言时间语义模型。文献[4]利用时间语法词典和时间本体库实现时间语义自动提取及时间语义结构填充。文献[5]提出了一种多层次时间语义表达结构和一种通用时间语义计算方法。时间语义理解是一个系统、复杂的研究任务。许多学者仅致力于其中子模块,如时间信息抽取、时间信息映射等的研究。
时间信息抽取一般采用基于规则的方法或基于序列标注的方法。基于规则的方法,通过手工制定规则来识别时间短语[6-10],如:文献[11]手工定义了24种规则模板匹配时间表达;文献[12]根据人工构建的启发式规则抽取时间短语并分解为一系列的时间基元,构建时间基元的规则库,以此抽取复杂的时间表达。此类方法使用简单,易于理解,但需要预备的词典和专家知识,工作量大,很难构建全面的规则库。基于序列标注的方法[13],如采用条件随机场[14-17]或最大熵模型[18-19]的序列标注机器学习算法,构建完善的特征向量是关键,如采用词汇特征[15-16]、位置特征[15]、依存特征[16, 19]、语义角色特征[14]等。基于序列标注的方法效果较好,但是结果好坏过分依赖于预先手工标注的训练语料的质量,还存在数据稀疏和词序依赖等问题。
时间信息映射方面,由于时间信息表现形式灵活多样,导致中文时间信息映射存在诸多难点,如相对时间转化问题、不完整时间补全问题等,导致时间短语规范化效果欠佳[8,20-21]。文献[10]利用6种时间转换算子及时间冲突处理算子输出其时间的规范化格式。文献[20]利用时间表达式模式及时间词典、近义词词典,采用模式匹配的方法把语料中的时间映射并转化为确定的时间值,需要制定精致的词典。
本文分析服务自然语言文本中时间信息表达规律,创建一套面向智能服务系统的时间语义理解模型,该模型研究主要从时间信息的抽取、映射和时间语义建模三个模块展开,最终设计时间语义模型表达时间语义信息,为一般的智能服务系统提供一种通用的时间表达模式。
1 基本概念
时间信息的表现形式具有灵活性和多样性。1)同一个时间可以有多种表述形式,比如“2017年10月1日”,可以简写成“2017-10-01”,也可以写成“国庆节”“十一”。2)时间语义信息会和上下文以及句义信息结合在一起,时间短语附加某些介词或方位词组合表达不同的时间语义。如“在12点时”表达了一个时点语义信息,“在12点以后”表达了一个时段语义信息。3)用户对时间表述时参照基准不一产生“绝对时间”和“相对时间”两种,比如,绝对时间“2005年9月30日”在某些语境下可以描述为相对时间“明天”。绝对时间可明确地表示时间轴上确切的一点。相对时间需要一个参照点才能表达明确的时间信息,在不同的参照点下,相对时间所表达的时间信息不同。参考时间可以是消息文本内容时间,也可能是当前时间 (即消息发布时间)。
时间信息主要以时间短语的形式出现。时间短语可描述两类时间对象:时点时间和时段时间,映射到时间轴上分别用点和区间来表示。时点时间表示某个事件发生的特定时间,可以用来回答“什么时候”的问题,也可以为事件发生的时间定位。时段时间表示具有起点、终点的或长或短的一段时间。时段大多可以回答“多长时间”的提问,可以标注事件可能发生的时间域。
时间短语是由时间基元构成的,时间基元即为时间要素的基本单元,如“2017年6月20日8点12分”由2017年、6月、20日、8点、12分5个时间基元构成。不同的时间基元表示不同的时间粒度。考虑服务系统中常用的时间信息,本文涉及5种不同的时间粒度,由粗至细分别为年(year)、月(month)、日(day)、时(hour)和分(minute)。
2 时间语义理解模型
2.1 时间信息抽取
本文设计了一个基于启发式策略的自动抽取时间信息算法。该方法并不依赖于时间触发词词典,无需人工制定规则模板,而是根据分词词性去抽取候选时间短语,通过限制策略过滤低质量时间短语,可以很好地解决时间表达模板的识别歧义问题。时间表达模板是最大化相邻时间单元的序列,即最长时间名词短语,通过启发式探索时间短语两端的介词和方位词,反复迭代,灵活地判断时间表达式的上下边界。自动抽取算法如图2所示。
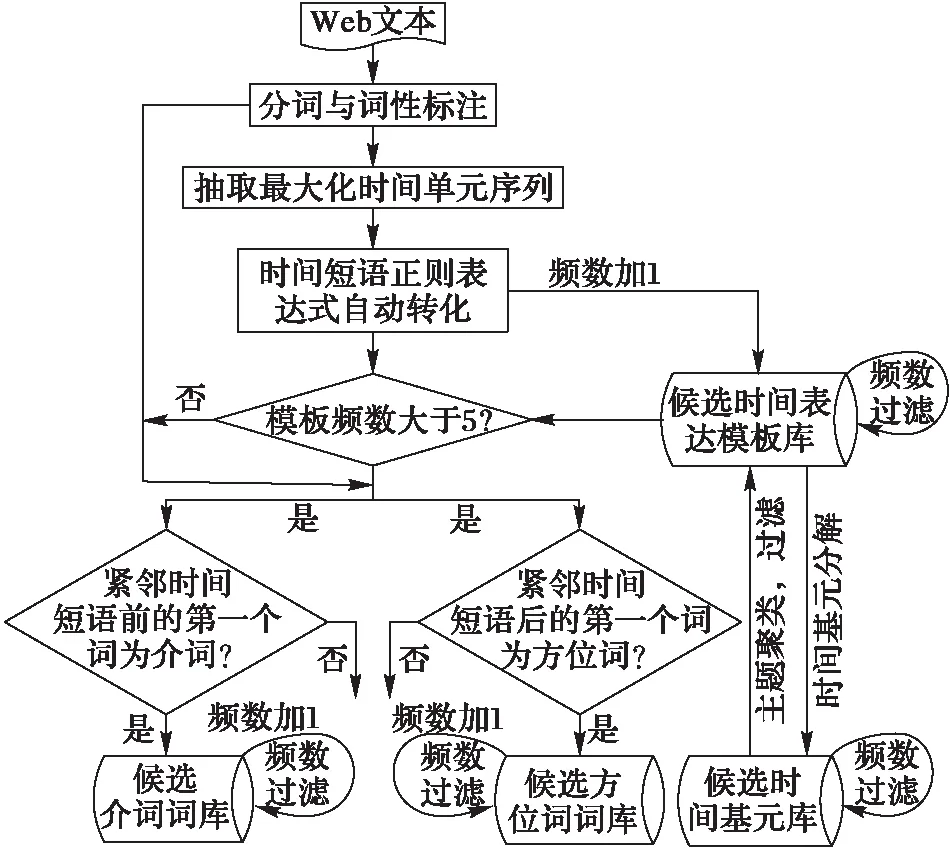
图2 时间信息自动抽取算法 Fig. 2 Automatic extraction algorithm for temporal information
由于高质量的服务文本语料较少,本文收集大量网络新闻文本以及文学作品等,这些文本中也包含大量的时间信息,可以起到一定的补充作用,待处理文本共约10 GB。为了避免分词与词性标注错误带来的干扰,本文利用集成学习的思想,利用四种分词工具对文本分别进行处理。
候选时间表达模板库中存储大量的候选时间短语,每个时间短语以三元组的数据结构存储,包括时间短语自动转化而来的时间短语正则表达式、频数、时间基元的正则表达式三部分。候选介词词库存储二元组形式的数据,包括介词本身和频数;同理,候选方位词词库存储由方位词本身和频数构成的二元组。
经过上述自动抽取过程后得到了候选的时间模板库、介词库以及方位词库。库中各条记录的统计频数越大,说明其越具有普遍性,转化为模板的正确率越高。因此,基于频数的过滤策略可以很好地降低抽取错误率,提高库的质量。根据各自的频数,低于设定阈值的将被过滤。更进一步,将过滤后的候选时间表达模板分解的时间基元构建“候选时间基元库”,并为每个时间基元统计频数,将频数低于阈值的过滤。不同的时间基元所表达的时间粒度不同,然后将这些时间基元进行聚类,聚类主题包括9大类,如表1所示。聚类方法采用K均值聚类算法,这里K取值9,各聚类中心点初始化时,分别指定为各主题中的一个实例。此外,未正则化的时间基元是一个个的名词,采用word2vec将它们转化为词向量,从而输入聚类模型。根据聚类结果,将离散的时间基元筛除,相应地把包含该时间基元的候选时间表达模板删除。经过双重过滤之后,可以得到高质量的时间信息库。
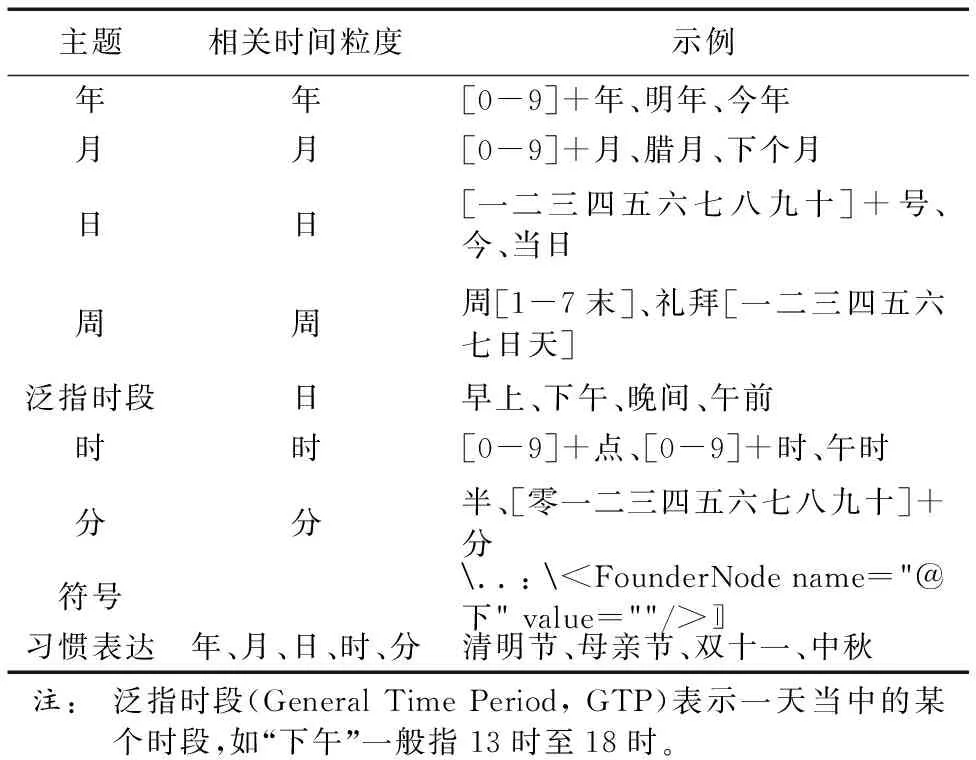
表1 时间基元聚类主题分类Tab. 1 Clustering theme classification of temporal unit
2.2 时间语义模型
时间语义模型是一种时间信息规范表达与时间语义表示的数据组织形式,目的是将服务文本中的时间信息抽取出来并进一步理解其语义,以结构化形式存起来,因此模型要尽可能全面地包含时间短语原始信息、规范化后信息和语义理解结果等,为后续服务制定提供充足的数据基础。
本文将时间语义模型定义为五元组TSM= (AT,RTP,PP,PD,ST)。其中:
RTP(Raw Temporal Phrase),是从文本中抽取出来的未经处理的原始时间短语表达。
AT(Absolute Time),为RTP所映射的一个规范绝对时间表达式。
PP(Pre-Preposition),为位于RTP前面的相关介词。
PD(Post-Direction),为位于RTP后面的相关的时间方位词。
ST(Semantic Type),为该时间短语在原文本中表达的语义类型。
本文采用基于多粒度时间基元的时间表达方式,将散乱的文本时间信息规范为结构化的时间表达。因此,AT定义为{year-month-day hour: minute}。其中的每个元素代表对应时间粒度下的时间信息。相邻的时间单位之间都具有一定的数量转换关系。时间单位系统是一种可扩展层级结构,可以方便地往其中添加具备转换关系的时间单位。该时间表达式为绝对时间的表达方式,相对时间经过推理映射也可以表达为这种形式。
时间短语可描述时点时间和时段时间两类时间对象。因此,时间语义类型定义为时点Tpoint和时段Tperiod两类。时点可以表示事件发生的开始时间、结束时间,或是事件执行过程中的某个特殊时间点。一个时段可以由二元组Tperiod(Tpoint1,Tpoint2)表示。Tpoint1表示事件发生的开始时间,或允许事件发生的最早时间;Tpoint2表示事件完成的结束时间,或允许事件开始的最迟时间,或允许事件完成的最晚时间。可能存在仅知时段的一个端点的特例情况,此时可表示为Tperiod(PAST,Tpoint2)或者Tperiod(Tpoint1, FUTURE)。
时间短语可以与时间介词PP或方位词PD联合表达多样的时间语义。例如对于时间短语“5月20日”,可以衍生出“截止5月20日”“在5月20日”“5月20日之后”等,这些短语包含不同的时间语义。因此,时间介词和方位词对于时间语义表达都具有重要意义。
2.3 时间信息映射
本文提出一种基于时间基元的映射方法,在已建立好的时间信息知识库基础上,首先建立起时间基元与规范时间单位的映射关系。从消息文本中根据时间表达模板抽取出每一个时间短语,依次自动地将其映射为绝对时间表达式。
对信息完整的时间表达短语,如“2017年10月1日15点30分”,它的AT比较容易得到,但是服务消息中大多是包含信息不完整的时间短语,本文总结了在时间信息映射过程中存在的几个难题:
1)相对时间转换。如“今天”“明年”等,需要参考一个日期才能确定。有的相对时间,如泛指时段,需要将其转换为一个时段。
2)不完整时间短语补全。需要确定一个参考时间,如“5月1日”需要参考一个年份才能映射到时间轴上。
3)时间未来倾向判定。比如在2017年6月20日发布消息中抽取出时间短语“明天下午5点40分”或“明天17点40分”,可以明确地判断该时间为2017年6月21日17时40分。但是对于时间短语为“5点40分”,如果消息发布是在同一天早晨的4时,该时间应该判定为2017年6月20日5时40分(当日早晨);若消息发布时间是下午2时,该时间应该判定为2017年6月20日17时40分(当日下午);再或者消息发布是在晚上8时,该时间应该判定为2017年6月21日5时40分(次日早晨)。人们在日常社交中十二小时制和二十四小时制的混用给时间标准化带来困难。
对于相对时间的处理,时间信息为时点或时段的判断将在下一节中描述。这里定义一组规则映射函数Rr,利用该函数集在绝对时间Ta的参照下,将目标相对时间Ti映射为绝对时间Tr:
Rr:{Ti,Ta,unit}→Tr
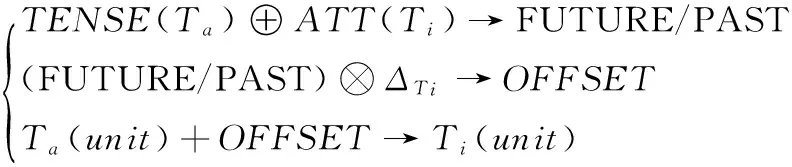
假设当前时间为2017年6月20日,相对时间“明天”,包含日粒度的时间基元“明天”,表示为unit。其属性是“将来”(ATT(Ta)=FUTURE)。参考时间是一般时TENSE(Ta) =PRESENT,和目标时间基元逻辑加所得结果为目标时间和参考时间的关系是“将来”。此关系包涵了时间的演化方向,与时间差量ΔTi(unit)=1 (单位日)逻辑乘,得到时间偏移量(符号为+或-),绝对时间的对应时间基元值与时间偏移量相加得到目标绝对时间Ti(unit)=21 (单位日),因此目标相对时间可以转化为绝对时间2017年6月21日。
结合泛指时段和参考时间判定目标时间的未来倾向,把时间判定为未来的一个距离参考时间最近的正确表达。涉及时间未来倾向判定问题的时间粒度主要包括周、时粒度。如果时间基元(unit)表示周(week)粒度,根据目标时间基元Ti(unit)与参考时间相应基元Ta(unit)的大小关系,计算目标时间时粒度基元Ti(day)的偏移量。如果unit表示时(hour)粒度,当其为24小时制时无需处理;否则,可根据时间短语Ti中存在的泛指时段GTP,将某些存在歧义的时间基元转化为24小时制。最后以参考时间为基准,计算目标时间的未来倾向偏移量,或是二分之一时单位周期时间halfCycle(hour)(12小时),或是全周期时间Cycle(hour)(24小时)。详情见算法1。
算法1 目标时间的未来倾向判定算法。
ifunitis week then
//时间基元(unit)表示周(week)粒度
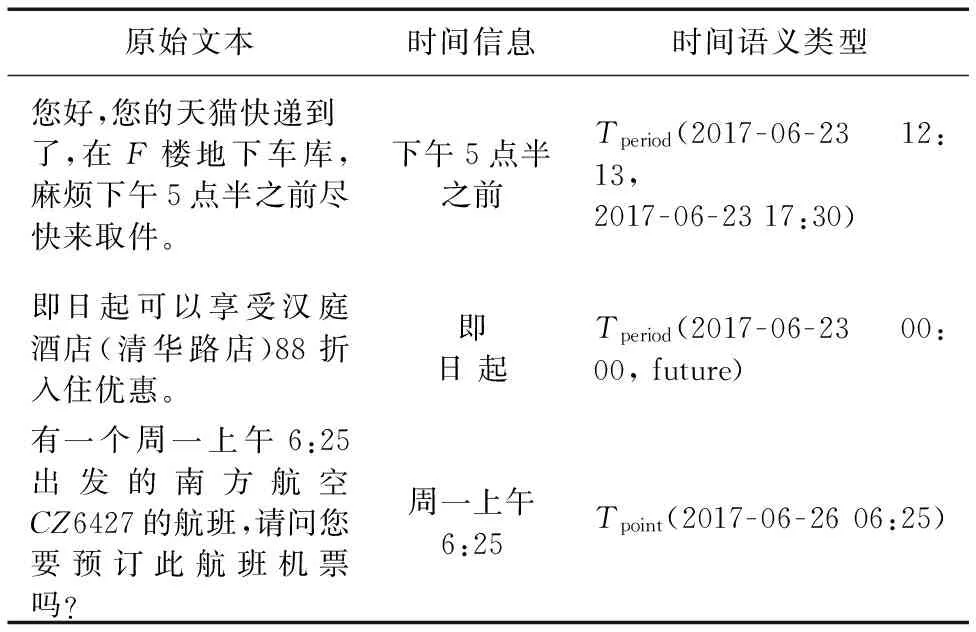
ifTi(unit) //目标时间基元Ti(unit)小于参考时间相应基元Ta(unit) Ti(day) +=Ti(unit) -Ta(unit) + Cycle(week)(=7) //计算目标时间时粒度基元Ti(hour)的偏移量 else Ti(day) +=Ti(unit) -Ta(unit) else ifunitis hour &Ti(unit)(0, 12) then //时间基元(unit)表示时(hour)粒度, 当其为12小时制时需处理 ifGTPis existed then //时间短语Ti中存在泛指时段GTP //将歧义的时间基元转化为24小时制 ifGTP[h1,h2] &Ti(unit)[max(0,h1-12), min(12,h2-12)] then //以参考时间为基准,计算目标时间的未来倾向偏移量 Ti(unit) += halfCycle(hour)(=12) el se ifTi(unit) <=Ta(unit) then Ti(unit) += Cycle(hour) end if else ifGTPis not existed then //时间短语Ti中不存在泛指时段GTP //将歧义的时间基元转化为24小时制 ifTi(unit) <=Ta(unit) then Ti(unit) += halfCycle(hour) ifTi(unit) <=Ta(unit) then Ti(unit) += halfCycle(hour) end if end if end if end if 服务信息文本中,不完整时间表达现象普遍存在。例如“预定10月11日从北京到上海的高铁,最好在上午9点前发车,同时预定静安寺附近的酒店,12日入住。”对于该句服务信息,其中包含“10月11日”“上午9点”“12日”三个不完整的时间短语。处于同一条信息语句中,因此它们处于同一时间语境内。考虑人们日常语言表达的省略习惯和参照信息发布时间(2017年10月9日星期一),可以将其尽可能地补全为“2017年10月11日”“2017年10月11日上午9点”和“2017年10月12日”。 本文刻画了3条不完整时间短语补全策略,用约束满足方法将文本中的模糊信息精确化: 1)同文本中抽取的其他时间短语分解出的更大粒度的时间基元可以补充目标时间短语的对应省略时间基元。如第一个时间短语中的时间基元“10月”和“11日”可以补充第二个时间短语,构成更加完善的时间表达“10月11日上午9点”,相反,“9点”不可以去补充第一个时间短语省略的时粒度基元。 2)同文本中先出现的时间短语分解的时间基元可以补充后出现的时间短语,反之不成立。例中第二个时间短语中日粒度基元根据第一个时间短语补全为“11日”是正确的,但由第三个时间短语中的“12日”来补全则是错误的。 3)同文本中时间短语互补操作执行后,时间短语仍无法补全的,可以利用信息发布时间去补充。因此,例中三个时间短语的年粒度基元均补全为“2017年”。 上述补全策略只适用于粒度为年、月、日的时间基元,时、分粒度的时间基元省略采用补零策略。上述策略可以根据时间语境信息较好地克服时间短语的不完整缺陷,对于时间信息量稀少的文本,如语句中只包含一个时间短语,可能效果欠佳。 时间语义信息会和上下文以及句义信息结合在一起,时间短语附加某些介词或方位词组合形成混合时间短语,时间词蕴含时点语义,其中介词和部分方位词可以表达时点语义倾向;同时,存在多时间短语联合表达时段语义信息的情况,如“从2018年2月1号到3月15号我们要去北京实习培训”,事件开始时间为2018年2月1号;同时,结束时间也继承上文时间,为2018年3月15号。此外,泛指时段(GTP)用法较特殊:一方面它还可以和其他时间基元组合使用,如“下午4点20分”,指示时间基元“4点”的未来倾向;另一方面GTP可以单独使用,表示一个时段。 时间语义建模是在时间短语抽取和时间信息映射的基础上,考虑时间信息与上下文之间以及多个时间之间的关系处理,进一步判定时间信息的语义类型,从而构建并完善时间语义模型五元组TSM。时间语义类型的判定主要考虑泛指时段、混合时间短语和多时间短语联合表达这三种特殊情况下的识别,本文采用算法2。 算法2 时间语义建模算法。 forTiinTPList ifTEXT.StrngAt(RTPi.endLocRTPi+1.startLoc)KBprepthen //判断相邻时间短语之间的字符串是否存在于介词知识库中 //识别多时间短语联合表达的情况 STi=STi+1=Tperiod(AT(RTPi),AT(RTPi+1)) TSMi+1=(AT(RTPi+1),RTPi-RTPi+1,PPi,PDi+1,STi+1) i++ else ifPPi!= null orPDi!=null then //根据时间介词或方位词的语义倾向PPi.sorient、 //PDi.sorient选择合适的时段语义类型 ifPDi.sorientis Forward orPPi.sorientis Forward then STi=Tperiod(AT(RTPi), future) else ifPDi.sorientis Backward orPPi.sorientis Backward then ifAT(now) STi=Tperiod(AT(now),AT(RTPi)) else STi=Tperiod(past,AT(RTPi)) end if end if else ifRTPiisGTPand alone then // 处理泛指时段GTP的语义类型 STi=Tperiod(AT(RTPi.GTP.period)) end if TSMi=(AT(RTPi),RTPi,PPi,PDi,STi) end for // 以上为时段语义类型的识别 从文本TEXT中抽取所有时间信息Ti存储在列表TPList中,首先判断相邻两时间短语RTPi和RTPi+1之间的字符串是否存在于介词知识库KBprep中,从而识别多时间短语联合表达的情况;然后根据时间短语两侧的介词或方位词的语义倾向PPi.sorient、PDi.sorient,选择合适的时段语义类型;最后处理泛指时段GTP的语义类型。以上为时段语义类型的识别,剩余的全部识别为时点语义类型,构建并完善时间语义模型五元组TSMi。 本文收集智能服务系统消息文本300条构建测试集,验证语义理解模型各模块在智能服务系统自然语言文本分析中的效果,并展示了模型语义建模结果。 本文利用准确率(Precision)、召回率(Recall)和F-measure值作为实验的评测标准。 由表2知,本文提出的时间信息抽取方法取得了不错的效果。基于规则的方法需要手工制定规则模板,与其相比,本文方法基于大规模语料自动抽取时间表达模板的方法在准确率和召回率上都有提升。基于监督训练算法条件随机场(Conditional Random Field, CRF)的序列标注方法,参照文献[15]的方法,取得了比本文方法稍好的效果,但该方法需要人工标注训练集,费时费力;而本文方法抽取过程是自动的,无需人工干预,因此本文方法在牺牲部分性能的基础上大大降低了人工成本。 由表3知,本文模型在服务消息文本上时间信息映射模块准确率也达到了87.88%。统计结果显示,在服务文本中相对时间表达占了一半以上,本文提出的专门针对相对时间转化的方法取得较好效果。此外,对时间未来倾向判定的处理效果最差,因为它是在其他处理结果之上的再处理,会有错误传递现象的发生。 表4为语义建模结果的示例,其中消息发布时间设定为2017年6月23日星期五12时13分。 表2 时间信息抽取模块测试结果比较Tab. 2 Comparison of results in temporal information extracting 表4 时间语义建模结果展示Tab. 4 Results of temporal semantic modeling 时间信息是智能服务制定的基础,时间语义理解在智能服务系统中发挥着重要作用。本文构建的针对服务消息文本的自然语言时间语义理解模型,实现了对时间信息的抽取、映射和语义建模,可以为智能信息系统提供通用的时间表达模式。本文实现了自动抽取时间表达模板,并构建时间信息知识库,无需人工建立抽取规则,无需人力搜集时间词词典,也不必人工标注训练集,大大节省人力资源。时间信息映射模块是基于时间基元开展的,这样的方法能够有效处理不同粒度的时间单位之间的影响关系。最后,综合利用时间自身信息与上下文信息设计时间语义建模算法,判定时间信息的语义类型,从而构建时间语义模型。本文方法也存在不足,比如,本文只涉及一般时间短语的处理,对于事件时间短语,如“他去上海之前”等,本文模型没有考虑。时间表达模板是基于序列匹配的,会错误识别非时间短语。 未来,可以研究如何进一步提高时间信息映射算法的泛化能力,使之适应更广泛的应用领域,同时进一步完善时间语义模型,使其表达更丰富的时间语义。 参考文献(References) [1] STEEDMAN M. 21—temporality [M]// van BENTHEM J, TER MEULEN A. 2nd ed. Handbook of Logic and Language. Amsterdam: Elsevier, 2011: 925-969. [2] 贺瑞芳,秦兵,刘挺,等.基于依存分析和错误驱动的中文时间表达式识别[J].中文信息学报,2007,21(5):36-40.(HE R F, QIN B, LIU T, et al. Recognizing the extent of Chinese time expressions based on the dependency parsing and error-driven learning [J]. Journal of Chinese Information Processing, 2007, 21(5): 36-40.) [3] 杜津.自然语言时间语义信息处理[D].北京:中国科学院自动化研究所,2005:25-34.(DU J. Natural language temporal semantic information processing [D]. Beijing: Institute of Automation, Chinese Academy of Sciences, 2005: 25-34.) [4] 成斌.汉语时间语义分析及推理[D].长沙:国防科学技术大学,2005:49-58.(CHENG B. Analysis and inference of Chinese temporal semantics [D]. Changsha: National University of Defense Technology, 2005: 49-58.) [5] 郭宏蕾,姚天顺.自然语言中时间信息的模型化[J].软件学报,1997,8(6):432-440.(GUO H L, YAO T S. Modeling of temporal information in natural language [J]. Journal of Software, 1997, 8(6): 432-440.) [6] WU M, LI W, LU Q, et al. CTEMP: a Chinese temporal parser for extracting and normalizing temporal information [C]// Proceedings of the 2005 International Conference on Natural Language Processing, LNCS 3651. Berlin: Springer, 2005: 694-706. [7] CHAMBERS N. Navytime: event and time ordering from raw text [EB/OL]. [2017- 04- 11]. https://www.cs.york.ac.uk/semeval-2013/accepted/75_Paper.pdf. [8] 左亚尧,龙耀发,李杰骏.基于规则的中文时间表达式识别与规范化[J].广东工业大学学报,2014, 31(3):88-94.(ZUO Y Y, LONG Y F, LI J J. Recognition and normalization of Chinese time expressions based on rules [J]. Journal of Guangdong University of Technology, 2014, 31(3):88-94.) [9] 林静,曹德芳,苑春法.中文时间信息的TIMEX2自动标注[J]. 清华大学学报(自然科学版), 2008, 48(1):117-120.(LIN J, CAO D F, YUAN C F. Automatic TIMEX2 tagging of Chinese temporal information [J]. Journal of Tsinghua University (Science and Technology), 2008, 48(1): 117-120.) [10] 李明月,王树鹏,王海平,等.面向安全事件新闻的时间抽取与转换[J].高技术通讯,2015,25(12):1040-1046.(LI M Y, WANG S P, WANG H P, et al. Extraction and normalization of temporal expressions for news reports on security events [J]. Chinese High Technology Letters, 2015, 25(12):1040-1046.) [11] 赵国荣.中文新闻语料中的时间短语识别方法研究[D].太原:山西大学,2006:11-15.(ZHAO G R. Research into temporal expressions of Chinese news [D]. Taiyuan: Shanxi University, 2006: 11-15.) [12] 邬桐,周雅倩,黄萱菁,等.自动构建时间基元规则库的中文时间表达式识别[J].中文信息学报,2010,24(4):3-10.(WU T, ZHOU Y Q, HUANG X J, et al. Chinese time expression recognition based on automatically generated basic-time-unit rules [J]. Journal of Chinese Information Processing, 2010, 24(4): 3-10.) [13] ZHAO H, JI X. English temporal expression recognition based on conditional random fields [C]// Proceedings of the 2013 9th International Conference on Natural Computation. Piscataway, NJ: IEEE, 2013: 1088-1092. [14] 刘莉,何中市,邢欣来,等.基于语义角色的中文时间表达式识别[J].计算机应用研究,2011,28(7):2543-2545.(LIU L, HE Z S, XING X L, et al. Chinese time expression recognition based on semantic role [J]. Application Research of Computers, 2011, 28(7):2543-2545.) [15] 朱莎莎,刘宗田,付剑锋,等.基于条件随机场的中文时间短语识别[J].计算机工程,2011,37(15):164-167.(ZHU S S, LIU Z T, FU J F, et al. Chinese temporal phrase recognition based on conditional random fields [J]. Computer Engineering, 2011, 37(15): 164-167.) [16] 高源,席耀一,李弼程,等.基于词典特征优化和依存关系的中文时间表达式识别[J].信息工程大学学报,2016,17(4):490-495.(GAO Y, XI Y Y, LI B C, et al. Chinese temporal expression recognition algorithm based on optimization of dictionary features and dependency parsing [J]. Journal of Information Engineering University, 2016, 17(4): 490-495.) [17] 吴琼,黄德根.基于条件随机场与时间词库的中文时间表达式识别[J].中文信息学报,2014,28(6):169-174.(WU Q, HUANG D G. Temporal information extraction based on CRF and time thesaurus [J]. Journal of Chinese Information Processing, 2014, 28(6): 169-174.) [18] 李君婵,谭红叶,王风娥.中文时间表达式及类型识别[J].计算机科学,2012,39(S3):191-194.(LI Y C, TAN H Y, WANG F E. Recognition of temporal expressions and their types in Chinese [J]. Computer Science, 2012, 39(S3): 191-194.) [19] 王风娥. 汉语文本中的时间关系识别技术研究[D]. 太原:山西大学, 2012:9-14.(WANG F E. Recognition of temporal relation in Chinese texts [D]. Taiyuan: Shanxi University, 2012: 9-14.) [20] 温艳霞.中文时间规范化方法研究[D].太原:山西大学,2010:19-24.(WEN Y X. Research on time standardization in Chinese [D]. Taiyuan: Shanxi University, 2010: 19-24.) [21] 郑立洲.短文本信息抽取若干技术研究[D].合肥:中国科学技术大学,2016:40-45.(ZHENG L Z. Research on some key issues in short text information extraction [D]. Hefei: University of Science and Technology of China, 2016: 40-45.) [22] 左亚尧,龙耀发,李杰骏.中文时间关键词识别研究[J].计算机应用研究,2017,34(4):981-985.(ZUO Y Y, LONG Y F, LI J J. Extraction of Chinese temporal keywords [J]. Application Research of Computers, 2017, 34(4): 981-985.) This work is partially supported by the National Natural Science Foundation of China (71571136), the National Basic Research Program (973 Program) of China (2014CB340404), the Basic Research Project of Science and Technology Commission of Shanghai Municipality (16JC1403000). JIAShengbin, born in 1994, Ph. D. candidate. His research interests include natural language processing, service computing. XIANGYang, born in 1962, Ph. D., professor. His research interests include natural language processing, service computing.2.4 时间语义建模
3 实验
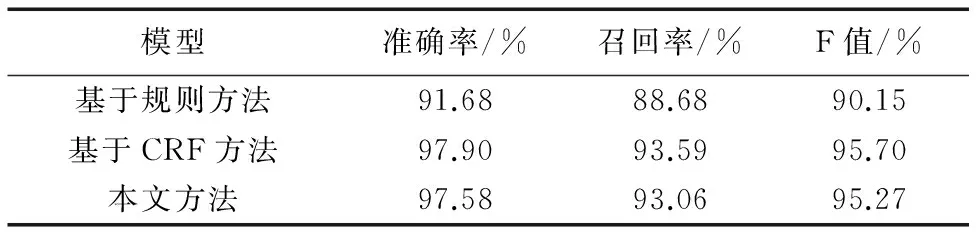
4 结语
猜你喜欢
兵工学报(2022年2期)2022-05-22粉末冶金技术(2021年3期)2021-07-28兵工学报(2021年4期)2021-06-19小型微型计算机系统(2020年10期)2020-10-21兵工学报(2020年12期)2020-02-06综艺报(2018年17期)2018-09-14计算机研究与发展(2018年6期)2018-06-08科学导报(2018年30期)2018-05-14新作文·高中版(2017年6期)2017-07-06中国文化遗产(2009年6期)2009-01-11
