
基于CTM模型的观点挖掘和可视化*
2018-05-08 09:39:02马长林谢罗迪陈梦丽
计算机工程与科学 2018年4期
马长林,谢罗迪,陈梦丽
(华中师范大学计算机学院,湖北 武汉 430079)
1 引言
如今的网络媒体时代,微博、微信、BBS论坛等信息媒介层出不穷,这些信息平台已经成为人们生活中必不可少的一部分,再加上移动终端设备以及无线通信技术的发展,大众可以随时随地利用手机、平板等设备获取互联网资源,人们可以方便地进行信息分享和人际交流。
互联网中的网页信息绝大部分以文本的方式存在,根据这些文本的描述性质可以将其划分为主观信息文本与客观信息文本两大类别。主观文本中的内容往往带有个人的感情色彩,以文本撰写者的意志为起点来发表对某一物品或者事件的观点;客观文本则是客观地没有掺杂个人主观感情色彩地去描述物品或事件的特征与属性。无论是主观文本或者客观文本,其中所包含的观点信息都是非常重要的,通过获取这些观点信息,人们可以宏观地把握某一事物具体的特征,进而推动社会和生产技术的进步。因此,当下面对大数据时代产生的海量网络评论,如何快速提取其背后隐藏的主题观点特征并进行情感分析,这是眼下亟待解决的问题,也是观点挖掘研究大发展的原因。
观点挖掘是当前自然语言处理领域的热门话题,被国内外学者广泛研究,它是指通过相关技术分析文本中表达的观点与情感极性,帮助用户快速地获取有用信息。情感极性一般被分为正向、负向、中性,正向表示情感倾向为褒义,负向表示情感倾向为贬义,而中性则表示没有明显的褒贬倾向,还有些学者将文档的情感倾向采用定量的方式来表示,例如分值1~9,这样不仅可以表示出情感倾向,还可以描述倾向的强弱。观点提取主要是挖掘文档背后潜在的观点,主要包含情感分析、特征词和观点词抽取聚类[1,2],在此基础上获取相关词表和文档主题评论摘要[3 - 5]。
目前,采用LDA(Latent Dirichlet Allocation)主题模型进行观点挖掘已取得很多研究成果[6 - 9],它是在假设文档主题独立的前提下进行观点抽取,但实际上主题与主题之间有着复杂的层次关系和内在联系;为此,Blei等[10,11]对LDA模型加以改进提出了相关主题模型CTM(Correlated Topic Model),对主题用正态对数分布取代了标准LDA模型中的狄利克雷分布,进而对主题相关性进行了分析,CTM模型的应用已经涉及自然语言处理的很多领域。
朱韶平等[12]以CTM模型和词间相关性为基础利用启发式迭代算法进行图像标注,提高了标注词的准确性。王燕霞等[13]利用CTM模型对数据集建模以降低数据维度,同时用支持向量机SVM(Support Vector Machine)对简化后的数据进行文本分类,取得了较高的分类精确度。徐桂彬等[14]首次将CTM模型运用到了音乐分类中,他们利用DBSCAN(Density-Based Spatial Clusting of Application with Noise)聚类为CTM模型选取最佳主题数目,同时将HMM(Hidden Markov Model)算法与CTM模型相结合提出了动态相关主题模型,提高音乐分类系统的性能。然而,目前还鲜有研究将CTM模型用于观点挖掘领域进行情感分析。
综合以上利弊,本文对CTM模型进行了改进,在引入情感层的基础上提出基于主题情感混合的CTM模型STCTM(Sentiment-and-Topic hybrid Correlated Topic Model),在分析主题相关性的前提下实现文档主题的观点特征提取和情感极性的分析。
2 STCTM模型描述
标准LDA主题模型中存在着狄利克雷与多项式分布这样一对共轭分布,在为一个单词选取主题时先由狄利克雷分布超参数得到一个关于主题的多项式分布,由多项式分布再获取主题,使用狄利克雷先验分布决定了主题是相互独立的,实际上文档中的主题与主题之间存在着复杂的层次关系和内在联系,例如体育类别下的文档经常讨论的主题“篮球”与“乒乓球”,二者在对应主题的特征词上具有一定的共性;主题与主题之间的出现也有一定的先后顺序,在一篇关于旅游的文档中,在出发之前讨论的主要是攻略、注意事项等话题,到达目的地以后则更多地会讨论具体的景点。LDA模型无法反映主题之间这种复杂的关系,而CTM模型则能很好地解决这一问题。
在CTM主题模型中,主题服从的分布不再服从狄利克雷分布,取而代之的是正态对数分布,模型图如图1所示[10]。
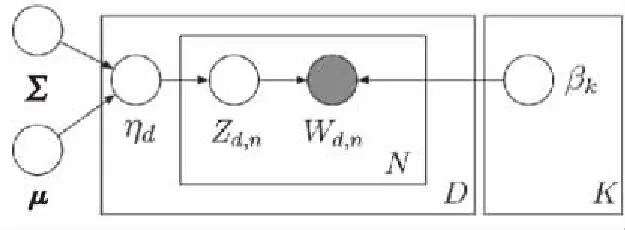
Figure 1 CTM model图1 CTM模型
从图1可以发现,CTM仍然是一个层次模型,与LDA主题模型类似,同样认为文档由不同的主题按照一定比例混合生成,而主题则是由不同的单词按照一定比例混合生成。其中βk表示主题k下单词的多项式分布;Wd,n表示第d篇文档下第n个单词;Zd,n表示第d篇文档中第n个单词的主题;ηd则为第d篇文档下的主题分布,其服从参数为μ,Σ的对数正态分布,ηd~N(μ,Σ),μ为K维均值向量,用来表示文档下的主题分布,Σ是一个K行K列的协方差矩阵,用于表示文档中主题与主题之间的内在联系。
CTM模型中将主题所服从的狄利克雷分布替换为正态对数分布,用以表征主题与主题之间的内在联系。由于正态分布没有类似狄利克雷分布与多项式分布共轭的性质,因此常规求解LDA模型的方法比如Gibbs采样等都不能够使用。
CTM主题模型与LDA主题模型类似也是一个生成模型,其生成文档过程描述如下[10]:
(1)对于一个语料库:
得到语料库中对应每个主题下的单词分布βk。
(2)对于语料库中的第d篇文档:
由正态分布先验参数得到其主题分布ηd,ηd服从参数为μ,Σ的对数正态分布。
(3)对于第d篇文档中的第n个单词Wd,n:
①从文档d中主题的多项式分布ηd中为单词Wd,n选择一个主题;
②从上述选定的主题所对应的单词多项式分布βk中确定具体的单词。
在利用CTM模型进行观点挖掘时,对于一个语料库如果已经确定其主题数目K以及其他相关参数,则需要推测语料库中文档的隐藏主题分布ηd,Blei等[11]提出使用快速变分推断算法用以近似估计。
对于语料库中的第ω篇文档,若其主题服从的正态对数先验和对应主题下的单词分布βk已经确定,则文档d中隐藏的主题后验分布如公式(1)所示:
p(η,z|ω,β1:k,μ,Σ)=
(1)
利用CTM模型进行观点挖掘研究,不仅可以获得对应主题下的特征词,还可以获得不同主题之间的内在联系,但它没有考虑到单词背后所隐藏的情感。为解决该问题,本文对CTM模型进行改进,提出STCTM模型,在主题层与单词层之间引入情感层进行情感极性分析,利用对数正态分布描述主题间相关性,在获取对应主题观点特征的同时,还得到每一主题下的情感分布。STCTM模型如图2所示,模型中参数含义如表1所示。
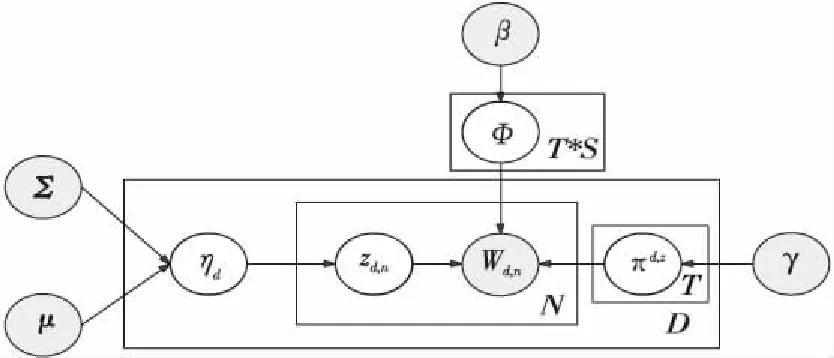
Figure 2 STCTM model图2 STCTM模型
STCTM模型生成文档过程描述如下:
(1)对一个语料库:
由狄利克雷先验参数β获得语料库中对应主题与情感下的单词分布Φt,s~Dir(β)(其中s表示

Table 1 Meanings of the notations in STCTM model表1 STCTM模型中符号含义
情感,取值-1,1;t表示主题,取值1,…,T)。
(2)对语料库中每一篇文档d:
①由对数正态分布参数{μ,Σ}得出文档下主题的多项式分布ηd~N(μ,Σ);
②由Beta先验参数γ得出对应主题下的情感分布πd,z~Beta(γ) (其中z表示主题,取值1,…,T)。
(3)对每一篇文档d中的第n个单词 :
①选择对应的主题zd,n,其中zd,n~Multinomial(ηd);
②选择对应主题下的情感sd,n,z,sd,n,z~Multinomial(πd,z);
③选择对应主题与情感下具体的单词,wd,n~Multinomial(Φt,s)。
3 STCTM模型推理
STCTM模型在CTM模型的基础上引入了情感层进行情感极性分析,在文档主题所服从的分布上与CTM模型类似,采用正态对数分布来处理主题间的相关性,而单词与情感的分布则与LDA模型类似,服从的是狄利克雷分布。
对STCTM模型的求解主要在于求解主题与情感的后验分布,由于情感服从狄利克雷分布,其求解过程与标准LDA模型类似,采用Gibbs采样算法进行求解,主题所服从的正态对数分布由于其不与多项式分布共轭,不能直接用积分求出,因此计算难度较大,本文采用变分推断的方式进行求解。
STCTM模型中主题的后验分布如公式(2)所示:
p(η,z|d,μ,Σ)=
(2)
其中,zn表示第n个单词的主题;分子表示对某个具体的η文档d中所有单词{w1,…,wn}取对应主题{z1,…,zn}的概率;分母则表示对η取所有可能的值时,文档d中所有单词{w1,…,wn}取所有主题的概率。由于正态对数分布与多项式分布不是一对共轭分布,对于分母的积分不能像LDA模型中推导后验概率一样使用马尔可夫链蒙特卡罗MCMC(Markov Chain Monte Carlo)的采样技巧直接求出,本文借助Blei[11]在其论文中所提出的解决办法。为了近似估计后验概率,采用变分法替代MCMC确定法估算出最真实的后验概率。变分方法的思想是优化一个对隐含变量的分布自由的参数,用以接近真实的后验分布。
首先,利用詹森不等式对文档的log似然函数进行可调约束,如公式(3)所示:
logP(w1:N|μ,Σ,β)≥
(3)

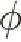
通过主题的后验分布为单词确定主题以后,使用Gibbs采样确定文档情感的后验概率。Gibbs抽样算法通过积分避免了对实际待估参数的直接计算,而是对文档中的每个词采样主题标签,然后在对应主题下具体选择一个单词,采样完成以后通过统计单词与主题频率计算模型参数。采样公式如(4)所示:
(4)

4 仿真实验
本文实验使用的开发工具为Java语言和R语言,实验数据来源于搜狗实验室提供的中文语料库,它们来自Internet的原始网页,涉及包括体育、汽车、财经等10个类别。
先对语料库文本进行预处理,主要是去除停用词和分词处理。实验步骤分为两部分:(1)主题相关性分析;(2)实验结果可视化。
本文提出的STCTM模型是对CTM模型的改进,在考虑主题相关性的前提下引入情感层进行情感极性分析。
首先从实验数据中抽取100篇文档,做出它们的文档词云图,如图3所示,按照指定的顺序给出每个关键词的颜色,同时使用词频参数进行设置,按照词频出现高低从大到小显示。从图3中可以看出文档大致分为10类,其中云图中各颜色分布表示不同类型文档所占比例。

Figure 3 Word cloud picture of document图3 文档词云图
再以体育类别下的1 990篇文档作为语料库进行观点抽样。CTM模型和STCTM模型的观点抽样结果分别如表2和表3所示。
对比表2与表3可知,在引入情感层后,STCTM模型在获取对应主题特征的同时还可以获取主题背后隐藏的情感极性,观点挖掘效果更加细腻有价值。
STCTM模型中协方差矩阵Σ如表4所示。
协方差矩阵是一个对角矩阵,由协方差矩阵可以计算出主题之间的相关性值表,如表5所示。表5中cor项代表主题之间的相关性取值,若为正,则代表主题之间正相关;若为负,则代表二者之间负相关。呈正相关的两个主题同时出现在一篇文档中的概率较大,并且随着相关性取值的增大概率也逐渐增大;呈负相关的两个主题同时出现在同一篇文档的概率则较小。观察表5可以发现,本文所设定的10个主题之间正相关的主题较多,这与实验所选用体育类别下的文档作为语料库有关,在体育类别中常见的主题例如“篮球”“足球”“乒乓球”等联系非常紧密。主题3与主题7正相关性最高。
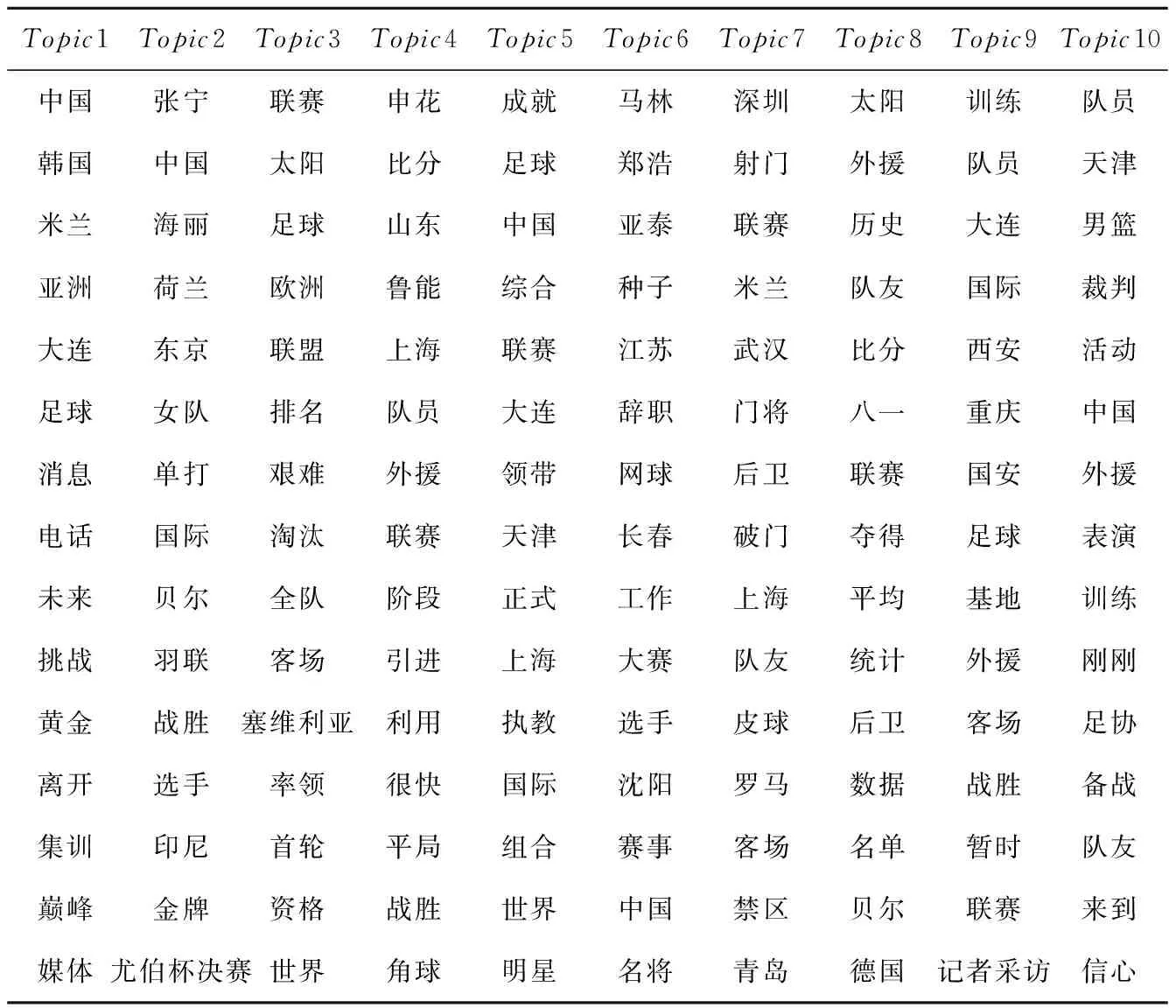
Table 2 Opinion sampling results of CTM model表2 CTM模型观点抽样结果
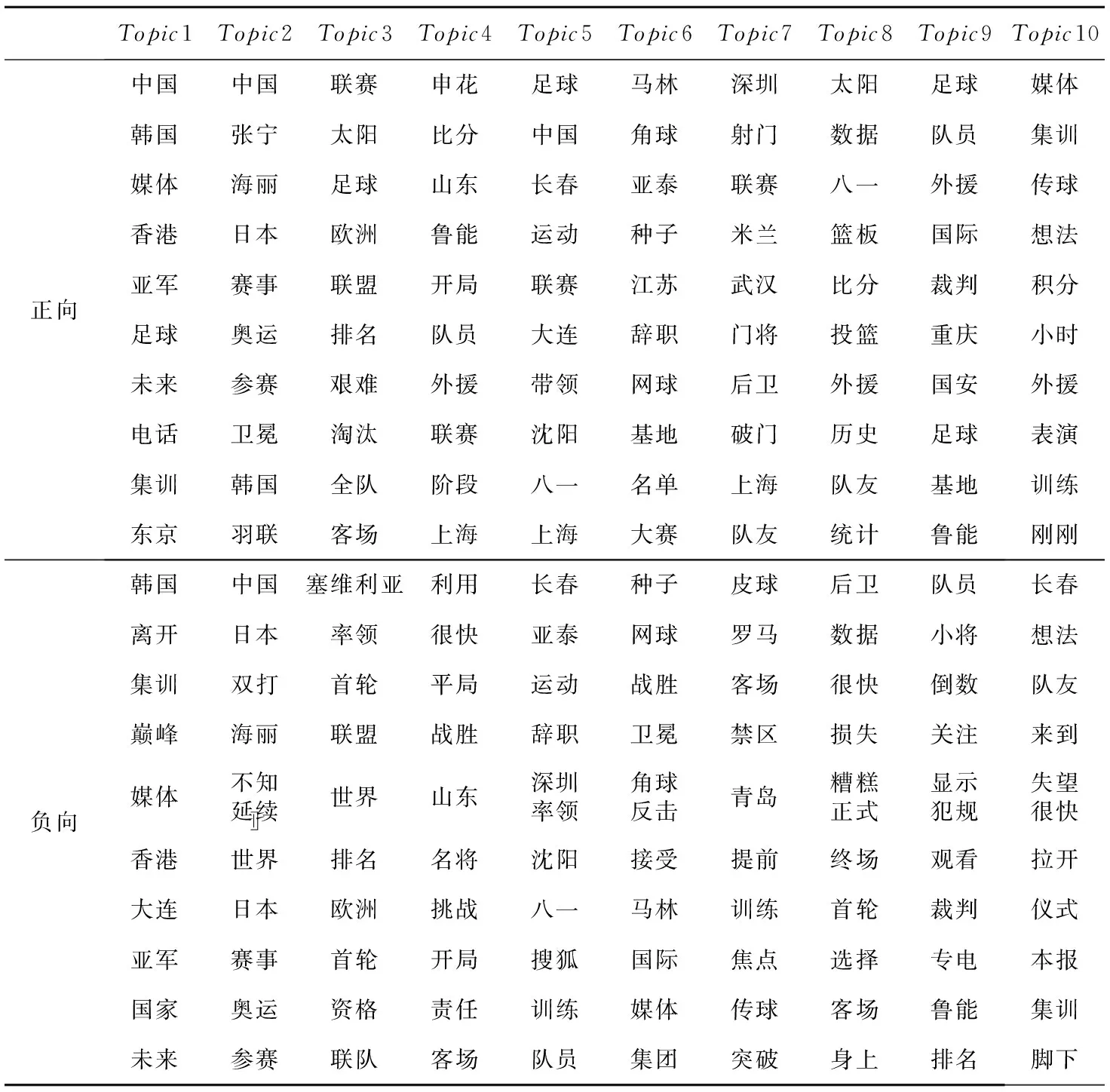
Table 3 Opinion sampling results of STCTM model表3 STCTM模型观点抽样结果

Table 4 Covariance matrix表4 协方差矩阵
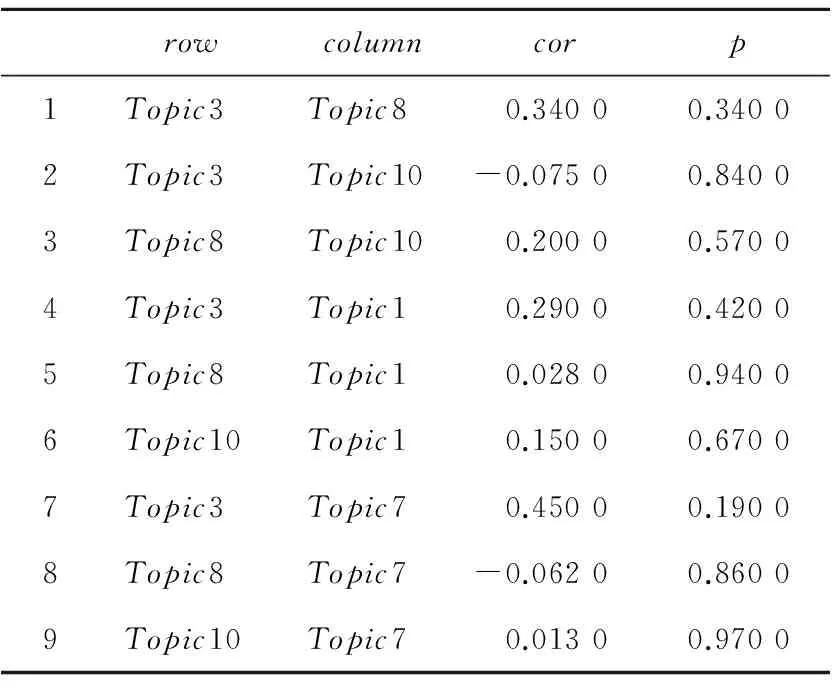
Table 5 Correlation values between topics表5 主题之间相关性取值
为了更直观清晰地展示主题之间的相关性,对表5进行可视化得到主题相关性图,结果如图4所示。图4中,圆圈表示两个主题之间正相关,而三角形表示主题之间负相关,颜色越深则表示相关性越强。观察图4发现,对角线上的圆圈颜色最深,这表示每个主题与自身之间都是强正相关。
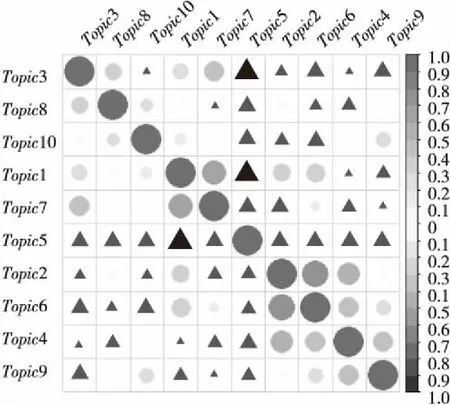
Figure 4 Figure of correlation between topics图4 主题相关性图
5 结束语
本文对CTM模型进行了改进,在引入情感层的基础上提出基于主题情感混合的STCTM模型,在考虑到主题相关性的同时,还分析了对应主题下的观点特征以及潜藏的情感倾向,更为精确地获取了文档主题的情感极性。实验结果验证了本文理论的正确性,可视化分析多方位丰富了实验数据的显示效果。
参考文献:
[1] Bethard S,Yu H,Thornton A,et al.Automatic extraction of opinion propositions and their holders[C]∥Proc of the 2004 AAAI Spring Symposium on Exploring Attitude and Affect in Text,2004:22-24.
[2] Choi Y,Cardie C,Riloff E,et al.Identifying sources of opinions with conditional random fields and extraction patterns[C]∥Proc of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing,2005:355-362.
[3] Kaji N,Kitsuregawa M.Building lexicon for sentiment analysis from massive collection of HTML documents[C]∥Proc of the Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-Co NLL),2007:1075-1083.
[4] Qiu G,Liu B,Bu J,et al.Expanding domain sentiment lexicon through double propagation[C]∥Proc of the 21st International Joint Conference on Artifical Intelligence,2009:1199-1204.
[5] Kanayama H, Nasukawa T.Fully automatic lexicon expansion for domain-oriented sentiment analysis[C]∥Proc of the Conference on Empirical Methods in Natural Language Processing (EMNLP),2006:355-363.
[6] Titov I, McDonald R. Modeling online reviews with multi-grain topic models[C]∥Proc of the 17th International Conference on World Wide Web,2008:111-120.
[7] Brody S,Elhadad N.An unsupervised aspect-sentiment model for online reviews[C]∥Proc of Human Language Technologies:The Annual Conference of the North American Chapter of the Association for Computational Linguistics,2010:804-812.
[8] Zhao X,Jiang J,Yan H,et al.Jointly modeling aspects and opinions with a MaxEnt-LDA hybrid[C]∥Proc of the Conference on Empirical Methods in Natural Language Processing(EMNLP),2010:56-65.
[9] Mei Q,Ling X,Wondra M,et al.Topic sentiment mixture:Modeling facets and opinions in weblogs[C]∥Proc of the 16th International Conference on World Wide Web, 2007:171-180.
[10] Blei D,Lafferty J.Correlated topic models [J].Advances in Neural Information Processing Systems,2005,18(1):147-154.
[11] Blei D, Lafferty J.Correction:A correlated topic model of science[J].Annals of Applied Statistics,2007,1(2):634.
[12] Zhu Shao-ping, Xia Li-min,Zhu Cheng.Image annotation based on CTM model and optimal tag sets [J].Journal of Fudan University(Natural Science),2014,53(1):147-153.(in Chinese)
[13] Wang Yan-xia,Deng Wei.Text classification method combining CTM and SVM [J].Computer Engineering,2010,36(22):203-205.(in Chinese)
[14] Xu Gui-bin. Research on the music classification method based on correlated topic model [D].Suzhou:Soochow University,2012.(in Chinese)
附中文参考文献:
[12] 朱韶平,夏利民,朱城.基于CTM模型和最优标签集的图像标注[J].复旦学报(自然科学版),2014,53(1):147-153.
[13] 王燕霞,邓伟.CTM与SVM相结合的文本分类方法[J].计算机工程,2010,36(22):203-205.
[14] 徐桂彬.基于相关主题模型的音乐分类方法研究[D].苏州:苏州大学,2012.
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
工程数学学报(2020年3期)2020-07-06 07:38:40
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
长治学院学报(2019年2期)2019-07-24 07:14:04
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
雷达学报(2017年6期)2017-03-26 07:53:04
信息安全研究(2016年4期)2016-12-01 06:06:54
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
语言与翻译(2015年4期)2015-07-18 11:07:45
华东理工大学学报(自然科学版)(2014年5期)2014-02-27 13:49:31
