
基于聚类分析的大容量耦合设计任务规划的研究
2018-05-03 08:53:16田启华梅月媛杜义贤周祥曼
中国机械工程 2018年5期
田启华 梅月媛 杜义贤 周祥曼
三峡大学机械与动力学院,宜昌,443002
0 引言
以往在大容量耦合设计中,某些耦合设计任务集仅因其部分设计任务之间存在较强的依赖关系而直接采用串行执行方式,造成原本可以并行执行的依赖关系相对较弱的耦合设计任务也按照串行方式执行。这种较为笼统的做法不仅延长了设计任务的执行周期,更因串行耦合设计任务的规划需考虑设计任务的执行顺序而造成有效规划方案会随着任务数的增多即容量的增大而呈现出爆炸增长[1],因此,有必要深入分析耦合设计任务之间的内在联系,并对其进行有效的分类和合理的规划,以缩短大容量耦合设计任务的执行周期,快速有效地获得耦合设计任务最佳规划方案,从而提升企业对市场需求的快速反应能力。
有关设计任务之间的内在联系以及设计任务的合理规划问题一直是学术界的研究热点,并已取得了相应的研究成果。DUIN等[2]在协同设计的基础上,应用树图网络建立了产品设计任务动态模型;宋小文等[3]提出了一种无强制解耦的并行设计过程规划方法,通过对各类子任务执行优先级的定义,完善了并行设计过程的规划;邢乐斌等[4]采用模糊排序算法确定了设计任务之间的串行或并行耦合关系,并建立了设计任务的网络图;胡从林等[5]通过有向图和可达矩阵对设计任务进行划分,快速建立了设计任务之间的耦合层次关系;王志亮[6]分别利用基于时间-耦合度和基于时间-序列的撕裂算法对串行耦合设计任务进行了序列优化;李玉家等[7]建立了并行产品开发过程中任务规划问题的数学模型,并利用遗传算法对数学模型进行求解。以上研究就如何解决耦合设计任务规划问题提供了较好的思路,但它们大多没有考虑设计任务的数量对设计任务规划的影响,因此在解决大容量耦合设计任务规划问题上,这些研究提供的方法还存在一定的局限性。
本文针对现阶段在大容量串行耦合设计任务的规划问题研究中存在的不足,研究基于聚类分析的耦合设计任务规划新方法,以达到缩短产品开发周期和快速有效地获得最佳任务规划方案的目的。
1 聚类分析用于耦合设计任务分类的可行性分析
基于聚类分析的大容量耦合设计任务规划方法的思想是:将大容量耦合设计任务集划分成若干小容量耦合设计任务子集,通过对各个任务数少的子任务集的规划实现对整个设计任务的快速规划。目前,任务的划分通常涉及划分、割裂、联合、聚类[8]这四种方法,聚类分析(cluster analysis)算法的优势在于它是一种探索性的分析方法,在分类的过程中,不需要事先指定分类的标准,能够从反映样本之间相似性的数据出发,自动地对样本进行分类,并且可以根据需求灵活地控制类的数量[9]。
为了对样品进行聚类分析,就需要得到表征衡量样品之间相似性的数据。聚类分析以相似系数将样本之间的相似关系量化。若用sij表示样品i和样品j之间的相似系数,则应满足:
(1)
性质越接近的样品,它们的相似系数的值越接近1;而彼此越无关的样品,它们的相似系数的值越接近于0。度量n个设计任务两两之间的相似性,可以得到一个n×n维的相似系数矩阵S:
(2)
聚类分析就是以相似矩阵S为出发点,对n个样品进行分类。分类之后的样品之间存在类内、类间两种关系。类内关系的样品之间存在相对较大的相似性,而类间关系的样品之间则存在相对较弱的相似性。
设计任务之所以产生耦合,是因为任务之间存在信息依赖。这种依赖关系使设计过程出现反复与迭代,伴随这种迭代反复的是设计任务间频繁的信息交互[10]。因此,为了保证耦合设计任务的顺利开展,需要对任务间在信息上的依赖关系进行量化。通常采用耦合强度表征两任务之间的依赖关系,如aij表示任务j输出对任务i输出的耦合强度,而aji则表示任务i输出对任务j输出的耦合强度,它们满足:
(3)
n个设计任务存在的信息依赖关系可用一个n×n维的耦合强度矩阵C表示:
(4)
定义Aij=aij+aji(i≠j),用它表示任务i与任务j之间的耦合度。计算任意两个不同任务之间的耦合度,并定义相同任务之间的耦合度为1,即得到耦合设计任务集的耦合度矩阵F:
(5)
其中,Aij满足:
(6)
Aij数值越大,任务i与任务j之间的依赖关系越紧密,即表明两个任务之间存在较高的相似性,反之,Aij数值越小,表明两个任务之间存在越低的相似性。所以Aij数值大小也是对耦合设计任务相似关系强弱的一种度量。另外,比较式(1)、式(6)可知,耦合度矩阵F与相似系数矩阵S的元素的取值范围是一致的,因此,通过反映耦合设计任务依赖关系的耦合度矩阵F对耦合设计任务进行聚类分析,进而实现耦合设计任务的有效分类是可行的。
类似地,聚类分析后的耦合设计任务之间也会存在两种关系:同一子集的任务关系;不同子集的任务关系。同一子集的设计任务之间耦合度相对较高,不同子集的设计任务之间耦合度相对较低。因此,耦合度较高的同一子集的设计任务采用串行执行的方式,而不同子集间由于耦合度较低,各个设计任务尽可能地独立于其他子集,有利于在设计过程中应用并行执行的方式来缩短开发周期。另外,对于n个设计任务,若分配给m个设计团队,按照串行耦合方式执行,有效的规划方案总共有mn×n!个,数量十分庞大。聚类分析通过将耦合设计任务进行有效的分类,实际上是将大容量耦合设计任务集的规划问题转化为小容量耦合设计任务子集的规划问题,相当于减少了设计任务n的个数,从而可以有效地减少规划方案的数量。
2 基于聚类分析的耦合设计任务分类
在进行聚类分析前,需要将设计任务之间的相似性参数转换成设计任务之间的距离参数。设计任务之间的距离与设计任务之间的相似性具有相反的物理意义,若两个设计任务之间的距离越近,则表明两个设计任务越相似,反之越远,则表明越疏远。整个设计中两两任务之间的距离通过n×n维的距离矩阵D进行描述,其元素dij表示任务i与j之间的距离,是一个纲量一的量。距离矩阵D与相似系数矩阵S存在如下关系:
D=E-S
(7)
式中,E为n×n维的全1矩阵。
通过第1章的分析,本文即以耦合度矩阵C来表示任务之间的相似性,通过式(7)得到耦合设计任务的距离矩阵D,并据此对大容量耦合设计任务集进行聚类分析。
另外,聚类前还需要定义类间距离的计算方法,类与类之间距离定义方法的不同,决定了不同的聚类方法。本文采用类平均法,定义两类之间的距离为这两类元素两两之间距离的平均,即
(8)
式中,p、q为类的编号;Dpq为类Gp与Gq之间的距离;dij为任务i与j之间距离,任务i、j分别属于类Gp、Gq;np、nq分别为类Gp、Gq中设计任务的数量。
耦合设计任务的聚类过程可描述如下:
(1)根据式(7)并结合耦合度矩阵C计算得到耦合设计任务的距离矩阵D,设为D(0),并将n个设计任务各自集结成一类,分别计为类G1、类G2、…、类Gn;
(2)找出D(0)的下三角非对角线最小元素,将对应的Gp和Gq合并成一个新类,设为Gr,Gr={Gp,Gq},在D(0)中去掉Gp、Gq所在的行和列,并通过式(8)计算新类与其余各类之间的距离,将这些距离值作为第一行、第一列元素与D(0)中去掉Gp、Gq所在行列后的矩阵结合,得到n-1阶矩阵D(1)。对D(1)重复上述对D(0)一样的操作,得到D(2),如此进行,直到所有任务并成一类为止;
(3)作出体现整个耦合设计任务分类过程的聚类树状图;
(4)根据任务规划需求,确定设计任务的分类数量。
下面以一个简单的5×5耦合设计任务集来分析说明采用类平均聚类分析方法划分耦合设计任务集的计算步骤。设表示这5个设计任务之间耦合强度关系的耦合强度矩阵C如下:
1 2 3 4 5
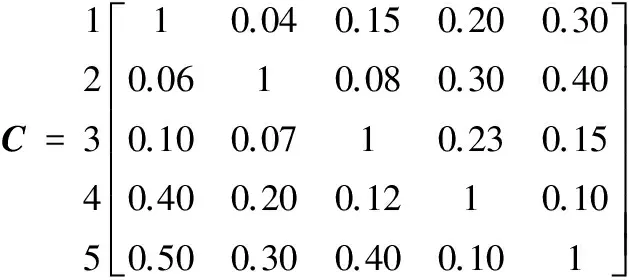
以耦合度度量任意两个任务之间的相似性,根据式(5),得到一个5×5维的相似系数矩阵S(0):
1 2 3 4 5
根据式(7),计算得到设计任务的距离矩阵D,记为D(0):
1 2 3 4 5
将5个设计任务各自集结成一类,分别为类G1、G2、G3、G4、G5。通过观察,D(0)下三角非对角元素中,第5行第1列元素的数值最小,那么将G1、G5合并成一个新类,记为G6,G6={G1、G5}。根据式(8),计算新类G6与其他类的距离:
得到一个新4×4维相似性矩阵D(1)如下:
6 2 3 4
从D(1)可以看出类G2、G4之间的距离最小,因此将G2、G4合并成G7,G7={G2、G4},同样地,根据式(8)计算新类G7与其他类的距离:
进而得到3×3维的矩阵D(2):
7 6 3
从D(2)可以看出,类G6、G3距离最小,聚为类G8,G8={G6、G3}={G1、G5、G3},至此只剩下G8、G7两类,它们之间的距离为
最后,将G8、G7合成一类G9,G9包含了全部5个设计任务。作出聚类树状图,见图1。
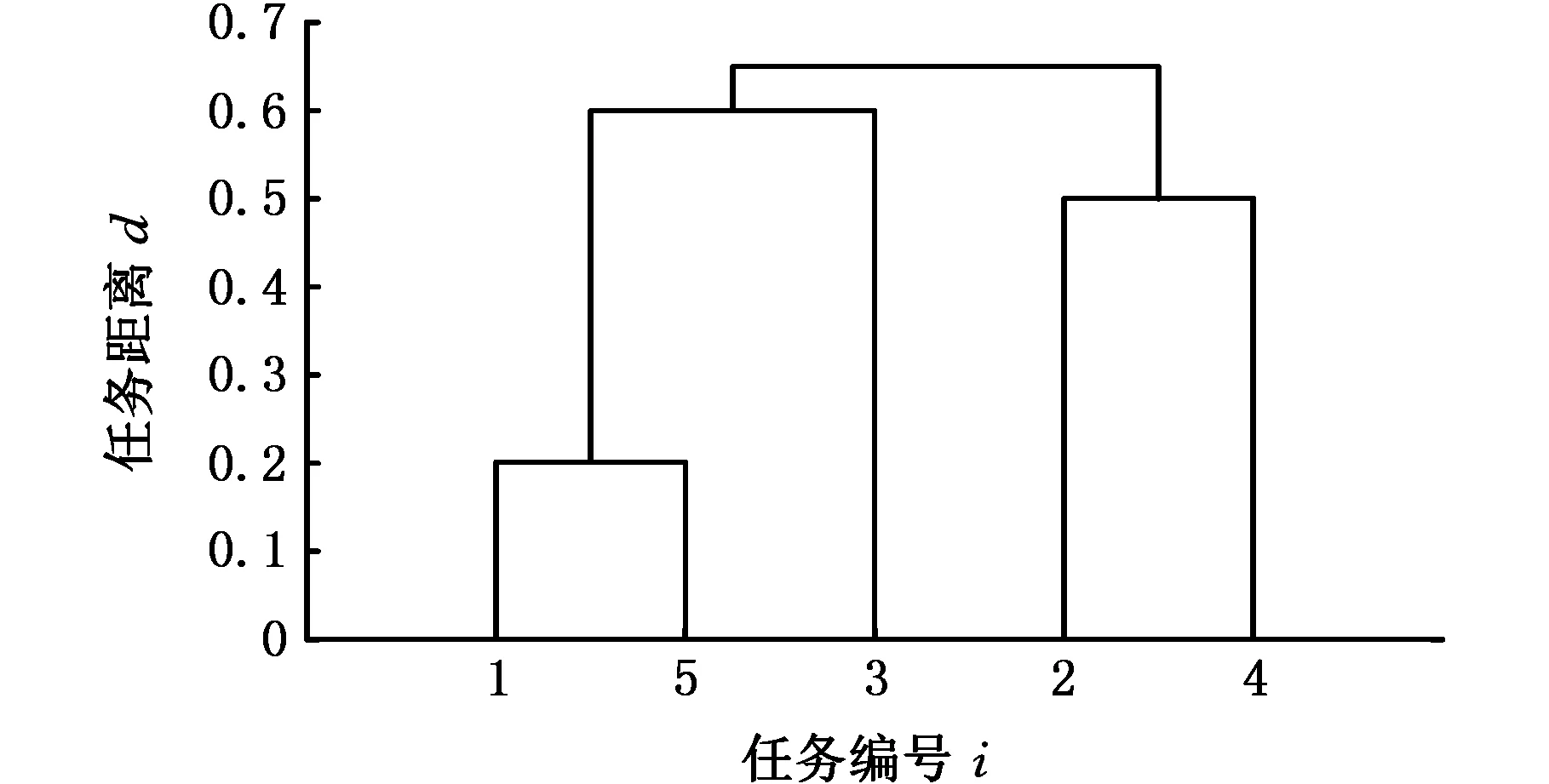
图1 设计任务聚类树状图Fig.1 Clustering diagram of design task
上述分析实例中的5个设计任务通过聚类分析后可以分为以下情况。5类:{1}、{2}、{3}、{4}、{5};4类:{1,5}、{3}、{2}、{4};3类:{1,5}、{3}、{2,4};2类:{1,5,3}、{2,4};甚至仅为1类:{1,2,3,4,5}。不同的分类方式下对应的耦合设计任务规划方案不同,项目管理人员可通过比较不同分类方式下的任务执行周期长短来决定最终的分类数量。
3 基于聚类分析的耦合设计任务的规划方法
耦合设计任务的规划包括确定设计任务的团队分配和执行顺序两方面内容。无论是否通过聚类分析解决大容量耦合设计任务的规划问题,都需要建立耦合设计任务的时间计算模型,再通过求解该模型得到最佳耦合设计任务规划方案。整个耦合设计任务的执行时间包含了子集内部任务执行时间与各子集间任务交互时间。
3.1 子集内部设计任务时间求解模型的建立及求解
假设通过聚类分析将含有n个设计任务的大容量耦合设计任务划分成了p个子集(p=1,2,…,n)。同一子集内的设计任务采用串行执行方式。本文引入工作转移矩阵(work transformation matrix,WTM)模型求解串行耦合设计任务的执行时间。WTM模型要求所有的耦合任务并行执行,但在实际中有可能出现其中一些任务由于受到资源约束或设计要求的改变等原因需要延迟,并在稍后的过程中才能执行。为此,SMITH等[11]提出了多阶段WTM设计过程,具体做法是,将n个耦合设计任务划分到r(r≤n)个阶段中,在第一个阶段中,一个有限任务集的所有任务并行执行;接下来的每个阶段所执行的任务均包含两个部分,即该阶段的任务集和前一阶段任务集的返工。这样,当r=n时,每个阶段只需执行一个任务,下一个阶段的任务包括当前任务和前一个任务的返工。此时任务的执行过程与串行迭代经典模型——马尔可夫链模型(图2)的描述一致。因此,当r=n时,用多阶段的WTM设计迭代模型求解串行耦合集设计任务的执行时间是可行的。
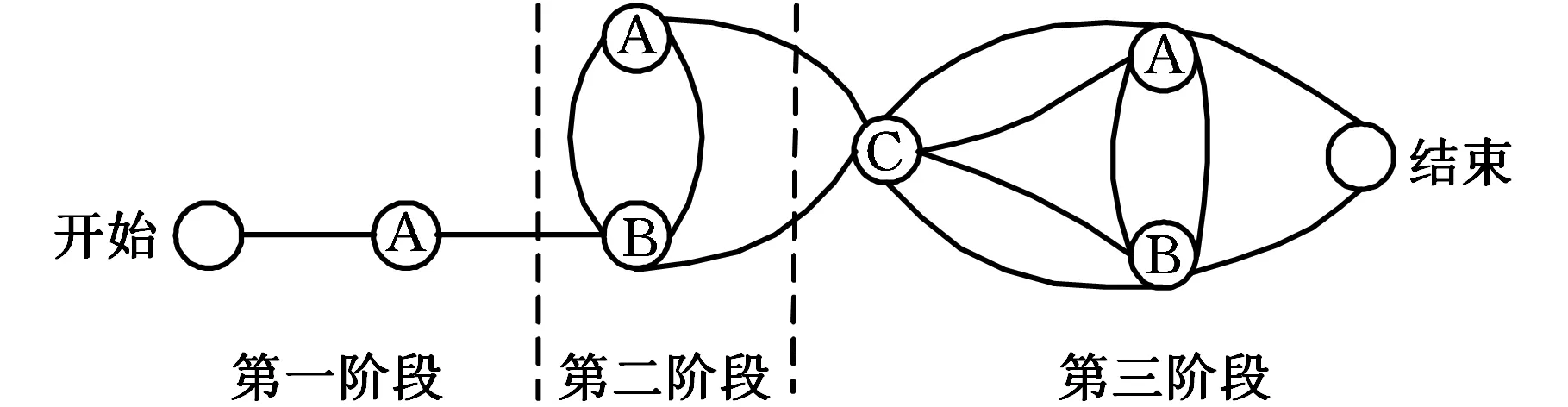
图2 具有3个任务的马尔可夫链模型Fig.2 Markov chain model with three tasks
聚类分析后的每个子耦合设计任务集都对应了一个WTM,用W表示,以任务子集p1对应的Wp1为例进行说明。设np1为子集p1包含的设计任务的个数,Wp1可以拆分成两个单独的np1×np1维的数值矩阵:返工量矩阵Rp1(非对角矩阵)和任务周期矩阵Zp1(对角矩阵)[12],即Wp1=Rp1+Zp1。
Rp1的元素(rp1)ij表示子集p1内的设计任务i在任务j之前完成,i在随后返工的返工量的比例大小。根据第1章的分析可知,任务耦合程度的大小体现了设计任务依赖关系的强弱。在实际设计过程中,依赖关系越强意味着设计任务在执行过程中需要做越多的假设,导致设计任务存在较大程度的返工量,依赖越弱则表示设计任务存在较小程度的返工量[1,13]。因此,从矩阵元素的性质方面考虑,可以将任务返工量矩阵R视为耦合强度矩阵C。
Zp1的元素(mp1)ii表示任务i单独完成的执行周期,其值取决于设计任务的团队分配方案。事实上,由于返工迭代引起的设计周期的延长只占耦合设计任务总设计周期的一小部分,总时间的长短更多地取决于初始执行周期的长短,所以为了缩短产品研发时间,只需将任务分配给执行该设计任务花费时间最少的设计团队即可,由此可以确定耦合设计任务的执行周期矩阵Zp1。
在任务分配方案确定,亦即任务执行周期矩阵Zp1确定的基础上,推断出p1中的第一个设计任务的执行周期T1为
T1=‖(Zp1)[I-K1(Rp1)K1]-1K1Up1‖1
(9)
式中,I为np1×np1维的单位矩阵;Up1为初始工作量矩阵,是一个np1×1维的全1矩阵;K1为第一阶段的任务分布矩阵,是一个np1×np1维的{0,1}布尔矩阵,其中的元素定义如下:
第二个设计任务的执行周期
T2=‖(Zp1)[I-K2(Rp1)K2]-1(K2-K1)Up1‖1
(10)
其中,K2为第二阶段的任务分布矩阵,其中的元素定义如下:
进而可以推断出第x(x=1,2,…,n)个设计任务的执行周期Tx为
Tx=‖(Cp1)[I-Kx(Rp1)Kx]-1(Kx-Kx-1)Up1‖1
(11)
其中,Kx为第x阶段的任务分布矩阵。Kx中的元素定义如下:
则子任务集p1中的所有设计任务在串行执行模式下的时间计算模型Tp1为
(12)
同理,建立其他子任务集的时间求解模型Tp2、Tp3、…、Tpp。
由于各子集间的耦合度较低,所有子任务集采用并行执行方式,因此在各子任务集独立并行阶段,设计任务的执行周期T1取决于执行时间最长的子任务集的设计时间,即
T1=max{Tp1,Tp2,Tp3,…,Tpp}
(13)
在任务分配方案确定的基础上,串行耦合设计子任务集的规划就只包含如何确定设计任务的执行顺序这一个内容。对于分别包含了np1、np2、…、npp个设计任务的子任务集p1、p2、…、pp,在任务分配方案确定的基础上,有效的规划方案仍分别有(np1)!、(np2)!、…、(npp)!种之多,因此,需要采用有效的寻优算法从这些方案中找出最佳的任务规划方案。考虑到遗传算法在一些离散优化问题中得到了非常有效的应用[14],本文采用遗传算法求解时间模型,用以解决串行耦合集设计任务的执行顺序的寻优问题。
串行耦合设计任务每一个执行序列在遗传算法中都对应了一个编码的染色体。染色体的长度表示耦合集包含的任务个数,每个编码位表示设计任务的编号。例如:有6个设计任务的耦合任务集{1,2,3,4,5,6},则|2|5|6|3|1|4|就是一个合法的染色体,它表示在串行执行模式下,任务将按照该染色体确定的顺序2-5-6-3-1-4执行。利用遗传算法对执行顺序寻优的具体过程如下:首先,准备一批表示起始搜索点的初始任务规划方案G,利用选择、交叉、变异3种方式对这个初始群体P进行遗传操作,实现执行序列的优化,得到新一代群体G+1。然后遗传算法会依据适应度函数对新一代种群进行评价,并判断终止条件,若不满足终止条件,则重复以上过程进行迭代计算,若满足终止条件,则输出最佳的任务执行序列以及该序列下任务的执行时间。
3.2 子集间设计任务时间计算模型的建立及求解
上述关于时间模型的建立及其求解仅解决了子集内部设计任务的规划和时间求解问题,通过第1章的分析可知,对耦合设计任务进行聚类分析时,各子集间的耦合关联并没有完全被消除,因此各子集的设计过程之间也必然产生迭代求解过程。故存在一个p×p维的反映子集间耦合设计关系和子集任务执行周期的工作转移矩阵Wp,同样,Wp同样包含返工量矩阵Rp和任务周期矩阵Zp两部分的信息。其中,Rp中的元素可通过式(7)、式(8)计算得到;Zp对角元素(zp)ii即为上述分析计算得到的每个子集的最佳任务序列下的任务执行时间。由于子集间设计任务耦合度低,因此,在项目开发过程中,应用并行执行的方式。
各子集间在并行耦合设计任务执行过程中,每一次返工产生的设计时间由一个p×1维的时间矩阵Ti表示:
(14)
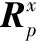
由于各个子集任务之间是并行执行的关系,所以每次迭代过程中,迭代时间最长的任务将决定本次返工最终的执行时间,每次最长返工时间的累加即为子集间耦合设计任务的总执行时间,即
(15)
式中,M为设计人员根据任务是否达到设计要求而确定的返工次数。
应用流行的MATLAB语言编制程序求解式(15),得到各个子任务之间耦合设计时间。
3.3 整个设计任务执行时间的确定
整个设计过程的执行周期T包含子集任务执行时间和子集间任务交互时间两部分。根据第3.2节建立的时间计算模型(式(13)、式(15)),分别求出这两部分时间,再进行求和,即
T=T1+T2
(16)
若不对耦合设计任务进行聚类分析,直接对整个耦合设计任务集按照串行方式执行,则类比式(11),项目的总时间为
T3=‖Z[I-KRK]-1(K-Kn-1)U0‖1
(17)
式中,R、Z分别为整个设计任务的返工量矩阵和执行周期矩阵;K为n×n维任务分布矩阵。
该模型也采用遗传算法求解,然而遗传算法并不能很好地解决大规模计算量问题,它很容易陷入“早熟”[15]。也就是说,若直接对n个串行执行的耦合设计任务的最佳执行序列进行寻优,则由于有效的执行序列高达n!种,有可能还没有得到最佳执行序列,遗传算法就已经给出了结果。聚类分析是将耦合设计任务进行有效的分类,实际上是将大容量耦合设计任务集的规划问题转化为小容量耦合设计任务子集的规划问题,
很大程度地减小了设计任务n的个数,因此,十分有利于在求解过程中利用遗传算法确定设计任务的执行顺序。
4 实例分析
机械手属于典型的多学科复杂产品,为满足产品的各项功能和性能,通常采用模块化研究技术按功能和需求对机械手的组成进行划分,提高机械手的使用灵活性,简化安装和维护[16],这是目前个性化机械手成本低、质量高、交货期短的主要原因之一。然而在研发阶段,机械手的每一组成部分的设计都存在大量的耦合关系[17],因此又制约着机械手的设计周期,从而影响其交货期。
本文以某机械手的规划和研发过程为例,对聚类分析解决大容量耦合设计任务规划的可行性和有效性进行分析。该机械手的研发过程经过简化处理后得到一个15×15维的耦合设计任务系统。将这15个耦合设计任务分配给设计团队,确定各个设计任务的开发时间,得到W矩阵如下:
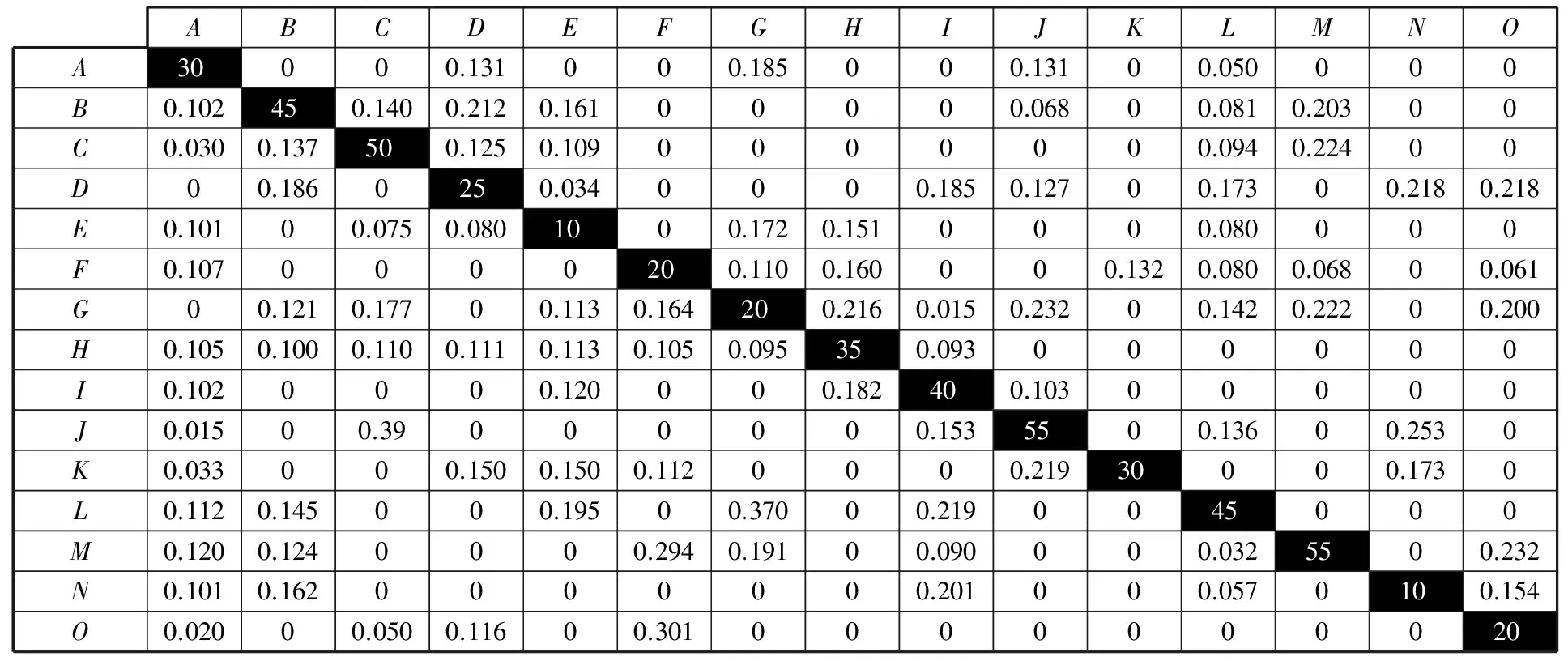
ABCDEFGHIJKLMNOA30000.131000.185000.13100.050000B0.102450.1400.2120.16100000.06800.0810.20300C0.0300.137500.1250.1090000000.0940.22400D00.1860250.0340000.1850.12700.17300.2180.218E0.10100.0750.0801000.1720.1510000.080000F0.1070000200.1100.160000.1320.0800.06800.061G00.1210.17700.1130.164200.2160.0150.23200.1420.22200.200H0.1050.1000.1100.1110.1130.1050.095350.093000000I0.1020000.120000.182400.10300000J0.01500.39000000.1535500.13600.2530K0.033000.1500.1500.1120000.21930000.1730L0.1120.145000.19500.37000.2190045000M0.1200.1240000.2940.19100.090000.0325500.232N0.1010.1620000000.201000.0570100.154O0.02000.0500.11600.3010000000020
按照第2节给出的耦合设计任务集聚类分析的一般步骤,对该耦合任务集进行聚类分析,得到的聚类树状图,见图3。
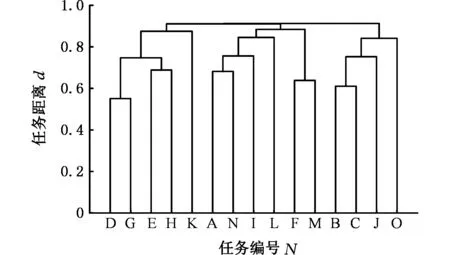
图3 机械手设计任务聚类图Fig.3 Clustering diagram of manipulator design task
假设项目管理人员将设计任务划分成3个子任务集,分别为p1={A,F,I,L,M,N}、p2={B,C,J,O}、p3={D,E,G,H,K}。各个子任务集的工作转移矩阵Wpx(x=1,2,3)如下:
A F I L M N
B C J O
D E G H K
分别建立这三个子耦合设计任务集的时间求解模型,并分别利用遗传算法求解,各子集的最佳设计任务规划方案的遗传算法的搜索空间分别为6! =720、4! =24、5! =720。各子集的最佳执行序列及对应的执行时间如表1所示。

表1 子任务集最佳执行顺序及对应时间
由于子集p1的执行时间最长,则在各个子集独立并行执行这一阶段,项目开发时间T1=216.336。
接下来,需考虑3个子任务集之间耦合迭代产生的时间。根据第1章的分析可知,可通过一个3×3维的工作转移矩阵Wp反映本实例中子集间的耦合设计关系和子集任务执行周期,其中,Rp中的元素可通过式(7)、式(8)计算得到,Zp对角元素(zp)ij即为表1中各子任务集在最佳任务序列下的任务执行时间。表征子集间的Wp为
p1p2p3
子集间的设计任务采用并行执行的方式,根据式(15),并取U0=[1 1 1]T,计算得到的子集间设计任务的耦合迭代阶段设计任务的执行时间为T2=29.124。则整个设计任务的执行周期为这两个阶段设计任务执行时间之和:T=216.336+29.124=245.46。
若不对耦合设计任务集进行聚类分析,直接对这15个设计任务在串行执行条件下进行规划,在任务分配方案确定的基础上,有效规划方式仍高达15!=1.377×1012种,利用遗传算法进行寻优,最佳任务规划方案下对应的任务执行周期T=1007.2,对应的任务序列为A-E-F-H-I-O-N-
D-M-B-C-G-L-J-K。然而,基于遗传算法的局限性,这个任务规划方案有可能不是最佳结果。
如表2所示,对两种规划方法的执行效果进行比较,按照本文提供的基于聚类分析的耦合设计任务的规划方法,开发项目的总设计时间大为缩短,最佳任务规划方案的搜索空间大大缩小。相比之下,遗传算法对聚类分析之后的子耦合设计任务集的执行顺序进行寻优得到的结果更为有效。
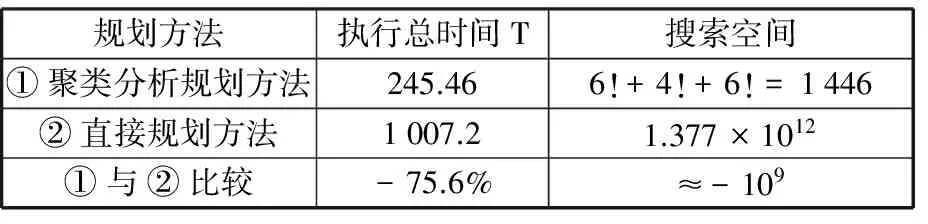
表2 两种规划方法执行效果比较
5 结语
本文针对串行耦合设计任务开发时间长,有效规划方案数量庞大的问题,通过聚类分析将耦合设计任务集划分成若干子集,并将串行耦合设计任务的规划和执行过程划分为子任务集的规划与执行、子集间的规划与执行两个阶段。子集内的任务由于耦合程度高故采用串行执行方式,而子集间任务由于耦合程度低故采用并行执行方式,从而有效地缩短了设计任务的执行周期,缩小了设计任务规划方案的搜索空间。对某机械手开发设计过程分析结果表明,聚类分析用以解决大容量耦合设计任务规划问题是可行且有效的。
参考文献:
[1] 王志亮,张友良. 复杂耦合系统设计过程动态规划[J]. 计算机工程与应用,2005,41(13):117-120.
WANG Zhiliang, ZHANG Youliang. A Dynamic Decision Model for the Complex Coupled System’s Design Process[J].Computer Engineering and Applications, 2005,41(13):117-120.
[3] 宋小文,洪智化,王耘,等. 无强制解耦的并行设计过程规划方法[J]. 计算机集成制造系统,2010,16(4):696-702.
SONG Xiaowen, HONG Zhihua, WANG Yun,et al. Concurrent Design Process Planning Method with Unforced Decoupling[J]. Computer Integrated M anufacturing Systems,2010,16(4):696-702.
[4] 邢乐斌,李君. 基于设计迭代的耦合任务动态分配策略研究[J]. 计算机工程与应用, 2012, 48(23):219-223.
XING Lebin, LI Jun. Dynamic Assignment of Coupled Tasks Based on Design Iteration[J]. Computer Engineering and Applications, 2012, 48(23):219-223.
[5] 胡从林,容芷君,陈奎生,等. 产品设计任务的聚类优化研究[J]. 机械设计与制造,2014(7):259-261.
HU Conglin, RONG Zhijun, CHEN Kuisheng, et al. Research on Clustering Optimization of Product Design Task[J]. Machinery Design and Manufacture, 2014(7):259-261.
[6] 王志亮. 复杂产品敏捷化开发中若干关键决策技术的研究[D].南京:南京理工大学,2004.
WANG Zhiliang. Research on Decision-making Techniques for Agile Development of Complex Product[D]. Nanjing: Nanjing University of Technology, 2004.
[7] 李玉家,胡宗武,金烨. 并行产品开发过程中的任务分配问题研究[J]. 中国机械工程,2002,13(7):46-49.
LI Yujia, HU Zongwu, JIN Ye. Research on Task Distribution in Concurrent Product Development[J]. China Mechanical Engineering,2002,13(7):46-49.
[8] 闫华锋,仲伟俊. 复杂产品系统模块化分解模型及应用研究[J]. 北京航空航天大学学报,2016,43(4):654-659.
YAN Huafeng, ZHONG Weijun. Modular Decomposition Model of Complex Product System and Its Application [J]. Journal of Beijing University of Aeronautics and Astronautics, 2016,43(4):654-659.
[9] 蔡洪山. 大数据分析中的聚类算法研究[D].淮南:安徽理工大学,2016.
CAI Hongshan. Research of Clustering Algorithms in Big Data Analysis[D]. Huainan: Anhui University of Science and Technology,2016.
[10] 肖人彬, 陶振武, 刘勇. 智能设计原理与技术[M].北京: 科学出版社,2006:45-46.
XIAO Renbin, TAO Zhenwu, LIU Yong. Intelligent Design Theory and Technology[M]. Beijing: Science Press, 2006:45-46.
[11] SMITH R P, EPPINGER S D. Deciding Between Sequential and Concurrent Tasks in Engineering Design[J]. Concurrent Engineering Research and Applications,1998,3:15-25.
[12] 陈庭贵,肖人彬. 基于内部迭代的耦合任务集求解方法[J].计算机集成制造系统, 2008,14(12):2375-2383.
CHEN Tinggui, XIAO Renbin. Coupled Task Set Solving Method Based on Inner Iteration[J], Computer Integrated Manufacturing Systems, 2008,14(12):2375-2383.
[13] 汪鸣琦,陈荣秋,崔南方. 工程迭代设计中产品族开发过程的研究与建模[J]. 计算机集成制造系统,2007,13(12):2373-2381.
WANG Mingqi, CHEN Rongqiu, CUI Nanfang. Modeling of Product Family Development Process in Engineering Iteration Design[J]. Computer Integrated Manufacturing Systems, 2007,13(12):2373-2381.
[14] 宁桂英,曹敦虔,周永权. 一种求解约束优化问题的改进差分进化算法[J]. 数学的实践与认识,2017,47(2):155-165.
NING Guiying, CAO Dunqian, ZHOU Yongquan. An Improved Differential Evolution Algorithm for Solving Constraint Optimization Problem[J]. Mathematics in Practice and Theroy, 2017,47(2):155-165.
[15] 李中华,张泰山. 可拓聚类适应度共享小生境遗传算法研究[J]. 哈尔滨工业大学学报,2016,48(5):178-183.
LI Zhonghua, ZHANG Taishan. Research of Fitness Sharing Niche Genetic Algorithms Based on Extension Clustering[J]. Journal of Harbin Institute of Technology, 2016,48(5): 178-183.
[16] 梁健文,林彩麟,李仕奇. 冲压机械手的模块化技术研究与应用[J]. 机电工程技术,2016,45(12):58-61.
LIANG Jianwen, LIN Cailin, LI Shiqi. Research and Application of Modular Technology of Stamping Manipulator[J]. Mechanical & Electrical Engineering Technology, 2016,45(12):58-61.
[17] 李潇波, 赵亮, 许正蓉. 基于改进的DSM耦合任务规划方法的研究[J]. 中国机械工程, 2010,21(2):212-217.
LI Xiaobo, ZHAO Liang, XU Zhengrong. Research on Improved DSM Algorithm for Coupling Task Order Programming [J]. China Mechanical Engineering, 2010,21(2):212-217.
猜你喜欢
语数外学习·高中版下旬(2023年7期)2023-09-25 00:45:13
干旱气象(2022年5期)2022-11-16 04:40:24
防爆电机(2022年1期)2022-02-16 01:13:58
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28 11:06:20
生产力研究(2020年5期)2020-06-10 12:01:36
南京大学学报(数学半年刊)(2020年1期)2020-03-19 02:24:44
石油地球物理勘探(2017年2期)2017-11-23 06:02:04
中央民族大学学报(自然科学版)(2017年1期)2017-06-11 07:13:32
统计与决策(2017年2期)2017-03-20 15:25:24
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
