
核磁共振氢谱结合PCASVM算法分类鉴别食用植物油
2018-05-01 20:37:24杨红梅贾婧怡
食品工业科技 2018年8期
李 玮,姜 洁,杨红梅,王 浩,贾婧怡
(北京市食品安全监控和风险评估中心,北京 100041)
食用植物油是人们日常饮食不可缺少的食物之一,是我国居民维生素E的首要来源[1]。目前市场上的食用油种类繁多,食用油因其种类不同、营养价值不同而价格差异很大。一些不法商家为谋取个人利益,常以菜籽油、棕榈油等廉价植物油掺兑优质、高价油品中以降低生产成本,从中谋取暴利。更有生产厂家甚至将非食用油脂(俗称“地沟油”)按一定比例勾兑到正规厂家生产的优质油品中,严重地损害消费者的利益和危害消费者的身体健康[2]。为保护合法生产经营者和消费者的利益,有必要进行食用油种类的鉴别。
目前,对食用植物油分类多采用气相色谱法、红外、拉曼光谱结合聚类分析、辨别分析等化学计量学的方法,但这些方法都存在各自的缺点[3-7]。例如,气相色谱法需要对样品进行衍生化,前处理繁琐、检测时间长;红外、拉曼等光谱法由于受其检测原理所限,其图谱对食用植物油混合物体系内各成分解释能力有限。另外,聚类、辨别分析等传统的化学计量学方法在处理分类问题时,一般需要事先知道样本的先验分布,并要求有足够多的样本数据,而这些要求在实际应用中往往难以达到。所以,在实际工作中应选用适合小样本集的数据处理分析方法。支持向量机(support vector machine,SVM)是统计学习理论中最实用的部分,其在分类问题中既考虑分类误差最小,又考虑分类线的结构,提高了机器学习的泛化能力。此外,SVM还通过引入核函数的方法使计算的复杂度不再取决于空间维数,而是取决于样本数量,尤其是样本中的支持向量数,特别适合小样本集数据的分类[8-11]。
核磁共振(nuclear magnetic resonance,NMR)是鉴定有机化合物结构和研究化学动力学等的极为重要的手段,具有前处理简单,不损伤样品,结构信息丰富等优点。NMR技术在食品领域的应用初期主要采用低场技术研究水在食品中的状态[12],但随着超导技术、计算机技术和脉冲傅立叶变换波谱仪的迅速发展,其在食品领域的研究及应用领域逐渐扩大[13-15]。近年来,国内外研究者采用高场NMR技术结合化学计量学方法,在食品的真伪鉴别、产地溯源等领域展开了大量的研究与应用[16-19],但这些研究多采用聚类、辨别分析等传统的化学计量学方法,少见采用SVM结合NMR的分类方法报道。
本研究对市售大豆油、花生油、玉米油、葵花籽油、橄榄油、芝麻油、菜籽油这7种市面上常见食用植物油的1H-NMR图谱进行测定,结合PCA-SVM算法建立分类模型。随机选取已知食用油种类的预测样本对模型进行检验,根据预测结果分析模型的可靠性,并与传统的簇类独立软模式法(soft independent modeling of class analogies,SIMCA)算法建立的分类模型进行对比。
1 材料与方法
1.1 材料与仪器
7种食用植物油 共119个样品,超市,其中大豆油19个,花生油18个,玉米油19个,葵花籽油17个,橄榄油17个,芝麻油17个,菜籽油10个;氘代氯仿(CDCl3) 氘代度:99.8%,美国CIL公司;Norell 5 mm核磁管 美国Norell公司。
AVANCE 600 MHZ超导傅里叶变换NMR仪 配有CPBBO探头,Topspin 3.2处理软件及60位自动进样器,瑞士Bruker公司。
1.2 实验方法
1.2.1 样品溶液的制备 吸取植物油样品200 μL于2 mL的EP管中,加入800 μL CDCl3,涡旋30 s,使样品与试剂混合均匀。取600 μL混合溶液于5 mm核磁管中,待测。
1.2.2 训练集与测试集样本的确定 在Matlab中用randperm函数随机将每种食用植物油样品分为两组,一组为训练集(training set)样本,一组为测试集(testing set)样本,保证训练集与测试集样本数量比约为3∶2,于是得到75个样本的训练集和42个样本的测试集。
1.2.3 仪器条件 NMR仪1H载波频率为600.13 MHz,采用Bruker标准脉冲zg30,检测温度为298 K,1H的90°脉冲宽度为11.90 μs,谱宽为12019.23 Hz,中心频率为3600.78 Hz,脉冲延迟时间为4 s,扫描次数为32,空扫次数为2。
1.2.4 样品测定及谱图处理 在1.2.2项实验条件下,调整仪器参数、调谐、控温、匀场、采样及傅里叶变换,得到1H-NMR图谱。测得谱使用Bruker Topspin 3.2软件处理,变换点数为65536,线宽因子为1.00 Hz,用指数窗函数处理,基线和相位校正均采用手动方式进行,四甲基硅烷(TMS)为内标信号(δ0.00)。
1.2.5 分类模型的建立 处理后的图谱用MestReNova(version 6.0.1,Spain)软件,以δ0.005积分段对化学位移区间δ0.15~10.00进行分段积分,去除谱中δ 7.21~7.30区域的信号后进行面积归一化处理,得到样品核磁图谱转换形成的典型二维矩阵,其中每行代表一个样本,每列代表样本在同一化学位移内的强度积分相对值。分别采用PCA-SVM和SIMCA法,对训练集数据进行分类模型的建立,用得到的模型预测测试集。程序采用Matlab(V7.0.4,Mathworks Inc,USA)软件编写、运行。
2 结果与分析
2.1 7种食用植物油的典型1H-NMR图谱分析
食用植物油中主要成分为甘油三酯,图1所示为7种食用植物油典型的1H-NMR(CDCl3)谱图,图谱显示主要存在9组信号峰,参考文献[20-21],对这9组主要信号峰进行了信号归属(表1)。图谱中所示,δ0.84~0.92信号为脂肪链末端甲基质子信号,δ1.22~1.39信号为长链脂肪酸一般性亚甲基质子信号,δ1.56~1.66信号为脂肪链上与羰基相隔一个亚甲基的亚甲基上的质子信号,δ1.96~2.09信号为与脂肪链上双键相连的亚甲基质子信号,δ2.27~2.36信号为脂肪链上与羰基直接相连的亚甲基质子信号,δ2.74~2.80信号为脂肪链上两个双键之间亚甲基质子信号,δ4.10~4.32和δ5.24~5.29信号分别为甘油三酯中丙三醇的亚甲基和次甲基质子信号,δ5.30~5.41信号为非共轭脂肪酸不饱和质子信号。

表1 食用植物油中脂类成分1H-NMR主要化学位移归属Table 1 1H-NMR major chemical shift assignments of fat in edible oils
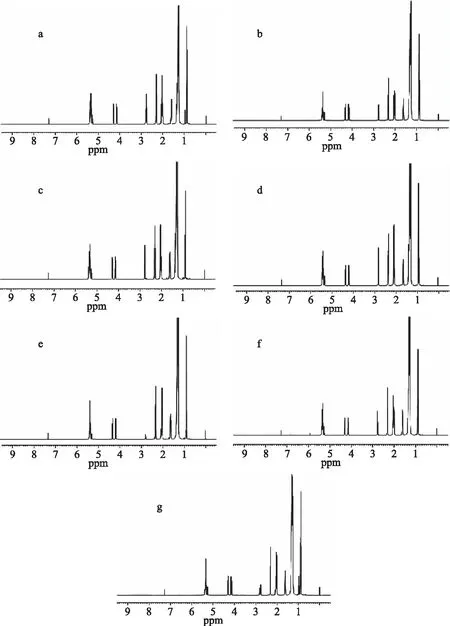
图1 7种常见植物油的典型1H-NMR谱图(CDCl3)Fig.1 1H-NMR spectrum of edible oils(CDCl3)注:a为大豆油;b为花生油;c为玉米油;d为葵花籽油;e为橄榄油;f为芝麻油;g为菜籽油。
2.2 PCA-SVM分类模型的建立
2.2.1 自变量的降维 经数据处理后的训练集数据是由75个样本,1950个变量(图谱分段积分获得)构成的75×1950的一个矩阵,其中每行代表一个样本,每列代表样本在同一化学位移内的强度积分相对值。当过多的自变量因子输入分类模型时,不仅会影响到模型的运算速度,还会引入噪音,影响了模型的预测精度。为解决训练集自变量过多问题,在建立模型前,首先采用PCA分析方法,将训练集数据自变量降维,得到新的特征变量的潜在变量数为2,累计贡献率在95%以上。因此,在建立分类模型时,以PCA分析得到的新特征变量代替原有的自变量作为模型建立的输入自变量。
2.2.2 惩罚参数c和核函数参数g的优化 SVM对模型参数的选择很敏感,为了得到比较理想的分类准确率,需要调节相关的惩罚参数c和核函数参数g。惩罚参数c代表模型对误差的宽容度,过高的c会导致过学习状态的发生,即训练集准确率很高而测试集准确率很低,而c过小将导致训练不完全。核函数参数g是径向基函数自带的一个参数,它决定了数据映射到新的特征空间后的分布。模型中这两个参数对支持向量个数、模型计算的复杂度和精确度都有很大的影响[22]。因此,为了提高模型的准确度和降低模型的复杂度,本研究分别采用网格划分法(Grid)和粒子群优化算法(PSO)对模型的惩罚参数c和核函数参数g进行了优化。表2结果显示,在建立SVM分类模型时,采用Grid法优化得到的c和g值,对测试集的预测的正确率更高,因此选用Grid法优化的c和g的值作为SVM分类模型的建模参数。

表2 两种优化方法所建校正模型对训练集和测试集样本进行分类判别的结果比较Table 2 Comparison of the correct recognition and prediction ability of the calibration models developed by Grid and POS
2.2.3 PCA-SVM分类模型的建立 采用2.2.1中得到的训练集数据新特征变量作为输入自变量,以食用植物油种类作为因变量,以2.2.2中得到的最优c,g值作为模型参数,建立PCA-SVM分类模型。采用测试集样品对模型的分类准确率进行评价,结果见表2中Grid项结果。结果显示,建立的PCA-SVM分类模型对训练集和测试集的分类正确率均为100%。SVM是一种有监督的机器学习方法,该方法在小样本、非线性和高维数据空间的模式识别问题上拥有传统模式识别方法所不具备的独特优势,特别适用于小样本量的复杂体系分析及数据挖掘。因此,在原理上,在样本量增加情况下,分类的准确率应不会有显著降低,但实际结果,还应通过增加样品量来验证。
2.3 PCA-SVM分类模型与SIMCA分类模型的分类结果对比
2.3.1 SIMCA分类模型的建立 采用1.2.2中得到的训练集数据建立SIMCA分类模型,选用中心化法(Center,Ctr)进行数据标度换算。优选的主成分数分别是4、4、4、3、4、5、2时,7种食用植物油被100%聚类识别。在利用训练集样本建立的SIMCA辨别模型对测试集样本进行验证,结果见表3。

表3 PCA-SVM和SIMCA分类模型的结果对比Table 3 Comparison of the correct recognition and prediction ability of the calibration models constructed by PCA-SVM and SIMCA
2.3.2 两种分类模型效果对比 分别采用PCA-SVM和SIMCA两种方法建立7种食用植物油的分类模型,分别对测试集数据进行预测,结果见表3。结果显示,PCA-SVM法和SIMCA法模型的训练集的分类正确率相同,均为100%,但对测试集的进行分类时,PCA-SVM模型要的正确率要远远高于SIMCA模型。
SIMCA是一种基于主成分分析的有监督模式识别方法,其核心思想是对训练集中的每个样本分类分别建立一个主成分分析模型以对其进行描述。该方法以经典的统计学数学理论为依据的,着眼于最大似然的基点,要求“残差平方和”最小,因而通常需要训练样本数目接近无限大时其有效性才能被真确的显露出来。SVM是一种有监督的机器学习方法,该方法在小样本、非线性和高维数据空间的模式识别问题上拥有传统模式识别方法所不具备的独特优势,因此目前在涉及统计分类以及回归分析的诸多相关领域中得到了广泛的应用,特别适用于复杂体系分析及数据挖掘。但因在实际的食品检测工作中所能获得的样本数量往往非常有限,因此SVM法更适合实际监测工作的要求。
3 结论
本研究采用1H-NMR结合PCA-SVM对7种市面上常见的食用植物油进行了分类研究。采用网格划分法优化得到模型最优核函数参数为1.7411,最优惩罚参数为0.3299。本研究结果显示,采用PCA-SVM算法建立的分类模型对测试集样品分类的正确率要远高于SIMCA分类模型,因此SVM法更适合实际监测工作中建模样本量小的要求,适于食用植物油的快速分类鉴别,可以快速、有效的鉴别食用植物油种类,适合实际食品检测工作中建模样本有限的实际,为食用植物油的品质鉴别和质量控制提供分析方法。
[1]马冠生,郝利楠,李艳平,等. 中国成年居民食用油消费现状[J].中国食物与营养,2008(9):29-32.
[2]王乐,刘尧刚,陈凤飞,等. 地沟油的污染及变质情况研究[J].武汉工业学院学报,2007,26(4):1-4,12.
[3]林晨,张方圆,吴凌涛,等. 气相色谱结合化学计量学分析4 种食用植物油的指纹图谱[J]. 分析测试学报,2016,35(4):454-459.
[4]王同珍,陈孝建,安爱,等. 气相色谱-质谱技术结合化学计量学对5种动物油进行判别分析[J]. 分析测试学报,2016,35(5):557-562.
[5]李娟,范璐,毕艳兰,等.红外、近红外光谱-簇类的独立软模式方法识别植物调和油脂[J]. 分析化学,2010,38(4):475-482.
[6]黄晓东,谢飞飞,尤勇,等.食用植物油傅里叶变换红外光谱鉴别的研究[J]. 安徽工程大学学报,2014,29(4):4-7.
[7]赵薇,刘翠玲,孙晓荣,等. 应用拉曼光谱技术识别食用油的种类[J]. 食品科技,2015,40(3):274-277.
[8]Blanco M,Coello J,Iturriaga H,et al. Calibration in non-linear near infrared reflectance spectroscopy:A comparison of several methods[J].Analytica Chimica Acta,1999,384(2):207-213.
[9]Despagne F,Massart D L,Chabot P. Development of a Robust Calibration Model for Nonlinear In-Line Process Data[J]. Analytical Chemistry,2000,72(7):1657-1665.
[10]Blanco M,Pages J. Classification and quantitation of finishing oils by near infrared spectroscopy[J]. Analytica Chimica Acta,2002,463(2):295-303.
[11]王春艳,史晓凤,李文东,等.基于主成分和支持向量机浓度参量同步荧光光谱油种鉴别[J].分析测试学报,2014,33(3):289-294.
[12]R H inrichs,J Gotz,H Weisser. Water-Holding Capacity and Structure of Hydrocolloid-gels WPC-gels and Yogurts Characterised by means NMR[J]. Food Chemistry,2003,82(1):155-160.
[13]李玮,姜洁,路勇,等.NMR氢谱定量测定奶酪中总共轭亚油酸的含量[J]. 食品科学,2015,36(10):134-138.
[14]姜洁,李玮,路勇,等. 核磁共振脉冲宽度法测定婴幼儿乳粉中乳糖、蔗糖含量[J]. 食品工业科技,2015,36(8):68-71,77.
[15]李玮,贾婧怡,姜洁,等. NMR氢谱法分析市售奶油中的脂肪酸[J]. 食品工业科技,2016,37(23):319-323.
[16]李玮,贾婧怡,李龙,等. 核磁共振代谢组学技术鉴别天然奶油与人造奶油[J]. 食品科学,2017,38(12):278-285.
[17]Andreotti G,Trivellone E,Lamanna R,et al. Milk identification of different species:13C-NMR spectroscopy of triacylglycerols from cows and buffaloes’ milks[J]. Journal of Dairy Science,2000,83(11):2432-2437.
[18]G Vigli,Angelos P,Apostolos S,et al. Classification of edible oils by employing31P and1H NMR spectroscopy in combination with multivariate statistical analysis. A proposal for the detection of seed oil adulteration in virgin olive oils[J]. Journal of Agricultural Food Chemistry,2003,51:5715-5722.
[19]Zou X Q,Huang J H,Jin Q Z,et al. Lipid composition analysis of milk fats from different mammalian species:potential for use as human milk fat substitutes[J]. Journal of Agricultural Food Chemistry,2013,61:7070-7080.
[20]Raffaele S,Francesco A,Livio P.1H and of Virgin Olive Oil.13C NMR An Overview[J]. Magnetic Resonance in Chemistry,1997,35:S133-S145.
[21]Maria L I,Sopelana P,Maria D G.1H Nuclear Magnetic Resonance monitoring of the degradation of margarines of varied compositions when heated to high temperature[J]. Food Chemistry,2014,165:119-128.
[22]李盼池,许少华. 支持向量机在模式识别中的核函数特性分析[J]. 计算机工程与设计,2005,26(2):2302-2304.
猜你喜欢
食品安全导刊(2021年21期)2021-08-30 08:21:48
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
基层中医药(2021年11期)2021-06-05 06:54:40
党的生活(黑龙江)(2021年1期)2021-03-24 15:03:05
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
农产品市场周刊(2017年6期)2017-03-10 20:34:29
中国中医药现代远程教育(2014年17期)2014-03-01 04:29:39
华东理工大学学报(自然科学版)(2014年2期)2014-02-27 13:48:41
