
基于SVD++与标签的跨域推荐模型
2018-04-19 08:03邢长征
计算机工程 2018年4期
邢长征,
(辽宁工程技术大学 电子与信息工程学院,辽宁 葫芦岛 125105)
0 概述
推荐系统根据用户的喜好(兴趣和目标)来确定用户感兴趣的潜在项目[1]。大部分的推荐系统都是根据单一领域中的用户和项目历史数据来进行推荐的,例如Netflix、Last.fm、Barnes & Noble网站对电影、音乐以及书籍的推荐,但由于用户不仅仅对单一领域的事物感兴趣,因此单领域推荐已经不能准确地预测用户的兴趣。针对单领域推荐模型在数据稀疏和冷启动情况下推荐效果较差的问题,大型电子商务网站Amazon和eBay通过多个领域来获取用户的反馈信息,从而产生了跨域推荐系统。跨领域推荐系统中的跨域推荐模型[2]是利用不同源数据域来对目标数据域[3-4]信息进行预测的。现如今各大网站利用标签信息来体现用户喜好和项目特征,而用户在给不同领域(如电影、音乐、书籍等领域)的项目添加标签时,可以使用通用词汇作为标签[5]。因此,标签可以作为连接不同领域的桥梁并且用来克服基于内容推荐时特征信息复杂性和不均匀性的不足[6-7]。目前,将跨域推荐模型融入标签因素来进行评分预测时,仍存在以下问题:UserItemTags模型[8]当用户没有给特定项目添加标签时预测误差变大,ItemRelTags[8]只是加入了项目的标签信息,并没有考虑用户标签信息,导致无法利用用户过去选择的标签来预测用户的喜好。
为提高预测准确度,本文构建一个新的跨域推荐模型。在使用SVD++模型评分数据预测的基础上,添加用户和项目历史标签信息,并利用标签使用次数、热门标签和项目的惩罚系数刻画并预测用户喜好。
1 相关研究
1.1 基于矩阵分解的推荐模型
1.1.1 隐因式分解模型
隐因式分解模型(Latent Factor Model,LFM)是推荐系统领域的热点研究话题之一,其核心思想是通过隐含特征联系用户兴趣和物品[9]。具体过程分为3个部分:将物品映射到隐含分类,确定用户对隐含分类的兴趣,选择用户感兴趣的分类中的物品推荐给用户[10]。LFM通过式(1)计算用户u对物品i的兴趣:
(1)
其中,pu,k和qi,k是模型的参数,pu,k代表用户u的兴趣是第k个隐类的权重,qi,k代表第k个隐类属于物品i的权重,K是隐类的个数。两者的乘积再对k积分就得到用户u对商品i的偏好程度。
将式(1)表示为向量乘积的形式,即为:
(2)
考虑到在真实的模型中,每个用户评分的基准线不同,每个商品得到评分的基准线也不同,引入参数μ表示训练集中所有记录的评分的全局平均数;引入参数bu,即用户偏置项,这一项表示用户的评分习惯中和物品没有关系的那种因素;引入参数bi,即物品偏置项,表示物品接受的评分中和用户没有什么关系的因素。因此,式(2)变为以下形式:
(3)
1.1.2 SVD++模型
LFM模型中并没有显式地考虑用户的历史行为对用户评分预测的影响,为此Koren在Netflix Prize比赛中构建一个模型,将用户历史评分的物品加入到LFM模型中。该模型被称为SVD++[10-12],具体如下:
将基于项目的协同过滤算法(ItemCF)[13]的预测计算式改为:
(4)

(5)
将前面的隐因式分解模型(LFM)和上面的模型相加,从而得到:
(6)
文献[10]提出为了不避免太多参数造成过拟合,可以令x=q,从而得到最终的SVD++模型,用式(7)表示SVD++模型:
(7)
1.2 基于标签的跨域推荐模型
用户使用社交标签对信息进行分类[14],可自由组织、管理和搜索所需的资源。这种易使用性使标签成为信息分类与索引的重要方式,既能反映出用户的兴趣爱好,又能体现资源特征,并且对稀疏数据和新资源推荐质量的提升有所帮助。在跨域推荐过程中,在其中一个领域中使用的标签,完全可以被重新用于另一个领域[15]。因此,可以在跨域推荐模型中利用标签信息作为连接不同领域的桥梁。
1.2.1 UserItemTags模型
UserItemTags[8]模型是一个通过标签体现用户兴趣偏好和资源特征信息的模型,在预测评分时利用了目标用户使用过的标签。使用此模型时假设用户没有对项目进行评分而只是添加了标签,然后利用这些标签来更好地预测用户对项目的评分。运用此模型进行推荐的一个经典案例是Delicious的社交书签网站,用户可以标记书签,但可以不对项目进行评分[8]。UserItemTags使用下式预测评分:
(8)
其中,Tu表示用户u给项目i添加的标签集合。
UserItemTags模型缺点为:当项目没有被用户添加标签时推荐预测性能会大幅度降低。
1.2.2 ItemRelTags模型
ItemRelTags[8]模型中没有涉及目标用户对目标项目添加的标签,而是使用了任意用户对目标项目添加的所有标签,这样就可以克服UserItemTags的局限性:目标用户在没有对某一项目添加标签的情况下无法进行评分预测。事实上,ItemRelTags模型只需要所有用户对项目i添加有关标签集合TR(i)。这里评估标签的相关性使用Wilcoxon秩和检验方法来决定每个标签的去留[8]。此外,假设标签对于任何用户都具有相同影响。由于在模型中用户给目标项目添加相关标签,因此相同的标记会出现多次。如果一个项目被添加同一个标签很多次,这就说明这个标签可以很好地反映此项目的特征。因此,该模型添加了标签的使用频率nt。ItemRelTags模型的计算式如下:
(9)
其中,TR(i)是整个标签集合中和项目i有关的标签,nt是用户给项目i添加标签t的次数。该模型的优点是即使是没有对项目做任何标签的新用户也可以为其做出评分预测。但其只是考虑特定项目的历史标签并没有考虑目标用户的历史标签,在这种情况下,可以通过用户在过去选择的标签来丰富用户的喜好。
2 TagSVD++跨域推荐模型
上文介绍的隐因式分解和SVD++模型虽然在推荐领域中流行度较高,但只能在单一领域中进行推荐,这样就会在冷启动情况下出现推荐准确度下降的问题。根据用户不只对单一领域感兴趣的现状,本文构建跨域推荐模型,用不同领域共有的标签信息作为连接不同领域的纽带,在多个领域信息中进行推荐预测,提升了预测的性能[16]。目前跨域推荐模型存在的不足是:利用UserItemTags模型进行预测,用户没有为项目添加标签时,模型预测效果没有原始模型隐因式分解(LFM)模型预测精准;ItemRelTags模型并没有考虑特定用户的历史标签来丰富用户的喜好。
本文构建基于SVD++改进标签跨域推荐模型TagSVD++。该模型继承了SVD++中利用评分信息间接表示用户喜好和项目特征的特点,同时又加入了用户以及项目的历史标签信息和标签使用频率,并通过热门标签惩罚系数来增强模型推荐效果的准确性和新颖性。
步骤1求相似的标签。
针对新用户或者新物品标签集合中标签数量较少的情况,需要对标签集合进行扩展,标签扩展的本质是对每个标签找到和它相似的标签,也就是计算标签之间的相似度。首先通过式(10)余弦相似度公式计算标签b和b′之间的相似度:
(10)
然后对标签集合排序,参考文献[17]中将排序结果中前20个标签作为用户相关的标签。
步骤2构造模型。
本文模型构建过程如图1所示。

图1 模型构建过程
模型公式表示为:
(11)
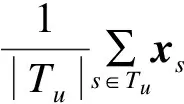
步骤3损失函数计算。
类似于SVD++模型,需要求得式(11),通过用户实际评分和预测评分之间损失函数的最小值来找到最合适的参数。
(12)
步骤4使用随机梯度下降法[18]求损失函数最小值。
最小化上述的损失函数,利用随机梯度下降模型来计算。该模型是最优化理论里最基础的优化模
型,通过求参数的偏导数找到最速下降的方向,然后通过迭代法不断地优化参数。根据随机梯度下降法,需要将参数沿着最速下降方向向前推进,因此,得到如式(13)~式(16)所示的递推公式。
(13)
(14)
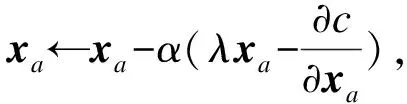
(15)

(16)
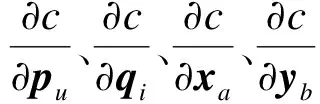
(17)
(18)
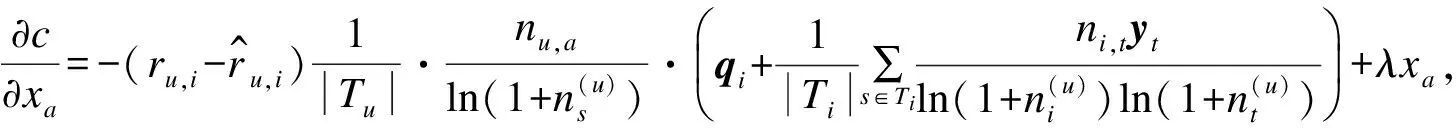
(19)

(20)
利用递推公式进行迭代直至值不再发生变化则迭代结束,从而利用随机梯度下降法求得使损失函数最小的各个参数:学习速率α和正则化参数λ。表1列出了跨域模型对标签信息的利用情况,其中√代表包括,×表示不包括。

表1 跨域模型比较
3 实验
3.1 实验数据及预处理
3.1.1 数据集
为了模拟跨域数据集,本文使用2个来自不同领域公开可下载的数据集:MovieLens数据集和LibraryThings数据集。2个数据集评分范围均为1分~5分,每0.5分为一级,评分代表用户的偏好程度。实验数据集规模如表2所示,原始数据集的典型示例如表3和表4所示。
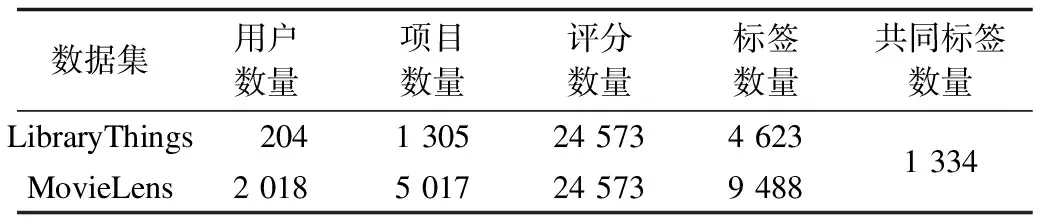
表2 实验数据集规模
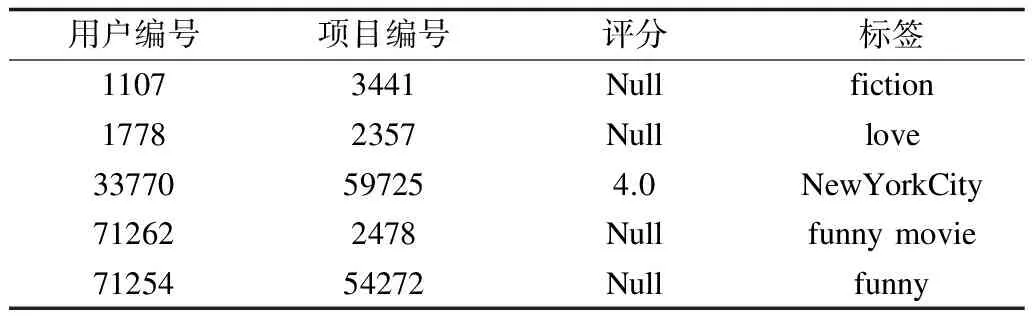
表3 MovieLens数据集典型示例

表4 LibraryThings原始数据集典型示例
3.1.2 标签剪修
对标签进行修剪:1)去除用户对项目添加的表示情绪的标签,比如“不好笑”,但是“不好笑”不能认为是用户的兴趣;2)去除词频很高的停止词;3)去除因词根不同造成的同义词;4)去除因分隔符造成的同义词。
3.2 评估方法
评估模型模型时,首先将MovieLens作为源数据域,LibraryThings作为目标数据域,然后反之也是如此。将目标数据域平均分为没有重叠的10份,在每一份数据中,10%的数据为测试集来评估方法的性能。剩下的90%数据做为训练数据集,在训练数据集中有20%的验证数据集,用来寻找模型的最优参数,其中包括学习速率α、正则化参数λ和隐特征个数k。而训练数据中剩下的80%数据结合源数据域来建立模型。为了测评目标数据域中用户评分的稀疏程度对模型性能的影响,将训练数据平均分为10份,依次取1份,2份,……,10份作为训练数据来训练模型以此来模拟用户评分数据不同的稀疏程度[15]。因为数据集中整个评分系统是以0.5分为一等级建立的,所以采用平均绝对误差(Mean Absolute Error,MAE)即来进行预测可以降低预测结果的误差[15]。MAE采用绝对值计算预测误差,其定义为:
(21)
3.3 实验结果与分析
各模型的平均最优参数如表5和表6所示。

表5 LibraryThings(源数据域)各模型平均最优参数
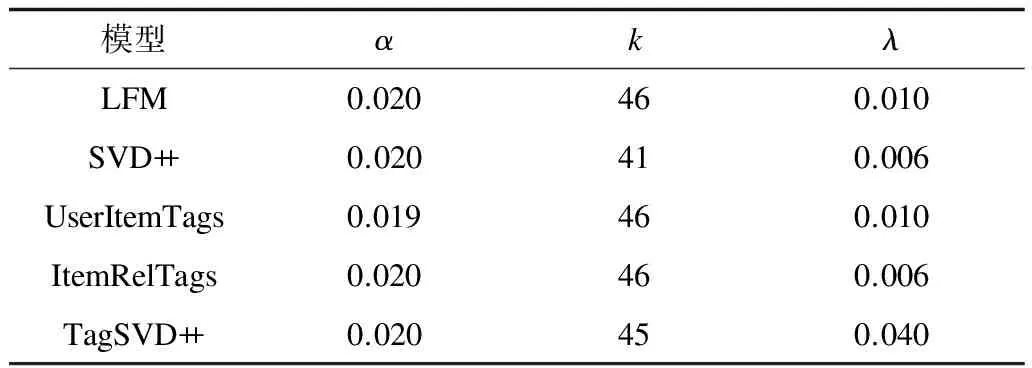
表6 MovieLens(源数据域)各模型平均最优参数
将LibraryThings数据集作为源数据集,将MovieLens数据集作为目标数据集,实验结果如图2所示。可以看出,LFM、SVD++单领域推荐模型的误差远远大于跨领域的推荐模型,而在跨域推荐模型中TagSVD++模型的预测误差都远小于其他几个模型,即使只有10%的评分数据(冷启动)存在的情况下。随着目标域评分量的增多平均绝对误差也在不断变小。
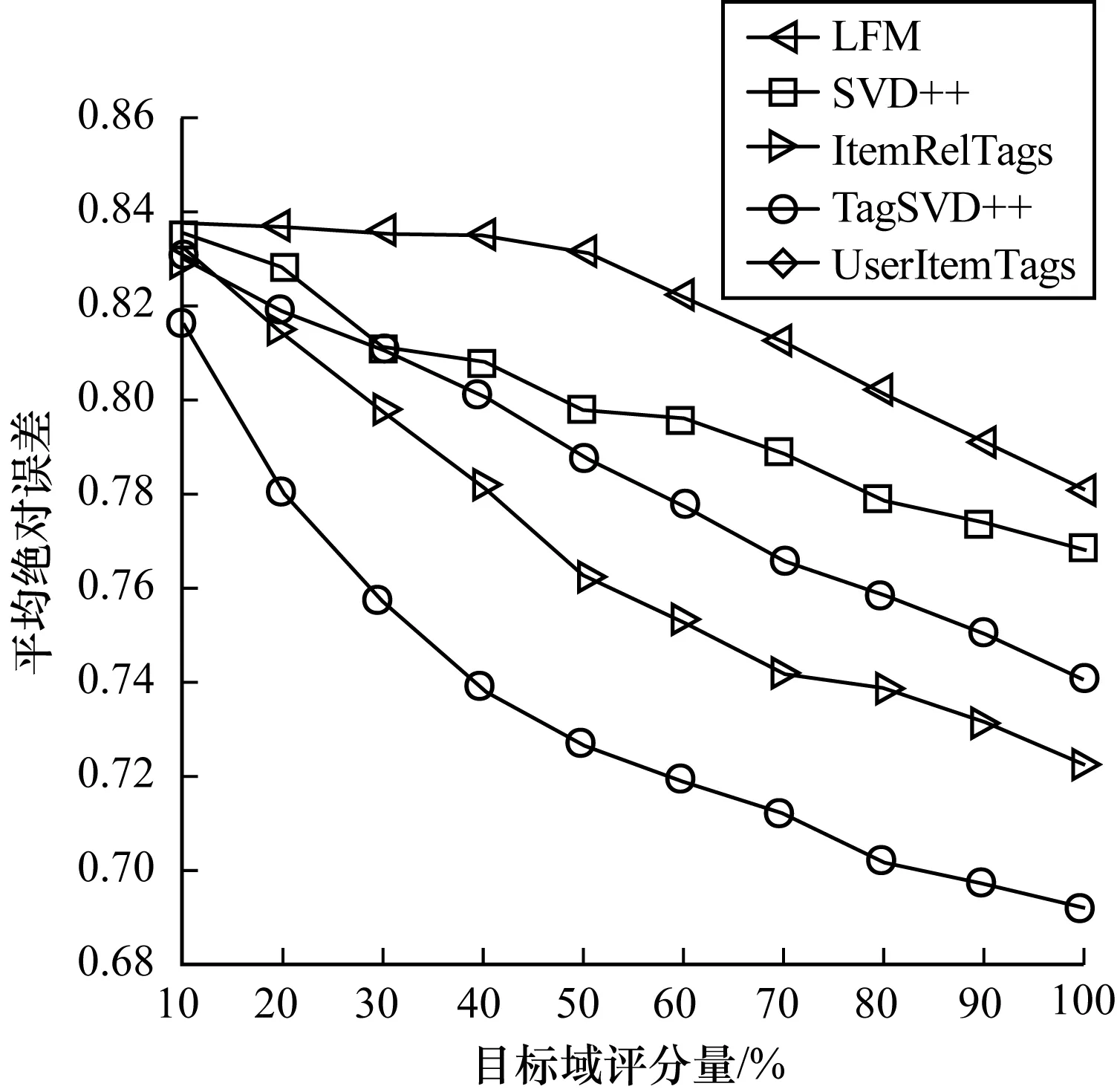
图2 平均绝对误差比较1
将MovieLens数据集作为源数据集,将LibraryThings数据集作为目标数据集,实验结果如图3所示。与前一种情况类似,跨域推荐模型推荐误差远远小于单域推荐模型,而在跨域推荐模型中TagSVD++推荐准确度又远远高于另外4个模型。而由图2和图1可以看出,第2种情况下所有的模型的预测误差都大于第1种情况,这是因为MovieLens数据域数据量大于LibraryThings数据域的数据量。因此,较少的训练数据会导致预测精准度的下降。
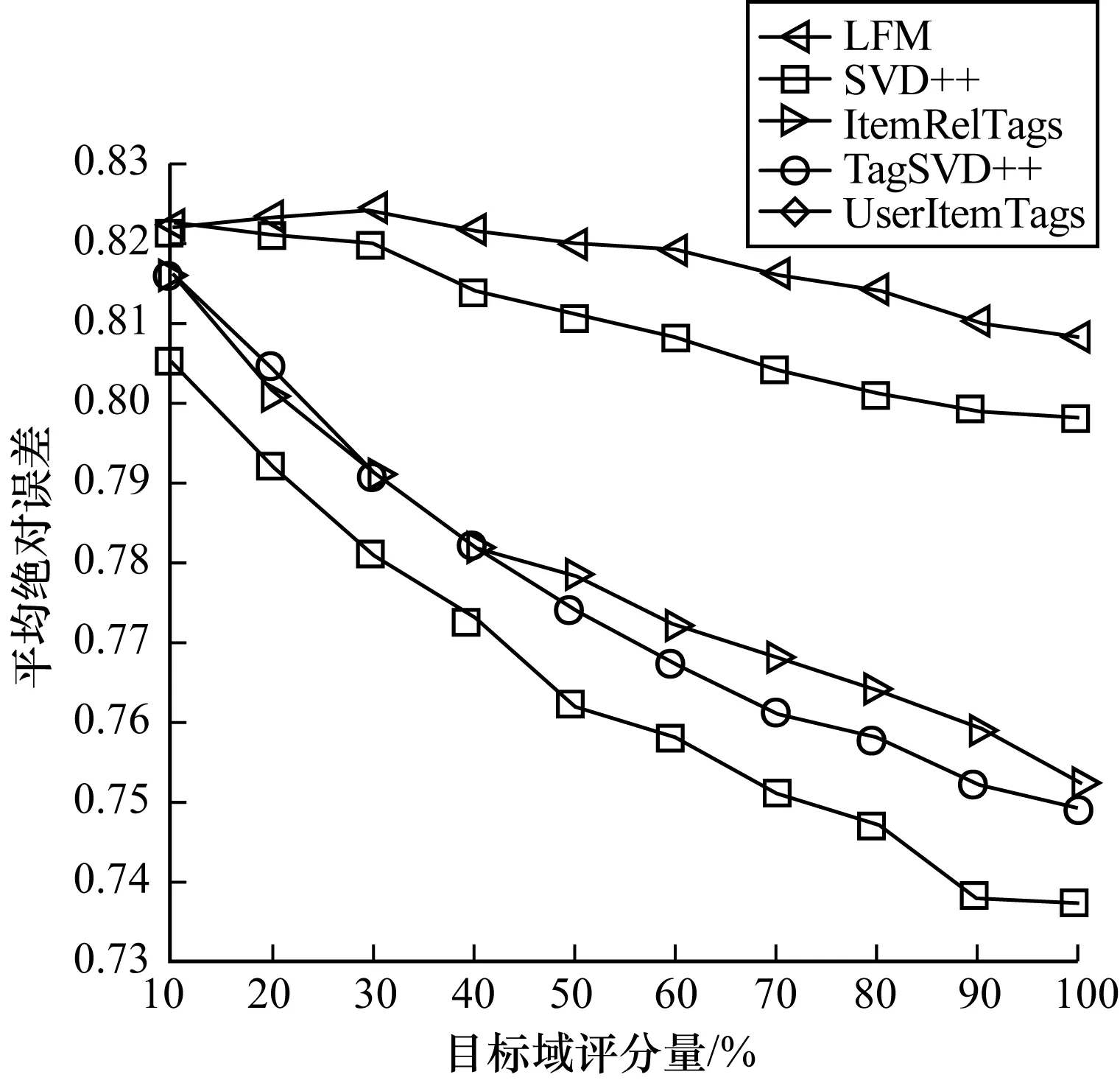
图3 平均绝对误差比较2
经过20次重复试验求得到的每组结果的标准差,如表7和表8所示。可以看出,TagSVD++在各个数据稀疏度下标准差都小于其他模型。这说明TagSVD++模型的预测结果不仅误差较其他算法小,而且预测结果稳定,可以被用来很好地预测用户的评分。

表7 LibraryThings(源数据域)各模型标准差

表8 MovieLens(源数据域)各模型标准差
4 结束语
目前利用标签信息来连接2个不同领域已经成为一种可靠有效的方式,即使在冷启动的情况下,本文建立的TagSVD++模型也能把源数据域中的信息更有效地传递给目标域。实验结果表明,该模型利用标签信息与用户和项目的融合,可有效提高用户兴趣和项目特征的预测精度。下一步将在不同领域中存在相同标签数量较少或者没有的条件下连接2个领域,并研究不同领域中相同标签存在语义差异的情况。
[1] ADOMAVICIUS G,TUZHILIN A.Toward the next generation of recommender systems:a survey of the state of-the-art and possible[J].IEEE Transactions on Knowledge and Data Engineering,2005,17(6):734-749.
[2] LI B.Cross-domain collaborative filtering:a brief survey[C]//Proceedings of IEEE International Conference on Tools with Artificial Intelligence.Washington D.C.,USA:IEEE Press,2011:1085-1086.
[3] GAO S,LUO H,CHEN D,et al.Cross-domain recom-mendation via cluster-level latent factor model[C]//Proceedings of European Conference on Machine Learning and Knowledge Discovery in Databases.Berlin,Germany:Springer,2013:161-176.
[4] LI B,YANG Q,XUE X.Can movies and books collaborate? cross-domain collaborative for sparsity reduction[C]//Proceedings of the 21st International Joint Conference on Artificial Intelligence.Berlin,Germany:Springer,2009:2052-2057.
[5] CREMONESI P,TRIPODI A,TURRIN R.Cross-domain recommender systems[C]//Proceedings of IEEE International Conference on Data Mining Workshops.Washington D.C.,USA:IEEE Press,2011:496-503.
[6] ENRICH M,BRAUNHOFER M,RICCI F.Cold-start management with cross-domain collaborative filtering and tags[C]//Proceedings of the 14th International Conference on E-commerce and Web Technologies.Berlin,Germany:Springer,2013:101-112.
[7] SHI Y,LARSON M,HANJALIC A.Tags as bridges between domains:improving recommendation with tag induced cross-domain collaborative filtering[C]//Proceedings of the 19th International Conference on User Modeling Adaption and Personalization.Berlin,Germany:Springer,2011:305-316.
[8] ENRICH M,BRAUNHOFER M,RICCI F.Cold-start management with cross-domain collaborative filtering and tags[M].Berlin,Germany:Springer,2014:36-37.
[9] FUNK S.Netflix update:try this at home[EB/OL].(2006-12-11).http://sifter.org/~simon/journal/20061211.html.
[10] KOREN Y,BELL R,VOLINSKY C.Matrix factorization techniques for recommender systems[J].IEEE Computer,2009,43(8):30-37.
[11] KOREN Y.Factorization meets the neighborhood :a multifaceted collaborative filtering model[C]//Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2008:426-434.
[12] KOREN Y,BELL R.Advances in collaborative filtering[M]//RICCI F,ROKACH L,SHAPIRA B.Recommender Systems Handbook.Berlin,Germany:Springer,2011:145-186.
[13] GREG L,BRENT S,JEREMY Y.Amazon.com recommenda-tions:item-to-item collaborative filtering[J].IEEE Internet Computing,2003,7(1):76-79.
[14] 张 斌,张 引,高克宁.融合关系与内容分析的社会标签推荐[J].软件学报,2012,23(3):476-488.
[15] CANTADOR F I.Cross-domain recommender systems:a survey of the state of the art[C]//Proceedings of the 2nd Spanish Conference on Information Retrieval.Washington D.C.,USA:IEEE Press,2012:187-198.
[16] SHI Y,LARSON M,HANJALIC A.Exploiting social tags for cross-domain collaborative filtering[C]//Proceedings of UMAP’11.Berlin,Germany:Springer,2011:2-18.
[17] 项 亮.推荐系统实践[M].北京:人民邮电出版社,2012:108-109.
[18] WANG B B,WANG Y X.Some properties relating to stochastic gradient descent methods[J].Journal of Mathematics,2011,31(6):1041-1044.
猜你喜欢
系统仿真技术(2022年4期)2023-01-17
北京航空航天大学学报(2022年8期)2022-08-31
读报参考(2022年1期)2022-04-25
科学家(2021年24期)2021-04-25
计算机世界(2020年50期)2020-01-15
青年生活(2019年23期)2019-09-10
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
