
数据中心网络中任务感知的传输控制协议
2018-04-19 07:37,,
计算机工程 2018年4期
,,
(中南大学 信息科学与工程学院,长沙 410083)
0 概述
近年来,随着网络带宽的飞速提升,在线搜索、社交网络、电子商务等网络应用得到了飞速发展和普及,越来越多的在线应用系统被迁移到数据中心网络(Data Center Network,DCN)[1],利用大规模的计算和存储资源来为用户提供各种服务[2]。数据中心网络中的应用任务包含一组相互独立却拥有共同目标的数据流,这些数据流中拖尾流的完成时间决定整个任务的完成时间。而数据中心网络中数据传输的时延是影响DCN中应用性能至关重要的一部分[2]。Facebook的日志文件表明数据传输占据了整个应用处理时间的33%[3]。因此,能否提高DCN传输性能将极大影响用户体验。
为了提升DCN应用中的网络传输性能,国内外学者做出了很多研究。最初的方案是基于数据流级别的延时敏感传输协议,这类协议以优化流级别平均完成时间作为目标。文献[4-6]通过RTT的测量来检测拥塞以调节拥塞窗口。这类协议需要准确探知链路的往返时间(Round Trip Time,RTT)或者链路RTT的变化情况。基于显式拥塞反馈(Explicit Congestion Notification,ECN)的协议DCTCP[7]、D2TCP[8]和 L2DCT[9]等利用ECN标记来更准确地反馈链路拥塞状态,从而调节发送速率[10]。然而,这些协议仅专注于流级别的数据传输控制,忽略了同一任务内的数据流具有共同目标的特性,降低了应用任务的性能。
针对以上问题,文献[11]假设已有任务的先验信息,利用中央调度器进行集中调度,提出最小瓶颈优先调度算法和MADD带宽分配算法,实现了近乎完美的调度系统。但是需要实时的网络全局信息,调度开销很大。文献[12]通过分布式系统进行任务调度,避免了额外的通信开销,并且提出了FIFO-LM的调度算法,改变了传统FIFO的调度模式,极大地避免了线头阻塞。文献[13]依据任务在集群中已发送的字节数更新coflow[14]在发送端的优先级队列,在不知道数据流先验知识的条件下实现了D-CLAS[13](Discretized Coflow-aware Least-attained Service)策略。而文献[15]首次提出在应用透明的情况下,通过自动鉴别对任务进行调度。CODA利用数据流的一些特定属性,计算某2条数据流的属性距离。如果小于特定的值,就认为这2条属于一个任务,通过绑定来减小鉴别任务大小不准确造成的影响。这些协议虽然通过任务感知进行优化,在一定程度上提升了任务级别的应用性能,但是难以实现且部署代价太大。
本文提出一种对任务大小及流拖尾程度感知的TCP拥塞控制协议TLDCT。在任务内部,减小所有数据流中拖尾流的完成时间,加速任务的完成时间。在任务之间感知任务大小,通过协议设计使得小任务优先,旨在减少平均任务完成时间。
1 问题分析
为了分析提升任务完成时间的关键因素,从DCN中应用任务的大小感知和任务内部流拖尾两个方面进行分析,探究对任务平均完成时间的影响。
1.1 任务大小感知
在网络中存在分属于任务A和任务B的4条流,所有流同时到达,如图1(a)所示。独占带宽时所需要的完成时间分别是3、3、3、1个单位。图1(b)是基于流公平共享带宽时,各数据流完成过程的时序图。此时,网络中所有未完成的流获得同样的带宽,流[fA1,fA2,fB1,fB2]将在[6,4,6,2]时刻完成,因此任务A和任务B都在6时刻完成。采用至少达到服务(Least Attained Service,LAS)策略[16]的时序图如图1(c)所示。由于LAS为最少服务流最高的服务优先级,fA和fB也都在6时刻才完成。而采用任务大小感知策略则能有效减小平均任务完成时间。如图1(d)所示,平均任务完成时间花费了5个单位时间。
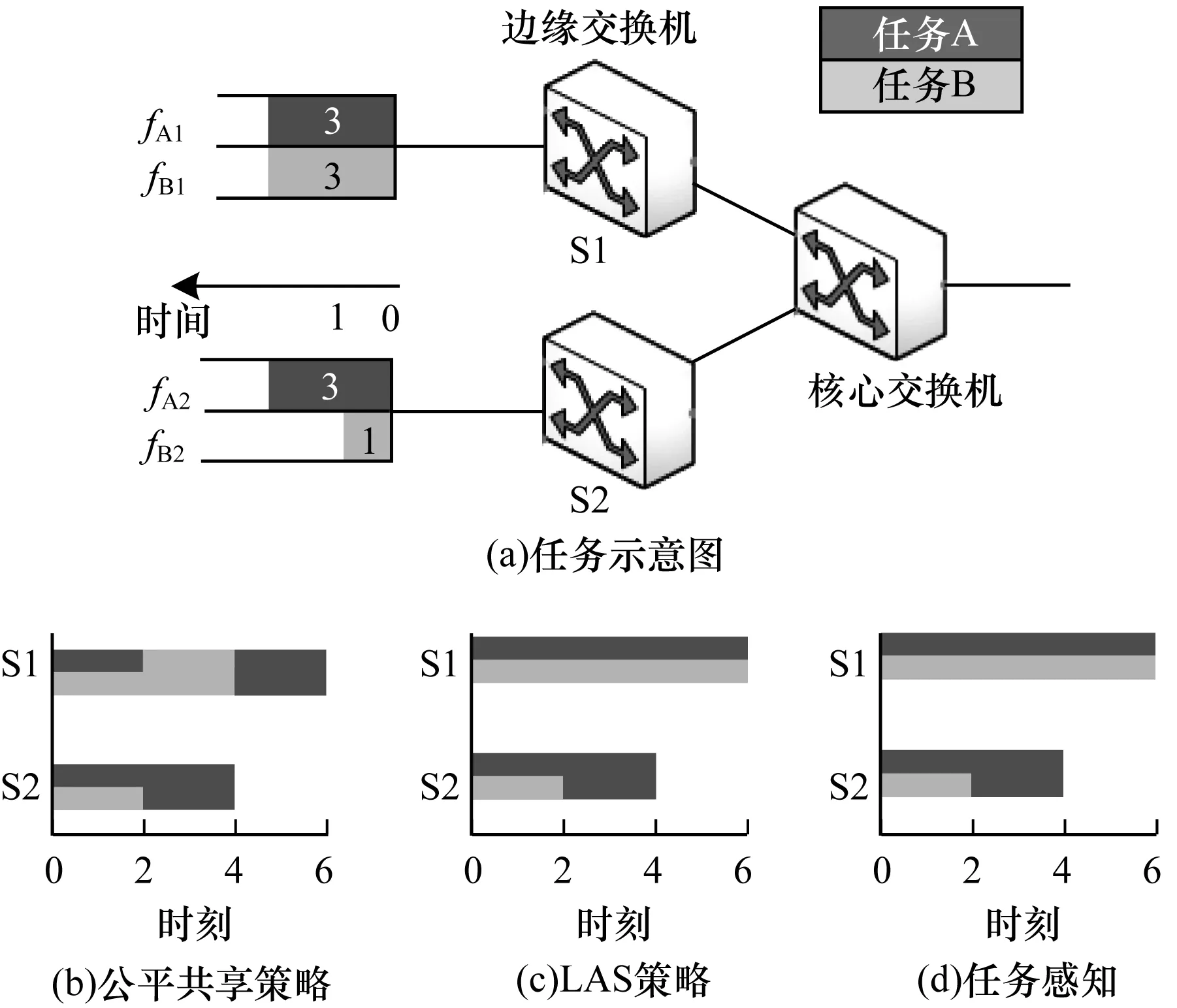
图1 已发送任务大小感知动机
任务感知策略相比于公平共享策略和LAS策略降低了20%的完成时间。因此,为了最小化平均任务完成时间,当小任务和大任务在同一个瓶颈时,优先小任务的传输有利于减少小任务等待的时间,从而也能减小平均任务完成时间。
1.2 任务内部流拖尾感知
由于任务由一组单独的数据流组成,其完成时间由所有数据流中最后一条流的完成时间决定。
如图2(a)所示,在同一个瓶颈交换机下的任务A包含2条流fA1和fA2,跟背景流fB竞争瓶颈传输数据。fA1、fA2和fB在独占带宽的情况下分别需要[1,2,3]个单位时间完成。fB和fA1在0时刻同时开始传输,fA2在1时刻开始传输。图2(b)为采用公平共享带宽策略时,fA1和fA2分别在2.5和5.5时刻完成,所以任务完成需要5.5个单位时间。采用LAS策略的时序图如图2(c)所示,fA和fB分别在3和5时刻完成。如图2(d)所示,在任务内部流拖尾程度感知的情况下,任务内部发送速率快的流将一部分带宽让给发送速率慢的流,则2条流都在4.75时刻完成。这相比于公平共享策略和LAS策略将任务完成时间降低了15%和5.2%。
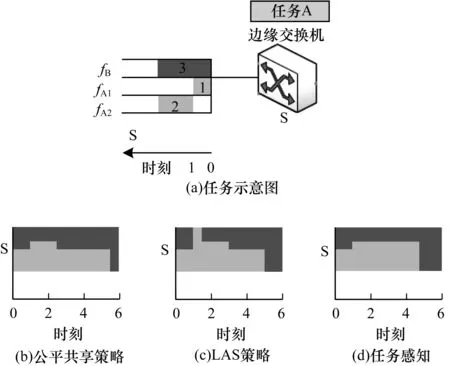
图2 拖尾流感知动机
2 协议设计
DCN中应用执行的任务具有多样性、复杂性和未知性。设计是针对DCN中未知先验知识的任务,将从区分任务大小和感知任务内部拖尾流程度2个部分来降低任务的平均完成时间。综合这2个部分提出降低平均任务完成时间的传输控制协议TLDCT。
2.1 任务大小因子和拖尾因子
为了控制任务的传输速率,定义了一个任务传输速率控制因子β,其计算如式(1)。其中,St表示任务已发送字节数,taskmin和taskmax是任务已发送字节数的最大最小门限值。任务传输速率控制因子β随着任务已发送字节数变化。β初始值为0.5;当任务已发送字节数超过taskmin时,β呈线性上升;当任务已发送字节数超过最大门限taskmax时,β为1.5。文献[17]分析了Web搜索应用的任务流量模型。其中约82%任务大小都分布在47 KB左右,而大约15%的任务远大于100 KB。在这种流量模型下,将taskmin和taskmax分别设置为47 KB和100 KB。
(1)
另一方面,为了控制任务内部的流传输速率,定义了任务内部流传输速率控制因子γ,其计算公式如式(2)。其中,Sf表示流已发送字节数,St表示任务已发送字节数,n表示任务内部的流数目。任务内部流传输速率控制因子γ由该流已发送字节数和它所属任务的平均每条流已发送字节数的差值除以该流已发送字节数决定,在数值小于0时归一到0值。
(2)
2.2 详细设计
本节详细阐述TLDCT协议在发送端、接收端的设计部署。TLDCT协议基于DCTCP协议扩展,利用ECN标记动态反馈链路拥塞状况。
接收方收到发送方的握手包,获取握手包中所携带的任务id号,并查询是否已经接收过同一id号的任务子流。若已接收过,就将该任务子流数目n加1。若初次收到该任务,初始化变量St和n,记录已发送字节数和任务子流数目n,令St=0,n=1。接收方收到数据包时就更新对应任务的St值。在收到关闭连接的FIN包时就将对应的n减1,直到n等于0时释放存储空间St和n。接收方在向发送方发送ACK时,将St和n值写入到ACK确认包TCP头部32 bit的选项字段中返回给发送方。
发送方收到当前发送窗口内的全部确认包ACK之后,依据拥塞标志位被标记的ACK数量计算拥塞程度:
(3)
其中,cwnd是当前发送窗口大小,m是当前发送窗口中拥塞标志位被标记的ACK包数量,αn表示当前数据包往返周期的拥塞度(α0=0),αn-1表示上一个数据包往返周期的拥塞度,g表示滑动平均权值。接收方在收到本轮窗口最后一个数据包的ACK包后,获得ACK中的任务已发送字节数St和任务中流条数n,利用式(1)计算得到任务大小因子。接收方在每次收到数据包的ACK时需要更新已确认发送字节数Sf,利用式(2)求出流的拖尾因子。
发送方通过之前计算出来的α、β、γ更新当前发送窗口cwnd:
(4)
3 性能评估
利用NS2模拟器对TLDCT协议以及DCTCP协议、L2DCT协议和Baraat进行基础性能对比测试。然后针对大规模场景,评估TLDCT协议。根据数据中心网络中的应用任务大小分布情况[17],约82%任务大小都分布在47 KB左右,而剩下约18%的任务都远大于100 KB。因此,将式(1)中的taskmin和taskmax分别设置为47 KB和100 KB。
3.1 基础性能测试
从区分任务大小和感知任务内部拖尾流程度2个部分来测试协议性能。实验拓扑为多对一模型[9]。
3.1.1 区分任务大小性能对比
图3比较了DCTCP、L2DCT、Baraat和TLDCT的大任务和小任务数据量在不同比值情况下的平均任务完成时间。实验包含3组比值,从图3可见,因为TLDCT加速了小任务的发送速率,减小了小任务等待传输的时间,最终降低了平均任务完成时间。其中,随着大小任务的数据量差距增加,TLDCT的收益越明显。例如,在大小任务数据量之比为2∶5的实验中,TLDCT的平均任务完成时间相比于DCTCP和L2DCT分别减少了17.5%和16.8%,仅比Baraat增多了8.7%。Baraat虽然取得了最好的性能,但其也带来极大的分布式部署开销。
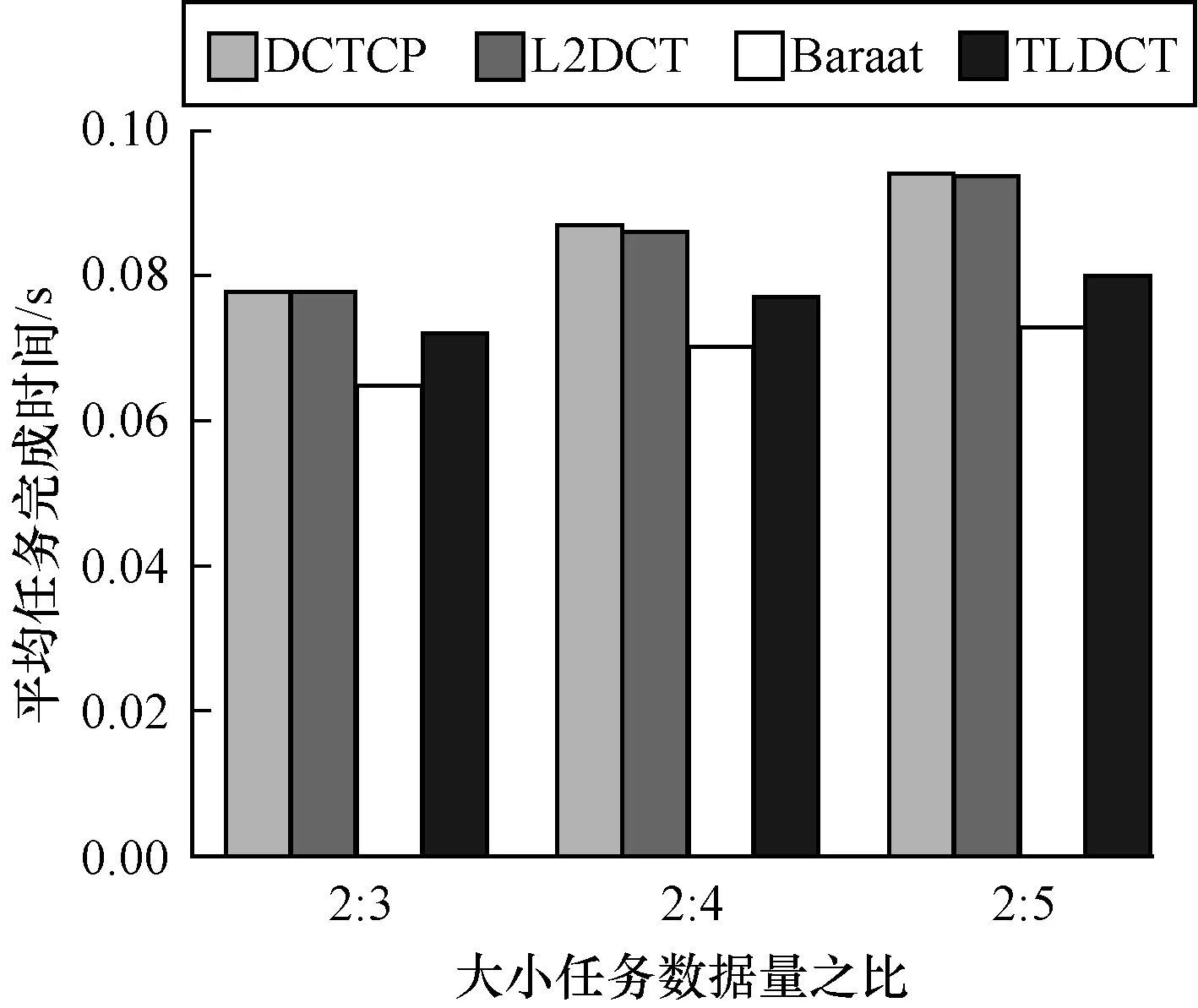
图3 加速小任务完成时间对比
3.1.2 感知拖尾流性能对比
图4显示了DCTCP、L2DCT、Baraat和TLDCT任务内部出现拖尾流的平均任务完成时间。每个任务中的数据流开始发送数据的相差时间分别在20 ms、50 ms、100 ms服从均匀分布。图4显示,相比于DCTCP和L2DCT,TLDCT的平均任务完成时间有所降低。随着时间间隔加大,TLDCT能提升拖尾流的发送速率,进一步加快任务完成速度,与Baraat的差距也越来越小。
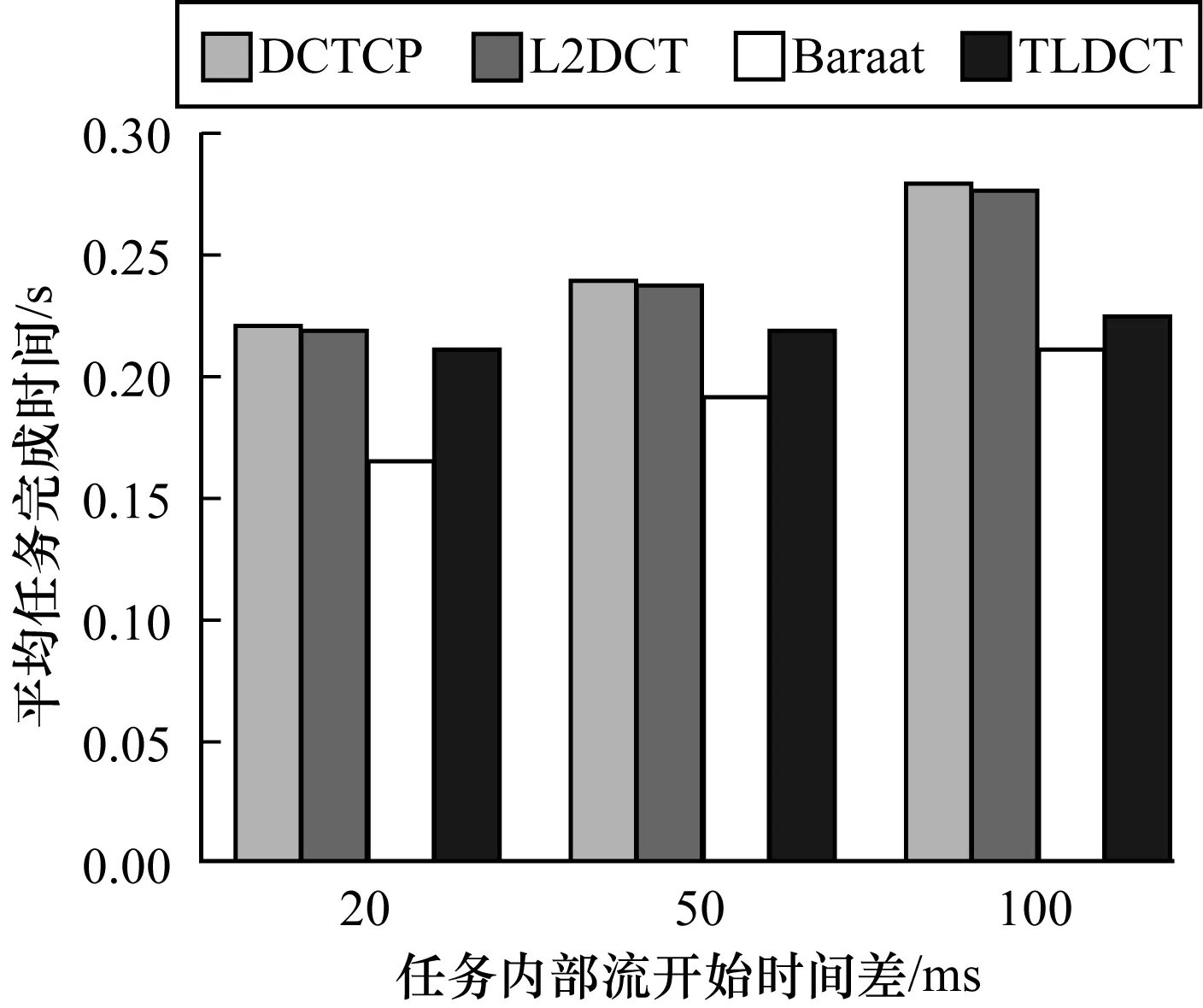
图4 加速任务内部拖尾流任务完成时间对比
3.2 协议性能测试
图5显示了TLDCT在真实DCN流量模型下的加速效果。其中,100台主机通过同一交换机向一台汇聚主机共发送2 038条流。这些流组成了4类任务,具体包括窄短任务、窄长任务、宽短任务和宽长任务。其中,52个窄短任务的宽度为3,流大小都是10 KB;16个窄长任务的宽度为7,流大小都是200 KB;15个宽短任务的宽度为50,流大小都是9 KB;17个宽长任务的宽度为60,流大小都是3 MB。任务的发送开始时间服从泊松到达分布,任务内部所有流的发送时间均匀分布在100 ms内。图5实验结果显示,TLDCT前50%、75%、95%完成任务的平均任务完成时间相比于DCTCP分别减少了47.0%、34.3%、15.1%,相比于 L2DCT减少了45.3%、29.9%、12.4%,相比于Baraat增加了17.6%、29.8%、5.2%。

图5 综合大规模实验任务完成时间对比
4 结束语
本文针对DCN中数据流具有的任务关联性,提出了一种任务大小和流拖尾感知的拥塞控制协议——TLDCT。该协议从加速拖尾流和小任务出发,在考虑数据中心实际环境的情况和易于部署的情况下,减少了任务的平均完成时间,提升了应用性能。在此基础上,下一步研究方向是在保证易于部署的前提下,实现阈值的自适应调节方法。
[1] 李 丹,陈贵海,任丰原,等.数据中心网络的研究进展与趋势[J].计算机学报,2014,37(2):259-274.
[2] MEISNER D,SADLER C M,BARROSO L A,et al.Power management of online data-intensive services[C]// Proceedings of the 38th Annual International Symposium on Computer Architecture.New York,USA:ACM Press,2011:319-330.
[3] CHOWDHURY M,ZAHARIA M,MA J,et al.Managing data transfers in computer clusters with orchestra[C]//Proceedings of ACM SIGCOMM Conference.New York,USA:ACM Press,2011:98-109.
[4] MITTAL R,LAM V T,DUKKIPATI N,et al.TIMELY:RTT-based congestion control for the datacenter[C]//Proceedings of ACM Conference on Special Interest Group on Data Communication.New York,USA:ACM Press,2015:537-550.
[5] LEE C,PARK C,JANG K,et al.Accurate latency-based congestion feedback for datacenters[C]//Proceedings of USENIX Technical Conference.Daejeon,Korea:[s.n.],2015:403-415.
[6] WU Haitao,FENG Zhenqian,GUO Chuanxiong,et al.ICTCP:incast congestion control for TCP in data center networks[J].IEEE/ACM Transactions on Networking,2010,21(2):345-358.
[7] ALIZADEH M,GREENBERG A,MALTZ D A,et al.DCTCP:efficient packet transport for the commoditized data center[C]//Proceedings of ACM SIGCOMM’2010.New York,USA:ACM Press,2010:1-15.
[8] VAMANAN B,HASAN J,VIJAYKUMAR T N,et al.Deadline-aware datadcenter TCP(D2TCP)[EB/OL].[2017-02-01].http://www.raincent.com/content-84-162-1.html.
[9] MUNIR A,QAZI I,UZMI Z,et al.Minimizing flow completion times in data centers[C]//Proceedings of INFOCOM’2013.Washington D.C.,USA:IEEE Press,2013:2157-2165.
[10] 苏凡军,牛咏梅,邵 清.数据中心网络快速反馈传输控制协议[J].计算机工程,2015,41(4):107-111.
[11] CHOWDHURY M,ZHONG Yuan,STOICA I.Efficient coflow scheduling with varys[C]//Proceedings of ACM Conference on SIGCOMM.New York,USA:ACM Press,2014:443-454.
[12] DOGAR F R,KARAGIANNIS T,BALLANI H,et al.Decentralized task-aware scheduling for data center networks[C]//Proceedings of ACM Conference on SIGCOMM.New York,USA:ACM Press,2014:431-442.
[13] CHOWDHURY M,STOICA I.Efficient coflow scheduling without prior knowledge[C]//Proceedings of ACM Conference on Special Interest Group on Data Communication.New York,USA:ACM Press,2015:393-406.
[14] CHOWDHURY M,STOICA I.Coflow:an application layer abstraction for cluster networking[EB/OL].[2017-03-10].http://www2.eecs.berkeley.edu/Pubs/TechRpts/2012/EECS-2012-184.pdf.
[15] ZHANG Hong,CHEN Li,YI Bairen,et al.CODA:toward automatically identifying and scheduling coflows in the dark[C]//Proceedings of ACM Sigcomm Conference.New York,USA:ACM Press,2016:160-173.
[16] RAI I A,URVOY-KELLER G,BIERSACK E W.Analysis of LAS scheduling for job size distributions with high variance[J].ACM SIGMETRICS Perfor-mance Evaluation Review,2003,31(1):218-228.
[17] JALAPARTI V,BODIK P,KANDULA S,et al.Speeding up distributed request-response workflows[C]//Pro-ceedings of ACM SIGCOMM Conference.New York,USA:ACM Press,2013:219-230.
猜你喜欢
舰船电子工程(2021年6期)2021-06-28
汽车维修与保养(2020年10期)2021-01-22
汽车维修与保养(2020年11期)2020-06-09
中国计算机报(2020年15期)2020-05-13
黑龙江电力(2017年1期)2017-05-17
雷达学报(2017年6期)2017-03-26
CHIP新电脑(2016年9期)2016-09-21
天津大学学报(自然科学与工程技术版)(2015年10期)2015-12-29
西北工业大学学报(2015年3期)2015-12-14
舰船科学技术(2015年8期)2015-02-27
