
组合分类器在金融行业数据分类中的应用研究
2018-04-18 11:07:56陈江涛吕建秋
计算机应用与软件 2018年2期
陈江涛 吕建秋,2*
1(华南农业大学 广东 广州 510642) 2(广东省科技管理与规划研究院 广东 广州 510642 )
0 引 言
金融行业是一个与我们的生活息息相关的行业,每天都会产生大量的数据,越来越多的金融企业也认识到这些客户数据背后的价值,重视对于客户关系的管理。客户分类是客户关系管理中的重要一环,它通过对以往的客户数据的分析建立分类模型,帮助金融从业人员识别目标客户,有助于金融企业更好地开展金融产品的营销。常用的客户分类算法有很多,并且已广泛应用于金融数据分析,帮助金融机构取得了巨大的效益。但是任何一种分类算法都有其优劣势所在,在分类过程中难免产生一些由于分类器本身的特点造成的分类错误,从而影响分类的准确率。为了避免这种由于分类器自身特点所产生的分类错误,分析目前单一分类方法的缺陷,找出它们的局限性,并结合他们各自的优点,构建组合分类模型是一种值得探究的重要方式。
1 国内外文献综述
金融行业的客户分类模型一直是分类研究中的热点领域之一,客户分类对于银行、证券或者保险机构识别目标客户,规避潜在风险发挥着越来越重要的作用。在此基础上,大量学者也对金融行业的客户分类进行了研究与改进,针对金融分行业的客户数据特点提出了各种各样的分类模型,这其中应用较多的有C5.0、贝叶斯网络、SVM支持向量机,神经网络算法等。例如Tam等[1]通过比较神经网络、支持向量机、KNN和ID3算法发现神经网络在银行提供的样本数据集中的预测准确性、适应性等的表现更好。Becerra等[2]则认为线性模型虽然简单易懂,但需要统计学上的假设,这是不现实的,神经网络能够区分不可线性分离的模式,但是参与神经模型的大量参数通常会导致泛化问题。因此提出运用小波分析来改善神经网络的分类模型。Dixon等[3]运用深度神经网络(DNN)算法来预测金融市场的运行方向。罗方科等[4]则运用Logistic信用风险评估模型对客户信贷风险进行分类处理,提出了一些风险规避的建议。周驷华等[5]则对多层感知器神经网络算法、SVM、线性判别、二次判别和逻辑回归等数据挖掘方法进行了比较发现多层神经网络算法在某小贷公司的小微企业信贷分类效果最好。
还有一些学者结合启发式算法对传统的分类算法进行了改进。这方面的研究有Gorzaczany等[6]运用多目标进化优化算法(MOEOAs)设计的基于模糊规则的分类器,发现这种分类器在准确性和分类速率方面要明显优于其他分类器。Marinakis等[7]针对金融行业的客户分类特征值的选择往往有很严重的主观性的问题,提出引进蚁群算法来进行特征值的选择并与分类算法相结合,有限避免了专家主观选择因素带来的分类结果影响。汤亚玲等[8]针对BP神经网络容易陷入局部极小值和收敛速度慢的问题提出将遗传算法与神经网络相结合,发现可以以更短的时间、更高的精度得到分类结果。
组合分类方法是将多种分类器组合起来,规避一种分类器分类错误风险的方法,在很多领域都有应用。例如闫瑞等[9]运用组合分类的方法研究了短文本分类中组合分类器的应用,发现组合分类器可有效改善分类算法在短文本分类中的查准率与召回率。陈学泓等[10]则在误差分析的基础上,结合两种有监督的学习算法,运用组合分类器有效提高了模型的分类精度。王昱等[11]则运用组合分类器研究了消费者信用评估,并发现其分类效果要明显好于决策树分类。
金融行业客户样本数据往往呈现维度高,样本容量大的特点,数据中可能还会存在各种各样的缺值、漏值的情况。因而在实际分析中,往往一种分类方法并不能完全满足需要,可能会陷入各种各样的分类误区,这就需要我们能综合运用多种分类方法,减少单一方法带来的缺陷。
2 本文的主要研究目标
由于几种分类算法本身的限制,其分类结果往往有一些差异,本文的主要研究目标是探究C5.0、logistic、贝叶斯网络三种分类模型对金融行业数据集中的分类表现,并根据置信度构建加权投票的组合分类模型来提高分类的准确率,为以后金融行业的客户分类等提供参考。
3 主要的研究方法
本文主要通过SPSS Modeler建模得到三种分类器在三个数据集上的分类结果。然后根据分类结果的置信度对分类数据进行组合加权,构建组合分类器模型。最后通过比较分析检验组合分类器的分类效果。
4 数据介绍
文中所选取的数据均来自于UCI数据集,UCI数据库是加州大学欧文分校提出的用于机器学习的数据库,是一个常用的标准测试数据集。本文选择的是其中三个关于金融行业客户分类的数据集[12]。
4.1 银行电话营销数据集
该数据集是葡萄牙银行从2008年-2010年的电销数据,包括有17个变量,45 211条记录,其中包含有客户的年龄、工作、教育、余额、房贷、个人信贷、电话营销结果等[13]。
4.2 信贷审批客户数据集
信贷审批的数据集包含有16个变量,690条记录,由于数据信息关系到客户信贷审批的个人隐私,因此所有的变量名都经过处理,用A1-A16表示,另外,该数据中还存在37条缺失值[14]。
4.3 信用卡客户数据集
使用信用卡客户的数据集有23个变量,30 000条数据,主要包含有给定的用户的年龄、性别、给定的信贷金额、还款历史,欠款数量等[15]。
5 基本分类方法介绍
5.1 C5.0算法
C5.0算法是一种基于决策树的分类算法,决策树的概念最早由Hunt等在1966年提出,后来提出了很多基于决策树的分类算法。其中比较著名的有Quinlan提出的基于信息增益的ID3算法,以及后来有ID3算法改进而来的C4.5算法,由C4.5算法发展而来的C5.0算法。C5.0是C4.5应用于大数据集上的分类算法,主要在执行效率和内存使用方面进行了改进,适用于处理大数据集,采用Boosting方式提高模型准确率,在软件上计算速度比较快,占用的内存资源较少[16-17]。
5.2 Logistic回归
Logistic回归是根据输入域值对记录进行分类的统计方法。Logistic回归建立一种方程,把输入域值与输出字段每一类的概率联系起来。一旦生成模型,便可用于估计新的数据的概率。对每一个记录,计算其从属于每种可能输出类的概率。概率最大的目标类被指定为该记录的预测输出值。Logistic算法计算代价不高,易于理解和实现,但是容易出现欠拟合的状态,分类精度偏低[18-19]。
5.3 贝叶斯网络
贝叶斯网络是一种以贝叶斯定理为基础的分类方法,它的基本原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。贝叶斯网络所需估计的参数很少,对缺失数据不太敏感,但是属性之间的独立性假设往往不成立,对独立性不好的数据分类效果较差[20-21]。
5.4 组合分类器
组合分类器是将多种分类器组合起来的一种方法,通过整合多种分类器的优点,避免单一分类器缺陷带来的分类错误,提升分类准确度。1990年Schapire提出了著名的弱学习定理,即只要能找到比随机猜测更好的弱学习方法,就可以将其提升为强学习方法。这里单独的分类方法就是弱学习方法,组合就是提升,因而通过组合分类器有可能找到更好的分类方法[22-23]。
6 模型构建
本文采用的是SPSS Modeler进行模型的构建与客户数据的分类。分别在上述三个数据集上应用上述三种分类算法进行分类,并比较各种算法在各个数据集上的预测精确度。最后运用组合分类器对样本进行重新分类。
6.1 数据整理
首先通过数据审核节点对三组数据进行检查,检查其中缺失值、无效值、离群值等,通过数据审核节点分析可以发现,银行电销数据集和信用卡客户数据集中无缺失值,但信贷审批客户数据集中存在部分缺失值,本文按照中程数插补这些缺失值。另外对于三个数据表中的离群值和极值按照强制替换离群值和丢弃极值得方法处理。
6.2 建 模
进行初步的数据整理后,本文建立了基于三种分类方法的分类模型,数据流图如图1所示。

图1 数据流图
6.3 组合分类器的构建
本文尝试将C5.0算法、Logistic算法和贝叶斯网络三种算法组合起来,基于这三种分类方法的分类结果得出一种新的汇总的分类模型。这种组合分类模型主要是在上述三种分类结果的基础上,通过置信度计算出权重,进行加权组合的。模型的主要流程如图2所示。

图2 组合分类器的分类流程
首先运用SPSS Modeler模型对数据进行建模,分别使用C5.0算法、logistic算法和贝叶斯网络三种方法得出分类结果以及代表各个数据对象分类精确度的置信度值。以其中一个数据集的分类结果为例,表1中最后两列分别代表分类结果以及置信度,置信度越高,说明分类的精确度越高。
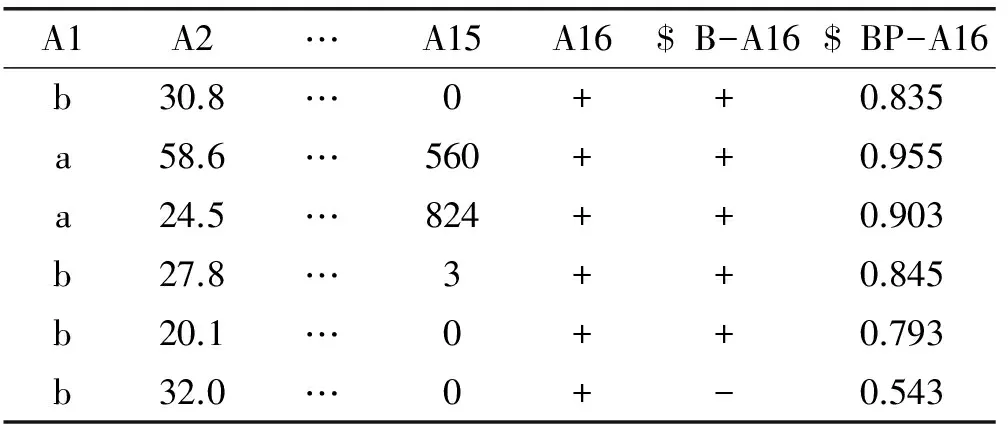
表1 信用卡客户数据集部分贝叶斯分类结果
假设有N个分类样本,分别用yij代表第i种方法中的样本j的分类结果,yj表示样本j的组合分类器分类结果,yij=0或1;αij代表第i种方法中的样本j的分类置信度,αij在0到1之间;用cij表示第j个样本中第i种分类方法的分类结果在组合分类器中的权重,以置信度来确定权重即:
(1)
(2)
(3)
通过对三种分类结果的加权组合,我们可以得到组合分类器的分类结果,由于篇幅限制,本文只截取其中部分分类结果。若三种分类方法的分类结果都是0,此时计算出来的mj必然也是0。若全是1,则计算出来的mj必然还是1,最终组合分类器的分类结果与其他三种分类结果相同。若三种分类器出来的结果不一样,组合分类器就会依据加权方法出来的mj进行判断,若大于0.5,则判断分类为1,否则为0。
从表2中我们可以看到,若三个分类器的分类结果相同,组合分类器上结果必然相同。若不同,比如mj=0.705的那一行数据样本来看,本来logistic的分类结果是错误的,但同时其置信度水平也处于最低水平,因而它在组合分类其中的权重会较小,达不到影响组合分类器分类结果的水平,最终组合分类器会在其他两种正确分类结果的影响下,得到正确的分类结果。
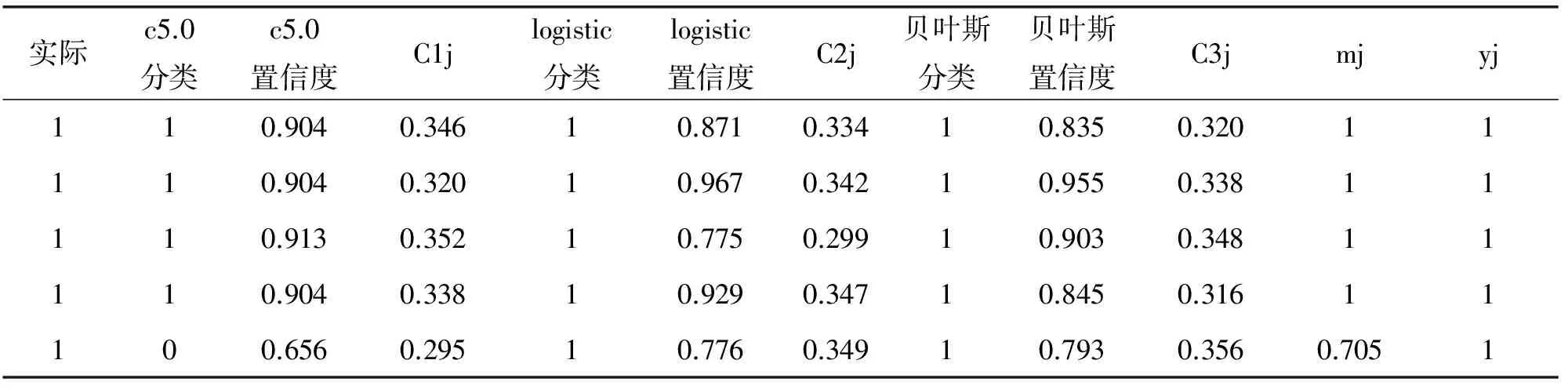
表2 信贷审批客户数据集部分分类结果
同理,在表3、表4两个数据集上组合分类器也会采取同样的计算方法,最终通过置信度来影响组合分类器的分类结果,提高分类的准确率。
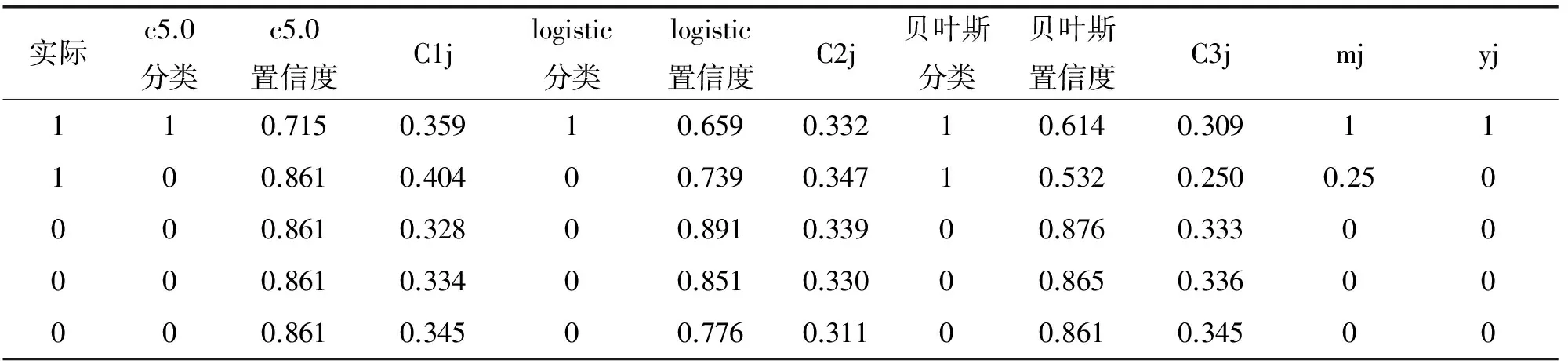
表3 信用卡客户数据集部分分类结果
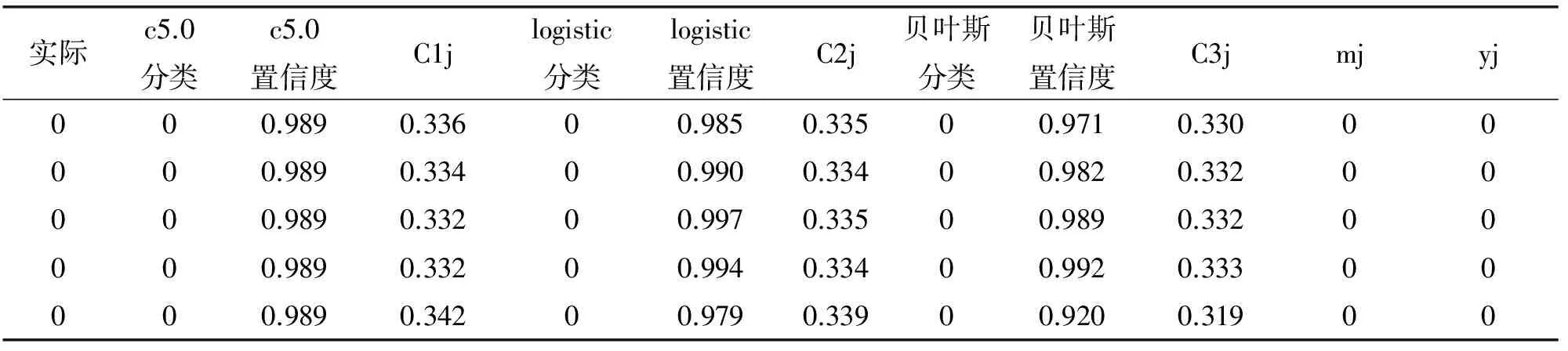
表4 银行电话营销数据集部分分类结果
7 几种分类模型的分类结果分析
从表5中我们可以看到,该组合分类器在银行电话营销数据集上表现最好,准确率远远超过其他三种单一的分类器,达到了91.39%。在信贷审批客户数据集上的分类效果也要远好于logistic分类器和贝叶斯网络分类器,略微超过C5.0分类器。在信用卡客户分类上,虽然没有明显的改进,甚至准确率要低于C5.0算法,但几种分类方法的分类准确率并没有太大的差距。从总体上来讲这种组合分类器对于分类模型能够起到一定的改善作用。
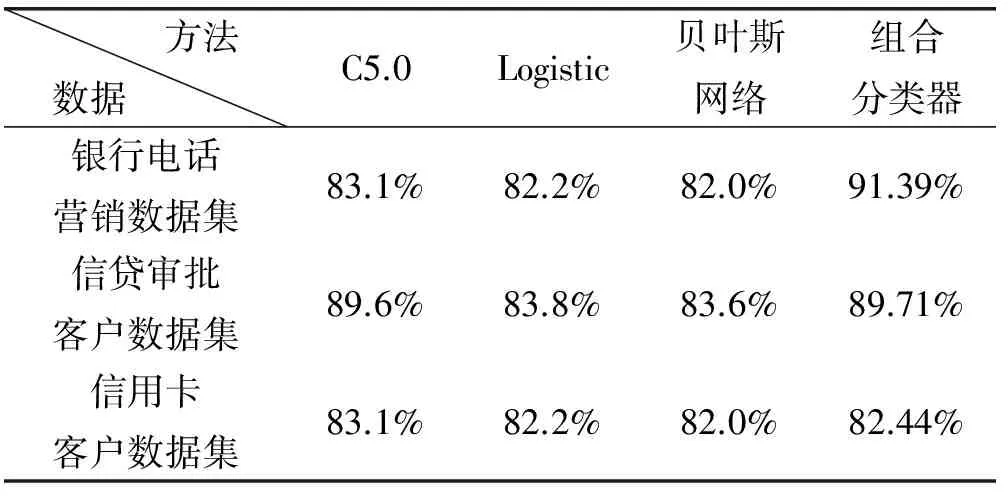
表5 几种分类方法的分类准确率比较
8 结 语
本文选取了三个金融行业的数据集,对这三个数据集分别使用SPSS Modeler中的C5.0算法、logistic算法和贝叶斯网络进行了分类。然后根据分类结果中的置信度对各个分类器的分类结果进行赋权,运用加权组合分类器的方法对三个数据样本进行了重新分类,发现该组合分类器在银行电话营销数据集和信贷审批数据集上要优于其他三种分类方法。在信用卡客户数据集上准确率虽然略低于C5.0,但高于其他两种方法,且与C5.0的准确率非常接近。从总体上讲,该种组合分类器能够对金融行业数据分类起到一定的改进作用。
[1] Tam K Y,Kiang M Y.Managerial applications of neural networks:the case of bank failure predictions[J].Management science,1992,38(7):926-947.
[2] Becerra V M,Galvão R K H,Abou-Seada M.Neural and wavelet network models for financial distress classification[J].Data Mining and Knowledge Discovery,2005,11(1):35-55.
[3] Dixon M,Klabjan D,Bang J H.Classification-based Financial Markets Prediction using Deep Neural Networks[J].Social Science Electronic Publishing,2016.
[4] 罗方科,陈晓红.基于Logistic回归模型的个人小额贷款信用风险评估及应用[J].财经理论与实践,2017,38(1):30-35.
[5] 周驷华,王素南.基于多层感知器神经网络的小微企业信贷风险研究[J].现代管理科学,2015(9):45-48.
[7] Marinakis Y,Marinaki M,Doumpos M,et al.Ant colony and particle swarm optimization for financial classification problems[J].Expert Systems with Applications,2009,36(7):10604-10611.
[8] 汤亚玲,黄华,程泽凯.基于自适应遗传神经网络的银行客户分类研究[J].计算机技术与发展,2014(7):192-195.
[9] 闫瑞,曹先彬,李凯.面向短文本的动态组合分类算法[J].电子学报,2009,37(5):1019-1024.
[10] 陈学泓,陈晋,杨伟,等.基于误差分析的组合分类器研究[J].遥感学报,2008,12(5):683-691.
[11] 王昱.基于组合分类的消费者信用评估[J].管理工程学报,2015,29(1):30-38.
[12] Frank A,Asuncion A.UCI machine learning repository[Z].2010.
[13] Moro S,Cortez P,Rita P.A data-driven approach to predict the success of bank telemarketing[J].Decision Support Systems,2014,62(1246):22-31.
[14] Mason L,Bartlett P,Baxter J.Direct optimization of margins improves generalization in combined classifiers[C]//Conference on Advances in Neural Information Processing Systems II.MIT Press,1999:288-294.
[15] Quinlan R.Data mining tools see5 and c5[J].Researchgate Net,2008(9).
[16] Quinlan J R.C5.0:An Informal Tutorial[J].Rulequest Research,2009(Suppl 4):834.
[17] 李强.创建决策树算法的比较研究——ID3,C4.5,C5.0算法的比较[J].甘肃科学学报,2006,18(4):84-87.
[18] Witten I H,Frank E,Hall M A,et al.Data Mining:Practical machine learning tools and techniques[M].Morgan Kaufmann,2016.
[19] 杨小平.二分Logistic模型在分类预测中的应用分析[J].四川师范大学学报(自然科学版),2009,32(3):393-395.
[20] Buntine W.Learning classification rules using Bayes[C]//Proceedings of the sixth international workshop on Machine learning,2016:94-98.
[21] 蒋良孝.朴素贝叶斯分类器及其改算法研究[D].中国地质大学,2009.
[22] 付忠良.分类器线性组合的有效性和最佳组合问题的研究[J].计算机研究与发展,2009,46(7):1206-1216.
[23] Schapire R E.The strength of weak learnability[J].Machine learning,1990,5(2):197-227.
猜你喜欢
核科学与工程(2021年4期)2022-01-12 06:30:22
计算机应用(2018年5期)2018-07-25 07:41:26
电子测试(2018年1期)2018-04-18 11:52:35
数理化解题研究(2017年4期)2017-05-04 04:07:54
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
铁道通信信号(2016年6期)2016-06-01 12:10:20
电子器件(2015年5期)2015-12-29 08:43:15
轴承(2015年2期)2015-07-25 03:51:04
电测与仪表(2014年15期)2014-04-04 12:05:20
