
基于神经网络的图像弱监督语义分割算法
2018-04-18 11:07张烽栋
计算机应用与软件 2018年2期
顾 攀 张烽栋
(复旦大学计算机科学技术学院 上海 201203) (上海市智能信息处理重点实验室(复旦大学) 上海 201203)
0 引 言
图像分类任务就是通过训练得到一个模型,该模型可以对于每一幅图像标注其语义的分类。而图像的语义分割任务是需要训练一个更为复杂的模型,它可以对于图像中的每一个像素,标注其像素的分类。相较于普通的图像分类而言,图像的语义分割可以提取得到更多的信息,不仅可以找到图像中的语义信息,还可以精确地定位到所有的语义信息在图像中的位置。
近些年来,越来越多的学者、专家在图像的语义分割这个领域作出了卓越的贡献。一些研究组也发布了他们所提供的图像数据集合(如Pascal VOC Challenge中的分割任务[1]),数据集中的所有图像都具有强监督标签的信息(所谓强监督的标签信息,就是对于每一幅图像中的每一个像素,都标记了该像素是属于哪一个分类的),大大地加快了图像的语义分割问题的研究进展速度。可是随之而来的一个问题在于,强监督的训练数据总是只在有限的数据集中提供,所有利用这些数据训练算法的鲁棒性和实用性都局限于数据集中的数据量。
图像语义分割的算法起源于文献[2],其中介绍了一种基于条件随机场模型的算法,它通过对图像每一个像素为离散点,构建了条件随机场模型。而后随着技术的发展,传统图像语义分割的算法大多都是通过设计一种提取像素(或图像)级别特征的算法,再与分类器(如支持向量机)相结合,计算语义分割的结果[3]。随着2015年全卷积网络的提出[4],图像的语义分割算法的研究开始偏向于使用深度学习的技术进行解决,大多数的研究都在全卷积网络的基础上进行。使用强监督数据训练的神经网络模型在该任务上取得了非常好的效果,同时,算法的鲁棒性与实用性都是取决于数据集中大量的强监督训练数据才达到的。
可是,现在除了那些少量的公开的数据集,具有强监督标注的数据在生活中几乎不存在,而另一种类型的数据,具有弱监督标签的图像数据(所谓弱监督的标签信息,就是对于每一幅图像而言,仅仅标注了图像中所包含的物体的类别),可以轻松地在互联网上进行收集得到。相对于数据集中有限的场景,如果能将生活中的数据全部加以利用,训练得到的模型的鲁棒性一定会大大提高。如何利用弱监督的图片数据来对深度学习模型进行训练,变成了一个值得研究的问题。
由于全卷集网络[4]的提出,近期提出的算法大多都是基于强监督标签的算法,相对于利用强监督标签数据进行训练的算法,利用弱监督标签的算法在效果上要较为差一些。主要是因为弱监督标签仅包括了图像级别的标注信息,而语义分割的任务需要得到的是像素级别的标注信息,在这种标注信息的层级不同的前提下,难以设计一种有效的损失函数。大多数现有的算法都是通过一些近似算法来回避这个问题。如果设计出一种有效的损失函数,让神经网络可以达到端对端的训练过程的话,那么算法的效果一定会得到巨大的提升。
本文提出了一套基于神经网络的图像弱监督语义分割框架,通过设计一个可以兼容弱监督标签的损失函数,使神经网络达到端对端的训练过程。方法也结合了一些经典的方法,将图像的语义分割与图像的目标检测相结合,提取并计算图像的语义分割结果。
1 图像弱监督语义分割框架
本节将介绍一种新的图像语义分割算法,它基于深度神经网络框架,并且可以通过弱监督的数据对网络进行端到端的训练,以最大化深度神经网络的效果。这里将首先介绍算法对于一种特殊的情况(图像中只存在单目标问题时)的检测算法,再通过提出多块损失函数,将算法扩展至对于多目标图像内容的检测。
1.1 弱监督的单目标图像语义分割
首先定义图像训练集中的图像为x,图像级别的标签为y,并x∈RN×M,y∈{0,1}C,其中N与M为图像的宽与高,而C为图像中一共可能包含的语义类别的数量。定义s为任务最终输出的语义分割结果,并s∈{0,1,2,…,C}N×M,每一个元素si,j表示了像素xi,j的语义类别,为0时表示属于背景(或不属于任何一个语义类别信息)。
在类别激活热度图算法中[5],如图1中所示的深度神经网络结构,可以通过弱监督的数据对网络结构进行训练,并获取得到在低层神经网络输出的特征帧。通过在特征帧与语义层之间,利用一个全局均值池化层将特征图转换成单个类别的置信度。由于最终的图像在一个类别上的置信度可以通过f1,f2,…,fK进行线性组合得到,所以对于某一个类别的热度图可以通过计算特征图中的每一帧的线性组合得到。
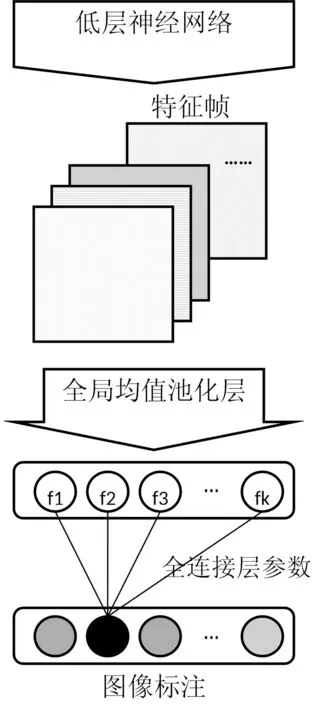
图1 利用全局均值池化层的神经网络语义层结构
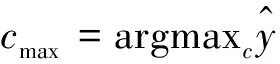
(1)
式中:F表示最后的特征图层的内容并且K表示该特征图层的通道数。通过热度图的结果,可以近似地计算得到物体在图像中所处于的位置,但无法求得物体更详细的边缘信息。而物体的边界信息可以通过一些其他的无监督的算法进行提取[6],这里可以定义提取得到的边界为m∈{0,1}N×M,其中每一个元素mi,j表示单个像素是否属于该物体中,将轮廓信息与热度图的内容相结合,可以求出该轮廓中所包括的物体所属的分类为:
(2)
式中:S=∑i,jmi,j表示物体轮廓所占据的区域大小,在计算得到该物体具体所属的分类后可以计算图像x的图像语义分割结果:
s=cmax×m
(3)
1.2 弱监督的多目标图像语义分割
图2是本文算法的整个算法框架内容,算法中神经网络的结构参考残差网络[10]的特征提取层进行实现。算法首先通过一些无监督的对象预检测算法在图像中找到所有的物体位置,这些物体所包含的语义类别的并集肯定会包含图像中所有出现的类别数。根据1.1节中所介绍的算法内容,对于仅包含单个分类的物体的图像可以通过深度神经网络的算法计算得到其图像语义分割的结果。
在通过对象预检测算法对图像进行检测后,可以得到多个包含物体的区域,将其截取后可以得到I1,I2,…,IT个图像,其中T是子图的个数。根据之前算法的介绍,每一幅子图都可以通过神经网络的内容计算得到单幅图像的语义分割结果si,在全部计算完毕后可以计算整幅图像的语义分割结果:
(4)
1.3 多块损失函数的应用
在1.2节中所介绍的方法中,对于每一幅子图而言,算法并不能获取得到每一幅子图中所包含的对象所属的分类信息,如果要仅通过弱监督的数据对深度神经网络的模型进行训练,需要对网络结果进行修改。使用弱监督的数据对神经网络参数进行训练,只能使用图像级别的标注,即对于每一幅图像x而言,存在标签y∈{0,1}1×C表示该图像中是否包含对应的类别的物体。在算法中,将所有的子图看作是一个整体作为输入,所有的子图将会送入深度神经网络中进行训练,在网络最后的语意层输出类别信息的位置,加入本文介绍的多块损失函数,即可完成使用弱监督数据对深度神经网络的训练过程。
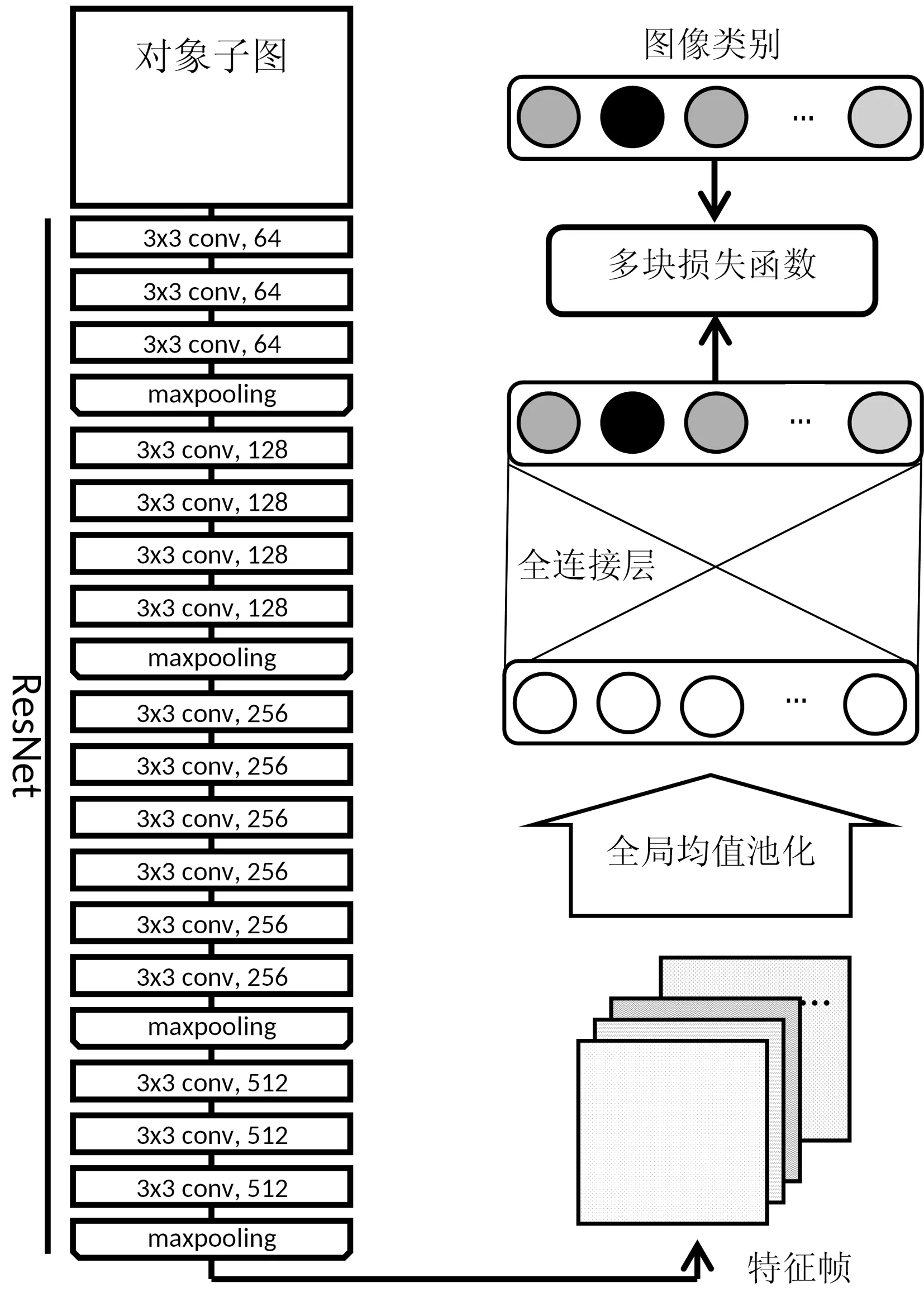
图2 弱监督图像语义分割算法框架
在介绍多块损失函数之前,首先回顾一下在深度神经网络算法中的经典问题,图像分类问题中所使用的代价函数:
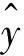
定义多块损失函数为:
MPF(y1,y2,…,yT;y)
(5)
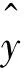
(6)
对于神经网络而言,它对于子图的类别输出结果应趋近于只有一个维度较高的情况(由于每一个子图中应该只包含了一个物体),使用求最大值的操作可以将这些子图的输出全部结合成为一个向量。所以在这里,多块损失函数具体可以被描述为:
(7)
式(7)所介绍的多块损失函数可以直接被用于深度神经网络训练过程的前向传播过程中,而在训练过程的反向传播中所使用到的损失函数的梯度大小,对于每一个子图所输出的类别置信度yt的梯度可以被计算为:
(8)
2 实 验
对于在第1节中所提出的算法,进行了一些在数据集中的实验。本节将介绍实验的具体配置以及实验的结果,并进行关于结果的适当的分析。
2.1 数据集配置及实现细节
算法在MSRC-21以及VOC2012[1]数据集中进行了实验,并与一些其他算法进行了比较。对比算法首先选择了一种基于特殊的随机森林的算法[7],它通过比较像素周围像素的值计算出像素特征,再通过随机森林对每一个像素进行分类。另一个对比算法是基于超像素分割的算法[3],首先将图像分割成超像素,然后再使用分类对超像素进行类别的判断,最终得到图像的语义分割的结果。这两个算法都是基于弱监督数据对模型进行训练的,与本文所介绍的算法条件相同。
训练用的两个数据集都是带有强标签信息的真实图像数据集,强标签的信息仅仅用于测试算法的语义分割结果,而在训练的过程中仅使用弱监督标签的部分。MSRC-21数据集包含了大小为320×213的591幅不同的图片,它们被分在了21个不同的分类中。需要一提的是,由于“horse”与“mountain”两个分类的图像数量较少,在训练及测试的过程中算法忽略了这两个分类的结果。而在VOC2012数据集中包括了1 464幅不同的训练图片以及1 449幅测试图片,它们被分在了20个不同的前景的分类中。
第1节所介绍的基于深度神经网络的图像语义分割的算法基于MatConvNet框架[8]进行构建,该框架是基于MATLAB语言的计算机视觉框架,它可以自定义不同的神经网络层、代价函数等,可以顺利地通过该框架将算法所介绍的神经网络算法进行实现。
在训练的过程中,为了在图像中提取所有物体的子图,使用Deep Mask算法[11]作为对象预提取算法。对于所有提取得到的子图都将包括一份对象的轮廓信息以及子图属于对象的置信度,并设计一个阈值,当子图属于对象的置信度大于该阈值时将该子图作为一个有效的对象在训练、测试过程中进行使用。对于一幅图像中有效的子图将它们打包后一齐送入深度神经网络,使用在第1.3节中介绍的多块损失函数对网络进行训练。
2.2 实验结果
算法在两个数据集中都是通过准确率作为评价标准的,准确率计算了在所有测试图像中所有的像素在语义分割问题中分类的正确率。
表1总结了算法与对比算法在MSRC-21数据集中图像的语义分割问题的结果。由于MSRC-21数据集中包含了许多个属于背景分类的像素,而算法中包含对象预检测算法的存在,对于图像中有大多数部分是背景,算法对背景区域不会特别敏感,性能将会受到一定的影响,所以在最终结果上要略逊于对比实验的算法。
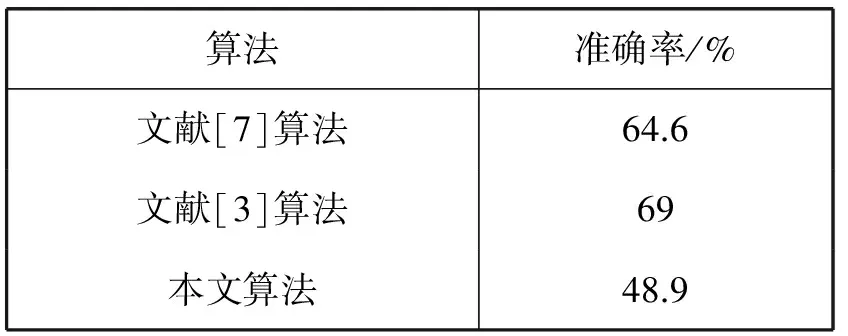
表1 算法在MSRC-21数据集中的结果
表2总结了算法与对比算法在VOC2012数据集中图像的语义分割问题的结果。相对于MSRC-21数据集而言,VOC2012数据集中包含前景的图像部分较多,所以在该数据集中算法表现的效果要比对比算法都要高上不少。
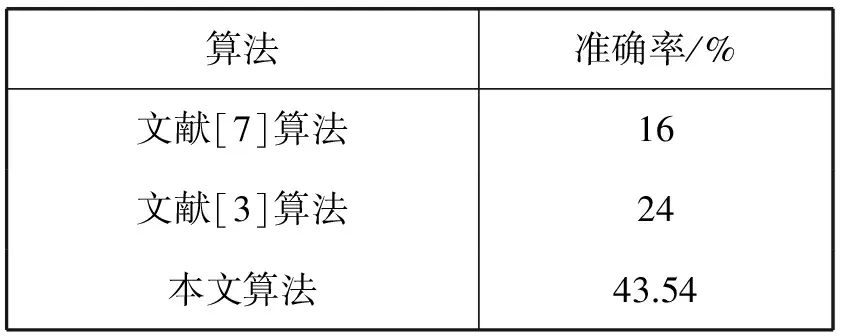
表2 算法在VOC2012数据集中的结果
这里要进一步介绍在VOC数据集中实验的结果以及细节,如表3所示,表格展示了在数据集中每一个具体分类的实验结果。其中“本”所表示的就是本文所介绍的算法,其他的对比算法以参考文献编号进行表示。在对比的实验中,增加了一些近年来强监督的算法作为比较算法,可以直观地看出弱监督算法与强监督算法之前的一些差距。
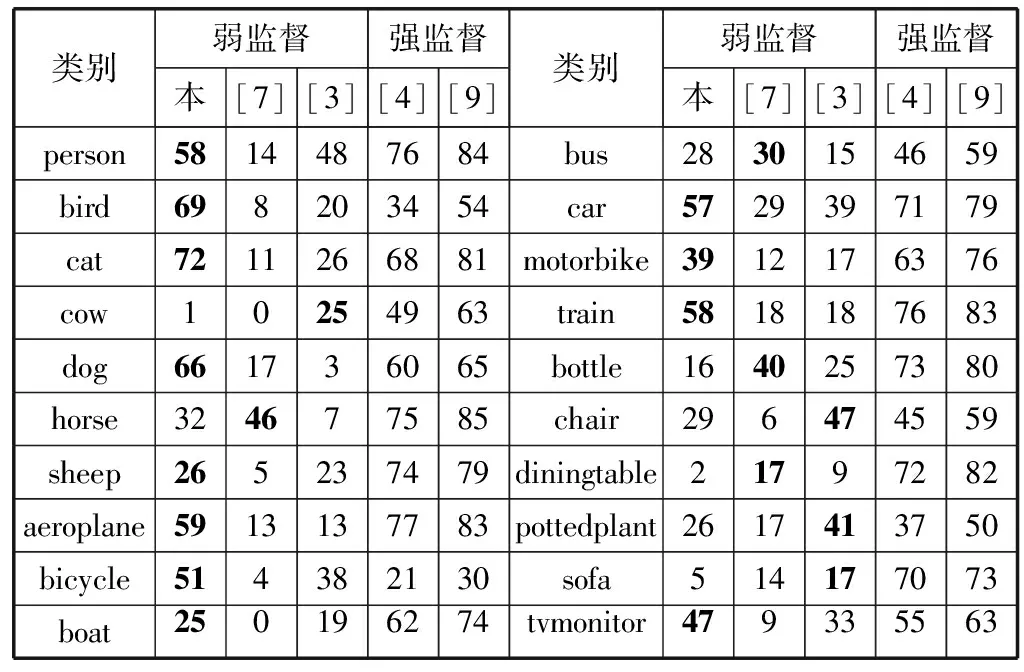
表3 算法在VOC2012数据集中的详细结果 %
可以看出,在大多数分类中本文算法实验的结果都比其他弱监督算法优秀,在一些分类的结果上已经可以追上强监督分类的算法结果。在物体属性很明显的类别中算法的效果已经接近与强监督的算法,但在那些“和背景较像”的分类中(如“沙发”、“餐桌”等),算法的表现非常不尽人意。因此,算法会受到一定的背景因素的影响,在VOC数据集中这个影响已经变低了不少,但还是依然存在,也证明了算法受背景的影响程度较高,这也是本文算法的一个不足之处。
3 结 语
本文提出了一种基于深度神经网络的图像语义分割的算法,算法可以通过弱监督的数据对模型进行端到端的训练,在训练数据易于收集的同时可以最大化神经网络的性能。在深度神经网络模型中,本文提出的多块损失函数很好地将多个不同的图像输出结合,使模型达到了端到端的训练过程。
本文的工作也还存在着一些不足,文中的对象预检测模块还是一个独立的模块,并无法用网络端到端的训练优化这一个模块的内容。在未来的工作中,如何将对象预检测模块与语义分割网络相结合是一个较为重要的问题。
[1] Everingham M,Van Gool L,Williams C K I,et al.The pascal visual object classes challenge 2012 (voc2012) results (2012)[OL].2010.http://www.pascal-network.org/challenges/VOC/voc2011/workshop/index.html.
[2] Shotton J,Winn J,Rother C,et al.TextonBoost:Joint Appearance,Shape and Context Modeling for Multi-class Object Recognition and Segmentation[J].Proc Eccv May Graz Austria,2006,1(2):1-15.
[3] Zhang K,Zhang W,Zheng Y,et al.Sparse reconstruction for weakly supervised semantic segmentation[C]//International Joint Conference on Artificial Intelligence,2013:1889-1895.
[4] Long J,Shelhamer E,Darrell T.Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2015:3431-3440.
[5] Zhou B,Khosla A,Lapedriza A,et al.Learning deep features for discriminative localization[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016:2921-2929.
[6] Papandreou G,Chen L C,Murphy K P,et al.Weakly-and semi-supervised learning of a deep convolutional network for semantic image segmentation[C]//Proceedings of the IEEE International Conference on Computer Vision,2015:1742-1750.
[7] Shotton J,Johnson M,Cipolla R.Semantic texton forests for image categorization and segmentation[C]//Computer vision and pattern recognition,2008.CVPR 2008.IEEE Conference on.IEEE,2008:1-8.
[8] Vedaldi A,Lenc K.Matconvnet:Convolutional neural networks for matlab[C]//Proceedings of the 23rd ACM international conference on Multimedia.ACM,2015:689-692.
[9] Papandreou G,Chen L C,Murphy K P,et al.Weakly-and Semi-Supervised Learning of a Deep Convolutional Network for Semantic Image Segmentation[C]//IEEE International Conference on Computer Vision.IEEE,2015:1742-1750.
[10] He K,Zhang X,Ren S,et al.Deep Residual Learning for Image Recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas,NV,United States,2016:770-778.
[11] Pinheiro P O,Lin T Y,Collobert R,et al.Learning to Refine Object Segments[C]//European Conference on Computer Vision 2016.Lecture Notes in Computer Science,2016,9905:75-91.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小哥白尼(军事科学)(2022年2期)2022-05-25
上海理工大学学报(2020年4期)2020-09-27
计算机与数字工程(2019年10期)2019-11-12
红领巾·萌芽(2019年8期)2019-08-27
计算机与数字工程(2019年3期)2019-03-26
现代计算机(2019年2期)2019-03-02
长江学术(2016年4期)2016-03-11
CHIP新电脑(2016年3期)2016-03-10
人间(2015年21期)2015-03-11
