
基于自学习的软件质量实时预警模型
2018-04-18 11:07:40刘原序韩培胜
计算机应用与软件 2018年2期
刘原序 韩培胜
(解放军信息工程大学密码工程学院 河南 郑州 450000)
0 引 言
随着软件规模的不断扩大,对于软件质量的分析控制已经成为各软件开发公司的关注的焦点。在软件质量管理这个问题上提出了许多有效的方法,如CMMI、ISO9126等。CMMI模型是现在常用的用于提高软件开发质量的模型。该模型通过规范软件的开发过程来实现软件质量的可控,模型认为规范的开发过程会产生良好的软件质量,不规范的开发过程会导致糟糕的软件质量[1]。但CMMI在应用时没有具体的指导,实施起来难度较大,而且一旦开发环境发生变化,无疑又会增加软件开发项目的质量成本。
软件质量评估一直是近几年的研究热点,国内外学者提出了许多科学有效的分析理念和模型。孙子谦等[2]提出了一种基于PDCA环的质量管理模型,但该方法仅在基于敏捷开发的软件上进行了应用,无法指导基于其他软件开发模型的软件项目的开发,不具有普适性。柴获等[3]提出了一种基于置信度的软件质量评估模型,将置信度引入模糊评价中,提高了软件质量评估的客观性和准确性,但该模型的指标评分还是需要人工评分,难以保证其合理性。Leon Osterweil[4]在软件质量管理方面提出了“软件过程即软件”的思想,这种思想以开发过程为软件开发项目的质量管理的核心,认为对于软件过程的控制和优化能提高软件开发项目的最终产品的质量。本文就是基于这种思想,建立了过程指标体系和软件质量预警模型。软件开发的过程模型虽然有许多,如:瀑布开发法、迭代开发法、原型开发法等,但总体来说其开发流程都是需要经历多次迭代,才能得到客户满意的产品。所以在软件开发过程中实时的对软件质量进行评估预警对于软件开发过程的优化和软件质量的提高具有十分重要的作用。
现有的软件质量评估的算法大多都是基于固定学习样本学习算法和模型,如:分类回归模型[5]、BP神经网络算法[6]和隐马尔科夫模型等[7]。这些模型虽然在分析软件质量和控制软件缺陷方面具有一定的优势,但也存在着许多不足:马尔科夫在实际应用时是建立在诸多假设之上,需要对软件内部的特性进行比较详细的了解;回归树在用于分类时其泛化能力低下,而BP神经网络的神经元的选择则存在多变性,无统一的指导。在现实中应对多变的开发环境时都需要重新生成学习样本进行新一轮的学习,而新的学习样本的生成会耗费大量的人力物力,这无疑会大量增加软件的质量成本。而且软件开发项目的开发环境可能会发生变化,现有的模型对于现实中样本点出现的新的规律难以进行及时的分析和处理[8],以至于大部分情况出现离群点时都被当作数据噪声来处理,这种情况在现实情况中是明显不合理的。
SVM(Support Vector Machine)是20世纪90年代Vapnik等提出来的一种二分类算法,该算法通过利用核函数,将低维空间的数据映射至高维空间,解决的低维空间内数据线性不可分的问题。相比其他分类算法,SVM基本不会陷入局部最优解,而且可以从较小的样本中获取足够的分类信息,减少了学习样本的开支,能较好地处理质量预警问题。
为了提高质量预警的可靠性,本文提出了一种基于过程指标分析的软件质量评估模型,该模型首先利用主成成分分析法对指标进行属性约简后利用IL-SVM模型对软件质量进行实时的预测分析。该模型能够通过分析异常点的出现频次来实现对学习规则的实时更新,自动分析样本中出现的新数据并对其进行标记与学习。
1 评估指标选取原则
现有的软件开发流程主要包括瀑布模型、螺旋模型、变换模型、增量模型和喷泉模型等。但在开发大型的软件时,项目组都会在对软件进行需求开发后将软件分成若干功能模块,每个模块由一个小组人员进行开发和维护。而每一个模块又需要实现若干的功能点,所以每一个模块又可以看作一个小程序,本文在对一个软件开发项目进行评估时,拟将一个项目先划分成若干的模块,然后对每个模块进行质量预警,通过对每个模块进行质量控制,从而实现对软件整体质量的合理保证。其结构如图1所示。
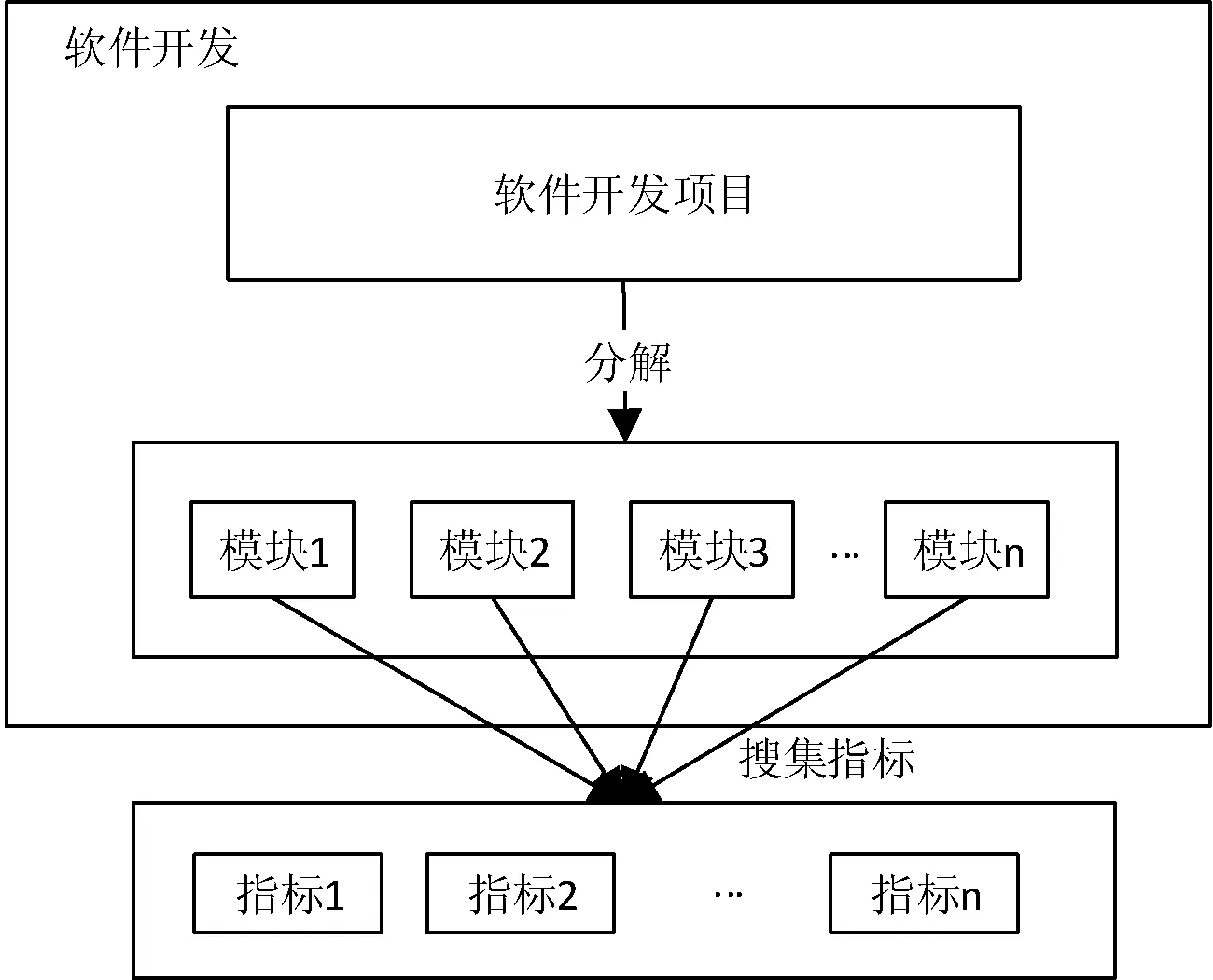
图1 指标搜集原则图
而每一个模块的开发也是需要经过不断的迭代,这样我们就可以在开发过程中不断的搜集对应的评估指标来实现对软件开发项目的实时的质量预警。
但是指标的搜集也需要项目组做好决策,如果搜集到的评估指标较少,会导致质量预警效果不好。而如果搜集过多的评估指标则会导致质量成本过高,提高软件开发的成本。
2 评估模型描述
在对软件开发项目进行指标选取之后,就应结合这些指标对软件的质量进行及时的预警分析。本文提出了一种基于过程指标分析的软件质量实时预警模型,该模型首先使用PCA(Principal Components Analysis)[10]进行属性约简后,然后再使用可自主进行分类知识更新的IL-SVM(Incremental Learning Support Vector Machine)算法来实现对软件的实时的质量预警。该模型与常规的软件质量模型不同,它能够主动更新分类规则,在多变的开发环境中具有较好的适应性,能够实现在开发过程中对软件的实时质量预警,模型的基本步骤如图2所示。

图2 评估模型流程图
图2中虚线代表模型进行分类知识的更新的流程,实线代表正常的质量评估的流程。从图2可以看出,本模型可以在对软件质量进行质量预警的同时也对评估数据集中产生的新样本点进行标记,通过自动生成增量学习集的方式,实现模型分类知识的更新,以达到适应数据集的变化的目的。
2.1 属性约简降维
属性约简降维的目的在于通过分析各评估指标的相关程度,将相关性较高的属性进行裁剪整合,在不影响评估结果的前提下减少评估指标数来达到降低分析时计算量的目的。PCA在属性约简方面具有较强的性能,能够将数据中的主要属性成分进行准确的筛选。PCA的目的是通过对数据库中的数据进行分析,通过K-L变换,将原数据的属性数量进行约减,通过较少的特征描述来满足数据分析的要求。这种算法通过将原数据库中的数据属性进行映射,将数据库中的数据点映射至一个维度较低的空间中,来实现对属性的约减。在经过PCA约简后的数据集不仅降低了属性维度,提高了分类效率,而且还会有降低数据噪声的作用,提高了SVM对于噪声数据的容忍度。
其基本步骤如下所示:
(1) 计算原数据库中数据的协方差矩阵。
(2) 得出协方差矩阵的特征值λ和特征向量q,并依据特征值的大小进行排序。
(3) 算出各属性的总计贡献率γ=∑λ,并且设定一个阈值ρ,如果该属性的γ≥ρ,则该属性为主成成分。
2.2 IL-SVM增量学习算法
在对原始数据进行降维处理后,分类的计算量大大的减少了,在现实的软件开发实践中,其开发的环境不可能一成不变,所以对于软件质量的预警知识也需要进行实时的更新。现有的分类方法虽然有增量学习,但其学习样本都需要再次进行搜集,而且其增量学习的时间点也难以确定。为了对软件质量的进行实时的管控分析,实现对软件开发项目的软件产品的及时的质量预警,本文提出了一种可增量学习的IL-SVM算法。与传统的SVM算法相比,IL-SVM算法的改进主要体现在它可以利用现有的数据集生成增量学习集,从而实现自主的知识学习。在进行第一次学习后如需更新SVM[11]分类规则,无需专门获取学习数据来对SVM进行学习,使其可以依据数据中产生的变化而对分类规则进行相应的更新,对于噪声数据也能较好的处理和分析。
IL-SVM是基于数据中的支持向量集而提出来的,首先给出几个定义:
定义1如果有一个超平面可以将数据集划分成两个部分,那么在超平面两边的间隔边界将其定义为支持平面f(x1)和f(x0)。
定义2如果在数据集中有点(xi,yi)满足((xi,yi)⊂f(x1))∪((xi,yi)⊂f(x0)),则称这些点为SV点。
定义3如果在数据集中我们(xi,yi)满足((xi,yi)⊄f(x1))∩((xi,yi)⊄f(x0)),且该点位于平面f(x1)与f(x0)中间,则称这些点为ISV点。
定义4如果在数据集中有点(xi,yi)满足((xi,yi)⊄f(x1))∩((xi,yi)⊄f(x0)),且该点位于平面f(x1)与f(x0)两侧,则称这些点为OSV点。
定义5设L为数据集中的数据点至超平面的几何距离,当L=1时,数据点位于支持平面上;当L>1时,数据点位OSV点;当L<1时,数据点为ISV点。
上述定义可以用图3进行概括。

图3 数据点分类图
SVM的目的是为了使得分割后的两个平面之间的距离最大化,而这个求最大化的问题可以转变成凸二次规划[12],如下式所示:
(1)
其最优解为:

(2)
式中:λ为超平面的向量;q为阈值;C为惩罚因子。
所以,在对数据集进行分类的过程中,那些远离超平面的数据pi=0 ,故这些数据点并未对分类的结果产生影响,对超平面有影响的是最靠近超平面的那些数据。所以我们可以得出SVM在训练的过程中,靠近超平面的数据对于算法的学习具有极其重要的影响作用,而且这部分数据在整个数据集中只占很小的一部分。如若使用该部分数据进行SVM的模型训练可以在不影响评估精度的前提下极大地降低训练消耗,提高训练的效率。所以我们可以在后续的模型训练中将在模型进行初次学习后,利用这一类数据进行增量学习。
IL-SVM的初次学习与常规的SVM算法一样,依据已有的学习数据集,找出将数据集的超平面,并将此超平面用于后续的分类。然而在后续的分析过程中,数据集中经常会产生许多“噪声”点,大多数算法在对待这些噪声点的方法只是对其进行删除或者忽略。但往往在这些离群的“噪声”之中存在着许多新信息,代表着数据集中的数据发生了新的变化,这些变化对于软件质量预警分析具有十分重要的意义。IL-SVM算法就是在进行了初次学习后,针对后续分类的过程中识别出来的“噪声”点进行的增量分析,挖掘这些离群点中所包含的信息,识别环境中发生新的变化。
2.2.1IL-SVM训练
首先我们使用人工标注的方式获取所需的学习数据集,标注依据为如果模块的缺陷值大于一则标记为问题点,如果缺陷值为零,则标记为正常点。利用获取的学习数据集T0进行模型训练,获得稳定的IL-SVM分类器F0,并且依据分类的结果,将数据集中的点标记为ISV点和OSV点。
在实际情况中,正常点的数量会远远大于问题点的数量,导致训练数据存在不均衡的情况,这就会使得在训练时可能会导致分类的结果出现误差。为了解决这个问题,我们采用下采样的方法进行采样,学习时我们首先从正常点中随机选择与问题点数量一致的样本点,得到正常点的子样本集,并将这些子样本集与问题点的样本集进行分类训练,得到若干分类分类器,最后在利用Ensemble(模型融合)的方法将分类器进行组合,最终得到一个合理的分类器。
然而SVM在学习时对于噪声数据也是十分敏感的,为了减少噪声数据和不合理数据对分类器学习的影响,我们将原函数进行修改,加入惩罚值来调节分类错误点的对于分类器的影响:
(3)
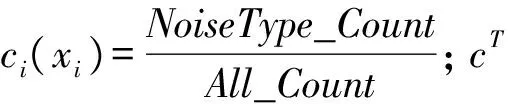
2.2.2IL-SVM增量学习
IL-SVM增量学习与普通的增量学习算法的不同之处在于IL-SVM算法无需专门建立学习数据集来进行模型的增量训练,它可以在使用过程中自动识别数据中存在的变化,依据数据集中产生的变化做出相应的分类规则的改变,以适应新的情况。
在对模型进行首次训练后,模型就会被应用到实际的分析数据集中,在实际的数据分析过程中会产生一些无法分类结果的数据点,我们将这些数据点记为Err点,并将这些数据点放入一个集合E0中。
E0集合中的数据点就是“噪声”点,由于在前面分析得出靠近超平面的数据点对于超平面的确定具有极其重要的影响,远离超平面的数据点对于超平面的确定影响不大,故我们选取E0和OSV点中1≤L≤2-ξn(0<ξn<1)的数据点作为增量训练集H0。对于增量候选集的我们依据规则1进行数据集的选取。
• 候选增量集选取规则
(1) 依据设定的阈值ξn选取候选增量训练集H0,选取ξn≤L≤1的ISV点和1≤L≤2-ξn的OSV点。
(2) 如果H0中含有OSV点,这些点在后续的增量训练时会保留。
(3) 如果H0中含有ISV点,这些点在后续训练中会依据点集更新规则2进行点集的淘汰更新,防止因为Err点的不断累积,影响分类器的准确度。
需要注意的是,增量训练集中的ISV点和OSV点并不是固定的,在对模型进行增量训练之后,原来的ISV点可能变成SV点甚至是OSV点。
• 候选增量集更新规则

(2) 如果E0集合中的点θ不是从最近k次分类中选取的ISV点,则说明该数据点不具有普遍性,将该数据点从点集E0中删除。
(3) 如果E0集合中的点θ如果是在IL-SVM模型进行增量训练后由OSV点变成ISV点的,则该点的赋值按照模型增量训练稳定后进行第一次实验分析算起。
对于规则中的参数K和参数ξn的选择和调整可以依据经验进行选择,当K和ξn取值过大,会导致增量样本集中的数据点过多,导致IL-SVM的增量训练效率下降;当K和ξn取值过小则会导致无法了解的识别数据集中数据产生的变化,对于出现的新样本点无法进行及时的分别。
• 增量学习规则
(1) 如果E0集合中的所有点在某次分类之后,其集合中的点的权值之和∑Bi大于设定的阈值M,则模型需要进行增量学习。
(2) 如果E0集合中的所有点在某次分类之后,其集合中的点的权值之和∑Bi小于设定的阈值M,则模型无需进行增量学习,继续进行软件质量预警。
算法1IL-SVM增量学习模型
输入:原IL-SVM模型F0、增量集H0、数据点的权值B
输出:新IL-SVM模型Fi
Firsttrain(H0)
//对IL-SVM进行初次的学习
Generate(F0)
//得到稳定的分类器H1
Set (K=x,M=y)
//设置增量学习的参数
If count(∑Bi)>M
//判断累积的Err点的权值之和是否超过阈值
Fori<2000
//设置增量学习的学习次数上限
i++
IncrementalTrain(Hi)
//依据得到的增量训练集Hi训练IL-SVM模型
If (Check (Fiis correct))
//利用最近几次的数据进行试验,检测分类器分类是否准确
OutputFi
End For;
Else
Generate(Hi)
//依据候选集生成规则生成新的数据候选集来对算法进行
//增量训练
3 模型应用
在现实的开发环境中,大部分软件开发项目会将软件划分成若干模块,每个模块会由一个明确的小组负责,在模块基本成型后再进行系统集成,从而实现对软件的合理科学的开发。在开发过程中,每一个模块都会进行若干次的迭代,不断地进行重复开发,我们就可以在模块的每一次迭代后、每一次集成后、每一次测试后甚至是每一次对开发产生的数据产生变动后,分析相关的数据来实现对模块的质量情况进行预警。
为了验证模型的在实际情况中的评估的准确性,我们从NASA数据中心下载了一个用于软件质量分析数据包来进行数据的模拟分析(运行的软件环境是Matlab5.3/Win10 硬件环境是Intel I5,处理速度3.4 GHz/4 GB内存)。针对我们分析的目的,我们对数据包中的数据集进行了筛选,筛选的依据为是否有与软件缺陷相关的度量项,得到如表1所示的数据集。

表1 数据集属性
在样本预处理阶段,对所有数据点的属性值进行检测,看是否存在为空的情况,如果存在部分属性值为空的数据点,这部分数据点将会被丢弃,使得剩下的所有数据点的属性值都是不为空。如表2所示。

表2 JM1属性示例

续表2
在对数据集进行分类前,先利用主成成分分析法对其进行属性约减,在保留EC(ERROR_COUNT)属性不变的情况下,将主成分的贡献率设置为90%,依据分析后的结果,将新的数据集作为分类属性用于软件质量的预警分析。
然后我们再依据各数据集中的EC属性的值对数据集的数据进行标记,当EC=0时,我们将这些数据点划分为正常点;当EC>0,我们则将这些数据划分为问题点。为了评估算法的分析能力,我们将本算法与传统SVM算法、BP神经网络算法与隐马尔科夫模型进行同时训练。在此次训练中,我们统一将K值设置为10,M值设置为3,ξn值设为0.3,C取2,g取值0.5。
训练方法为:将各数据集的数据等分成10份,如果不能等分的,对份数进行去尾,如PC1*中数据量为1 107,等分10份其每份数据量为110,数据集中最后7项数据舍弃。然后轮流将10份中的9份数据进行训练,剩下的1份作为分类模型进行分类,也就是所谓的十折交叉验证。
当所有数据都轮回完后,将所有结果进行求均值,该均值作为对算法运算能力的评估值。
为了验证本模型的分析能力,我们针对其分类结果的准确度进行评判,依据EC属性的取值和实际模型的分类结果来了解模型的分类精度:
TP值:TP值是代表数据集中EC属性取值为0,并且模型分析后结果为无质量问题的数据集的数据的个数。
FN值:TP值是代表数据集中EC属性取值为0,并且模型分析后结果为有质量问题的数据集的数据的个数。
FP值:TP值是代表数据集中EC属性取值不为0,并且模型分析后结果为无质量问题的数据集的数据的个数。
F1值:TP值是代表数据集中EC属性取值不为0,并且模型分析后结果为有质量问题的数据集的数据的个数。
依据上面的这4个统计值,我们可以得到以下4个指标:
AC值用来评估正确分类的数据占整个数据集的比重:
(4)
PR值用来评估正确分类的且无质量问题数据占分类正确的数据集(包括无质量问题和有质量问题)的比重:
(5)
RC值用来评估正确分类的且无质量问题的数据占整个数无质量问题的数据集的比重:
(6)
F1值用来表示RC值和PR值得调和平均:
(7)
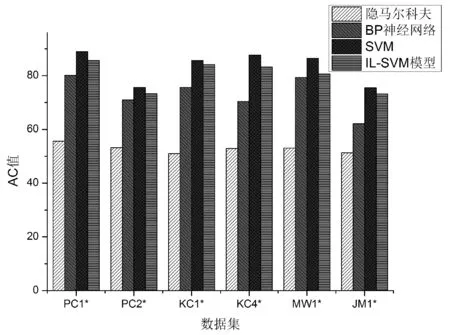
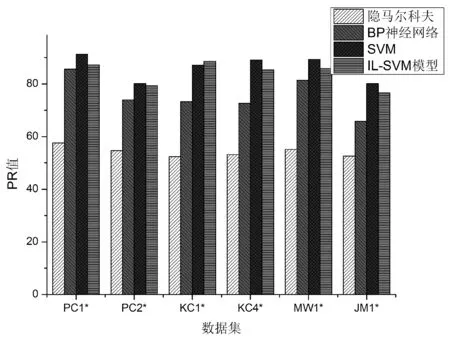
隐马尔科夫模型常用语模式识别,在本实验中将除EC外的其他属性作为显性状态,EC属性作为隐性状态。然而从图4可以看出,其分类效果低于其他三类项目的分类结果,这主要是因为在应用该方法前未对原始数据进行对应的处理。而有些数据的属性值极差较大,并且在观察序列存在一种多重的交互特征形式,观察元素之间广泛存在长程相关性,而且在样本中存在数据分布不均衡性也影响了隐马尔科夫模型的准确性。而基于BP神经网络算法的结果则明显优于隐马尔科夫模型的分类结果,但由于神经网络尚未有一种确定的方法,所以对软件质量难以进行准确的评估。SVM由于只能依据现有的知识进行分类,所以分类效率不是特别稳定。而本模型则在对样本进行分类的同时,积极考虑实验样本中存在的新样本点的存在,从而使得在多次的分类中也具有较优的分类结果。
(a)
(b)

(c)

(d)图4 预测结果图
为了验证本模型在增量训练分析方面的优势,选取PC1、PC2、KC1数据集,将其中的数据进行5等份分类,等量分类后剩余的数据舍弃。第一份数据作为初次训练,后4次的数据集用作增量训练,结果如表3所示。

表3 模型增量学习性能对比分析
从表3可以看出,ISVM在分类精度上略优于IL-SVM,这主要是由于其在选取增量样本集时基本无支持向量的损失,而IL-SVM在选择增量样本集的时候则对其进行了适当的裁剪,导致部分支持向量的丢失。但是从整体而言,虽然IL-SVM的分类精度低于ISVM,但其在分类效率上远远高于ISVM,而且在对比其他几种常用的分类模型:隐马尔科夫模型,BP神经网络时,IL-SVM在分类精度上是优于他们的。并且在实际应用时,可以无需人工加入增量样本集,从实际的分析过程中自主生成增量样本集,模型可以自己根据样本发生的变化进行分类规则的更新,更加切合实际应用的情况。
4 结 语
本文首先针对软件开发项目的开发流程进行分析,结合PCA和IL-SVM,提出了一种可自主进行分类知识更新的软件质量评估模型。该模型不仅利用PCA从属性层次对分类的属性进行了约减,降低了模型的运算量,提高了评估效率,而且针对软件开发过程中的复杂性和多变性提出了一种可自动进行分类知识更新的增量学习算法IL-SVM。该算法通过自主生成增量样本集进行增量运算,更新模型的分类规则,及时的应对软件开发项目中产生的变化,保证在开发过程中对软件进行质量预警的可靠性和稳定性。实验结果表明,该方法具有良好的分类精度,并且在训练效率上也优于传统方法,具有良好的实际应用价值。下一步的研究方向是针对有问题的软件开发项目,找出对应的问题点。
[1] Wang M H, Lee C S. An Intelligent PPQA Web Services for CMMI Assessment[C]//Eighth International Conference on Intelligent Systems Design and Applications. IEEE, 2008:229-234.
[2] 孙子谦, 王雅琴, 黄明明. 戴明循环在敏捷软件质量管理中的应用方法研究[J]. 计算机应用与软件, 2016, 33(11):8-10.
[3] 柴获, 闫军, 李秦渝. 基于置信度的软件质量模糊评价模型研究[J]. 计算机工程与设计, 2012, 33(2):607-611.
[4] Osterweil L J. Software Processes Are Software Too, Revisited: An Invited Talk on the Most Influential Paper of ICSE 9[C]// International Conference on Software Engineering. IEEE, 1997:540-548.
[5] Bansiya J, Davis C G. A hierarchical model for object-oriented design quality assessment[J].IEEE Transactions on Software Engineering, 2002, 28(1):4-17.
[6] Khoshgoftaar T M, Seliya N. Tree-based software quality estimation models for fault prediction[C]//Software Metrics, 2002. Proceedings. Eighth IEEE Symposium on. IEEE, 2002:203-214.
[7] Lyu M R. Handbook of software Reliability Engineering[M].New York: IEEE Computer Society Press and Mc GrawHill Book Company, 1996.
[8] Shaw S E J,Michael S. Target modeling in the POPS optical propogation software[C]//7th Annual Directed Energy Symposium,Rockville,Maryland,2004:610-625.
[9] Kast F E, Rosenzweig J E. General System Theory: Applications for Organization and Management[J].Jona the Journal of Nursing Administration, 1981, 11(7):32-41.
[10] 霍静, 王永明, 顾君忠. 感染性腹泻周发病例数的PCA-SVM回归预测研究[J]. 计算机应用与软件, 2016,33(2):51-54.
[11] Cortes C, Vapnik V. Support-Vector Networks[J]. Machine Learning, 1995, 20(3):273-297.
[12] Santos P, Villa L F, Reones A, et al. An SVM-based solution for fault detection in wind turbines[J].Sensors,2015,15(3):5627-5648.
猜你喜欢
当代陕西(2022年6期)2022-04-19 12:12:22
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
中学生数理化·中考版(2019年9期)2019-11-25 09:39:44
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
数学学习与研究(2017年3期)2017-03-09 18:12:42
电信科学(2016年9期)2016-06-15 20:27:25
