
基于网络爬虫的京东电商平台数据分析
2018-04-16 00:55魏倩男贺正楚陈一鸣
经济数学 2018年1期
魏倩男 贺正楚 陈一鸣
摘 要 以京东平台的网页数据抓取为例,研究如何提高网络爬虫技术对网页数据的抓取效率,进而对抓取到的数据进行数据挖掘和数据分析.该网络爬虫技术主要建立在分布式系统的基础上,多台计算机多线程同时运行,使数据抓取效率显著提高.分析京东平台的网页信息,统一分类,抓取分类下的商品信息,获取到网页内容后,利用解析器重建网页DOM树,通过JQUERY选择器,针对选择不同的标签名称和标识名称获取商品信息,把获取到的数据进行过滤、整合,然后进行数据挖掘和数据分析,对电商行业走势进行预测,进而指导电商运营团队决策.
关键词 电商平台;数据分析;分布式系统;AJAX;MapReduce;Jumony Core
中图分类号 F424,F716,F724.6文献标识码 A
Abstract Taking the data web Jingdong platform as an example, this paper researched how to improve the efficiency of data capture of web crawler technology, and to crawl into data for data mining and data analysis. The crawler technology is mainly built on the basis of distributed system, and multiple computers run simultaneously at the same time, so that the efficiency of data capture is significantly improved. After analyzing Web information, Jingdong platform unified classification, grasping under the category of commodity information, and the access to web content, DOM tree was reconstructed by using parser, and through the JQUERY selector, different commodity information was selected according to the label name and logo name, and the obtained data was filtered, integrated, and then data mining and data analysis were carried out to predict the trend of the e-commerce industry, and then to guide the decision-making of the e-commerce operations team.
Key words electronic business platform;data analysis;distributed system;AJAX;MapReduce;Jumony Core
1 引 言
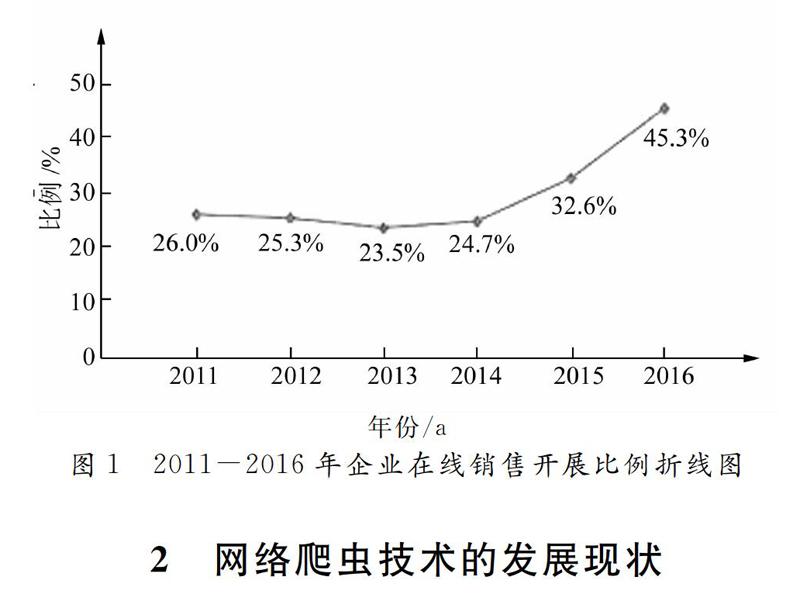
2017年1月,中国互联网络信息中心(CNNIC)发布第39次《中国互联网络发展状况统计报告》,根据报告显示,截至2016年12月,中国网民规模相当于欧洲人口总量,高达7.31亿,全年新增网民共计4229万人.互联网普及率达53.2%,较2015年底提升了2.9个百分点.其中在商务交易应用类发展方面,截至2016年12月,中国有99.0%的企业使用计算机办公.在电子商务方面,开展在线采购、在线销售的比例分别为45.6%和45.3%,大约有38.7%的企业利用互联网开展营销推广活动.中国的互联网行业整体向价值化、规范化的方向发展,同时,移动化联网推动了共享化、设备智能化和场景多元化的消费模式[1].
图1为CNNIC中国互联网络发展状况统计调查结果.图1显示截至2016年12月全国有45.3%的企业开展在线销售业务.“十二五”期间,中国电子商务市场发现迅速,交易额翻了两番.2016年,“十三五”的开局之年,电子商务市场规模的增速依然保持稳定,企业的参与程度越来越深入,开展在线销售的企业数量也大幅增加.随着企业对品牌推广意识的提升、电子商务的日益普及,以及中国互联网的广告市场逐步规范化,互联网的营销市场仍然有很大的增长空间.但是近几年来电商行业的各大网站为抢占市场经常采取的策略是打价格战,纷纷通过促销、甚至降价等方式来吸引客户.据KPCB的调查报告显示,2009年到2016年全球移动端新用户的增长率持续下滑,可以预测在2017年这一增长率将继续放慢,用户增长将更加乏力,这就意味着人口增长带来的流量红利正在逐渐消退.那么,单纯地通过价格战来吸引新用户的方式已不容乐观.严峻的市场竞争形势迫使企业思考,在不依靠价格战这种野蛮增长的方式下,当企业面临增长困境,该如何应对?2017年11月在北京举办的“第三届中国行业互联网大会”为这一问题指出了解决思路,即在互联网时代下“新动能,新模式”将助推企业转型升级,优化要素配置,促进新经济转型.因此,对电商平台来说,数据是电商分析问题的基础,面对不断增长的海量信息,如何高效的获取数据、挖掘信息是电商企业精细化运营和数据驱动决策中亟待解决的问题.网络爬虫技术在电商信息来源方面和其他领域都有很广泛的应用.
2 网络爬虫技术的发展现状
随着Internet规模的不断扩大的和Internet技术的迅速发展,Web信息量呈指数增长,数据呈现出数据量大、种类多、实时性强、价值大等特点,大数据的应用已经蔓延到各个领域[2].数据挖掘是从海量数据中寻找其规律和联系的技术,是统计学、数据库技术和人工智能技术的综合.目前,在数据挖掘的领域范畴中,相关研究机构(如:Google、百度等)已经给出了较为成熟稳定的大型网络爬虫解决方案,由于涉及商业化利益和机密,相对成熟的搜索引擎技术不会被公开化,网络中的相关资源也只是肤浅的描述和概括,而且这些方案大都只能为一般用户提供一种不可定制的搜索服务,大部分公司并不提供相关的技术方案支持.开源在网络爬虫方面,也已经有一些相对成熟的网络爬虫项目,但很多并不能被广泛采用,并且可能会存在一些问题,如:不穩定、体验效果差、配置繁琐等.在开源爬虫项目中,大部分都是单机版的,无法应用于海量数据的采集等其他情况,因此,针对电商平台研究出一套配置简单、稳定性强、效率高的爬虫是很必要的.
网络爬虫追求的方向是如何尽可能及时、全面、有效地获取互联网上的数据索引,主要包括以下方面的研究:发展大规模分布式系统、提高系统的性能[3].一是分布式系统有效地推动了搜索引擎技术的发展.搭建一套扩展性强、性能稳定、成本低廉的分布式集群系统,多台机器并行运算,可以有效地解决多个网间访问速度过慢对网页信息获取的影响,加快数据的计算速度,提高网络爬虫的性能[4];二是网络数据抓取内容越来越多元化.人们对网络资源的需求不仅仅是单纯的文字,需求正朝着多元化的道路发展,例如,视频搜索,图片搜索以及各类文档搜索,因此网络爬虫面对这些也应该能够准确的解析并且准确的获取;三是更多的个性化服务.当前抓取内容需要具备个性化搜索,人们关心的并不是所有的电商平台网站和其他品类网站,而只是满足自己所需要的一些电商网站等站点,因此就需要网络爬虫有针对性的去获取,不同的站点对应不同的权值;四是AJAX数据获取[5].AJAX框架有大量的表现层代码,由于网络和其他的反爬虫因素在一定程度上降低了网络爬虫的效率.因此,开展支持AJAX框架站网络爬虫的研究,对解决AJAX站点地址(URL)获取以及检索隐藏在其中大量数据的问题,具有重要的理论意义与实用价值[6].
事实上,在网络爬虫领域,学术界以及商业界都已有一些研究,其中包括:网络爬行策略、海量数据存储方式、海量数据索引方式、网页评级分类等.随着网络信息资源的快速增长以及网络信息资源动态的变化,传统的爬虫技无法满足人们对个性化服务的需求,以何种方式访问网络,提高爬虫效率,已成为近几年来网络爬虫研究的主要问题之一.但大多数研究仅着眼于某一个方面的改进,因此对于一个完整的爬虫系统来说,或多或少的会存在着某些不足.本文在已有研究成果基础上,设计一个高效可行的网络爬虫方案,进而对爬取到的数据进行数据分析和数据挖掘,为企业决策提供指导.
本文主要基于MapReduce分布式系统实现了网络爬虫在电商中的应用,提高了网爬虫性能,加快页面信息获取速度[7].针对海量信息无法存储的问题,采用非结构化分布式存储技术,它是一种全新的非关系型的分布式存储技术,采用新的数据模型,具有海量数据存储、高性能、高可用性、强伸缩性等特点,可以有效地解决数据存储的问题.针对页面通过AJAX异步请求获取后台数据,呈现到网页信息无法获取的问题,采用Selenium技术,它可以通过调用浏览器的方式,加载页面自身内容和通过AJAX异步请求展现的内容,完全加载后,Selenium可以获取到所有页面内容,Selenium还可以模拟鼠标单击、双击、右击等一些操作,解决隐藏数据无法获取的问题[8].
3 相关理论基础
3.1 MapReduce
MapReduce是Google在2004年提出的一个用于处理大规模数据集合的分布式计算架构.该构架的提出是由编程函数中常用的Map,Reduce函数启发结合而来,通过这个架构,可以帮助对分布式计算不太了解的程序员完成分布式计算程序的编程,实现对问题的分解与合并[9].
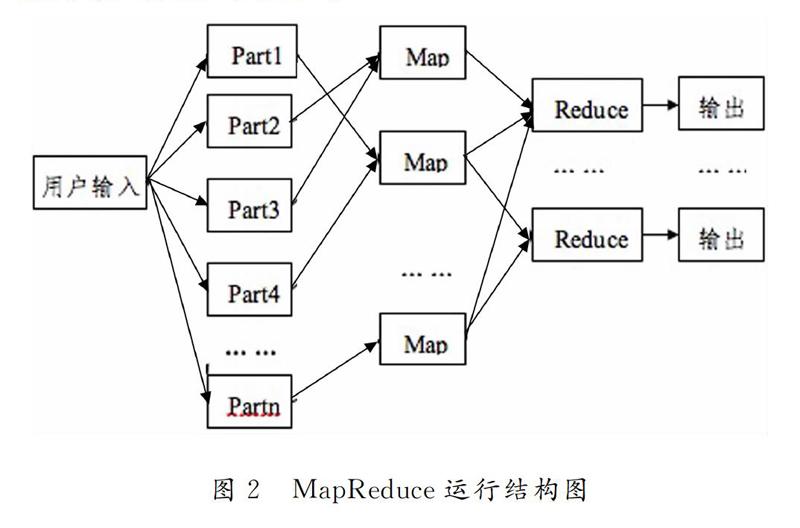
分布式计算是将整个任务先分割成很多小的子任务到子节点处理,再将子节点处理得到的结果进行合并整理,获取最终结果[10].在MapReduce的执行任务的过程中主要分为Map和Reduce两个步骤:当用户输入一条指令后,Map程序首先把任务分割成不相关的小任务块,这些小的任务块会被分配到不同的计算机进去处理,得到的结果通过Reduce程序整合.MapReduce的一般运行结构如图2所示.
“Map”过程:Master节点接收到输入的数据后会将数据分割成许多小的数据块并把它们分给不同的Worker节点.Worker节点可能会再次重复上面内容;或者Worker节点调用用户自定义的函数,将处理得到的键值数据对写入到本地磁盘中.
“Reduce”過程:在Worker节点上执行Reduce函数,整理Map函数处理好的全部数据,把键名相同的数据通过用户提交的指定的方法合成不同的数据集合,保存到磁盘中.
3.2 AJAX
Ajax并不能说是一种新的研发技术,而是提取的Java、XML与JavaScript等技术的特点,创建了交互式网页应用的Web开发技术,其中包括这些技术:使用HTML和CSS定义呈现给用户的页面内容和媒体信息;使用DOM实时动态修改页面显示内容和加载效果;使用XML和XSLT进行数据交换获取和结构化处理;使用XMLHttpRequest方法进行异步数据的查询和获取;使用JavaScript绑定和处理以上部分.
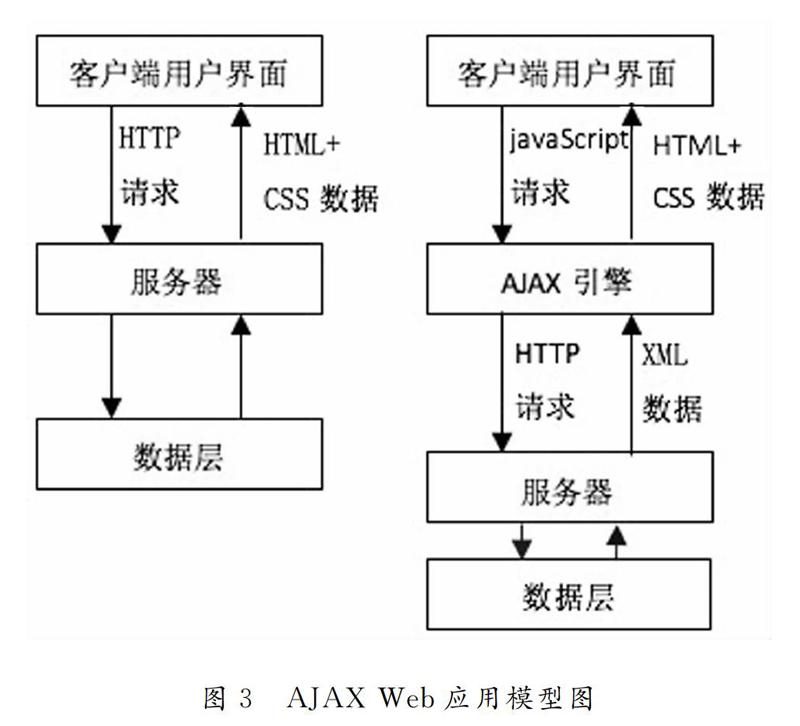
AJAX Web应用模型如图3所示.
客户端与Web服务器之间增加了Ajax引擎,客户端接口与Ajax引擎交互,而Ajax引擎再通过HTTP传输协议与Web服务器端交互.Ajax Web应用采用了异步交互模式,比传统的Web应用体验效果更佳,更加受用户的喜爱,有5个方面的优点[11]:①Ajax能在不刷新整个页面的前提下更新页面信息和页面数据,网页加载的速度更加快速,用户等待页面加载的时间更短.在等待服务器响应的过程中,用户可以在已加载页面进行任何操作,缩短可感知时间.②通过异步调用模式,可以带来更好的用户体验,用户可以更加直观感觉到丰富、动态的页面内容.③Ajax采用的原则是“按需按量取数据”,可以最大程度的减少冗余请求和大量数据的一次性加载,优化服务器和客户端的传输,从而提高网络带宽的利用率,减轻服务器负担.④Ajax不但可以调用本地资源,还可以加载外部数据,非常具有灵活性.⑤Ajax技术应用非常简单,没有任何插件和程序的安装,操作简单,能被开发者广泛支持.
3.3 Jumony Core
Jumony Core是一个非常真实的HTML引擎.目前的HTML解析器加上简单的正则表达式已经可以满足用户操纵HTML文档的需求,但对于Jumony Core,它更加强大.Jumony Core解析结果和浏览器的解析结果相似度非常高,无论是无结束标签的元素,可选结束标签的元素,或是标记属性,或是CSS选择器和样式,一切合法的,不合法的HTML文档,浏览器解析成什么样式和内容,Jumony Core出来的效果几乎和浏览器一样.Jumony Core包含的封装方法及作用如表1所示.
4 本研究对爬虫技术的设计
4.1 设计思想
目前,爬虫在抓取数据上,一般采取两种策略:广度优先策略与深度优先策略[12].广度优先是指爬虫沿着树进行横向遍历,直到抓取完起始网页中连接的所有网页为止,然后再选择其中的一个网页链接,循环这个过程.此方法可以让爬虫并行进行,提高了抓取速度.深度优先是指爬虫沿着树进行纵向遍历.深度优先策略是一个递归的过程,因此在程序执行的时候会大量消耗计算机的内存,很容易使爬虫陷入问题,甚至是电脑死机.另外,递归与多线程是无法兼容的,因为多线程可以一次运行多个任务,但每个线程都要有自己的堆栈.而在递归时,当一个方法调用它自身时,它们需要使用同一个堆栈.因此,本爬虫程序采用广度优先策略.具体实现方式为:首先,统一不同电商平台的分类信息,通过比较判断找出不同电商平台的公共分类信息,分类信息还分为一级分类和二级分类,一级分类下面包含多个二级分类;其次,整合所有二级分类,获取所有二级分类所对应的商品列表URL,初始化URL,直到对应的URL没有商品为止;最后,把获取到的产品信息存储到数据库,存储到数据库中的数据经过清洗过滤得到标准化的数据,然后进行数据统计分析,从而把握电商行业的销售趋势.图4为本程序对商品数据获取及保存示意图.
4.2 操作流程与实现
图5清晰地展示了程序的主要流程.收集网络中不同的电商平台进行分析对比,获取不同电商网站针对的不同分类的侧重点,对于相似的分类,可以关联分类后统一化名称.对于每个分类下面的商品,需要不断的初始化对应URL,从而获得不同分页下面的商品信息,获取商品信息的时候,对信息不完整的商品进行舍弃.在数据整理的时候,过滤不符合规则、异常的数据.
4.3 统一分类
当前网络电商平台众多,其中国内比较知名的主要有淘宝、天猫、京东等,但这些电商平台的一级分类和二级分类,甚至更深层的分类错综复杂[13].把这些电商平台的所有分类整合,挑选出其中具有代表性的一级分类,在一级分类的决断中,尽可能的要包含人们生活的各方面.对于二级分类的确定,通过与一级分类的关联度和常识去决定.最终,可以得到基于不同电商平台下的一套相对统一的标准化分类.
4.4 初始化URL
不同电商平台的二级分类下面可能会有更细的小分类,但不是商品列表,要尽可能完整的获取到所有分类下面的信息就需要把这些更小的分类下面的商品列表对应的URL也存储到数据库,这些小的分类应该与其父级分类建立关联外键.每个URL对应的商品列表只有一页,一般要想获取更多的页面列表就需要改变URL中对应页码的数值.尚待访问URL队列可以被构造为一个先进先出(FIFO)队列,信息搜索的下一个将要爬行的页面来自队列头,新的URL被加入到队列尾.每一步都是从队列头中选出下一个URL供爬虫抓取,直到爬完此队列中所有URL为止.
4.5 页面信息提取
在提取页面信息时,首先必须先判断页面的编码方式,目前的字符集种类非常多,其中主要以“UTF-8”,“GBK”,“GB2312”为主,具体可以在网页头部可以看到,例如:.在读取页面内容时,先要判断获取内容的类型,如果是多媒体数据,则可以下载存储到网页数据库中,如果是无结构或半结构化的网页文本,则需要继续分析.在获取URL页面内容时,如果出现超时、页面丢失、获取错误等现象时,就认为此网页失效,对应的URL就被存儲到相应的错误列表中,如果能正常获取,则需要解析网页内容.
4.6 解析页面内容
网页解析主要是内容分析和链接提取.获取页面内容后,根据页面内容去解析提取所需要的信息,并通过标签,CSS名称或者标签ID获取目的标签路径.一般情况下,元素会包含很多属性,其中具有唯一性的属性就是元素的ID,这样能更快更精确的找到需要的内容,其次就是元素的CSS名称,CSS名称可以存在有很多,可以通过下标或者结合元素其他属性来准确获取,最后就是通过元素的标签获取,一个页面内容会包含很多这样的标签,想确定唯一想要的就要逐步的查找该元素的父级,通过不同的父级元素来获取唯一的子级元素.获取到的元素内容文档可以提取到如下信息:
1)文档标题:通过文件头标签
2)商品链接:链接一般都是元素里面的属性“href”的值,通过链接可以得到商品的详情页面,获取更多的商品信息.
3)商品标题:商品标题一般可以在两个地方获取,第一,商品列表中有标题的信息,第二,在商品详情页面中可以获取商品的标题信息.
4)图片:电商平台中商品几乎都是存在图片的展示,图片的信息可以通过命令符或
5)多窗口页面:通过命令符
各种电商平台信息采集最直接得到的就是以上4个方面获取标记,并作相应的处理.其中文档标题,商品标题这些可以直接从当前网页中获取,其他通过URL相关的信息则需要记录URL并标记,从而进行更深一步的采集.
电商平台采集主要是获取关于每个商品的详细信息,其中包括商品标题,商品ID,商品的价格,商品的发售地,商品的月销量,商品的评论数甚至商品的评论,还有当前商品的店铺名称,店铺ID,店铺链接,店铺信誉(评分)都要获取到,这些信息有的并不能在网页内容中直接获取,例如,在京东商品详情页里面,店铺的地址,评分等一些不能直接在网页内容中找到,有的要更加深一步的找到相关的URL,通过再次解析网页内容的方式获取.还有的就更加复杂,这些信息在新的页面也不能够找到,这时候就要查找当前页面所有的JS文件,看是否能够在JS文件中获取所需要的信息,然后找到相关此JS文件的路径进行分析,看和其他商品的此路径有什么不同,找出规律,拼接成相应的URL地址来获取内容.
4.7 程序实现
电商平台数据采集建立在分布式系统上,计算机集合通过通讯网络相互连接,实现资源共享和协同工作,而呈现给用户的是单个完整的计算机系统,分布式系统与面向对象技术相结合过后,极大的扩展了分布式软件的应用领域,提高了软件的性能和生产效率.程序使用的开发程序主要有Visual Studio和SQL SERVER.电商平台采集数据量非常庞大,需要定义多线程或线程池来加快程序的运行速度.这里主要以京东为例.首先在程序中定义一个线程,线程执行需要一个无返回(void)方法,在这个线程中定义所要执行的方法,名称定义尽量规范,方法里面是关于电商平台采集的主要编程代码.
1)获取分类URL:获取SQL SERVER中存儲的二级分类对应的所有URL,声明一个表格(DataTable),把所获取到的URL存放到表格当中.为避免重复的用到SQL SEVER增删改查的一些方法,在程序中新建一个类,这个类中定义了一些基本的SQL SEVER增删改查的方法,对应的代码填充完毕后,每次需要用到这些方法得时候,可以直接通过类名和相应的方法调用,如表2所示.
2)循环商品列表:循环表格里面的URL,获取并解析里面的内容,找到本页面所有的商品集合,通过URL的规律,找到下一页(page=1,2….),直到获取此分类中的所有商品.
3)获取商品信息:获取商品集合后,通过选择器得到相应商品详情页的URL,在商品详情页里面,把剩下所需要的信息提取出来,提取信息的各种方法如表3所示.
4)存储到数据库:得到所需要的信息,通过定义的SQL方法把得到的数据存入数据库.
在商品信息的获取过程中,会出现很多不规范的商品信息,在程序运行过程中,无法解析网页内容时,程序就会停止并抛出异常信息.此时就需要手动去处理这些异常,而人工处理的效率非常低,因此添加异常处理是必不可少的,一般情况下,都会舍去这些不规范的商品.当一个商品信息获取完毕时,开始执行保存到数据库的操作,在保存数据库之前,需先判断数据库中是否已经包含此商品,在数以万计的商品中,免不了存在非常多的重复商品.对于带有AJAX和JavaScript的动态网页,通过模拟鼠标事件来获取相应信息.
5 网络爬虫技术的应用
事实上,越来越多的电商运营团队已意识到精细化运营和数据驱动思维已经成为电商自身增长日益重要的因素[14-18],所以一个能高效率的网络爬虫对一个电商平台进行数据挖掘有效信息而言是非常重要的.因此,本文主要建立在分布式系统的基础上,多台计算机多线程同时运行,对京东平台的商品信息进行抓取.通过对获取信息的整理、分析,对京东电商的发展形势进行把握.基于以上介绍对京东电商平台信息获取的运行界面如图6所示.
图6界面简洁,信息框显示程序正在获取的商品信息.当点击开始时,所有线程开始工作,每个线程都有唯一的标识名称,不同线程分配不同的分类任务,获取的内容信息也不一样,图6信息框显示程序运行时商品信息一些展示,其中包括商品标题,商品所属分类,线程标识以及商品的型号,当某个商品信息不规则或者信息获取不符合要求时,程序就会自动提示异常,丢弃此商品.当点击暂停时,所有的线程都会停止工作,多线程提高了商品信息获取的效率.
通过本程序获取到了京东电商平台的各类信息,其中比较重要的有月销售量、价格、产品的一些重要属性.通过获取每个月所有产品的总销量,总销售额,通过统计分析计算,预测下个月电商行业景气度指数,结合前端HTML,CSS和JavaScript技术,把结果进行图形化处理,更加直观清楚的看到电商景气度的变化趋势,如图7所示.
根据图7电商景气度指数折线图显示,京东电商景气度大体上呈上升趋势,虽然在上半年有过几次波折,但是总体来看是在曲折中上升的,尤其后半年电商景气度走势大致已经趋于稳定,该分析结果可以在运营团队进行决策时作为参考资料.
进一步地,分别筛选出一级类目和二级类目数据,可以对不同分类产品进行分析,获取更详细的信息,如图8所示.
根据图8电商类目销售趋势显示,实线部分展示了护肤彩妆行业近一年的销售量和销售额的趋势变化情况.虚线部分展示了对护肤彩妆行业未来一个月的销售量和销售额进行预测的结果,结果仅供参考.同样的,运用网络爬虫技术可以获取其他行业类别的不同信息,然后对获取到的信息进行清洗、整合等标准化处理后,建立不同的数据挖掘模型,获取有效信息指导企业决策.
6 结束语
随着电商平台信息资源的快速增长以及商品信息资源动态的变化,传统的爬虫技术无法满足对海量信息及时获取的需求,以何种方式访问网络,提高爬虫效率,已经成为近年来数据挖掘研究领域的主要方向之一.因此,本文采用多线程的网络爬虫技术对京东平台资源信息进行采集和提取,把整个京东平台的产品信息集成为一个数据仓库,进行数据挖掘和数据分析,获取有用的信息以提供完善的实时监控和精细化运营策略.基于MapReduce技术并行加载页面,多个页面内容同时采集,针对调用JavaScript所展现出的内容,通过Selenium技术模拟浏览器打开相应网址,等待JavaScript执行完毕后再获取页面内容,对于带有分页的页面,Selenium可以模拟鼠标单击指定元素达到翻页的效果,页面加载完毕后再次获取内容,直到获取最后一页内容为止.
在电商行业飞速发展的时代,搜索引擎不断更新,电商平台不断完善,电商平台数据的获取面临挑战.电商平台商品的重要数据的不公开,对网络爬虫的访问限制成了获取数据的主要难题.在以后的研究中,会尝试通过代理IP、控制访问速度、寻找真正的JavaScript地址等方式解决上述问题.(本论文特别感谢课题组成员楚少波、杨艳艳等同志的协助与支持)
参考文献
[1]中国互联网络信息中心.中国互联网发展状况统计报告[R].中国互联网络信息中心,2017.
[2]李志义.网络爬虫的优化策略探略[J].现代情报,2011,31(10):31-35.
[3]李代祎,谢丽艳,钱慎一,吴怀广.基于Scrapy的分布式爬虫系统的设计与实现[J].湖北民族学院学报(自然科学版),2017,35(3):318-322.
[4]ZHONG S J,DENG Z J. A Web crawler system design based on distributed technology[J].Academy Journal,2011,6(12):1682-1689.
[5]楊俊峰,黎建辉,杨风雷.深层网站Ajax页面数据采集研究综述[J].计算机应用研究,2013,30(6):1607-1616.
[6]张升平.Ajax在优化Web系统中的应用[J].通信技术,2009,42(2):286-288.
[7]孔涛,曹丙章,邱荷花.基于MapReduce的视频爬虫系统研究[J].华中科技大学学报(自然科学版),2015,43(5):130-132.
[8]岳雨俭.基于Hadoop的分布式网络爬虫技术的设计与实现[J].网络通讯及安全,2015,11(8):36-38.
[9]赵辉,杨树强,陈志坤.基于MapReduce模型的范围查询分析优化技术研究[J].计算机研究与发展,2014,51(3):606-617.
[10]吴黎兵,柯亚林,何炎.分布式网络爬虫的设计与实现[J].计算机应用与软件,2011,28(11):177-213.
[11]胡晟.基于网络爬虫的Web挖掘应用[J].软件,2012,33(7):145-147.
[12]岳雨俭.基于Hadoop的分布式网络爬虫技术的设计与实现[J].网络通讯及安全,2015,11(8):36-38.
[13]李也 贺正楚 , 潘红玉.基于众筹商业模式的中国动漫产业培育研究[J].东莞理工学院学报,2015,22(2):69-74.
[14]贺正楚,黄颖琪,吴艳,等.跨境电商发展的制约因素、优势及措施--兼以湖南为例而论[J].长沙理工大学学报(社会科学版),2016,31(5):115-121.
[15]吴艳.战略性新兴产业的评价与选择[J].科学学研究,2011,29(5):678-683,721.
[16]贺正楚,张训,周震虹.战略性新兴产业的选择与评价及实证分析[J].科学学与科学技术管理,2010,31(12):62-67.
[17]贺正楚,潘红玉.中国制造业跨境电商发展面临的问题及对策[J].求索,2017(6):129-135.
[18]贺正楚, 黄颖琪, 吴艳.制造业电子商务发展面临的问题及其对策[J].地方财政研究,2016(6):9-18.
猜你喜欢
商场现代化(2016年26期)2016-11-21
商场现代化(2016年22期)2016-10-18
