
面向用户的电商平台刷单行为智能检测方法
2018-04-12 05:51康海燕于爱民
计算机应用 2018年2期
康海燕,杨 悦,于爱民
(1.北京信息科技大学 信息管理学院,北京 100192; 2.中国科学院 信息工程研究所,北京 100093)(*通信作者电子邮箱kanghaiyan@126.com)
0 引言
随着电子商务行业的迅猛发展,网络购物逐渐成为一种新的生活方式,但电商行业的恶性竞争也愈演愈烈。2016年的3·15晚会上曝光的购物平台疯狂刷单现象[1],揭露了时下电商平台恶性竞争的不良后果。所谓“刷单”是指网店经营者雇佣专业从事网店信誉提升的刷单平台或网站,模拟真实的网购流程,仅有货款往来,不进行商品的收发,以提高店铺的信誉度和销量,实现流量价值转换。电商刷单具有一定的隐蔽性,因此活跃在法律的灰色地带,对经济秩序造成了严重威胁。但由于电商业务尚在发展之中,各种约束规范都不完善,所以电商平台的刷单问题暂时很难通过法律制度得到有效解决,刷单之风盛行所带来的不良影响体现在各个方面。
为了解决刷单所带来的信誉安全问题,淘宝和京东一直致力于刷单检测系统的开发和完善。文献[2]介绍了京东商城的“天网”系统,目前已全面覆盖京东商城数十个业务节点,有效支撑了京东集团旗下的京东到家及海外购风控的相关业务,保证了消费者的利益和京东的业务流程。京东反刷单系统从订单、商品、用户、物流等多个维度进行统计,分别计算每个维度下的不同特征值,能够较精准识别刷单相关的恶意行为。文献[3]详细介绍了淘宝后台检测刷单的第三代稽查系统,主要包括机审和人工审核两方面。机审的判定顺序为:判断点击过滤(pmcots防恶意点击系统)→判断交易(ctu支付宝智能实时风险监控系统)→检索订单数据(数据检索系统)→结果判定。先根据计算机本身的物理信息来判断,再根据各个检测维度判断订单是否在正常范围内,综合考虑判定商品是否有刷单嫌疑。机审主要依靠三大检测系统:CTU(支付宝智能实时风险监控系统)、pmcots系统(防恶意点击系统)和数据检索系统。CTU是支付宝风险管理的一个核心系统,基于用户行为来判断风险等级,集风险分析、预警、控制为一体,并配备风险稽核专家小组进行风险稽查及处置,进行全天候风险监控。pmcots系统主要考核的是流量环节,检测技术包括IP防止作弊、Netclean防止作弊,点击率对比,唯一参数识别(如MAC、硬盘序列号、浏览器版本、系统UI等),分析流量来源和流量构成,考察点击时间参数有效性、物流信息真实性,进行浏览时间和深度比对,记录鼠标值以检测刷单软件。数据检索系统是从索引数据库或存储数据中查找和选取所需数据的过程。对于稽查系统难以判断的订单进行人工排查得出最终结果,店家可申诉,申诉后即可进入人工判定阶段,通过查看商品评价内容、买家信息等进行判断。
综合分析当前电商平台所研发的检测刷单系统,均为后台封装系统,检测结果对消费者不公开,无法对用户网购提供直接的参考。所以在电商行业和立法部门对于刷单行为的努力遏制的同时,作为刷单现象的直接受害者——网购群体也需要有一个自行判别刷单行为的第三方工具,以此降低刷单对于消费者所造成的财产损失。本文主要工作有:1)提出了面向用户的电商平台刷单行为智能检测方法SVM-NB,该方法能定量计算出商品信息的可信度,有很强的说服力;2)提出了构建刷单特征值方法;3)通过K折交叉验证算法验证了SVM-NB方法的合理性和准确性,实验条件下计算结果的准确率高达95.053 6%,并与相关工作进行了对比。
1 关键技术
1.1 支持向量机
本文提出的面向用户的电商平台刷单行为智能检测方法SVM-NB采用支持向量机(Support Vector Machine, SVM)[4-6],基于有监督学习,通过多次训练得出训练点和类别之间的对应关系,以便判断待测点所对应的类别,它在解决小样本、非线性以及高维模式识别中表现出许多特有的优势。
设X为N维输入空间的训练向量,令Φ(X)=[φ1(X),φ2(X),…,φM(X)]表示从输入空间到M维特征空间的非线性变换,Φ(X)称为输入向量X在特征空间诱导出的“像”,并且可在该特征空间构建一个分类超平面,数学公式[7]如下:
(1)
其中:wj为将特征空间链接到输出空间的权值;b为偏置。
其拉格朗日函数为:
(2)
其中:拉格朗日系数αp≥0,第一项为代价函数(W),第二项非负。
(3)
最优判别函数为:
(4)
1.2 爬虫技术
网络爬虫技术是一种“自动浏览网络”的程序,从一个或若干个初始网页的URL开始,不断从当前页面上抽取新的URL放入队列,直到满足系统的停止条件结束。爬虫技术工作原理:1)首先将当前用户搜索的网页URL放入待抓取URL队列;2)从待抓取的URL队列中取出URL,下载对应的电商网页,存入已下载网页库中,并将这些URL放入已抓取URL队列;3)从已抓取的URL队列中抽取新的URL进入下一个循环。
2 SVM-NB方法
SVM-NB方法的流程如图1所示。
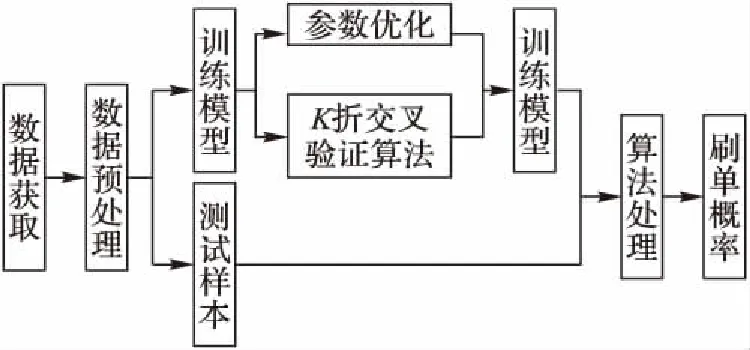
图1 SVM-NB方法流程Fig.1 Flow chart of SVM-NB method
具体步骤如下:
1)数据获取阶段。
第1步通过文献查询、商家调研和网页爬虫三种方式对不同行业的典型商品建立原始数据库,包括单一商品与行业数据的正常数据和异常数据(即疑似刷单的店铺商品数据)。
第2步用户有两种方式来查询商品:一种是地址输入,即在网页地址搜索框输入目标商品的网页地址,确认查询,系统后台根据用户输入的网址以及选择的时间段,自动获取目标商品的页面、类别、商品信息等;另一种方式是在当前商品页面查询商品名称或者编号,若数据库中存在该商品信息,则可以直接从数据库获取,否则只能采用第一种方式来查找商品。
第3步系统后台先在数据库中查询该商品是否被检测过。若未检测过,则通过网页爬虫技术和数据库查询,获得其原始数据(特征量包括访客数、咨询数、付款数、订单数、收藏数、点击次数、买家ID、下单时间、确认收货时间、付款时间、店铺停留时间、交易时间、IP地址信息),存入数据库对应表中。
2)数据预处理阶段。
第4步将刷单和不刷单两类商品的原始数据进一步计算,转化为特征率值,记入初始特征向量集。
第5步对行业的初始数据作同等处理,建立特征值数据库。
第6步将优化后的特征数据项进行归一化处理,去除极端数据。
3)训练模型阶段。
第7步将经过预处理的两类数据格式转化成SVM分类器可接受的输入格式(类别向量Y,特征向量Xi),作为训练样本对分类器进行训练。
第8步设置SVM参数,并利用K折交叉验证算法寻找最优参数。
4)算法处理阶段。
第9步将用户输入的目标商品特征值作为测试样本输入SVM分类模型中进行分类判断。
5)输出结果阶段。
第10步将SVM算法得出的分类结果代入朴素贝叶斯公式中得出刷单概率,将最终结果反馈给用户,并将结果记录到数据库中,定期更新数据库,同时给出同类商品在不同店家中的检测结果以供参考。
2.1 数据获取
电商平台刷单行为智能检测系统数据获取主要采用了三种方法:商家调研主要是对淘宝和京东平台上的电商采集其商品的销售情况以及店铺的信誉度等信息;网络爬虫则是利用爬虫技术从商品基础信息页面进行信息的收集;文献查询主要是通过中国知网等电子论文库和线下纸质书籍来搜集刷单检测的相关信息。通过这三种方法获取到刷单检测的原始数据分为两种类型:店家原始数据和单一商品原始数据,分别如表1和表2所示。
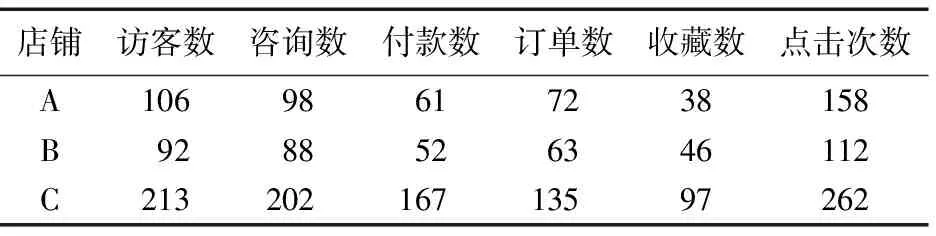
表1 店家原始数据表Tab. 1 Raw data of store
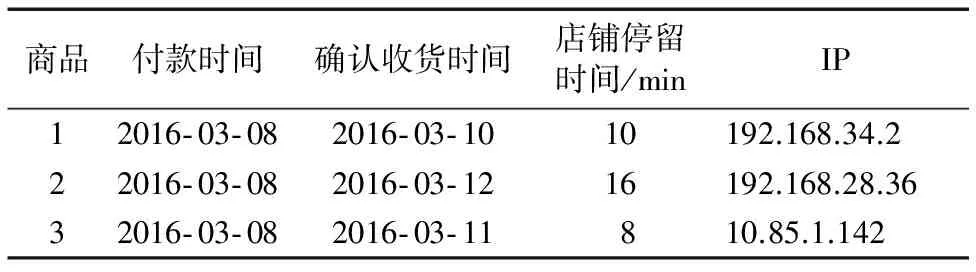
表2 单一商品原始数据表Tab. 2 Raw data of single commodity
2.2 数据预处理
2.2.1构建刷单特征值方法(率值计算)
通过数据获取的三种方法所得到的原始数据包括:访客数、咨询数、付款数、订单数、收藏数、点击量、确认收货时间、付款时间、店铺停留时间、IP地址信息,其中部分初始数据需要经过进行率值计算,经过初步转化构建出刷单特征值,即得到输入算法的特征向量的值,如表3所示。
2.2.2归一化处理
将经过初步转化的特征值进行归一化。由于采集的特征项的数据单位不一致,需要将有量纲的表达式化为无量纲的表达式,成为纯量,因而须对数据进行归一化处理。率值需要归一化到区间[0,1],数值需要归一化到区间[-1,1]。归一化处理的目的:一是为了算法处理过程中更加方便,二是为了加快训练网络的收敛。归一化计算公式如下:
y=(x-MinValue)/(MaxValue-MinValue)
其中:x、y分别为转换前、后的值,MaxValue、MinValue分别为样本的最大值和最小值。
2.3 模型训练
本文采用了SVM的模式识别与回归的软件包(LIBSVM)[7]。算法数据计算过程如图2所示。

图2 SVM计算过程Fig. 2 Computation process of SVM
训练数据和测试数据格式为:
如:01:47.562:89.553:35.124:33.515:60.096:32.017:58:9.319:15
其中:
SVM_train实现对训练样本的训练,获得SVM模型。
SVM_NB则根据训练获得的模型对数据集合进行分类结果的预测。
利用SVM_train实现对输入的训练数据集的训练,获得SVM模型文件。SVM算法将输入的每一个训练样本,即n维向量映射到高维空间中,形成多个散布的点,并通过点的聚集区域模拟分类超平面,并且不断利用新输入的训练样本数据进行修正,最后生成模板文件,记录分类特征[9]。

表3 原始数据项率值计算表Tab. 3 Conversion instructions of raw data item
本文采用著名的K折交叉验证方法,通过验证结果的准确性来得到最优参数。验证算法的主要思想是将数据集A分为训练集(training set)B和测试集(test set)C,在样本量较少时,可以将数据集A随机分为k个包,每次将其中一个包作为测试集,剩下k-1个包作为训练集进行训练。交叉验证方法主要用于防止模型过于复杂而引起的过拟合现象。经过不断地变换SVM的两个重要参数:惩罚因子C和核函数参数g,确定了最优参数为:C=2 048,g=0.007 8,能够为用户提供更为准确的购物参考[8]。
2.4 算法处理
2.4.1处理过程
输入x={a1,a2,…,am},y={y0,y1},x表示测试样本中每一个商品的特征项集合,y表示类别0和1的集合,分别表示未刷单和刷单;
输出商品的刷单概率p。
Begin
//1)~8)为SVM算法过程,9)~13)为朴素贝叶斯算法
1)
对特征项集合进行归一化处理
2)
将数据格式转化为分类器可接受的输入格式(类别向量Y,特征向量Xi)
3)
设置SVM类型0-SVM,核函数类型为RBF
4)
设置惩罚因子C和核函数参数g
//如C=2 048,g=0.007 812 5
5)
设置K折交叉验证算法的K值
//如K=5
6)
利用SMO求出支持向量
//SMO算法用于优化对偶问题中的二次规划,求出
//优化至收敛的Lagrange乘子向量作为支持向量代入算法
7)
利用训练样本构建超平面模型
8)
输入测试样本进行分类,得到分类结果y
9)
计算各个特征属性在分类结果y中的条件概率估计:P(ai|y)
10)
计算类别y出现的概率p(y)
11)
计算各个特征属性出现的概率p(ai)
12)
代入公式:
13)
returnP(y|x)
End
2.4.2算法分析
1)SVM-NB作为分类算法,其求得的是距离最优解,即相对公平的分类,可以很好地解决如何判断刷单的问题。
2)SVM-NB用于分类的模型体积较小,经优化后的模型更是可以达到10 KB以下。因为SVM的优势在于根据小样本进行分类,所以相比之下SVM算法在检测时间上有优势。
3)SVM-NB学习问题可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值,而其他分类方法(如基于规则的分类器和人工神经网络)都采用一种基于贪心学习的策略来搜索假设空间,这类方法一般只能获得局部最优解[13]。
4)SVM-NB算法采用朴素贝叶斯来进行刷单概率的计算,优点主要是特征项相关性较小,性能较优,而且利用小样本就可以得到较为精确的概率。
2.5 输出结果
SVM-NB算法通过建立分类器得出刷单分类的结果,然后将结果代入朴素贝叶斯公式,求出最终的刷单概率,并显示在用户可见的系统页面中。检测结果显示页面中用户可以点击详细信息按钮,进入详细信息显示页面。在此页面中,可以显示两种详细数据:行业数据和商品信息,均包括已设定的用于检测的特征值,可以使用户更清楚地了解该商品及其同类产品的详细信息。此外,用户可以直接选择某一种商品进行同类商品检测,即系统可以同时检测一种商品在多家店铺销售的刷单概率。
3 实验与分析
3.1 实验环境和实验数据
实验基于开源软件LibSVM与Java平台进行,LibSVM是台湾大学林智仁(Lin Chih-Jen)教授2001年开发设计的一个简单、易于使用且快速有效的SVM模式识别与回归的软件包[9-10]。利用LibSVM与Java的接口,在eclipse环境下实验。
通过商家调研、网页爬虫、文献查询和模拟方式获得了含有16 000个刷单数据的样本,其中包括真实数据1 600个和按照正态分布模拟的数据14 400个。数据集总共包含9个特征,记为f1~f9,分为刷单和不刷单的两类商品。商品详细数据格式如表4所示。
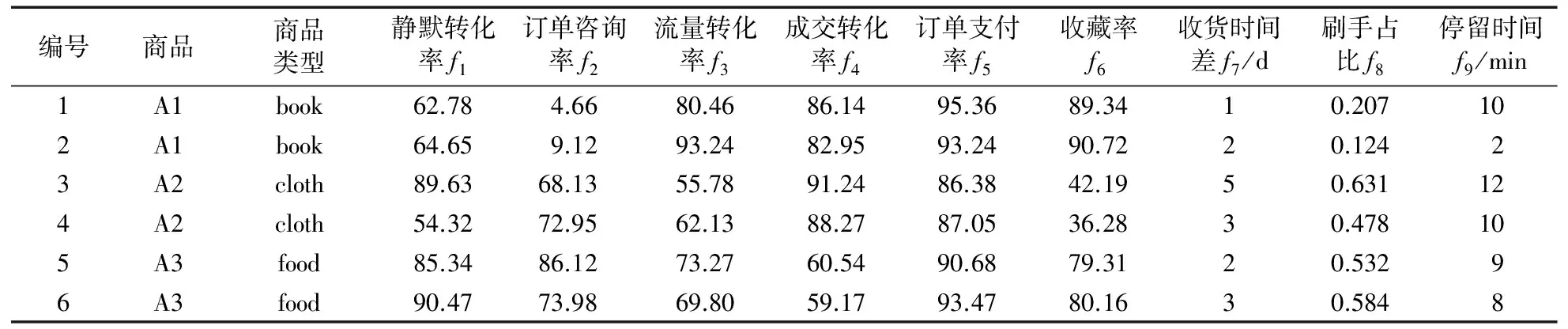
表4 数据特征项具体数值表Tab. 4 Detailed values of data characteristic items
3.2 实验与分析
第一步,数据预处理。首先对原始数据集进行率值计算,得到9个特征向量,训练数据样本如表5所示;然后对9个特征量的数值进行归一化处理,转化成算法可接受的数据格式。
第二步,SVM-NB方法处理实验及其他分类方法比较,并输出结果。
实验1核函数的选择。
本文将刷单数据集分成两部分,其中10 000个样本数据作为训练集,另外6 000个数据作为测试集,运用上面得到的最优化参数训练模型,算法参数优化结果如表6所示,经过交叉验证算法得出的刷单检测分类性能比较如表7[11]所示。
经过对SVM-NB算法的性能分析,最终确定采用了准确率较高的径向基函数(Radial Basis Function, RBF)作为核函数,该核函数将样本非线性地映射到一个高维的空间,能够处理分类标注和属性的非线性关系,符合SVM-NB算法对于分类结果的要求[12]。
实验2SVM-NB方法实验及其他分类方法比较。
将训练样本和测试样本数据输入SVM-NB算法,进行模型训练和结果预测。系统可以同时检测一种商品在多家店铺销售的刷单概率,并在同一界面上显示,以供用户对比。运行结果如表8所示。
SVM-NB方法与其他分类方法[13-15](包括朴素贝叶斯和BP神经网络)在正确率和计算速度方面的比较结果如表9所示。
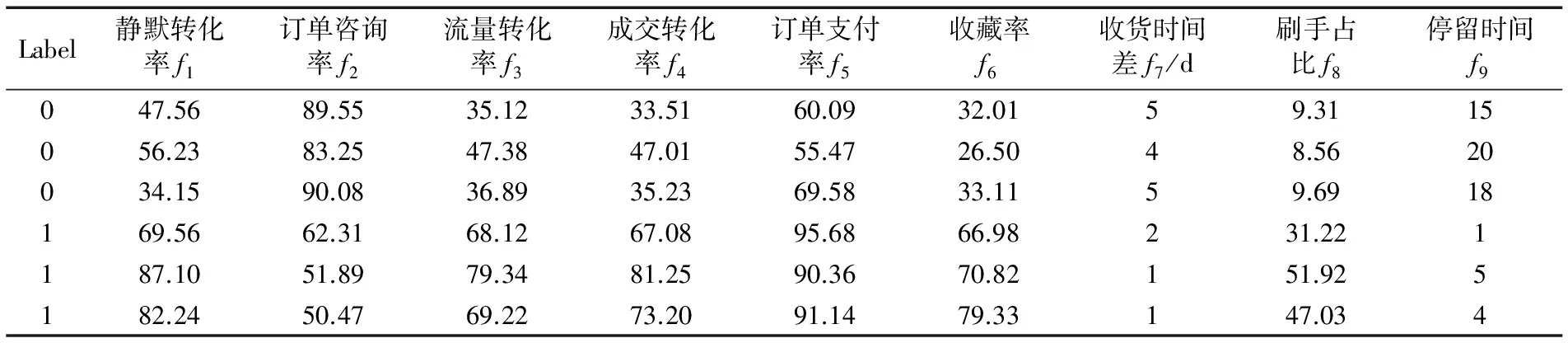
表5 训练数据样本Tab. 5 Samples of training data
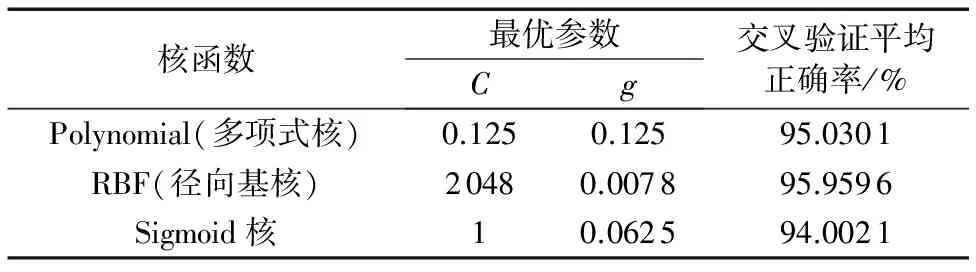
表6 各种核函数对刷单检测的最优参数Tab. 6 Optimal parameters of various kernel functions for click farming detection
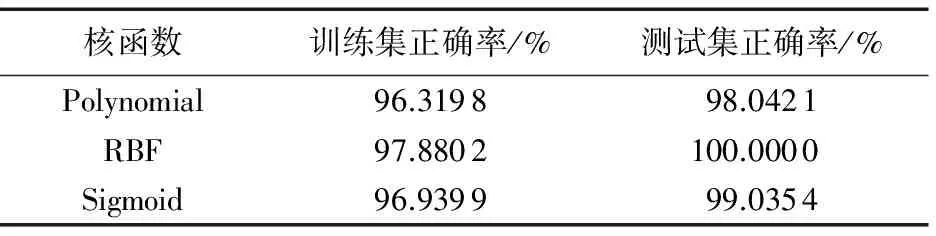
表7 各种核函数对刷单检测分类性能比较Tab. 7 Performance of various kernel functions for detection of click farming
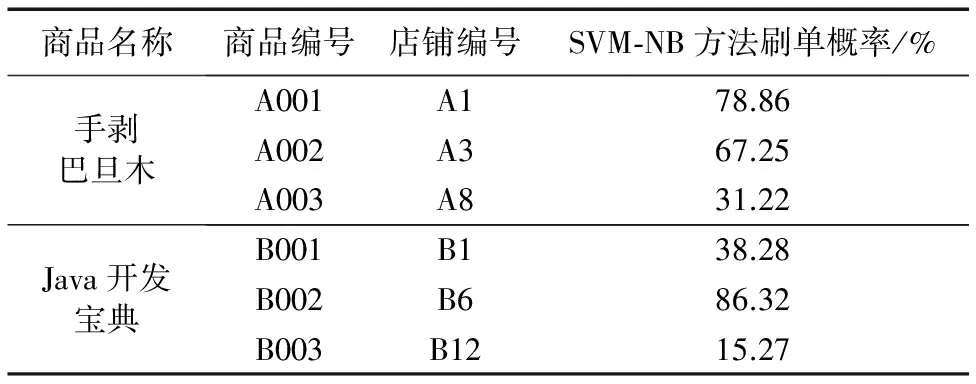
表8 SVM-NB方法刷单概率检测结果Tab. 8 Detection results for click farming by SVM-NB method
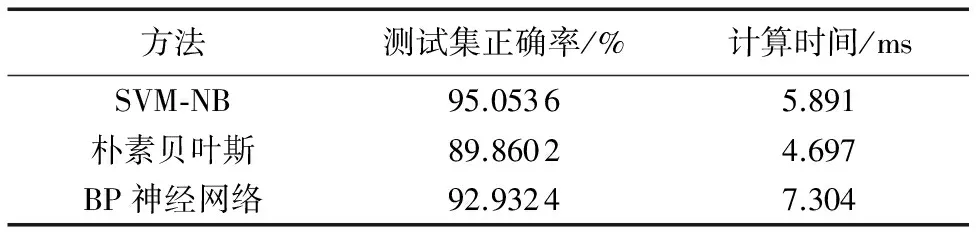
表9 SVM-NB与其他分类方法性能比较Tab. 9 Performance comparison of SVM-NB with other classification methods
SVM-NB算法与朴素贝叶斯和BP神经网络方法相比,特点如下:
1)在三种算法中本文所采用的分类算法得到的刷单概率正确率最高,且速度较快;BP神经网络算法的准确率居中,但速度最低,计算量大;朴素贝叶斯算法速度最高但准确率最低,因为朴素贝叶斯要求各项特征之间相互独立,但本文的刷单数据特征项之间有一定的联系,所以朴素贝叶斯算法并不适合本文要求。综合三种算法来看,本文采用的分类算法较为合适。
2)采用了动静结合的方式。当用户检测的商品在数据库中已经存在相关信息时,则为静态检测,只需将数据库中的数据转化成测试样本输入SVM-NB算法中进行分析,得出刷单概率并存入数据库中,以便下次针对同一商品进行检测时可以节省时间;当用户检测的商品在数据库中不存在相关信息时,根据用户输入的网址首先利用爬虫技术动态爬取网页内容,获取用户选择时间段内的商品最新信息。
3)本文方法有较好的完整性和闭环性,能够对刷单概率过高的店铺提出警告信息,不仅能够基于数据库中已有的店铺商品信息进行检测,而且实现了动态更新,保证了刷单概率检测结果的可用性和准确性;在给出最终的检测结果后,用户还能够查看所选商品的详细测试数据以及同行业数据,直观明了,增强了结果的说服力。
4)用户能够同时对多个商品进行刷单概率的检测,最终系统会显示出所选择的多个商品的计算结果,以供用户进行同类商品刷单行为检测结果的对比,并且能够同时显示多个商品的数据信息。
4 结语
随着网络购物逐渐成为一种新的生活方式,电商刷单现象也愈演愈烈。为了保证网购环境的透明化与可信度,本文提出了面向用户的电商平台刷单行为智能检测方法(SVM-NB)和构建刷单特征值方法,基于SVM算法训练样本数据并进行分类,为用户提供判断刷单的商品特征项信息,直观地给出系统计算的刷单概率,并通过K折交叉验证算法验证了SVM-NB算法应用的合理性和准确性,采用RBF函数在实验条件下的计算结果准确率达到了95.053 6%。但本文实验受真实数据量所限,随着真实数据量的增加,计算结果的准确性会有所变化,不过该结果仍可以帮助消费者较为准确地鉴别店铺资质和商品质量,降低消费者由于电商刷单所带来的财产风险。
参考文献:
[1]3·15曝光刷单超详细过程曝光淘宝刷单黑产业 [EB/OL]. [2016- 03- 16]. https://v.qq.com/x/page/a0188rpxwvn.html. {(3·15 exposure the detailed process of click farming and exposure Taobao black industry click farming [EB/OL]. [2016- 03- 16].https://v.qq.com/x/page/a0188rpxwvn.html.)
[2]贺骏.电商刷单产业链屡禁不止京东利用大数据“捉妖”[EB/OL]. [2016- 03- 21]. http://tech.hexun.com/2016- 03- 21/182861037.html. (HE J. E-commerce industry chain of click farming repeatedly banned, Jingdong use big data “catch demon” [EB/OL]. [2016- 03- 21]. http://tech.hexun.com/2016- 03- 21/182861037.html)
[3]新浪.详细解读淘宝稽查系统的主证与旁证系统 [EB/OL]. [2016- 10- 11]. http://edu.yjbys.com/taobao/104994.html. (Sina. Detailed interpretation of the main symptom and circumstantial evidence system of Taobao check system [EB/OL]. [2016- 10- 11]. http://edu.yjbys.com/taobao/104994.html.)
[4]COUELLAN N, WANG W. Uncertainty-safe large scale support vector machines [J]. Computational Statistics and Data Analysis, 2017, 109: 215-230.
[5]高雷阜,王飞.基于混沌更新策略的蜂群算法在SVM参数优化中的应用[J].计算机工程与科学,2017,39(1):199-205. (GAO L F, WANG F. Application of artificial bee colony based on chaos update strategy in support vector machine parameter optimization[J]. Computer Engineering & Science, 2017, 39(1): 199-205.)
[6]MOKHTARI A, RIBEIRO A. A Quasi-Newton method for large scale support vector machines [C]// ICASSP 2014: Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway, NJ: IEEE, 2014: 8302-8306.
[7]CHANG C-C, LIN C-J. LIBSVM — a library for support vector machines [J]. ACM Transactions on Intelligent Systems and Technology, 2011, 2(3): Article No. 27.
[8]何东健.SVM支持向量机算法的详细推导 [EB/OL]. [2016- 05- 10]. http://www.doc88.com/p- 1905946677891.html. (HE D J. Detailed derivation of Support Vector Machine (SVM) algorithm [EB/OL]. [2016- 05- 10]. http://www.doc88.com/p- 1905946677891.html.)
[9]熊浩勇.基于SVM的中文文本分类算法研究与实现[D].武汉:武汉理工大学,2008. (XIONG H Y. Research and implement of Chinese text categorization algorithm based on SVM [D]. Wuhan: Wuhan University of Technology, 2008.)
[10]BURGES C J C. A tutorial on support vector machines for pattern recognition [J]. Data Mining and Knowledge Discovery, 1998, 2(2): 121-167.
[11]XIE L, LI G, XIAO M, et al. Hyperspectral image classification using discrete space model and support vector machines [J]. IEEE Geoscience and Remote Sensing Letters, 2017, 14(3): 374-378.
[12]VOISAN E I, PRECUP R E, DRAGAN F. Facial expression recognition system based on a face statistical model and Support Vector Machines [C]// SACI 2016: Proceedings of the 2016 IEEE 11th International Symposium on Applied Computational Intelligence and Informatics. Piscataway, NJ: IEEE, 2016: 63-68.
[13]LI J, CAO Y, WANG Y, et al. Online learning algorithms for double-weighted least squares twin bounded support vector machines [J]. Neural Processing Letters, 2017, 45(1): 319-339.
[14]王雅玡.基于朴素贝叶斯和BP神经网络的中文文本分类问题研究[D].昆明:云南师范大学,2008. (WANG Y Y. Researching on Chinese text classification based on naive bayes and BP neural network [D]. Kunming: Yunnan Normal University, 2008.)
[15]AAZI F Z, ABDESSELAM R, ACHCHAB B, et al. Feature selection selection for multiclass support vector machines [J]. AI Communications, 2016, 29(5): 583-593.
猜你喜欢
今日农业(2022年16期)2022-11-09
数学小灵通(1-2年级)(2021年4期)2021-06-09
大众投资指南(2020年10期)2020-07-24
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
法制博览(2018年31期)2018-01-22
初中生世界·七年级(2017年9期)2017-10-13
对外经贸(2017年6期)2017-08-24
少儿科学周刊·儿童版(2017年3期)2017-06-29
领导决策信息(2017年17期)2017-06-21
中国知识产权(2016年6期)2016-06-30
