
Key-Attributes-Based Ensemble Classifier for Customer Churn Prediction
2018-04-08 03:11:18YuQianLiangQiangLiJianRongRanandPeiJiShao
Yu Qian, Liang-Qiang Li, Jian-Rong Ran, and Pei-Ji Shao
1.Introduction
Data mining has become increasingly important in management activities, especially in the support of decision making, most of which can be attributed to the task of classification. Therefore, classification analysis has been widely used in the study of management decision problems[1]-[4], for example, trend prediction and customer segmentation.Obviously, classification methods with high accuracy would reduce the decision loss of misclassification. However, with the increasing complexity of modern management and the diversity of related data, the results provided by a single classifier are suspected of having poor semantics and thus are hard to understand in management practice, especially for the prediction tasks with complex data and managerial scenarios[5].
In recent years, ensemble classifiers have been introduced into solving complicated classification problems[6], and they represent the new direction for the improvement of the performance of classifiers. These classifiers could be based on a variety of classification methodologies, and could achieve different rates of correct classified individuals. The goal of the classification result integration algorithms is to generate more certain, precise, and accurate results[7].
In literature, numerous methods have been suggested for the creation of ensemble classifiers[7],[8]. Although the ensemble classifiers constructed by any of the general methods have archived a great number of applications in classification tasks[8],they have to face two challenges in performance under some real managerial scenarios. The first one is the expensive time cost for classifiers’ training/learning, and the second one is about the poor semantic understanding(management insights) of the classification results.
In this research, we propose a method which builds an ensemble classifier based on the key attributes (values) that are filtered out from the initial data. Experiment results with real data show that the proposed method not only has high relative precision in classification, but also has high comprehensibility of its calculation results.
2.Related Work
2.1 Classification Models for Churn Prediction
In most real applications, studies are mainly focused on improving the performance of a single algorithm in predicting activities, typically in predicting the customer churn in the service industry.
In this stream, Hu et al. analyzed and evaluated three implementations for decision trees in the churn prediction system with big data[9]. Kim et al. used a logistic regression to construct the customer churn prediction model[10]. Tian et al.adopted the Bayesian classifier to build a customer churn prediction model[11]. More complicatedly, artificial neural network (ANN)[12]and random forest (RF)[13]have been adopted to build the customer churn prediction model. Ultsch introduced a self-organizing map (SOM) to build the customer churn prediction model[14]. Rodan et al.[15]used support vector machine (SVM) to predict customer churn. Au et al. built the customer churn prediction model based on evolutionary learning algorithms[16].
2.2 Ensemble Classifier
The main idea of the ensemble classifier is to build multiple classifiers on the collected original data set, and then gather the results of these individual classifiers in the classification process. Here, individual classifiers are called base/weak classifiers. During the training, the base classifiers are trained separately on the data set. During the prediction, the base classifiers provide a decision on the test dataset. An ensemble method then combines the decisions produced by all the base classifiers into one final result. Accordingly, there are a lot of fusion methods in the literature including voting, the Borda count, algebraic combiners, and so on[7].
The theory and practices in literature have proved that an ensemble classifier can improve the performance of classification significantly, which might be better than the performance provided by any single classifier[8]. Generally,there are two methods to construct an ensemble classifier[7],[8]:1) algorithm-oriented method: Implementing different classification learning algorithms on the same data, for example, the neural network and decision tree; 2) data-oriented method: Separating the initial dataset into parts and using different subsets of training data with a single classification method.
Particularly, for the decline of the prediction precision caused by the complex data structure, processing the training data is a feasible way for ensemble classifier construction.Bagging and boosting are two typical ensemble methods of handling the datasets[17]-[19].
As mentioned before, the focuses of these researches have been put on the prediction accuracy of each single model.However, we could also address the problems of constructing an ensemble classifier based on the data distribution for better prediction results.
3.Research Method
3.1 Research Problem
Representing each user as an entity, then the dataset is composed by the values of user-attributes can be treated as an initial matrix as shown in Table 1. In which, the value of xiis typically vectors of the formand it denotes the whole values to the Useri. The value of Aiis typically vectors of the formwhose components are discrete or real value representing the values for attribute Ajsuch as age, income, and location. The attributes are called the features of xi.

Table 1: Initial data matrix
Since the basic research context of this study is about complicated training data and complex decision scenarios, both of the algorithm- and data-oriented methods would be taken into consideration in ensemble classifier construction by training a group of classifiers.
3.2 Key Attribute Selection
As the dimensionality of the data increases, many types of data classification problems become significantly harder,particularly at the high computational cost and memory usage[20]. As a result, the reduction of the attribute space may lead to a better understandable model and simplifies the usage of different visualization techniques. Thus, a learning algorithm to induce a classifier must address the two issues: Selecting some key attributes (dimension reduction) and further splitting a dataset into parts according to the value distributions of these key attributes.
Key attribute selection used in this study is to select a lot of attributes from data sets and the selection is basically consistency with the goal of prediction.
The two ways of supervised and unsupervised methods can be used to selecte attributes. The supervised method is also called the management-oriented method. It is used to determine whether an attribute A is a key attribute according to the management needs and prior knowledge. The typical method is asking some experts to label out the key attributes. The advantage of this method is that its calculation process is simple and its results have higher comprehensibility. To avoid the selection bias from the experts’ side, sometimes, the unsupervised method is used for data preprocessing by introducing some methods with the computational capacity of grouping or dimension reduction, for example, clustering or principal component analysis (PCA).
To simplify the calculation, we introduce the following“clustering-annotation” process to selecte the key attributes.Firstly, we use a clustering method to cluster the attributes ofintogroups, i.e.,,according to their values’ similarity. In other words, ifare similar to each other, then
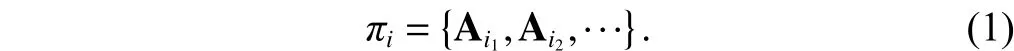
Next, we associate one representative attribute for πiin accordance with the management semantics of attributes in πi.The basic rule for the association is that the selected attribute should have strong potential correlation (management insights)with the decision-making problem.
3.3 Attribute Value Based Dataset Splitting
After the key attributes are selected, then the data set X would be split (clustered) into k parts by the value distributions of these key attributes.
The general method for such task is the binning method which can distribute sorted values into a number of bins.Assume that the maximum value of attribute A is max and its minimum is min, and divide the original data set into k subdataset. The record x, whose value of attribute A satisfies the following condition, will be classified as a member of the group Ci:

where i = 1, 2, ···, k.
In literature, researchers have introduced some efficient methods to split the initial dataset into sub-datasets automatically, for example, the maximum information gain method and Gini method[8],[21]. The performance of such unsupervised methods is affected by the type, range, and distributions of the attribute values, and especially, they may suffer from the higher computational complexity.
Equation (2) works well on data splitting with one attribute A. Moreover, we could split data with a set of attributes as clustered in (1). To deal with a very large dataset, it is argued that the singular value decomposition (SVD) of matrices might provide an excellent tool[22].
Based on the values of selected key attributes of πi, in this study, the datasetwill be split as follows:
2) Computing the SVD of matrixsuch that
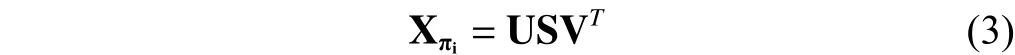
where U and V are orthonormal and S is diagonal. The column vectors of U are taken from the orthonormal eigenvectors of, and ordered right to left from largest corresponding eigenvalue to the smallest.
3) The elements of S are only nonzero on the diagonal, and are called the singular values. By convention, the ordering of the singular values is determined by high-to-low sorting, so that we can choose the top-k eigenvalues of S and cluster the vectors x(πi) ininto k clusters:.Finally, the cluster information foris further used to map each vector of x in X into the group:
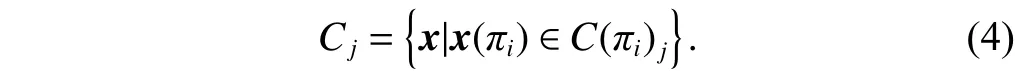
3.4 Ensemble Classifier
To keep more managerial information, we can construct an ensemble classifier as following:
Firstly, given a decision-making goal, we cluster all the attributes into l groups and associate each group with a representative feature. Then, we introduce SVD to split the data matrix offor the group πi, and the results are used to map all the vectors in X into k groups, each of which is a sub-dataset specially for the purpose of better prediction for the targeted decision-making goal. Next, based on the new generated subdataset, we can introduce the general algorithm or data oriented method to train a set of approximate classifiers and use them to perform the classification tasks for decision-making problem.At last, a fused result will be reported for the prediction.
Another important work is to select an appropriate classification algorithm for those aforementioned sub-datasets.Considering the cost of calculation and the precision of results,in this study, we choose three typical classification algorithms of neural net, logistic, and C5.0[23]as the basic algorithms to build the hybrid model.
The classification of a new instance x is made by voting on all classifiers {CFt}, each has a weight of αtwhere t={Neural net, Logistic, C5.0}. The final prediction can be written as:

where, αtis a value between [0, 1] according to the performance of CFt. In order to simplify the calculation, αtcan be set as 1 for the best classifier and 0 for the others.
3.5 Evaluation Method
In this paper, the precision[21]and receiver operating characteristic (ROC)[24]are used to evaluate the results.
Given a set of prediction results made by a classifier, the confusion matrix of two classes “true” and “false” are shown in Table 2. Here, variable the A, B, C, and D are used to denote the number of true positive, true negative, false positive,and false negative results, respectively.
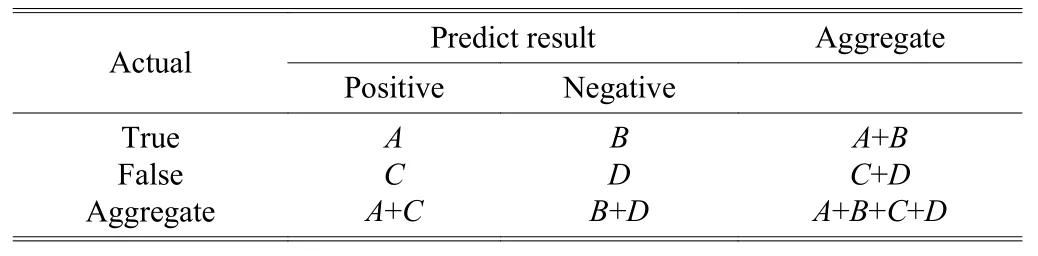
Table 2: Results matrix predicted by the classifier

The ROC is a graphical plot that illustrates the performance of a classifier system as its discrimination threshold is varied.The ROC analysis is originated from the statistical decision theory in the 1950s and has been widely used in the performance assessment of classification[21]. The ROC curve is plotted by treating the ratio of true positive as Y-axis and ratio of false positive as X-axis. The closer to the upper left corner of ROC curve, the higher the accuracy of the model predictions.The area under curve (AUC) can be used as a measure of the prediction effect. The value of AUC generally ranges between 1.000 and 0.500 and it represents the better prediction if the area value approaches closer to 1.000.
4.Experiment Results
4.1 Data Set
With the speedup of the market competition, maintaining the existing customers is then becoming the core marketing strategy to survive in the telecommunication industry. For the better performance of customer maintaining, it is necessary to predict those who are about to churn in the future. Studying the churn prediction is an important concern in the telecommunication industry. For instants, in the following experiments, the data is collected from China Mobile.
Note that, due to the great uncertainty of the consumer behavior and little data recorded in companies’ operation databases, the records generated by temporary customers and the customers who buy a SIM card and discard the card soon after short-term consumption are cleared. At last, all together 47735 customers are randomly selected from three main sub-branches which located in 3 different cities separately. The observation period is from January 1st, 2008 to May 31st, 2008 and the extracted information is about the activities of the users in using the telecommunication services, such as contract data, consumer behaviors, and billing data.
After data preprocessing such as data clean, integration,transformation, and discretization, the valid customer data is 47365 (99.2% of the total number of samples and noted as dataset X), in which, 3421 users are churn customers (the churn rate is 7.2%). In the experiments, the data set X has been separated into two parts: The training data which were generated from January 1st to March 31st, 2008, denoted by X1,and the test data which are generated from April 1st to May 31st, 2008, denoted by X2.
The experiment platform is SPSS Clementine12.0, which provides well-programmed software tools for the classification algorithms of C5.0, logistic, and neural net.
4.2 Attribute Selection and Dataset Splitting
In total, there are 116 (n=116) variables included in the customer relationship management (CRM) system are extracted as the initial data set X.
Implement the cosine similarity based k-means clustering method on vectorsin X. Inspired by the customer segmentation in marketing (in conjunction with necessarily experts’ annotations), we cluster the common variables according to their relations in marketing practice.At last, the attributes are clustered into 4 (l=4) groups and 4 attributes of brand, area, age, and bill (having strong correlation with customers’ churn in the telecommunication industry) are chosen as the key attributes, respectively.
Moreover, the values of these four attributes are split into 3(k=3) sub-datasets, respectively, according to the SVD clustering results. The results are summarized in Table 3.

Table 3: Subdivision categories of each variables
4.3 Ensemble Model Construction
In the following, four ensemble classifiers will be built according to the sub-datasets separated by four attributes of brand, area, age and bill.
The classification algorithms of C5.0, logistic, and neural net algorithms are implemented on each sub-dataset for a series of repeated prediction experiments. The logic view of the ensemble classifier model construction is shown in Fig. 1.
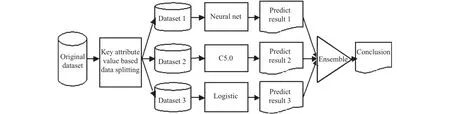
Fig. 1. Logic view of ensemble classifier models.
For the attribute of brand, the training set X1is firstly divided into three sub-datasets, namely GoTone, EasyOwn, and M-Zone. Each of them accounts for 7.2%, 80.7%, and 12.1%customers, respectively. In the learning process, each subset is separated firstly into training and test sets according to the ratio of 60.0% and 40.0%.
Among all the classification results reported by each algorithm on the test dataset, the result with the largest AUC area under the ROC curve is selected as the basic model for such a sub-dataset. The AUC results reported by three models on each brand are shown in Table 4.
The comparative results are shown in Fig. 2. The results in Table 4 show that the neural net algorithm works the best in the prediction of GoTone and EasyOwn sub-datasets, whereas the C5.0 works the best on the M-Zone sub-dataset.

Table 4: AUC of prediction on brand sub-datasets
Similarly, the performances of classification (prediction) on sub-datasets split by attributes of area, age, and bill are reported in Tables 5 to 7, respectively. Accordingly, the visualized results are shown in Figs. 3 to 5.
4.4 Result Evaluation
The previous experiments on sub-datasets separated by different key attributes provide 4 hybrid models. Next, we will use these four models to make prediction on datasetX2. Also,the measurements of precision and ROC curve are used to evaluate the performance of each model.
1) Comparison of precision
The average accuracy of prediction provided by the four of each model based onX2is summarized in Table 8. It shows that there is the highest precision (86.1%) reported while using the key attribute of area for data segmentation to build a hybrid model, followed by the result generated with the attribute bill(85.9%). However, the performance of hybrid models constructed by the attributes brand and age for data segmentation is lower (81.2% and 76.2%).
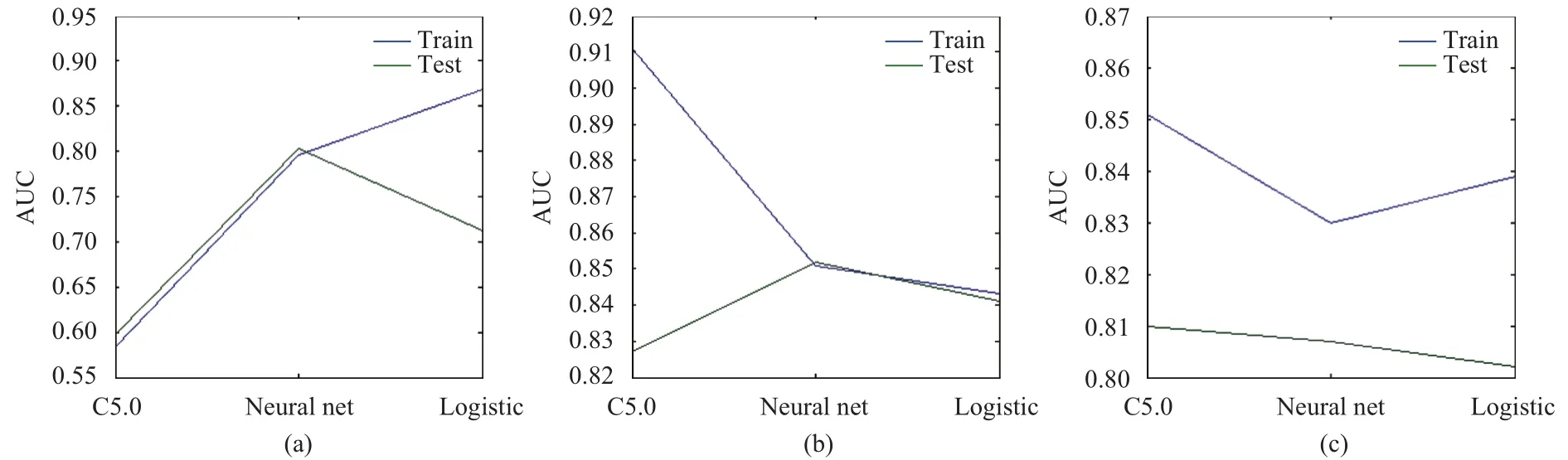
Fig. 2. AUC of prediction on brand sub-datasets: (a) GoTone, (b) EasyOwn, and (c) M-Zone.
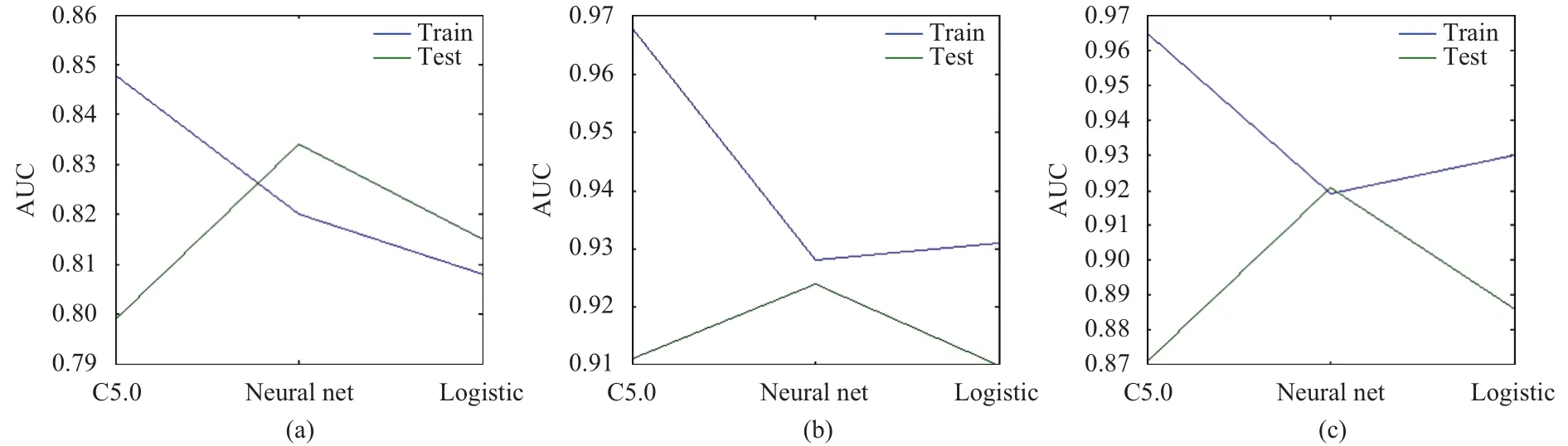
Fig. 3. AUC of prediction on area sub-datasets: (a) area A, (b) area B, and (c) area C.

Fig. 4. AUC of prediction on age sub-datasets: (a) net age low, (b) net age middle, and (c) net age high.

Fig. 5. AUC of prediction on bill sub-datasets: (a) low consumption level, (b) middle consumption level, and (c) high consumption level.

Table 5: AUC of prediction on area sub-datasets

Table 6: AUC of prediction on age sub-datasets

Table 7: AUC of prediction on bill sub-datasets

Table 8: Prediction accuracy of the four hybrid models on test set X2
2) Comparison of ROC
The ROC curves for the prediction results provided by the four hybrid models on testing set X2is shown in Fig. 6. The area under the ROC curve of each hybrid model is calculated in Table 9.
Comparing the results in Fig. 6 and Table 9, we know that the two hybrid models constructed based on attributes of area and bill would generate a better AUC (0.888 and 0.855) than based on brand and age (0.828 and 0.845).
According to the experiment results, we can conclude that using the attribute of area as the segment variable would get the best prediction results, which are followed by those of the bill attribute. However, the key attributes age and brand would perform relatively poorly. Therefore, in practice of customer churn prediction, it is recommended that telecommunication companies use the consumers’ bill information as the key attribute to build the customer churn prediction hybrid model for each area separately. Moreover,it is necessary to strengthen brand management and to improve the customer segmentation effect of different brands.
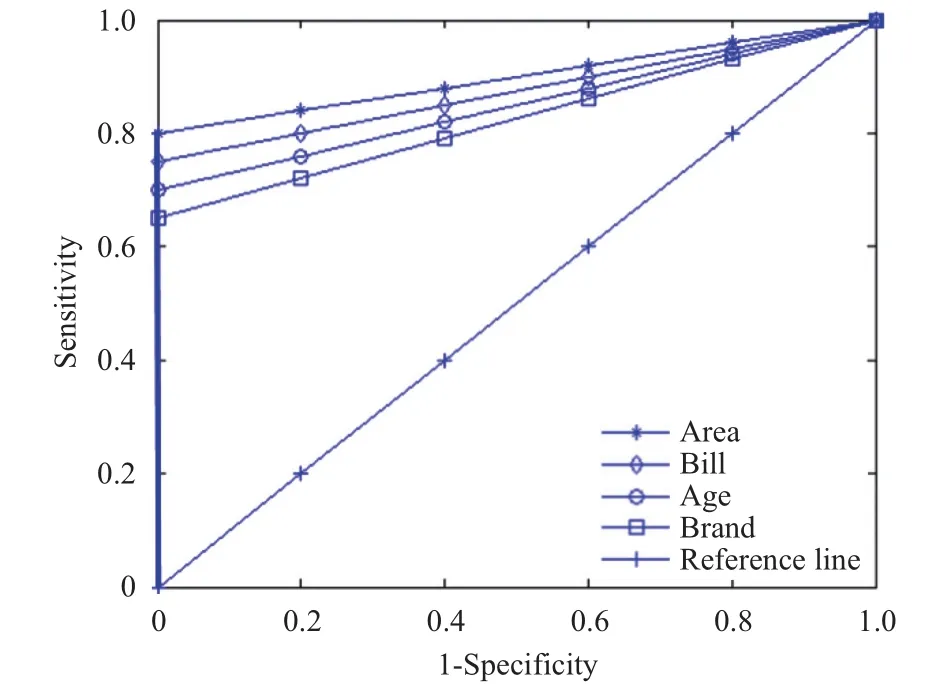
Fig. 6. ROC curve of prediction accuracy of the four hybrid models on test set X2.

Table 9: AUC of prediction accuracy of the four hybrid models on test set X2
3) Limitations
The main idea of the method proposed in this work is to construct an ensemble classifier for higher precision and managerial insights. We should note some limitations of this work. First, there is a lack of criteria for how many base classifiers should be selected in the hybrid classifier. Second,the proposed method has involved some time consumption preprocessing processes in ensemble classifier construction, for example, the PCA and SVD methods, which would cause the higher complexity of computation.
5.Conclusions
Classification analysis has been widely used in the study of decision problems. However, with the increasing complexity of modern management and the diversity of related data, the results provided by a single classifier are suspected of having poor semantics, thus are hard to understand in the management practice, especially for the prediction tasks with the very complex data and managerial scenarios.
Regarding to the management issues of classification and prediction, an ensemble of single classifiers is an effective way to improve the prediction results. In order to solve the problems of poor precision and management semantics caused by the ordinary ensemble classifiers, in this paper, we proposed the ensemble classifier construction method based on the key attributes in the data set. The experimental results based on the real data collected from China Mobile show that the keyattributes-based ensemble classifier has the advantages on both prediction accuracy and result comprehensibility.
[1]M. J. Berry and G. S. Linoff,Data Mining Techniques: for Marketing, Sales, and Customer Support, New York: John Wiley & Sons, 1997, ch. 8.
[2]Y. K. Noh, F. C. Park, and D. D. Lee, “Diffusion decision making for adaptivek-nearest neighbor classification,”Advances in Neural Information Processing Systems, vol. 3,pp. 1934-1942, Jan. 2012.
[3]X.-L. Xia and Jan H.-H. Huang, “Robust texture classification via group-collaboratively representation-based strategy,”Journal of Electronic Science and Technology, vol.11, no. 4, pp. 412-416, Dec. 2013.
[4]S. Archana and D. K. Elangovan, “Survey of classification technique in data mining,”Intl. Journal of Computer Science and Mobile Applications, vol. 2, no. 2, pp. 65-71, 2014.
[5]H Grimmett, R. Paul, R. Triebel, and I. Posner, “Knowing when we don’t know: Introspective classification for mission-critical decision making,” inProc. of IEEE Intl.Conf. on Robotics and Automation, Karlsruhe, 2013, pp.4531-4538.
[6]R. L. MacTavish, S. Ontanon, J. Radhakrishnan,et al., “An ensemble architecture for learning complex problem-solving techniques from demonstration,”ACM Trans. on Intelligent Systems and Technology, vol. 3, no. 4, pp. 1-38, 2012.
[7]T. G. Dietterich,Ensemble Methods in Machine Learning,Multiple Classifier Systems, Berlin: Springer, 2000, pp. 1-15.
[8]Z.-H. Zhou,EnsembleMethods: Foundations and Algorithms, Boca Raton: Chapman and Hall/CRC, 2012.
[9]X.-Y. Hu, M.-X. Yuan, J.-G. Yao,et al., “Differential privacy in telco big data platform,” inProc. of the 41st Intl.Conf. on Very Large Data Bases, Kohala Coast, 2015, pp.1692-1703.
[10]H. S. Kim and C. H. Yoon, “Determinants of subscriber churn and customer loyalty in the Korean mobile telephony market,”Telecommunications Policy, vol. 28, no. 9, pp. 751-765, 2004.
[11]L. Tian, K.-P. Zhang, and Z. Qin, “Application of a Bayesian network learning algorithm in telecom CRM,”Modern Electronics Technique, vol. 10, pp. 52-55, Oct. 2005.
[12]A. Sharma and P. K. Panigrahi, “A Neural network based approach for predicting customer churn in cellular network services,”Intl. Journal of Computer Applications, vol. 27,no. 11, pp. 26-31, Aug. 2011.
[13]Y.-Q. Huang, F.-Z. Zhu, M.-X. Yuan,et al., “Telco churn prediction with big data,” inProc. of ACM SIGMOD Intl.Conf. on Management of Data, Melbourne, 2015, pp. 607-618.
[14]A. Ultsch, “Emergent self-organizing feature maps used for prediction and prevention of churn in mobile phone markets,”Journal of Targeting, Measurement and Analysis for Marketing, vol. 10, no. 4, pp. 314-324, 2002.
[15]A. Rodan, H. Faris, J. Alsakran, and O. Al-Kadi, “A support vector machine approach for churn prediction in telecom industry,”Intl. Journal on Information, vol. 17, pp. 3961-3970, Aug. 2014.
[16]W. H. Au, KCC. Chen, and X. Yao, “A novel evolutionary data mining algorithm with applications to churn prediction,”IEEE Trans. on Evolutionary Computation, vol. 7, no. 6, pp.532-545, 2003.
[17]S. B. Kotsiantis and P. E. Pintelas, “Combining bagging and boosting,”Intl. Journal of Computational Intelligence, vol. 1,no. 4, pp. 324-333, 2004.
[18]N. C. Oza, “Online bagging and boosting,” inProc. of IEEE Intl. Conf. on Systems, Man & Cybernetics, Tucson, 2001,pp. 2340-2345.
[19]C.-X. Zhang, J.-S. Zhang, and G.-W. Wang, “A novel bagging ensemble approach for variable ranking and selection for linear regression models,” inMultiple Classifier Systems, Friedhelm Schwenker, Ed. Switzerland: Springer,2015, pp. 3-14.
[20]W. Drira and F. Ghorbel, “Decision bayes criteria for optimal classifier based on probabilistic measures,”Journal of Electronic Science and Technology, vol. 12, no. 2, pp. 216-219, 2014.
[21]J. Han, M. Kamber, and J. Pei,Data Mining: Concepts and Techniques: Concepts and Techniques, 3rd ed., San Francisco: Morgan Kaufmann, 2011.
[22]P. Drineas, A. Frieze, R. Kannan, S. Vempala, and V. Vinay,“Clustering large graphs via the singular value decomposition,”Machine Learning, vol. 56, no. 1, pp. 9-33,2004.
[23]T. Bujlow, T. Riaz, and J. M. Pedersen, “A method for classification of network traffic based on C5.0 machine learning algorithm,” inProc. of IEEE Intl. Conf. on Computing, Networking and Communications, Okinawa,2012, pp. 237-241.
[24]A. P. Bradley, “The use of the area under the ROC curve in the evaluation of machine learning algorithms,”Pattern Recognition, vol. 30, pp. 1145-1159, Jul. 1997.
 Journal of Electronic Science and Technology2018年1期
Journal of Electronic Science and Technology2018年1期
- Journal of Electronic Science and Technology的其它文章
- Message from JEST Editorial Committee
- Modeling TCP Incast Issue in Data Center Networks and an Adaptive Application-Layer Solution
- UEs Power Reduction Evolution with Adaptive Mechanism over LTE Wireless Networks
- Multi-Reconfigurable Band-Notched Coplanar Waveguide-Fed Slot Antenna
- High Power Highly Nonlinear Holey Fiber with Low Confinement Loss for Supercontinuum Light Sources
- Overview of Graphene as Anode in Lithium-Ion Batteries