
基于主题相似度的宏观篇章主次关系识别方法
2018-04-04 02:42褚晓敏李培峰朱巧明
中文信息学报 2018年1期
蒋 峰,褚晓敏,徐 昇,李培峰,朱巧明
(苏州大学 计算机科学与技术学院,江苏 苏州 215006;江苏省计算机信息技术处理重点实验室,江苏 苏州 215006)
0 引言
近年来,自然语言处理领域的研究内容,逐步从浅层次的词汇、句法分析延伸到了深层次的语义理解。因此,自然语言处理研究的文本颗粒度,从单个词、短语、句子,延伸至句群、段落、篇章。篇章分析是目前研究的热点和重点,其目的是进一步研究自然语言文本的内在结构,并理解文本单元间的语义关系,挖掘出文本的结构化和语义信息。
篇章主次关系表示了篇章内部或篇章与篇章间的主要内容和次要内容的关系。其中,主要内容是指篇章中居于支配地位、起决定作用的部分,而次要内容是指篇章中居于辅助地位、不起决定作用的部分[1]。篇章主次关系主要分为微观和宏观两个层面,微观主次关系是指篇章中的一个句子内部的主次关系或两个连续句子间的主次关系,而宏观主次关系则是更高层次的主次关系,表现为段落、章节间的主次关系。研究篇章主次关系,有助于更好地认识和理解篇章的中心主题,更有效地挖掘篇章的宏观主题和篇章各部分之间的语义关联,并为自然语言处理的相关应用,如信息抽取[2]、自动文摘[3]、问答系统[4]等提供支撑。
本文以CTB8.0中一个篇章(chtb_0056.nw.raw)为例来说明宏观篇章主次关系,如图1所示(完整的宏观篇章关系结构标注如图2所示)。在图2所示的树形结构中,自然段落是叶子节点(如段落a、b等),篇章关系为非叶子节点(如R2、R3等),箭头指向篇章关系中较为重要的部分。本文将篇章主次关系分为三类: (1)P-S(primary and secondary),即主要在前,次要在后; (2)S-P(secondary and primary),即主要在后,次要在前; (3)M-P(multi-primary),即前后同等重要。

中国高新技术开发区发展迅速成果显著a新华社北京十二月十七日电(记者秦杰)中国五十三个国家高新技术开发区发展迅速,已形成一大批机制灵活、适应市场经济要求、技术创新能力强的高新技术企业。b中国高新技术开发区酝酿于八十年代初。到去年为止,中国高新技术开发区技术工贸年总收入达二千三百亿元,利税总额达二百三十八亿元,年出口创汇达四十三亿美元,均比创办初增长数十倍。其中,形成了一批具有一定规模的高新技术支柱产业,产值超亿元的企业达四百零五家,产值超十亿元的大企业四十二家。c一九九六年,中国高新技术开发区企业研究开发投入达六十二点三五亿元,占企业产品销售收入的百分之三点五,开发、生产高新技术产品一万三千多种。d近年来,中国高新技术开发区初步建立了适应社会主义市场经济体制和高新技术产业发展需要,与国际惯例接轨的管理体制和运行机制,建立并不断完善了包括信息、金融、法律、资产评估、产权交易等中介和服务机构,初步形成了适于高新技术产业发展的较为完善的支撑服务体系。e为规范高新区的管理,依法治区,中国颁布了《国家高新技术产业开发区管理暂行办法》,同时长春、苏州、沈阳、长沙、石家庄、昆明等高新区也先后完成了高新区的人大立法工作或以政府令形式发布了高新区管理办法。(完)图1 中文宾州树库篇章示例

图2 宏观篇章结构的树形表示(chtb_0056.nw.raw)
该例中,段落a中提出中国高新技术开发区发展迅速,段落b是对中国高新技术开发区发展情况的详细介绍。因此,主要是段落a的内容与外界发生语义关系,段落a主要,段落b次要,而且段落a、b间形成了解说关系;而段落c、d、e分别从三个方面阐述了中国高新技术开发区发展迅速的原因,因此三者为同等重要,形成并列关系。
本文组织结构如下: 第二部分从理论、语料、模型三个方面介绍了篇章主次分析的相关研究工作;第三部分介绍了宏观汉语篇章语料库的建设;第四部分给出了一个基于主题相似度的宏观篇章主次关系识别框架,并介绍了计算主题相似度的算法;第五部分详细分析了实验结果;第六部分总结全文并指出下一步工作。
1 相关工作
理论研究方面,在微观篇章关系上,Mann和Thompson[5-6]的修辞结构理论(RST)根据修辞关系提出了“核-卫星”(nucleus- satellite)模式,并将篇章关系分为单核关系和多核关系两大类。对于单核关系来说,有关系的两个篇章单元一方为核心,别一方为卫星。对于多核关系来讲,篇章关系连接的两个篇章单元同等重要,没有主次之分。在宏观篇章关系上,Van Dijk[7]的篇章宏观结构理论提出了篇章宏观结构,宏观结构与微观结构相对,是篇章整体上的高层次的结构,每一层的宏观单元都由下一层的宏观单元通过归总形成,代表更为主要的篇章内容。
目前涉及篇章主次关系语料资源主要包括修辞结构篇章树库(RST-DT)和汉语篇章树库(CDTB)等。修辞结构篇章树库以修辞结构理论(RST)为支撑,标注了篇章单元、篇章关系、主次关系(即“核心”和“卫星”)和篇章结构等,从而生成有层次的篇章结构树。汉语篇章树库基于连接依存树的篇章结构理论,在宾州大学汉语树库(CTB)上标注了500篇微观篇章关系结构,共计2 342 个段落。该语料库是在每个段落上自顶向下地标注一棵篇章关系结构树,其篇章基本单元为子句。RST-DT和CDTB都进行了微观篇章主次关系的标注,但均未进行宏观篇章主次关系的标注。
微观篇章主次关系方面的计算模型研究较为广泛。在修辞结构篇章树库上,Hernault[8]使用的是开源的HILDA分析器, HILDA分析器使用两个支持向量机(SVM)来构建篇章树,其分析器在篇章主次关系识别任务中的F1 性能为 61.3%。Joty[9]在他们前期[10]句内篇章结构分析的工作基础上,分别应用句内和句间两个动态条件随机场模型(DCRF),构建了句内和句间两个层级的篇章分析器,在篇章主次识别任务上,其F1值达到了68.43%。Feng 和 Hirst[11]在其前期工作[12]的基础上,使用线性链的条件随机场模型对微观篇章关系区域划分和主次做出了识别,其正确率分别达到了85.7%和71%。在汉语篇章树库上,Chu[13]使用了上下文、词对、词和词性等特征,在主次关系识别上达到了53.21%的正确率,识别中心在前、中心在后、多中心三类关系的F1值分别达到了51.58%、53.59%、54.64%。李艳翠[14]构建了一个自底向上的汉语微观篇章结构分析平台,其中在篇章单位主次区分的任务上,中心在前、中心在后、多中心三类识别上分别取得了43.6%、51.5%、79.3%的F1值,识别的总正确率为69%。在宏观篇章主次关系计算模型方面,还尚不完善。
2 宏观汉语篇章树库(MCDTB)
基于以上针对宏观篇章主次关系研究现状的分析,目前宏观篇章主次关系在理论、语料库建设和计算模型上还尚不完善。为此,本文构建了一个以篇章主次关系为载体的篇章结构表示体系,如图3所示。该体系自上而下由全文标题、章节、段落、句子、子句等组成。其宏观结构和微观结构均是多层的,在微观篇章主次关系方面复用了李艳翠[14]基于连接依存树的篇章结构表示体系,本文关注的重点是宏观篇章主次关系的识别模型,即段落层以上的篇章主次关系识别模型。
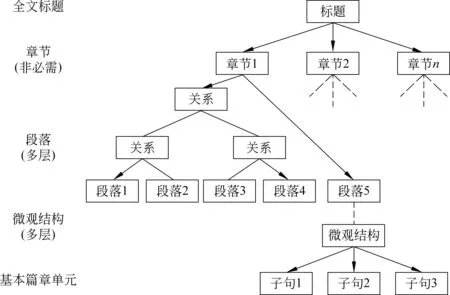
图3 篇章结构多层树形表示
依据这个篇章结构表示体系,本文构建了宏观汉语篇章树库(MCDTB)。该语料来源于LDC2013年发布的CTB8.0,选择其中最为规范的新闻报道(Newswire)作为原始语料,标注了篇章主题、篇章摘要、段落主题、篇章关系、主次关系等信息。MCDTB更侧重于整个篇章层面,以段落为基本篇章单元,并对段落及更高层次的篇章单元间的结构、主次与关系进行相应的标注。在段落及更低的语义单元内,复用CDTB所标注的微观篇章结构。
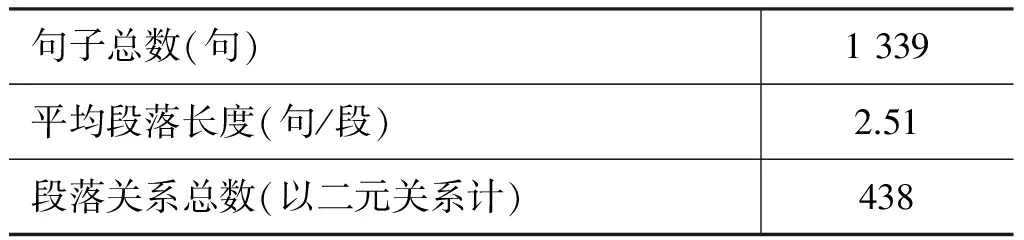
在标注方法上,本文使用自下而上的标注策略,在判断篇章单元的主次关系时,注重宏观上篇章单元与篇章主题的语义关联程度。在标注规则上,本文制定了一系列标准。在实施过程中,由3名标注人员根据标注标准对语料进行同时标注。在遇到标注不同的情况时,三名人员经过讨论后,把一致同意的结果作为标准标注。宏观汉语篇章树库(MCDTB)目前已标注了 97 个篇章的宏观篇章结构(选取 CTB8.0语料中前 100 篇,去掉段落数为 1的不能形成段落间关系的3 篇),共标注了 533 个段落之间438 个关系(其中多元关系都转换为二元关系保存),统计数据如表1所示。

表1 宏观汉语篇章树库宏观篇章标注情况
续表
在标注格式上,宏观汉语篇章树库(MCDTB)采用XML格式存储,以篇章的主题(DiscourseTopic)、短摘要(LEAD)、长摘要(ABSTRACT)、篇章关系(RELATION)、段落主题句(ParagraphTopic)为标注对象,并针对篇章关系标注了篇章关系层级(Layer)、篇章关系类型(RelationType)、篇章关系主次(Center)、篇章关系位置(ParagraphPosition)、父关系节点(ParentId)和子关系节点(ChildList)等,具体形式如图4所示。

图4 标注语料实例保存结果(chtb_0056.nw.raw)
篇章主次关系经过二元关系转换后,具体的统计数据如表2所示。通过表中数据可以看出,宏观篇章主次类型S-P的数目十分稀少,只占到了全部数据的4.79%。而P-S类型和M-P类型数量大致相当。考虑到本任务是识别汉语宏观篇章主次关系,根据李锦和廖开洪[15]的统计,在汉语文章中,篇章单元中重要部分在前的情况占70%。而本文使用的新闻类篇章,因为体裁原因,主要内容在前若干段描述的比例更大,符合自然分布规律,因此本文未对数据不平衡问题进行处理。

表2 篇章主次关系统计表
3 宏观篇章主次关系识别框架
3.1 宏观篇章主次关系计算模型
在处理宏观篇章主次关系上,本文把篇章主次关系的识别看作是一个分类问题。篇章主次关系中,多数情况都是二元主次关系,本文用一个元组来表示([Arg1,Arg2],label),其中Arg1和Arg2表示一个篇章主次关系的两个篇章单元,label表示两个篇章单元间的主次关系,正如图2中的关系R3。但是也存在像R2这样的多元主次关系,本文用([Arg1,Arg2,…,Argn],label)来表示。为了统一化表示篇章主次关系,本文把所有的多元关系都转换为二元关系。以R2为例,其元组表示为([c,d,e],M-P),经过转换后,其表示形式为([c,d],M-P)、([d,e],M-P)。
这样,最终的问题就转换为给定篇章单元Arg1与Arg2,判断两个篇章单元之间的主次关系的三分类(P-S、S-P、M-P)问题。
在特征选取上,Joty[9]、Feng[11]、Chu[13]等使用词汇、句法、文本结构等信息作为特征,而没有使用语义信息,并且上述研究都是在句内和句间进行主次关系的识别,即微观篇章主次关系。
本文的研究重点是宏观篇章主次关系,其篇章基本单元是自然分割的文章段落,相较于微观篇章主次关系的研究,更应该注重段落之间的语义关系。考虑到词及词性等特征相对于段落的语义来说颗粒度较小,而篇章单元与主题的相似度可以在更高层次上表现出篇章单元所涵盖的主要语义信息,因此本文将篇章单元与篇章主题的相似度作为一个重要特征,并提出了基于word2vec[16]和基于LDA[17]的两种主题相似度的计算方法。
3.2 基于word2vec的主题相似度算法
基于word2vec的主题相似度是计算篇章单元Arg1与篇章主题的语义相似度Score1、篇章单元Arg2与篇章主题的语义相似度Score2。该算法使用word2vec算法得到w2vCTB模型,再通过该模型获取目标词向量,在徐帅[18]的句子与句子之间的语义相似度计算方法的基础上,使用式(1)~(3)实现篇章单元与篇章单元的语义相似度计算,分别得出两个篇章单元与篇章主题之间的语义相似度。w2vCTB模型使用的训练语料为CTB8.0前5 558篇文章。表3为主题相似度获得过程中部分符号所表示的含义。

表3 主题相似度相关符号及含义
在MCDTB语料库的宏观篇章关系中,本文把篇章标题作为篇章主题,由此计算两个篇章单元与篇章主题的语义相似度。记篇章标题为篇章单元Arg0,则要计算的为篇章单元Arg0与篇章单元Arg1和篇章单元Arg0与篇章单元Arg2之间的语义相似度。
如式(1)所示,定义两个单词的语义相似度为余弦相似度Similarity(Wi,Wj),其中Vi、Vj分别为单词Wi、Wj通过w2vCTB模型获得的词向量。如式(2)所示,定义篇章单元i里的第n个单词对于篇章单元j的最大映射相似度为MaxSiminj。如式(3)所示,定义篇章单元i和篇章单元j间的语义相似度为Score。
3.3 基于LDA的主题相似度算法
基于word2vec的主题相似度算法使用篇章标题作为篇章主题,当篇章标题不能较好地表现出真正的篇章主题时,就会出现主题偏差现象。为了弥补这一偏差,本文提出了基于LDA的主题相似度算法。
基于LDA的主题相似度是计算篇章单元Arg1与该篇章单元所在的篇章全文Textall的相似度LDAScore1、篇章单元Arg2与该篇章单元所在的篇章全文Textall的相似度LDAScore2。LDACTB模型是使用Hoffman[19]提出的LDA算法对CTB8.0中全部的新闻语料(篇章编号为0001-0325、0400-0454、0500-0540、0600-0885、0900-0931、4000-4050)训练所得。本文使用训练好的LDACTB模型对篇章单元Arg1、篇章单元Arg2和篇章全文Textall 进行主题分类,并选取分类结果中概率最大的前四个主题种类作为其主题集合ThemeSet1、ThemeSet2和ThemeSetall。LDAScore1、LDAScore2的计算方法如式(4)、(5)所示。
3.4 特征选择
在宏观篇章主次关系分类的任务上,由于目前还没有相应的基准系统,本文使用了Joty[9]、Feng[11]、Chu[13]中使用的部分组织结构特征作为基准系统来进行比较,并在基准系统的基础上添加了基于word2vec和LDA的主题相似度作为语义特征,记基于word2vec的主题相似度特征为SimW2V,基于LDA的主题相似度特征为SimLDA,因此最终使用了表4所示的3组特征。

表4 本实验使用的特征集合
4 实验
4.1 实验设置
本实验使用自然语言处理工具(NLTK)中的最大熵分类器(nltk.classify.maxent)*http://www.nltk.org/构建了宏观篇章主次关系识别模型,参数均使用默认选项。数据集大小为438条宏观篇章关系,考虑到小样本训练集的不稳定性,实验采用了十倍交叉验证,即把原数据集按照类别比例均分为10份,其中1份作为测试集,剩余9份作为训练集,并进行10次实验。
本实验使用四组不同的特征集组合进行对比验证。基准系统使用组织结构特征,第二组和第三组在基准系统的特征上分别添加了基于word2vec的主题相似度和基于LDA的主题相似度作为语义特征,第四组则在基准系统基础上,同时添加了基于word2vec的主题相似度特征和基于LDA的主题相似度特征。
4.2 实验结果
最终的实验结果如表5所示,表中的准确率(Precision)、召回率(Recall)、F1值(F1-score)分别是3种主次关系分类结果中标准Precision、Recall和F1-score的加权平均,正确率(Accuracy)为使用式(6)计算所得。

表5 采用不同特征集的实验结果(10次实验平均结果)
从表5中可以看出,使用了组织结构、基于word2vce的主题相似度和基于LDA的主题相似度特征的第四组在准确率、召回率、F1值和正确率上均达到最好值,相较于未添加语义特征的基准系统,分别提升了1.2%、2.0%、1.7%和1.81%。
第二组和第三组较基准系统都有了一定的性能提升,这证明了语义特征对于宏观篇章主次的识别具有积极作用。而融合了两种主题相似度的第四组最终取得最好性能,其原因是基于word2vec的主题相似度和基于LDA的主题相似度在不同维度上计算语义相似度,两者在语义层面形成互补,因而增强了模型识别宏观篇章主次关系的能力。
但是,对于取得最好性能的第四组来说,不同的篇章主次类型,其表现也并不相同,如表6所示。

表6 第四组的分类结果情况统计表(10次实验平均结果)
各类别的情况表现出一种不平衡的分布。对于样本数量稀少的S-P类型,模型基本没有识别出此类别,通过对实验结果的分析后发现,一方面是因为其样本数量较少,模型没有学习到应有的特征。另一方面,S-P类型两个篇章单元包含的段落数大致相等,因此从结构上,容易被判别为M-P类型。另外,S-P类型多半为因果关系或者评价关系,对于一个篇章而言,事件的原因重要还是事件的结果重要,或者事件本身重要还是事件评价重要,通过主题相似度很难区分,在人工进行语料标注时,也存在一定的主观误差。
相比之下,P-S类型和M-P类型的识别效果较为良好,通过表7的混淆矩阵可以看出,P-S类型和M-P类型没有误分类到S-P类型中,除了S-P类型被误分类到P-S和M-P类型外,本模型的性能损失主要在于P-S类型与M-P类型之间的混淆。

表7 第四组实验结果的混淆矩阵(10次实验平均结果)
5 结论与展望
实验结果证明,在宏观篇章主次关系识别的任务上,主题相似度特征能够表现出各篇章单元与篇章主题之间的密切程度,提升了宏观篇章主次关系识别的性能。本文提出的融合了基于word2vec的主题相似度和基于LDA的主题相似度的主次关系识别方法在实验中取得了最好的性能表现,其准确率、召回率、F1值和正确率分别达到了79.0%、81.9%、79.9%和81.82%,相比较只含有组织结构特征的基准系统,分别提升了1.2%、2.0%、1.7%和1.81%。
在接下来的工作中,我们将继续标注MCDTB语料库,完善标注规则,扩大数据集,并针对不平衡数据集出现的原因及应对策略、寻找富文本特征集等问题进行相应的探究。
[1]褚晓敏,朱巧明,周国栋. 自然语言处理中的篇章主次关系研究[J]. 计算机学报, 2017, 40(4): 842-860.
[2]Zou B, Zhou G, Zhu Q. Negation focus identification with contextual discourse information[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. Baltimore, Maryland, USA: Association for Computational Linguistics, 2014: 522-530.
[3]Cohan A, Goharian N. Scientific article summarization using citation-context and article’s discourse structure[C]//Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon, Portugal: Association for Computational Linguistics, 2015: 390-400.
[4]Liakata M, Dobnik S, Saha S, et al. A discourse-dri-ven content model for summarising scientific articles evaluated in a complex question answering task[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Seattle, Washington, USA: Association for Computational Linguistics, 2013: 747-757.
[5]Mann W C, Thompson S A. Relational propositions in discourse[J]. Discourse Processes, 1986, 9(1): 57-90.
[6]Mann W C, Thompson S A. Rhetorical structure theory: A theory of text organization[J]. Text-Interdiscip-linary Journal for the Study of Discourse, 1987, 8(3):243-281.
[7]Van Dijk T A. Macrostructures: An interdisciplinary study of global structures in discourse, interaction, and cognition[M]. Hillsdale, New Jersey, USA: Lawrence Erlbaum Associates, Inc., 1980.
[8]Hernault H, Prendinger H, Ishizuka M. HILDA: A discourse parser using support vector machine classification[J]. Dialogue & Discourse, 2010, 1(3): 1-33.
[9]Joty S R, Carenini G, Ng R T, et al. Combining intra-and multi-sentential rhetorical parsing for document-level discourse analysis[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. Sofia, Bulgaria: Association for Computational Linguistics, 2013: 486-496.
[10]Joty S, Carenini G, Ng R T. A novel discriminative framework for sentence-level discourse analysis[C]//Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Jeju Island Korea: Association for Computational Linguistics, 2012: 904-915.
[11]Feng V W, Hirst G. A linear-time bottom-up discourse parser with constraints and post-editing[C]//Proceedings of the 52nd Annual Meeting of the Association for Association for Computational Linguistics. Baltimore, Maryland, USA: Association for Computational Linguistics, 2014: 511-521.
[12]Feng V W, Hirst G. Text-level discourse parsing with rich linguistic features[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics. Jeju, Republic of Korea: Association for Computational Linguistics, 2012. 60-68.
[13]Chu X, Wang Z, Zhu Q, et al. Recognizing nuclearity between Chinese discourse units[C]//Asian Language Processing (IALP). 2015 International Conference on. IEEE, 2015: 197-200.
[14]李艳翠. 汉语篇章结构表示体系及资源构建研究[D]. 苏州:苏州大学, 2015.
[15]李锦,廖开洪. 汉英语篇主题与段落结构模式的比较研究[J]. 暨南学报(哲学社会科学版),2001,23(5):89-93.
[16]Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[J]. Advances in Neural Information Processing Systems, 2013,(26): 3111-3119.
[17]Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3(Jan): 993-1022.
[18]徐帅. 面向问答系统的复述识别技术研究与实现[D].哈尔滨:哈尔滨工业大学,2009.
[19]Hoffman M, Bach F R, Blei D M. Online learning for latent dirichlet allocation[C]//Advances in Neural Information Processing Systems. Hyatt Regency, Vancouver CANADA: Neural Information Processing Systems Foundation, Inc., 2010: 856-864.
猜你喜欢
小学阅读指南·低年级版(2022年5期)2022-05-09
通信技术(2021年12期)2022-01-25
小学阅读指南·低年级版(2020年9期)2020-10-12
阅读(快乐英语高年级)(2020年9期)2020-01-08
散文诗(2017年17期)2018-01-31
中国机电工业(2016年5期)2016-12-01
中国机电工业(2015年5期)2015-02-28
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
中文信息学报(2012年2期)2012-06-29
