
结合全局向量特征的神经网络依存句法分析模型
2018-04-02 03:20王衡军司念文宋玉龙单义栋
通信学报 2018年2期
王衡军,司念文,宋玉龙,单义栋
结合全局向量特征的神经网络依存句法分析模型
王衡军1,司念文1,宋玉龙2,单义栋1
(1. 解放军信息工程大学三院,河南 郑州 450001;2. 73671部队,安徽 六安 237000)
利用时序型长短时记忆(LSTM, long short term memory)网络和分片池化的卷积神经网络(CNN, convolutional neural network),分别提取词向量特征和全局向量特征,将2类特征结合输入前馈网络中进行训练;模型训练中,采用基于概率的训练方法。与改进前的模型相比,该模型能够更多地关注句子的全局特征;相较于最大化间隔训练算法,所提训练方法更充分地利用所有可能的依存句法树进行参数更新。为了验证该模型的性能,在宾州中文树库(CTB5, Chinese Penn Treebank 5)上进行实验,结果表明,与已有的仅使用LSTM或CNN的句法分析模型相比,该模型在保证一定效率的同时,能够有效提升依存分析准确率。
依存句法分析;图模型;长短时记忆网络;卷积神经网络;特征
1 引言
句法分析作为自然语言处理的一个重要环节,对于提升机器理解文本的准确率具有重要作用。依存句法分析因其灵活简洁、易于理解和标注等特点而受到大量研究人员的青睐,准确率也不断提升。文献[1]最早提出将依存句法分析归结为从一个完全有向图中寻找最大生成树问题,采用在线学习算法学习边的权值,模型解码利用Eisner算法[2],通过自底向上不断合并低阶子树,构成更高阶的子树,直到找出最优依存句法树结构。
传统的基于图的依存句法分析[1~6]采用线性模型计算树的分值,树的分值由满足特定结构的子树分值之和确定,子树的分值由该子树的特征函数和相应权向量乘积得到。典型的线性模型依存分析器如MSTParser[1]已经能够达到一定的准确率,然而,这类传统模型依靠人工设计的特征模板提取特征,存在明显不足:1) 特征提取过程受限于固定的特征模板,难以获取实际真正有效的特征;2) 特征模板的设计依赖于大量的领域知识,只有通过特征工程进行不断的实验选择,来提升准确率;3)所提取的特征数据稀疏,且不完整。
近年来的研究多将深度神经网络(DNN, deep neural network)应用到依存分析中[7~11],采用分布式词向量作为输入,利用DNN从少量的核心特征(词和词性)自动提取复杂的特征组合,减少了人工参与的特征设计,取得了比传统模型更好的效果。这个过程中,DNN被用于自动特征提取,训练出一个非线性得分模型,输出任意2个词之间的依存关系得分,模型解码依然采用传统的最大生成树算法。
文献[7]提出了一种前馈神经网络(FNN, feed-forward neural network)依存分析模型,但由于FNN通常受到窗口大小的限制,和传统的n-gram语法特征类似,只能利用有限的上下文信息。
文献[8,9]采用时序型长短时记忆网络建立依存分析模型,当前时刻的网络输出由当前时刻输入和前一时刻输出共同决定,通过这样的循环结构,理论上可以利用到无限长度的上下文信息。实验结果验证了LSTM比FNN的依存分析效果更好。
文献[10]采用卷积神经网络进行高阶基于图的依存分析,试图利用CNN从句首到句尾的卷积操作,克服FNN的窗口大小限制,提取更大范围的上下文特征,改善基于图的依存分析在计算子树得分上的局部决策问题。与文献[7~9]的最大化间隔训练不同,本文采用了概率标准进行训练,将所有依存树的得分概率化,考虑的情形更加一般,在一定程度上提升了模型准确率。但是其使用的三阶模型复杂度较高,分析效率受到一定限制。
文献[11]将CNN和LSTM结合进行依存分析,利用CNN提取字符特征,形成字符级别的向量表示,再结合词向量共同输入LSTM。与文献[10]类似,采用对数似然的概率标准进行训练。由于字符级别特征的加入,该模型取得了更好的结果。
上述的依存分析模型中单独使用LSTM,只能提取到词向量特征,只有文献[11]同时结合了CNN和LSTM,可以分别提取字符向量特征和词向量特征,效果上也达到了最佳。实际上,由于CNN在句子结构建模上效果很好[12,13],可以用来提取整句级别的全局特征,这与文献[11]利用CNN提取字符特征的应用恰好相反。基于该思路,本文将CNN和LSTM结合进行依存分析。首先,预训练的分布式词向量用来表示单个词语,作为网络输入。然后,将标准的双向LSTM和经过改进的CNN结合使用,与文献[11]不同,本文的CNN和LSTM以并行方式进行特征提取,分别提取词向量特征和全局向量特征,其中,全局向量特征关注支配词与被支配词的上下文特征以及整个句子中的位置和相对顺序等特征,形成一个包含整句信息的全局向量。最后,输入到FNN中并行训练,输出依存弧的得分。模型训练中采用基于概率模型的训练方法,与最大化间隔训练方法相比,更充分地利用所有的可能依存树进行参数更新。
为了验证模型的依存分析性能,在宾州中文树库上进行依存句法分析实验。实验结果表明,本文提出的结合LSTM和CNN的特征提取方法与单独采用LSTM或CNN的模型相比,能够利用更加丰富的特征,有效提升依存分析准确率。同时,基于概率模型的训练方法在效果上也优于最大化间隔训练方法。
2 相关研究
2.1 基于图的依存分析
依存句法分析的目的是为每个句子建立一棵有向的、带根节点的依存句法树。一棵标准的依存句法树结构如图1所示,树节点为句子中的词语,节点之间的有向弧(依存弧)表示父节点(支配词)和子节点(被支配词)的依存关系及类型,依存关系类型用来表示2个词之间的句法或语义关系。句子下方标注了词语的词性和在句中的相对位置。
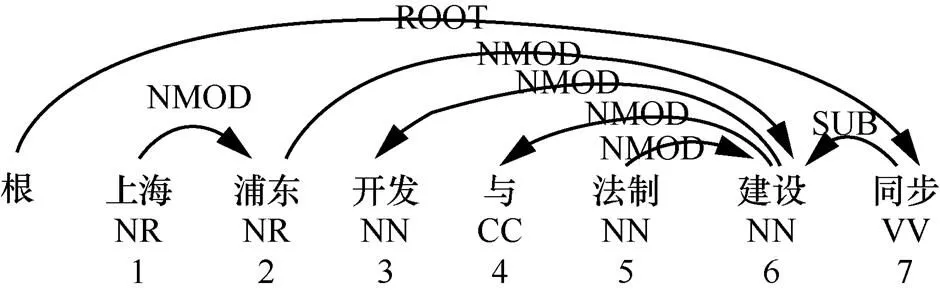
图1 依存句法树结构
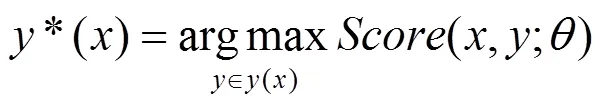
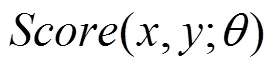
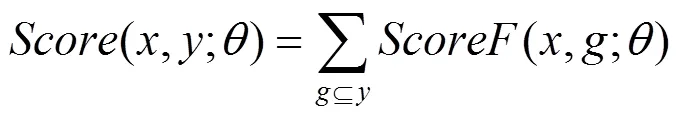

根据子树中包含的依存弧数目,可将子树划分为不同的阶数。根据依存分析模型所采用的最大子树的阶数,可将其划分为一阶[1]、二阶[3,4]、三阶[5]以及更高阶模型[6]。文献[1]最早提出了一阶线性模型,其假设弧与弧之间没有关联,单个弧相当于一棵子树,依存句法树分值等于该树所包含的所有依存弧分值之和。由于模型阶数越高,在分析准确率上升的同时,大量的子树特征计算极大地提升了模型复杂度,降低了效率。因此,在准确率和效率兼顾的前提下,目前一阶和二阶模型的研究和应用较为广泛。
2.2 神经网络依存分析
近年来,基于深度学习的方法在自然语言处理中应用广泛。深度神经网络(DNN, deep neural network)结合词的分布式向量(distributed embedding)作为输入,在词性标注[14]、命名实体识别[15]、文本表示[16]、机器翻译[13]等任务上实现了较大的提升。关于DNN在依存句法分析领域的应用,近年来有许多深入的研究工作。由于DNN在特征提取和表示上的优势,极大缓解了传统方法的特征依赖问题,DNN自动提取的特征优于人工设计的特征,使依存分析在性能上有较大提升。因此,当前主要关注神经网络下的依存分析模型。
基本的前馈神经网络(FNN, feed-forward neural network)依存分析模型如图2所示,由输入层、隐含层和输出层构成,其中,隐含层可由多个层构成。文献[17]首次采用FNN对基于转移的依存分析进行建模,将stack和buffer中主要元素(共18个)的分布式向量送进输入层,采用交叉熵目标函数训练一个神经网络分类器,为每次所要采取的转移动作做分类决策。与传统的使用大量特征模板相比,该模型特征集合仅包含18个元素,极大简化特征设计过程,保证一定的分析准确率,并且速度上有很大提升。在文献[17]的基础上,文献[18]将FNN拓展到更深层的模型,并在最后一层增加感知层,采用柱搜索解码,进一步提升分类器的准确率。文献[19]同样使用FNN模型,采用全局归一化策略,设计基于特定任务的转移系统,实现FNN模型下效果最佳的基于转移的依存分析器。在基于图的依存分析方面,文献[7]将FNN应用到基本的图模型中,训练出一个非线性的得分模型,输出每个依存弧分值,采用最大生成树算法从图中搜索最佳树结构。
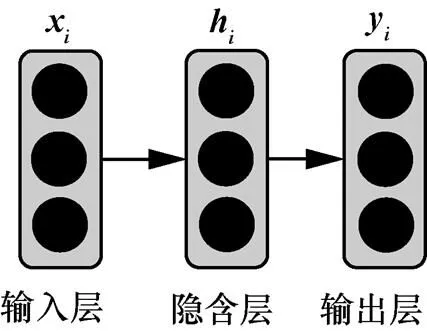
图2 FNN依存分析模型
由于FNN存在窗口大小限制,研究者们采用具有循环结构的时序型LSTM神经网络进行依存分析。与FNN相比,LSTM更加擅长处理序列化数据,可以很好地利用输入序列的历史信息,分析其整体逻辑关系。与普通的循环神经网络(RNN, recurrent neural network)相比,LSTM引入了记忆核(memory cell)和门机制,解决梯度消失/爆炸问题,可以学习到更长距离的依存关系特征。文献[20]首次将LSTM应用到基于转移的依存分析中,利用LSTM分别为转移系统中的堆栈建模,取得了比FNN更好的效果。文献[9]提出了更加一般的基于bi-LSTM的特征提取器,采用特征提取器获取词语及其上下文特征表示,并将其应用到基于转移和基于图的依存分析框架中,都取得了很好的效果,如图3所示。文献[8]采用LSTM提取词向量特征后,进一步加入了一种分段向量,该分段向量由单向LSTM的隐含层向量相减获得,理论上包含句子层面的全局特征,实验也表明其能够提升长距离依存分析的准确率。
最近的依存分析模型将注意力机制引入LSTM神经网络,如文献[21]提出的基于双向注意力的神经网络依存分析模型,文献[22]提出的支配词动态选择策略的依存分析模型。其中,文献[22]设计了双向仿射得分函数,采用交叉熵目标函数训练,实现目前最好的依存分析效果。
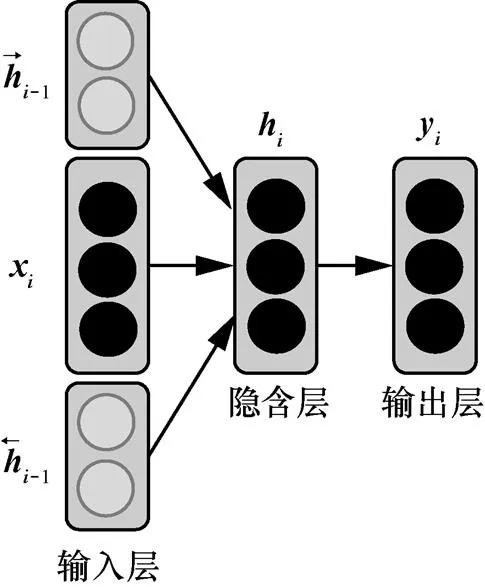
图3 bi-LSTM依存分析模型
3 结合全局向量特征的依存分析模型设计
本文提出的依存分析模型基于当前广泛应用的LSTM神经网络,在此基础上,在模型输入层之后增加特征层,特征层中引入一种全局向量特征,设计分片池化的CNN提取该全局特征向量。通过结合LSTM提取的上下文词向量特征以及CNN提取的句子级别的全局向量特征,使句法分析模型在不增加所使用的基本特征的情况下,充分利用到更丰富的特征组合,提升分析准确率。
具体的模型结构如图4所示。主要分为以下几个部分。
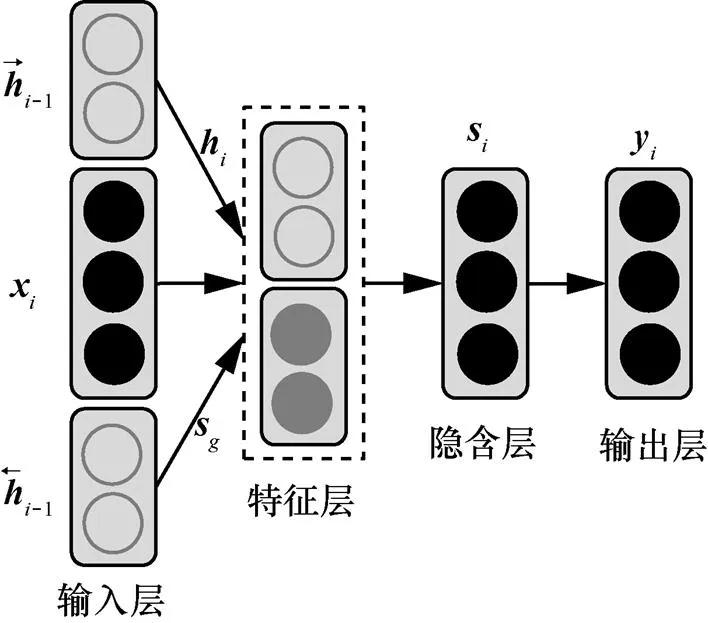
图4 加入特征层的bi-LSTM依存分析模型
1) 输入层。对于给定句子中的每个词语,在预训练的词向量矩阵中进行索引,生成相应的词向量序列作为模型输入。
2) 特征层。对输入的词向量进行特征提取,采用bi-LSTM和分片池化的CNN分别提取上下文词向量特征和全局向量特征。
3) 隐含层和输出层。对提取后的特征进行组合和非线性变换,输出层给出依存弧的分数值。
下面分别就特征层的词向量特征、全局向量特征和基于概率的训练方法进行详细介绍。
3.1 词向量特征
由于分布式词向量本身含有词语之间相似度信息,对词性标注和句法分析等任务是很好的原始特征。本文采用预训练的分布式词向量作为输入,然后采用bi-LSTM对其进行处理,提取上下文词向量特征,该过程如图5所示。
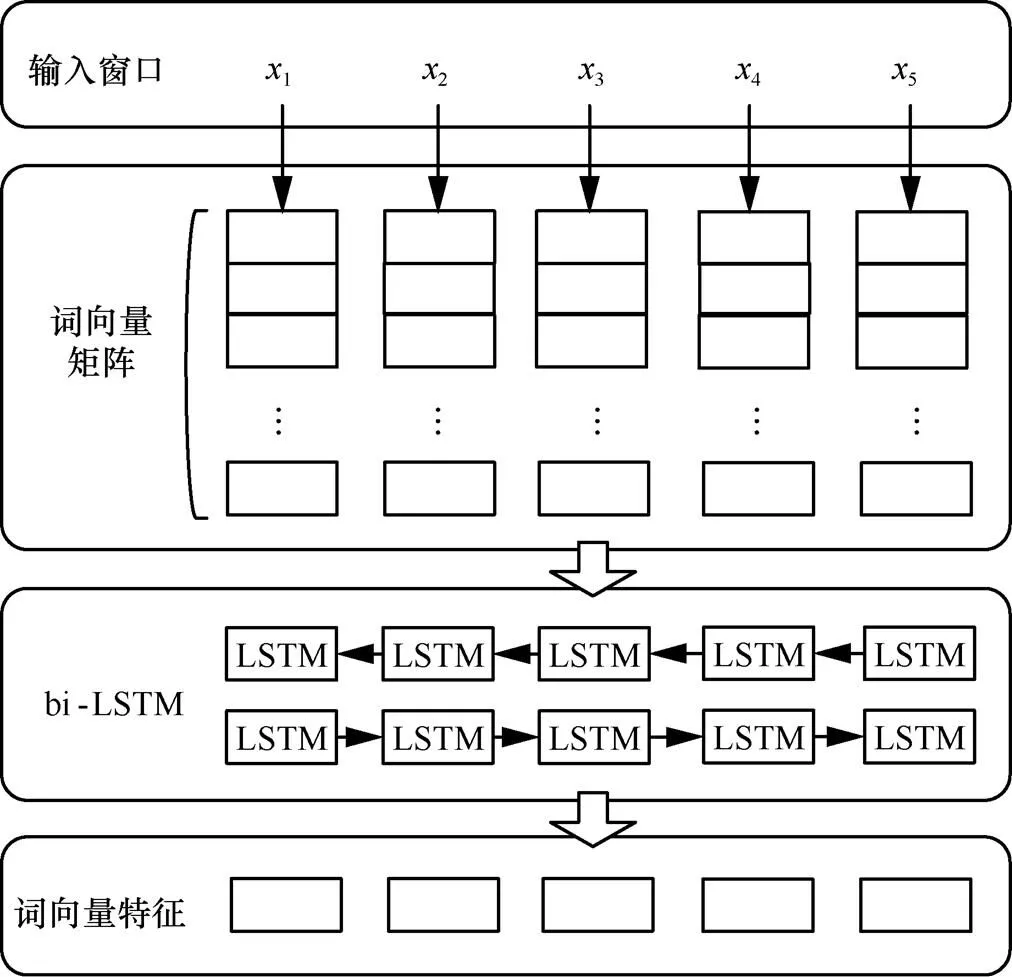
图5 bi-LSTM提取词向量特征过程
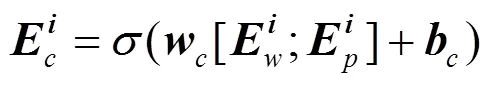
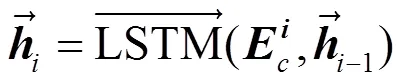
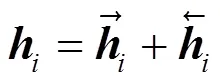
bi-LSTM输出向量聚合了词语前向和后向的上下文信息,将其作为词向量特征,与原始词向量相比,融入了更加丰富的上下文信息,能够更好地利用长距离依赖特征。
3.2 全局向量特征
卷积神经网络在自然语言处理中应用广泛,文献[12]提出在机器翻译任务中,采用CNN对句子进行建模,通过分块池化最大限度保留原始句子的语义信息,得到全局级别的句子向量表示。依存句法分析中,支配词和被支配词的上下文信息对分析其搭配关系十分重要,充分利用该特征有利于提升依存分析准确率[1,7]。为提取这类特征,借鉴文献[12]的思想,通过改进标准的CNN结构,将其应用于提取句子级别的全局向量特征,如图6所示。
卷积神经网络的工作过程分为以下3个部分。
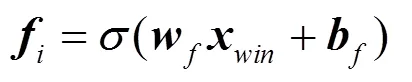
其中,向量表示大小为win的窗口内的词向量,为权重矩阵,为偏移向量,函数为tan h非线性激活函数。每个filter输出向量的维度需要和句子长度保持一致,为此,采取通常的做法,对句子首尾分别填充零向量。
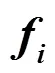

图7 分片池化过程
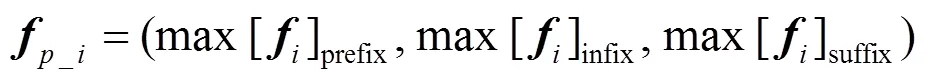
3) 输出全局向量。为了得到最终的输出向量,池化层后紧跟着一个全连接层,将该向量矩阵映射到输出层,得到输出向量,即全局向量特征。
由于CNN在池化过程中采用了分片池化方式,针对支配词和被支配词的位置进行分片池化,使得到的向量包含支配词和被支配词之间的依赖关系、相对位置、在整个句子中的位置等特征信息,并且采用多个filter且每个filter扫描整个句子最终得到该向量,因此称作该句子的全局向量特征。
模型的特征层将特征词向量和全局向量特征进行连接,输入一个简单的FNN进行训练。FNN的输出是一个||维的向量(为依存关系类型集合),每一维即代表一种依存关系类型的得分。
3.3 基于概率的训练方法
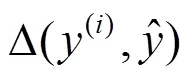
采用最大化间隔算法时,按照目标函数最小化的一般形式,将目标函数设置为[7,8]
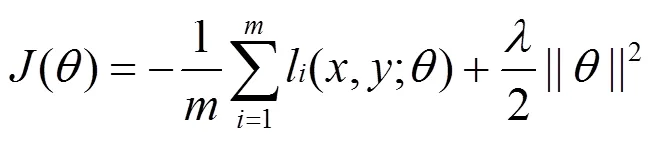
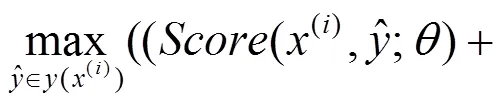
最大化间隔训练算法的优点是可以减少过拟合,同时并不需要太多额外的计算量。但是,在实际训练过程中,模型参数更新仅依赖于错误分析结果,即仅利用最佳预测树和标准树之间的误差,而直接忽略了其他可能的依存树对参数更新的作用,这样通过降低计算复杂度的方式,在一定程度上简化了模型的训练过程。
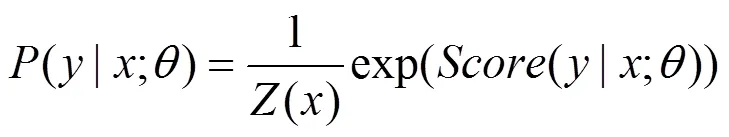
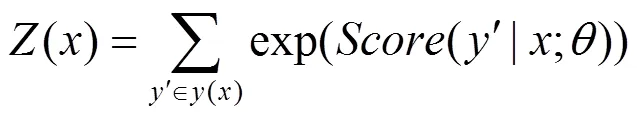
训练中的目标函数定义为
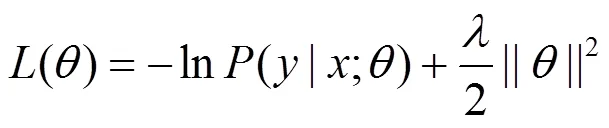
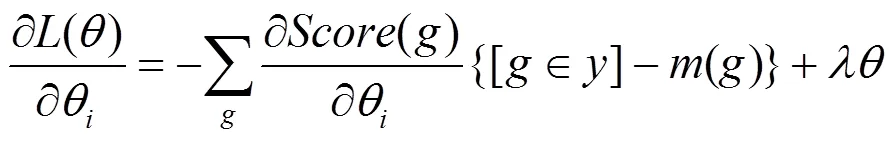
根据以上结果,目标函数可重新定义为
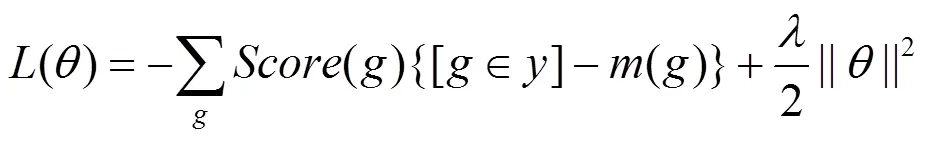
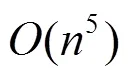
4 实验与结果分析
4.1 实验设置
1) 实验数据及评价指标
实验采用宾州中文树库数据集,该数据集由LDC语言数据联盟发布,语料主要来源于新华社和部分香港新闻等媒体,句子的平均长度为27个词,分别进行了分词、词性标注和短语结构句法树构建,共包含33种词性分类和23种句法标记。
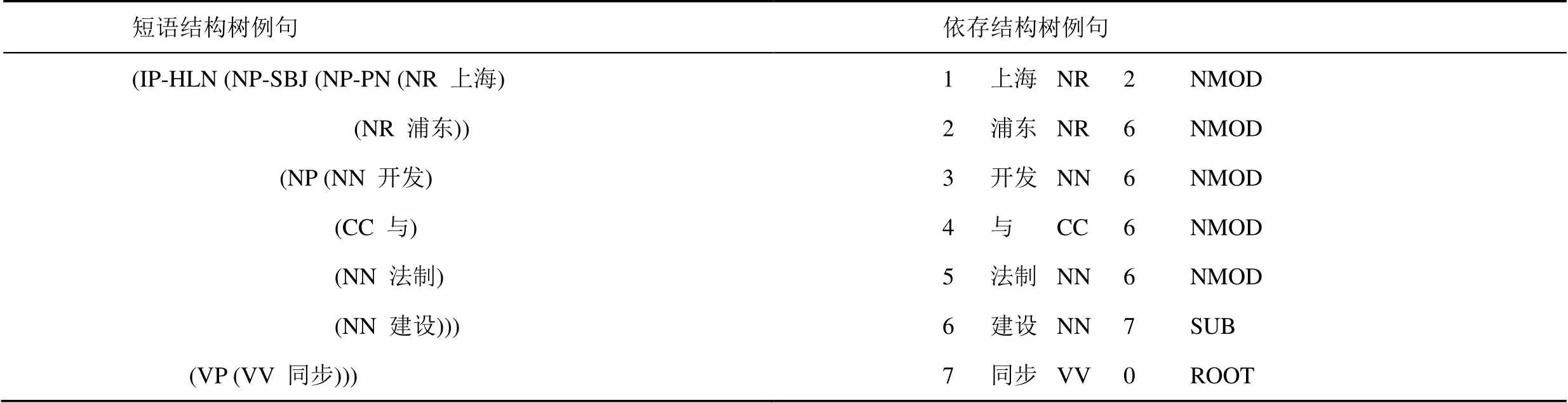
表1 采用Penn2Malt工具转换CTB5前后对比
由于CTB5数据集本身是短语结构句法树库,需要采用Penn2Malt工具将其转化为依存结构树库,在转换后的数据集上进行依存句法分析实验。实验中,采用标准分词和词性标注,利用其自带的支配词节点发现规则,找到每个词对应的支配词节点位置。表1给出了例句“上海浦东开发与法制建设同步”转换前后的句法结构对比。
其中,表1左侧为转换之前的短语结构树标注。右侧为转换为依存结构树后的标注,第1~5列分别表示词语顺序、词语、词性、支配词位置(0表示其支配词为ROOT虚根节点,其余从1开始)、与支配词之间依存关系类型。例如:词性NR、NN、CC、VV表示该词为专有名词、普通名词、并列连词、其他动词;位置标记2表示“上海”对应的支配词为“浦东”,位置标记0表示“同步”的支配词为ROOT,“同步”为该句的核心动词;句法关系标记NMOD表示复合名词修饰关系(上海,浦东),SUB表示主谓关系(建设,同步)。与该例句对应的依存句法树结构如图1所示。
按照前人工作中的做法[20],实验中将数据集划分为训练集、开发集和测试集,各部分统计及划分如表2所示。

表2 数据集统计及划分情况
在实验结果评价上,采用无标记依存正确率(UAS, unlabeled attachment score)和带标记依存正确率(LAS, labeled attachment score)作为依存分析结果评价指标,如式(16)和式(17)所示。


由于和标点符号有关的依存关系不包含额外的句法结构信息,对其进行统计的意义不大,因此,不考虑与标点符号相关的依存关系。
2) 预训练的词向量与参数初始化
实验中所用的预训练的词向量,采用谷歌公司的开源工具word2vec在Gigaword语料上训练得到。word2vec工具是一款简单高效的词向量训练工具,能够对大量语料分析,将词语映射到多维向量空间,输出词语的向量表示形式。输出的词向量包含丰富的词汇和语义关系,可以被用到许多自然语言处理工作中,例如句法分析、语义角色标注、机器翻译等。词向量维度根据训练时设置的参数而定,本文词向量维度设定为50维。表3为2个例句在生成的词向量矩阵中进行索引,得到对应的词向量数值(只列出了前8维部分数值)。词性向量和依存关系类型向量的维度设定为30,其元素值统一随机初始化在区间(−0.05, 0.05)内。模型中其他待初始化的权重矩阵和偏移向量等参数,根据所在层的向量维度具体确定。
3) 实验环境与流程
本文实验均采用python语言,在anaconda集成开发环境下的spyder软件平台进行程序编写。依存分析模型中调用的神经网络来源于DyNet动态神经网络工具包[23],该工具包由美国卡耐基梅隆大学等多所学校的研究人员共同开发,其中,包含了RNN、LSTM和CNN等常用的深度神经网络模型,主要面向基于深度学习的自然语言处理领域研究。同时,实验中参考了部分前人工作所设计的模型代码[9,20]。
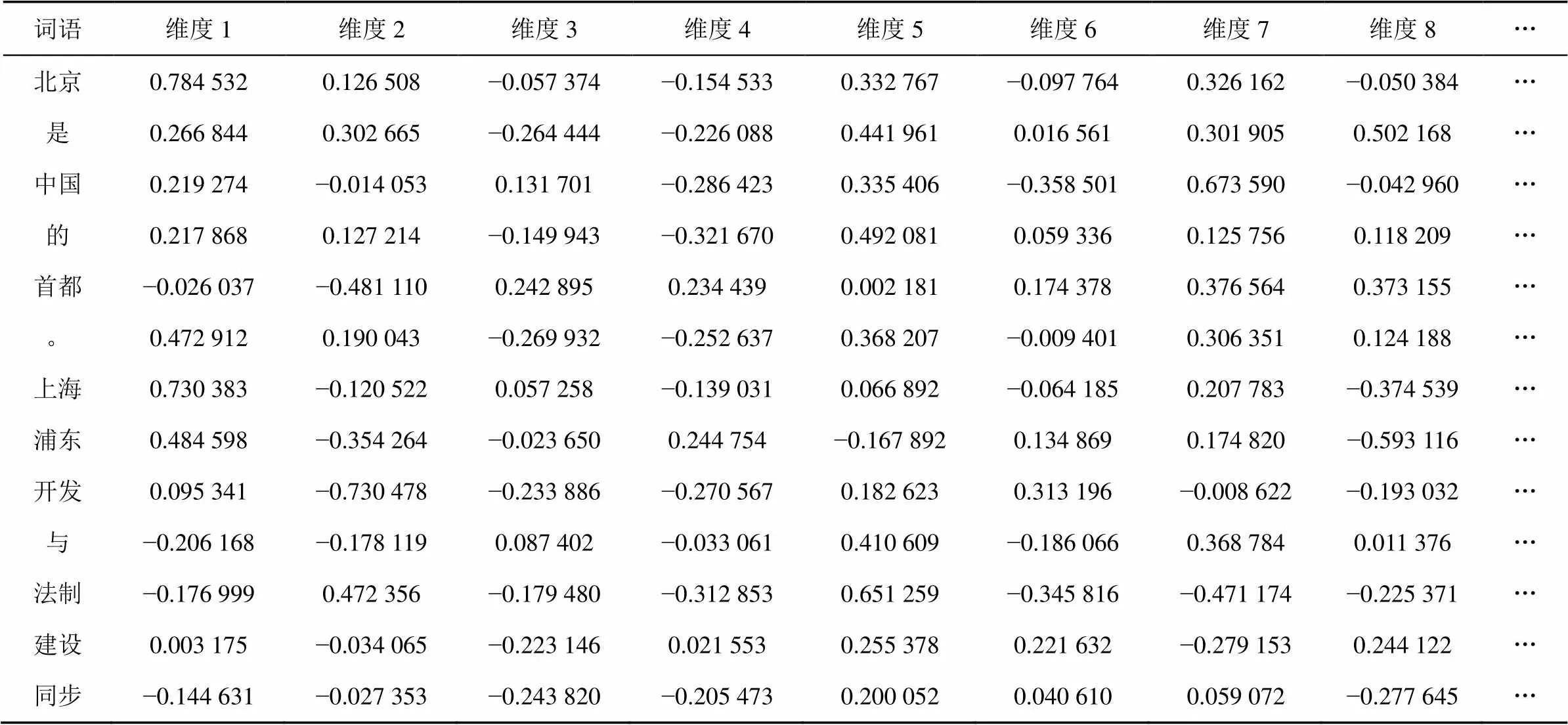
表3 预训练词向量维度数值
实验硬件环境为Core i7处理器,主频2.6 GHz,8 GB RAM,操作系统为64位Ubuntu 14.04。
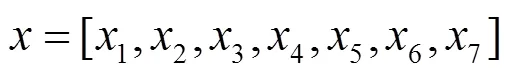
Step2 模型初始化。调用库中的LSTM函数,搭建模型结构,初始化模型的参数矩阵。
Step4 前向传播。经过前向传播直到输出层给出每2个词之间的依存弧分值,根据其构建该句对应的完全有向依存图,从图中搜索得到预测的相应依存句法树结构,计算()及()等。
Step5 反向传播及参数更新。计算目标函数并求其对各参数的偏导数,采用批次梯度下降法更新参数,每批样本训练结束后调整参数矩阵值,计算该批样本训练损失值。每个结束时计算整个的平均损失。设定大小,直到达到迭代次数为止,训练结束。
Step6 模型测试。从文件中加载训练后的模型参数,输入测试集中待分析句子,得出句子的依存句法结构,计算依存分析准确率。
从上述过程可以看出,相比于传统的线性依存分析方法,非线性的神经网络相当于完成了如下的功能。对句子从输入词向量开始,经过特征层提取和组合,计算出词语之间的依存关系得分,如式(18)所示。

以式(13)代替式(3),实现了采用神经网络计算依存弧的分值。神经网络的优势在于特征提取,而和已有的神经网络依存分析模型不同的是,本文中的模型在工作流程的Step3中,同时采用了bi-LSTM和CNN提取不同类型的特征,在Step5中使用了基于概率的训练方法,使模型在特征提取和模型训练上效果更佳。
4.2 实验结果及分析
本文提出的模型中,影响依存分析性能的主要因素包括3部分:词向量特征、全局向量特征和基于概率的训练方法。为了比较这3个因素的影响,分别设计了如下实验进行对比测试。
实验1 考察所提取的向量特征对依存分析准确率的影响,分别为词向量特征和全局向量特征。采用bi-LSTM提取词向量特征时,bi-LSTM隐层大小将影响到词向量特征的质量,因此,这里主要考察bi-LSTM隐层大小变化对依存分析结果的影响。对于全局向量特征,为了验证提取的全局向量特征的有效性,分别比较加入和不加入全局向量特征时,实验结果的非标记依存正确率值。综上,实验中通过改变bi-LSTM隐层大小,分别观察加入与不加入全局向量时的值,结果如图8所示。
从图8可以看出,分别采用基于概率的训练方法和最大化间隔训练算法的情况下,全局向量特征的加入都提升了依存分析的值,证明了该全局向量特征的有效性。同时也可以看出,bi-LSTM隐层大小影响到提取的词向量特征,进一步影响到依存分析结果。从图8(a)可以看到,隐层大小达到120后,值大小基本不再变化。
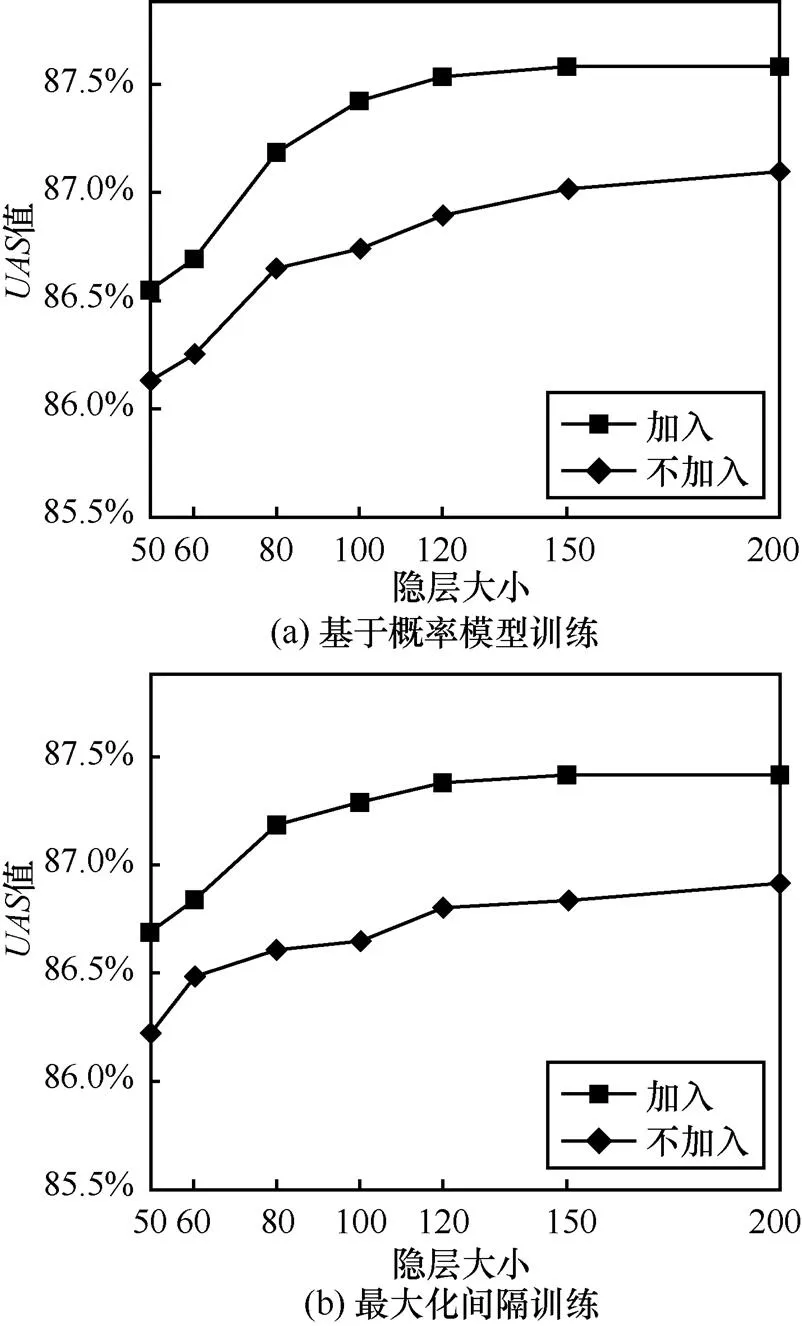
图8 不同隐层大小下的实验结果UAS值
实验2 考察基于概率的训练方法和最大化间隔训练算法在依存分析准确率上的影响。此时加入全局特征向量,分别观察2种训练方法下的值,如图9所示。从图9可以看出,随着隐层大小增大,2种训练方法下的值都在不断提升。同时,在bi-LSTM隐层较小时,最大化间隔训练方法效果较好;当隐层增大后,基于概率的训练方法对依存分析提供了更大帮助,其值超过了最大化间隔方法。在隐层大小为120时,基本不再有太大提升。
基于概率的训练方法思想受文献[6]启发,文献[10]也采用了类似的方法,将其应用到高阶的基于图的依存句法分析中。与它们不同的是,本文将其应用在一阶模型中,同时结合了bi-LSTM和CNN来提取不同的特征,在基于概率的训练下,依存分析效果更好,在一些指标上超过了这2篇文献,表4列出在相同数据集上的实验结果对比情况。
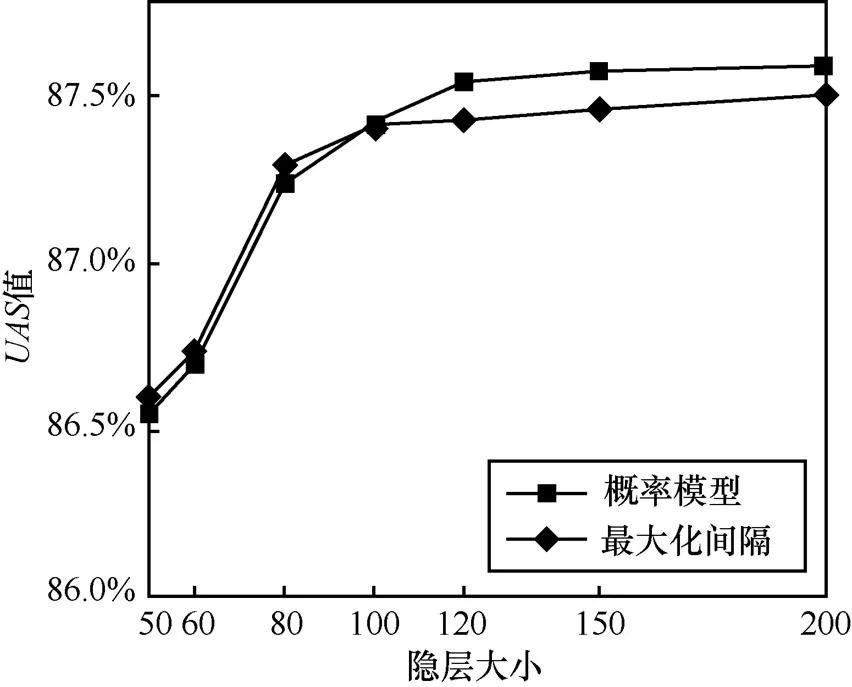
图9 不同训练方法的实验结果UAS值
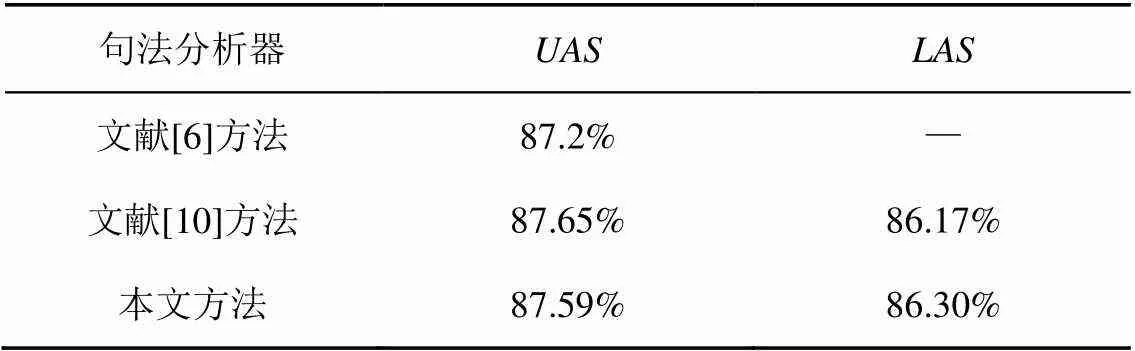
表4 依存分析结果对比
实验3 为了横向比较本文的依存分析模型性能,分析研究了目前已有的依存分析模型,通过实验结果对比依存分析准确率。在最终的对比实验中,选择准确率最高的模型参数设置,如表5~表7所示。

表5 bi-LSTM(前向)参数设置
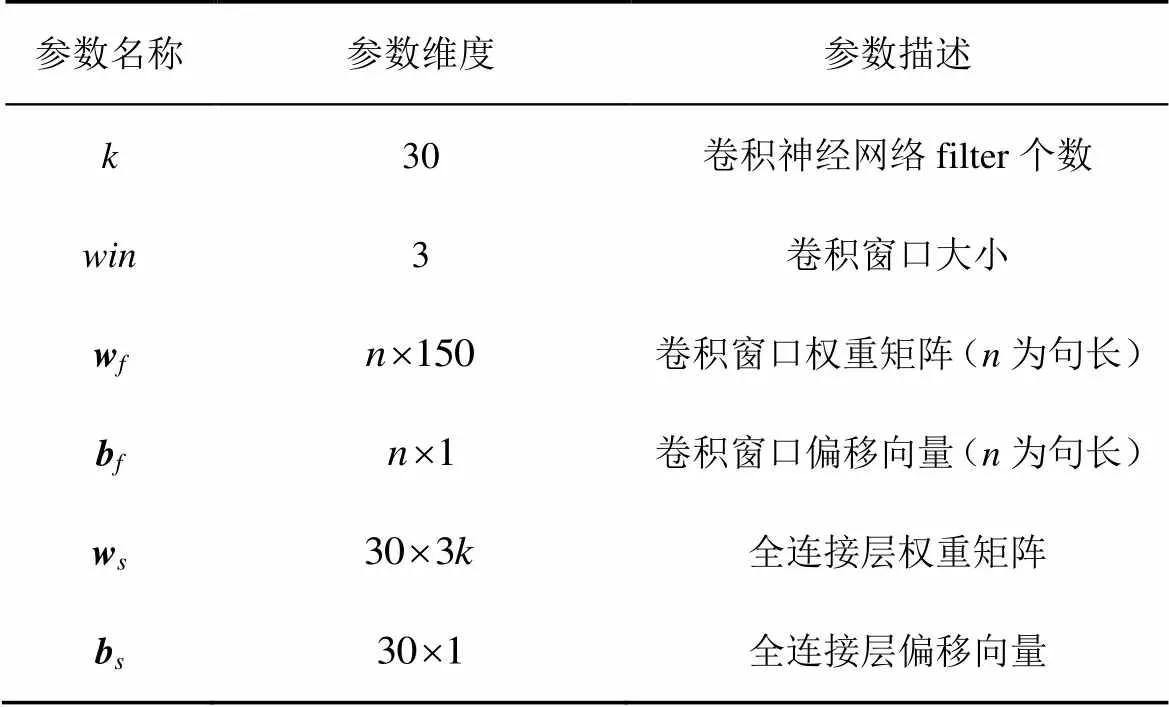
表6 CNN参数设置
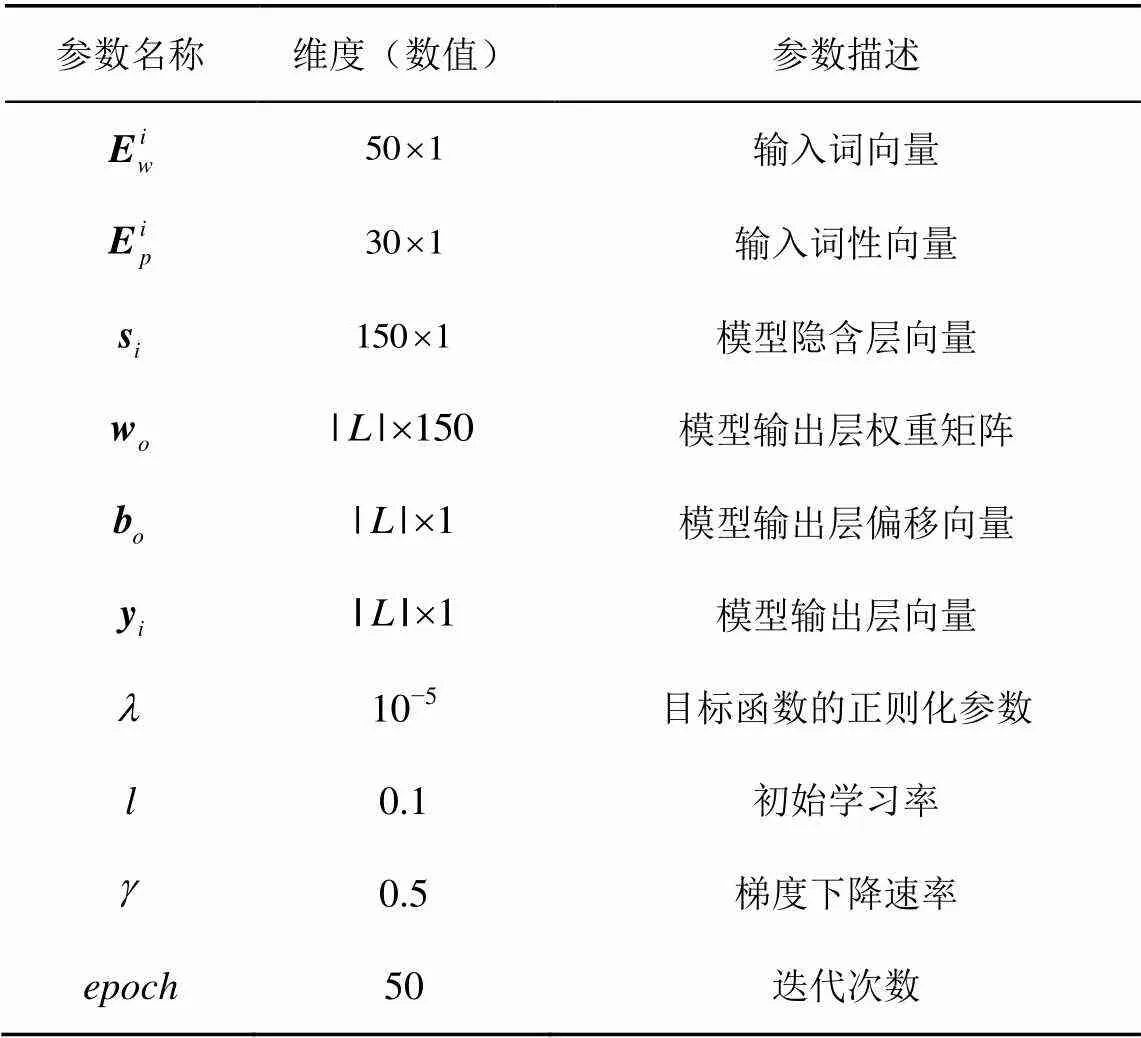
表7 其他参数设置与向量维度大小
图10给出了该设置下模型在训练集上的损失值变化,横坐标为训练过程中的迭代次数,每个内训练集训练完一次。下一个开始前重新打乱训练集中样本顺序,防止模型在训练集上的过拟合。纵坐标表示每个结束时,整个的平均训练损失大小。为了对比实验效果,图10给出了该设置下LSTM和bi-LSTM的训练过程,仅从训练效果上看,bi-LSTM+CNN模型损失值降到了最小,表明同时应用词向量特征和全局向量特征,对依存分析提供了更大的帮助。
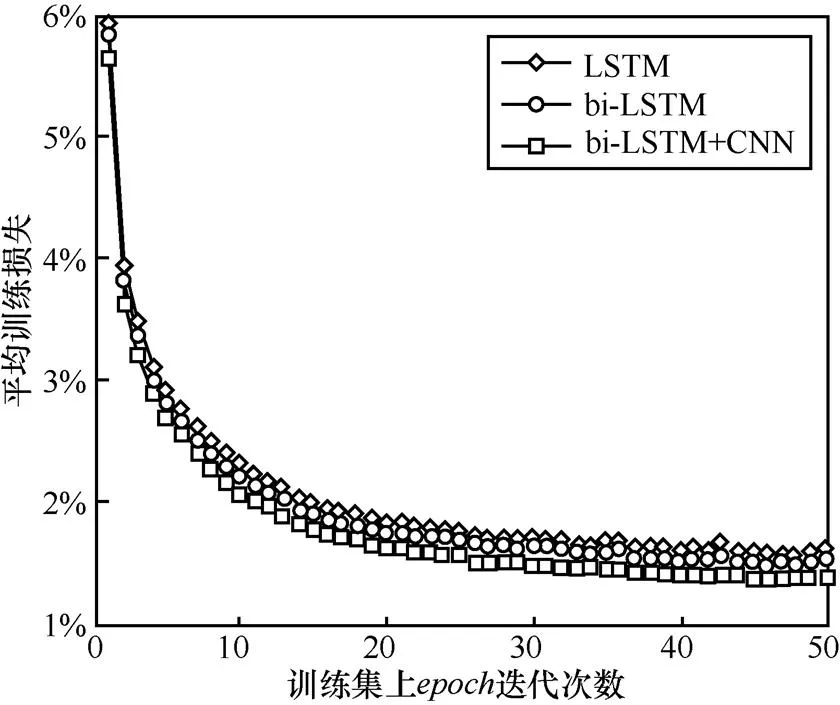
图10 训练过程每个epoch的平均损失值
为了验证本文方法相对于基线系统的性能提升,采用了经典的依存分析器进行对比测试:基于图的依存分析器MSTParser和基于转移的依存分析器MaltParser,表8列出了详细的测试结果。此外,本文还与部分准确率较高的中文依存分析器进行了详细比较,分别包括:线性模型下基于转移[24]和基于图[25]的依存分析系统;与本文类似的,采用LSTM[8,9,11,20]或CNN[10,11]的依存分析系统。
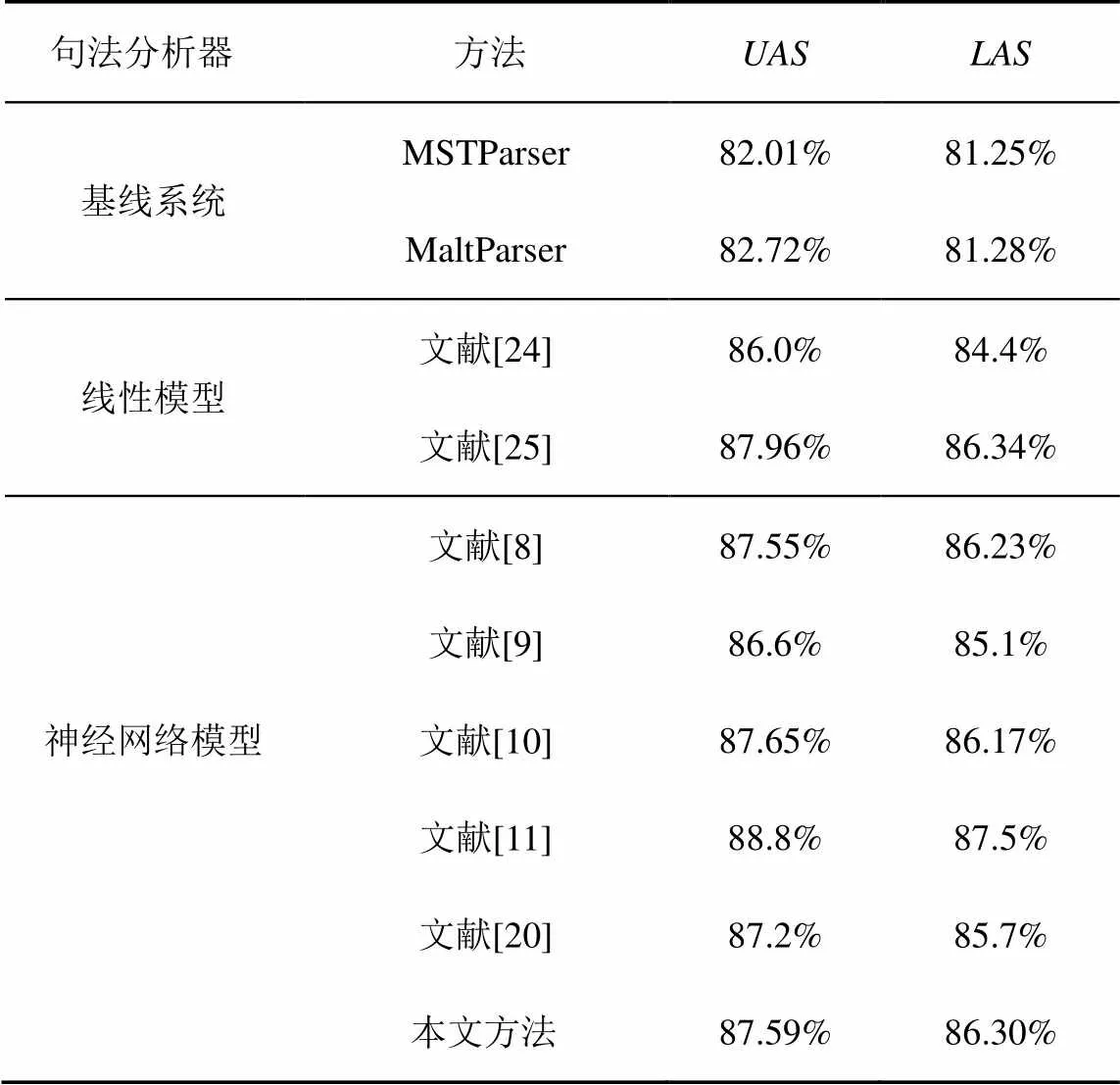
表8 依存分析结果及对比
从表8可以看出,本文提出的依存分析模型,相较于基线系统在值和值上都有明显提升,大约都在5%左右。与传统模型下准确率最高的基于转移[24]和基于图[25]的依存分析系统相比,本文模型也达到了高于或者十分接近的准确率。和仅使用LSTM的文献[8,9]相比,本文在加入CNN提取的全局向量特征后,值高于文献[8],与文献[9]十分接近。和仅使用CNN的文献[10]相比,由于其采用三阶模型,能够利用更复杂的特征,而本文仅为一阶模型,所以值略低,但值更高。与同时使用CNN和LSTM文献[11]相比,其采用CNN和LSTM分别提取字符向量特征和词向量特征,准确率高于本文模型,达到了目前最佳,而本文模型与其相比仍有一定差距,有待进一步提高。
5 结束语
本文在前人工作的基础上,将bi-LSTM和CNN结合使用,提出了一种基于bi-LSTM的依存句法分析模型,该模型能够结合句子级别的全局向量特征,提升依存分析效果。与传统线性模型相比,该模型采用深度神经网络自动学习上下文特征和全局特征表示,不需人为选择特征,避免了特征依赖问题。与神经网络依存分析模型相比,本文将LSTM和CNN结合使用,建立了基于图的一阶模型,复杂度低于其他高阶模型。采用了基于概率模型的训练方法,充分利用了所有可能的依存分析树进行训练,依存分析结果接近或高于单独使用LSTM和CNN的模型。
下面是对目标函数式(13)求偏导数的详细过程。
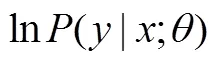
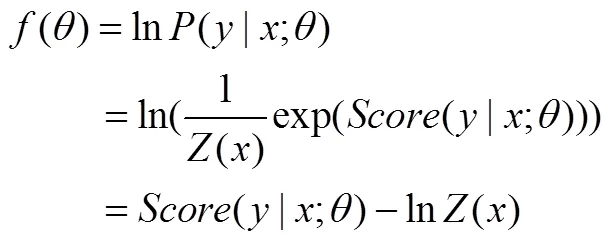
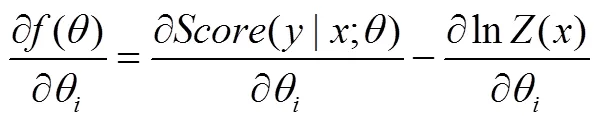
式(20)难点在于()偏导数的计算,式(21)是()的偏导数具体求解过程。
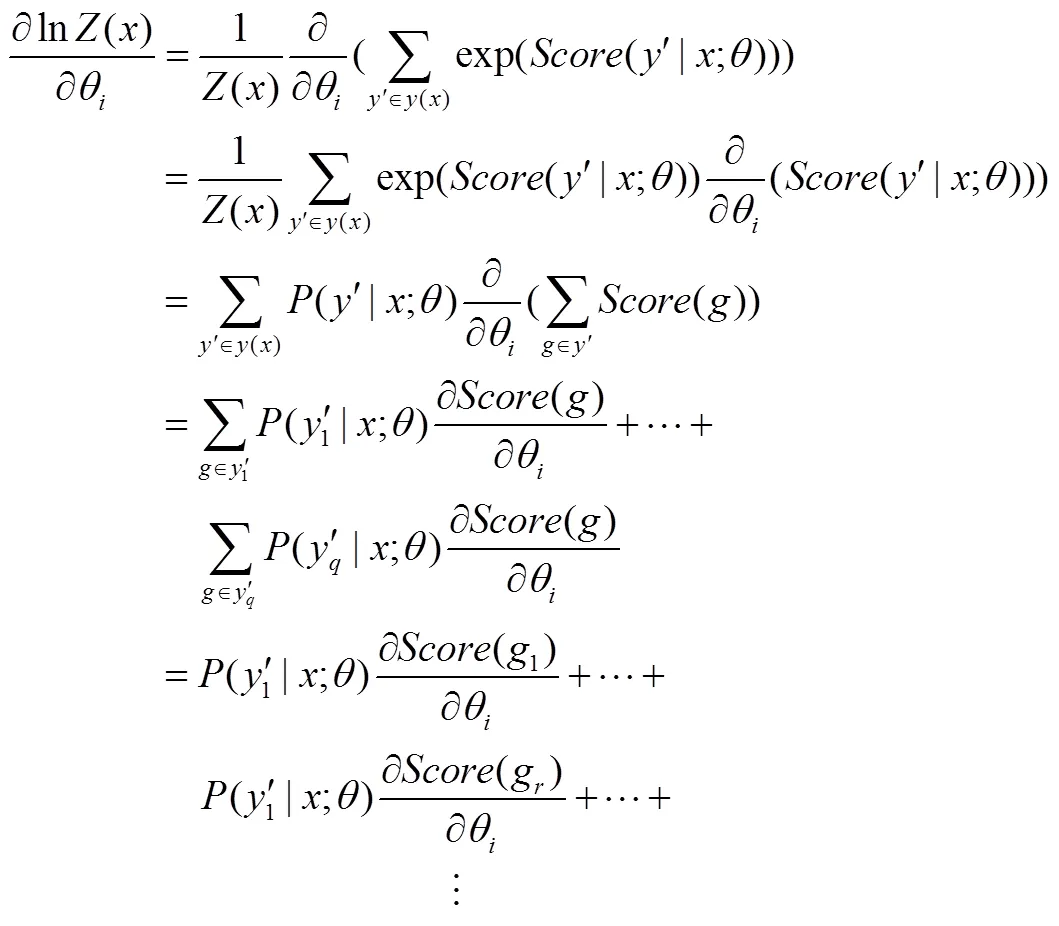
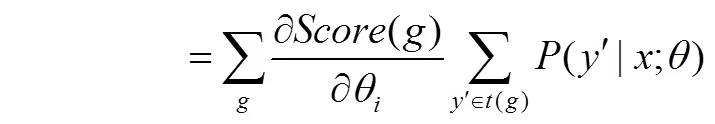
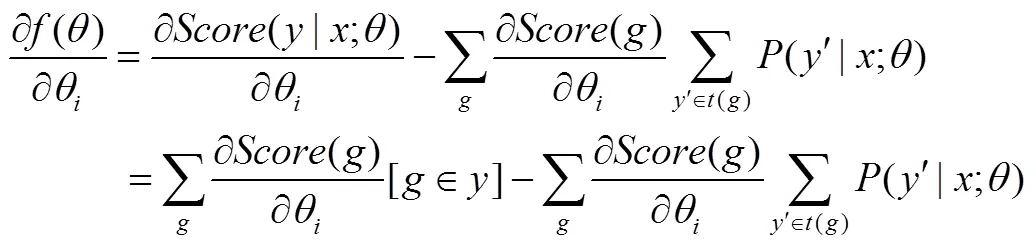
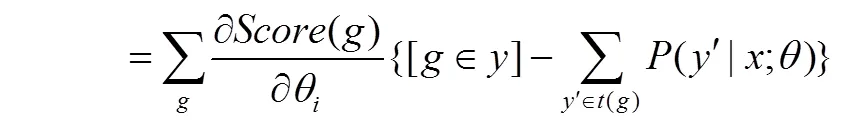
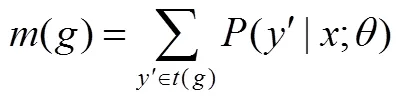
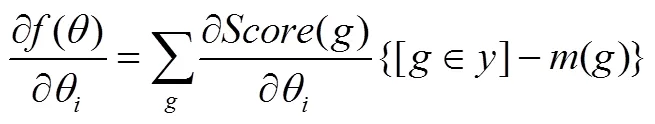
式(13)中第一项偏导数的计算结果即式(24),则式(13)的最终的偏导数为
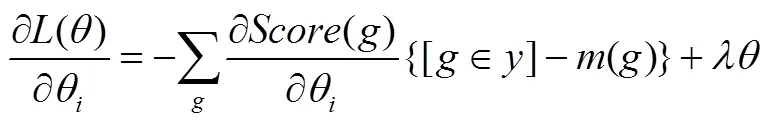
[1] MCDONALD R, CRAMMER K, PEREIRA F. Online large-margin training of dependency parsers[C]//The 43rd Annual Meeting on Association for Computational Linguistics. 2005:91-98.
[2] EISNER J M. Three new probabilistic models for dependency parsing: an exploration[J]. Computer Science, 1997:340-345.
[3] MCDONALD R T, PEREIRA F C N. Online learning of approximate dependency parsing algorithms[C]//The 11th Conference of the European Chapter of the Association for Computational Linguistics. 2006: 81-88.
[4] CARRERAS X. Experiments with a higher-order projective dependency parser[C]//The 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. 2007: 957-961.
[5] KOO T, COLLINS M. Efficient third-order dependency parsers[C]// The 48th Annual Meeting of the Association for Computational Linguistics. 2010:1-11.
[6] 马学喆. 依存句法分析的若干关键问题的研究[D]. 上海: 上海交通大学, 2013.
MA X Z. Research on key issues of dependency parsing[D]. Shanghai: Shanghai Jiaotong University, 2013.
[7] PEI W Z, GE T, CHANG B B. An effective neural network model for graph-based dependency parsing[C]// The 53rd Annual Meeting of the Association for Computational Linguistics. 2015: 313-322.
[8] WANG W H, CHANG B B. Graph-based dependency parsing with bidirectional LSTM[C]//The 54th Annual Meeting of the Association for Computational Linguistics. 2016: 2306-2315.
[9] KIPERWASSER E, GOLDBERG Y. Simple and accurate dependency parsing using bidirectional LSTM feature representations[J]. Transactions of the Association for Computational Linguistics, 2016(4): 313-327.
[10] ZHANG Z S, ZHAO H, QIN L H. Probabilistic graph-based dependency parsing with convolutional neural network[C]//The 54th Annual Meeting of the Association for Computational Linguistics. 2016: 1382-1392.
[11] MA X Z, HOVY E. Neural probabilistic model for non-projective MST parsing[J]. arXiv: arXiv: 1701.00874, 2017.
[12] ZHANG J J, ZHANG D K, HAO J. Local translation prediction with global sentence representation[C]//The 24th International Joint Conference on Artificial Intelligence. 2015:1398-1404.
[13] KALCHBRENNER N, GREFENSTETTE E, BLUNSOM P. A convolutional neural network for modelling sentences[J]. Eprint Arxiv, 2014(1).
[14] COLLOBERT R, WESTON J, BOTTOU L, et al. Natural language processing (almost) from scratch[J]. Journal of Machine Learning Research, 2011(12): 2493-2537.
[15] JASON C, ERIC N. Named entity recognition with bidirectional lstm-cnns[J]. Transactions of the Association for Computational Linguistics, 2016(4): 357-370.
[16] 曾谁飞, 张笑燕, 杜晓峰, 等. 基于神经网络的文本表示模型新方法[J]. 通信学报, 2017, 38(4): 86-98.
ZENG S F, ZHANG X Y, DU X F, et al. New method of text representation model based on neural network[J]. Journal on Communications, 2017, 38(4): 86-98.
[17] CHEN D Q, MANNING C. A fast and accurate dependency parser using neural networks[C]//Conference on Empirical Methods in Natural Language Processing. 2014:740-750.
[18] WEISS D, ALBERTI C, COLLINS M, et al. Structured training for neural network transition-based parsing[C]//The 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. 2015: 323-333.
[19] ANDOR D, ALBERTI C, WEISS D, et al. Globally normalized transition-based neural networks[C]//The 54rd Annual Meeting of the Association for Computational Linguistics. 2016: 2442-2452.
[20] DYER C, BALLESTEROS M, WANG L, et al. Transition-based dependency parsing with stack long short-term memory[J]. Computer Science, 2015, 37(2): 321-332.
[21] CHENG H, FANG H, HE X D, et al. Bi-directional attention with agreement for dependency parsing[C]// Conference on Empirical Methods in Natural Language Processing. 2016: 2204-2214.
[22] DOZAT T, MANNING C D. Deep biaffine attention for neural dependency parsing[J]. arXiv: arXiv 1611.01734, 2016.
[23] NEUBIG G, DYER C, GOLDBERG Y, et al. DyNet: the dynamic neural network toolkit[J]. arXiv: arXiv 1701.03980, 2017.
[24] ZHANG Y, NIVRE J. Transition-based dependency parsing with rich non-local features[C]//The 49th Annual Meeting of the Association for Computational Linguistics. 2011:188-193.
[25] ZHANG H, MCDONALD R. Enforcing structural diversity in cube-pruned dependency parsing[C]//The 52nd Annual Meeting of the Association for Computational Linguistics. 2014:656-666.
Neural network model for dependency parsingincorporating global vector feature
WANG Hengjun1, SI Nianwen1, SONG Yulong2, SHAN Yidong1
1. The Third Institute, PLA Information Engineering University, Zhengzhou 450001, China 2. 73671 Army, Luan 237000, China
LSTM and piecewise CNN were utilized to extract word vector features and global vector features, respectively. Then the two features were input to feed forward network for training. In model training, the probabilistic training method was adopted. Compared with the original dependency paring model, the proposed model focused more on global features, and used all potential dependency trees to update model parameters. Experiments on Chinese Penn Treebank 5 (CTB5) dataset show that, compared with the parsing model using LSTM or CNN only, the proposed model not only remains the relatively low model complexity, but also achieves higher accuracies.
dependency parsing, graph-based model, long short-term memory network, convolutional neural network, feature
TN912.3
A
10.11959/j.issn.1000-436x.2018024
2017-06-12;
2017-12-08
司念文,snw1608@163.com
王衡军(1973-),男,湖南衡阳人,解放军信息工程大学副教授、硕士生导师,主要研究方向为机器学习、自然语言处理和信息安全。

司念文(1992-),男,湖北襄阳人,解放军信息工程大学硕士生,主要研究方向为机器学习、自然语言处理。
宋玉龙(1995-),男,安徽阜阳人,73671部队助理工程师,主要研究方向为网络与信息安全。

单义栋(1988-),男,山东乳山人,解放军信息工程大学硕士生,主要研究方向为自然语言处理。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
金桥(2018年4期)2018-09-26
高中生学习·高三版(2016年9期)2016-05-14
燕山大学学报(2015年4期)2015-12-25
新高考·高二数学(2015年11期)2015-12-23
海军航空大学学报(2015年4期)2015-02-27
中国卫生(2014年5期)2014-11-10
