
基于卷积神经网络的外周血白细胞分类
2018-03-28 07:43程少杰李卫滨
中国生物医学工程学报 2018年1期
陈 畅 程少杰 李卫滨 陈 敏*
1(中国科学技术大学信息科学技术学院,合肥 230022) 2(解放军福州总医院全军检验医学研究所,福州 350025)
引言
外周血白细胞(white blood cell,WBC)分类是临床检验的一项常规工作,对许多疾病的诊断、鉴别诊断及疗效评估都有重要意义。目前实验室通常采用血细胞分析仪进行WBC分类计数,这些分析仪一般采用物理(电阻抗、激光散射)、细胞化学(过氧化物酶染色、核酸荧光染色)等分类技术,在自动化程度、检测速度和结果准确性上能满足大批量标本的检测需求[1]。尽管如此,形态学镜检仍然是血细胞分析的“金标准”用于仪器性能的评估[2],以及对血液系统疾病的诊断[3]。据统计,对于住院病人,约20%的标本需要通过人工镜检确认结果[4]。人工镜检操作,不但耗时,更需要训练有素的专业人员。如何减轻工作压力,提高镜检的自动化水平,成为临床检验的现实需要。为此,针对血涂片镜检的计算机图像分析研究成为一个活跃的领域[5-6]。
目前报道的白细胞图像计算机分类识别研究中,都需要运用各种算法对细胞进行细致的分割后,再进行特征提取和分类识别[7-13]。文献[13]总结了2003—2011年该领域的研究成果,发现各种算法的分类正确率差别较大,从70.6%~96%不等。最近,Su等在这一领域的研究有了新的突破,其“区域判别(Discriminating region)分割+多层感知器分类”的算法组合在白细胞图像的5分类研究中,正确率达到了99.11%的目前最好结果[14]。而郝连旺等在国内率先开展了白细胞图像的6分类研究,其综合正确率已达95.98%[15]。
卷积神经网络(convolutional neural network,CNN)是目前较为成功的图像识别神经网络,其概念最早是从研究动物大脑视皮层对光的反射反应的分层处理机制中提炼出来的,而现代意义上的CNN则是由LeCun等对手写数字识别的研究中提出来的经典的CNN结构LeNet-5[16],其后出现了更为复杂的AlexNet[17]、ResNet[18]、GoogleNet[19]等。
目前,CNN在图像识别中的研究正方兴未艾[20],但未见其用于白细胞图像的“端对端”分类识别研究。本研究基于开源的深度学习框架Caffe[21],构建卷积神经网络,实现了外周血白细胞5分类图像的高正确率识别。
1 实验方法
1.1 外周血细胞图库的准备
1.1.1图像采集与标记
随机选择本院就诊患者的常规血细胞分析标本(静脉血2 mL于EDTAK2抗凝管中),用SYSMEX- SP10自动推片染色机制备外周血染色涂片,再用CellaVision DM96全自动血细胞形态学分析仪采集白细胞的单个图像(分辨率为360像素×363像素)。由两位经验丰富的细胞形态学检验人员共同鉴定确认细胞图像的分类属性,分别并存放在单独的文件夹中。
1.1.2图像扩充
基于CNN模型的深度学习是一种统计学习方法,参数的调整完全依赖于训练数据,数据量的大小影响着网络的训练结果,较大的数据集更容易使网络收敛。但对于外周血白细胞图像,能够获取的带标签的训练数据是有限的,需要通过图像处理的方法扩增数据量。本研究采取移动平移、旋转及镜像等方法扩充图像数量,详见图1中的图示和说明。
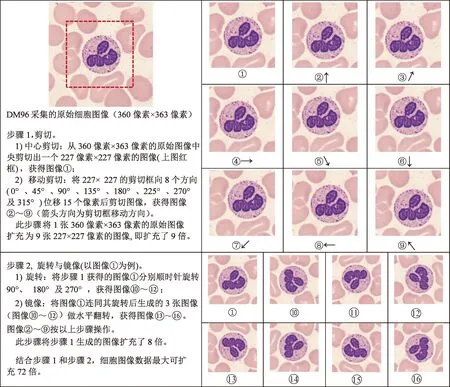
图1 细胞图像数据扩充方法Fig.1 Data augmentation methods
1.2 实验平台的构建
1.2.1主要软、硬件
图像工作站为自行组装PC机,主要配置:CPU为Intel Core i7-6700k,主板为华硕Z170,显卡为英伟达GeForce GTX 1080,内存为金士顿DDR4 64GB,硬盘为三星SSD 950 PRO 256 GB(系统盘)+希捷ST2000 2.0TB(数据盘)。
操作系统为Windows 10企业版,Caffe系统是Windows版(GitHub:BVLC/caffe release candidate 3)。其他软件有Matlab R2015b,Microsoft Visual Studio 2013等。
Caffe平台的安装主要是Caffe的编译工作,编译时要注意修改第三方库的路径、选择匹配的编译平台。
1.2.2Caffe工作原理
Caffe是计算机视觉领域中常用的开源深度学习框架,主要用来搭建与优化深度卷积神经网络模型。它分为3个部分:存储数值的Blobs、实现具体运算的Layers与描述网络拓扑结构的Net。每层均连接着一个或者多个的Blobs,用于存储层的输入与输出,Blob结构对数据进行抽象,使数值存储独立于具体计算设备(如CPU、GPU),网络由实现不同功能的Layers连接构成有向无环图的结构,如图2所示。该图描述了一种典型卷积神经网络结构:网络的前馈过程从数据输入层开始,经过若干卷积层与非线性激活层的运算,将数据传输到损失函数层计算分类器输出与标签的逻辑回归误差。

图2 Caffe框架下卷积神经网络的结构Fig.2 The structure diagram of Caffe framework
1)前馈:设CNN中第l层中的第i个特征图像为ail,第l+1层中的第j个特征图像zj,l+1是由第l层中ai,l与对应的卷积核wjil经过卷积运算并求和后得到的结果,则有
(1)
将式(1)展开,设图像zj,l+1中有一点坐标为zj,l+1(p,q),则有
2)反馈:设L为损失函数,则反向求导的公式为
1.2.2.1数据层
经人工标定的训练图像需打包成特定的数据库格式作为网络的数据输入,以减少数据读取时间,加速模型优化。Caffe支持HDF5、LevelDB及LMDB等数据库格式,因LMDB数据库读写速度较快,且允许多种训练模型同时读取同一组数据集。因此,本研究选择LMDB数据库格式。
1.2.2.2卷积层
卷积操作的基本原理是用一组可学习权值的卷积核对输入的图像进行卷积操作。卷积运算的本质是线性变换,具有提取特征信息的作用,图3演示了一个简单的卷积过程。

图3 卷积层操作示意图Fig.3 The schematic diagram of convolution operation
1.2.2.3池化层
池化(pooling)是一种下采样操作,目的是降低CNN模型中间数据的维度。池化操作分为最大池化(max pooling)、均值池化(average pooling)、混合池化等不同类型。以本研究采用的max pooling为例,图4是其具体的实现过程。

图4 最大池化的计算方法Fig.4 The calculation method of max pooling
1.2.2.4非线性激活层
非线性激活层的主要作用是使网络的非线性建模能力。常用的非线性激活函数有Sigmoid、tanh(hyperbolic tangent)与ReLU(rectified linear unit)等,本研究选用目前在图像识别领域应用效果较好的ReLU作为非线性激活函数[22],图5是几种常见的非线性激活函数。

图5 3种激活函数的公式及曲线Fig.5 The formula and curves of nonlinear activation functions
1.2.2.5损失函数层
损失函数层有两个作用:一是根据损失函数计算训练误差与分类准确率;二是计算误差值对前一层网络参数的导数,是反向传播误差并调整网络参数的开始。对于分类任务最常用的是softmax_loss,此外,损失函数hinge_loss具有支持向量机(support vector machine, SVM)的特性,也常用在分类任务中。
1.2.3网络训练
1.2.3.1网络模型
以AlexNet、LeNet模型为基础编制网络结构文件net.prototxt,其中数据层中的data_param应根据数据库的实际情况设定:
data_param {
#数据库的路径和文件名
source: "d: /wbc_dif/data/train_db1"
backend: LMDB #数据库类型
batch_size: 64 #一次迭代的样本数
prefetch: 256 #预取标本数
}
根据训练结果调整网络结构,最终确定适宜的网络模型。
1.2.3.2训练参数
网络的训练参数在solver.prototxt文件中设定,其中学习速率(learning rate, LR)是模型优化算法中重要的参数,通常在优化的初始阶段采用较大的学习率使模型有更大的搜索范围,避免过早陷入局部极小值。随着模型在较大的学习速率下持续训练,误差函数的输出曲线呈现震荡的态势,此时需降低学习速率使模型误差进一步减少(通常以0.1倍的步长降低,即gamma=0.1),学习参数的基本设定如下所示:
base_lr: 0.01~0.001
momentum: 0.9
weight_decay: 0.001~0.0001
lr_policy: “multistep“or “fixed”
gamma: 0.1
stepvalue: 5000(lr_policy=“multistep”时设定)
文件中test_iter参数用于设定完成一轮校验的迭代数,其值与net.prototxt文件中校验数据库的batch_size参数有关,二者的乘积应等于校验集样本总数;而max_iter参数是用于定义每次训练的最大迭代次数,一般取10~100个epoch(1个epoch的迭代次数等于训练集样本总数除以net.prototxt文件中训练数据库的batch_size值)。
1.2.3.3网络训练方法
完成net.prototxt 和solver.prototxt文件的配置后,在DOS控制台执行下列命令即可开始训练:
caffe.exe train-solver=..solver.prototxt-model =.. net.prototxt-gpu=0
训练中,根据solver.prototx的设定,可在目标目录中按照设定间隔生成权值文件*.caffemodel和中间状态文件*. solverstate。前者用于模型评价和移植应用,后者用于在某断点处恢复训练:
caffe.exe train-solver=..solver.prototxt-model=.. et.prototxt-snapshot=..xxx.solverstatec-gpu=0
通过观察训练的loss值和校验的Accurate值变换趋势来判断本次实验的结局。

图6 不同CNN模型的训练曲线。(a) AlexNet;(b) LeNet;(c) CCNetFig.6 The training curves of 3 CNN models. (a)AlexNet; (b)LeNet; (c)CCNet
1.2.3.4网络模型评价
对完成训练的网络,用caffe-Matlab接口调用网络结构文件和最佳训练正确率的权值文件,用测试集对其进行分类性能的评价,计算识别正确率和识别效率。调用、判断语句如下。
网络定义:
net=caffe.Net (net_model, net_weights, ‘test’);
计算分类概率:
result=net.forward({single(im) * 0.00390625});
在输出数组中取概率最大的标签值:
[~, max_i]=max(result{1});
2 结果
2.1 图像扩充
表1汇总了本研究所用5种白细胞原始数量及最终扩充数量,从中可以看出,训练集图像数据从原始的9 773个图像,经过平移剪切、旋转和镜像操作,最大可扩充到703 656个图像(3个数据集的db3总数之和)。根据数据集的图像组成分别命名为db1(Center)、db2(Center+旋转+镜像,比db1扩大8倍)和db3(Center+平移+旋转+镜像,比db1扩大72倍)并按照训练∶校验∶测试=7∶2∶1的比例随机分配图像。训练和校验集图像转换成LMDB格式,测试集图像保存在各自的分类名目录中。
表1用于训练、校验及测试的数据集构成
Tab.1Thenumberofdatasetsusedfortraining,validationandtesting

数据集白细胞分类数据嗜碱嗜酸淋巴单核中性总数数据库大小/GB原始图像2557462570108451189773训练集db11795221799756358368391.06db21432417614392604828664547128.52db312888375841295285443225797649240876.70校验集db150149514219102319550.30db24001192411217528184156402.43db336001072837008157687365614076021.90测试集db12675257109512979db2208600205687240967832db3187254001850478483686470488
2.2 网络结构的确定
2.2.1AlexNet、LeNet网络训练结果
分别用3个不同大小的数据集训练AlexNet网络和LeNet网络,结果AlexNet网络均快速陷入局部最小值,无法完成训练,即使改用其他梯度优化方法(如AdaDelta、AdaGrad等)均无法收敛,图6(a)是其中一个典型的训练曲线图;而LeNet网络则表现出良好的训练效果(见图6(b)),校验数据集的测试正确率均大于95.0%。
2.2.2网络结构的优化
尽管LeNet可以获得满意的结果,但是其网络参数模型较大,运算耗时较长,对训练系统的内存和显存要求较高,不利于移植应用。通过大量的网络结构调整实验,最终优化出一个高效、轻量的卷积神经网络结构,图6(c)是其训练曲线。为了方便表述,将其命名为CCNet(cell classification net)。
从表2可见,CCNet与LeNet网络结构最大的区别在于删减了一个有500输出量的全链接层,同时增大了第一卷积层的卷积核,并在其后增加了一个非线性激活层。

表2 CCNet与LeNet结构参数的比较
2.3 网络性能评估
2.3.1网络训练时效比较
表3比较了CCNet和LeNet用3个不同大小数据集训练时的用时情况。从表中可见,随着训练集规模的增加,两个网络训练用时皆同步增加;而对于相同规模的训练集,CCNet的训练用时明显少于LeNet。特别是CCNet生成的模型只有276 KB,是LeNet模型大小的1%。
表3网络训练用时与模型大小比较
Tab.3Thecomparisonoftrainingtimeconsumingandmodelsize

网络完成1epoch训练用时/sdb1db2db3模型大小CCNet555732276KBLeNet201501775278MB
2.3.2网络分类性能比较
对分别采用db1、db2和db3的3个训练集训练的CCNet和LeNet,按表4的配对方式进行细胞分类性能评价。
从表4中可以看出,不论是配对识别还是针对同一测试集的识别,两个网络的识别正确率都随着训练集规模的扩大而提高。对原图(db1)的最佳识别正确率(db3~db1)都高于文献[14]的99.11%。
从数据扩充效果上分析,db1到db2的识别率增幅较为明显,CCNet和LeNet分别增加了1.66%和3.22%,而增加了平移扩充的db3,识别率仅分别提升了0.1%和0.63%,说明CNN对图像平移不具敏感性。在识别效率方面,轻量级的CCNet具有明显的速度优势,特别在CPU运算模式下,其优势更加明显,用时仅为LeNet的1/30。
表4CCNet和LeNet分类性能比较
Tab.4ThecomparisonofclassificationperformancebetweenCCNetandLeNet

训练集-测试集综合识别正确率/%平均识别效率/(ms/图)CCNetLeNetCCNetLeNetdb1-db197.7595.40db2-db199.3998.37db3-db199.6999.18db2-db299.4198.62db3-db399.5199.253.73a1.08b99.59a4.09b
注:a为CPU运算模式,b为GPU运算模式。
Note:aCPU running time,bGPU running time.
2.6 CCNet的特征提取
从卷积层输出的特征映射图可以看出,网络提取特征的能力在“端对端”的优化中被训练出来。本研究提取了CCNet 第一卷积层的特征映射图,与原细胞图像进行比较。从图7可以看出,卷积层对原图细胞的几何特征、灰度特征和亮度特征进行了充分的提取和表征,并随着训练次数的增加,对输入图像的特征提取也不断强化。

图7 细胞原图与卷积特征映射图。(a)细胞原图;(b)1 000次迭代特征映射图;(c)10 000次迭代特征映射图Fig.7 The original image and it′s feature maps.(a)original image; (b)feature maps with one thousand iterations;(c) feature maps with ten thousand iterations
3 讨论
近年来,深度学习在图像识别方面异军突起,在多项图像识别大赛中已经超越了人类的水平。一方面,这得益于CNN集图像特征提取与分类识别于一身的优异能力;另一方面,训练数据的扩增与计算能力的提高,使得CNN模型能挖掘图像中关键的特征信息,在特征提取的深度和广度上是传统方法无法比拟的。在实际训练中,为了提升模型的鲁棒性和泛化能力,首先需保证训练图像多样性和真实性。本研究所收集的图像资料皆来自日常工作标本,包含多位操作员制作的涂片,其质量品相各异,入选的唯一标准是其人工可识别性。为充分发挥CNN强大的学习能力,更好地从样本中提取高维特征信息,本研究采取了多种图像变换方法扩充训练图像数量,发现图像的“旋转”和“镜像”变换能有效增加细胞图像的多样性,提升CNN训练的正确率;而“平移”变换虽然可大幅度扩充数据量,但因CNN对图像的“平移不变性”使得实际效果提升有限,相反却大大增加了训练时间的开销。
在CNN的网络结构设计及训练方面,目前还没有规范的理论指导。通常以一个有效的网络结构为原型,通过大量实验改进网络结构,调整并选取适合网络结构的超参数(学习速率、损失函数、激活函数等)。就本研究而言,从经典的AlexNet、LeNet着手,逐步调整优化网络结构。除了对全连接层的优化,通过监视卷积层输出的特征映射图与分类正确率的变化关系,发现对于细胞分类问题,区分不同类别细胞的关键信息更多地在于全局信息(如形状结构、边缘特征等)。所以通过增加卷积层的步长(Stride)对图像进一步降维,提取出具有显著性的全局特征作为全连接分类器的输入特征向量。这使得CCNet在提高了正确率的同时,显著地加快了运算速度(较LeNet约平均提速30倍)。
相对AlexNet的高斯初始化方法,CCNet与LeNet均采用了Xavier初始化方式对卷积核的权值进行初始化。Xavier方法由Bengio等于2010年提出[23],充分考虑了输入输出神经元个数与数据流方差的关系,是高斯初始化方式的改进。CCNet对LeNet的主要改进在于优化了全连接层的数量。对于5分类问题,高输出的全连接层带来过多的参数,扩大了解空间的搜索范围,不利于网络的收敛,同时也增加了模型运算的时间成本。在损失函数方面,CCNet采用了HingeLoss来替代SoftmaxLoss。HingeLoss与全连接层共同构成了SVM作为分类器,SVM通过支持向量学习超平面,对卷积层降维输出的低维特征向量有较好的分类效果。
卷积神经网络因需要大量的运算而限制了其在便携和嵌入系统的应用,本研究提出的CCNet具有轻量、高效、低计算量需求的特点,有望扩大CNN在细胞识别领域的应用平台。
由于缺乏统一的细胞图库,不同方法之间一般难以量化比较。而Su等的研究也是基于CellaVision DM96平台收集细胞图像,其99.11%的识别正确率是对450张标准图像的分析结果[14],而本研究99.69%的识别正确率是对979张临床实际标本图像的分析结果,图像数量比前者多了1倍多,结果应更具说服力。
尽管本文的初步研究取得良好的效果,但应该说明,本研究所采集的细胞图像仅限于正常白细胞的5分类图像,不含各种非白细胞的干扰图像如红细胞聚集、重叠的图像(DM96常将其识别为嗜酸细胞)、异常淋巴细胞图像以及粘连、重叠细胞图像等。对干扰图像的鲁棒性是本课题进一步研究的一个主要方向。
4 结论
实验结果表明,CNN可用于外周血白细胞的“端对端”分类识别,特别是本研究提出的CCNet模型兼具准确与效率优势,为下一阶段在干扰条件下更多类别细胞的识别及镜下自动识别的研究打下良好基础。
[1] Chabot-Richards DS,George TI. White blood cell counts- Reference methodology[J].Clin Lab Med,2015,35(1):11-24.
[2] Kim SJ, Kim Y, Shin S,et al.Comparison study of the rates of manual peripheral blood smear review from 3 automated hematology analyzers, UnicelDxH 800, ADVIA 2120i, and XE 2100 using international consensus group guidelines[J].Arch Pathol Lab Med, 2012,136(11): 1408-1413.
[3] Bain BJ.Diagnosis from the blood smear[J]. N Engl J Med, 2005; 353(5):498-507.
[4] Rabizadeh E,Pickholtz I,Barak M,et al.Acute leukemia detection rate by automated blood count parameters and peripheral smear review[J].Int J Lab Hem,2014,37(1):44-49.
[5] Da Costa L.Digital image analysis of blood cells[J]. Clin Lab Med, 2014,35(1):105-122.
[6] Mohammed EA,Mohamed MM,Far BH,et al.Peripheral blood smear image analysis:A comprehensive review[J].J Pathol Inform,2014,5(1):9.
[7] Sadeghian F,Seman Z,Ramli AR,et al.A Framework for white blood cell segmentationin microscopic blood images using digital image processing[J].Biol Proced Online, 2009,11(1):196-206.
[8] Ko BC,Gim JW,Nam JY.Automatic white blood cell segmentation using stepwise merging rules and gradient vector flow snake[J]. Micron,2011, 42(7):695-705.
[9] Mohapatra S,Patra D,Kumar K.Fast leukocyte image segmentation using shadowsets[J].Int J Comput Biol Drug Des, 2012,5(1):49-65.
[10] 郝连旺,洪文学.基于多颜色空间特征融合的彩色白细胞图像识别[J].生物医学工程学杂志,2013,30(5):909-913.
[11] 陈爱斌,江霞.细胞分割算法研究方法综述[J].电子世界,2011,15:76-79.
[12] Pore YN,Kalshetty YR. Review on blood cell image segmentation and counting[J].International Journal of Application or Innovation in Engineering & Management,2014,3(11):369-372.
[13] Saraswat M,Arya KV.Automated microscopic image analysis for leukocytes identification:A survey[J]. Micron,2014;65:20-33.
[14] Su Muchun, Cheng Chunyen, Wang Pachun. Neural-network-based approach to white blood cell classification[J].Scientific World Journal,2014:796371.
[15] 郝连旺,洪文学.属性多层次结构关系在白细胞形态六分类技术中的应用[J].中国生物医学工程学报,2015,34(5):533-539.
[16] LeCun Y,Bottou L,Bengio Y,et al.Gradient-based learning applied to document recognition[J].Proceedings of the IEEE,1998,86(11):2278-2324.
[17] Krizhevsky A, Sutskever I, Hinton GE. ImageNet Classification with Deep Convolutional Neural Networks[C]// Proceedings of the 25th International Conference on Neural Information Processing. Lake Tahoe:Curran Associates Inc,2012:1097-1105.
[18] He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep residual learning for image recognition[EB/OL]. https://arxiv.org/pdf/ 1512.03385v1.pdf,2015-12-10/2016-08-17.
[19] Szegedy C, Liu Wei, Jia Yangqing, et al. Going deeper with convolutions [EB/OL]. https://arxiv.org/pdf/1409.4842v1.pdf,2014-09-17/2016-08-17.
[20] Gu Jiuxiang, Wang Zhenhua,Kuen J,et al. Recent advances in convolutional neural networks[EB/OL]. https://arxiv.org/pdf/ 1512.07108v4.pdf,2016-08-06/2016-08-17.
[21] Jia Yingqing, Shelhamer E, Donahue J, et al. Caffe: Convolutional architecture for fast feature embedding[C]// Proceedings of the 22nd ACM international conference on Multimedia. Orlando:ACM,2014:675-678.
[22] Nair V, Hinton GE.Rectified linear units improve restricted Boltzmann machines[C]// Proceedings of the 27th International Conference on Machine Learning. Haifa:IMLS, 2010:807-814.
[23] Glorot X, Bengio Y. Understanding the difficulty of training deep feedforward neural networks[J].J Mach Learn Res,2010,9:249-256.
猜你喜欢
医学食疗与健康(2022年3期)2022-04-23
中国宝玉石(2021年5期)2021-11-18
中华养生保健(2020年7期)2020-11-16
人人健康(2017年19期)2017-10-20
家教世界·创新阅读(2016年11期)2016-12-27
故事会(2016年15期)2016-08-23
军事运筹与系统工程(2016年4期)2016-07-10
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
转化医学电子杂志(2015年4期)2015-12-27
智能系统学报(2015年4期)2015-12-27
