
一种带偏置的专家信任推荐算法
2018-03-27 01:27王建芳刘冉东刘永利
小型微型计算机系统 2018年2期
王建芳,刘冉东,刘永利
(河南理工大学 计算机科学与技术学院,河南 焦作 454000)
1 引 言
推荐系统[1,2]的基本功能是利用用户对项目的历史评价信息产生推荐,大数据[3]时代用户接触的信息呈指数级,实际操作过程中,由于用户精力有限,造成大量项目未得到评分,导致评价矩阵极为稀疏.传统协同过滤[4]算法的稀疏用户(评价项目相对较少的用户)评分预测准确度较低,如何提高稀疏用户的推荐准确性成为比较热门的研究课题.
针对稀疏用户评分预测问题,常采用的处理方法有:
1)数据平滑算法[5]:对用户尚未评分的项目进行填充.文献[6]运用其他用户对该项目的评分均值填充缺省值.文献[7]将用户信息聚类后,以分类用户的评分来填充缺省值.
2)专家算法:把项目按类别划分,找到每个类别的专家,利用专家评分预测用户对项目评分.文献[8]提出了把专家算法与传统协同过滤技术相结合.文献[9]提出了“明星用户”的算法,在评分预测阶段加权平均所有“明星用户”的评分.
以上两类算法,一定程度上缓解了稀疏用户评分预测准确性不高的问题,但是计算得到稀疏用户与用户,稀疏用户与各个“专家”之间的相似度区分不明显,无法合理利用用户与专家的预测信息.鉴于此,本文提出IBETA算法(Improved With Biased Expert Trust Algorithm,IBETA),该算法在专家算法的基础上添加专家信任,在评分形成的过程中区别对待不同级别专家的预测值,同时将独立于用户-项目评分以外的因素添加到评分预测公式中,使预测值更加合理.
2 相关工作
2.1 专家算法
定义1.对于A类项目,专家Ec被定义为:
Iu≤Iv(∀u∈U-Ec,∀v∈Ec)
(1)
其中,Iu是指用户u评价所有项目的集合,Iv是指“专家”v评价的项目集合,U是所有用户集合.统计每个用户评价A类项目数量,当用户评价项目的数量使公式(1)成立时,该用户被定义为“专家”.
2.2 生成推荐值
Cho[10]提出的“专家算法”在计算预测评分时,采用无条件相信专家的策略-EA(Expert Algorithm,EA),评分预测采用公式(2).
(2)

需要预测的项目属于多个类别时,采用公式(3)计算评分值.
(3)
其中,Ci是项目所属的类数,Pu,i,c是每一类预测的值.
以上预测评分算法的运行时间复杂度较低,但稀疏用户评分预测准确性较低,原因是该算法在项目确定的情况下,对于不同用户的预测分数几乎是一样的,因为专家的选择只考虑了当前用户需要预测的项目;在选定专家集合中,同等对待每个专家的预测值.专家的专业水平有高有低,以上算法显然有失偏颇.
Breeze[10]提出“专家与相似结合算法”在计算预测评分时,采用把专家看成某种意义上的近邻,在预测评分时根据专家与当前用户相似度[11]的大小赋予不同的权重值ESA(Expert Similarity Algorithm,ESA),评分预测采用公式(4).
(4)
其中,Su,v表示专家与当前用户的相似度,与EA算法相比ESA算法对于不同的专家赋予了不同的权重值.随着稀疏性的增加,稀疏用户与各个专家的邻近程度区分不明显,计算量增加的同时稀疏用户的推荐准确性并没有实质性的提高.
2.3 Baseline 预测
评估一个策略的性能好坏,需要建立一个对比基线,在对比基线[13]的基础上观察后续试验效果的变化.观测到的评分数据有一些和用户无关的因素产生的效果,即一部分因素是和用户对物品的喜好无关而只取决于用户或物品本身的特性,例如,乐观积极的用户对于一些项目的评分普遍较高,而悲观消极的用户对项目的评分普遍较低,也就是说即使这两类用户对同一项目的评分相同,但是对物品的喜好程度确是不一样的.对于项目来说道理是一样的,受用户欢迎的项目评分普遍较高,不受用户欢迎的项目评分较低,加入偏执信息[14]的评分预测公式如公式(5)表示:
R*(i,j)=μ+bu(i)+bu(j)
(5)
其中R*(i,j)表示用户i对项目j的预测评分,μ为数据集的总体偏置信息,bu(i)表示用户i的偏置信息,bu(j)表示项目j的偏置信息.假设项目的总体偏置为a,项目1的口碑普遍高于其他项目的值为b,如果u1是悲观严谨的,其bu(i)值为c,那么u1对项目1的预测值为a+b-c.
计算b(i)和b(j)的值,采用公式(6)、(7)求解.
(6)
(7)
其中,i表示用户,j表示项目,I表示用户i评价过的项目集合,μ为数据集的总体偏置信息,I表示集合的个数,Ui表示评价过项目j的用户集合,Ui表示集合的个数,参数λ1,λ2需要实验确定的值.
3 改进专家算法
从专家算法提出至今,许多研究人员都围绕着利用专家与用户、项目的关系提升推荐准确度.但是现实生活中人们在参考权威人士的意见时,必然要考虑权威人士的可信度.到目前为止推荐系统没有对“信任”[15]给出一个具体的概念.在可查资料中,信任是指接收推荐者对提供推荐者特定行为的主观可能性预测.在社交网络中信任需要考虑的因素有很多,完整的考虑各个方面难度很大且通常没有太大必要,在面对同一个用户时,只需要对该用户所处的情形进行相应的加强和减弱,以便于对对象之间的信任程度进行较好的量化.
3.1 改进专家信任
在推荐系统中存在着各种各样的数据,其中包括了评分数据、项目属性数据、用户属性数据等,这些数据基本构成了本文需要的信任度量情境.充分考虑专家及用户所在环境,本文用以下定义量化专家信任中涉及的重要概念.
定义2.专家评价可信度
一个专家评价的项目数量越多,可以从一定程度上反应出其评价项目的质量、可信度,度量专家评价可信度可以采用公式(8).
(8)
其中,Qall是指所有用户,Qu代表专家u评价过的所有项目的集合,max(Qall)是指所有专家中评价项目的最大值.
定义3.专家专业度
咨询专家意见之前,人们通常会考虑专家的专业度,专家并不是对所有种类的项目都具有全面的专业知识,在某种情况下,一名专家显然只会对一个或者很少种类的项目上投入比较多的精力,具体表现为在某一类项目上评价比较多的项目,因此专家专业度用公式(9)表示.
(9)
其中,Tui表示专家已评价且属于某一种类的所有项目集合,T为系统中获得过用户评价且属于这一主题的所有项目集合.
定义4.专家评价偏差度
专家计算的预测评分与真实评分之间的差值为专家评价偏差度,如公式(10)所示.
(10)
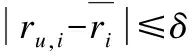
基于以上表述专家的Du,Pu,Ru,权重系数w1,w2,w3及公式(11)计算专家信任值.
TRu=w1·Du+w2·Pu+w3·Ru
(11)
式(11)中权重系数需要采用原始专家算法CE矫正,调节原理是设置一个初始RMSE值,利用评分预测公式计算预测值并计算一次RMSE值,当前RMSE值大于设定RMSE值时,利用控制变量法更新一次权重系数,记录每个参数达到最优RMSE值时的值,最后归一化处理三个参数得到最终权重系数值.
3.2 评分形成
由于传统相似度计算对稀疏用户基本失效,本文把专家可信度,用户、项目偏置与专家算法相结合,如公式(12)所示生成预测值.
fu,c+bu(i)+bi(j)
(12)
其中,TRu表示专家可信度,Ci表示当前项目所属类别总数,fu,c表示用户u评价的c类项目占所有c类项目的百分比,bu(i)、bi(j)分别表示用户U及项目i的偏置.该算法对于每个电影类别的专家评分,根据专家在此类别评价项目中信任值,加权计算预测评分,有效避免了不同类别专家对项目的评分同等对待的问题,根据专家信任值赋予不同专家不同的权重,在一定程度降低了预测误差.确定专家依据的是用户的历史评价信息,在该过程中主观因素起决定性作用,为了提升算法的健壮性,在形成评分的过程中需要考虑独立于评分以外的客观因素,本文把用户、项目偏置引入到评分预测公式中,在改进专家算法形成评分的基础上引入用户、项目偏置,进一步提升了预测准确性及合理性.
3.3 算法描述
输入:评分矩阵R及项目类别矩阵T,RMSE阈值0.98,Round值.
输出:预测矩阵Rpred.
算法步骤:
步骤1.数据预处理;baseline预测确定数据集上λ1,λ2的值;初始化w1,w2,w3.
步骤2.利用定义(1)确定每个类别的专家.
步骤3.根据评分偏差修正一次w1,w2,w3,直到出现最优RMSE值.
fori=1:round
根据公式(2)计算预测值并计算RMSE值.
if(当前RMSE值>设定RMSE值)
修正一次w1,w2,w3的值(控制变量法);
end
i++;
end
步骤4.根据公式(6)、(7)计算用户、项目偏置.
步骤5.根据步骤2寻找到的专家及公式(12),形成预测值.
步骤6.产生预测矩阵Rpred.
4 实验结果与分析
4.1 数据集
本实验分别在Epinion、Ciao、Movielens三个数据集进行,这三个数据集都包含了用户对项目的评分且分值分为1-5的离散值,数据集的具体信息如表1所示:
表1 实验数集
Table 1 Data sets
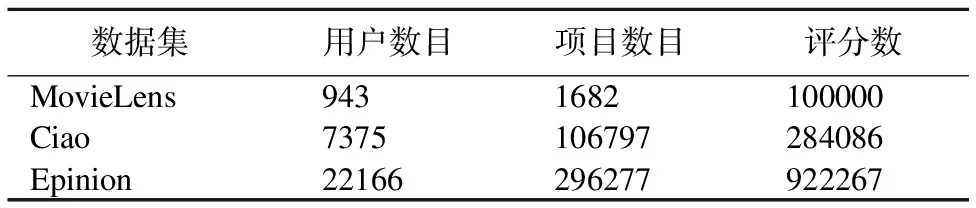
数据集用户数目项目数目评分数MovieLens9431682100000Ciao7375106797284086Epinion22166296277922267
4.2 评估标准
评估推荐系统预测准确性的标准分为决策精度标准和统计精度标准两类.本文采取了对特大或特小误差反应敏感的均方根误差(RMSE),在推荐系统中RMSE作为一种常用度量误差标准被广泛使用,其原理是通过计算用户关于项目的预测值与真实值之间的偏差平方和与用户个数n比值的平方根,如公式(13)所示.
(13)
其中,xi是代表预测值,x0代表与预测值对应的真实值.

图1 MovieLens数据集Baseline预测Fig.1 Baseline prediction of MovieLens 1M dataSets

图2 Ciao数据集Baseline预测Fig.2 Baseline predictions of ciao data sets

图3 Epinion数据集Baseline预测Fig.3 Baseline prediction of ciao data sets
4.3 实验结果及分析
4.3.1 BaseLine预测
首先将数据集的90%作为训练集,其余的10%作为测试集,首先根据项目评分的平均值确定为数据集的总体偏置μ,其次根据公式(6)、(7)及初始化的λ1,λ2计算用户及项目的偏置,调整λ1,λ2的值提高BaseLine预测RMSE值,选择BaseLine预测的目的在于该算法的训练时间短,预测精度高,可以通过实验训练得到最优参数.
如图1是在Movielens数据集上做的Baseline预测,经实验发现当λ1=3,λ2=6,RMSE达到最优,最小为值为0.964.
如图2是在Ciao数据集上做的Baseline预测,经实验发现当λ1=58,λ2=43,RMSE达到最优,最小为值0.976.
如图3是在Epinions数据集上的Baseline预测,经实验发现当λ1=53,λ2=56,RMSE达到最优,最小为值0.998.
4.3.2 用户可信度指标分布与分析
以MovieLens 1M数据集为例,图4给出用户专业度、评价可信度、评价偏差度的分布情况.其中58.21%的用户专业度分布在[0,0.2]之间,56.4%的用户评价可信度分布在[0,0.1]之间,说明多数用户的专业度、评价可信度两种指标较低,少数用户评价可信度能在全体的用户评价可信度中体现个性化的特质.从图4可以看出,用户的评价偏差度分布几乎成正态分布,评价偏差度分布在[0.2,0.6]的用户所占比例为77.6%,说明用户大多数用户的评价偏差度就比较高(评价比较接近真实评分),以上足以说明选定专业用户以后(专家),该专家对项目的评分信任度可以由以上三种指标体现.

图4 评价指标分布图Fig.4 Distribution of evaluation index
4.3.3 稀疏用户分布
对于大型数据集,稀疏用户的数量比较大,图5按照用户评价项目数量,把MovieLens 1M数据集、Ciao数据集、Epinion数据集的用户分为4类,可以看出三种数据集第一类用户(本文视为稀疏用户)占全部用户的比例较大.
4.3.4 专家可信度分布与分析
以MovieLens1M数据集为例,图6表示专家信任值随着矫正次数的变化情况.在实验开始阶段,专家可信度指标之间系数是初始化值,所以专家可信度比较低,随着矫正次数的增加的专家信任值从100次矫正的0.12提升到0.63共经过了400次的矫正,从400次开始专家信任值稳定在[0.63,0.69]之间, 此时得出w1,w2,w3值分别为 0.31、0.46、0.23,在后续计算专家对此类别项目评分时,可以直接利用此训练后的系数值,但是对于不同类别的专家信任因子系数值不同,需要同样的方法训练得到.
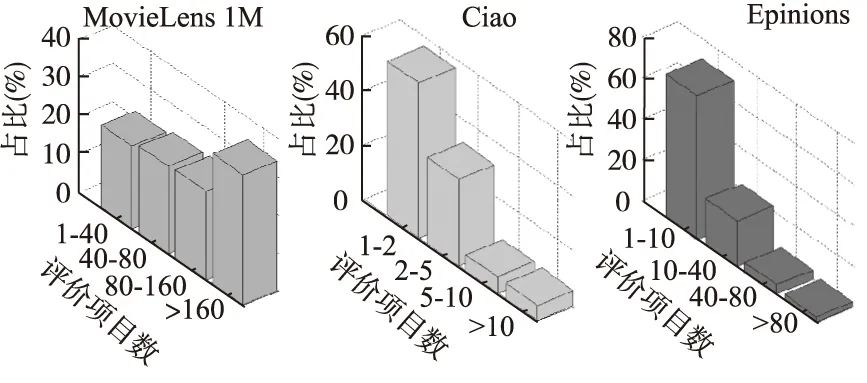
图5 用户评价项目数量分布图Fig.5 Distribution of users who evaluate items

图6 专家可信度分布图Fig.6 Distribution of expert′s reliability

图7 MovieLens 1M数据集上三种算法对比Fig.7 Three algorithms on MovieLens 1M DataSets

图8 Ciao数据集上三种算法对比Fig.8 Three algorithms on Ciao DataSets

图9 Epinion 数据集上三种算法对比Fig.9 Three algorithms on Epinion DataSets
4.3.5 在不同数据集上稀疏用户预测对比
本文选定三中数据集的第一类为测试集,从图8-图9三幅图可以明显看出,在实验开始阶段三种算法针对稀疏用户的预测准确度较低,随着专家人数的增加,相比于传统的EA、ESA算法,本文提出的IBETA算法在三种数据集下RMSE有普遍提高,这其中的原因是随着独立于用户与项目的偏置信息的加入,预测稀疏用户的项目评分增加了客观的预测值.随着稀疏用户评价项目的增多三种算法的预测准确性都有明显的上升趋势,原因是随着用户评价项目的增多,相似性计算能够更加明确的区分出用户与专家之间的相似性,由近邻算法的特点不难理解预测准确性提升.
5 结束语
本文研究了专家算法的产生与改进,IBETA算法在ESA算法和EA算法的基础上加入专家信任度用户、项目偏置信息.实验表明,改进后的带偏置专家信任协同过滤推荐算法在稀疏用户的预测准确性方面有较大提高,但是,在算法的改进过程中专家信任指标的融合还不够完善.所以,下一步工作的重心将放在信任的动态调整及建立有效的信任传递机制,使信任度量更加合理.
[1] Adomavicius G,Tuzhilin A.Toward the next generation of recommender system[J].IEEE Transactions on Knowledge & Data Engineering,2005,17(6):734-749.
[2] Zhu Yang-yong,Sun Qian.Research progress of recommendation system[J].Computer Science and Exploration,2015,9(5):513-525.
[3] Mcafee A,Brynjolfsson E.Big data:the management revolution[J].Harvard Business Review,2012,90(10):60-66.
[4] Piao C H,Zhao J,Zheng L J.Research on entropy-based collaborative filtering algorithm and personalized recommendation in e-commerce[J].Service Oriented Computing & Applications,2009,3(2):147-157.
[5] Yu Feng-quan,Wang Xu-ming,Xie Yan-hong.Comparison of data smoothing algorithms for flight data processing[J].Command Control and Simulation,2015,(1):116-119.
[6] Deng Ai-lin,Zhu Yang-yong,Shi Bo-le.Collaborative filtering recommendation algorithm based on project score predicts[J].Journal of Software,2003,14(9):1621-1628.
[7] Wang Q M,Liu X,Zhu R,et al.A new personalized recommendation algorithm of combining content-based and collaborative filters[J].Computer & Modernization,2013,1(8):64-67.
[8] Hwang W S,Lee H J,Kim S W,et al.On using category experts for improving the performance and accuracy in recommender systems[C].ACM International Conference on Information and Knowledge Management,2012:2355-2358.
[9] Liu Qiang.Research on the key algorithm in collaborative filtering recommendation system[D].Zhejiang University,2013.
[10] Breese J S,Heckerman D,Kadie C.Empirical analysis of predictive algorithms for collaborative filtering[C].Fourteenth Conference on Uncertainty in Artificial Intelligence,2013:43-52.
[11] Cho J,Kwon K,Park Y.Collaborative filtering using dual information sources[J].IEEE Intelligent Systems,2007,22(3):30-38.
[12] Gouya G,Arrich J,Wolzt M,et al.Antiplatelet treatment for prevention of cerebrovascular events in patients with vascular diseases[J].A Journal of Cerebral Circulation,2014,45(2):492-503.
[13] Marinho L B,Hotho A,Jöschke R,et al.Baseline techniques[M].US:Springer US,2012.
[14] Peng Fei,Deng Hao-jiang,Liu Lei.Add user ratings offset recommendation system model[J].Journal of Xi ′an Jiaotong University,2012,46(6):74-78.
[15] Shen Li-men,Wang Li-hua,Li Feng.An adaptive trust model based on time series analysis in opportunistic networks[J].Journal of Chinese Computer Systems,2015,36(7):1553-1558.
附中文参考文献:
[2] 朱扬勇,孙 婧.推荐系统研究进展[J].计算机科学与探索,2015,9(5):513-525.
[5] 于凤全,王旭明,谢彦宏.面向飞参数据处理应用的数据平滑算法对比[J].指挥控制与仿真,2015,(1):116-119.
[6] 邓爱林,朱扬勇,施伯乐.基于项目评分预测的协同过滤推荐算法[J].软件学报,2003,14(9):1621-1628.
[9] 刘 强.协同过滤推荐系统中的关键算法研究[D].浙江大学,2013.
[14] 彭 飞,邓浩江,刘 磊.加入用户评分偏置的推荐系统排名模型[J].西安交通大学学报,2012,46(6):74-78.
[15] 申利民,王立华,李 峰.机会网络中基于时间序列分析的自适应信任模型[J].小型微型计算机系统,2015,36(7):1553-1558.
猜你喜欢
智能计算机与应用(2022年9期)2022-09-28
汽车实用技术(2022年15期)2022-08-19
中国信息化(2022年5期)2022-06-13
计算机应用(2022年2期)2022-03-01
北京汽车(2021年1期)2021-03-04
桃之夭夭B(2017年2期)2017-02-24
宠物世界·猫迷(2016年3期)2016-04-23
少儿科学周刊·少年版(2015年3期)2015-07-07
高中生·青春励志(2014年11期)2014-11-25
家庭医学(2009年2期)2009-02-25
