
基于机器学习的用户窃电预测及用电检查计划辅助编排研究
2018-03-21 02:34蔡嘉荣王顺意吴广财
电子测试 2018年2期
蔡嘉荣,王顺意,吴广财
(广东电网有限责任公司,广东广州,510080)
1 绪论
1.1 背景与意义
2014年,南方某县级供电公司统计该地区非正常技术损耗电量5163万度。其中,居民和农村地区理论上被盗窃电量达4290万度,占理论总被盗窃电量的83%,按居民用电0.61元/度计算,损失电费超2600万元。由此可见,每年因窃电对国家资产造成了巨大损失。
目前供电企业反窃电工作主要存在查证难、取证难、定量难的问题,用检人员在查证上往往无从入手。一方面电力营销中总供电量和总售电量之差称为线损,往往与用户窃电很容易混杂,另一方面窃电用户越加狡猾,窃电手法更加隐蔽,不再局限于传统的改接线路等方法,同时普通用检人员由于理论与实践上的约束,增加了反窃电管理难度。
1.2 本文主要工作
本文主要通过选取历史用户用电行为数据(包括窃电数据实例),运用机器学习算法对用户窃电行为进行有监督学习,形成用户窃电分类模型,同时使用当年用电检查实际数据对模型进行检验,分析模型识别准确率,为实际用检工作提供参考。
2 用户窃电检查现状分析
为了维护正常供用电秩序和公共安全,保护供用电双方的合法权益,供电企业按照《电力供应与使用条例》等法规履行用电检查职责,其中周期检查和专项检查是供电企业用电检查的两大手段,供电企业应在每年第四季度编制出下一年度周期检查计划,在每月末要及时编制下月周期检查计划。对于0.4千伏及以下的居民客户每年按不低于1%的比例进行抽查,其他客户每年按不低于5%的比例进行抽查。对于客户安全风险等级较高客户应缩短检查周期。
3 基于机器学习的用户窃电预测方案
3.1 数据选择和处理
供电企业用电检查业务指导说明书中明确指出:对于客户线损异常、抄表异常、计量异常、业扩变更异常、举报、投诉、无档案户(黑户)违窃电等情况,应开展专项检查。归纳起来,营销线损、电费、计量、业扩、客服、稽查等专业数据可作为用户窃电预测信息来源。
将上述业务数据从时间维度上划分,可分为静态数据和动态数据两大类,静态数据主要包括用户编号、用户名称、用户类别、电压等级、信用等级、地区类型、行业类别、用电类型、用电性质、用电容量、用电地址、计量点与用户关联关系、平均月电能量、平均月电费、欠费记录、违约记录、客户投诉举报记录、现场检查记录等;动态数据包括电表表码数据、电压数据、电流数据、相位角、台区线损、线路线损、电能量差动异常、电能表开盖、电能表停走、三相不平衡、电流过流、电压断相、电能表失压、电能表失流、用电负荷、各行业类别平均用电情况等。
3.2 确定目标和算法
用户窃电预测本质上为分类问题,即通过适当的模型可以将实际的、未知的用户用电行为数据进行自动分类(如正常、窃电两类),同时分类过程要求可解释性强,便于用检人员调查取证。
基于上述考虑,本文采用决策树方法,其构建思路如下:(1)给一个带有类标签(正常/窃电)的样本数据集;(2)选择信息量大的属性作为根结点;(3)根据根结点属性的取值对数据集进行划分,形成一个二叉(或多叉)树;(4)根据分叉将数据又分成几个数据集;(5)再递归用其余属性对几个数据集进行划分,直到分类属性为止。
决策树方法难点在于如何选择属性进行分枝。决策树中越靠近根节点的属性,该属性对分类的决定越重要,信息增益是属性选择的一个重要指标(信息增益=信息熵-条件熵),属性越重要,信息增益越大。
信息熵的计算公式如下:
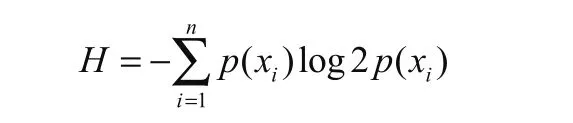
其中的n代表有n个分类类别(本文n取2,即只有正常、窃电两种情况)。分别计算这2类样本在总样本中出现的概率p1和p2,这样就可以计算出未选中属性分枝前的信息熵。
现在选中一个属性xj(假定是电压等级) 用来进行分枝,此时分枝规则是:如果xj=vx(假定vx=0.4kV)的话,将样本分到树的一个分支;如果不相等则进入另一个分支。很显然,分支中的样本很有可能包括2个类别(即0.4kV用户中同时有正常和窃电两种分类),分别计算这2个分支的熵H1和H2,计算出知道属性xj之后的条件熵H’=p1*H1+p2*H2(此时p1表示0.4kV用户在样本中出现的概率,p2表示其他用户出现的概率)。则此时的信息增益ΔH=H-H’。以信息增益为原则,把所有的属性都计算一遍,选择信息增益最大的属性根节点,以此类推直至分类属性为止。
3.3 数据挖掘及评价
首先,通过带有类别标记的样本集进行机器学习,由于样本的标记是人给定的,也称有指导的学习。这个样本集称训练样本集。训练样本集的样本典型(有代表性)量越多,学到的模型就会好。
为了测试模型的准确性,可用一个测试样本集测试分类器的准确性,实际过程中可由用检部门设定模型准确度阀值,当没有达到阀值时,可增加训练样本集重新训练模型直至满足要求为止。
对于实际用电检查过程中,任意给定一个没有标记的实际数据,用学到的模型对其进行分类,即可给出其分类标记。
4 用电检查计划辅助编排方案
用电检查计划制定过程中首要风险点在于遗漏检查客户,对于大客户和重要客户,目前只能采取定期检查的手段(每半年至每两年检查一次);而对于数量庞大的0.4千伏及以下的居民客户,只能按照1%的比例去抽取检查对象,检查的盲目性太大。
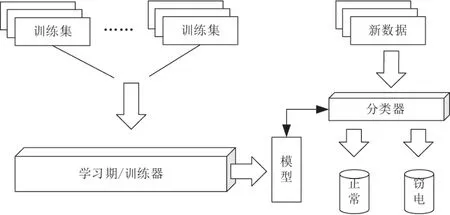
图1 机器学习示意图
运用本文方法对用电客户的窃电潜在行为进行预测,有针对性地根据概率安排用户用检顺序,优化班组工作计划性,帮助供电用检人员有针对性地开展用户检查工作,提升用检查处效率,同时也解决过去用检工作查证难的问题。
5 结语
本文通过分析用户用电相关特征及数据,运用机器学习决策树方法,对窃电行为进行科学的数学判断,帮助工作人员及时发现用户是否存在窃电行为,有效减少窃电行为给供电企业所带来的经济损失,同时也能很好地避免因窃电、破坏电力设备行为造成的人身伤亡和电气火灾事故,保障人民生命财产安全,减少用电纠纷。
[1]周瑾.国网江苏电力应用大数据分析精准反窃电[J].国家电网报,2017,5(第003版).
[2]凤凰资讯.一年被窃电3000万元,2016年01月07日,http://news.ifeng.com/a/20160107/46971190_0.shtm l.
[3]吴毅良,基于Hadoop的窃电预测平台研究[J].电气工程与自动化,2017(6).
猜你喜欢
智能建筑电气技术(2022年2期)2022-02-06
北京航空航天大学学报(2021年6期)2021-07-20
中国化肥信息(2021年12期)2021-04-19
中学生数理化·中考版(2020年12期)2021-01-18
中国电业与能源(2020年7期)2020-08-18
电子制作(2019年19期)2019-11-23
红土地(2019年10期)2019-10-30
中学生数理化·中考版(2018年12期)2019-01-31
小学生必读(中年级版)(2018年10期)2019-01-04
电子制作(2018年19期)2018-11-14
