
Word文本解析和关键字快速匹配方法*
2018-03-21 00:56廖怨婷兰小龙陈庆春
通信技术 2018年3期
廖怨婷,兰小龙,陈庆春
0 引 言
在大数据时代,网络技术快速发展带动着各行各业朝着信息化方向发展的同时,网络安全事件频繁发生。如何保护网上信息安全和数据安全,具有重要的理论和应用价值[1]。随着电子文档的普及应用,现在办公基本无纸化。企业的大量重要数据和保密信息基本以电子文档的形式存在,各种敏感信息和保密数据时刻受到潜在的泄露风险。这些敏感信息直接或间接地关系到企业或个人的数据安全,甚至关系到国家的信息安全。由此可见,对电子文档的涉密信息进行保护,或者对敏感数据进行防泄漏处理,是保护网上内容信息安全的重要需求[2-3]。
本文提出一种Word文本内容解析及关键字快速匹配方法。首先以Microsoft Word文件为背景,研究Office套件中文字处理软件Word组件的二进制格式。在此基础上,分析如何在不安装任何Microsoft Word办公软件的情况下,实现对Word文档格式判别并读取Word文本内容。同时,为了对文本内容的敏感信息进行保护,提出在读取文本内容的同时,使用模式匹配算法对敏感信息进行查找。最终,在对现有的BM、BMH以及BMHS等算法进行分析比较的基础上,提出了一种改进的BMHS算法。研究结果表明,所提方法适用于网络在线的Word文本内容解析与敏感信息的保护要求。
1 Word文档解析方法
Microsoft Office文 件 中,Microsoft Word 97-2003文档(.doc)是一种典型的复合二进制文件[4]。复合文档的整个文件由一个头(Header)以及其后的所有扇区(Sectors)组成,结构如图1所示。其中,头(Header)大小为定长512字节,每个扇区的大小都相同,其大小由头指定。根据头的前8字节(D0H CFH 11H E0H A1H B1H 1AH E1H),可判断接收文件是否为复合文档[5]。

图1 复合文档结构
复合文档包含很多独立的数据流,这些数据流存放在不同的仓库(Storage)中。流又都被划分成小数据块,叫做扇区(Sectors)。目录(Directory)用来控制复合文档中独立的数据流,由一系列目录入口组成。每一个目录的入口都指向复合文档的一个仓库或流。目录入口以其在目录流中出现的顺序被列举,一个以0开始的目录入口索引称为目录入口标识(Directory Entry IDentifier,DEID)。每个目录入口的大小为定长128字节。
.doc文件的文本内容存储在“WordDocument”流中。确定文件为复合文档后,需要找到存放流的目录入口。遍历所有目录入口,直到找到“WordDocument”流。遍历方法可通过目录入口的前64字节判定其入口名字为“WordDocument”。计算第一个目录流的偏移量的公式为:

其中512指头的长度;SID(Secror Identifier,扇区标识)是一个扇区的索引值,位于头的第48字节;s_size是复合文档中扇区的大小(ssz),以2的幂形式存储,位于头的第30字节。
对于“WordDocument”流,最重要的是其中包含的FIB(File Information Block,文件信息块)。FIB从“WordDocument”流的偏移0x00开始。FIB是可变长的,其中FIB最开始为定长32字节的FibBase结构。根据FIB的前2字节(A5H ECH),可判断接收文件是否为Word二进制文件,即.doc文件。FIB指定文件中所有其他数据的位置。位置由一对整数指定,第一个整数指定位置,第二个整数指定大小。这些整数出现在FIB的子结构中,如FibRgFcLcb97。位置名称带有前缀fc,大小名称带有前缀lcb。
在确定文档为.doc文件后,需要读取Clx结构信息。Clx结构是由零个或多个Prc结构组成的包含属性信息的数组,后跟一个Pcdt结构。该结构又包含一个PlcPcd结构。PlcPcd结构将一个字符位置数组映射到Pcd结构。换言之,它将流中的字符位置映射到文档文本中的字符。Pcd结构指定文本在“WordDocument”流中的位置,同时指定文本的一些属性。
Clx相对文本的偏移地址=“Table Steam”流的偏移位置+fcClx (2)
其中,获取“Table Steam”流的偏移位置同WordDocument”流,其目录入口名为“1Table”;fcClx在FIB第268个字节处读取,指定了Clx相对“Table Steam”流的偏移位置。具体地,确定Clx相对文本的偏移位置流程,如图2所示。
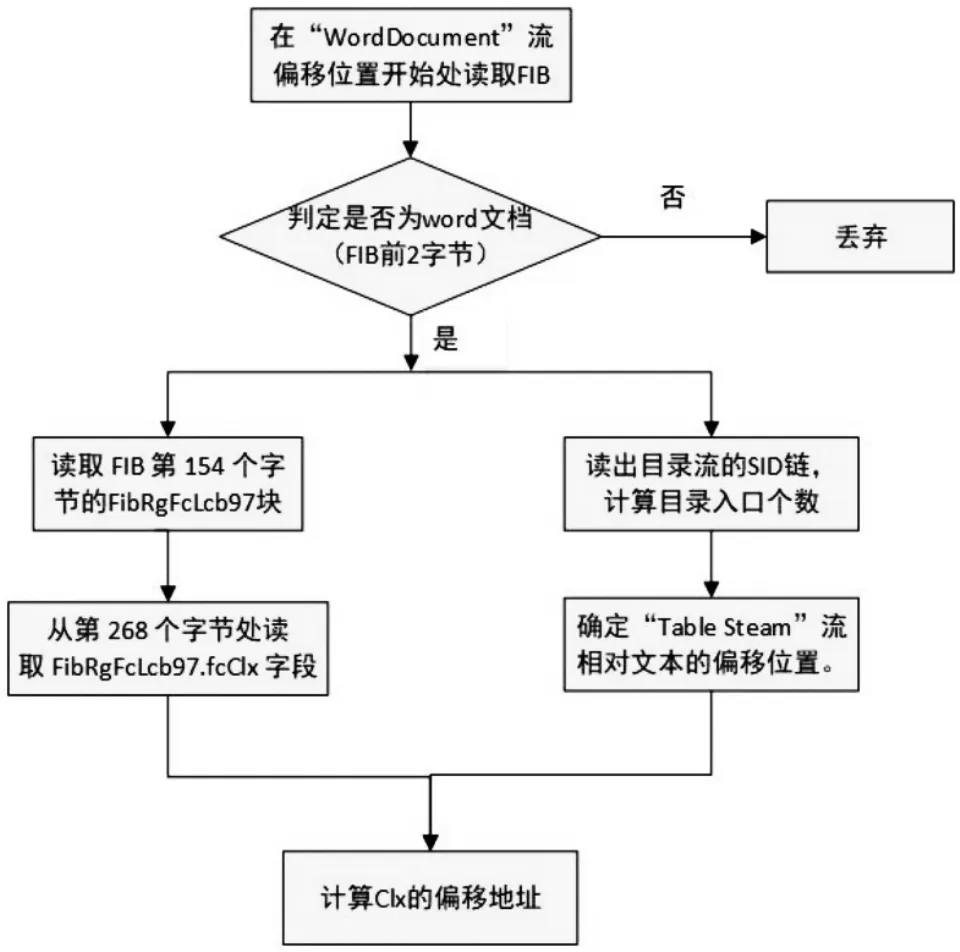
图2 Clx相对文本的偏移位置流程图
Clx的结构如图3所示,其中RgPrc若为空,第一字节必为0x02。Pcdt结构如图4所示,如果clxt=0x02,表明已找到Pcdt,其中lcb在FIB第272个字节处读取,指定了PlcPcd的大小。
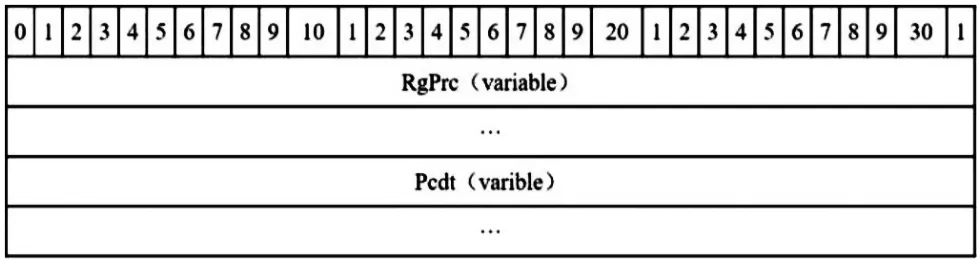
图3 Clx结构
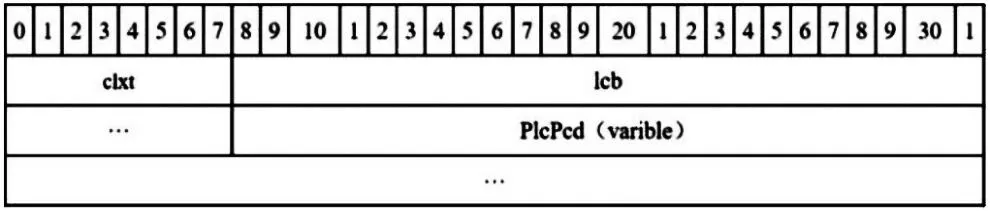
图4 Pcdt结构
PlcPcd结构从Pcdt的第5个字节开始。一个PlcPcd结构包含一个(乃至以上)aCP和一个(乃至以上)aPcd,每个aCP是4字节,每个aPcd是8字节。计算aPcd的个数n,即:

加载这些aPcd数组和aCp数组。这些数组的成员通过索引值彼此对应。对于每个aPcd结构,在当前第46位处读取fCompressed字段的值。如果fCompressed=0,则Pcd结构指代一个16位的Unicode字符。如果fCompressed=1,则指代一个8位的ANSI字符。如果是Unicode,则文本的起始偏移量等于在“WordDocument”流中的Fc值(位于当前Pcd的第2~5个字节),且每个字符占2个字节;如果是ANSI,文本开始于Fc值的一半的偏移量处,且每个字符占1个字节。至此,.doc文件中的文本内容的位置就可以准确确定。
2 改进的BMHS匹配算法
在Word文档解析的基础上,字符串的模式匹配可以应用于搜索和查找特定的字符串位置。对于长度为n的文本串T=T0T1T2…Tn-1,假设模式串P=P0P1P2…Pm-1的长度为m(n≥m),在T中查找模式串P首次出现的位置。如果在文本串T总存在等于模式串P的子串,则匹配成功,返回模式串P首次出现在文本串T中的位置;否则,称为匹配失败。这个过程称为模式匹配。
目前,国内外已提出了不少模式匹配算法。典型的BF算法[6]是从文本串T的开始位置开始逐个字符依次匹配,算法的时间复杂度是O(n×m),BF算法虽然简单但效率很低。KMP算法[7]在匹配过程中遇到不匹配时,不产生回溯,而是根据已有的部分匹配结果,令P向右滑动到某个位置,然后重新开始进行匹配。这在一定程度上提高了匹配效率,减少了匹配次数,但时间复杂度依然达到O(n+m)。BM算法[8]是由Robert S. Boyer教授和J Strother Moore教授提出的一种新的字符串匹配算法。该算法从模式串P的尾部与文本串T自右向左开始匹配。如果不匹配,则根据模式串P决定的好后缀规则和坏字符规则进行右移,降低无效的匹配次数,然后继续与文本串T进行匹配,直至匹配成功或者文本串T匹配结束。实践中,BM算法比KMP算法的实际效率更高,因而得到了广泛应用。BMH算法[9]进一步解决了BM算法中模式串P有可能左移的问题。在BMH中,无论失配发生在当前文本串T中的什么位置,都由文本T中和模式串P的尾字符对应的字符决定右移距离。它摒弃了好后缀规则后,省去了求最大值的计算。
BMH算法的坏字符规则如下:
当模式串P从右向左与文本串T进行匹配时,若模式串P中某个字符x与文本串T中相对应字符不匹配,即出现坏字符时,则根据式(4)跳转:

其中P[ j ]代表模式串P中的第j个字符,max(x)表示字符m出现在模式串P中最右的位置。
2.1 BMHS算法
BMHS算法[10]在BMH算法的基础上又进一步进行了改进,主要思想是:由文本T中和模式串P的尾字符的下一个字符(即当前匹配窗口的下一个字符)对应的字符决定右移距离。这使得最大和平常情况下,它的速度优于BMH。
BMHS算法中坏字符规则为:
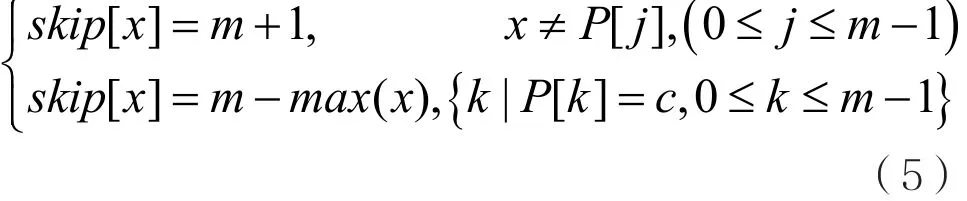
2.2 改进的BMHS算法
通过对模式串P特点的分析以及经过实际测试,本文对BMHS算法做出改进。实际应用中,匹配的模式串P多数情况下是一个英文单词。通常,英文单词有相同前缀或后缀的概率较高,而单词中间部分相同的概率较小,如internet与interaction、sixteen与seventeen等。因此,本文在保留BMHS算法的坏字符规则和根据当前匹配窗口的下一个字符决定右移距离的思想的基础上,针对相同前后缀出现的概率大、中间部分相同的概率小这一特点,对BMHS算法进行改进。具体地,匹配过程中,先匹配模式串P的尾字符,若匹配成功,则匹配模式串P的首字符;若依然匹配,则匹配模式串P中间的字符。最后,从P的第二个字符依次匹配,直至倒数第二个字符,其中跳过中间的字符。整个过程中,一旦出现不匹配,则根据式(4)向右移动相应的距离。改进的BMHS算法实现流程如图5所示。
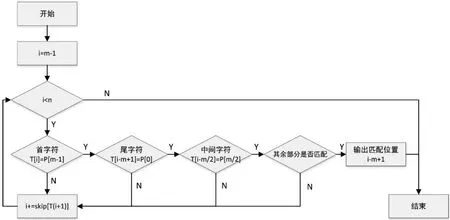
图5 改进的BMHS算法基本流程
3 实验结果
3.1 BMHS和改进BMHS算法比较分析
基于对BMHS算法和改进的BMHS算法进行的简单说明,下面将从匹配次数和比对次数2个方面对BMHS和改进BMHS算法进行详细比较。实验平台是windows 10操作系统,开发工具是Microsoft Visual Studio 2013。
文本串T=“nagativelasgrelfcivehbdcgm relative”,模式串P=“relative”。根据模式串P计算的坏字符表,如表1所示。BMHS和改进BMHS算法的详细匹配过程,分别如图6、图7所示。

表1 BMHS和改进的BMHS算法中模式串P的坏字符表

图6 BMHS算法匹配过程

图7 改进的BMHS算法匹配过程
可以看出,改进的BMHS算法在匹配过程中,相比于BMHS算法减少了比对次数。这是因为文本串中出现了前后缀相同的单词,改进算法有效避开了这类单词,减少了比对次数。这种优势在较大的文档中能更好地体现出来。
下面从时间消耗方面比较BMHS算法和改进BMHS算法的性能。
(1)对同一个大小为575 kB的文档,用2种匹配算法对模式串P=“life”进行匹配,实验结果如表2、图8所示。
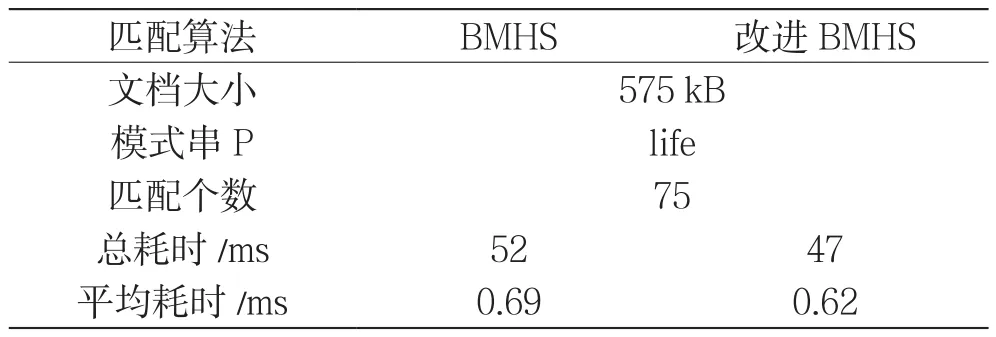
表2 文档匹配耗时比较
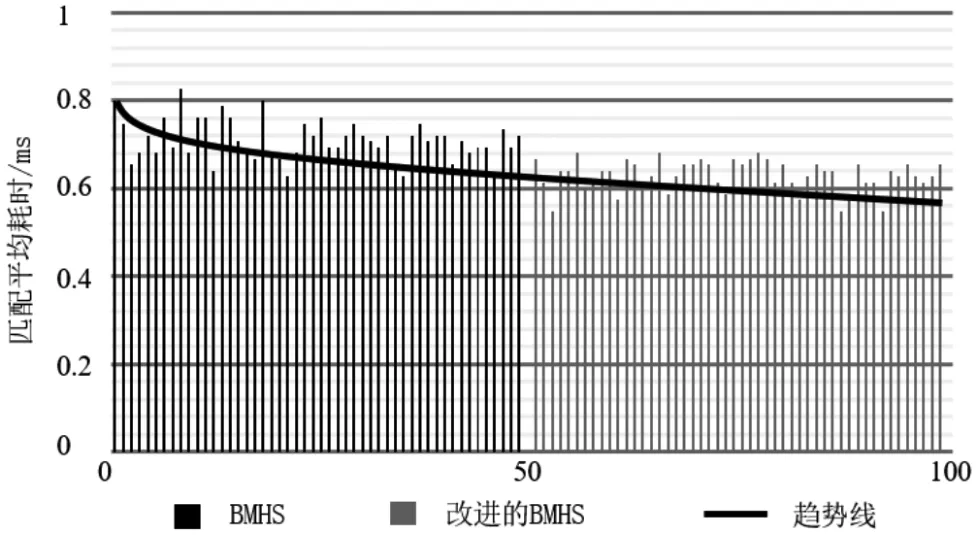
图8 文档匹配耗时比较结果
表2显示模式串“life”在文档中共检测到75次,用改进BMHS算法匹配完成后,总耗时和平均耗时均小于BMHS算法。
图8中,对2种匹配算法共进行了各50次匹配实验,纵坐标表示单词匹配所消耗的时间,单位为ms,其中黑色为BMHS算法的匹配结果,灰色为改进的BMHS算法的匹配结果。从所耗时间的整体趋势可以看出,本文提出的算法对BMHS算法有一定程度的改进,耗时缩小。
(2)针对不同长度字符串对BMHS算法和改进BMHS算法的影响,本文对不同模式串长度下两种匹配算法的耗时进行比较和分析。实验中,针对长度从2~15的不同模式串用2种算法进行匹配,每次匹配时间的结果比较如表3、图9所示。
从表3、图9的比较结果可以看出,对于长度在4~11的模式串,本文提出的改进BMHS算法要比BMHS算法耗时少。因为英文单词大部分长度都在这个范围内,前后缀相同的单词有很大概率在匹配过程中遇到。当模式串长度长于12时,文本中很少遇到这种单词,因此两种算法的耗时基本一样,体现不出优越性。
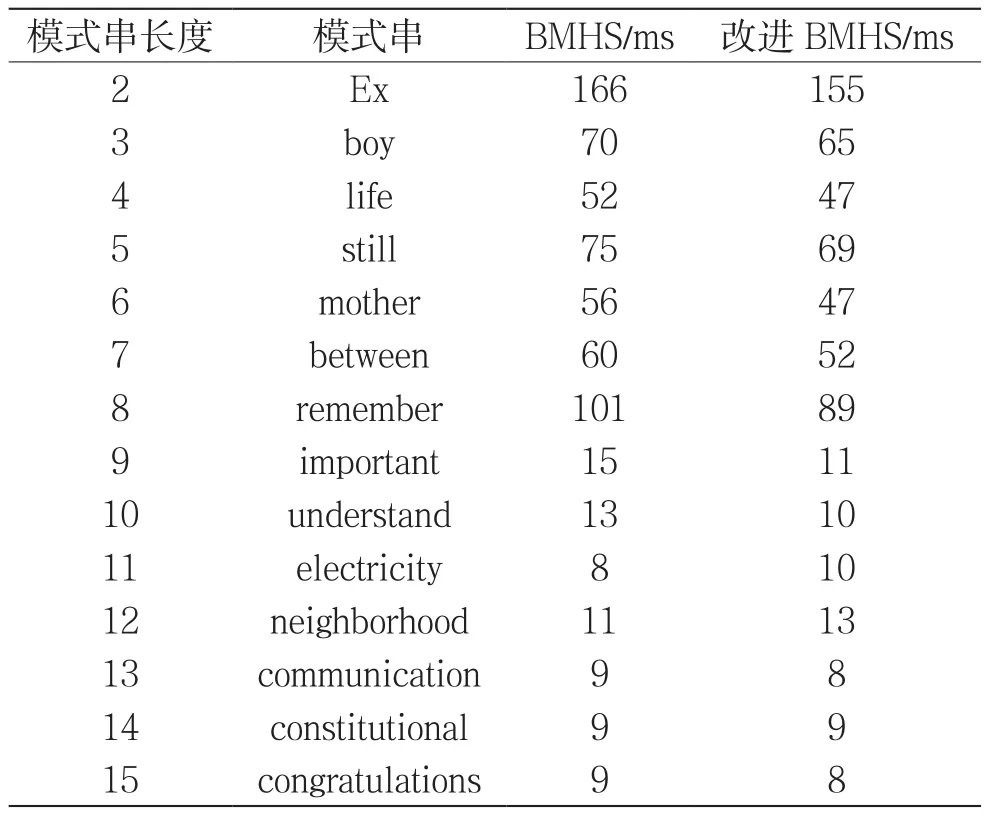
表3 不同长度模式串下两种匹配算法耗时比较
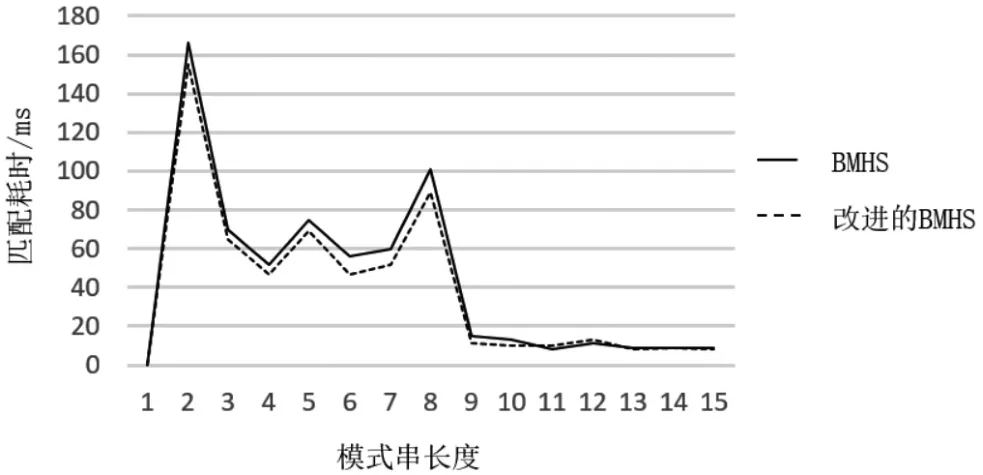
图9 不同长度模式串下两种匹配算法耗时
3.2 Word文本解析及脱敏
通过对Word文本格式的分析,运用改进的BMHS算法,针对测试文档地址(http∶//xueshu.baidu.com/s?wd=paperuri%3A%28872b584de8d1c2358b1c401caf810527%2 9&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Fieeexplore.ieee.org%2Fdocument%2F 6918451%2F&ie=utf-8&sc_us=16970001388366800462)下载Word文档,后对其“Vehicle”敏感词汇进行脱敏,结果如图10所示。可以看到,凡是出现“Vehicle”的地方均变成了****。

图10 Word文档解析及脱敏效果展示
4 结 语
本文研究了Word文件的二进制格式,在无需Microsoft Office办公软件的条件下,能够对Word文档进行格式判别和文本内容解析,方法简单易行,解析结果准确清晰。本文使用模式匹配算法对文本内容的敏感信息进行快速定位,在研究了BM、BMH以及BMHS等算法的基础上,提出了一种基于BMHS的改进快速匹配算法。实验结果显示,本文提出的改进的BMHS算法相比BMHS算法,匹配次数有所减少,匹配时间有所降低,更好地提高了匹配效率。
[1] 闫玺玺.开放网络环境下敏感数据安全与防泄密关键技术研究[D].北京:北京邮电大学,2012.YAN Xi-xi.Research on Key Technologies of Security and Anti-leakage of Sensitive Data in Open Network[D].Beijing:Beijing University of Posts and Telecommunications,2012.
[2] 陈天莹,陈剑锋.大数据环境下的智能数据脱敏系统[J].通信技术,2016,49(07):915-922.CHEN Tian-ying,CHEN Jian-feng.Detective Data Depletion System Based on Big Data Environment[J].Communications Technology,2016,49(07):915-922.
[3] 胡卿.电子文档防泄密系统研究与实现[D].济宁:曲阜师范大学,2013.HU Qing.Research and Implementation of Electronic Document Anti-leakage System[D].Jining:Qufu Normal University,2013.
[4] Microsoft.[MS-DOC]:Word(.doc) Binary File Format[EB/OL].(2016-01-01)[2017-11-24].https://msdn.microsoft.com/enus/library/office/cc313153(v=office.12).aspx.
[5] Daniel R.Microsoft Compound Document File Format[EB/OL].(2004-01-01)[2017-11-24].http://www.openoffice.org/sc/compdocfileformat.pdf.
[6] GUO Jiong,Hermelin,Danny,et al.Local Search for String Problems:Brute-force is Essentially Optimal[J].Theoretical Computer Science,2014,525(03):30-41.
[7] WANG Cheng,LIU Jin-gang.An Improved String Matching Algorithm[J].Computer Engineering,2006,32(02):62-64.
[8] Boyer R S,Moore J S.A Fast String Searching Algorithm[J].Communications of the ACM,1977,20(10):762-772.
[9] 刘胜飞,张云泉.一种改进的BMH模式匹配算法[J].计算机科学,2008(11):164-165,173.LIU Sheng-fei,ZHANG Yun-quan.An Improved BMH Pattern Matching Algorithm[J].Computer Science,2008(11):164-165,173.
[10] 朱宁洪.字符串匹配算法Sunday的改进[J].西安科技大学学报,2016,36(01):111-115.ZHU Ning-hong.Improvement of String Matching Algorithm Sunday[J].Journal of Xi'an University of Science and Technology,2016,36(01):111-115.
猜你喜欢
中国交通信息化(2022年4期)2022-06-17
销售与市场(营销版)(2021年10期)2021-11-21
中国交通信息化(2020年7期)2021-01-14
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
销售与市场(营销版)(2019年6期)2019-06-21
动漫星空(兴趣百科)(2018年5期)2018-10-26
计算机应用与软件(2018年10期)2018-10-24
