
一种基于深度相机的机器人室内导航点云地图生成方法
2018-03-20 02:55马跃龙曹雪峰李登峰
测绘工程 2018年3期
马跃龙,曹雪峰,万 刚,李登峰
(1.信息工程大学,河南 郑州 450052;2.炮兵训练基地,河北 宣化 075100)
地图是人类空间认知的工具,无论早期的纸质地图还是如今的电子地图,都在人类的日常生活中发挥着重要作用[1]。随着以无人车、无人机为典型代表的智能机器人平台逐渐进入人们的视野,智能机器人的自主导航成为当前的研究热点,而作为导航基础的地图生成方法更是成为智能机器人自主导航的关键。
点云是智能机器人导航地图的一种有效表示形式。目前智能机器人的点云获取主要有激光点云与图像点云两种主要方式。三维激光扫描仪能够直接快速地获取高精度的三维激光点云,在城市建模[2]、文物与古建筑修复[3-4]等领域得到了成功的应用。三维激光扫描仪造价高昂,体积较大,常常需要车载或机载配合使用;所获取的点云数据量较大,处理较为复杂,需要人工对点云数据进行编辑。
图像点云的生成主要有SfM与SLAM两种方法。计算机视觉领域的SfM(Structure from Motion)方法通过对大量无序图片的离线处理,恢复相机的运动轨迹并重建相应的图像点云,进而恢复三维场景结构[5-6]。经过几十年的发展,SfM方法相对较为成熟,并且有PhotoScan与Pix4D等成熟的商业软件可供选用。由于SfM方法大多使用单目相机作为图像获取手段,因而在处理过程中不容易获得三维场景结构的真实尺度,且其离线处理方式使其不适用于实时性要求较高的应用场景。
机器人领域的SLAM(Simultaneous Localization and Mapping)问题自20世纪80年代提出,至今已经过近30年的发展[7]。早期的SLAM研究主要以激光、声纳等测距类传感器为主。随着传感器技术以及计算机视觉技术的发展,特别是多视图几何技术[8]的逐渐成熟,简单轻便的单目、双目以及深度(RGBD)相机等图像类传感器越来越受到研究者的青睐。
以微软Kinect代表的深度相机可同时获取彩色图像与深度图像,为室内模型构建与机器人导航地图的生成提供了新工具。KinectFusion[9]通过ICP(Iterative Closest Point)算法实现点云数据之间的配准,估计相机在空间中的运动;基于体素格网实现室内物体的表面重建,所有的测量直接融合为体素表示。KinectFusion可实时计算,但由于算法的复杂性,需要高性能显卡的支持,且体素的表达方式内存占用较大,仅适用于小范围场景。Kintinuous[10]通过移动带有当前相机位姿的体素格网动态改变融合区域,改进KinectFusion的内存占用问题,采用基于BoW(Bag of Words)[11]的环路检测算法降低了位姿估计误差的累积影响,通过CUDA运算实现相机位姿的实时估计与图像点云的实时拼接,但位姿估计的精度有待进一步提高。RGBD-SLAM[12]是为开源社区广泛使用的实时SLAM系统,通过相邻图像帧之间的视觉特征提取与匹配估计相机运动,并通过ICP算法对估计得到的相机运动进行验证以保证相机位姿估计的正确性,而位姿估计的实时性与精度有待进一步提高。DVO[13-14]通过直接方法(Direct-Method)利用像素强度实现相邻图像帧的配准并估计相机位姿。相比于ICP算法,DVO可通过CPU实现实时运算。DVO适用于窄基线场景(相机运动变化较小),对于相机运动变化较大的情况鲁棒性不高,且直接方法受光照条件的影响较大,因而对所使用的相机有较高的要求。
为了能够实时精确地生成机器人室内导航所需的点云地图,本文提出一种基于深度相机的视觉特征与ICP相融合的点云地图生成方法。
1 算法设计
本文提出一种基于深度相机的机器人室内导航点云地图实时生成方法:①利用ORB(Oriented FAST and Rotated BRIEF)算子对深度相机所拍摄的彩色序列图像进行视觉特征的快速提取与匹配,结合ICP算法,实时估计相机位姿;②在相机位姿优化操作中添加ICP误差约束,应用图优化算法[15]对深度相机所获取的彩色图像的投影误差以及深度图像的反投影误差进行联合优化,得到相对精确的相机位姿与三维稀疏点云;③利用估计得到的相机位姿对关键帧所对应的稠密图像点云进行拼接融合,得到稠密点云表示的机器人室内导航点云地图。算法流程如图1所示。
1.1 相机模型
由深度相机可以同时获得彩色图像IRGB→R3与深度图像ID→R。设标准针孔相机的焦距为f,相机投影中心沿图像x轴与y轴的偏移分别为cx与cy,将三维空间中某点P=(X,Y,Z)T映射为图像像素位置p=(u,v)的投影函数π[8]定义为
(1)
给定图像像素坐标p=(u,v)T以及所对应的深度值Z(p),重建空间三维点的反投影函数π-1可定义为
(2)
相机刚体变换[16]定义为
g=[R|t]∈SE(3).
(3)
其中R∈SO(3)为正交旋转矩阵,t∈R3为平移矩阵。
将相机位姿定义为刚体变换矩阵,并使用曲线坐标系(twist coordinate)表示:
ξ=(v1,v2,v3,w1,w2,w3)T.
(4)
其中,[v1,v2,v3]∈R3表示相机的线性速度,[w1,w2,w3]∈R3表示相机的角速度。
由李群与李代数的运算规则,相机在空间中的刚体变换(位姿)可表示为
g=exp(ξ).
(5)

图1 算法流程
1.2 相机跟踪
将第一帧图像所对应的相机位姿ξ0=(0,0,0,0,0,0)T定义为世界坐标系的原点,通过相邻两帧图像之间的相对变化估计相机位姿,并描述相机在三维空间中的运动。
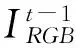
(6)

通过优化彩色图像的投影误差,可以得到相机位姿为
(7)

1.3 关键帧处理
在SLAM点云地图中并不会保存所有的图像帧,而是选择保存满足一定条件的关键帧。将两帧图像之间的相对距离定义为相机位姿的平移与旋转的权重组合:
(8)
式中:W是一个对角矩阵,表示ξji中每个参数的权重。如果当前帧与上一个关键帧Ki-1之间的距离超过所设定的阀值时,则创建新的关键帧Ki。
对关键帧的处理:
1)三角化匹配的特征点生成3D地图点。为了尽可能多地生成3D地图点,对于跟踪中未成功匹配的所有特征点,沿极线在相邻关键帧中查找更多的匹配。
2)执行数据关联操作融合重复的地图点,并剔除误差较大的地图点。
3)计算并注册新关键帧的BoW向量,以用于后续操作的快速搜索与匹配。
4)进行局部优化,优化相机位姿与3D地图点坐标。
对新添加的关键帧K,通过BoW向量快速检索与关键帧K共享相同视觉单词(Visual Words)的关键帧构成局部关键帧集合KL,同时与关键帧集合KL相对应的3D地图点集合。对关键帧集合KL以及相对应的3D地图点集合进行投影误差与反投影误差的联合优化,以提高关键帧所对应的相机位姿以及3D地图点坐标的估计精度。

(9)

彩色图像的投影误差为
(10)
对彩色图像的投影误差与深度图像的反投影误差进行联合优化:
(11)
其中wrgb为彩色图像投影误差的权重参数。
1.4 环路检测与地图优化
由于估计误差的不断累积,在视觉SLAM中相机跟踪漂移是不可避免的。为了有效地抑制误差累积的影响,得到更好的全局一致地图,在SLAM处理流程中引入基于BoW[11]的环路检测。
在关键帧处理阶段,为新生成的关键帧注册BoW向量。在环路检测阶段,对于当前关键帧,在已构建的BoW向量数据库中检索与当前关键帧共享相同视觉单词的关键帧作为环路候选项,计算其与当前关键帧的相似度,并选择相似度超过一定阀值的关键帧作为环路候选项。为了提高系统的鲁棒性与环路检测的准确性,仅选择其相邻帧作为环路候选项,并使用RANSAC方法计算其与当前关键帧的变换关系,选择满足一定数量的关键帧作为环路关键帧,确保与当前关键帧的几何一致性。
在检测到SLAM环路之后,执行数据关联操作融合重复的地图点,利用位姿图优化方法对构成环路的关键帧以及所对应的3D地图点进行投影误差与反投影误差的联合优化,提高SLAM位姿估计精度,得到全局一致地图。
2 实验结果
2.1 机器人测试
使用Turtlebot作为机器人平台,搭载Asus Xtion Pro深度相机,并使用安装有Intel Core I5-3230 CPU,8G内存,64位Debian Sid系统的笔记本电脑作为主控计算机,负责Turtlebot机器人的运行控制与SLAM信息处理,通过手动遥控方式控制机器人在室内行走,构建机器人室内导航点云地图。
对深度相机所拍摄的序列图像进行视觉特征提取,通过相邻图像帧之间的特征点匹配集合实时估计相机位姿,得到相机在空间中的运动轨迹,如图2所示。

图2 相机估计轨迹
利用所获取的深度图像,对相邻图像帧之间的特征点匹配集合执行三角化操作,重建图像像素点所对应的空间三维点坐标,得到稀疏三维点云,如图3所示。

图3 三维稀疏点云
由关键帧对应的彩色图像与深度图像可得到该关键帧所对应的三维点云,利用估计得到的相机位姿对关键帧所对应的三维点云进行拼接融合,得到以稠密点云表示的三维空间场景结构,如图4所示。

图4 稠密点云表示的室内三维场景
为了对所生成的稠密点云进行有效的管理与使用,使用八叉树对稠密点云进行剖分与管理,所得到结果如图5所示(分辨率0.01 m)。

图5 稠密点云的八叉树表示
为了测试本文方法的效率,对关键步骤进行速度度量,结果如表1所示。
由定位速度的测试结果可以看出,本文方法中的相机跟踪平均耗时为23.5 ms,即可以实现每秒42帧的处理速度,由程序性能度量以及实际的机器人测试结果来看,本文方法可满足机器人室内导航点云地图生成的实时性需求。
2.2 数据集测试
为了评估本文方法位姿估计的精确性,应用TUM-RGBD数据集[17]进行精度评估测试,度量估计得到的相机轨迹与相机轨迹真值之间绝对轨迹误差(ATE),并与典型的KinectFusion[9]以及RGBD-SLAM[12]的精度测试结果进行对比,以绝对轨迹误差(ATE)作为度量指标,如表2所示。由测试结果可以看出,本文方法估计得到的相机位姿精度与鲁棒性优于另外两种方法。

表2 绝对轨迹误差(ATE)对比 m
本文方法估计得到的相机轨迹与数据集相机轨迹真值之间的对比如图6所示。由对比结果可以看出,本文方法估计得到的相机轨迹可以很好地接近数据集的相机轨迹真值。
3 结束语
通过处理深度相机所拍摄的序列图像实时估计相机位姿,利用图优化算法,综合考虑深度相机所获取的彩色图像的投影误差与深度图像的反投影误差,对相机位姿与稀疏三维点云进行联合优化;利用优化后的相机位姿对关键帧所对应的图像点云进行拼接融合,从而得到表示三维空间场景结构的稠密点云地图。通过机器人实验以及标准数据集测试,验证本文方法的有效性、精确性与实时性。
[1] 高俊. 地图学寻迹[M]. 北京:测绘出版社, 2012.
[2] 康永伟. 车载激光点云数据配准与三维建模研究[D]. 北京:首都师范大学, 2009.
[3] 赵煦, 周克勤, 闫利,等. 基于激光点云的大型文物景观三维重建方法[J]. 武汉大学学报(信息科学版), 2008, 33(7): 684-687.
[4] 詹庆明, 张海涛, 喻亮. 古建筑激光点云-模型多层次一体化数据模型[J]. 地理信息世界, 2010(4):6-11.
[5] SNAVELY N, SEITZ S, SZELISKI R. Photo Tourism: Exploring Image Collections in 3D. ACM Transactions on Graphics[J]. ACM Transactions on Graphics, 2006.
[6] SNAVELY N, SEITZ S M, SZELISKI R. Modeling the world from internet photo collections[J]. International Journal of Computer Vision, Springer, 2008, 80(2): 189-210.
[7] BAILEY T, DURRANT-WHYTE H. Simultaneous localization and mapping(SLAM): Part I[J]. IEEE Robot. Autom. Mag., 2006.
[8] HARTLEY R I, ZISSERMAN A. Multiple View Geometry in Computer Vision[M]. 第2版. Cambridge University Press, ISBN: 0521540518, 2004.
[9] NEWCOMBE R A, IZADI S, HILLIGES O, et al. KinectFusion: Real-time dense surface mapping and tracking[C]//Mixed and augmented reality (ISMAR), 2011 10th IEEE international symposium on. IEEE, 2011: 127-136.
[10] WHELAN T, KAESS M, FALLON M, et al. Kintinuous: Spatially extended kinectfusion[C]. National Conference on Artificial Intelligence. 2012.
[12] ENDRES F, HESS J, STURM J, et al. 3-D mapping with an RGB-D camera[J]. IEEE Transactions on Robotics, IEEE, 2014, 30(1): 177-187.
[13] KERL C, STURM J, CREMERS D. Robust Odometry Estimation for RGB-D Cameras[C]//International Conference on Robotics and Automation. 2013.
[14] KERL C, STURM J, CREMERS D. Dense Visual SLAM for RGB-D Cameras[C]//Proc. of the Int. Conf. on Intelligent Robot Systems (IROS). 2013.
[15] KÜMMERLE R, GRISETTI G, STRASDAT H, et al. G2o: A general framework for graph optimization[J]. Proceedings - IEEE International Conference on Robotics and Automation, 2011: 3607-3613.
[16] MA Y, SOATTO S, KOSECKA J, et al. An invitation to 3-d vision: from images to geometric models[M]. Springer Science & Business Media, 2012, 26.
[17] STURM J, ENGELHARD N, ENDRES F, et al. A benchmark for the evaluation of RGB-D SLAM systems[C]//2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2012: 573-580.
猜你喜欢
微型电脑应用(2020年12期)2020-12-25
电子制作(2019年16期)2019-09-27
智能城市(2018年7期)2018-07-10
大连理工大学学报(2017年4期)2017-08-07
自动化学报(2017年5期)2017-05-14
电子世界(2016年18期)2016-10-24
重庆交通大学学报(自然科学版)(2016年1期)2016-05-25
西北工业大学学报(2015年3期)2015-12-14
东北电力大学学报(2015年1期)2015-11-13
电测与仪表(2014年8期)2014-04-04
