
基于冗余字典学习的图像修补算法
2018-03-19 02:45:40王鑫朱行成宁晨王慧斌
计算机工程与应用 2018年6期
王鑫,朱行成,宁晨,王慧斌
1.河海大学计算机与信息学院,南京211100
2.南京师范大学物理科学与技术学院,南京210000
基于冗余字典学习的图像修补算法
王鑫1,朱行成1,宁晨2,王慧斌1
1.河海大学计算机与信息学院,南京211100
2.南京师范大学物理科学与技术学院,南京210000
1 引言
数字图像采集、传输、压缩、存储或编辑修改过程中,有时会造成图像像素信息的丢失,影响图像的视觉效果。如何对缺失部分进行修补,改善图像的质量,直接影响到后续的应用。因此,设计有效的图像修补算法以提高受损图像的质量,具有非常重要的现实意义和应用价值[1]。
图像修补技术是利用已知的信息推测并恢复丢失的信息,经过多年的研究发展,已经涌现出多种算法。这些算法归纳起来可以分为两种类型:基于偏微分方程和变分算法理论的方法、基于样本纹理合成技术的方法。其中,第一类方法的修补思路是从图像中已知的区域扩展到未知区域,即图像中缺失的部分。例如,Takeda等人[2]提出Steering核回归(Kernel Regression,KR)模型,通过各向异性距离自适应调节权值,建立了非局部均值方法和核回归模型之间的联系,在图像复原问题中取得了良好的应用效果。Chan和Shen[3]提出了一个基于全变分模型(Total Variation,TV)的图像缺失信息修补方法,该算法在修补过程中会选择最近的直线距离来连接断裂的线性结构物体,因此无法满足视觉连通性原则,修补效果不是很好。为此,Chan和Shen[4]随后又提出了利用基于曲率扩散的非线性偏微分方程修补模型来解决这个问题。考虑到图像信号具有非局部自相似性,Peyré等人[5]在非局部图上扩展全变分模型,进一步有效解决了图像修补这一典型的逆问题。基于偏微分方程和变分算法理论的图像修补方法在处理较小的缺失区域时,可以很好地恢复结构层信息,比如边缘部分;但是在处理较大区域时效果不是很好,容易引入模糊和平滑效应。第二类基于样本纹理合成技术的图像修补方法,其思想是从待修补区域边缘开始分割图像小块,从缺失图像的已知部分寻找与待处理的图像小块最匹配的图像块,利用对应位置上的元素来进行图像修补。例如,Efros和Leung[6]提出通过从缺失图像的剩余区域中寻找最匹配的图像块来合成缺失区域的纹理层信息。但需要注意的是,自然图像除了具有纹理层之外,还具有结构层信息,仅修补图像的纹理层并不能取得很好的修补效果。为此,Criminisi等人[7]针对图像修补问题在纹理合成的同时考虑了结构信息的传播,利用合成纹理时的优先顺序来保持结构信息的修补,提升了修补的性能。Chen等人[8]分别针对图像缺失位置的结构信息和纹理信息进行图像修补,其首先基于草图模型重构缺失图像的结构信息,然后利用基于图像块的纹理合成方法去合成图像中缺失的区域。基于样本纹理合成技术的图像修补方法可以处理大块的缺失区域,更好地恢复待修补区域的纹理信息,但是该类修补算法具有贪婪性,在处理过程中可能会引入不相关的物体。
近年来,稀疏表示(Sparse Representation,SR)作为一种新兴的图像表示模型,能够利用很少量的稀疏捕获到图像的主要信息和内在几何结构,并且对噪声与误差更加鲁棒,在图像超分辨率重建、压缩感知成像、图像分割、图像复原等问题中取得了良好的效果[9-11]。针对图像修补问题,由于图像在退化过程中丢失了信息,图像修补逆问题通常具有病态特性。图像的先验模型在图像修补问题中起着重要作用。利用基于图像稀疏性的正则化模型可以对真实解空间进行正则化约束,从而将具有不适定性的图像修补病态问题转换为适定问题,获得符合人眼视觉特性的稳定解。为此,本文在稀疏表示理论研究的基础上,提出了基于不同冗余字典的图像修补算法。该方法首先设计采用离散余弦变换(Discrete Cosine Transform,DCT)[12]或K-奇异值分解(K-Singular Value Decomposition,K-SVD)算法[13]获得冗余DCT字典、KSVDG全局字典及KSVDA自适应字典等三种不同的字典;然后分别基于上述三种不同的冗余字典,稀疏表示待处理图像;最终图像中缺损的部分将通过冗余字典和稀疏系数有效地表示出来。实验结果表明,提出的算法能够得到良好的图像修补结果。
2 图像修补问题描述
图像修补是图像恢复研究中的一个重要方向,它的目的是根据图像中残留的信息,恢复图像中缺失的部分,以达到更好的视觉效果,这个过程可以形象地用图1表示。图中,E表示图像中残缺的部分,即待修补的部分,Ec为图像中已知的部分,修补问题即描述为如何通过Ec恢复出E。
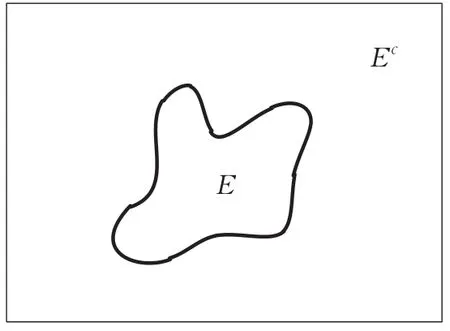
图1 图像修补问题描述
上述图像退化过程还可以表示为如下数学问题[14]:

其中,x表示原始的清晰图像,y表示有部分内容缺失的待修补图像,η是指图像退化过程中可能引入的噪声(一般认为是加性高斯噪声)。H是图像缺失问题中的退化算子,当H为只包含0和1两种元素的掩码时,其可以将图像中部分位置的像素值置0,造成图像内容缺失的效果。图像修补的目的就是从缺失的图像y中恢复出原始的清晰图像x。
3 提出的算法
3.1 算法整体框架
信号的稀疏表示理论发展至今,在图像处理领域众多问题,如图像压缩、图像去噪中得到了广泛的应用,并为图像复原问题的研究打开了新的方向。但是,目前如何将稀疏表示理论在图像修补问题中得以有效地应用仍然是需要进一步研究的内容。基于此,本文提出了基于不同冗余字典学习的图像修补算法,其采用离散余弦变换或K-SVD方法学习了三种不同类型的冗余字典,即:DCT字典(记为DCT)、全局字典(记为KSVDG)及自适应字典(记为KSVDA);然后分别基于这三种字典,对待修补图像进行稀疏表示;最终原始图像中缺损的部分就可以由这些冗余字典和计算得到的稀疏编码系数表示出来。图2给出了提出算法的整体结构图。
3.2 算法具体步骤
提出算法的具体步骤如下:
(1)给定原始待修补图像y∈ℝN,如图3所示(这里给出了两个退化图像例子)。首先对其进行可重叠分块处理,每一个图像块可以表示为其中表示从待处理图像中选取图像块的矩阵算子。
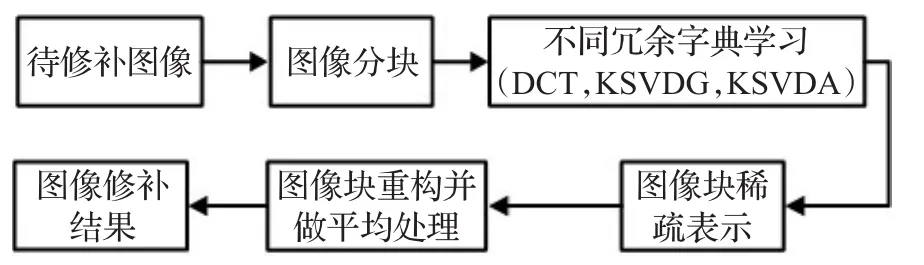
图2 提出算法的结构图

图3 原始待修补图像示例
(2)当采用稀疏表示理论进行图像修补时,假设冗余字典D已知,结合退化模型(1),则图像修补问题可以表示为:

(3)训练冗余字典D∈ℝB×K,其中K是字典中原子的个数,即字典的列数,K>B,保证冗余。为了得到适用于图像修补问题的冗余字典,分别采用离散余弦变换方法计算得到结构稳定的DCT字典、K-SVD方法训练得到KSVDG全局字典和KSVDA自适应字典。其中,全局训练字典是指从大量清晰的自然图像块中训练得到的,而自适应字典是从待处理的图像中获得图像块,作为训练样本集获得的冗余字典。
利用K-SVD的方法训练冗余字典的详细训练过程如下:首先,给定一组训练图像块S=[]s1,s2,…,sJ,其中J代表训练图像块的个数,字典学习和稀疏系数的联合优化问题可以表示为:

图4给出了不同冗余字典的示例图。其中,图4(a)是经过离散余弦变换得到DCT字典,图4(b)是从一组大量的清晰自然图像中训练得到的KSVDG全局字典,其中图中每一个小块表示一个原子。可以看出DCT字典和KSVDG全局字典在结构上有很大不同,KSVDG全局字典中的原子会包含有更多的图像结构信息。图4(c)是从被文字污染的图3(a)中利用K-SVD方法学习得到的KSVDA自适应字典,图4(d)是从被文字污染的图3(b)中利用K-SVD方法学习得到的KSVDA自适应字典,比较这两幅图像可以看出,两个KSVDA自适应字典结构上也存在不同,这说明自适应字典对待处理图像具有适应性,即待处理图像在其相应的自适应字典上会有更稀疏的表示,从而得到更好的处理结果。

图4 不同冗余字典示例
(4)训练得到冗余字典后,采用OMP算法计算每个图像小块yk在冗余字典D上的稀疏系数α̂k,则恢复后的每一个图像块x̂k可以表示为:

(5)依次重建所有的图像块,则恢复后的完整的图像x就可以表示为:

通过式(5),即可将恢复后的图像块放置在原来的位置上,而对于图像块间相互重叠的部分取平均处理,这样可以有效减少图像块在各重叠区域的误差,获得更好的修补结果。
本文提出的上述修补方法主要利用了自然图像的稀疏性,该特性指明图像信号可以由冗余字典中少量原子的线性组合准确表示出来,也就是说字典中的原子结构中包含有自然图像恢复的关键信息,所以利用冗余字典中少量原子的线性组合稀疏的表示待处理图像信号,则图像中缺失的部分就可以由冗余字典和更新得到的稀疏系数表示出来,实现图像修补。
4 实验和分析
在本实验中,选取的测试图片大小为256×256,对待修补图像进行重叠分块处理,每一小块的大小为8×8,获取图像块时的步长为1,则共处理的图像小块数为62 001。
字典D大小设置为64×256,保证冗余,根据字典的不同,本文基于稀疏表示模型的图像修补算法分为三种情况,分别是基于结构固定的DCT字典、训练得到的全局字典和自适应字典。全局训练字典由K-SVD算法训练得到,迭代了180次,在每次的迭代中,采用OMP算法求解稀疏系数,系数的稀疏度设置为6。训练了超过100 000幅8×8的图像小块,该图像块都是从清晰的自然图像中获得。而自适应字典则是从缺失的图像中训练得到,具有自适应性,采用K-SVD方法训练,迭代10次获得。下面将给出分别基于上述三种不同的冗余字典得到的图像修补结果。
4.1 评价标准
在给出实验结果和分析之前,首先选择两种典型的全参考图像质量评价方法,即峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)[18]和特征相似性方法(Feature Similarity,FSIM)[19],用于后续定量衡量修补后图像的质量。这里,所谓全参考图像质量评价方法,是指已知原始的清晰图像,通过把处理后的图像和原始的清晰图像作比较来评价图像质量,可见,这是一类切实有效的评价标准。
峰值信噪比的定义如下:
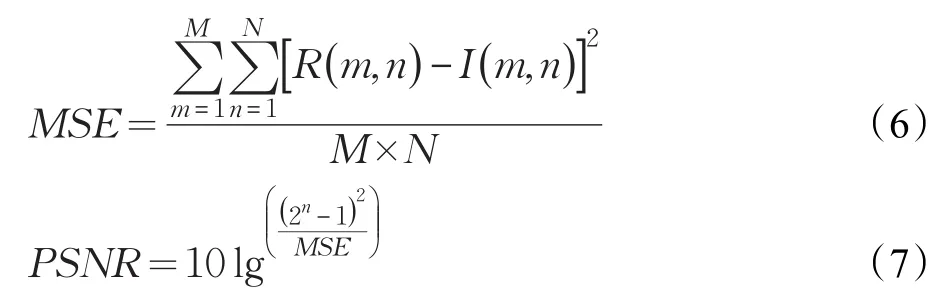
其中,MSE为图像灰度值的均方误差,M和N分别代表图像的长和宽,和分别代表参考图像(原始清晰图像)和失真图像在位置处的灰度值。n是图像的深度,本文中测试的图像深度均为8。峰值信噪比被用来评价信号失真率,通常来说,该值越大,则代表图像失真越小。
从峰值信噪比的计算公式可以看出,峰值信噪比只是计算了图像间灰度值的差异水平,并没有考虑图像块间的结构相似性。为此,下面又采用了特征相似性方法来评价图像恢复后的质量,该标准利用了梯度信息和相位一致性信息两个特征,相位一致性用于体现局部结构信息重要性,而图像梯度用于衡量图像对比度,该标准从多角度来评价复原后的图像,也更加客观和准确。要计算特征相似度,首先要求解各像素点的相位一致性和梯度值。设和分别是原始图像和复原后图像中某像素点的相位一致性的值和梯度值。首先求得下面两部分:
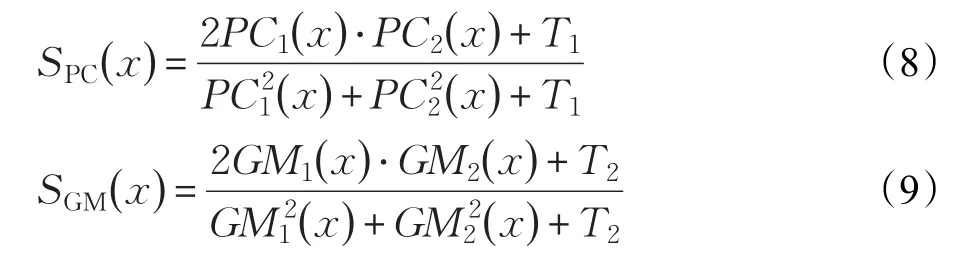
其中,T1和T2为常量。则原始图像和复原后图像的相似性记为:
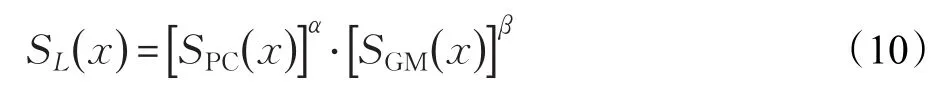
其中,α和β为常数,通常设置为1。要说明的是,图像上任意像素点的显著性是不同的,如果原始图像和复原后图像上相同位置的像素点的相位一致性的值都比较大,则说明该位置更容易引起人们的兴趣。所以这里采用来调节相似性SL()x在该评价标准中的重要性。最终,图像的特征相似度定义为:

其中,Ω代表整幅图像范围。
上述给出的是求解灰度图像的特征相似度值,但是在实际情况下,经常处理的是彩色图像,所以下面给出彩色图像的特征相似度性值(FSIM)的求解方法。在彩色图像的特征相似性求解公式里,增加了彩色图像的色度信息,首先将原始图像从RGB空间转换到YIQ空间,其中I和Q代表图像的色度信息,Y则代表图像的亮度信息,记和分别是原始图像和复原后图像的色度信息,则原图和复原后图像色度间的相似度可表示为:
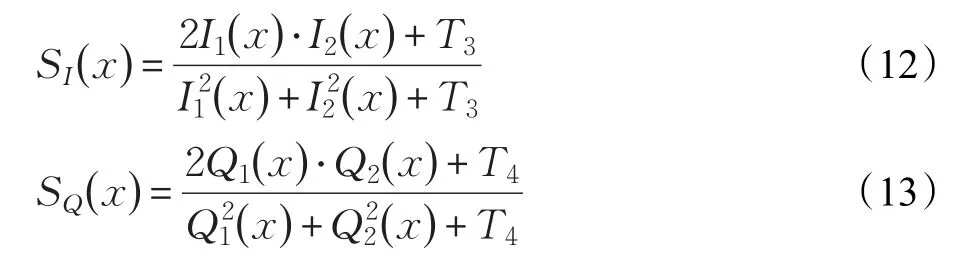
其中,T3和T4是调节因子,为了计算简单,这里设置两者的值相等。可以通过和得到图像的色度信息SC()
x,如下所示:

这样,彩色图像FSIM的求解可以定义为:
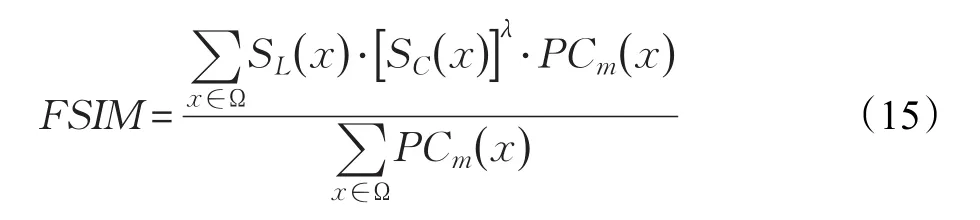
其中,λ为公式中的调节因子,可以调节色度信息在彩色空间所占的比值。由于彩色图像的FSIM加入了图像的色度信息,所以该评价标准更为可靠,效果也更好。本节实验中采用的就是求解彩色图像的FSIM值。一般来说,该值越接近1,代表图像的主观质量越好。
4.2 结果和分析
为了证明提出的基于不同冗余字典的图像修补算法的修补效果,这里将提出算法和现有的两种代表性算法进行了比较。第一种比较算法是传统的基于全变分模型的修补方法(记为TV算法)[3],第二种比较算法是经典的基于核回归(Kernel Regression,KR)的修补方法(记为KR算法)[2]。图5~图9分别给出了三种不同的算法在5幅被文字污染的景物图像的去字效果。在每一幅图中,(a)表示原始清晰图像,(b)表示被文字污染的退化图像,(c)是TV算法修补后的结果,(d)是KR算法修补后的结果,(e)~(g)是提出的基于不同冗余字典(即DCT、KSVDG、KSVDA)的稀疏表示算法修补后的结果,这些算法分别记为SR-DCT算法、SR-KSVDG算法和SR-KSVDA算法。

图5 图像修补效果对比示例一

图6 图像修补效果对比示例二
对比最终定性实验结果可以看出,TV算法、KR算法,及本文设计的基于不同冗余字典的图像修补算法都可以有效消除加在原始图像上的英文或中文字符,对图像整体进行修复。但是,本文的算法视觉效果更好。例如,比较图6中(c)、(d)和(e)~(g)可以看出,(c)图和(d)图中湖边的台阶处可以看到英文字符并没有去除干净,而经过本文提出的算法处理后得到的图(e)~(g)看起来更接近原始图像。

图7 图像修补效果对比示例三

图8 图像修补效果对比示例四

图9 图像修补效果对比示例五
下面用峰值信噪比PSNR和特征相似度FSIM两个标准来定量评价修补后图像的质量,结果如表1所示。每一组实验中最高的峰值信噪比和特征相似度值均用粗体表示。可以看出,表中后三列的值都高于第二列和第三列的值,说明本章提出的基于不同冗余字典的修补算法比全变分修补算法或核回归修补算法的效果要更好,修补后的图像具有更高的峰值信噪比和特征相似度值,表明修补后的图像失真更小,局部结构信息也更丰富,有更好的视觉效果。后三列是基于不同冗余字典的稀疏表示算法的修补结果,比较后三列的值可以看到,基于自适应字典的稀疏表示算法(SR-KSVDA)在多数实验图像上取得了较好的结果,这是因为KSVDA自适应字典是从待处理的图像中训练得到的,可以获得更好的稀疏性,所以相对于DCT和KSVDG字典,会有更好的处理结果。
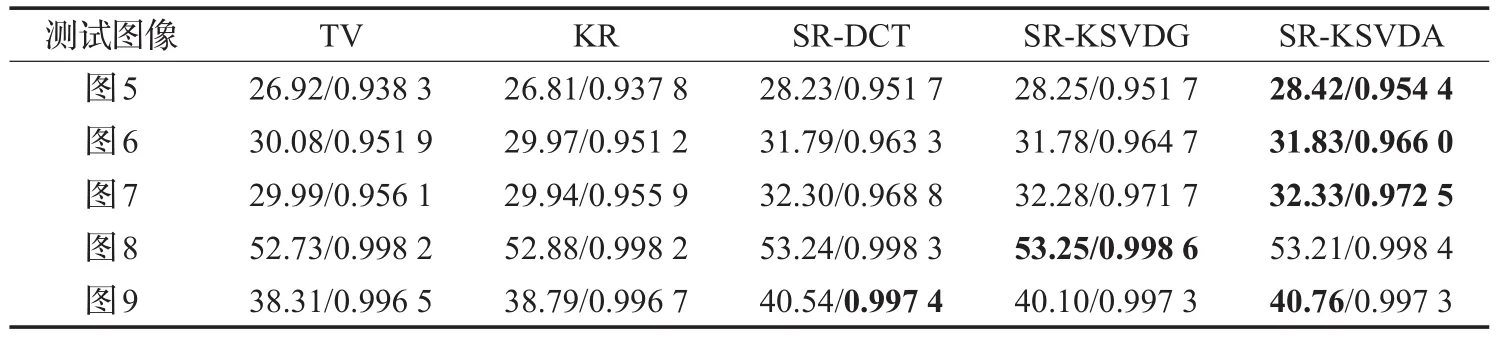
表1 不同算法修补后的图像PSNR/FSIM结果
5 结束语
本文提出了基于不同冗余字典的图像修补方法。该方法首先利用离散余弦变换获得冗余DCT字典,或利用K-SVD方法训练获得KSVDG全局字典及KSVDA自适应字典;然后基于上述三种不同的冗余字典分别稀疏表示待处理图像;最终图像中缺损的部分就可以由冗余字典和更新得到的稀疏系数表示出来。实验将提出的基于不同冗余字典的图像修补方法与经典的基于全变分模型的图像修补算法、基于核回归的图像修补算法进行了比较,结果证明了提出方法的有效性。
[1] 宋锦萍,郑昌燕.高阶模型的快速图像修补[J].计算机工程与应用,2015,51(11):154-157.
[2] Takeda H,Farsiu S,Milanfar P.Kernel regression for image processing and reconstruction[J].IEEE Transactions on Image Processing,2007,16(2):349-366.
[3] Chan T,Shen J.Local inpainting models and TV inpainting[J].SIAM Journal on Applied Mathematics,2010,62(3):1019-1043.
[4] Chan T,Shen J.Nontexture inpainting by curvature-driven diffusions[J].Journal of Visual Communication&Image Representation,2001,12(4):436-449.
[5] Peyré G,Bougleux S,Cohen L.Non-local regularization of inverse problems[C]//Proceedings of European Conference on Computer Vision,Marseille,France,2008:57-68.
[6] Efros A A,Leung T K.Texture synthesis by non-parametric sampling[C]//Proceedings of IEEE International Conference on Computer Vision,Washington,DC,USA,1999:1033-1038.
[7] Criminisi A,Pérez P,Toyama K.Object removal by exemplar-based inpainting[C]//Proceedings of IEEE International Conference on Computer Vision and Pattern Recognition,Madison,Wisconsin,USA,2003:721-728.
[8] Chen Y,Luan Q,Li H,et al.Sketch-guided texture-based image inpainting[C]//Proceedings of IEEE International Conference on Image Processing,Atlanta,GA,USA,2006:1997-2000.
[9] Wang X,Shen S,Ning C,et al.Multi-class remote sensing object recognition based on discriminative sparse representation[J].Applied Optics,2016,55(6):1381-1394.
[10] 费博雯,邵良杉,刘万军.基于子区域匹配的稀疏表示跟踪算法[J].计算机工程与应用,2017,53(9):201-207.
[11] Wang X,Shen S,Ning C,et al.A sparse representationbased method for infrared dim target detection under sea-sky background[J].Infrared Physics&Technology,2015,71:347-355.
[12] Liu Y,Yang Z,Yang L.Online signature verification based on DCT and sparse representation[J].IEEE Transactions on Cybernetics,2015,45(11):2498-2511.
[13] Jiang Z,Zhe L,Davis L.Label consistent K-SVD:Learning a discriminative dictionary for recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(11):2651-2664.
[14] Zhang J,Zhao D,Gao W.Group-based sparse representation for image restoration[J].IEEE Transactions on Image Processing,2014,23(8):3336-3351.
[15] Mairal J,Bach F,Ponce J.Task-driven dictionary learning[J].IEEETransactionsonPatternAnalysisand Machine Intelligence,2012,34(4):791-804.
[16] Isaac Y,Barthélemy Q,Atif J,et al.Multi-dimensional sparse structured signal approximation using split bregmaniterations[C]//ProceedingsofIEEEInternational Conference on Acoustics,Speech and Signal Processing,Vancouver,BC,Canada,2013:3826-3830.
[17] Kowalski M.Thresholding RULES and iterative shrinkage/thresholding algorithm:A convergence study[C]//Proceedings of IEEE International Conference on Image Processing,Paris,France,2015:4151-4155.
[18] 蒋刚毅,黄大江,王旭,等.图像质量评价方法研究进展[J].电子与信息学报,2010,32(1):219-226.
[19] Zhang L,Zhang L,Mou X,et al.FSIM:A feature similarity index for image quality assessment[J].IEEE Transactions on Image Processing,2011,20(8):2378-2386.
WANG Xin,ZHU Hangcheng,NING Chen,et al.Image inpainting based on redundant dictionary learning.Computer Engineering andApplications,2018,54(6):198-204.
WANG Xin1,ZHU Hangcheng1,NING Chen2,WANG Huibin1
1.College of Computer and Information,Hohai University,Nanjing 211100,China
2.School of Physics and Technology,Nanjing Normal University,Nanjing 210000,China
Based on the sparse representation theory,this paper proposes an image inpainting framework by using different redundant dictionaries.First of all,it utilizes the Discrete Cosine Transform(DCT)or K-Singular Value Decomposition(K-SVD)to learn three different dictionaries,i.e.,the redundant DCT dictionary,K-SVD global(KSVDG)dictionary and K-SVD Adaptive(KSVDA)dictionary.Then,the image to be inpainted is sparsely represented by using these three different redundant dictionaries,respectively.At last,based on the redundant dictionaries and sparse coefficients,the missing part of the image can be well expressed.Experimental results show that the proposed algorithm achieves good visual effects.Further,compared with several existing classical image inpainting methods,it produces superior results in terms of some main image quality evaluation indexes such as peak signal-to-noise ratio and feature similarity.
image inpainting;redundant dictionary;sparse representation
在稀疏表示理论研究的基础上,提出了基于不同冗余字典的图像修补算法。首先设计采用离散余弦变换或K-SVD算法获得冗余DCT字典、KSVDG全局字典及KSVDA自适应字典等三种不同的字典;然后分别基于上述三种不同的冗余字典,稀疏表示待处理图像;最终图像中缺损的部分将通过冗余字典和稀疏系数有效地表示出来。实验结果表明,提出的算法修补后的图像视觉效果好,并在峰值信噪比、特征相似度等主要图像质量评价指标上优于现有几种经典的图像修补方法。
图像修补;冗余字典;稀疏表示
2017-07-10
2017-10-23
1002-8331(2018)06-0198-07
A
TP394.1
10.3778/j.issn.1002-8331.1707-0161
国家自然科学基金(No.61603124,No.61374019);中央高校基本科研业务费专项资金(No.2015B19014);江苏省“333高层次人才培养工程”;江苏省“六大人才高峰”高层次人才项目(No.XYDXX-007)。
王鑫(1981—),女,博士,副教授,研究领域为图像处理,模式识别,计算机视觉,E-mail:wang_xin@hhu.edu.cn;朱行成(1990—),男,硕士研究生,研究领域为图像处理和分析;宁晨(1978—),男,博士研究生,讲师,研究领域为压缩感知理论和应用;王慧斌(1967—),男,博士,教授,研究领域为图像处理、视觉计算。
猜你喜欢
家教世界(2023年28期)2023-11-14 10:13:50
家教世界(2023年25期)2023-10-09 02:11:56
黑龙江大学自然科学学报(2022年4期)2022-11-17 08:08:06
农村财务会计(2020年9期)2020-09-21 10:25:56
作文小学中年级(2020年6期)2020-07-24 08:33:10
会计之友(2018年4期)2018-02-02 22:05:21
金融经济(2017年14期)2017-12-23 14:52:09
创新作文(小学版)(2016年19期)2016-08-22 05:54:08
读者(2016年14期)2016-06-29 17:25:50
财会学习(2014年5期)2014-08-30 09:14:10
