
面向个性化站点的用户检索意图建模方法
2018-03-19 02:44张瑞芳郭克华
计算机工程与应用 2018年6期
张瑞芳,郭克华,2
1.中南大学信息科学与工程学院,长沙410083
2.南京理工大学高维信息智能感知与系统教育部重点实验室,南京210094
面向个性化站点的用户检索意图建模方法
张瑞芳1,郭克华1,2
1.中南大学信息科学与工程学院,长沙410083
2.南京理工大学高维信息智能感知与系统教育部重点实验室,南京210094
CNKI网络出版:2017-03-16,http://kns.cnki.net/kcms/detail/11.2127.TP.20170316.1528.032.html
1 引言
近年来,个性化Web站点,如高校网站、政府网站、中小型企业网站等,在互联网上发挥着越来越重要的作用。与大型Web网站相比,个性化站点的关注点一般以内容为主,在网站建设与维护中常忽略搜索算法的优化。用户在浏览这些站点时,可能耗费更多时间和精力来得到符合自己检索意图的结果。因此,如何为个性化站点提供一种检索优化方法,使其能为用户提供更加优质的检索服务,成为个性化站点检索研究的一个重要问题。
目前,商用搜索引擎公司如谷歌等始终致力于搜索引擎算法的优化[1],来预测用户搜索意图,保证用户搜索结果的质量,取得了一定的成果。文献[2]将用户查询意图分为导航类、信息类和事务类三种。文献[3]通过分析用户搜索上下文猜测其检索意图。文献[4-5]将查询结果分类后让用户粗略选择,并以此为依据对结果再提取。文献[6]提出,Web日志中可能隐含用户检索意图,因此,可以通过分析Web日志得到用户历史模型。文献[7]通过分析浏览器的公共查询日志和用户个人查询活动来理解用户意图。
但是,由于商业原因,以上这些方法未广泛应用于个性化站点的优化。针对此问题,研究者提出了很多对个性化站点的优化方法。文献[8]提出一种针对小型机构的网站服务器模型,采用了Top-k关键词有机搜索、相似关键词搜索和图像搜索的优化技术。文献[9]通过挖掘用户访问日志,建立反馈相似度模型,利用该模型训练用户访问日志,指导搜索结果排序。文献[10]针对新闻网站,从用户的浏览日志中提取上下文相关特征,然后训练一个Logistic回归模型来预测用户的查询内容。但是,现有这些优化方法中有的是基于站点的建设初期对网站设计方案的研究,而不是对已投入运行的个性化站点的优化;有的则需要训练数据模型,存在冷启动及日志增量不易处理等问题。目前,对于个性化站点搜索策略优化问题的研究仍处于起步阶段。个性化站点的文本检索通常仅以用户提交的关键词为查询依据,较少考虑用户检索意图。
关键词提取[11]和文本排序是个性化站点搜索优化的两大重要问题。目前,有很多方法可以有效提取
关键词:(1)基于统计的方法,该方法通过统计词语的频率判定其权重,典型代表为交叉信息熵算法(TFIDF)[12]。文献[13]基于基尼指数原理提出一种改进的TFIDF特征选择算法,文献[14]提出一种基于信息增益与信息熵的TFIDF改进算法。(2)基于语义的方法[15-16],该方法用词语的语义特征提取关键词。文献[17]提出基于词汇链的关键词提取方法。基于语义的方法从语义的角度考虑词语权重,但它难以很好地解决同义词冗余等问题。(3)基于机器学习的方法[18],如贝叶斯分类器[19]和基于SVM的方法[20]。该方法属于机器学习范畴,需要大量训练数据。(4)基于文档网络的方法,它将一篇文档映射成词语网络。代表性算法有TextRank[21]和复杂网络算法[22]。但是,TextRank算法忽略了词语本身的重要性,复杂网络算法仅考虑单一文档。
文本排序旨在使查询结果顺序更加合理且符合用户意图。引入文本表示模型,并计算文本间相似度,可以对文本进行排序。常见的文本表示模型有:(1)布尔检索模型[23]:以布尔逻辑为基础,对词语进行严格匹配。但由于逻辑表达式过于严格,容易导致漏检;且没有计算词语权重,从而返回了大量无序文本。(2)概率模型[24]:该模型考虑了词语与文本间的内在联系,但忽略了词语在文档中的频率。(3)向量空间模型[25]应用简单的数学方法将文本内容量化成空间向量。
考虑个性化站点网页结构简单的特点,本文通过充分分析用户与服务器交互过程中的访问行为,从中挖掘出用户意图模型。该模型采用结合交叉信息熵和词语特征信息的关键词提取方法以及结合余弦相似度和加权海明距离的文本排序方法。它首先从用户浏览的网页中提取出关键词集并建立意图模型,然后将新关键词集作为查询条件重新检索,最后对检索结果重新排序,从而为用户提供更加符合用户检索意图的结果。该方法不要求用户进行额外的反馈操作,在用户正常检索时可以实现用户意图的即时建模过程。
2 基本框架
个性化站点的检索模式通常为将用户输入的查询条件与数据库中的数据进行匹配,得到查询结果列表。而一般情况下,用户只输入简短的词语作为查询条件,这样就导致在该模式下的检索结果滥而不准,用户则需要耗费更多的时间和精力于通过查看链接的详细信息来查找目标结果。
因此,利用本文提出的检索模式,以现有个性化站点为应用对象,为其提供关键词提取和文本排序两个功能,能够使个性化站点为用户推荐更加符合检索意图的结果。具体流程如图1所示。

图1 基于用户意图检索系统流程图
个性化站点网页访问路径命名规则普遍单一化,同一站点中同类型内容网页采用相同的访问路径构造方法。因此,可据此对用户访问的网页进行过滤,当用户浏览信息类网页(非导航类网页)时,系统可利用过滤器获取该网页访问路径并通过爬虫得到用户想要访问的网页信息。基于关键词提取和文本排序的用户意图检索方法以该交互文本为前提,对该文本中的信息进行分析,此文本在一定程度上包含了用户希望获得的信息。
将从用户与个性化站点服务器交互中提取的文本信息记为T,对T进行分析。用结合交叉信息熵和词语特征信息算法对T进行关键词提取,得到关键词集K={(ki,w(ki))|1≤i≤M},其中,M表示集合K中元素个数,ki表示K中第i个关键词,w(ki)表示ki的权重值。构造用户意图模型U=[w1,w2,…,wM],其中,U是由K中M个关键词的权重值降序排列形成的矩阵向量。
由于K中包含了用户检索意图,因此,以K作为检索条件在搜索引擎中进行二次检索,从而得到检索结果集Ts={ti|1≤i≤H},其中,ti表示Ts中第i个文本信息,H表示Ts中文本个数。为Ts中的文本建立向量空间模型Ti=[w1,w2,…,wM]。通过计算Ti与U之间的向量空间距离Sim(U,Ti)对Ts排序,从而将更加符合用户意图的结果显示在靠前部分,提升用户体验。
3 实现方案
3.1 关键词提取算法
关键词提取部分采用结合交叉信息熵和词语特征信息的方法计算关键词权重,已有前人对该方法进行过类似研究,但未曾应用于此场景。
用户所浏览网页可以反映其兴趣方向,因此,利用该网页中的文本信息可以建立用户意图模型。关键词提取过程如图2所示。
文献[26]中的NLPIR分词系统在分词方面能够取得较好效果,但它在提取关键词时采用的是交叉信息熵算法,较少考虑词语特征信息,因此,本文同时考虑词语特征信息和交叉信息熵来决定关键词权重。
对于词的特征信息,可以考虑以下方面:(1)词频权重;(2)词性因子权重;(3)词位置权重;(4)词跨度权重。具体定义如下:
(1)词频权重(F)

其中,freq(ki)表示词语ki在T中的频率。
(2)词性因子权重(P)

其中,p(ki)表示词语ki的词性,noun表示名词,verb表示动词,others表示其他词性。
(3)词位置权重(L)

表示若词语ki位于标题位置,则将L(ki)赋值为0.5。
(4)词跨度权重(S)
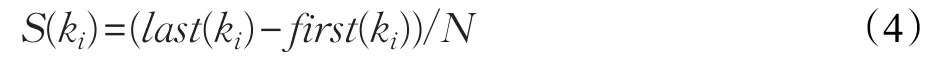
其中,last(ki)、first(ki)分别表示词语ki最后一次和第一次出现在T中的位置,N表示T分词后词语的总数。
已知利用网络爬虫技术抓取文本信息T,需要从T中提取关键词集K,并建立用户意图模型U。具体过程如下:
步骤1利用NLPIR分词系统从文本T中提取初始关键词集K1={(k1i,w1(k1i))|1≤i≤R},其中,w1的值等于词语k1i的交叉信息熵值TFIDF(ki)。并保留由NLPIR系统分析计算得到的关键词的p(ki)、freq(ki)和TFIDF(ki)。
步骤2计算K1={(k1i,w1(k1i))|1≤i≤R}中各关键词的综合权重值w(ki),得到K2={(ki,w(ki))|1≤i≤R}。k2i的综合权重值计算公式如下:
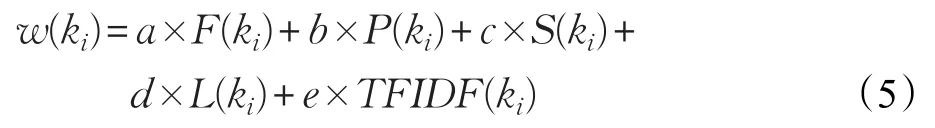
其中,a、b、c、d、e分别为各特征权重的比例系数,用来调节不同特征权重对于综合权重的重要程度,此公式中,设置各比例系数为:a=1.5,b=1.1,c=0.8,d=1.0,e=0.8。TFIDF(ki)已由步骤1计算得到。
步骤3父串子串过滤。为消除同一关键词重复提取和父串子串共现问题,采用如下算法:
算法1父串子串过滤
输入:由步骤2计算所得K2={(k2i,w(k2i))|1≤i≤R}。
输出:过滤后的关键词集K={(ki,w(ki))|1≤i≤M}。
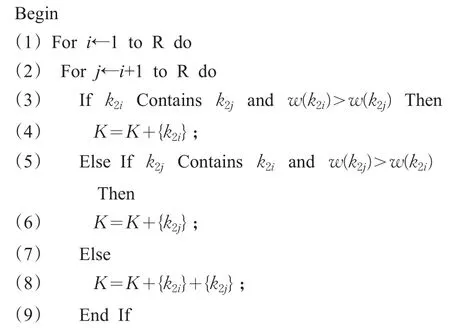
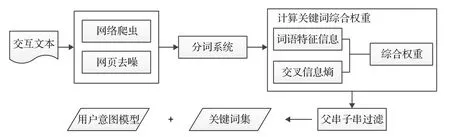
图2 关键词提取过程
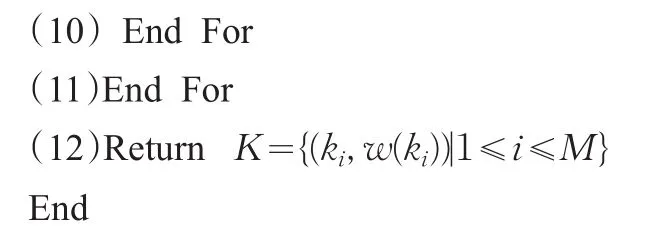
步骤4按降序对集合K中关键词的w值排序,得到向量U=[w1,w2,…,wM],即为用户意图模型。
3.2 结果集排序算法
本模型中,把利用关键词提取算法提取出的K中的Q(1≤Q≤M)个元素作为重新检索的条件在该搜索引擎中重新检索,得到Ts={ti|1≤i≤H},采用上述方法计算每个文本的特征向量Ti=[wt1,wt2,…,wtM]。然后采用余弦相似性与加权海明距离相结合的方法计算Ts中每个文本与U的相似度大小Sim(U,Ti)。Ti与U的余弦相似度计算公式如下:
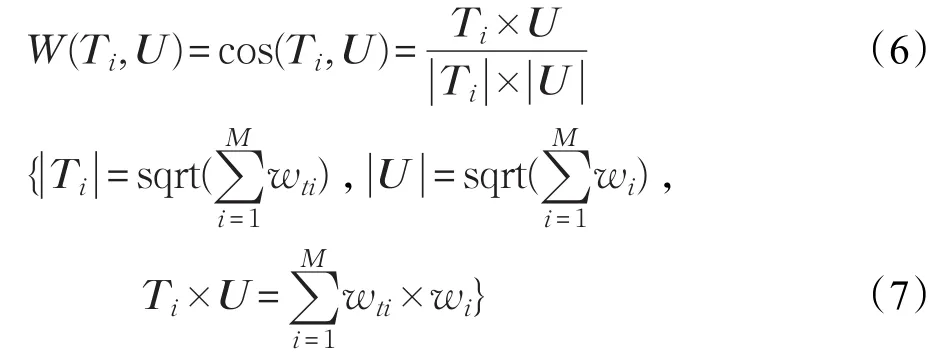
U中的特征值按降序排列,而余弦相似性方法未考虑不同关键词的重要性差异,为此,本文采用加权海明距离算法来弥补该不足点。加权海明距离指按照关键词作用不同,在海明距离基础上添加合适的权值,然后对不同关键词的权值进行求和计算。不同位置关键词的距离权值定义为:
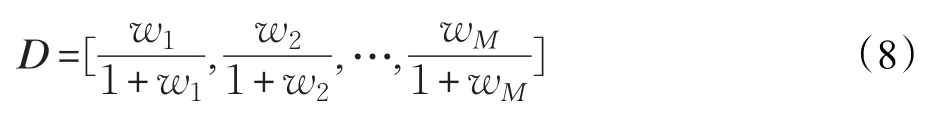
本文中计算两个文本空间向量的加权海明距离算法如下:
算法2加权海明距离
输入:用户意图模型U=[w1,w2,…,wM],文本Ti的特征向量Ti=[wt1,wt2,…,wtM]。
输出:用户意图模型与文本Ti的加权海明距离dis(U,Ti)。
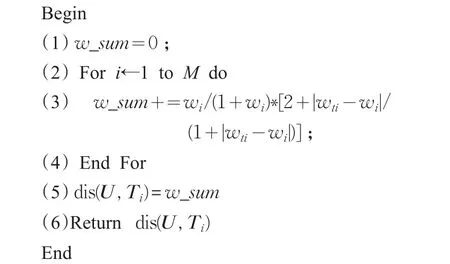
利用以下公式计算U与Ti的最终相似度值Sim(U,Ti):
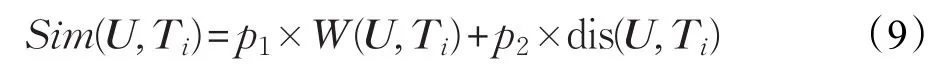
其中,p1、p2为比例系数,并取p1=p2=1.0。
将集合Ts中的所有文本按Sim(U,Ti)降序排列并返回给用户,从而实现基于用户意图检索的建模过程。
3.3 系统模块化
由于不同个性化站点采用不同的开发技术,且拥有各自的系统框架,如果将本文中基于用户检索意图建模方法分别在不同个性化站点实现,可能会导致大量的代码修改或增加。因此,本文提出将该方法进行模块化处理,网站开发者只需进行少量配置和代码增加就可以实现个性化站点搜索性能的优化。模块结构图如图3所示。

图3 模块包图
利用该模块对个性化站点进行优化的步骤如下:
步骤1将mainpackage包和nlpir包放入工程中。
步骤2在工程中添加过滤器并在web.xml中配置。
步骤3新建一个web页面用于显示推荐结果。
该模块的时间成本包括三个因素:(1)对每个文本进行关键词提取,并构造特征向量Ti,时间复杂度为O(H)。(2)计算Ti(1≤i≤H)与U之间的相似度Sim(U,Ti),时间复杂度为O(H)。(3)根据Sim(U,Ti)对Ts排序,采用快速排序算法,时间复杂度为O(HlgH)~O(H2)。
4 性能测试与评价
4.1 实验设置
为验证本文中基于用户意图检索模型的有效性,实验选取若干个性化站点测试效果,并以典型站点(http://news.csu.edu.cn/)为例说明。实验抓取了典型站点中32 236条数据作为测试数据集,该站点主要提供校内新闻,抓取的测试数据中,包含学校要闻、综合新闻、领导论坛等20余个专题,每个专题爬取约1 000个对应的网页,网页内容主要包括新闻的标题、内容及发布时间等信息。
系统开发和运行环境如下:(1)PC(Personal Computer)版本为微软系列(CPU为Intel®CoreTMi5-3470,3.20 GHz,内存为8.00 GB,操作系统为Windows 10)。(2)服务器配置:使用Oracle 11g数据库和Tomcat 7.0 Web服务器。(3)实验过程使用Java语言实现,开发环境为MyEclipse 10.7。
4.2 实验结果与分析
实验1结合交叉信息熵和词语特征信息计算综合权重时交叉信息熵比例系数e的设定对检索结果的影响。
在对用户所浏览网页的文本内容进行分析时,依据词语的综合权重值大小从中提取关键词,而公式(5)中系数e的设定直接影响提取结果(系数a、b、c、d均已确定)。本实验分别统计公式(5)中系数e设置为0.5~1.5时检索结果中Top40提取精度,得到图4所示的统计结果。比较对象如下:
方法1采用本文所描述的算法,结合交叉信息熵和词语特征信息计算关键词权重。
方法2只根据交叉信息熵算法提取关键词。
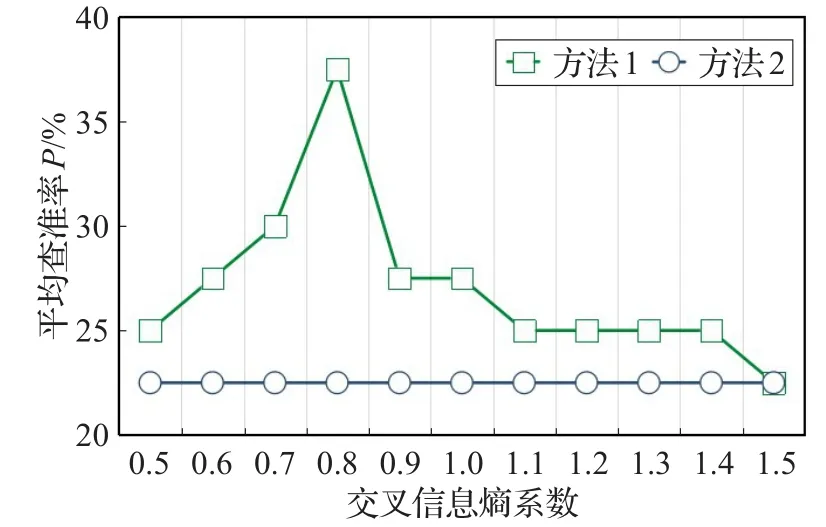
图4 交叉信息熵系数e不同时的查准率
由图4可知,当系数e设置较小时,平均查准率较低,当e值达到0.8时,平均查准率达到最优状态,而随着e值增大,平均查准率逐渐降低并趋于一定值。这是由于当系数e值较小时,交叉信息熵对综合权重值影响小,词语的特征信息作为综合权重值计算的主导,当系数e较大时,则与上述情况相反。而当两者对综合权重值的贡献达到最佳状态时,能够得到最高平均查准率。同时,从图4可以得出,本文结合词语特征信息和交叉信息熵计算关键词综合权重的方法优于文献[26]中的交叉信息熵算法,并有效地提高了原网站的查准率。
实验2算法1(父串子串过滤算法)对检索结果的影响。
为了测试本文中过滤算法的有效性,以不同的查询词作为检索条件,统计检索结果Top40的提取精度。此时,将系数e设置为0.8。比较使用和不使用父串子串过滤规则时的检索查准率。比较对象如下:
方法1使用本文提出的父串子串过滤规则。
方法2不使用父串子串过滤规则。
从图5可知,在多数检索情况下,使用父串子串过滤规则时的查准率更高。这是因为当检索关键词数量一定时,若存在的父串、子串的词语组合过多,会严重影响检索结果的查全率,进而影响查准率。因此,采用一种有效的父串子串过滤规则来适当减少该类组合占用的关键词资源,对提高检索结果的查准率有一定影响。
实验3采用算法2(加权海明距离算法)对检索结果的影响。
对查询结果排序的目的是将符合用户检索意图的结果排在前面。本实验通过采用不同向量空间距离计算方法对文本排序结果的对比,验证本文所采用的文本排序算法的有效性。比较对象如下:
方法1利用本文提出的结合余弦相似度与加权海明距离算法对文本排序。
方法2利用余弦相似度方法对文本排序。
方法3利用欧式距离算法对文本排序。
方法4利用海明距离算法对文本排序。
方法5利用加权海明距离对文本排序。
方法6利用Jaccard距离算法对文本排序。
由图6可知,在检索结果的Top40中,通过方法1和方法5计算得到的符合用户意图的结果最多,这是因为这两种方法比传统计算空间向量相似度方法(方法2、方法3和方法6)考虑了更多可能影响计算结果的因素,从而使相似度计算更加精确。通过方法1计算得到的检索结果排序中,符合用户意图的结果排名比方法5更加靠前,原因是仅仅通过计算两个文本向量空间夹角来衡量它们的相似度还不够,在该方法基础上,进一步考虑两个文本相同关键词的个数及其权重,从而获得更好的效果。

图5 选择性使用父串子串过滤规则时的查准率
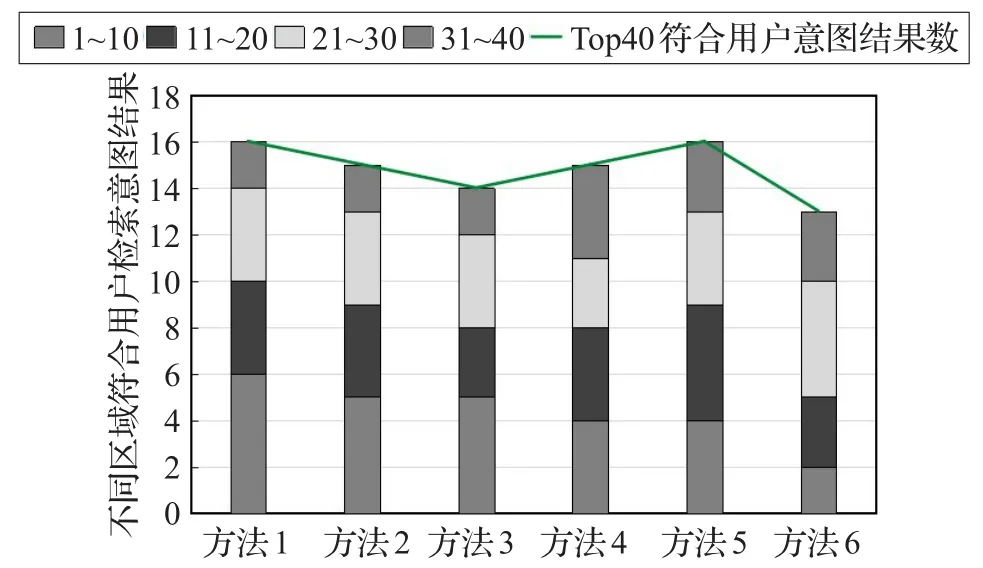
图6 不同文本排序方法对检索结果的影响
实验4从K中选取查询关键词个数Q的确定对检索结果的影响。
本实验对从K中所选取查询关键词个数Q进行设置,统计检索关键词个数不同时系统的平均查准率。为了测试关键词个数对检索结果的影响,以1为步长,将N分别从4取至14,统计Top40中满足用户检索意图结果的个数。
由图7可知,查询关键词个数Q对检索精度存在影响。关键词个数较少时,检索的平均查准率较低,这是因为关键词个数少,不足以全面涵盖用户的检索意图,导致漏查。关键词个数增多,对于某一搜索引擎而言,将会达到一个最优值,使检索的平均查准率最高。而若关键词个数继续增加,则发现平均查准率将会下降且最后趋于稳定值,原因是过多的关键词中除了能够代表用户意图的信息外,还会包含噪声干扰,导致查准率下降,但是即使存在这些噪声干扰,系统仍能够通过文本相似度计算将更加符合用户意图的结果排在前面。
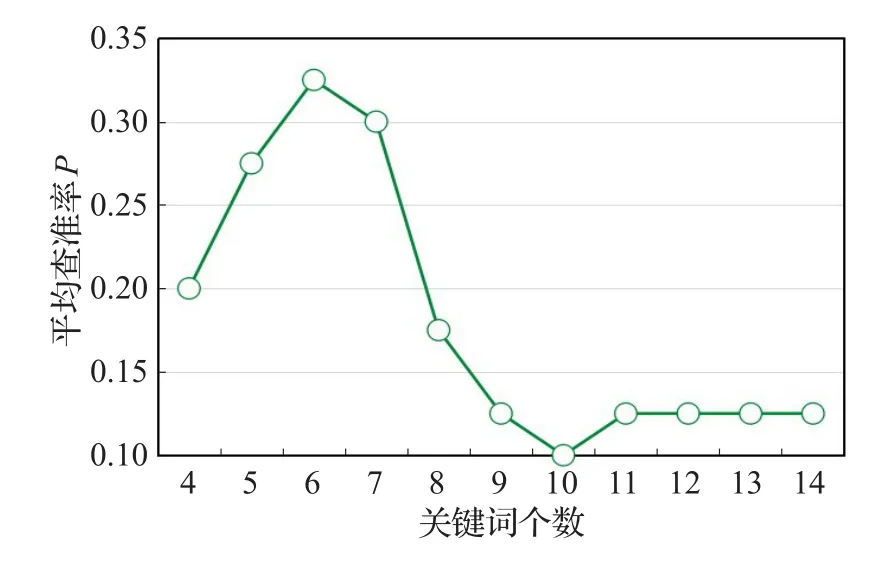
图7 关键词个数对检索结果的影响
实验5不同数据集下参数的设置与相关策略的不同对检索结果的影响。
在上述4个实验中,参数的设置与相关策略的采用与否都是针对前述数据信息集进行决策的,将该数据信息集记为数据集1。为研究文中参数的设置对不同搜索引擎检索精度的影响,本文另采集某一个性化站点中13 211条数据作为数据集2进行实验1至实验4。分别统计交叉信息熵系数e、查询关键词个数Q变化时以及采用不同向量空间距离计算方法和父串子串过滤算法时,检索结果中Top40的平均检索精度,得到如表1和表2所示的结果。
由表1和表2可知,对于不同的数据集,最佳检索精度的参数设置并不完全相同。由表1可以看到,交叉信息熵系数e设置为0.8左右、采用父串子串过滤策略对于数据集1和数据集2均可获得较高平均查准率,而针对参数Q设置问题,要想得到最优查准率,数据集1中应设置为6,而数据集2中应设置为7,这是因为不同搜索引擎的检索策略不同,对用户输入的关键词处理方式也不同。由表2可以得出,利用方法1进行文本排序对于数据集1和数据集2均可得到最佳结果。
5 结束语
本文主要针对中小型搜索引擎检索效果差的情况,提出了一种基于关键词提取和文本排序的用户意图检索模型。该模型可实现一种轻量级、模块化、适用于结构简单的网站(如高校、新闻类网站)的结果推荐模块。实验表明,该方法能够有效提高搜索引擎的检索查准率,具有一定可行性。
但本文中的实验是在较单一检索条件下进行的,在检索策略上与真实网站存在一定差异,所得实验结果与在真实情况下运行的结果可能存在差距;其次,如果两个不同的用户在该方法实现的场景下进行完全相同的操作,他们将得到相同的推荐结果,未考虑不同用户的个体差异而可能导致不同检索意图的推测;此外,本文考虑到该模型的应用场景,在提取关键词和文本排序方面采用的是使用较为广泛且复杂度较小的算法,为进一步提高结果的准确率,有必要在后续研究中进行改进。
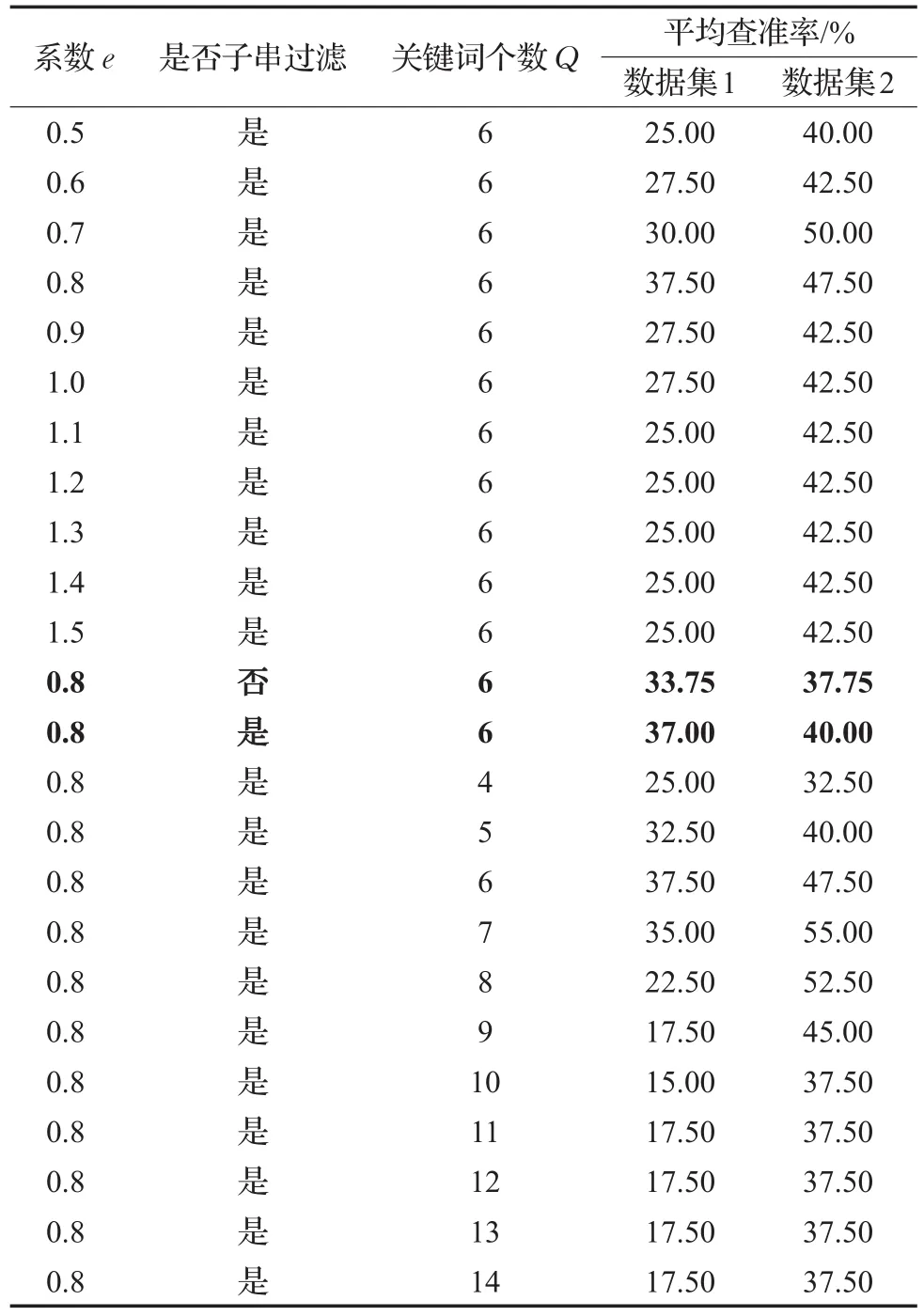
表1 不同参数设置对不同数据集检索查准率的影响

表2 不同向量空间距离计算方法对不同数据集检索精度的影响
[1] Gudivada V N,Rao D,Paris J.Understanding searchengineoptimization[J].Computer,2015,48(10):43-52.
[2] BroderA.A taxonomy of Web search[J].ACM SIGIR Forum,2002,36(2):3-10.
[3]Yu Jie,Liu Fangfang.Mining user context based on interactive computing for personalized Web search[C]//2010 2nd International Conference on Computer Engineering and Technology,2010:209-214.
[4] Tang Xiaoou,Liu Ke,Cui Jingyu,et al.IntentSearch:Capturing user intention for one-click Internet image search[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(7):1342-1353.
[5] Guo Kehua,Zhang Ruifang,Zhou Zhurong,et al.Combined Retrieval:A convenient and precise approach for Internet image retrieval[J].Information Sciences,2016,358(9):151-163.
[6] Ravi B,Rajender N.Automatic recommendation of Web pages for online users using Web usage mining[C]//2012 International Conference on Computing Sciences,2012:371-374.
[7] Shang Yue,Ding Wanying,Liu Mengwen,et al.Scalable user Intent mining using a multimodal restricted boltzmann machine[C]//2015 International Conference on Computing,Networking and Communications,2015:618-624.
[8] Chung P,Chung S,Hui C.A web server design using search engine optimization techniques for web intelligence for small organizations[C]//IEEE Long Island Systems,Applications and Technology Conference,2012:1-6.
[9] 潘明远,方金云,章立生.基于用户反馈的POI搜索引擎优化研究[J].计算机工程与应用,2010,46(32):112-115.
[10] 张骁逸,苏宇,晏小辉.基于用户浏览日志的上下文相关新闻推荐[J].计算机工程与应用,2016,52(22):99-104.
[11] Wang Zhijuan,Feng Yinghui.F2N-Rank:Domain keywords extraction algorithm[J].Metallurgical and Mining Industry,2015,7(9):225-230.
[12] Wang Jingyu,Zhao Weiyan.Research on parallelizing the TFIDF algorithm based on Hadoop[J].Computer Engineering and Science,2014,36(6):1018-1022.
[13] Yang Chengcheng,He Xingshi.A text feature selection algorithm based on improved TFIDF[C]//2008 Chinese Conference on Pattern Recognition(CCPR’08),2008:1-2.
[14] Li Xueming,Li Hairui,Xue Liang,et al.TFIDF algorithm based on information gain and information entropy[J].Computer Engineering,2012,38(8):37-40.
[15] 姜芳,李国和,岳翔,等.基于语义的文档关键词提取方法[J].计算机应用研究,2015,32(1):142-145.
[16] Guo Kehua,Pan Wei,Lu Mingming,et al.An effective and economical architecture for semantic-based heterogeneous multimedia big data retrieval[J].Journal of Systems and Software,2015,102(4):207-216.
[17] 刘端阳,王良芳.基于语义词典和词汇链的关键词提取算法[J].浙江工业大学学报,2013,41(5):545-551.
[18] Sarkar K,Nasipuri M,Ghose S.Machine learning based keyphrase extraction:Comparing decision trees,Naïve Bayes,and artificial neural networks[J].Journal of Information Processing Systems,2012,8(4):693-712.
[19] Rabia I,Sharifullah K,Ali M Q,et al.Refining Kea++automatic keyphrase assignment[J].Journal of Information Science,2014,40(4):446-459.
[20] Xu Ruifeng,Gui Lin,Xu Jun,et al.Cross lingual opinionholderextractionbasedonmulti-kernelSVMs and transfer learning[J].World Wide Web,2015,18(2):299-316.
[21] Li Peng,Wang Bin,Shi Zhiwei,et al.Tag-TextRank:A webpage keyword extraction method based on tags[J].Journal of Computer Research and Development,2012,49(11):2344-2351.
[22] Nan Jiangxia,Xiao Bo,Lin Zhiqing,et al.Keywords extraction from Chinese document based on complex network theory[C]//2014 7th International Symposium on Computational Intelligence and Design,2015,2:383-386.
[23] Arash H L,Fereshteh M,Vahid G.A boolean model in information retrieval for search engines[C]//2009 International Conference on Information Management and Engineering(ICIME’09),2009:385-389.
[24] Takafumi N.Semantic context-dependent weighting for vector space model[C]//2014 IEEE International Conference on Semantic Computing(ICSC),2014:262-266.
[25] 胡堰,彭启民,胡晓惠,等.一种基于隐语义概率模型的个性化Web服务推荐方法[J].计算机研究与发展,2014,51(8):1781-1793.
[26] 张华平.NLPIR/ICTCLAS2014分词系统开发文档[EB/OL].(2014).http://ICTCLAS.nlpir.org.
ZHANG Ruifang,GUO Kehua.Novel retrieval intention modeling method for personalized website.Computer Engineering andApplications,2018,54(6):37-43.
ZHANG Ruifang1,GUO Kehua1,2
1.School of Information Science&Engineering,Central South University,Changsha 410083,China
2.Key Laboratory of Intelligent Perception and Systems for High-Dimensional Information of Ministry of Education,Nanjing University of Science and Technology,Nanjing 210094,China
Personalized website rarely considers user’s search intention in retrieval process.To recommend more satisfactory results without any user feedback in personalized website retrieval,this paper proposes a keyword extraction method combining the cross entropy with word feature information,and a text ranking method assembling the cosine similarity with weighted Hamming distance.Firstly,web page text content is obtained from the requested personalized website by filtering the web page address.Secondly,based on the obtained text content,keywords which can reflect user’s retrieval intention are extracted.Thirdly,user’s intention vector model is constructed and a re-retrieval process is performed by calling the main search engine.Finally,the similarity between the user’s intention model and the re-retrieved records is computed,and the results sorted by the similarity values are returned to user.Experimental results show that the proposed method can reflect the user’s query intention and provide a notably convenient user experience.
personalized website;user intention;query recommendation;information retrieval
针对个性化站点较少考虑用户检索意图的问题,提出结合交叉信息熵和词语特征信息的关键词提取方法以及结合余弦相似度和加权海明距离的文本排序方法,旨在不需要用户任何反馈的条件下,为用户推荐更满意的检索结果。通过过滤用户请求个性化站点时的访问地址,获取用户浏览的网页文本内容,从中提取能够表示用户检索意图的关键词集进行重新检索后对检索结果排序,最后将排序后的结果作为推荐模块返回给用户。实验表明,利用该方法获得的查询推荐结果能够更加符合用户检索意图,提供更好的用户体验。
个性化站点;用户意图;查询推荐;信息检索
2016-11-07
2017-01-03
1002-8331(2018)06-0037-07
A
TP391
10.3778/j.issn.1002-8331.1611-0108
国家自然科学基金(No.61672535);高维信息智能感知与系统教育部重点实验室创新基金(No.JYB201502);湖南省普通高校青年教师培养计划;中南大学中央高校基本科研业务费专项(No.2016zzts351);中南大学创新驱动计划(No.2015CXS010);中南大学升华育英计划专项。
张瑞芳(1992—),女,硕士生,主要研究方向为多媒体检索;郭克华(1980—),通讯作者,男,副教授,主要研究方向为多媒体检索、普适计算。
猜你喜欢
法律方法(2022年2期)2022-10-20
福建基础教育研究(2022年4期)2022-05-16
名家名作(2021年4期)2021-05-12
法律方法(2021年3期)2021-03-16
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
现代电子技术(2018年16期)2018-08-21
现代电子技术(2017年23期)2017-12-20
计算机应用(2016年10期)2017-05-12
延河(下半月)(2014年3期)2014-02-28
