
小型英语学习者语料库与错误分析
2018-03-14 08:36:32韩国全汶基
山东理工大学学报(社会科学版) 2018年1期
于 建,[韩国]全汶基
(1.山东理工大学 外国语学院,山东 淄博 255000;2.韩国建国大学 英语系,韩国 首尔05029)
一、引言
学习者在语言学习过程中经常会出现语言使用方面的错误。20世纪五六十年代,对比分析理论(contrastive analysis)在第二语言习得研究中占据主导地位。在对比分析理论体系中,错误通常被认为是学习者语言能力欠缺的标志,因而是应该严格避免的。错误的根源在于语言间的差异性,所以语言学家及语言教师的任务是比较学习者的母语与他们学习的目标语言的差异,从而对学习者可能出错的领域做出预测,以此来帮助他们尽可能地避免这些错误[1]1-3。20世纪60年代后期,由于对比分析理论固有的理论及实证缺陷,比如无法预测所有可能的错误,有些预测的错误从未实际发生等,它很快沦为一种过时的理论,转而被错误分析理论(error analysis)所取代。在错误分析理论体系中,语言错误被认为是学习者必须经过的发展阶段,与儿童习得母语的过程类似[2]161-170。错误不是语言能力欠缺的标志,它们的存在恰恰表明学习者正在努力探索所学习的语言,不断归纳与总结,并试图形成与之相关的规则和认识。从这个角度来看,学习者的语言错误不应该被视为问题;相反地,经过详尽的分析,它们可以为认识学习者语言的发展过程提供有价值的信息[3]102。
然而,传统的错误分析理论也有其局限性。 Dagneaux,Denness & Granger将它们总结如下。第一,错误分析经常基于差异化的学习者语料。第二,错误类别间的界限不明晰。第三,错误分析无法解释有些语言现象,比如学习者为何避免使用某种语言结构。第四,错误分析仅局限于分析学习者之力所不能及,而无视学习者之力所能及。第五,错误分析把第二语言学习看作是一个静态静止的过程[4]164。
第一个局限性表明了错误分析中语料收集的重要性,参见Ellis(1994)[5]68-70。Corder也指出,只有学习过程中产生的系统性错误才具有收集分析的价值[2]170。第二个局限性与错误分类的标准有关。这些标准通常缺乏客观性,定义较为模糊,会直接影响错误分析的结果及有效性。其他三个局限性则表明,在错误分析中使用正确、使用避免以及使用不足等现象也应该纳入到分析的范畴中来。同时,学习者的学习过程也不应被视为是静态的,而应视为一个动态发展、不断修正、逐步提高的过程。
20世纪90年代,随着计算机技术的发展以及语料库分析方法的广泛使用,学习者语料库开始在语言习得研究中兴盛起来。作为语料库的一种重要类型,学习者语料库中收集的是语言学习者在实际使用语言过程中的口语或书面语的语料。基于语料库语言学的理论与分析方法,学习者语料库可以为语言习得研究提供更好的手段,同时也能够满足更广的研究需求[6]22。在此背景下一种新的错误分析方法应运而生,即计算机辅助错误分析(computer-aided error analysis)[4]163。
与传统错误分析所使用的语料相比,学习者语料库中的语料具有几个显著的优点。其一,学习者语料库的体量可以比较庞大,规模庞大的语料能够更全面地反映学习者语言的使用特征,同时也有利于形成更具规律性的分析结果。其二,学习者语料库在建库之初就能够较好地控制各种相关变量,比如学习时长、语言水平、任务类型、母语背景等。其三,学习者语料库中的语料既包含各种错误使用形式,同时也包含各种正确使用形式,因此学习者的语言成就和语言不足都可以得到客观反映。从语言不足的角度来讲,通过相关语料,研究者可以试图找到错误的源头;而且借助于语料库语言学的定量分析方法,错误频率及分布规律也可以得到量化分析。其四,学习者语料库可以收集相同学习者在不同学习阶段的语料,从而可以进行纵向研究(longitudinal study),比如学习者在哪个阶段更易出现哪些错误或哪些使用不足。最后,大量相关软件可以实现语料收集、标记及数据分析的自动化,从而减轻研究者的负担。借助于这些工具,研究者可以对语料进行更全面的分析,例如利用类符形符比例(type-token ratio)来分析词汇丰富度(lexical richness),利用词汇分布率(word range)来分析词汇复杂度(lexical complexity)等[7]123-138。
基于上述优点,学习者语料库非常适合对学习者语言进行基于使用频率的各项研究。例如,International Corpus of Learner English(ICLE)收集了不同母语背景的英语学习者语料,研究者已开展了基于这些语料的多维度研究,如补语从句、时态、高频动词、习惯用语等。 依托这个语料库,Liu发现一般现在时、一般过去时、以及过去完成时是中国英语学习者经常出现的时态错误[8]16。这些错误可能与汉语缺乏时态系统有关。Milton & Tsang比较了中国英语学习者与英语母语使用者的语料。他们发现前者倾向于过度使用某些逻辑连词,比如,moreover 在学习者语料中出现的频率是其在布朗语料库(Brown Corpus) 中的10倍;therefore 出现的频率是6.9倍。他们认为教材设计及写作教学导致了这些使用过度[9]227-240。
学习者语料中的错误能够标记出来并加以定性或定量分析的话,分析结果对课堂教学及学生学习会具有一定的借鉴意义。教师可以根据分析结果对大纲设计和课堂教学做出相应的调整,也可以将学习者语料库中提取的索引行(concordance lines)作为教学材料呈现给学生,并鼓励学生利用语料库和检索工具主动进行相应检索,从而促进学习。这种数据驱动的学习和教学(data-driven learning & teaching)方法要比传统的以教材为中心的方法效率更高,尤其适用于口语和写作课堂[10]134-144。Schmidt提出的注意假说(Noticing Hypothesis)认为,学习者在学习过程中需要对输入信息(input)保持一定程度的注意。如果注意的程度较高,输入信息就更容易转化成内化(intake)[11]1-48。在语音学习过程中,研究者已经发现注意力导向确实能够促进语音习得[12]54-59。包含错误标记的索引行如果作为教学材料,就能把错误更直观系统地呈现给学习者,从而提高他们对错误的注意,提高学习效果。
以英语的冠词系统为例。学习者的母语中如果缺乏冠词系统,那么他们在学习过程中可能会产生较多与冠词有关的错误。Master做了冠词学习相关的实证研究。在教师系统地讲述了英语冠词之后,相比较于对照组,他的实验组在后续测试中冠词使用的准确率得到大幅度提升。Master认为系统地呈现英语冠词一方面减轻了学习过程中的疑惑,另一方面,英语冠词系统的形式特征及语法功能的共同呈现也有助于学习者的掌握[13]242-247。
基于前人的研究,我们提出了如下两个假设。
其一,中国英语学习者可能会出现较高频率的时态错误,尤其是一般现在时、一般过去时、以及诸如现在完成时的复合时态。
其二,由于汉语中缺乏冠词系统,中国英语学习者可能出现较多冠词相关的错误。
二、数据
(1)语料库数据
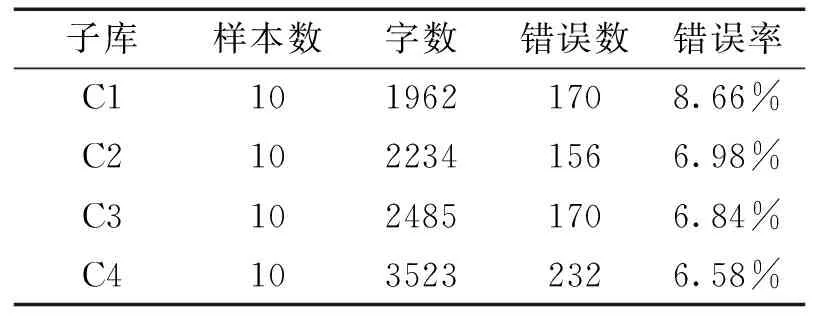
论文涉及的语料来自于《中国学生英语口笔语语料库》[14]11-29。语料收集是按大学年级顺序,每个年级随机抽取10篇英语作文,总共40篇 (平均长度=255.1, 标准差=73.9),然后按年级分成四个子库 (C1-C4,每个子库10篇作文)。 表1列举了这四个子库的相关信息。
表1 语料库字数及错误信息
子库样本数字数错误数错误率C1C2C3C41010101019622234248535231701561702328.66%6.98%6.84%6.58%
(二)错误标记
四个子库中的语料随后进行手工错误标记,标记参考使用的是Cambridge Learner Corpus(CLC)错误标记集,具体参见 Nicholls (2003)[15]572-576。下面是错误标记的示例,表2 则列举了几类主要的错误及标记代码。
<#CODE>wrong form|corrected form<#CODE>
“CODE” 指错误的标记代码,“wrong form”指原来的错误形式,“corrected form”指修正后的正确形式,两者之间用“|”加以分割便于区分。
表2 常见错误及标记形式
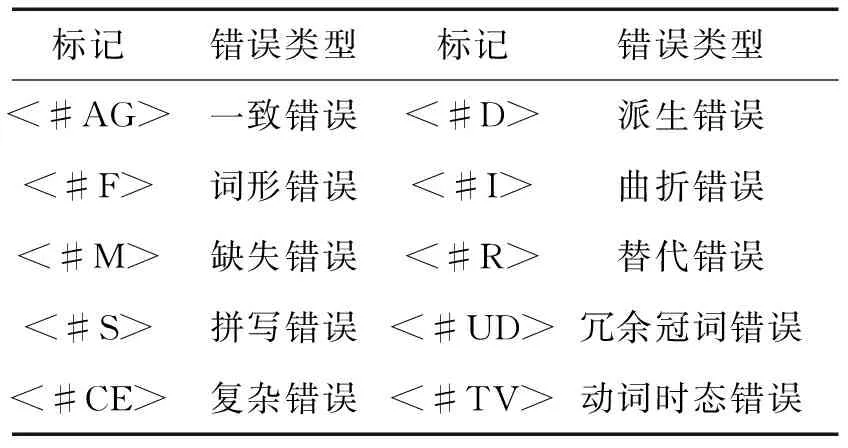
标记错误类型标记错误类型<#AG>一致错误<#D>派生错误<#F>词形错误<#I>曲折错误<#M>缺失错误<#R>替代错误<#S>拼写错误<#UD>冗余冠词错误<#CE>复杂错误<#TV>动词时态错误
论文着重关注三类错误。第一类是冗余冠词错误,是学习者在无需使用冠词的时候使用了而产生的错误。在语言习得研究中,这类错误通常被认为是过度概括化(overgeneralization)的结果。论文涉及的冗余冠词错误几乎全部与定冠词 the 相关。 例1中包含了一个典型的冗余冠词错误。
例1.Some people think the <#UD>the|<#UD> university education is to prepare students for employment. (C1_01.txt)
第二类错误是动词时态错误,主要是学习者错误使用了标记时态的动词曲折变化形式而产生的。第三类错误是复杂错误。有时一个短语或句子中可能包含两个或更多的错误,而当修正这些错误时,会极大地改变原有形式的结构或意义,这种错误就被标记为复杂错误。例2包含了两个复杂错误。
例2.They may be more helpful and warmhearted, instead of becoming a silfish person a silfish person|selfish persons, who will consider his benifit <#CE>consider his benifit|consider their own benefit as the most important thing. (G1_05.txt)
学习者语料中的错误加以标记后,利用语料库检索程序,包含某种特定错误标记的形式就可以从语料库中检索出来,方便做进一步分析处理。
三、数据分析
(一)错误标记的数据分析
错误标记搜索及统计是通过语料库检索软件AntConc来完成的[16]。首先,利用AntConc载入全部40篇错误标记过的样本,利用错误标记代码检索即可获得特定错误,软件会自动统计频次。检索结果如表1所示,四个子库中共有728处错误。从字数来讲,从C1到C4样本字数呈逐渐增加的趋势,表明随着学习时长的增加,学生英文作文长度也随之增加。从错误表面数量来看,二年级大学生所犯错误最少,为156个。一年级跟三年级的错误数相同,为170个。大学四年级学生错误最多,为232个。然而,当统计错误率时(错误率 = 错误总数/语料库字数*100%),一年级大学生错误率最高,为8.66%,二年级为6.98%, 三年级为6.84%,而四年级为6.58%。错误率总体上呈现随年级增加逐渐下降的趋势。这种错误率总体下降的趋势与样本长度总体上升的趋势正好相反,表明随着学习时长的增加,以及语言能力的逐渐提高,错误频率也随之减少。四个子库中每个样本的错误总数以及冗余冠词错误信息可见如下两图。
为了进一步验证错误与年级差异以及文本长度的关系,利用SPSS 24.0统计软件中的线性回归、方差分析等模块对所获取的数据做了进一步的统计分析。首先是线性回归分析, 用来验证数据间的关联性。线性回归分析表明, 当利用样本长度(样本数=40)来预测错误频率时,一个具有显著意义的相关性确实存在,F(1,38)= 5.665,p=0.022;R2=0.130。这表明在语料库中,样本长度跟错误率具有关联性,即无论语言能力如何,当写作长度增加时,学习者同时也会犯更多的错误。为了确定样本长度与冗余冠词错误间的关联性,第二个线性回归分析利用样本长度(样本数=40)来预测冗余冠词错误频率, 分析结果并未表明两者之间有显著的相关性:F(1,38) =0.210,p= 0.650;R2=0.005。这表明随着文本长度的增加,冗余冠词错误并未相应增加。第三个线性回归分析利用样本中的总体错误数(样本数=40)来预测冗余冠词错误数。分析结果表明样本中的错误总数与冗余冠词错误数具有显著的相关性:F(1,38)=11.521,p=0.002;R2=0.233。这表明当错误总数增加时,冗余冠词错误数也会相应增加,考虑到冗余冠词错误在总体错误中所占比例最大(21.56%),这种相关性的存在也确实有其基础。其次是方差分析,两个方差分析分别用来验证总体错误数量和冗余冠词错误是否有子库效应(子库数=4)。第一个单因素方差分析结果表明四个子库中的总错误数并无显著差异,F(3,36)=1.820,p=0.161。 第二个单因素方差分析表明四个子库中的冗余冠词错误也无显著差异,F(3,36)=1.820,p=0.162。这两个方差分析的结果表明四个子库之间无论是就总体错误数还是冗余冠词错误数而言并无显著差异。这证明学生学习能力的提高并没有显著降低错误频率。
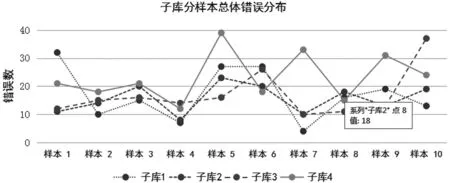
图1 子库中分样本总体错误分布状态
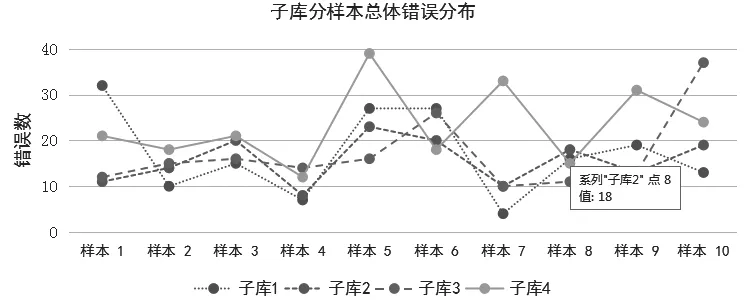
图2 子库中分样本冗余冠词错误分布状态
由于所选样本写作有限时与不限时的区别,两个独立样本T检验用来确定时限区别是否对总体错误数及冗余冠词错误数有影响。两个T检验的结果表明限时样本中的总错误数与不限时样本中的总错误数并无显著差异,t(36) =0.416,p=0.678。同时,限时样本中的冗余冠词错误数与不限时样本中的冗余冠词错误数亦无显著差异,t(36) =-1.088,p=0.285。这表明时限要求对总体错误数以及冗余冠词错误数并无显著影响。当时限性这个可能的影响因素被剔除后,语料库中的错误更有可能是由于语言能力发展的因素或学习者学习的因素而导致的,比如过度概括化等学习策略的影响。
(二)时态错误与复杂错误分析
在所有的错误类型中,时态错误共出现17次,占错误总数的2.33%。复杂错误共出现63次,占错误总数的8.65%。与其他研究,如Liu(2012)[8]11-23相比,论文所涉及样本的时态错误出现频率较低。论文提出的第一个假设并没有得到验证。造成这个结果的可能性有两个:一是本语料库中收集的样本多用一般时态,比如一般现在时与一般过去时。这可能与测试中国学生英语写作能力的方式有关。在英语测试中,作文部分一般的体裁都是论说文,而这类体裁对时态多样化的要求不高,所以时态的使用会较为单一。时态单一的另一个益处是可以避免时态多样化带来的错误率增大的问题,作为预防措施,学生在写作时也可能有意识地减少多种时态的使用。二是样本的差异性,论文所涉及样本的写作者对英语简单时态的掌握可能要好于Liu(2012)[8]11-23研究中的写作者。
除了时态错误以外,另外一种应该引起注意的是复杂错误。例3中就包含了这样的复杂错误。
例3.Now of socity call for a good deal have a lot of knowledge of talent <#CE>Now of socity call for a good deal have a lot of knowledge of talent|Now our society calls for a lot of talented people<#CE>. (C1_01.txt)
这个只有十几个单词的句子,包含了五处错误。首先,英语中并不存在“now of”这个表达方式,因此最有可能的错误是拼写错误,比如把“our”误拼成“of”。其次,单词“society”被误拼成了“socity”,这更加增加了前面“of”是误拼的可能性。再次,“a good deal”后面缺失被修饰成分,这是一个缺失错误。随后, “have a lot of knowledge of talent”前面缺失一个做从句主语的关系代词 who。最后“a lot of knowledge of talent”并不是一个符合英语语法的结构。这句话可以修改为“Now our society calls for a lot of talented people.”之所以这样修改,是因为剑桥学习者语料库在进行错误标记时遵从这样一个原则:尽量减少不必要的错误。基于这个原则,在修正句子时,上面列举的第四个错误就不做修改,同时句子的顺序做了调整,句子成分也做了简化处理,从而使得修正后的句子更简洁通顺。在错误分析中我们应该关注这样的复杂错误,它们包含了丰富的信息,表明学习者尚未完全掌握英语句子相关的基本知识,比如词性、句子成分、语序等;同时复杂错误也表明学习者缺乏对英语句子成分间及句子间逻辑关系的认识。
(三)逻辑问题
除了样本中标记的语法词汇错误之外,逻辑关联方面的问题,比如语篇衔接与连贯的问题,也值得引起关注。除少数连词缺失错误以外,语料库中并没有系统标记这类问题,因为这类问题一般跨度较大,容易造成标记困难或者无法标记。汉语是一种意合语言(paratactic language),它主要依赖于句子间隐性的、语义的关系作为衔接连贯的手段。而英语则是一种形合语言(hypotactic language),它更多地依赖显性的手段,比如连词和副词,以及句子间的从属关系来作为句子衔接连贯的手段。例4中包含了多个逻辑问题,为了阅读的方便,例子中的错误标记已经移除,错误处加了下划线用来标示。
例4.The young people are not having a correct concept of the world. They may easily make criminal, this will be a terrible things. Nobody will hope it happens. At this time the parents should have a wise thought. It is silly to indulge the children. This is not to love them but to induce them to do bad things. They should ask the children to demand themselves everyday. (C4_07.txt)
除词汇语法错误以外,这段话里还有非常严重的逻辑问题。首先,“没有正确的世界观的人”并不一定“可能很容易地”就变成 “罪犯”,尽管写作者用了一个表达确定意义并不强烈的“可能”(may)来试图弱化这种因果关系,但这仍是一个极其夸大的说法。其次,这段话里面的句子之间缺乏连词,作者只是把一些简单句机械地堆砌在一起,使得最后的行文既不通顺,又表意不清,阅读起来非常困难。再次,写作过程中的母语影响非常明显,比如“demand themselves”就是汉语中“要求自己”直译的结果,而英语中并没有这样的表达方式。这种行文逻辑等方面的问题也提醒我们,在对学习者的语言使用进行分析时,既要有微观的分析,比如具体的词汇语法错误分析,也要有宏观的分析,比如衔接连贯、逻辑推理、甚至体裁特征等方面的分析,只有这样才能获得对学习者语言较为全面的认识,同时也能给课堂教学提供更丰富的借鉴。
四、讨论
论文的结果表明小型语料库在分析学习者语言特征方面具有重要的价值。虽然作为先行研究,论文所使用的语料库样本数较少,但是却为后续的基于大规模学习者语料库的研究提供了极有价值的参考。
首先,论文中提出的第一个假设并没有得到实证支持。在所有的40篇样本中,只有17例时态错误,这一结果与前人研究的结果非常不同。由于语言间的差异性,如果母语中缺乏时态系统,学习者在学习时态语言时可能会遇到较多与时态有关的困难。造成本语料库样本中时态错误较少的原因已在前文表述过。从学习者的角度来讲,语料库中样本的写作者都是大学生,他们在进入大学之前已经至少有六七年的英语学习经历,对于简单时态的掌握已经相对熟练,所以在简单时态方面的表现会相对较好。这种语言能力影响语言使用的现象也提醒我们,如果想要获得更多时态相关的错误,最好收集英语能力相对较低的学习者语料。
其次,论文中提到的第二个假说得到了实证数据的支持。样本中出现了频率较高的冗余冠词错误,共117例,外加11例冠词缺失错误,使得冠词相关的错误占全部错误总数的17.6%。这种高频错误可能与冠词本身的结构无关,而更可能与学习者的学习策略有关,比如是过度规范化的结果。Dulay & Burt指出,冠词系统是第二个被中国英语学习者习得的语法系统,而这个系统本身的三个成员尽管在形式上并不复杂,但是在使用上却极为繁琐[17]51。因为英语定冠词的使用频率非常高,所以学习者会误认为英语定冠词是广泛适用的,而其母语中又没有冠词系统作为使用参考,因而会造成过度规范化的错误。
五、结论
论文论证了利用错误标记的小型语料库来研究学习者语言的可行性。当学习者语料收集科学,错误标记标准统一的情况下,即使是小型学习者语料库也能提供丰富的信息,能够较为系统地反映学习者语言使用的规律和特征。这对大型学习者语料库研究及语言教学都具有一定的借鉴意义。
[1]Lado R. Linguistics across cultures: applied linguistics for language teachers[M].Ann Arbor: University of Michigan Press, 1957.
[2]Corder S P. The significance of learners’ errors [J]. International Review of Applied Linguistics, 1967,(5).
[3]Gass S M, Selinker L. Second language acquisition: An introductory course (3rd ed.) [M].New York: Routledge/Taylor Francis, 2008.
[4]Dagneaux E, Denness S, Granger S. Computer-aided error analysis [J]. System,1998,(26).
[5]Ellis R. The study of second language acquisition [M]. Oxford: Oxford University Press, 1994.
[6]Granger S. A Bird’s-eye view of learner corpus research [M]// Granger S, J. Huang, Petch-Tyson S. Computer Learner Corpora, Second Language Acquisition and Foreign Language Teaching. Amsterdam: John Benjamins, 2002.
[7]Granger S. Computer learner corpus research: Current status and future prospects [M]// Connor U, Upton T A. Applied corpus linguistics: A multidimensional perspective. Amsterdam & Atlanta: Rodopi, 2004.
[8]Liu Juan. CLEC-based study of tense errors in Chinese EFL learners’ writings [J].World Journal of English Language 2012, (4).
[9]Milton J, Tseng S C. A Corpus-based Study of Logical Connectors in EFL Students’ Writing: Directions for Future Research [M]// Pemperton R, Tseng S C. Studies in Lexis. Hong Kong: HKUT, 1993.
[10]Nesselhauf N. Learner corpora: Learner Corpora and Their Potential for Language Teaching [M]// Sinclair J M. How to Use Corpora in Language Teaching.Amsterdam: John Benjamins Publishing Company, 2004.
[11]Schmidt R. Consciousness and Foreign Language Learning: A Tutorial on Attention and Awareness in Learning [M]// Schmidt R. Attention and Awareness in Foreign Language Learning. Honolulu, HI: University of Hawaii, 1995.
[12]Pederson E, Guion S. Orienting Attention During Phonetic Training Facilitates Learning [J]. Journal of Acoustic Society of America,2010, 127 (2).
[13]P. Master. The Effect of Systematic Instruction on Learning the English Article System [M]// Odlin T. Perspectives on Pedagogical Grammar. Cambridge: Cambridge University Press, 1994.
[14]文秋芳,王立非,梁茂成. 中国学生英语口笔语语料库 [M]. 北京:外语教学与研究出版社,2005.
[15]Nicholls N. The Cambridge Learner Corpus - error coding and analysis for lexicography and ELT [C]// Archer D, Rayson P, Wilson A, McEnery J. Proceedings of Corpus Linguistics 2003, Lancaster, UK: Lancaster University, 2003.
[16]L.Anthony.AntConc(3.4.4)[CP/OL].(2015-06-26)[2017-06-15]. http://www.laurenceanthony.net/software/antconc/releases/AntConc344/.
[17]H. Dulay, M. Burt. Natural Sequences in Child Second Language Acquisition [J].Language Learning, 1974,(24).
猜你喜欢
疯狂英语·初中版(2023年5期)2023-06-01 12:31:16
初中生学习指导·提升版(2021年4期)2021-09-10 07:22:44
家庭影院技术(2021年2期)2021-03-29 07:18:22
疯狂英语·新策略(2019年12期)2020-01-04 02:48:06
疯狂英语·初中天地(2019年6期)2019-10-17 01:50:40
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
外语教学理论与实践(2014年1期)2014-06-15 06:40:18
