
P2P校园贷款个人违约风险因素指标探析
2018-03-13 03:34博士生导师
财会月刊 2018年6期
,(博士生导师),
一、引言
在我国,随着互联网技术、通信信息技术的不断创新以及与金融业的快速融合,互联网金融中的重要组成部分——P2P网络借贷得到了快速的发展。P2P(Peer to Peer Lending)是指借贷双方不经过金融中介机构,直接在线交易的金融借贷服务模式。P2P在促进普惠金融发展、提升金融服务质量和效率、满足多元化投融资需求等方面发挥了积极作用,展现出了其巨大的市场空间和发展潜力。2017年6月底,全国网贷平台贷款余额为10449.65亿元,历史累计成交量达到了48245.23亿元,可以看出,其已成为一个新兴的万亿级市场。
值得注意的是,网贷当中的活跃群体——高校学生需要多元化的消费,但他们的经济尚未完全独立,因此成为网络信贷市场上重要的借款人群。据“网贷之家”对高校学生网络借贷数据统计,西部地区学生借款占比最大,达到总量的73.53%;借款需求度排前五位的依次为甘肃(11.2)、青海(9.95)、贵州(8.99)、内蒙古(6.66)、宁夏(6.37)。可见,校园网络贷款作为国家助学贷款的补充,为低收入地区高校学生提供了有力的经济支持,起到了一定的“帮弱扶弱”作用。
然而,学生贷款普遍存在违约几率较高的问题。2006年全国学生资助管理中心公布的数据显示,31所中央部署高校和118所地方高校中,助学贷款平均违约率为18.53%。2009年,助学贷款的不良率达30%,是普通贷款坏账的15倍。校园网络借款情况更加不容乐观,总体逾期几率和违约几率分别达到36.74%、10.28%,其中用于创业的借款违约率最高,为11%。同时,除了少数恶性行为以外,“裸条”“暴力催收”等一系列负面事件的发生使校园贷款蒙上灰色。导致这些事件发生的根本原因是高校学生经济尚未独立,缺乏还款保障和自我保护意识。2017年5月27日,银监会、教育部、人力资源社会保障部下发了《关于进一步加强校园贷规范管理工作的通知》,要求未经银行业监管部门批准设立的机构禁止提供校园贷款服务,且现阶段网贷机构一律暂停校园贷款业务,对于存量业务要制定整改计划,明确退出时间表。
无论P2P校园网络贷款这一在我国曾经服务过几十万在校学生的金融工具是否消失,也无论其会再以哪种新模式服务高校学生,都十分有必要对其进行重新审视。发现与高违约相关的重要个人风险因素,对构建校园网络贷款的安全线、降低借款违约几率、保护在校学生权益、培养大学生的信用意识以及加强P2P网贷平台个人信用风险防范管理都具有重要的意义。
二、相关研究及启示
与P2P网络贷款相关的研究尚处于起步阶段,而对大学生P2P网络贷款行为的研究更为鲜见,但P2P网贷中关于个人信用的研究方法可以作为借鉴和参考。
目前国内外的研究多考察借款发起人的“软信息”和“硬信息”对其违约风险和贷款获得产生的影响。“软信息”是不能用准确的数值或者指标表示的信息,如社会资本、受欢迎程度;“硬信息”是指能用准确数值或者指标表示的信息(刘峙廷,2011),如年龄、性别、财务状况等。
在评价个人信用的方法上,以统计学和运筹学方法为主,如判别分析法、Logistic回归法、线性回归法、ZEAT模型等。此外,信用评分的非参数统计方法也得到了很快的发展,如决策树法、K-近邻判别分析法等。20世纪80年代,基于人工智能的信用评价方法,如神经网络、遗传算法等,为解决评价中的复杂问题提供了新的思路。在评估方法方面,混合方法比单一方法显示出更高的精度和更强的解释力(Blanco,2013;Oreski,2014;Lopez、Jeronimo,2015)。在利用数据挖掘技术构建的评分模型中,Logistic回归模型整体准确率比较高(Bekhet、Eletter,2014)。Lyer(2014)认为对于小规模借款人,非标准的财务信息数据筛选机制十分重要。
国内学者多基于“拍拍贷”数据,从评估方法上展开研究,如进化的神经网络模型(喻敏、吴江,2011)、决策树和神经网络组合模型(杨胜刚等,2013)、非线性主成分法结合神经网络及Logistic法(熊志斌,2013)、模糊近似支持向量机(姚潇、余乐安,2012)。国内网络贷款平台对借款人的信息采集多偏向“硬信息”,这使得与“软信息”相关的研究难以开展。
鉴于我国对于高校学生P2P网络借贷个人信用风险因素研究尚处于空白阶段,且国内P2P平台缺少“软信息”数据,本文采用美国网络贷款平台Lending Club公开脱敏数据,运用机器学习和数据挖掘方法,得到P2P校园贷款个人违约风险因素重要字段,并据此提出降低P2P校园网络贷款个人违约风险、保护在校学生的措施。
三、数据分析
美国目前P2P网络贷款总额已超百亿美元,其中Lending Club网贷平台交易规模占到美国交易总量的60%以上,含有丰富的借款人信息可供研究。本文根据“Student-College”“Student-Technical School”等字段,从LendingClub.com公开的231059条脱敏信息中,选出含有81个维度的共817条高校学生借款数据,采用R语言(x64 3.2.3)软件并基于Adaboost算法进行数据挖掘分析。
数据分析主要步骤如下图所示:①对数据进行清洗、填补、变量格式转化、变量整合、系统化、标准化等初步处理,以获得可供分析之用的合理数据。②对于维度大的数据,筛选信息增量大的维度,作为回归分析的重要变量。③将样本分为训练数据集和检测数据集两部分。在训练数据集上采用Adaboost迭代算法,基于数据特点构建Logistic回归分类器,对分类器集训后,基于拟合误差,赋予各弱分类器不同权重,当误差小于设定值时,停止训练,构建强分类器,计算自变量系数。由于样本维度大,本文选择随机迭代方法。④在检测数据集上检验结果的准确性。

本文数据分析方法图
(一)数据初步处理
数据初步处理主要包括数据取舍和重要缺失值填补。每条数据的81个维度中,主要舍弃两类维度:一是14个缺失值超过400导致填补难度过大的维度;二是15个诸如编号一类的中性维度。对借款状态、雇佣状态等信息的赋值详见表1。

表1 部分指标维度赋值
Total Credit Linespast 7 years、Inquiries Last 6 Months、Current Delinquencies、Delinquencies Last 7 Years、Public Records Last 10 Years五个字段缺失 4条数据,采用均值进行填补。剩余12个字段存在约120个缺失,利用其余37个无缺失字段对其进行线性拟合,补全缺失值。经以上处理后,得到维度为51的814条借款数据。
(二)模型与方法
本文基于Adaboost迭代算法数据挖掘方法对样本赋予不同的权重后,采用Logistic回归模型,以Loan Status(借款状态)为目标变量,通过训练得到各指标参数,利用随机梯度算法进行样本参数自适迭代估计,探究P2P校园贷款借款人违约的重要因素指标。
1.Adaboost迭代算法。Adaboost迭代算法是一种增强式学习算法,它能在普通算法产生的弱分类器的基础上集成多个分类器,进而学习得到强分类器。此方法可以排除次要训练数据特征,加强关键训练数据权重。主要的迭代过程为:
取样本集T={(x1,y1),…,(xN,yN)},其中xi为参数的属性向量,yi为布尔值。初始化数据权值:D1=(w1,1,…,w1,i,…,w1,N)。

其中w1,i为第i个样本第一次弱分类迭代权重。
假设弱分类器为其在原始样本迭代学习下符号输出:

据此进一步计算该分类误差εm:
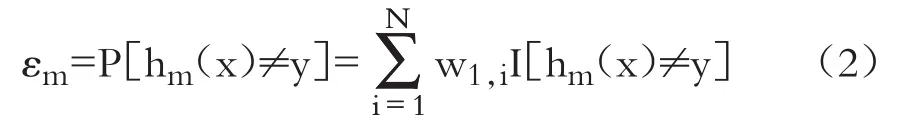
上述误差率是样本权重加权值,即样本的平均误差。
得到分类器hm(x)的误差率,进一步可以衡量该分类器的权重am:

将该权重送交下一轮迭代,并重新分配样本的权重:

其中:
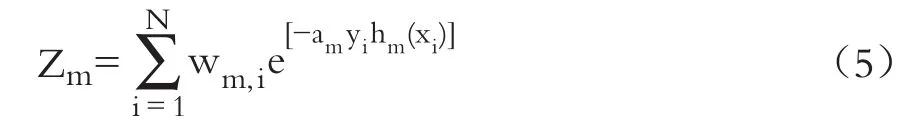
当分类结果与实际结果一致时,e的指数部分为负;当分类结果与实际结果不同时,e的指数部分为正。通过权重更新,对于分类错误的点,将赋予更高的权重;对于分类正确的点,将降低其权重。这样在下一轮迭代中,若之前误判的点被分类正确,则将有可能被重新选择。
重复式(1)~式(5),直至m=M,集成M个弱分类器构建最终强分类器H(X):

2.Logistic算法。鉴于目标变量为一个二分类变量取值,在Adaboots算法中采用Logistic回归作为其中的分类器。Logistic模型是适合二分类问题结构的线性模型,其基本形式为:
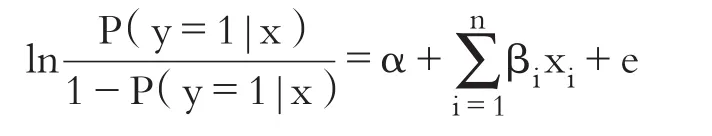
其中,e为残差项,且当自变量x=(x1,x2,…,xi)时,因变量y=1的概率为:E(y=1|x)=E(α+β1x1+…+βnxn)=P(y=1|x)。
3.随机梯度算法。梯度算法在机器学习中常被用于参数的迭代估计,由于每次迭代都要遍历m个样本,固定梯度模型复杂度O(m)会随样本数和样本维度大幅上升,减慢迭代速度。相较于固定梯度模型,Stochastic Gradient Descent(随机梯度)在一定程度上降低了批梯度的遍历量,复杂度从O(m)降为O(1),其算法表达式如下:
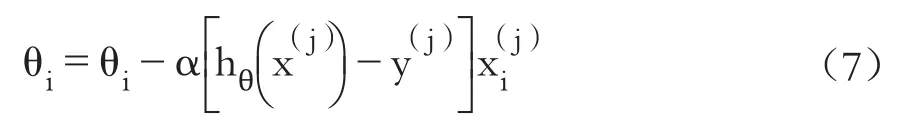
4.模型建立。
(1)根据信息增益值筛选重要维度指标。模型的一般特征工程包括缺失值处理、数据归约、降维等步骤。由于Logistic分类时变量过多,容易造成“维度灾难”、过度拟合、学习周期过长等问题,需要运用信息增益原理进行指标筛选。

表2 Credit Grade字段各等级属性信息
样本的信用等级从高到低用“0~8”表示,“Loan Status”中“1”代表该样本处于违约状态,“0”代表该样本处于正常状态。
计算该字段信息增益值:

用同样的方法处理其余49个字段(分为离散型字段和连续型字段),可得到如表3和表4所示的信息增益。

表3 离散型字段信息增益
从表3可以看出,“最低社会信用评分”“是否朋友推荐”“是否获得朋友投资”三个字段带来的信息增益最高。表4中,由于离散化分区的大小对结果的影响较大,故其信息增益值Gain(x)与离散字段稍有不同,其中离散化后,“规则还款金额”“本金滞纳损失”“规则本金还款滞纳”“借款利率”四个字段带来的增益效果均超过0.025,可将其作为自变量。

表4 连续型字段信息增益值

表5 中心化标准化后数据(部分)
(2)采用基于Logistic分类器的Adaboost迭代分类进行集训。首先为样本赋予初始权重:

再构建Logistic弱分类器:

通过梯度下降估计参数:

每次迭代估计利用式(11)分类错误率进行判断选择,为简化表达式,令偏置项α=β0,j表示样本编号,下标i表示样本维度编号,j=1,2,…,N,i=0,1,2,…,K。
计算分类错误率:

更新样本权重,重新训练分类器:
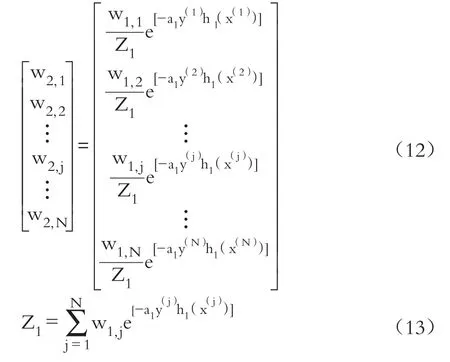
重复式(8)~式(12)M次后,构建强学习模型:

将总样本按照8∶2分为652个训练样本和162个检测样本后,按上述方法在训练集上构建一个Logistic弱分类器,先给各样本赋予初始权重:
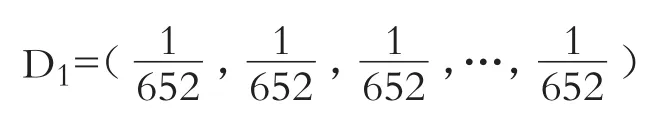
再初始化Logistic模型自变量系数参数,经线性回归得到偏置项和7个维度自变量系数估计值:

代入Logistic模型,进行第一次粗略判别,得到:
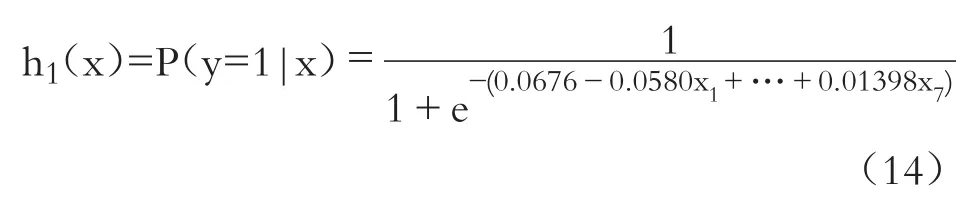
将训练样本相应变量代入式(14),得到的部分结果如表6所示。对结果取值0或者1,得到表7。

表6 初始迭代结果

表7 判别结果对照
随机查找获取判断错误的点,如随机获取第144号样本,查看原数据可知该点被误判为1,则利用该点做第一次随机梯度迭代,如随机选择梯度下降学习步长为0.2,则得到各自变量系数修正值:

继续对结果(15)进行第二次判别,并计算第二次判别错误率,以错误率作为迭代循环结束条件。适当的条件阈值对迭代精度和节约迭代次数十分重要,通常可以在0.3~0.6之间调整,本文取0.3。
再次通过式(14)可得到,在该参数下的判别错误的样本个数为174,则判别错误率为:

其中w1,j为初始样本权重,均为表示判断错误的点。判别错误率低于0.3满足条件跳出循环,可见由于随机梯度的随机性,在算法参数估计时将批梯度的复杂度O(N)降到O(1),极大地提高了大数据量处理的效率。
得到该Logistic弱分类器的判别错误率后,可进一步计算该分类器在Adaboost中的权重:

确定了第一个分类器权重a1后,利用a1更新样本权重,首先计算归一化因子Z1:
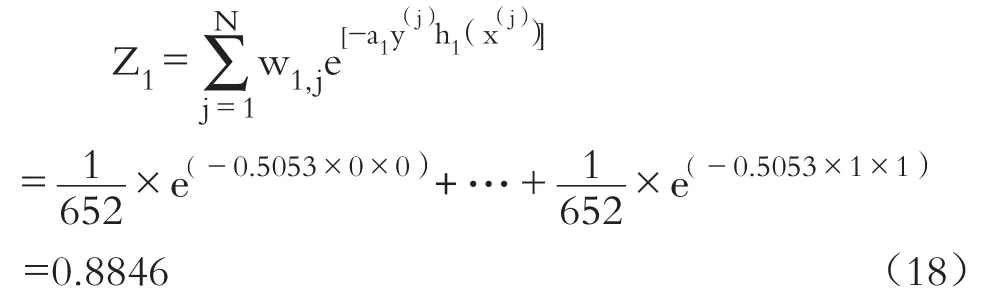
再利用归一化因子Z1,确定样本权重为:

重复式(14)~式(19),构建1000个Logistic弱分类器,得到各分类器的参数及权重,如表8所示。

表8 组合分类器概况(部分)
在加权Logistic回归下,得到对应系数(β0,β1,β2,β3,β4,β5,β6,β7)=(-1.1479,-0.0857,-1.4949,-1.8405,-0.4174,0.0872,-0.0633,0.0019)。
(3)回归准确性检测。利用训练数据集,得到该算法的预测情况,如表9所示。可见,训练数据集上的准确率为:(585-26)/652=93.71%。同样地,利用检测数据集得到该算法的预测情况,如表10所示。可见,检测数据集上的准确率为:(143+47)/162=90.74%。总体上,准确率较高,要达到更高的准确率,可调低式(16)的错误阈值,但要以迭代次数为代价。

表9 训练数据预测结果

表10 检测数据预测结果
(三)结果分析
通过美国网贷平台高校学生借款数据可知,信息贡献度最大的字段为“最低社会信用评分”“是否朋友推荐”“是否获得朋友投资”“规则还款金额”“本金滞纳损失”“规则本金还款滞纳”“借款利率”,这些字段与借款人是否能履约还款有较高的关联度。
四、启示
校园贷款的对象主要是高校学生,从年龄上来讲,高校学生已属完全民事行为能力人,但一般不具备独立的经济能力,主要的消费经济来源是家庭,同时也缺乏理财能力和风险意识,属于成年人中的“弱势群体”,在个人小额社会信贷活动中需要得到必要的保护。
1.构建家校联合的学生网贷知情机制。网络贷款是一种市场行为,本质上是贷款方为了获得经济利益进行的放贷。借款利率由交易双方自行决定,具有市场化特点,波动性较大。过高的借款利率会给借款人带来较大的还款压力,容易造成借款不能及时归还、“恶性催收”等不良后果。从保护学生角度出发,家长和学校要了解学生网络贷款情况,对不合理的借款予以制止,支持和保护合理的借款需求。
2.网络贷款平台在对学生的贷款中要加强其社会支持确认。是否朋友推荐、是否获得朋友借款是重要的信用因素,如果平台无法了解借款人的还款能力,则可通过与借款人有过正面互动的社交伙伴获得相关信息。因为得到朋友推荐、获得朋友的借款,往往意味着对借款人还款能力和信用的肯定。这与Lin(2009)的“‘软信息’在P2P网贷平台十分重要,社交网络资源有助于减少信息不对称,降低借款违约概率”的研究结果一致。因此,加强借款人的平台社会网络认可能更好地保证借款人具备必要的还款能力,降低借款人的道德风险。
从我国情况看,拍拍贷、名校贷、我来贷、分期乐等贷款平台要求学生注册时填写的信息中(见表11),身份特性指标欠缺,中性信息(无法通过该指标判断用户属性,如手机、姓名、身份证号码等)较多,但这对评估用户信用属性贡献度较小。贷款平台应在缺少借款人信用“硬指标”的情况下,采用“软指标”(如社会网络资源指标),以降低其违约风险。
3.把控借款用途和借款利率,建立借款风险档案。网贷平台要严格把控借款利率和借款用途两道关,从借款利率和用途两方面入手建立借款人的风险档案。据统计,校园借款在创业、教育、购物方面的需求最大,借款人数分别占比31.13%、28.09%和27.09%,借款金额分别占比32.78%、27.95%、26.43%。风险最高的创业资金需求占据着重要的地位。
鉴于借款利率越高,违约概率越大,网贷平台应对学生借款的利率予以限制,对特殊情况下的高利率借款及时进行记录和监控。高利率借款反映出借款人对资金需求的迫切性,可能是非理性消费情况下的借款,有较高的潜在违约风险。因此,一旦借款人不能依约分期还款,就要及时了解情况,提醒干预,必要时联系家长和学校,降低借款人违约风险。
4.尽快实现借款人社会信用信息共享。一方面,从“最低社会信用评分越高,违约概率越小”这一结果可知,过往的借贷信用积累对借款人违约风险有重要的参考作用。但目前全社会成员的借贷信用信息并没有公开,不利于网贷平台控制借款人违约风险。另一方面,目前我国高校学生信用状况不容乐观。从已公开的助学贷款信息来看,历年借款违约率在10%以上,2002和2009年甚至达到30%以上,对学生进行信用教育迫在眉睫。实现社会信用信息共享,既对在校学生增强信用意识、培养理性消费和理财观念有着重要作用,又有利于网贷平台把控借款人信用状况,降低高校学生借款违约几率。

表11 我国校园贷平台学生信息字段
五、不足与展望
本文基于美国Lengding Club网贷平台数据,采用Adaboost算法对P2P校园贷款违约相关因素进行挖掘,而海量数据是数据挖掘的基础,本文所采用的数据较为有限,加之未能采用我国校园贷款数据进行分析,得到的结果可能不够全面。将来可进一步探讨的问题还包括社会支持网络在降低校园贷违约风险中的作用机制,在网贷活动中如何识别、评估借款人风险,以及如何建立家、校、社会联合的风险管理机制等。无论校园贷是否还会回归市场,也无论其是否会以一种新模式出现,数据时代为改进这一为在校学生提供大量金融服务的新工具创造了可能性。
Angilella S.,Mazzu S..The financing of innovative SMEs:A multicriteria credit rating model[J].European Journal of Operational Research,2015(3).
杜婷.基于粗糙集支持向量机的个人信用评估模型[J].统计与决策,2012(1).
李旭升,郭春香,郭耀煌.扩展的树增强朴素贝叶斯网络信用评估模型[J].系统工程理论与实践,2008(6).
陈辉,任越.高校大学生信用缺失的成因及对策[J].黑龙江教育(高教研究与评估版),2009(10).
熊志斌.基于自适应遗传模糊神经网络的信用评估建模[J].系统仿真学报,2011(3).
熊志斌.基于非线性主成分分析的信用评估模型研究[J].数量经济技术经济研究,2013(10).
喻敏,吴江.基于多进化神经网络的信用评估模型研究[J].计算机科学,2011(9).
杨胜刚,朱琦,成程.个人信用评估组合模型的构建——基于决策树—神经网络的研究[J].金融论坛,2013(2).
姚潇,余乐安.模糊近似支持向量机模型及其在信用风险评估中的应用[J].系统工程理论与实践,2012(3).
猜你喜欢
公民与法治(2020年23期)2021-01-04
公民与法治(2020年17期)2020-10-27
蒙古学问题与争论(2020年0期)2020-03-29
法制博览(2019年29期)2019-12-13
中国外汇(2019年10期)2019-08-27
上海财经大学学报(2019年3期)2019-06-04
瞭望东方周刊(2018年4期)2018-02-01
商周刊(2017年17期)2017-09-08
商周刊(2017年17期)2017-09-08
黑龙江科学(2016年22期)2016-03-16
