
文本分类中特征权重算法改进研究
2018-03-13 07:23:33李鹏鹏范会敏
计算机与现代化 2018年2期
李鹏鹏,范会敏
(西安工业大学计算机科学与工程学院,陕西 西安 710021)
0 引 言
作为互联网的主要信息载体,文本、图像和声音具有显著的特点。其中,文本是主要的信息载体,自然语言处理在当今仍然是研究的热门和重点方向。文本分类是自然语言处理中的重要研究课题,特征权重算法在文本分类中起到了至关重要的作用。目前文本分类中常用的特征权重算法TF-IDF是一种基于词频的特征权重算法,该方法容易实现、思想简单,兼顾效率的同时往往能取得较满意的效果从而被广泛使用。但该算法没有体现特征词在文档类之间和类内的分布信息,无法适应不平衡数据集,分类准确性不高。目前主要的改进包括以下几种:在传统算法基础上,增加特征权重所蕴含的信息;利用特征选择算法对传统算法TF或IDF部分进行替换,或对二者结合,使其携带新的分类信息[1-2];此外,还有文献通过加入类别相关度平衡因子对互信息公式进行改进,同时将其应用于特征加权算法;利用跨不同类文本的细粒度术语分布信息,特征权重计算利用文本集特征全集而非本类特征集合;利用剔除近义词方法优化文本向量中的特征项,提出贡献率因子的概念,提高了文本分类准确率[3-7]。以上多种改进算法均在一定程度上提升了分类准确率,但并未完全兼顾文档分布信息与算法在倾斜数据集上的表现。鉴于传统TF-IDF算法的不足,本文提出一种文本分类中改进的特征权重TF-IDF-dist算法。相比以上各种改进方法,本文方法兼顾文本类间与类内分布均匀程度的同时,还加入特征类间比重信息,使其对文档集分布不敏感,从而对文档集有更强的适应性。实验表明本文算法在准确率、召回率和F1值方面均优于传统TF-IDF算法。
1 传统TF-IDF算法
TF-IDF算法认为,刻画某一关键词的权重可根据其在类内文档中的出现频数和在类间出现分布来表示。算法分为2部分TF和IDF,TF即词频,代表词在类内的出现频数,IDF代表特征词概率密度的交叉熵[8]。
TF-IDF经典公式表示形式为:
(1)
其中Wi表示特征词求得的权重结果,tfi表示该特征在文档中出现次数,N表示总文档数,ni表示出现过该特征词的文档数,β是一个经验值,一般取0.01[9-11]。
计算中通常使用归一化的形式:
(2)
2 改进的TF-IDF-dist算法
从经典公式可以看出,TF-IDF算法仅基于特征词的词频与逆文档频率进行计算。计算所得权重反映了特征词在文档集范围内的出现次数信息,一定程度上反映了特征词的分布信息,但在进行分类时特征仅由以上信息决定,分类准确率较低。
经典公式中N代表的是多个类别的文档数总和,由于每一类文本可以包含多个文档,无法从N得出类别之间的分布信息。按照算法思想,当特征词在多数类中普遍出现时,该特征词应该给予较低权重,但由于文档中特定特征词的绝对数量大,经过计算得到的权重值却很大;另外,随着特征项在类内出现次数的增加,IDF应该随之增大,但算法的计算结果却几乎无变化;同时在倾斜数据集某类文档较少情况下,IDF几乎失效。
IDF的计算忽略了特征词在类内文档的分布,当特征词在同一类多个文档中出现次数一定时,根据经典公式,IDF值保持不变。特征词分布具有随机性,从而IDF的计算结果对文本类内分布不具有代表性。
针对以上算法缺陷,本文采用类内类间分布信息丰富特征权重,提高文本分类的准确性。引入类间文档、词频分布以及类内词频分布因子对TF-IDF算法进行改进。
1)提出因子introC描述文本类间分布信息:
(3)

对因子乘号左半部分,如果此项越高,即特征词在文档类别间分布比例越低,说明特征词在类别间分布越有倾向性,即分类能力越强。对右半部分,特征词在类之间分布的均匀程度能反映特征词是否普遍存在于多个类别文档。该项越大,说明该特征词在类之间分布更不均匀,也即偏向某一类别,对文档的区分能力更强。反之,该项越小,说明该词在各类别文档分布更均匀,区分类别的作用更小。两部分的乘积,可以反映特征词在类之间分类能力。
因子introC乘号左半部分反映了特征词在类别之间分布情况,规避了文本集类之间文档数据量差异带来的干扰,对类别间文档总数不敏感,提高了对倾斜文本数据集的适应性;根式部分反映了特征词在类别之间分布频数的标准差,即反映了特征词在类别之间分布均匀程度,描述因子introC,反映了特征词在类间的分布比例与类别之间分布均匀程度。
2)提出因子interC描述类内词频分布:
(4)
(5)
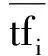
特征词在类内的分布信息也对特征词的分类能力有影响。如果特征词在类内分布更加均匀,说明特征词普遍存在于本类文档,对本类文档有更强的代表性。反之,如果特征词仅仅在一类文档的个别文档出现,那么该词更具有偶然性,不具备代表本类文档的能力。interC反映了特征词在每个类别文档中文档之间分布均匀程度均值。该项越大,说明特征在类内分布越分散,特征词随机性越强,对文档类别的区分性越低。反之,该项越小,特征在类内分布越均匀,对文档类别越有区分性。因子interC可以反映特征词区分能力。
3)改进后的特征权重算法为:
Wij=TFij×IDFij×introCi×interCi
(6)
改进后的特征权重算法TF-IDF-dist结合了传统算法与因子interC和introC,丰富了特征权重的分布信息,具有更强的分类性能。下面设计实验验证改进算法的有效性。
3 实验结果及分析
3.1 特征权重算法对比实验设计
文本分类一般首先要对文档进行预处理,包括分词去停用词等步骤。之后得到一个词的集合,集合包含停用词以外的所有词。然后进行特征选择,特征选择在降低特征维度且保持文本分类准确率的同时,可以提高文本分类效率。随后对所选特征词进行特征权重计算。需要注意的是,本文训练过程中计算所得因子interC和introC将被用于计算测试集对应的特征词权重。计算所得权重作为文档在该特征项的特征值。最后将计算所得特征值作为分类器的输入进行分类,得到分类器模型。随后在测试集验证模型的准确性[12-15]。
为验证本文算法改进的有效性,本文基于卡方统计特征选择算法,在多个分类算法以及多特征词数量下,对本文算法、TF-IDF算法和常用的改进TF-CHI算法做对比实验。具体实验流程如图1所示,在本文算法与TF-CHI算法进行比较时,图中“TF-IDF”部分为TF-CHI算法。
图1中训练过程中特征选择所得结果与训练所得分类器将被用于测试过程。测试过程的分类结果被用来分析分类准确率验证试验结果。

图1 TF-IDF权重算法与TF-IDF-dist算法对比实验流程
为测试本文算法在多个对比实验的准确率,实验数据采用搜狗实验室数据集,对财经、教育、汽车、娱乐、女性5个类别文档合计5000篇新闻文档正文进行提取作为本实验文本数据集。对文本集进行划分,每类随机选取80%文档作为训练文本集,其余20%作为测试文本集。
3.2 不同特征维度下对F1值的影响
为分析TF-IDF-dist算法在不同特征维度下分类准确率的变化,对实验文本集采用卡方统计特征选择算法,分别选取不同特征维数特征,在多项式贝叶斯分类器下进行对比实验,实验结果如图2所示。

图2 特征维数对比实验结果
分析图2发现,特征维数较少时,3种算法的准确率均处在较低位置,随特征数的增加,3种特征权重算法对应分类模型F1值均呈上升趋势,TF-IDF-dist算法F1值一直处于较高水平;随着特征维数的增加,由于特征维度已达到一定规模,3种算法的F1值增长速度逐渐趋缓,新的特征维度对整体准确率的影响逐渐下降;在各个特征维数下,TF-IDF-dist算法F1值均高于TF-IDF算法和TF-CHI算法,在各特征维度下算法F1值相较TF-IDF平均提升了3.2%,相较TF-CHI算法平均提升2.7%。
3.3 不同特征选择算法比较
为验证TF-IDF-dist算法在不同分类器下分类准确率变化,对实验文本集采用信息增益、卡方统计和互信息特征选择算法,特征维数设置为3000维,特征权重算法分别采用TF-IDF,TF-CHI和TF-IDF-dist算法,结合贝叶斯分类器做对比实验。实验结果如表1所示。
分析表1发现,当特征权重算法为传统TF-IDF算法时,结合以上3种特征选择算法,分类准确率、召回率与F1值处于较低水平,其中卡方统计表现略好于其他2种特征选择算法;采用TF-CHI算法时,结合以上3种特征选择算法,分类准确率、召回率、F1值与TF-IDF算法相比基本持平。当特征权重算法为TF-IDF-dist算法时,结合3种特征选择算法,分类准确率、召回率与F1值均有提升。其中,对比TF-IDF算法,互信息与TF-IDF-dist结合对应的F1值提升较小为2%,信息增益F1值提升最大为4%;在3种特征选择算法所计算得到的特征维度基础上,TF-IDF-dist计算所得权重的分类F1值相比TF-IDF平均提升3%,相比TF-CHI算法平均提升2.7%。
表1 TF-IDF-dist算法与TF-IDF算法针对不同特征选择算法比较

特征选择算法特征维度特征权重算法分类器平均准确率/%平均召回率/%平均F1值卡方统计3000TF⁃IDFTF⁃CHITF⁃IDF⁃dist贝叶斯分类器949494949594979797互信息3000TF⁃IDFTF⁃CHITF⁃IDF⁃dist贝叶斯分类器939393939493959595信息增益3000TF⁃IDFTF⁃CHITF⁃IDF⁃dist贝叶斯分类器939393939494979797
3.4 倾斜数据集对比实验
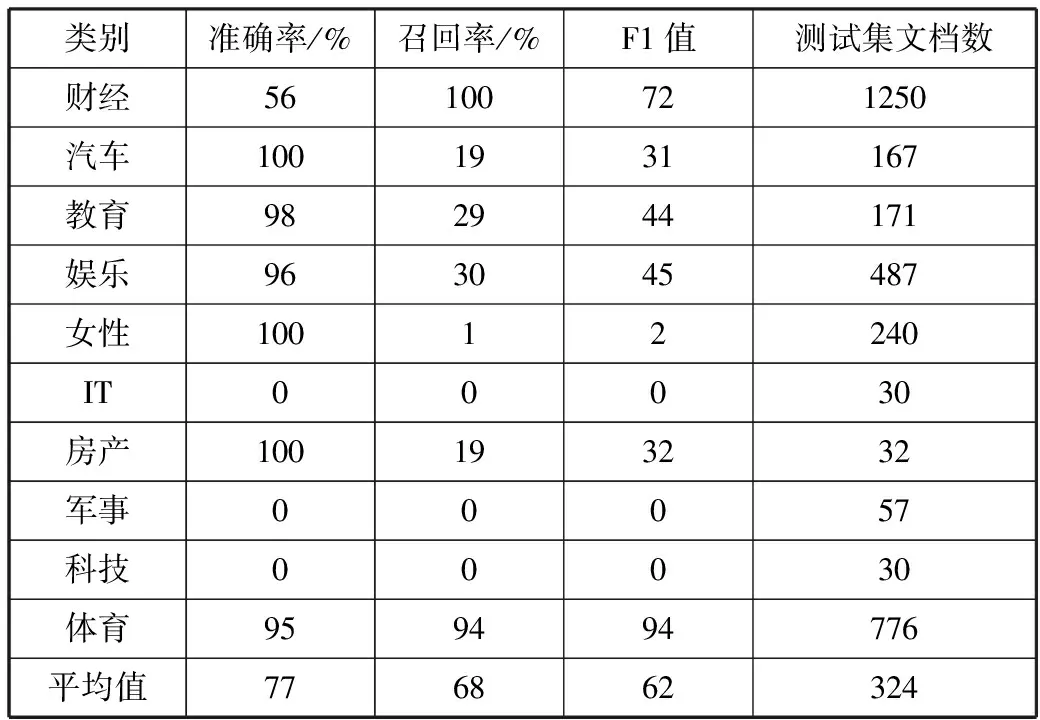
为验证改进的TF-IDF-dist算法在倾斜数据集的有效性,采用搜狗实验室10个类别新闻正文作为数据集。实验数据各类别分布如表2所示。采用卡方统计特征选择算法,特征维度为3500,采用贝叶斯分类器进行对比实验。实验结果如图3所示。
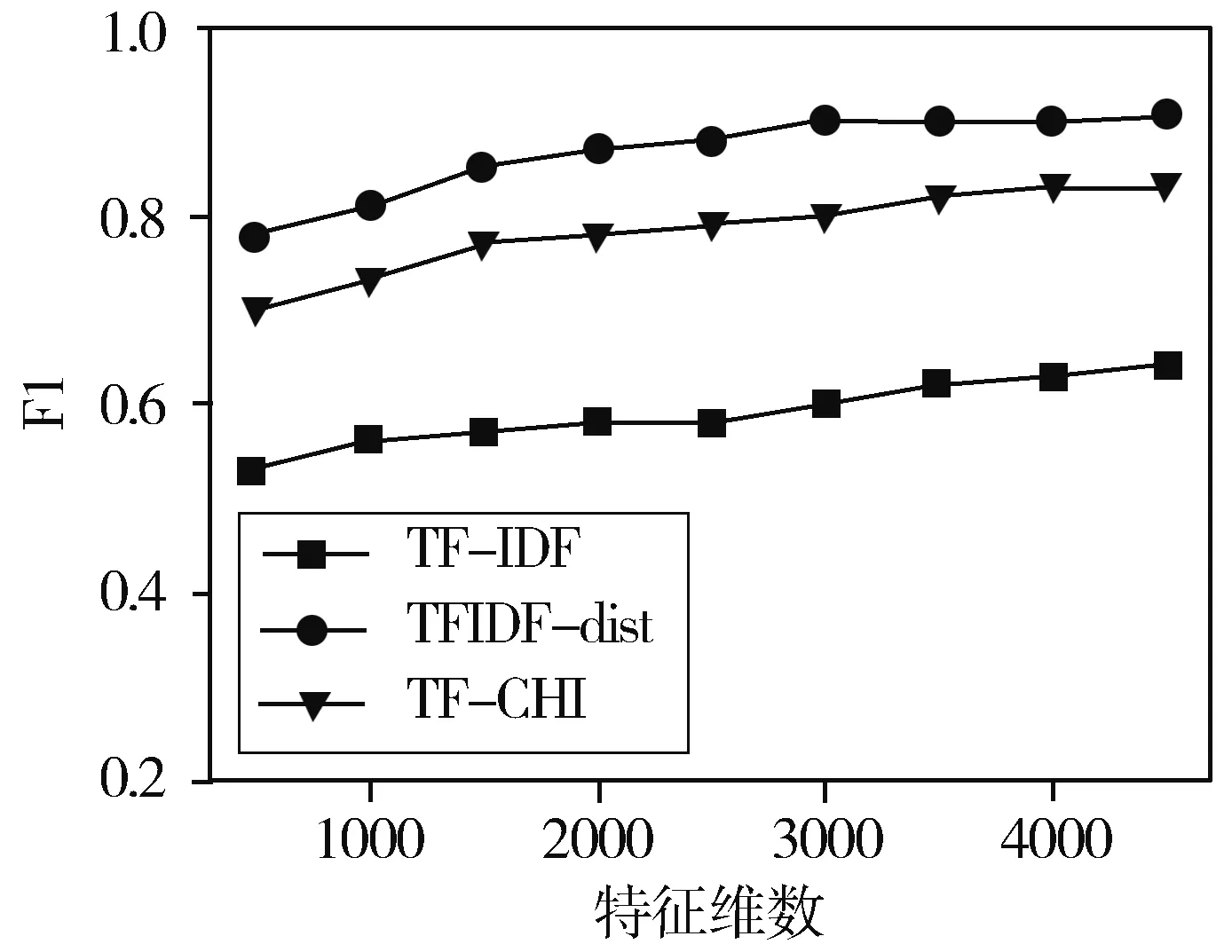
图3 倾斜数据集对比实验
表2 倾斜数据集

类别财经汽车教育娱乐女性IT房产军事科技体育训练集文档数500066768719849621201282301203106测试集文档数125016717148724030325730776
分析图3发现,随特征维数增加3种特征权重算法对应分类模型的F1值均呈上升趋势,这与均衡数据集表现一致;传统TF-IDF算法对倾斜数据集适应性较差,TF-CHI算法在倾斜数据集的F1值相比TF-IDF算法有较大提升,对倾斜数据集适应性较强。改进的TF-IDF-dist算法分类结果F1值整处于较高水平,对倾斜数据集适应性更强;改进的TF-IDF-dist算法F1值比TF-IDF算法平均高27.7%,比TF-CHI算法平均提升8.3%。
为进一步分析算法在倾斜数据集各类别的表现,取特征维度为3500,对3种模型分类结果中每类文档的准确率召回率以及对应F1值进行整理如表3~表5所示。
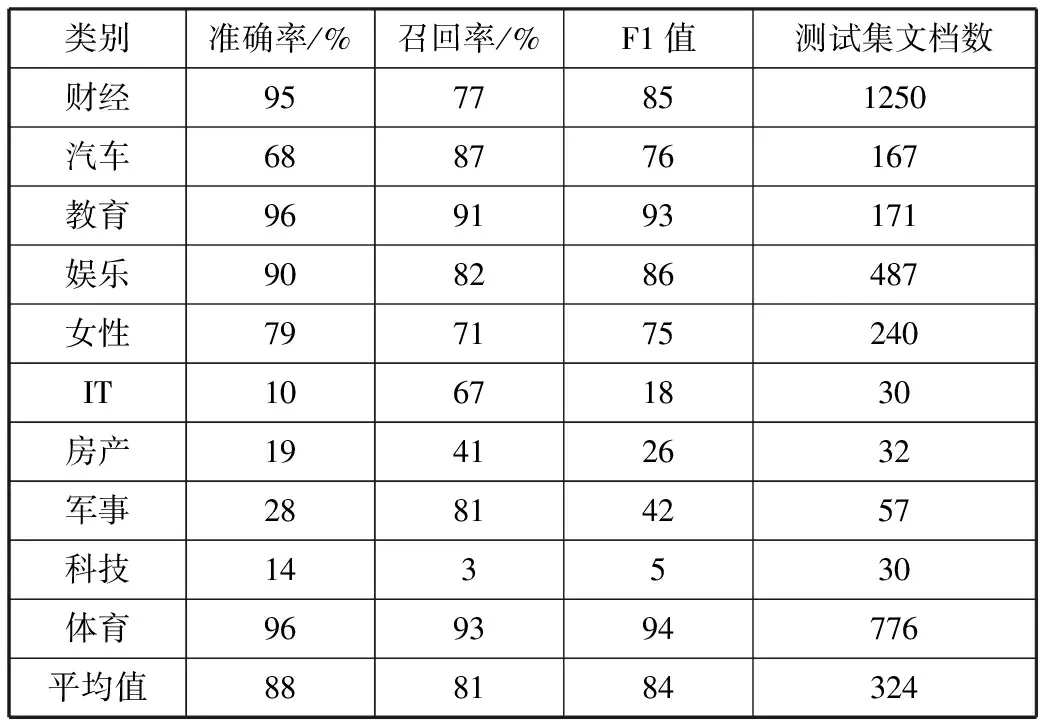
对比表3~表5数据发现,传统TF-IDF算法分类结果倾斜于文档数较大的类别,分类结果偏向性很大;TF-CHI算法对倾斜数据集适应性更强,但在训练集文档数较大的类别F1值较低;改进的TF-IDF-dist算法在各类别表现均处于较好水平。
表3 倾斜数据集各类别分类指标(TF-IDF)
类别准确率/%召回率/%F1值测试集文档数财经56100721250汽车1001931167教育982944171娱乐963045487女性10012240IT00030房产100193232军事00057科技00030体育959494776平均值776862324
表4 倾斜数据集各类别分类指标(TF-CHI)
类别准确率/%召回率/%F1值测试集文档数财经9577851250汽车688776167教育969193171娱乐908286487女性797175240IT10671830房产19412632军事28814257科技143530体育969394776平均值888184324
表5 倾斜数据集各类别分类指标(TF-IDF-dist)
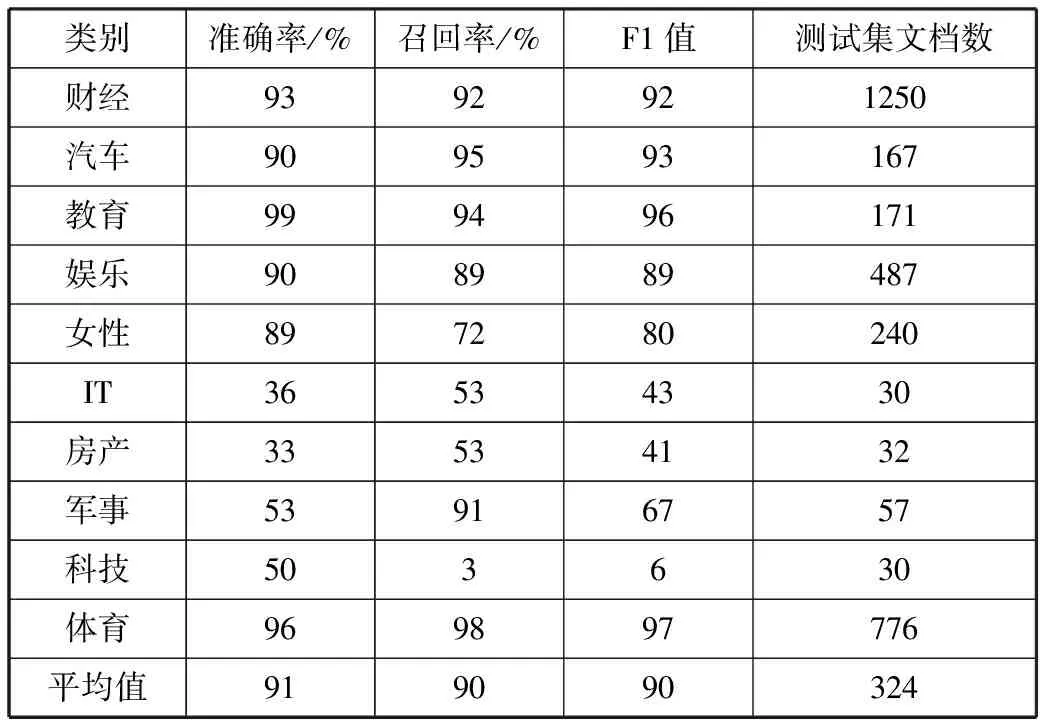
类别准确率/%召回率/%F1值测试集文档数财经9392921250汽车909593167教育999496171娱乐908989487女性897280240IT36534330房产33534132军事53916757科技503630体育969897776平均值919090324
4 结束语
1)将基于文本数据集类之间分布信息与词在类间分布比重相结合,设计实现了一种基于类间比重和类间类内方差的改进的TF-IDF-dist算法。
2)与传统TF-IDF算法相比,改进的算法在多种特征维度下,结合贝叶斯分类器,F1值平均提升3.2%;在特征数足够大且一致时,结合不同特征选择算法,F1值平均提升3%;改进的TF-IDF-dist算法在倾斜数据集,分类F1值有较大提升。
3)本文改进的TF-IDF-dist算法相较于传统算法,计算速度略有下降。在不影响算法准确率的基础上,需要进一步提高TF-IDF-dist算法的效率。
[1] Li Yongfei. A feature weight algorithm for text classification based on class information[C]// Advanced Materials Research Trans Tech Publications. 2013,756-759:3419-3422.
[2] 彭时名. 中文文本分类中特征提取算法研究[D]. 重庆:重庆大学, 2006.
[3] 徐冬冬,吴韶波. 一种基于类别描述的TF-IDF特征选择方法的改进[J]. 现代图书情报技术, 2015(3):39-48.
[4] Gautam J, Kumar E. An integrated and improved approach to terms weighting in text classification[J]. International Journal of Computer Science Issues, 2013,10(1):310-314.
[5] 黄磊,伍雁鹏,朱群峰. 关键词自动提取方法的研究与改进[J]. 计算机科学, 2014,41(6):204-207.
[6] 张玉芳,彭时名,吕佳. 基于文本分类TFIDF方法的改进与应用[J]. 计算机工程, 2006,32(19):76-78.
[7] How B C, Narayanan K. An empirical study of feature selection for text categorization based on term weightage[C]// Proceedings of IEEE/WIC/ACM International Conference on Web Intelligence. 2004:599-602.
[8] 施聪莺,徐朝军,杨晓江. TFIDF算法研究综述[J]. 计算机应用, 2009,29(S1):167-170.
[9] Chen Keli, Zong Chengqing. A new weighting algorithm for linear classifier[C]// Proceedings of 2003 International Conference on Natural Language Processing and Knowledge Engineering. 2003:650-655.
[10] 赵小华. KNN文本分类中特征词权重算法的研究[D]. 太原:太原理工大学, 2010.
[11] Aless R B, Moschitti A, Pazienza M T. A text classifier based on linguistic processing[C]// International Joint Conference on Artificial Intelligence. 1999.
[12] 樊小超. 基于机器学习的中文文本主题分类及情感分类研究[D]. 南京:南京理工大学, 2014.
[13] Chen Chien-Hsing. Improved TFIDF in big news retrieval: An empirical study[J]. Pattern Recognition Letters, 2016,93(1):113-122.
[14] Chen Kewen, Zhang Zuping, Long Jun. Turning from TF-IDF to TF-IGM for term weighting in text classification[J]. Expert Systems With Applications Journal, 2016,66(C):245-260.
[15] 郭正斌,张仰森,蒋玉茹. 一种面向文本分类的特征向量优化方法[J]. 计算机应用研究, 2017,34(8):2299-2302.
猜你喜欢
计算机技术与发展(2018年8期)2018-08-21 02:08:14
中国机械工程(2017年22期)2017-12-02 01:52:34
电子制作(2017年23期)2017-02-02 07:17:06
西北工业大学学报(2015年4期)2016-01-19 03:31:47
新校长(2016年8期)2016-01-10 06:43:59
中文信息学报(2015年4期)2015-04-21 08:29:12
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
振动工程学报(2014年4期)2014-03-01 01:15:41
计算机工程(2014年6期)2014-02-28 01:26:36
