
一种基于用户信任网络的物质扩散推荐算法
2018-03-13 07:23韩立新
计算机与现代化 2018年2期
梁 艺,韩立新
(河海大学计算机与信息学院,江苏 南京 211100)
0 引 言
基于集体智慧及合作共享的Web2.0的出现及迅速发展,极大丰富了社交网络,基于标签的社会化标注系统为越来越多社区网站所采用,例如图片标注网站Filckr、代码标注网站SourceForge、网站连接标注网站Delicious等。在其上,用户可以用简短的标签对目标资源进行主观评价。标签由用户主动标注,反映了用户的偏好,非常适合对用户的兴趣进行建模。同时标签本身的语义信息也很好地反映了资源本身的属性与内容。因此如何充分利用标签标注信息,成为推荐系统的研究热点之一。
传统推荐系统构建资源模型时,往往仅仅基于所有用户的选择历史,假定各个用户都是独立且没有联系,未能充分考虑用户之间的信任关系,并且由于新资源没有充分地被选择历史,存在冷启动及稀疏性问题。因此基于社会化标注网站中标签在用户之间的共现现象,本文设计一种信任网络,以期利用标签信息充分挖掘用户之间的信任关系,优化基于用户的资源模型。在此基础上,设计基于资源相似性及用户标注记录的资源-资源-标签三部图,在其上执行物质扩散算法,得出推荐结果。
1 相关工作
1.1 信任网络
Golbeck[1]对信任给出了如下定义:如果用户A认为根据用户B的行为进行决策将会产生积极意义,则A信任B。而信任网络则由各个用户之间的信任关系构建而成,刻画用户之间的信任程度。使用信任信息可以缓解传统CF推荐算法中的数据稀疏性问题[2]。自FaceBook为代表的社交网络兴起以来,用户在网上诸如关注、评论、注释这样的行为与表现日益丰富,众多研究者均开始借助用户的主动标注信息提取用户之间的信任关系,进而优化原算法。Kim等人[3]基于标签共现,利用KL散度来衡量用户信任关系,改进了传统直接利用标签共现衡量用户信任度的方法。Bhuiyan等人[4]将用户标签信息与资源文本描述信息结合起来以提取用户信任关系。Norwati等人[5]在文献[4]的基础上混合了Golbeck[6]提出的Tidal Trust方法,更准确地衡量了用户信任度。
以往基于标签衡量用户信任的推荐方法一般直接用于优化或替代CF中的第一步,即寻找相似用户。本文则将用户信任信息用于对基于用户的资源模型进行更新优化。
1.2 物质扩散推荐算法
基于物质扩散的推荐算法最早由Zhou等人[7]提出,将用户与项目都抽象成一个节点,根据历史选择记录组成用户-资源二部图,并认为用户已选择的资源拥有可以称之为能量的推荐能力。当需要向一位用户生成推荐时,即从用户已选择的资源开始经过资源到用户及用户到资源2次扩散,将能量扩散至其他资源,对最终用户尚未选择的资源能量进行排序,即可得出最终推荐结果。贾春晓[8]证明了在不同的推荐列表长度时,基于物质扩散的二分网络推荐算法的命中率和排序分均优于协同推荐算法。
近年来,学者们纷纷对物质扩散推荐算法进行了改进。Zhang等人[9]建立了用户-资源-标签三部图,以用户已选择资源作为能量源,通过将经标签与用户扩散返回的能量进行加权融合,得出最后推荐结果。张新猛等人[10]认为资源本身的文本内容反映用户的偏好,将其融合到物质扩散推荐算法中,提高了结果。文献[11-12]同时将未选择资源向已选择资源的扩散考虑进来,并对热门商品进行了惩罚,优化了原算法。通过对比以往基于二部图的优化方法发现,其仅仅从优化初始能量分配[13]、能量扩散分配比例[14]等方面入手,而没有更深入地试图优化二部图的结构。在本文中,区别于以往稀疏的二部图,根据资源之间的相似性建立了资源-资源完全二部图,并与资源-标签二部图合并,组成资源-资源-标签三部图作为执行物质扩散算法的基础。
2 基于用户信任网络的物质扩散推荐算法(UTNDR)
传统基于用户的资源模型通常没有考虑用户之间的信任关系,因此本算法要解决的问题有2个:1)如何构建基于用户信任网络的资源模型;2)如何将资源模型与物质扩散推荐算法结合起来进行推荐。
本文算法的具体流程概括如下:
步骤1构建用户信任网络。
步骤2基于用户信任网络,构建基于用户的资源模型。
步骤3计算资源相似度,组成资源-资源完全二部图。
步骤4将资源-资源二部图与资源-标签二部图合并,组成资源-资源-标签三部图。
步骤5针对每一名用户,在资源-资源-标签三部图上执行物质扩散算法,得到推荐结果。
2.1 符号定义
符号定义见表1。
表1 符号定义

符号说明U用户集R资源集T标签集p用户数量q资源数量o标签数量
2.2 具体算法流程
2.2.1 构建用户信任网络
如图1所示,社会化标注系统中的标注信息可以由用户-标签-资源三部图展现。标签反映用户的偏好与兴趣,如果2名用户曾使用了同一个标签,则认为他们有一定联系且有一定互信任度。如此,将这种基于标签共现的联系表示为信任网络中连接这2名用户的一条边,考虑到所有的标签共现,就组成了信任网络。据此,图1中所有用户的信任网络如图2所示。

图1 用户-标签-资源三部图
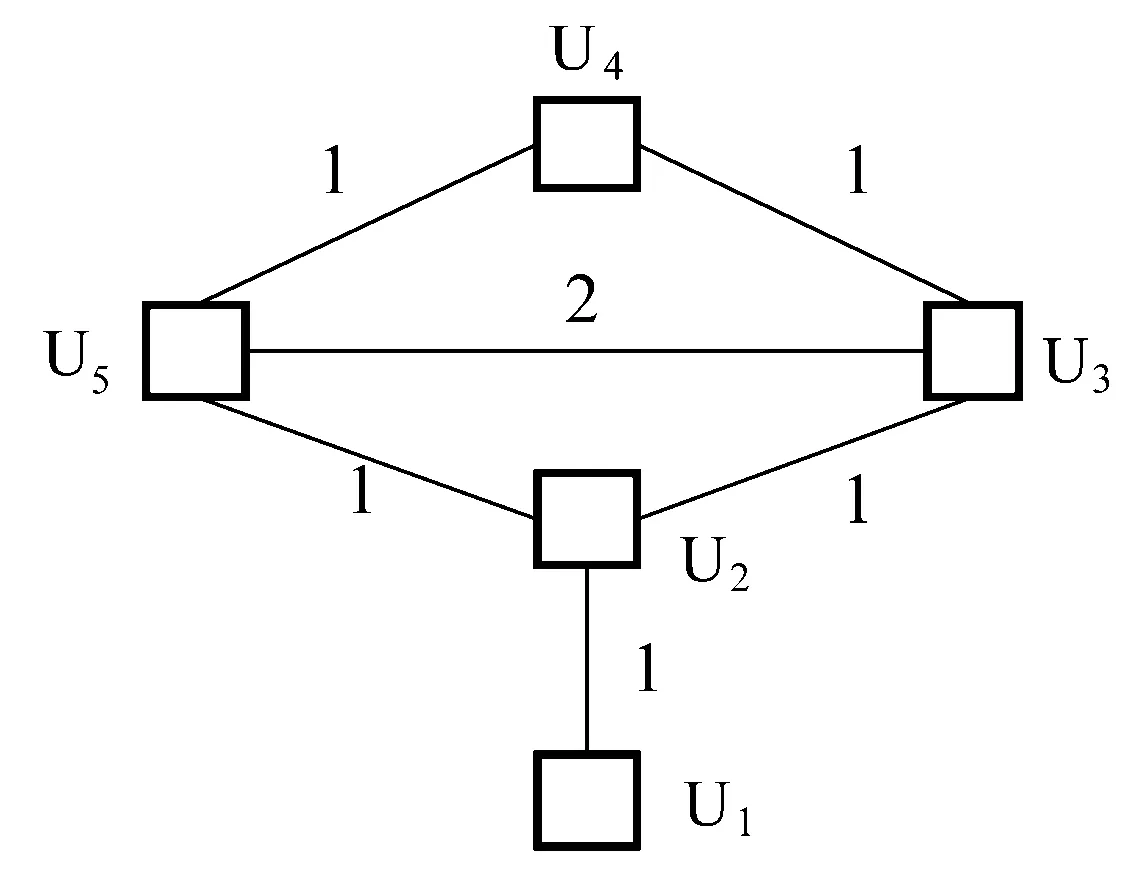
图2 用户信任网络
因此,信任网络可以定义为:
G={U,E}
(1)
其中U表示所有用户节点,E为G中边集,记录用户之间的所有信任联系。
E中任意一条边eij定义为:
eij={Ui,Uj,trij}
其中trij为Ui与Uj之间的信任度值,即Ui与Uj共同使用过的标签数量。例如图1中U3与U5都曾使用过标签t2,t3,则其信任度为2。
2.2.2 构建基于用户的资源模型
2.2.2.1 基于TF-IDF的初始资源模型
将不同用户的活跃度差异考虑进来,基于搜索引擎中经典的TF-IDF来建立初始资源模型,以减少过于活跃的用户对模型的影响。
Profile(rj)={w1j,w2j,w3j,…,wpj}
(2)
其中,wij=tfij×idfij,tfij定义为ui对rj的标记次数与ui对所有资源的最高标注次数之比:
(3)
idfij定义为ui对所有资源的标注次数之和与对rj的标注次数之比的对数:
(4)
2.2.2.2 利用用户信任网络优化资源模型
初始资源模型没有考虑用户之间的信任关系。这里在用户信任网络中使用基于随机游走的PageRank算法对资源模型进行更新优化。
基于PageRank模型,漫步者以初始资源模型中非零用户节点为起点根据与相邻节点间边的权重随机地漫步至相邻节点,并将自身权重传播至相邻节点,则由当前用户节点Ui游走至其一个相邻用户节点Uj的概率为:
(5)
其中,n(i)表示Ui的相邻节点,trij表示用户Ui与Uj之间的信任度。
使用PRi(k)来表示第k次迭代后用户Ui节点的权重,由式(5)则有下式:
PRi(k)=d∑j∈n(i)ajiPRj(k-1)+(1-d)PRi(0)
(6)
其中,PRi(0)表示用户Ui节点的初始权重,d为阻尼参数,控制节点从相邻节点接收权重的比例。
最终,PageRank算法迭代一定次数后,所有用户节点的权值会收敛至一定值,即为其最终权重。
2.2.3 计算资源相似度,组成资源-资源完全二部图
采用经典的余弦相似性分别两两计算资源间的相似性:
(7)
基于式(7)计算的相似性值,生成资源-资源二部图。这里的二部图为一完全二部图,即左边集合的任一顶点与右边集合的任意顶点间均有连接,其权值为相似性值。
2.2.4 将资源-资源二部图与资源-标签二部图合并,组成资源-资源-标签三部图
从图1所示的用户-标签-资源三部图提取出资源-标签二部子图。并与2.2.3节中所得的资源-资源完全二部图合并,可得资源-资源-标签三部图。将初始的无向边替换为有向边,以表示物质扩散算法中能量的传输方向。如图3所示。

图3 资源-资源-标签三部图
2.2.5 在资源-资源-标签三部图上执行物质扩散算法,得到推荐结果
现为一用户ui推荐资源,根据ui以往的标注历史可以得到初始能量分布为:
v(ui)=(uri1,uri2,…,uriq,uti1,uti2,…,utio)
(8)
其中元素值为ui对各个资源的标注次数或标签的使用次数。
与传统物质扩散推荐算法需要进行2次往返扩散过程不同,本文提出的算法这一部分只需进行一次扩散,即同时进行资源->资源,标签->资源的一次性扩散。
其中资源rj到ri的扩散效率RSij为:
(9)
标签tj到ri的扩散效率TSij为:
(10)
通过对最终资源的能量值排序,就可得到最终的推荐结果。这一过程可以向量化表示为:
e(ui)=Mv(ui)
(11)
其中:
(12)
e(ui)=(eri1,eri2,…,eriq)表示一次模拟扩散后各个资源的能量值。对最终各个资源的能量值进行排序后,即可得到针对用户ui的最终推荐结果。
2.3 相关工作比较
在众多推荐算法中,构建资源模型是一重要的步骤。以往推荐系统构建资源模型时,往往仅仅基于评分矩阵[15]或其为所有用户的01选择历史[7],假定各个用户都是独立而没有联系,未能充分考虑用户之间的信任关系。标签反映用户的偏好与兴趣,众多算法都将标签信息融入到原有算法中,提高了推荐结果[9,15],但其一般仅将由资源-标签关系获得的推荐结果与原来由资源-用户关系获得的推荐结果进行一定的加权融合,未能从用户信任关系角度出发,更深地挖掘用户兴趣关联。因此本文从优化资源模型角度出发,基于标签共现现象建立了用户信任网络,将标注信息转化为用户互信任信息,对资源模型进行了更新优化,并配合改进的物质扩散算法以提升推荐结果。
3 实验结果与分析
3.1 实验数据
提供标注服务的社区网站有很多,本文采用MovieLens和Delicious的数据,以及采用文献[15]中的p-core方法使实验数据较为稠密,以更好地验证所提模型的有效性。具体操作为,过滤掉MovieLens数据集中出现次数少于5次及Delicious数据集中出现次数少于20次的所有标签、用户及资源种类。过滤数据后2数据集的详细分布信息如表2所示。
表2 数据详细信息

数据集标注数目用户数目资源数目标签数目MovieLens3533681924452309Delicious7207887665156125746
表2中标注数目是标注行为的总发生数目。
3.2 评估标准
采用最经典的精确率、召回率以及F值来评估算法。对于每一个用户,从其历史标注信息中提取其所有标注过的资源,记为Rh,然后根据算法得出规模为k的推荐结果集Ru。
精确率用于衡量推荐结果集中有多少为用户真实选择,计算公式为:
(13)
召回率表示用户真实选择的资源有多少为推荐算法所命中,计算公式为:
(14)
精确率和召回率指标有时候会出现矛盾的情况,F值可以综合考虑他们,其计算公式为:
这里取α为1,即F1值。
3.3 实验结果
本文选择Gemmell等人[15]提出的一种基于标注数据的线性加权混合方法(LHCF)及Zhang等人[9]提出的基于三部图的物质扩散推荐算法(IDTG)与本文提出的基于用户信任网络的物质扩散推荐算法(UTNDR)进行比较。Gemmell等人创造性地将用户-资源-标签三维信息降维提取出用户-资源、用户-标签、资源-标签信息,并在其上分别应用经过改进适应的CF算法,得出各自的推荐结果,最后利用梯度下降法在训练集上训练出各自最好的权重系数,进而得出最终的推荐结果。Zhang等人建立了用户-资源-标签三部图,将经标签与用户扩散返回的能量进行线性加权融合,得出最后推荐结果。
在具体试验中,采用交叉验证法,取10次平均结果作为最终结果。每一次随机选取70%的数据作为训练集,剩余30%作为测试集,训练完模型后,选取测试集中的50%用来生成推荐,剩余50%用来与推荐结果作比较,计算得出精确率及召回率。
在资源推荐目标数量k取不同值时,在2数据集上的精确率比较结果如图4及图5所示。

图4 Delicious精确率比较结果

图5 MovieLens精确率比较结果
2数据集上召回率比较结果如图6及图7所示。

图6 Delicious召回率比较结果
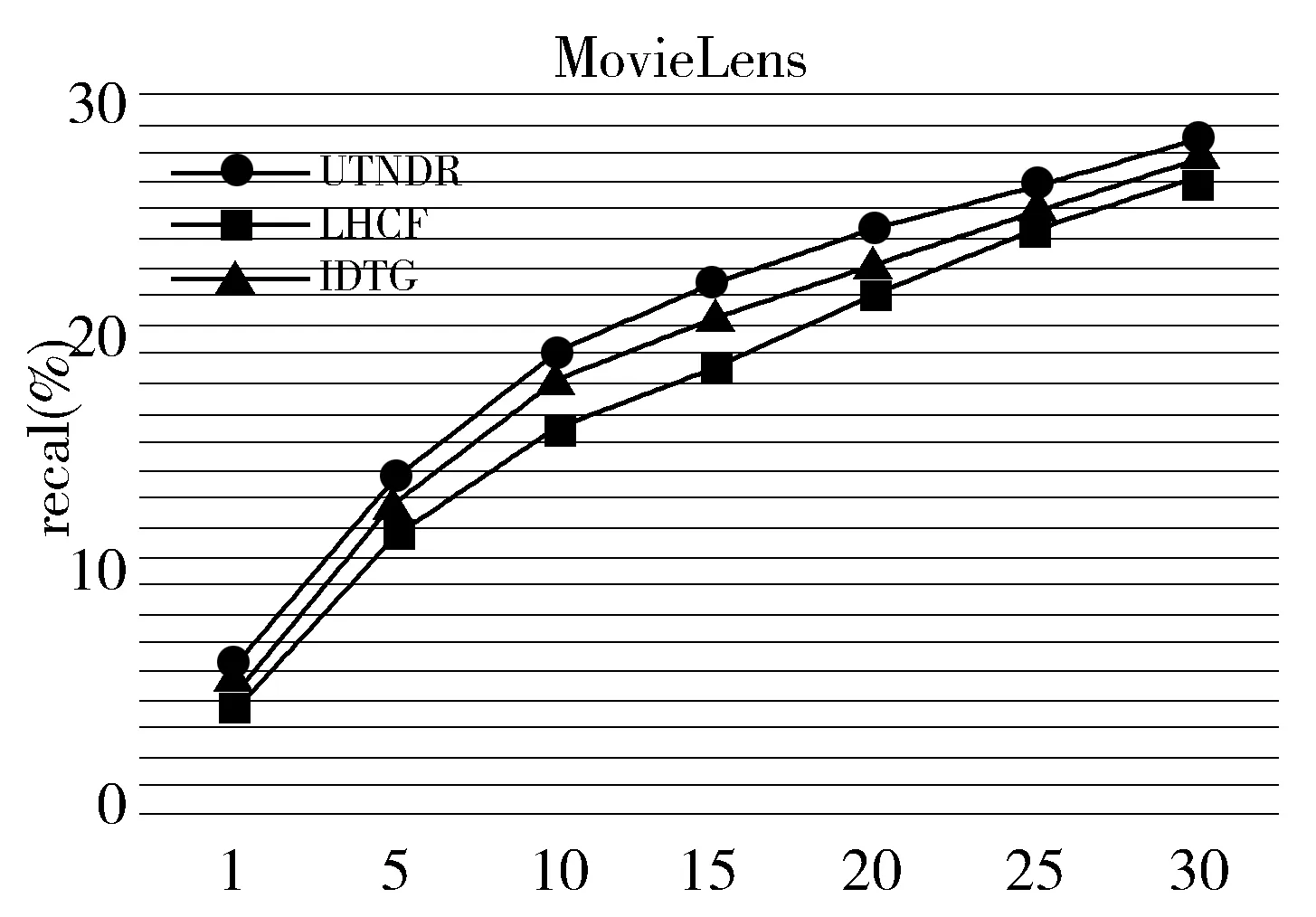
图7 MovieLens召回率比较结果
2个数据集上F1值比较结果如表3及表4所示。
表3 Delicious F1值比较结果/%

151015202530UTNDR3.076.157.377.737.737.587.37LHCF2.794.945.305.625.645.655.56IDTG3.135.546.546.836.987.016.90
表4 MovieLens F1值比较结果/%

151015202530UTNDR8.3912.9413.2512.2311.1110.049.07LHCF6.2110.8110.589.689.048.217.50IDTG7.0311.7511.8610.959.939.278.29
以上最佳结果Delicious数据集于阻尼参数d为0.45时取得,MovieLens则在d取0.2时取得。对比结果,可以发现,本文提出的算法无论是在Delicious数据集上,还是Movielens数据集上,精确率、召回率及F1值均整体优于对比算法,证明了本文算法的优越性。
4 结束语
本文针对传统基于用户的资源模型没有考虑用户信任的不足,提出基于标签共现构建的用户信任网络模型,通过PageRank算法对资源模型进行了修正优化,充分将用户对资源的直接标注频率以及用户互信任信息相结合。进而基于修正优化后的资源模型,计算资源彼此的相似度,生成资源-资源完全二部图,并与资源-标签二部图合并,组成资源-资源-标签三部图。最终通过在三部图上执行物质扩散算法,得出最终结果。通过对比分析本文算法与对比算法在2大数据集上的基于精确率、召回率及F1值的表现,本文的算法较好地提升了推荐效果。下一步,将尝试基于用户信任网络,从用户社团划分及兴趣迁移等方面入手,更好地建立用户及资源模型,进一步提升推荐结果。
[1] Golbeck J. Computing and Applying Trust in Web-based Social Networks[D]. Park:University of Maryland, 2005.
[2] Massa P, Bhattacharjee B. Using trust in recommender systems: An experimental analysis[C]// International Conference on Trust Management. 2004:221-235.
[3] Kim H, Kim H J. Improving recommendation based on implicit trust relationships from tags[C]// Proceedings of the 2nd International Conference on Computers, Networks, Systems, and Industrial Applications. 2012:25-30.
[4] Bhuiyan T, Xu Yue, Josang A, et al. Developing trust networks based on user tagging information for recommendation making[C]// International Conference on Web Information Systems Engineering. 2010:357-364.
[5] Mustapha N, Voon W P, Sulaiman N.User recommendation algorithm in social tagging system based on hybrid user trust[J]. Journal of Computer Science, 2013,9(8):1008-1018.
[6] Golbeck J. Generating predictive movie recommendations from trust in social networks[C]// International Conference on Trust Management. 2006:93-104.
[7] Zhou Tao, Ren Jie, Medo M, et al. Bipartite network projection and personal recommendation[J]. Physical Review E: Statistical, Nonlinear, and Soft Matter Physics, 2007,76(4):70-80.
[8] 贾春晓. 基于复杂网络的推荐算法和合作行为研究[D]. 合肥:中国科学技术大学, 2011.
[9] Zhang Zike, Zhou Tao, Zhang Yicheng. Personalized recommendation via integrated diffusion on user-item-tag tripartite graphs[J]. Physica A: Statistical Mechanics and Its Applications, 2010,389(1):179-186.
[10] 张新猛,蒋盛益,张倩生,等. 基于用户偏好加权的混合网络推荐算法[J]. 山东大学学报(理学版), 2015,50(9):29-35
[11] Chen Guilin, Gao Tianruan, Zhu Xuzhen, et al. Personalized recommendation based on preferential bidirectional mass diffusion[J]. Physica A: Statistical Mechanics and Its Applications, 2017,469:397-404.
[12] Zhu Xuezhen, Tian Hui, Zhang Ping, et al. Personalized recommendation based on unbiased consistence[J]. EPL (Europhysics Letters), 2015,111(4):48007-1-48007-6.
[13] Zhou Tao, Jiang Luoluo, Su Riqi, et al. Effect of initial configuration on network-based recommendation[J]. EPL (Europhysics Letters), 2008,81(5):58004-1-58004-5.
[14] Sarwar B, Karypis G, Konstan J, et al. Item-based collaborative filtering recommendation algorithms[C]// Proceedings of the 10th International Conference on World Wide Web. 2001:285-295.
[15] Gemmell J, Schimoler T, Mobasher B, et al. Resource recommendation in social annotation systems: A linear-weighted hybrid approach[J]. Journal of Computer and System Sciences, 2012,78(4):1160-1174.
猜你喜欢
中老年保健(2022年5期)2022-11-25
中老年保健(2022年4期)2022-08-22
中学生数理化·中考版(2022年5期)2022-06-05
中学生数理化·中考版(2021年5期)2021-11-22
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
桃之夭夭B(2017年2期)2017-02-24
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
高中生·青春励志(2014年11期)2014-11-25
