
基于文本挖掘和自动分类的法院裁判决策支持系统设计
2018-03-09 01:33卫柯臻丁兰琳黎建强
中国管理科学 2018年1期
朱 青,卫柯臻,丁兰琳,黎建强
(1.陕西师范大学国际商学院,陕西 西安 710119;2.陕西师范大学交叉过程感知与控制实验室,陕西 西安 710119;3.香港城市大学管理科学系,中国 香港;4.西安交通大学管理学院,陕西 西安 710049;5.西安交通大学经济金融学院,陕西 西安 710049)
1 引言
在许多大陆法系的发展中国家,随着新型法律关系的不断产生,成文法无法及时制定和修改的缺陷逐渐显现,判例法的适当补充能够增加中国法律体系的灵活性。审判实践中长期积累的判例综合概括了各种各样的案例,为法律的适用提供了具体、生动的例子,这些判例和法律规范本身结合在一起,比抽象的立法条文更有助于加强法的权威和稳定[1]。所以,充分挖掘以往法院裁判文书的价值对中国法律体系的完善具有重要作用。而随着中国法院信息化建设的逐渐完善,裁判文书数据库为我们进行文本挖掘提供了可能。与此同时,世界各国纠纷诉讼的数目也在急剧增长,如何在保证审判质量的前提下提高法院系统的审判效率已经成为世界各国面临的问题。因此,在进行制度改革的同时,建立决策支持系统将会有效地辅助司法判决。本文提出的法院裁判决策支持系统(CJ-DSS)正是这方面的努力和尝试,其本质是文本的自动分类,该系统可以依据以往判例,预测医疗损害诉讼的判决结果,为司法判决和个人诉讼提供决策支持。
20世纪70年代以来,决策支持系统(Decision Support System)一直受到学术界的广泛关注,近年来,计算机在预测科学、复杂系统方面的技术进步和多学科的交叉发展促进了决策支持系统在不同领域的应用研究,大大提高了DSS的辅助决策能力。目前的研究中,DSS在医疗健康领域的研究较为热门,临床决策支持系统(CDSS,Clinical Decision Support System)已经在疾病诊疗上表现出较大的辅助优势[2-3],但也有学者认为CDSS在医疗实践中的应用还较为有限[4],尤其是医疗工作者通常难以理解计算机系统的内部运作。此外,在企业管理领域,DSS的应用也非常普遍,万映红等人[5]在虚拟合作伙伴的选择上进行DSS的设计。方淑芬和吕文元[6]则在设备维修管理方面采用DSS以期帮助设备管理人员进行科学决策。总之,当前DSS的设计思想已经在各个领域广泛应用。
对于本文提出的CJ-DSS而言,文本自动分类技术是系统设计的核心。相较于中国而言,国外对文本自动分类的实际应用研究比较丰富,尤其是对专利文本的分析。Tseng等[7]认为,专利文本中包含许多重要的研究成果,然而其篇幅和专业术语使得对专利文本的分析需要耗费较多时间和精力。Kim等[8]也认为,随着专利文本的日益增多,自动分类系统能够取代手动分类。同时,他强调专利文本较之其他文本而言,具有一些结构化信息,比如主张(Claims)、目的(Purposes)、发明实例(Embodiments of invention)等,而这一特点应当在分类过程中受到关注。因此,Kim利用专利文本的这一特点,先对上述结构化信息进行聚类筛选出语义元素(Semantic elements),以此作为文本分类的基本特征,然后使用k-NN(k-Nearest Neighbour)方法进行分类。实验发现,相对于未使用结构化信息的系统而言,分类效果提升了74%。
此外,文本分类技术还应用于其他领域。Pong等[9]通过实证研究表明,KNN算法是构建有效率的文本分类系统,从而增强当前的图书馆情报学实践的重要手段之一。Fang Ruihua等[10]使用支持向量机(SVM)技术设计出能够对实验数据的类型进行识别并分类的系统。余乐安和汪寿阳[11]在对信用问题分析后构造了基于核主元分析的带可变惩罚因子模糊支持向量机模型来进行信用分类研究,研究结果表明该方法对于二元分类问题的分类效果和适用性都较好。Coussement和 Poel[12]使用E-mail中的语义特征作为指标,结合传统的文本分类方法,设计出一个能够区分投诉和非投诉类的自动邮件分类系统,该系统能够达到83%的准确率。梁昕露和李美娟[13]认为传统的投诉分类体系过于繁杂且缺乏逻辑,因此从业务维度和生命周期维度对投诉数据进行二次分类,采用SVM算法对样本训练后进行预测,查准率超过七成。Al Qady和Kandil[14]则依据文本内容对项目文件进行了自动分类,并在不同的条件下(如维数水平(Dimensionality level)和赋权方法(Weighting method)测试了分类器的性能。该研究发现,准确率最高的分类器是应用降维技术和TF-IDF赋权法的Rocchio和kNN分类器,其次,使用投票策略将分类器结合也能够提高分类器的性能。
尽管近年来,决策支持系统和文本自动分类技术在许多领域都得到广泛的应用,但其在司法领域的应用并没有受到太多关注。一方面是由于大陆法系依据法典进行判决,另一方面则是受制于数据的难以获得和文本的分析技术。但随着司法模式的综合使用以及数据库和文本挖掘技术的建立和发展,法院裁判决策支持系统(CJ-DSS)不仅可以提高司法判决系统的效率,而且能够增强以往法院判例的参考价值。具体而言,随着中国法律实践中判例的大量积累,自动分类技术能够从中挖掘出有价值的信息来辅助司法判决,有效地在保证审判质量的前提下提高法院系统的审判效率。
2 研究方法
2.1 文本预处理
2.1.1 中文分词与初步特征降维
鉴于中文与英文文本的差异性,分词方法各有不同。本文使用R软件中的Rwordseg包作为分词工具。该程序包是由李舰提出,是一个R环境下的中文分词工具,使用rjava调用java分词工具Ansj。Ansj是基于中科院的ICTCLAS中文分词算法,采用隐马尔科夫模型(Hidden Markov Model, HMM)。现有中文分词主要采用字典匹配法,通过添加专业词汇,可以使Rwordseg的灵活性和识别度更高。本文通过加载sougou细胞库中的法律词汇、法律文本词汇以及医学词汇字典,能够识别判决书中的专业术语,避免未识别词汇的干扰。
进行初步降维时,首先需要删除中文停用词,如“我”“你”“的”等无意义词汇。进一步通过词性标注,选取名词、动词以及专业词汇等具有更高价值的词汇,减少无意义词条干扰性,以备后阶段使用。
2.1.2 文档表示模型与词条权重
对文本内容的特征表示主要有布尔模型、向量空间模型、概率模型和基于知识的表示模型,在文本分类领域,最常用的文本表示模型是向量空间模型[15]。向量空间模型是是Salton等[16]于70年代提出的。其基本思想是:给定一文本D=D(T1,W1;T2,W2;…;Tn,Wn),其中Ti(i=1,2,…,n)表示文档中的词条,且互不相同,Wi(i=1,2,…,n)代表词条对应的数值。可以把T1,T2,…,Tn看作是一个n维的坐标,而W1,W2,…,Wn是n维坐标所对应的值,从而文档D就可被看作一个n维的向量。
为了获得更高的精准度,本文使用向量空间模型。向量空间模型本质上能够将文档转化为电子表格形式,电子表格的每一列关联一个特征,每一行代表一个文档,词条权重是指某词条在某篇文档中出现的频率。词条权重通常使用0(该词条未出现)和1(该词条出现)填充。为了获得更好的精度,词条权重还有其他的表示方法。比如使用词条出现的实际频率或三值系统(0(未出现)、1(出现一次)、2(出现1次以上))。目前在研究中最为常用的是TF-IDF权值,它是一个由词条重要性比例因子来修正的词频,这个比例因子称为反文档频率(IDF)[17]。而后Salton等[18]提出了TF-IDF的权值计算公式:
tf-idf(j)=tf(j)×idf(j)
(1)
其中,tf(j)表示词条j的实际频率,N表示全部文档,df(j)表示出现词条j的文档数。
2.2 特征提取
用向量空间模型表示文本时, 该向量的维数非常大, 能够达到几十万维, 而一般只选择2%-5%的特征项[19]。本研究面临的困难是特征空间的高维性和文档表示向量的稀疏性。近年来在中文文本自动分类中使用较多的特征抽取方法包括文档频率DF[20]、互信息MI、信息增益IG[21]和卡方(chi-square)检验。代六玲等[22]比较研究了在中文文本分类中特征选取方法对分类效果的影响,结果表明,在英文文本分类中表现良好的特征抽取方法(IG、MI和CHI)在不加修正的情况下并不适合中文文本分类。他认为除了加大训练集外,还可以通过组合的特征抽取方法来进行改善。因此本文将使用DF、CHI统计法以及DF-CHI组合,分别进行特征提取。其基本思想如下:
(1)DF(Document Frequency)是指语料库中出现某词条的文档数目,它是最简单的特征抽取技术。DF通过设定阈值可以剔除低频词,筛选出出现某词条的文档数目大于该阈值的词条作为分类特征,其基本假设是低频词对于预测贡献度较低,对分类效果无显著影响。因此将低频词剔除能够降低特征维数,有可能提高分类精度。
(2)CHI统计的原理是通过观察实际值与理论值的偏差来确定理论的正确与否,在进行特征选择时,可以用来度量特征t和类标c之间的相关程度,并假设t和c之间符合具有一阶自由度的χ2分布。原假设为特征t和类标c不相关,χ2统计值越高,该词条与该类别的相关性越大,对预测结果也更有价值。CHI统计是一种依赖分类类别的特征提取方法,对低频词有所倚重,即存在“低频词缺陷”。其计算公式如下:
(2)
其中N表示训练语料中的文档总数,c表示某一特定类别,t表示特定词条,A表示属于c且包含t的文档频数,B表示不属于c类但包含t的文档频数,C表示属于c类但不包含t的文档频数,D是既不属于c也不包含t的文档频数。
(3)组合特征提取法是指依据不同特征选择算法的优劣,将两种及以上的算法组合后对文本特征进行筛选,以期找到对分类结果更有价值和更有预测性的特征。DF-CHI组合特征提取法是由于DF和CHI统计本身对低频词的基本思想不同,我们认为在无法证实哪种基本假设更合理时,可以将两种方法结合,即先用DF滤去出现次数较低的词条,然后在此基础上通过CHI筛选出与分类结果更为相关的特征集。这种方法能够通过组合互补,提取出带有更多分类信息的词条,理论上能够提升分类器的性能表现。
2.3 分类技术
2.3.1 支持向量机(SVM)
SVM由Vapnik[23]在2000年提出,是一种相对较新的机器学习技术,近年已被广泛地用于模式识别的多个领域[24],同时,该算法对文本分类问题也是非常快捷有效的。在几何方面,一个二值SVM分类器可以看作是特征空间超平面,分别代表正反例。分类超平面是两类边界间隔最大的平分平面[25]。通过学习算法,SVM在训练样本中寻找具有最好区分能力的样本点集,称为支持向量(Support Vectors)。在分类阶段,SVM利用这些支持向量对未知类别样本的类别属性做出预测[26]。SVM分类器与特征空间的维数无关,因此在理论上能合理解决过拟合问题。
2.3.2 人工神经网络(ANN)
人工神经网络(Artificial Neural Network)是在1943 年由神经生物学家MeCulloch和青年数学家 Pitts 合作提出的。ANN分类器可采用一种三层前馈型网络,包括输入层、输出层和隐含层。网络的输入节点接收特征值,输出节点产生类别值,连接权重代表依赖关系。神经网络可以通过反向传播训练修正分类错误,从而提高准确性。ANN具有广泛的系统自净化性,因此可以实现模糊推理功能,同时,在大量数据负载的情况下能够保持较高的运算速度[27]。
2.3.3 最近邻法(KNN)
k最近邻法(k-Nearest Neighbor)[28]是一种传统的模式识别方法,在搜索引擎中的应用最为常见,同时也被广泛的应用于文本自动分类研究[8-9,14],在准确率和召回率上表现出众。KNN通过计算新文档与已知类别的文档集中所有文档的相似度,选择k个和新文档最相似的文档,在这k个文档中频率最高的标签就是该文档的分类标签。
2.4 评价标准
为评价不同特征选择方法和分类器的性能,本文采用最通用的性能评价方法:召回率R(Recall)、准确率P(Precision)和F1评价。对于某一特定的类别,召回率定义为被正确分类的文档数和被测试文档总数的比率,即该类样本被分类器正确识别的概率。准确率定义为正确分类的文档数与被分类器识别为该类的文档数的比率,即分类器做出的决策是正确的概率[29]。F1的计算公式如下:
(3)
2.5 集成学习模型
通过不同特征提取方法和分类器的组合使用,我们能够找到多组达到我们预期性能的组合。但是面对新案例时,使用哪个组合能够保证分类结果的可靠性?如何将不同组合的判断结合起来?每个组合的预测结果应当赋予多大权重?本文以德尔菲法为理论基础,采用集成学习来解决这一问题。集成学习是指通过构建一个新模型,经过适当训练后,将达到预期性能的基学习器的预测结果作为输入,经过线性或非线性运算后最终输出一个概率最大的预测结果。集成学习相对单一模型而言,除了能够节省单一最佳模型的时间,在性能上也更具有普适性[29]。
假设通过预期性能的基学习器有n个,表示为Di(wherei=1,2,…,n),其预测的类别用Ti表示,其中Ti∈{0,1},我们可以将n个基学习器对某一文本的预测值Ti作为输入,其可能的分类结果作为输出,构建B-P神经网络来确定每个基学习器的权重Wi,从而构成自动判决系统的集成学习模型,对未标注类别的文本进行预测。集成学习模型如图1所示。
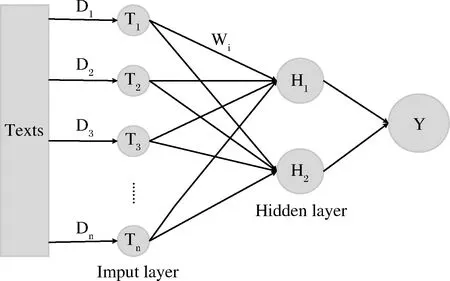
图1 集成学习模型
3 系统整体设计
根据第二部分的研究方法,本文所尝试构建的法院裁判决策支持系统(CJ-DSS)的整体设计如图2所示。
该系统主要分为两个部分,第一部分以非结构化文本作为输入,经过预处理后形成结构化的词条文档矩阵,然后通过更换特征提取方法和分类器,筛选出达到预期性能的基学习器,同时输出基学习器的判决结果;第二部分则将基学习器对测试集文本的分类结果作为输入,通过集成学习后,输出对测试集文本的最终判决。
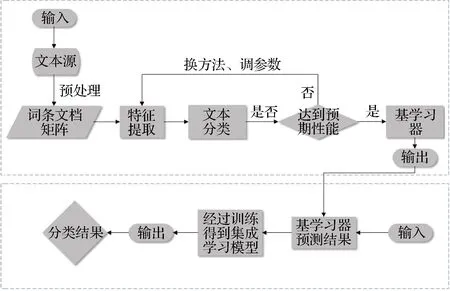
图2 CJ-DSS系统整体设计
4 实证分析与结果
4.1 数据来源及数据结构
本文的数据来源为北大英华提供的“北大法宝”大型法律数据库,本文以“医疗纠纷”为关键词检索出2013年法院判决书及调解书等文本共300余篇,由于调解书的文本格式较短,且案情叙述略简,故从中删除调解书文本。其余文本经过预处理后进行训练和测试。本文用于实验的数据共计220篇。其中,用于选择基学习器的训练集共100篇,用于BP神经网络模型训练的文档共计60篇,其余60篇作为测试集。为了便于集成学习模型和单一模型的性能比较,测试集新文本数据保持不变。
对于训练集中驳回类和非驳回类的结构问题,经过统计2011-2013年中国法律医疗损害判例中驳回与非驳回两类文本的经验分布,发现驳回与非驳回类文本所占比例均在1:4附近。在实验中我们分别以1:1和1:4的训练集数据比例进行了测试,结果发现1:1的数据结构下各分类器的性能均低于1:4比例下的性能,因此我们认为符合实际经验分布的数据比例更能够保证分类效果。故我们将训练集中驳回类与非驳回类的分布比例均设为1:4。由于分类器对新文本进行分类是单独进行的,故测试集中新文本的结构比例不会影响分类结果。数据结构具体如表1所示。

表1 实验文本数据量及构成
4.2 单一特征提取法和组合特征提取法的自动判决结果
通过对DF和CHI调整参数,我们筛选出不同条件下的特征集并据此进行分类,文章在各参数的定义域内挑选出部分进行试验。为了行文简洁同时便于理解,此处我们将对下文出现的符号进行具体说明。见表2。

表2 符号表示及说明
4.2.1 单一卡方法的自动判决结果
图3显示了三个分类器在不同卡方值下的性能表现。随着卡方值的增大,能够通过相关性检验的词条数目越来越少,由于支持向量机依赖支持向量进行快速分类,所以对特征的维数不是特别敏感,因此保持了较为稳定的变化趋势。人工神经网络的性能则随着特征值的减少产生了较大波动。K近邻表现较差,在0.700左右波动,对特征值的数量不敏感。
4.2.2 单一DF法与DF-CHI组合法的自动判决结果
为了更加直观地表示单一法和DF-CHI组合法自动判决结果的差异,我们将DF参数以下列方式改写坐标,以单一DF法和SVM的组合为例,以D0作X轴,D1作Y轴,F1值作Z轴,如表3所示。
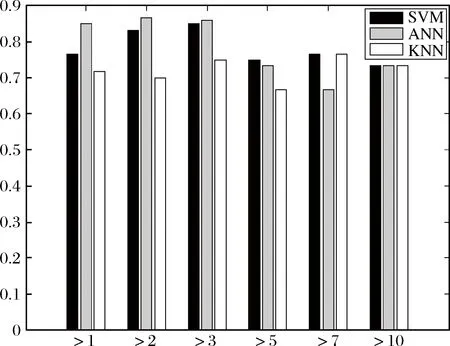
图3 不同卡方值参数下的分类器性能
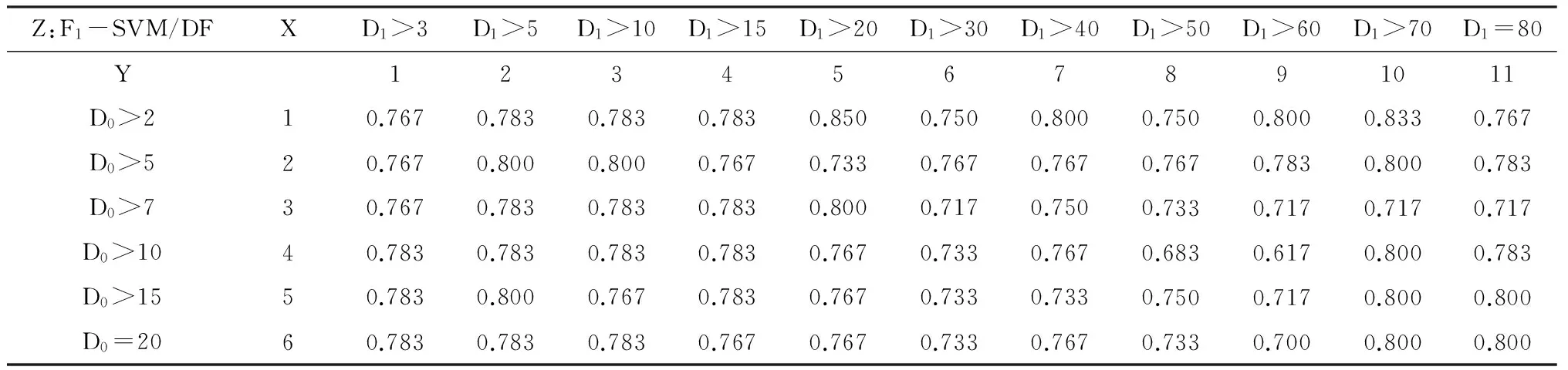
Z:F1-SVM/DFXD1>3D1>5D1>10D1>15D1>20D1>30D1>40D1>50D1>60D1>70D1=80Y1234567891011D0>210.7670.7830.7830.7830.8500.7500.8000.7500.8000.8330.767D0>520.7670.8000.8000.7670.7330.7670.7670.7670.7830.8000.783D0>730.7670.7830.7830.7830.8000.7170.7500.7330.7170.7170.717D0>1040.7830.7830.7830.7830.7670.7330.7670.6830.6170.8000.783D0>1550.7830.8000.7670.7830.7670.7330.7330.7500.7170.8000.800D0=2060.7830.7830.7830.7670.7670.7330.7670.7330.7000.8000.800
下列三组图4-1、4-2、4-3分别是SVM、ANN、KNN分类器的性能表现,红色代表单一DF法,绿色代表DF-CHI组合法。如图所示,针对不同的分类器,DF-CHI组合法对分类结果的性能均有改善(否则俯视图将全为红色),但其改进的程度有所不同:SVM改进程度达到45%左右,ANN改进程度达到80%,KNN改进程度在40%左右。

图4-1 SVM(DF) 和SVM(DF-CHI)的三维图和俯视图
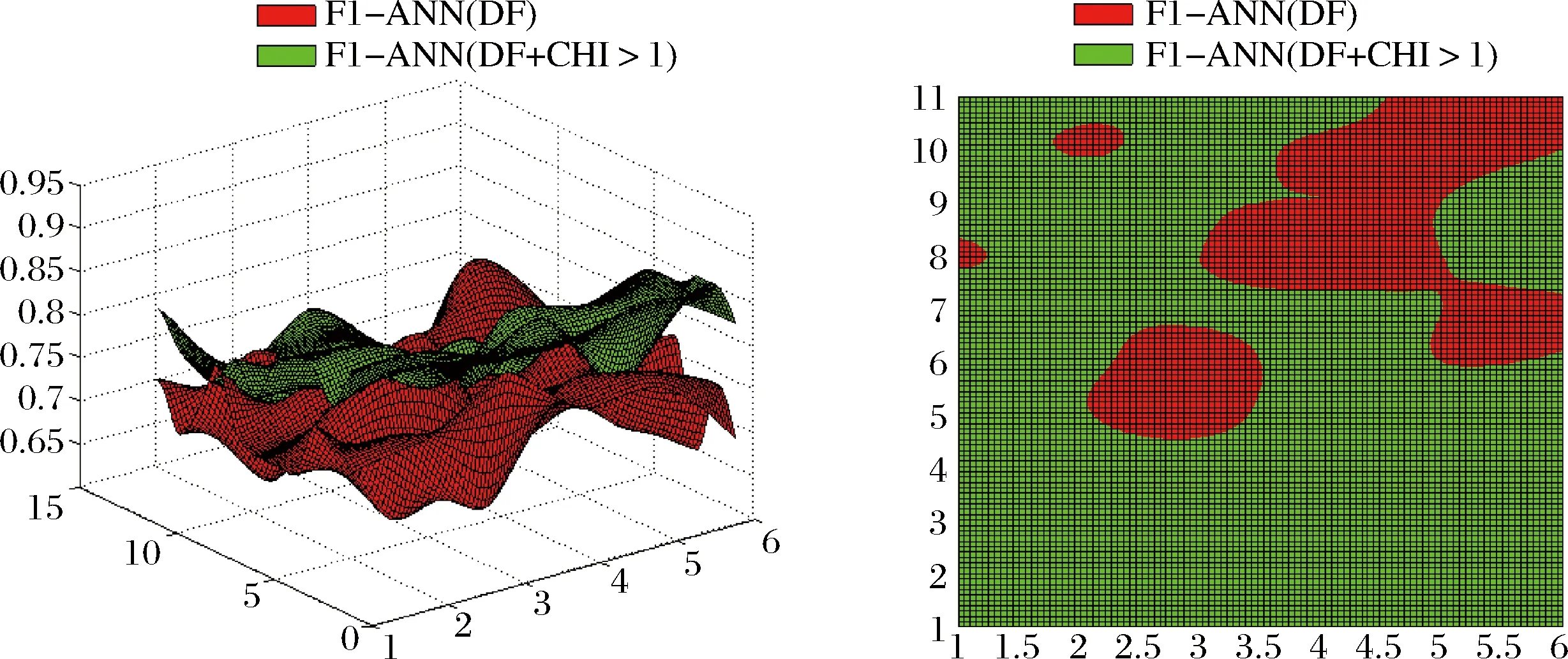
图4-2 ANN(DF) 和 ANN (DF-CHI) 的三维图和俯视图
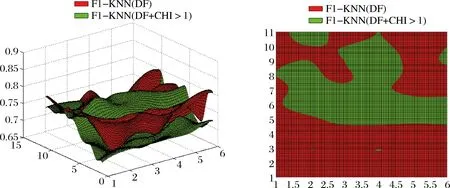
图4-3 KNN(DF) 和 KNN(DF-CHI)的三维图和俯视图
4.3 B-P神经网络的集成学习
通过组合特征提取法我们不同程度的提高了各分类器的性能,以此增加了满足预期分类效果的基学习器的个数。我们设定预期的分类器性能为F1> 0.850,根据上述结果,我们选出以下符合预期性能的组合作为基学习器。表4显示了经过实验调参后筛选出的分类器性能F1>0.850的全部组合,这构成本文的多个基学习器,具体见表4。
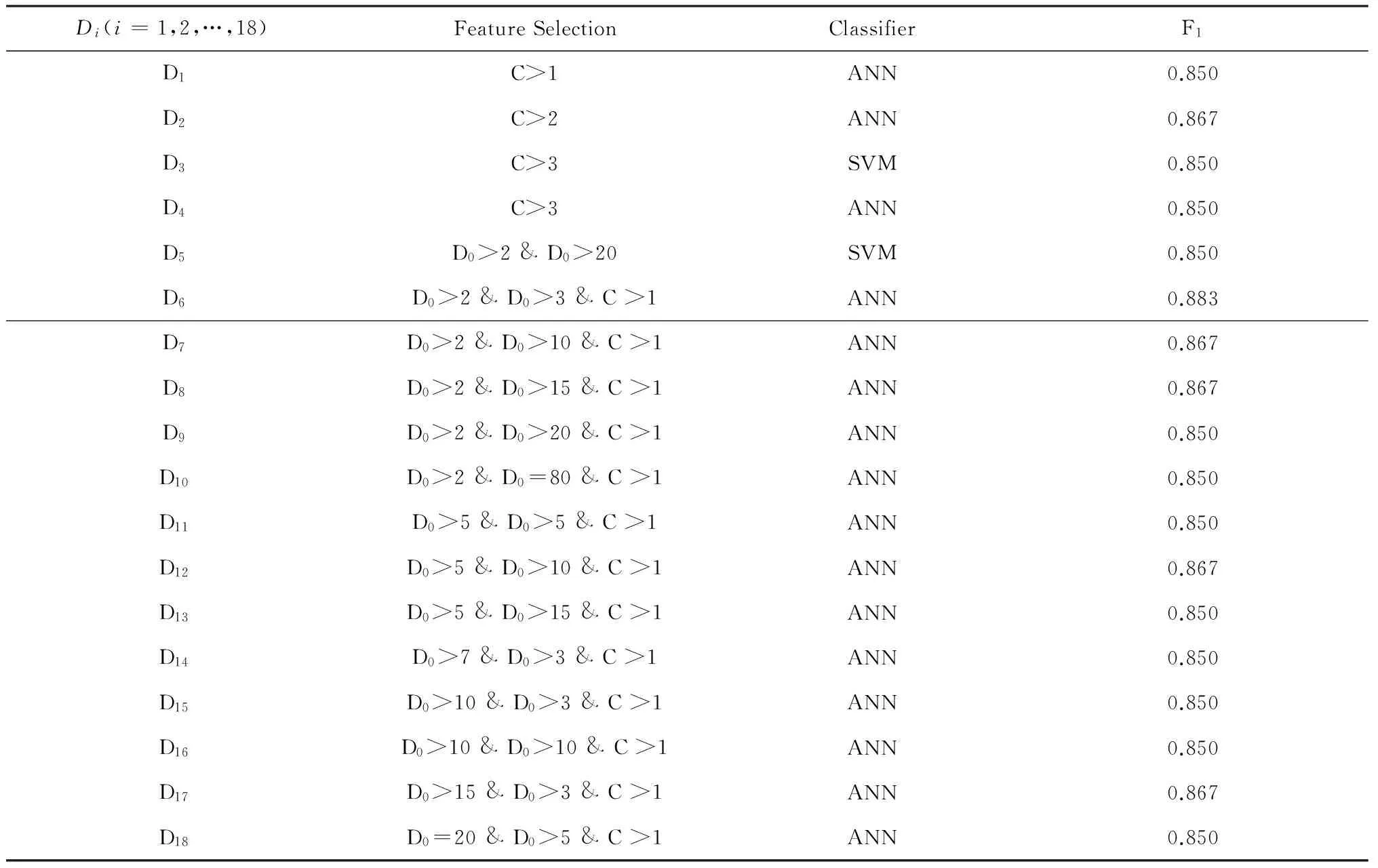
表4 基学习器具体构成
注:根据训练集中驳回与非驳回类的文本数量,DF(Type=0)的值在[1,20]区间内, DF(Type=1)的值在[1,80]区间内,同时两者的值都为整数。
依据2.5中B-P神经网络模型,将18个基学习器对测试集的预测结果作为输入,驳回(0)和非驳回(1)作为输出,采用多种BP网络结构(改变隐含层的神经元数),经过反复多次凑试,经过1000次迭代后达到平稳,其中学习率为0.1,隐含层神经元个数为5,该集成学习模型的预测结果见表5,混淆矩阵如下:

表5 混淆矩阵
由此可得F1值达到93.3%,有效提升了系统的性能。拟合图表示真实的判例类别(黑线)和预测类别(红线)之间的误差,如图5可见拟合效果较好。
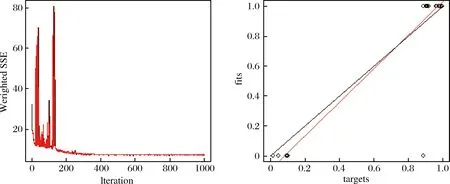
图5 迭代结果及拟合图
5 结语
本文以中国医疗纠纷诉讼判决文本为例,使用文本挖掘和自动分类技术提出了一个法院裁判决策支持系统(CJ-DSS),该系统可以预测新诉讼文本的判决结果:驳回与非驳回。我们通过组合不同的特征选择方法和分类器建立模型,然后使用F1值评价其性能,同时,为了提高系统的实际应用能力,使用组合特征提取法提高分类性能,并使用集成学习综合多个分类器的判决结果提高系统的稳定性,从而构建适合中国法院诉讼文本的CJ-DSS。
同时,结合案例,本文研究发现,组合特征提取法确实能够改进和提高分类器的分类性能,而且针对SVM、ANN、KNN三种不同的分类器,DF-CHI组合特征提取法对性能的改进程度有所差异:SVM改进程度达到45%左右,ANN改进程度达到80%,KNN改进程度在40%左右。除此之外,集成学习后该系统的分类性能更加稳定,性能最优达到93.3%,有效改进了系统准确性。
在以往的研究中,通常文本分类系统的准确性受到训练集规模的较大影响,训练集数据越多,往往性能越好。本文依据较小规模的文本集实现了较高性能的CJ-DSS系统设计,对未来小样本训练集构建高性能系统有一定的借鉴意义,对其研究也应继续深入。同时,在实际操作中,由于标注文本的过程耗费成本,对未标注文本的学习建模将是数据科学家们下一步的研究方向。
[1] 董茂云. 法典法,判例法与中国的法典化道路[J]. 比较法研究, 1997, 11(4):1-31.
[2] Prevedello L M, Raja A S, Ip I K, et al. Does clinical decision support reduce unwarranted variation in yield of CT pulmonary angiogram?[J]. American Journal of Medicine, 2013, 126(11):975-81.
[3] Park S H, Rha S W, Byun J S, et al. Performance evaluation of the machine learning algorithms used in inference mechanism of a medical decision support system.[J]. The Scientific World Journal,2014,2014(7):137896-137896.
[4] O'Sullivan D, Fraccaro P, Carson E, et al. Decision time for clinical decision support systems.[J]. Clinical Medicine, 2014, 14(4):338-41.
[5] 万映红, 李江, 李怀祖. 虚拟合作的伙伴选择智能决策支持系统框架研究[J]. 系统工程理论与实践, 2001, 21(12):60-65.
[6] 方淑芬, 吕文元. 设备维修管理智能决策支持系统的研究[J]. 系统工程理论与实践, 2001, 21(12):53-59.
[7] Tseng Y H, Lin C J, Lin Y I. Text mining techniques for patent analysis[J]. Information Processing & Management, 2007, 43(5):1216-1247.
[8] Kim J H, Choi K S. Patent document categorization based on semantic structural information[J]. Information Processing & Management An International Journal, 2007, 43(5):1200-1215.
[9] Pong Y H, Kwok C W, Lau Y K, et al. A comparative study of two automatic document classification methods in a library setting[J]. Journal of Information Science, 2008, 34(2):213-230.
[10] Fang Ruihua, Schindelman G, Auken K V, et al. Automatic categorization of diverse experimental information in the bioscience literature[J]. Bmc Bioinformatics, 2012, 13:1-12.
[11] 余乐安,汪寿阳. 基于核主元分析的带可变惩罚因子最小二乘模糊支持向量机模型及其在信用分类中的应用[J]. 系统科学与数学,2009,29(10):1311-1326.
[12] Coussement K, Poel D V D. Improving customer complaint management by automatic email classification using linguistic style features as predictors[J]. Decision Support Systems, 2008, 44(4):870-882.
[13] 梁昕露,李美娟. 电信业投诉分类方法及其应用研究[J]. 中国管理科学,2015,23(S1):188-192.
[14] Al Qady M, Kandil A. Automatic classification of project documents on the basis of text content[J]. American Society of Civil Engineers, 2015,29(3):04014043.
[15] 周茜, 赵明生, 扈旻. 中文文本分类中的特征选择研究[J]. 中文信息学报, 2004, 18(3):17-23.
[16] Salton G, Yang C, S A Wang A. A vector space model for automatic indexing. Communications of the ACM, 1975,18(11):613-620.
[17] Rocchio J J. Relevance feedback in information retrieval[M]//Salton G, The SMART retrieval system: Experiments in automatic document processing. Englewood cliffs, NJ: Practice-Hall,1971.
[18] Salton G, Buckley C. Term weighting approaches in automatic text retrieval[J]. Information Processing and Management, 1988,(5):24,513-523.
[19] 赵燕平,李超.网络安全信息挖掘中的特征选择与专利分析研究[J].中国管理科学,2004, 12(S1):514-518.
[20] Yang Yiming, Pedersen J O. A comparative study on feature selection in text categorization[C]//Proceedings of the 14th International Conference on Machine Learning San,Fransisco, July 08-12,1997.
[21] Lee C, Lee G G. Information gain and divergence-based feature selection for machine learning-based text categorization[J].Information Processing and Management,2006,42(1):155-165.
[22] 代六玲,黄河燕,陈肇雄. 中文文本分类中特征抽取方法的比较研究[J]. 中文信息学报, 2004, 18(1):26-32.
[23] Vapnik V. The nature of statistical learning theory[M]. Berlin Springer, 2000.
[24] Burges C J C. A tutorial on support vector machines for pattern recognition[J]. Data Mining and Knowledge Discovery,1998,2(2):121-167.
[25] 程显毅. 文本挖掘原理[M]. 北京:科学出版社, 2010.
[26] B Lantz. Machine learning with R[M]. Bejjing:China Machine Press,2015.
[27] 刘钢, 胡四泉, 范植华,等. 神经网络在文本分类上的一种应用[J]. 计算机工程与应用, 2003, (36):73-74.
[28] Dasarathy B V. Nearest neighbor (NN) norms: NN pattern classification techniques[M]. Los Alamitos: IEEE Computer Society Press, 1990.
[29] Weiss S M, Indurkhya,Zhang Tong. Fundamentals of predictive text mining[M]. Berlin:Springer,2012.
猜你喜欢
计算机系统应用(2021年2期)2021-02-23
电脑知识与技术·经验技巧(2020年3期)2020-05-07
电子技术与软件工程(2019年18期)2019-11-18
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
电子技术与软件工程(2017年14期)2017-09-08
航天返回与遥感(2014年5期)2014-07-31
