
TUOD遮挡图像库的设计与实现
2018-02-23 02:26刘宸昊马惠敏
图学学报 2018年6期
高 磊,刘宸昊,马惠敏
TUOD遮挡图像库的设计与实现
高 磊,刘宸昊,马惠敏
(清华大学电子工程系,北京 100084)
遮挡问题是复杂场景图像中一个普遍存在的现象,探索遮挡对图像认知的影响规律、建立具有抗遮挡能力的认知模型直接关系到计算机视觉技术的实际应用,是一个迫切需要解决的科学问题。通过研究复杂场景图像中的遮挡问题,探索遮挡对图像认知的影响规律,建立一个评估检测识别算法的抗遮挡能力、研究图像认知模型及抗遮挡规律的TUOD (Tsinghua University Occlusion Database)遮挡图像库。首先,根据遮挡对图像识别的影响,提出遮挡部件、遮挡面积、遮挡关系、遮挡复杂度4个维度的图像遮挡属性,建立了图像遮挡程度量化标准;其次,基于遮挡维度提出一个新的层次化图像库组织结构,以此为基础进行数据库构建。从PASCAL VOC和ImageNet中进行图像筛选和处理,构建了一个包括飞机、车辆、人、动物4大类,共2 100张图片的TUOD遮挡图像库。利用TUOD图像库,结合机器学习理论,通过实验比较分析不同遮挡维度对Faster R-CNN算法的影响。实验表明,TUOD遮挡图像库能够为算法的抗遮挡能力提供量化评估标准。TUOD遮挡图像库的建立为提高抗遮挡算法的性能奠定了基础,具有实用性。
遮挡维度;遮挡规律;抗遮挡能力评估;遮挡图像库
遮挡作为复杂场景图像中一个普遍存在的现象,对图像识别率影响很大,是面对各种复杂情况的自动驾驶视觉导航、公共安全视频监控等实际应用无法回避的核心问题,是计算机视觉、模式识别、目标识别与跟踪等研究领域的重点和难点[1-2]。但因图像中的遮挡具有复杂语义,缺少对遮挡元素进行量化分析的相关研究,本文通过遮挡认知理论分析,建立一个能够量化评估图像认知模型及算法抗遮挡性能的遮挡图像库,提供有效的数据和评价标准,在视觉导航、视频监控、医疗诊断、工业产品检测等方面有着重要的实用价值和广阔的发展前景。
在实际场景中遮挡现象不可避免,情况也千差万别,随着深度学习等检测、识别方法的提出,计算机视觉在简单图像、理想测试场景中的目标检测与识别上得到了很大的突破,国际上研究工作也开始转向复杂图像等更难的实际应用场景。为了满足计算机视觉的发展,尤其是图像分割、目标检测识别方法的研究需要,先后出现了一些国际评测平台:2005年欧盟建立了PASCAL (pattern analysis,statistical modelling and computational learning)数据集[3],开启了VOC(visual object classes)挑战;2010年斯坦福大学建立了当时世界上最大的ImageNet图像库[4],为相关图像研究提供数据源和国际评测平台,其中的图像基本上都是辨识度很高的简单图像;2014年微软推出了图像复杂度很高的COCO (common objects in context)图像数据集[5],其中大量场景非常复杂,存在严重的目标聚集和遮挡现象;另外还有自动驾驶KITTI库[6]、加州理工学院的Caltech行人数据库[7],虽有涉及到物体识别和遮挡图像,但仅将数据库根据遮挡情况简单分为无遮挡、部分遮挡、严重遮挡,未能对遮挡现象给出量化评估标准,缺乏对抗遮挡检测、识别方法的支撑。
1 遮挡认知理论分析
图像库的建设是很多研究中非常重要的一个环节,但是现有的图像库缺乏对遮挡的量化描述,通常仅以类似图1的形式根据遮挡面积对图像物体的复杂度进行分级(例如:简单、中等、困难)。然而,遮挡对图像识别的影响的要素很多,仅以遮挡面积进行衡量是不完备的。例如,被遮挡的部件、自遮挡或互遮挡关系、是否相似遮挡等要素对物体识别都会带来不同程度的影响。已有一些研究通常对某种特定的遮挡要素进行分析,但缺乏全面的系统的规律挖掘。

图1 飞机的几种简单遮挡类型
研究发现,遮挡区域的大小以及物体关键部件是否被遮挡是影响识别的重要因素,现有研究针对特定种类的识别对象进行了讨论,研究了遮挡不同部件对识别性能的影响。例如,WRIGHT等[8]发现,在对人脸器官如鼻子、嘴、眼睛的人工遮挡时,人脸的识别率不同,其重要性排序为:眼睛>嘴>鼻子。EKENEL和STIEFELHAGEN[9]从关键特征遮挡方面介绍了一种基于局部纹理识别的人脸识别算法,对预先存在遮挡的一组图片进行对比测试,发现戴墨镜人脸的识别率远低于围围巾人脸的识别率。然而,这些研究大都针对结构规则的特定类别,难以推广到一般物体。
从以上特定类别的规则物体的研究可以看出,影响物体识别的遮挡要素非常多,且耦合性很强。具体而言,有以下几点关键要素:
(1) 遮挡不同部件对物体识别的影响通常不同;
(2) 同一部件被遮挡面积大小对物体识别的影响也不同;
(3) 遮挡物与被遮挡物之间的关系(是否自遮挡、是否相似)会对物体识别带来影响;
(4) 图像信息复杂难度会对识别跟踪带来影响。
此外,不同识别算法对同一遮挡情况的敏感度也不同。现有的遮挡识别研究缺乏规则的、一致的和系统的分析。很多已有研究对遮挡的关键部件的选择很大程度上依赖于人的主观决定,容易出现遗漏。另外,已有研究通常只针对特定算法进行遮挡评估,缺乏一般性的对比分析。
因此,为了优化抗遮挡算法,需要对遮挡影响物体识别性能的规律进行系统的研究。本文建立了一个用于评估检测识别算法抗遮挡能力、研究图像认知抗遮挡规律及模型的遮挡图像库。此图像库可以通过仿真平台完成对算法性能的分析和评估。在建库时,采用层次模型系统,以遮挡的分类为依据,既覆盖了典型遮挡,又保证了图像库的结构化和可扩展性。
2 图像库的设计与构建
2.1 图像入库原则
对于采集到的图像需要经过严格的评定标准,以保证其适用于仿真平台上对追踪算法的验证,主要有以下几个方面的要求:
(1) 对应单一遮挡,由于图像库的作用是分析检测识别算法的抗遮挡性能,提出遮挡图像认知模型评估方法,因此图像应明确和突出所存在的遮挡,不宜包含多种遮挡,以避免对评估结果造成不良影响;
(2) 保证图像库的适用性,所采集得到的图像应当可以应用于对任何的算法的评估,同时应保证加入的遮挡相对典型和具有说服力;
(3) 应保证遮挡图片数量,有足够的图像包含遮挡,以减小对算法的评估结果的随机性,增强结果的有效性。
符合标准的图像即可入库,可以用来检测算法对相应遮挡的抗干扰性能。
建库体系流程主要部分为图像分类、采集图片、遮挡属性定义、遮挡图片标注和图像入库5个部分,整个的图像建库流程如图2所示。
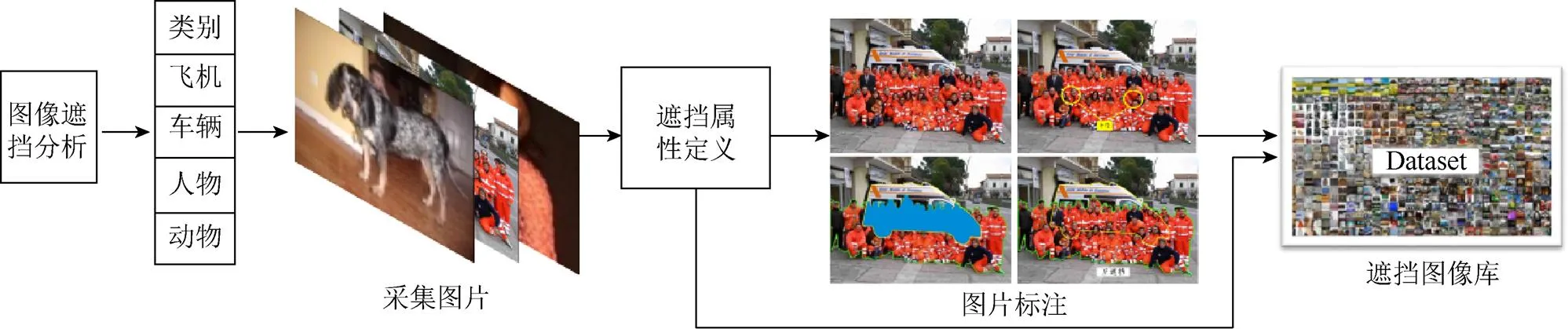
图2 图像建库流程
依据上述原则,本文选取带有遮挡的目标图像,采用Labelme[10]工具对图像分别按照遮挡部件、遮挡面积、遮挡关系和遮挡复杂度4个遮挡描述维度进行标注,生成XML文件,建立遮挡图像集合。其中,部件指目标元素具有的典型特征,如对于“车”这个类别,关键部件包含车头、车灯、车轮、车窗等;遮挡面积根据在遮挡规律研究中学习得到的阈值划分成若干级,如<20%、20%~50%、51%~70%、>70%;遮挡关系分为同类/不同类物体之间的遮挡、自遮挡/互遮挡等;遮挡复杂度描述了人在认知遮挡图像时的眼动行为特征。最后,将集合映射到树形分类结构中,在每个遮挡维度中添加对应的带有遮挡的图像,形成TUOD图像库,结构如图3所示。本文构建的遮挡图像库与现有的图像库的对比见表1。
2.2 遮挡元素标注
2.2.1 遮挡部件的标注
由于不同部件的遮挡情况对物体识别有着不同程度的影响,本文需要建立部件级别的数据标注,标出遮挡物体各个部件是否被遮挡以及部件被遮挡的比例,在物体部件标注中,需要对物体按部件进行划分,并进行像素级的标注。在此基础上本文根据部件的缺失程度、部件的遮挡类型对图像进行分类,和已有的部件分割数据集相比,强调了被遮挡部件的标注。按照图像内容对遮挡物体与被遮挡物体进行分类,并将类别进行编号,以便入库,之后再对入库图片进行粗分类和细分类:粗分类指将图像中被遮挡物体与遮挡物体按种类分组;细分类指将被遮挡部分按照遮挡部位进行分组。如图4所示:图片中救护车被人群遮挡,标注“车轮”为遮挡部位。
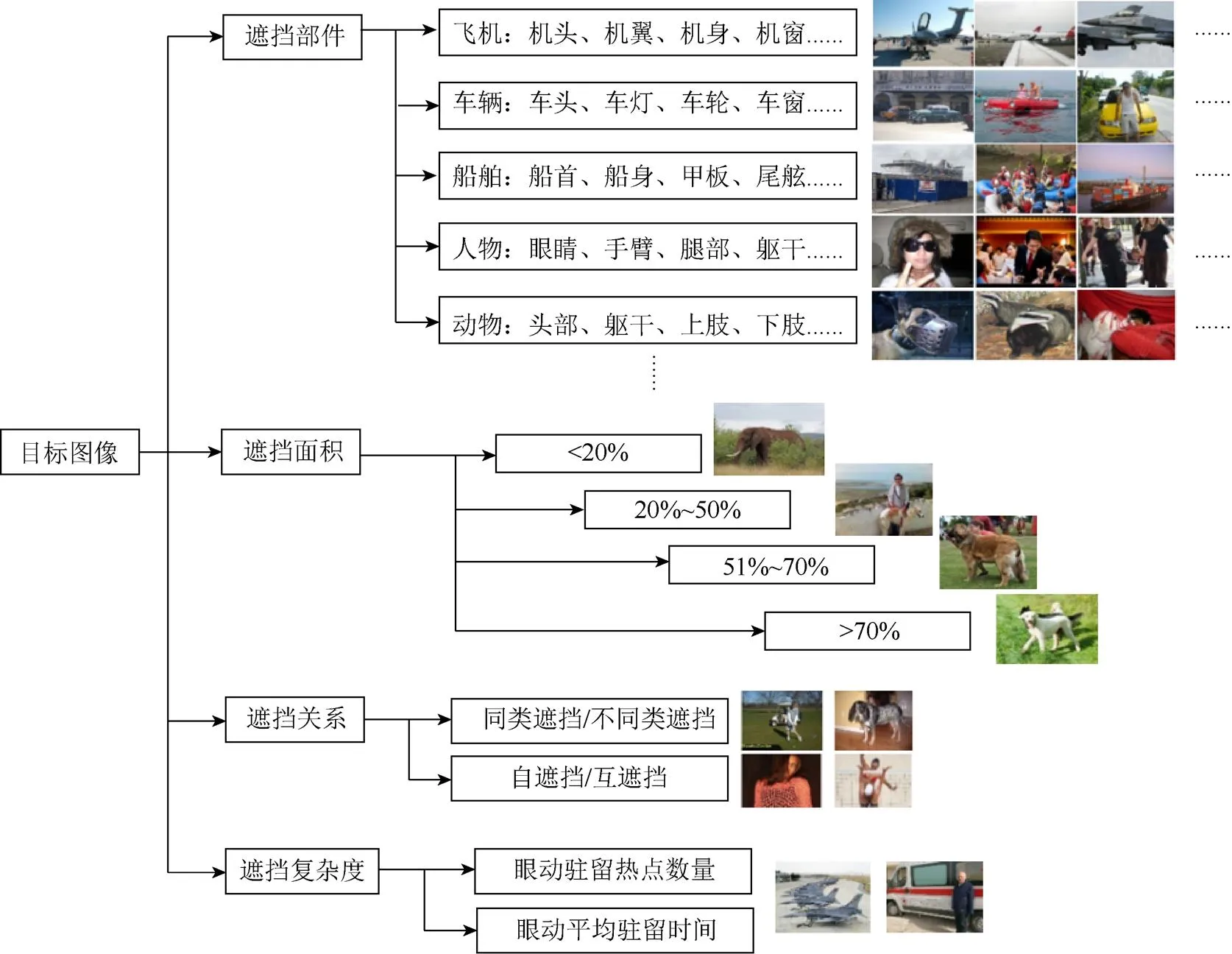
图3 图像库结构
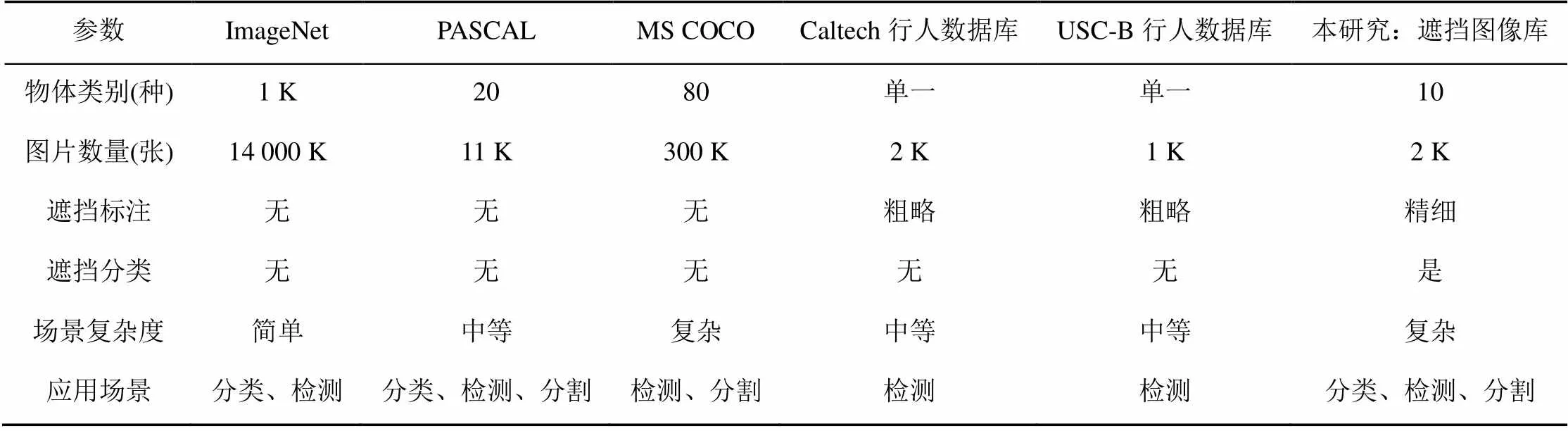
表1 图像库特征比较

图4 遮挡部件标注
2.2.2 遮挡面积的标注
遮挡面积的计算必须基于遮挡物体与被遮挡物体的轮廓的提取,本文在像素级部件标注的基础上,研究中采用人工物体补全的方式,进行遮挡标注,从而计算出遮挡面积比例。物体补全方法是通过人工绘出遮挡物和被遮挡部分的轮廓,恢复物体整体形状信息,计算遮挡面积,如图5所示,对遮挡物(人群)和被遮挡物(救护车)进行标注,重合部分(蓝色)为被遮挡物的遮挡面积。计算公式为
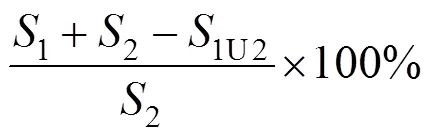
其中,1为遮挡物(人)面积;2为被遮挡物(车辆)面积;1U2为整体面积。计算得到不同遮挡面积比例的图像实例如图6所示。
图5 物体补全方法

图6 遮挡面积图像示例
2.2.3 遮挡关系的标注
已有研究表明,物体间纹理相似性的差异对通用算法的抗遮挡能力有很大影响,根据遮挡物体与被遮挡物体是否为同一类物体分为同类物体遮挡与非同类物体遮挡;根据遮挡物体与被遮挡物体是否为同一物体分为自遮挡(目标物体自身的一部分遮挡了的另一部分)与互遮挡(两个不同物体之间存在遮挡)。在此基础上,本文研究标注了更细致的图像中遮挡物体之间的关系。遮挡关系标注的实例如图7所示。

图7 遮挡关系标注
2.2.4 遮挡复杂度
眼动仪用于记录人在处理视觉信息时的眼动轨迹特征,广泛用于注意、视知觉、阅读等领域的研究。本文利用眼动仪结合视线焦点检测技术定义遮挡复杂度,通过对观察者眼动轨迹的分析可得到观察者注视点序列,描绘注视点轨迹的方法如下:
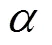
心理护理与健康教育可以让患者的心理状态得到有效的改善,不仅是提升手术治疗效果的关键,同时也是疾病转归的关键[3-4]。根据患者的心理情绪给予心理疏导,每天和患者进行交流与沟通并及时为患者讲解疾病相关的知识以及临床治疗措施、必要性以及疗效等,从而有效的减轻心理顾虑,为患者预后健康生活提供有效的帮助和支持[5]。

图8 驻留热点图和注视轨迹图
3 遮挡对识别算法的影响实验分析
本文建立的TUOD图像库旨在提供适用于研究图像识别、图像检测[11-15]、图像分割[16]等计算机视觉任务中的遮挡问题的平台。为了进一步说明的TUOD的实用性,本文就物体识别与检测任务进行了以下实验:①采用不同物体检测算法进行对比实验分析;②采用控制变量的方法对不同遮挡条件下的物体识别性能进行评估分析。
3.1 不同物体检测算法性能比较
本文选用了传统的DPM anti occlusion capability[17]算法和深度学习中的基于Caffe[18]的VGG-16[19]网络两种不同的物体检测算法对TUOD图像库进行了实验。对实验结果的物体检测准确率进行了分析,结果见表2。根据数据标注,计算待检测物体被遮挡的面积比例,作为描述图像中存在遮挡情况的描述要素,按照遮挡比例<20%、20%~50%、>50%对图像进行分类。
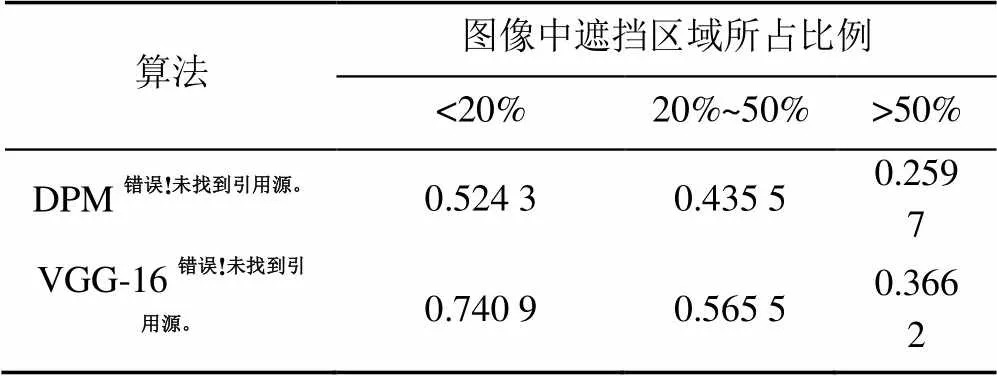
表2 不同物体检测算法性能比较
由实验结果可以看出,在本文TUOD图像库上可以实现对不同算法在不同遮挡程度条件下的检测性能的比较。除本文依照遮挡比例上述划定方法外,使用者还可以自行选取阈值进行划分,或利用本文的像素级标注设计针对遮挡问题的划分方式。
3.2 不同遮挡条件下物体识别性能评估分析
本文采用控制变量的方法对不同物体检测模型在遮挡面积和几何关系加权的遮挡面积两种不同遮挡条件下的物体识别性能进行评估分析,以验证本数据库对于遮挡图片分类量化的准确性。实验步骤如下:
步骤1.利用主流算法,对库中图像进行目标识别,并判断识别结果;
步骤2.对遮挡图像进行相应的遮挡强度(如遮挡面积、遮挡复杂度等)计算;
本文采用基于Caffe的VGG-16网络,利用网络在PASCAL VOC2012数据集上的预训练模型,对本数据库中的图像中的人、动物以及车辆目标进行识别,得到相应物体的检测框(bounding box)。进一步将识别结果与物体框标注进行比较,计算其交并比,并设定交并比>0.7作为正确识别的阈值。
本文对图像库进行了物体识别算法实验,得到约400个物体检测框。在此检测的基础上,本文按照图像中遮挡比例<20%、20%~50%、>50%划分,统计物体检测准确率,检测准确率随遮挡程度的变化如图9所示。
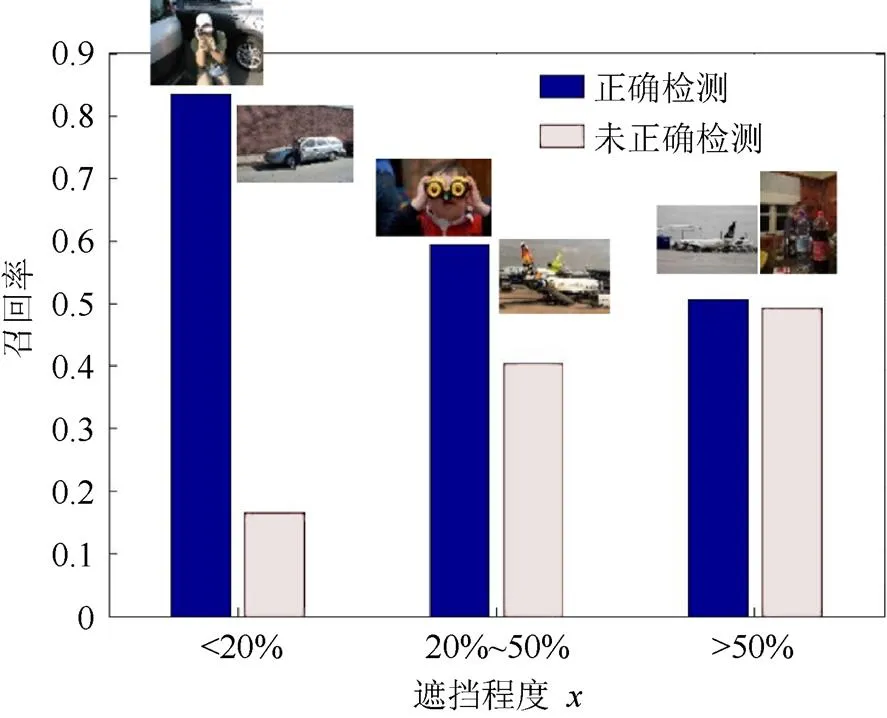
图9 VGG-16物体识别效果随遮挡面积比例的变化情况
在此基础上,本文研究进一步提出了基于几何位置的遮挡特征描述方法,对图片像素按照其在物体多边形中的几何位置进行加权,加权方法为:
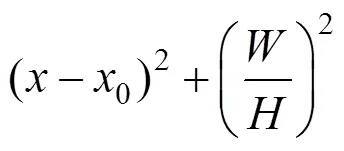
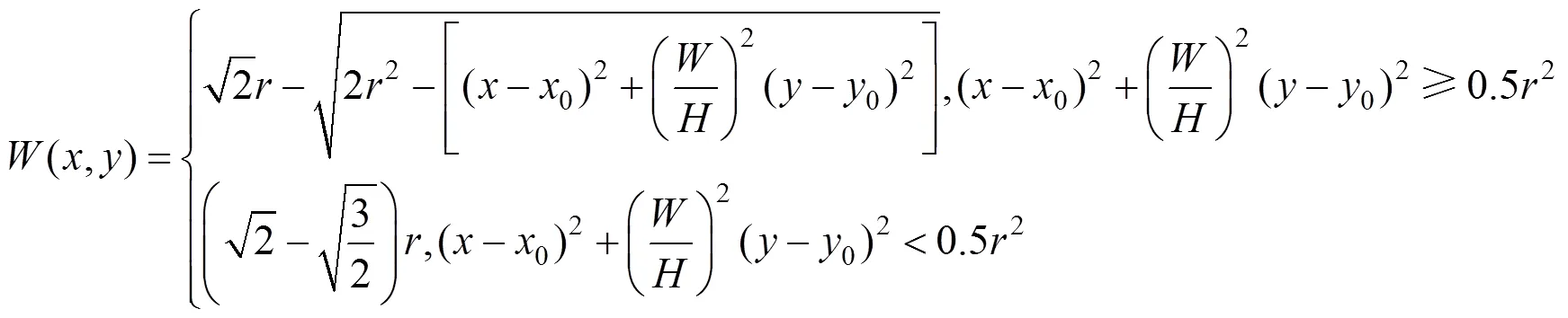
进行加权;
(2) 利用边缘和角点检测子矩阵对标注多边形边缘的二值图进行卷积,以强化物体边缘。此外,绝大多数物体的上部都对物体识别具有相对更显著的影响,因此,本文对上述两个权值矩阵再按照从上到下的位置进行加权,然后求和得到按几何位置加权的遮挡程度,加权图像的示例如图10所示。对于加权遮挡比例按照0.2、0.4分为不同子集,检测分析的结果如图11所示。

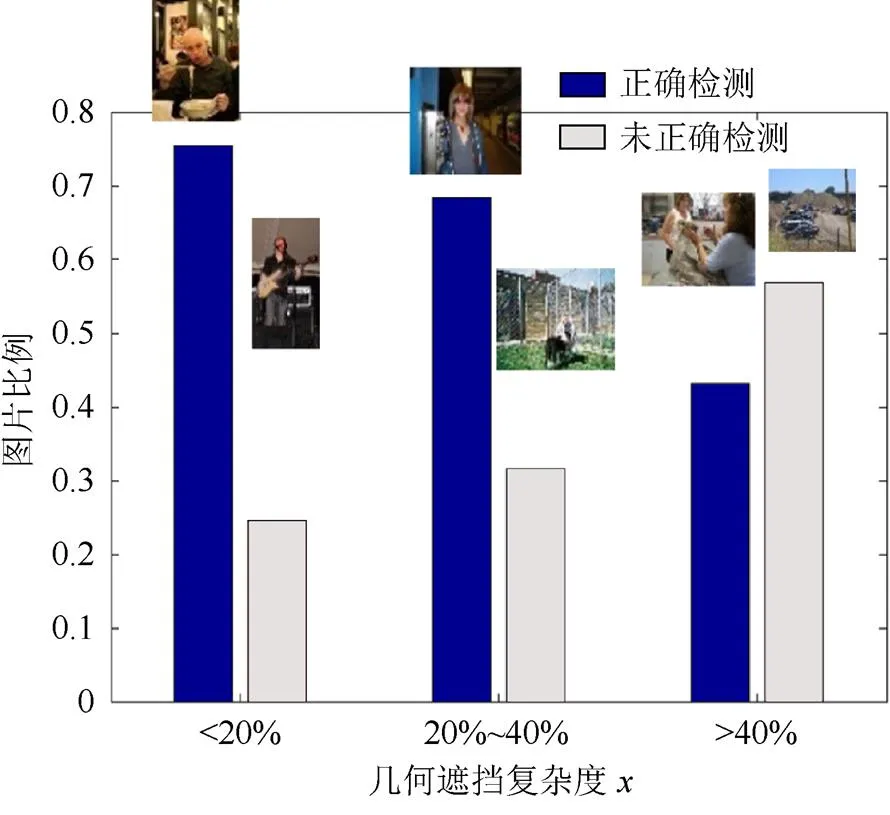
图11 VGG-16物体识别效果随加权遮挡面积比例的变化情况
由实验分析验证,被检测的VGG-16算法的识别性能随标注的遮挡程度呈现显著变化,遮挡程度越强,算法的识别效果越差;此外,在不同的遮挡要素下,算法性能的变化趋势存在明显区别,例如,从图12可观察到,在相似遮挡面积下,引入几何位置加权的遮挡面积计算可以有效地突出轮廓缺失及撕裂性遮挡对物体识别的影响。以上两点表明,本文研究建立的遮挡图像库可以为算法抗遮挡性能的评估提供量化实验的平台。
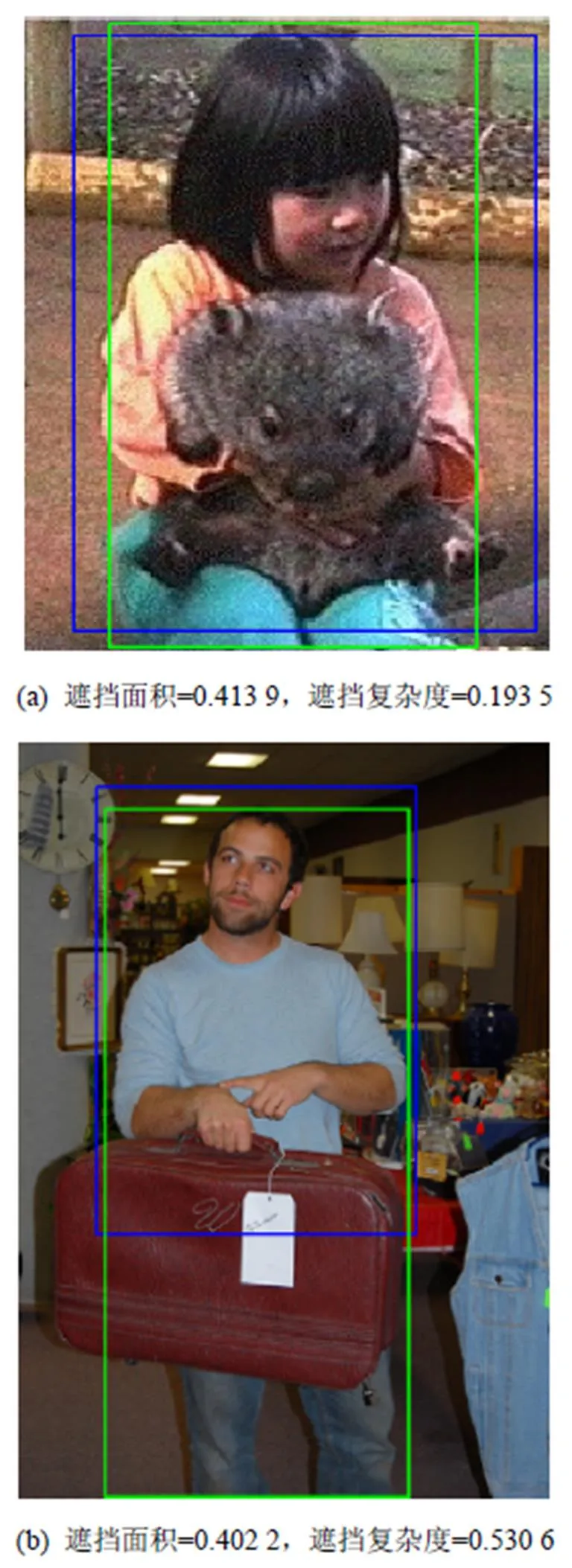
图12 相似遮挡面积下不同遮挡复杂度造成识别性能衰减
4 结 论
本文提出了基于遮挡维度描述的方法,对遮挡元素进行标注,建立了TUOD遮挡图像库。图像库采用层状结构,以遮挡的分类为依据,使图像库的结构严谨又不乏灵活性,便于探索遮挡因素影响物体识别检测算法的规律。TUOD图像库体现出了针对性和完整性,克服了以往图像库中遮挡分类与标注不详细、缺乏量化的不足,保证了图像库的弹性和容量,使得图像库的图片易于处理和检索,具有更普遍的适用意义。相比较之下,本遮挡图像库:①建立了针对遮挡的图像难度函数模型和图像遮挡程度量化标准;②创新性的定义了4个遮挡维度,提出遮挡图像库的组织结构,标注遮挡属性;③对VGG-16算法的抗遮挡性能进行分析,为抗遮挡算法的优化和改进奠定了基础。
本文希望通过构建含有遮挡的图像库,以达到评估算法性能的目标,从而进一步针对性地优化识别检测算法,以克服目前目标识别检测过程中所面临的种种困难,研究遮挡对图像认知的影响规律,为复杂场景中的目标检测、识别应用提供抗遮挡图像认知模型和算法,为计算机视觉提供新的理论和方法。
[1] 高艳霞. 基于Gabor+ PCA特征与粒子群算法的部分遮挡人耳识别研究[J]. 图学学报, 2014, 35(1): 100-104.
[2] 罗月童, 朱会国, 韩娟, 等. 遮挡线索增强的最大密度投影算法[J]. 图学学报, 2014 , 35(3): 343-349.
[3] EVERINGHAM M, ESLAMI S M A, VAN GOOL L, et al. The pascal visual object classes challenge: a retrospective [J]. International Journal of Computer Vision, 2015, 111(1): 98-136.
[4] DENG J, DONG W, SOCHER R, et al. Imagenet: a large-scale hierarchical image database [C]//2009 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2009: 248-255.
[5] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft coco: common objects in context [M]//Computer Vision–ECCV 2014. Berlin: Springer, 2014: 740-755.
[6] GEIGER A, LENZ P, STILLER C, et al. Vision meets robotics: the KITTI dataset [J]. The International Journal of Robotics Research, 2013, 32(11): 1231-1237.
[7] WU T F, LI B, ZHU S C. Learning and-or model to represent context and occlusion for car detection and viewpoint estimation [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(9): 1829-1843.
[8] WRIGHT J, YANG A Y, GANESH A, et al. Robust face recognition via sparse representation [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(2): 210-227.
[9] EKENEL H K, STIEFELHAGEN R. Why is facial occlusion a challenging problem? [M]//Advances in Biometrics. Berlin: Springer, 2009: 299-308.
[10] RUSSELL B C, TORRALBA A, MURPHY K P, et al. LabelMe: a database and web-based tool for image annotation. International Journal of Computer Vision, 2008, 77(1-3): 157-173.
[11] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2014: 580-587.
[12] GIIRSHIEK R. Fast r-cnn [C]//Proceedings of the IEEE International Conference on Computer Vision. New York: IEEE Press, 2015: 1440-1448.
[13] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[14] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]//European Conference on Computer Vision. Berlin: Springer, 2016: 21-37.
[15] WANG X, MA H, CHEN X. Geodesic weighted Bayesian model for saliency optimization [J]. Pattern Recognition Letters, 2016, 75(c): 1-8.
[16] WANG X, MA H M, CHEN X Z, et al. Edge preserving and multi-scale contextual neural network for salient object detection [J]. IEEE Transactions on Image Processing, 2018, 27(1): 121-134.
[17] FELZENSZWALB P, MCALLESTER D, RAMANAN D. A discriminatively trained, multiscale, deformable part model [C]//2008 IEEE Conference on Computer Vision and Pattern Recognition, New York: IEEE Press, 2008: 1-8.
[18] JIA Y Q, SHELHAMER E, DONAHUE J, et al. Caffe: convolutional architecture for fast feature embedding [C]//Proceedings of the 22nd ACM international conference on Multimedia. New York: ACM Press, 2014: 675-678.
[19] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL]. [2018-03-02]. https://x-algo. cn/wp-content/uploads/2017/01/VERY-DEEP-CONVOLUTIONAL-NETWORK-SFOR-LARGE-SCALE-IMAGE-RECOGNITION.pdf.
Design and Implementation of Tsinghua University Occlusion Image Database
GAO Lei, LIU Chenhao, MA Huimin
(Department of Electronic Engineering, Tsinghua University, Beijing 100084, China)
Occlusion is a common phenomenon in images characteristic of complex scenes. Discovering the pattern of how occlusion affects image cognition and establishing a cognition model insusceptible to occlusion is closely related to the utilization of computer vision technologies, and it is also an important and pressing scientific problem to be solved. By analyzing occlusion in complex scenes and how occlusion affects image cognition, this paper established the Tsinghua University Occlusion Image Database for evaluating the anti-occlusion performance of algorithms and studying image cognition model. Firstly, based on occlusion’s impact on image cognition, this paper proposed a 4-dimension occlusion attribute including occluded part, occluded area, occlusion relationship and occlusion complexity, as well as a quantification standard for the extent of occlusion. Then we proposed a novel hierarchical dataset structure, based on which the database could be constructed. This paper established TUOD database which consists of 2 100 images extracted from PASCAL VOC and Image Net databases. Those images covered 4 major object types: aeroplane, car, person and animal. An experiment was conducted to analyze the influence of each dimension of occlusion attribute on the performance of Faster R-CNN using images in TUOD. As is shown in the aforementioned experiment, TUOD database can provide quantitative criteria for the anti-occlusion performance of algorithms and thus it is highly practical and lays the foundation for improving the anti-occlusion performance of object recognition algorithms in complex scenes.
influence of occlusion classification; assessment of anti occlusion capability; assessment of anti occlusion capability; occlusion image database
TP391.4
10.11996/JG.j.2095-302X.2018061084
A
2095-302X(2018)06-1084-08
2017-05-04;
2017-05-09
国家重点研发计划项目(2016YFB0100900);自然科学基金项目(61171113)
高 磊(1984-),男,河北邯郸人,硕士研究生。主要研究方向为图像识别。E-mail:leigaogl@126.com
马惠敏(1972-),女,河南洛阳人,副教授,博士。主要研究方向为图像识别。E-mail:mhmpub@tsinghua.edu.cn
猜你喜欢
小学生学习指导(高年级)(2022年5期)2022-06-02
数学小灵通·3-4年级(2021年5期)2022-01-01
中学生数理化·中考版(2021年8期)2021-07-31
装备制造技术(2020年4期)2020-12-25
汽车维修与保养(2020年11期)2020-06-09
中学生数理化·高一版(2020年1期)2020-02-20
制造技术与机床(2019年7期)2019-07-22
中学生数理化·八年级物理人教版(2018年10期)2018-12-06
中学生数理化·七年级数学人教版(2018年4期)2018-06-28
科普童话·百科探秘(2015年4期)2015-05-14
