
基于注意力机制的多尺度融合航拍影像语义分割
2018-02-23 02:26郑顾平
图学学报 2018年6期
郑顾平,王 敏,李 刚
基于注意力机制的多尺度融合航拍影像语义分割
郑顾平,王 敏,李 刚
(华北电力大学控制与计算机工程学院,河北 保定 071003)
航拍影像同一场景不同对象尺度差异较大,采用单一尺度的分割往往无法达到最佳的分类效果。为解决这一问题,提出一种基于注意力机制的多尺度融合模型。首先,利用不同采样率的扩张卷积提取航拍影像的多个尺度特征;然后,在多尺度融合阶段引入注意力机制,使模型能够自动聚焦于合适的尺度,并为所有尺度及每个位置像素分别赋予权重;最后,将加权融合后的特征图上采样到原图大小,对航拍影像的每个像素进行语义标注。实验结果表明,与传统的FCN、DeepLab语义分割模型及其他航拍影像分割模型相比,基于注意力机制的多尺度融合模型不仅具有更高的分割精度,而且可以通过对各尺度特征对应权重图的可视化,分析不同尺度及位置像素的重要性。
语义分割;多尺度融合;注意力机制;卷积神经网络
图像语义分割(semantic segmentation)又称为图像标注或场景解析[1],其目标是为图像中的每个区域或像素分配对应的语义类别,将其分割为视觉上有意义或者感兴趣的区域。随着深度学习的发展,SHELHAMER等[2]提出全卷积神经网络(fully convolutional networks,FCN),现已成为图像语义分割的基础模型,为了实现端到端的分割,FCN去掉了VGG16[3]末端的全连接层,随后的SegNet[4]、U-Net[5]等语义分割模型也均采用了此策略。近年来随着遥感领域的发展,航拍影像的像素级语义分割受到众多研究人员重视,基于各种语义分割模型的分割方法[6-7]被提出。但因航拍影像同一场景中不同对象尺度差异较大,如沿海城市场景中海洋的尺度远大于建筑、道路等对象的尺度,因此,如何为不同尺度对象针对性地选择合适的分割尺度以及选取适当的策略进行尺度融合,仍然是航拍影像语义分割急需解决的问题。
许多研究人员通过提取多尺度特征的思路得到对象的不同尺度,以处理分割尺度的选择问题。多尺度特征的提取通常使用两种结构来实现:①网络跳接(skip-net)[8-9]结构,该结构通过结合中间卷积层的特征实现不同尺度特征的提取,但由于尺度特征来源受限,存在无法任意选择合适尺度的局限性。②网络共享(share-net)[10-11]结构,该结构通过将原图像调节为不同的尺度并各自输入一个共享的深度网络来提取多样的尺度特征,但增加了模型计算量,同时也耗费了更大的存储空间。CHEN等[12]提出了多孔空间金字塔池化(atrous spatial Pyramid pooling,ASPP)结构,将不同采样率的多个并行的扩张卷积分别视为不同的尺度,避免了上述两种方法的缺陷,但其尺度提取十分依赖采样率的选择。
另一方面,语义分割模型目前常用的多尺度特征融合方法为平均池化(average pooling)[13]和最大池化(max pooling)[14]。但平均池化在特征融合时视每个尺度及位置像素同等重要,并未考虑不同的尺度特征对场景中各尺度对象的影响;最大池化在各尺度中选择了最大的激活值作为融合结果,但对于特征图每个位置的尺度选取过于绝对且对场景尺度的理解仍然停留在像素层面。近年来,注意力机制(attention mechanism,AM)凭借其能够聚焦于具有丰富信息的显著区域的特性[15],越来越多地被应用到图像分割任务中。然而,传统的视觉显著模型如基于认知模型[16]、基于图论模型[17]以及基于频域分析模型[18]等,大多都采用自底向上的注意力机制而仅受数据的驱动[19],因而无法满足深度神经网络自顶向下的基于任务驱动的要求。而深度学习中的AM,更多是将其引入到特征的空间或时间维度,针对特征的尺度维度的应用则鲜有涉及。
针对以上问题,本文在FCN模型的基础上,提出了一种基于AM的多尺度融合语义分割模型,实现对航拍影像端到端的分割。在尺度特征提取阶段,对ASPP结构进行改进,结合多采样率同层卷积(multi-rate same layer convolution,MRSLC)方式在某一尺度上同时用多个采样率的扩张卷积提取特征,增加了模型的鲁棒性;在多尺度特征融合阶段,将AM引入特征的尺度维度,使得模型自适应地为同一场景中不同对象选择合适的分割尺度,并能够对场景尺度的理解上升到对象层面。实验结果表明,该模型在一定程度上提高了分割准确率和鲁棒性。此外,AM的引入提供了可供分析的可视化权重图,直观展现了网络模型中每个尺度和位置像素的重要性。
1 基于注意力机制的多尺度融合语义分割模型
本文的语义分割模型整体框架如图1所示。
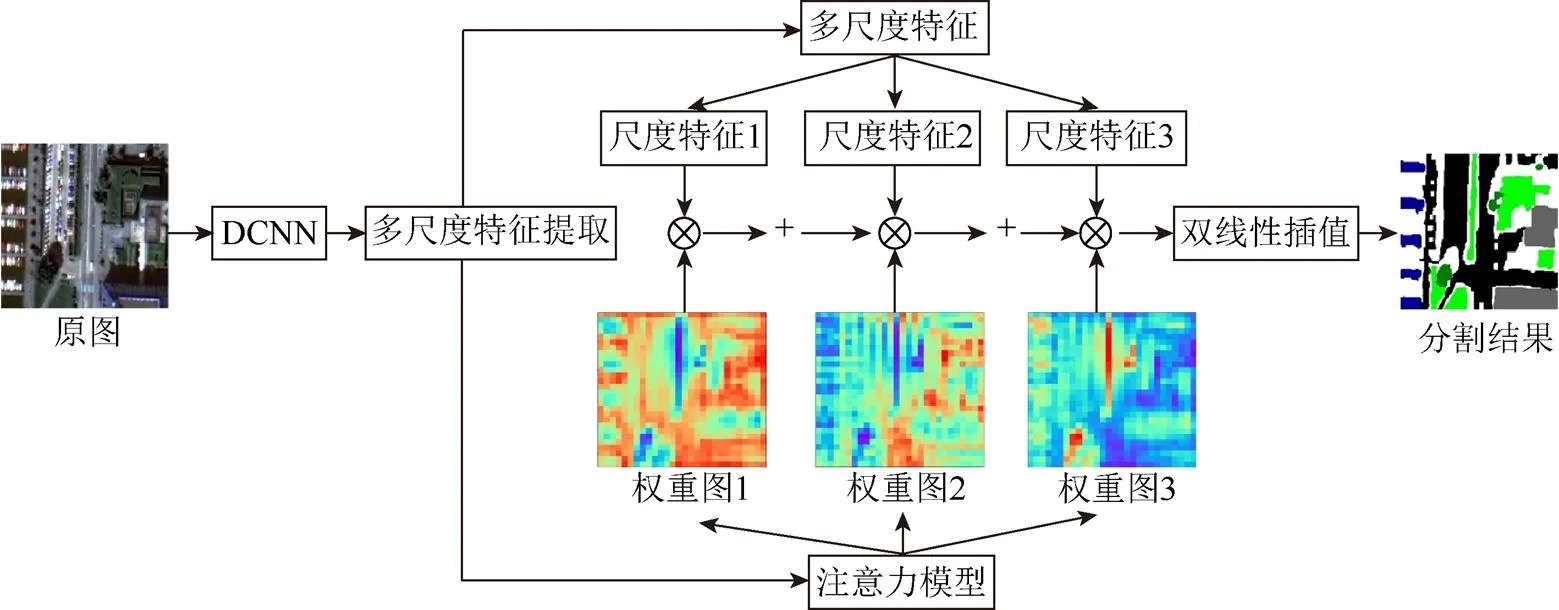
图1 基于注意力机制的多尺度融合分割模型整体框架
(1) 将待分割航拍影像经过深度卷积神经网络(deep convolutional neural network,DCNN)提取影像的高层全局性特征。
(2) 对影像的高层特征进行多尺度特征的提取,生成多个不同的尺度特征。
(3) 同时将多尺度特征提取的卷积结果作为注意力模型的输入,得到分别对应于每个尺度特征的权重图。
(4) 对所有尺度特征加权求和并在双线性插值之后对每个像素进行分类,得到与原图像尺寸相同的最终的语义分割结果。
(5) 采用反向传播算法训练模型,利用端到端的方式微调整个模型参数。
1.1 DCNN的构建
1.1.1 DCNN结构
高分辨率特征图能够更好地保留原图中丰富的细节信息,且允许模型采用速度更快的双线性插值方法进行上采样。因此,为了得到更为密集的航拍影像高分辨率特征图,本文的DCNN网络基于VGG16深度神经网络建立模型框架,并在网络结构上作了两方面的改变,如图2所示。

图2 DCNN网络结构
(1) DCNN网络移除了VGG16中最后两个池化层pool4和pool5,使得最后一层特征图的尺寸由原图大小的1/32增至1/8,有效地增加了高层特征图分辨率。
(2) 移除pool4、pool5之后,DCNN网络在conv5卷积层中使用采样率为2的扩张卷积代替原来的传统卷积方式,在不损失特征图分辨率以及不增加更多训练参数的情况下,增大了特征图中每个像素的感受野。
虽然最后两个池化层的移除导致特征图像素的感受野不能随原VGG16网络继续成倍增加,但由于扩张卷积能够随着其采样率的线性增加使得特征图感受野呈指数型增长,得以直接代替原网络中的池化操作而不影响原网络参数的传递。
1.1.2 DCNN构建方法
DCNN网络的输入为3通道的彩色航拍影像,输出为512通道的高分辨率特征图。网络中间层特征图的构建如下:
(1) 卷积层特征图
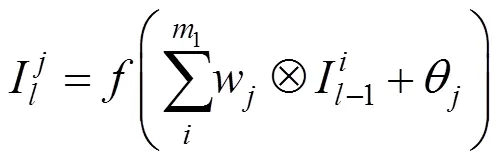
(2) 池化层特征图
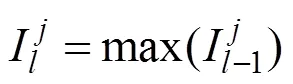
(3) 扩张卷积层与卷积层的输出特征图获得方法相同,可通过式(1)得到。但其引入的采样率使得卷积核膨胀变大,扩大后的卷积核=×(–1)+1,其中,为扩张卷积采样率;为原始卷积核大小。
1.2 多尺度特征提取
ASPP通过不同采样率的多个并行卷积来提取图像的多尺度特征,网络结构如图3所示。该结构将VGG16的fc6、fc7和fc8这3个全连接层均变为卷积层并扩展成个并行的fc6-fc7-fc8分支。其中,fc6层主要用于提取场景中不同尺度对象的特征,使用3×3的采样率为rate的扩张卷积核进行卷积,={1, 2, ···,}表示不同的采样率,fc7与fc8层均采用1×1的卷积核。网络的输出为提取的多尺度特征图,且每个尺度的特征图数量与图像的语义类别数目相同。
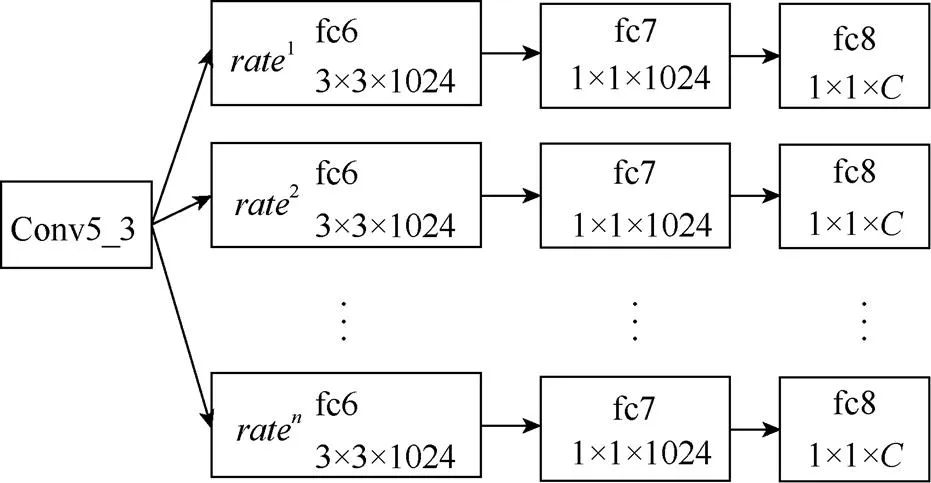
图3 ASPP结构
ASPP结构虽然能够通过并行的扩张卷积提取图像的多尺度特征,但仅依靠一种采样率来代表某一尺度容易导致模型的分割结果不够稳定,而且当DCNN网络产生的特征图分辨率较大时,可供选择的采样率较多,采样率的选取则尤为重要。本文提出一种MRSLC来缓和ASPP对采样率选取的依赖性,结合了MRSLC的多尺度特征提取结构ASPP+MRSLC,如图4所示。
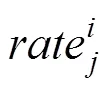
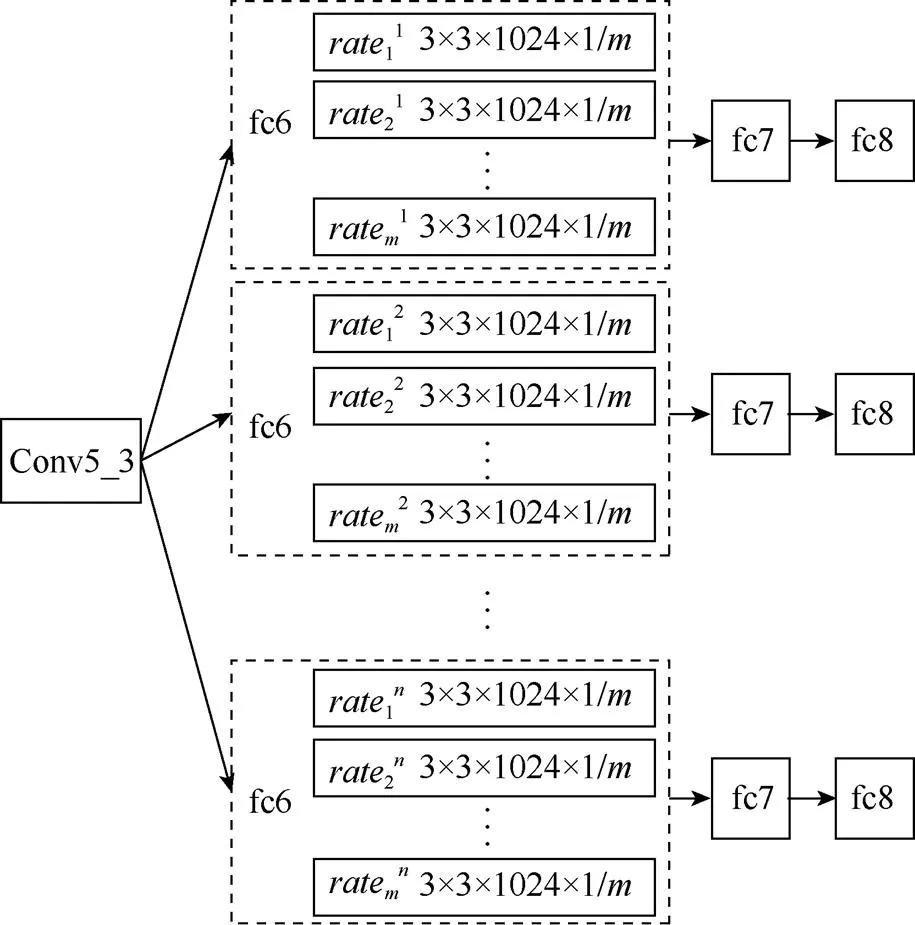
图4 ASPP+MRSLC结构
1.3 基于注意力机制的多尺度融合
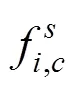
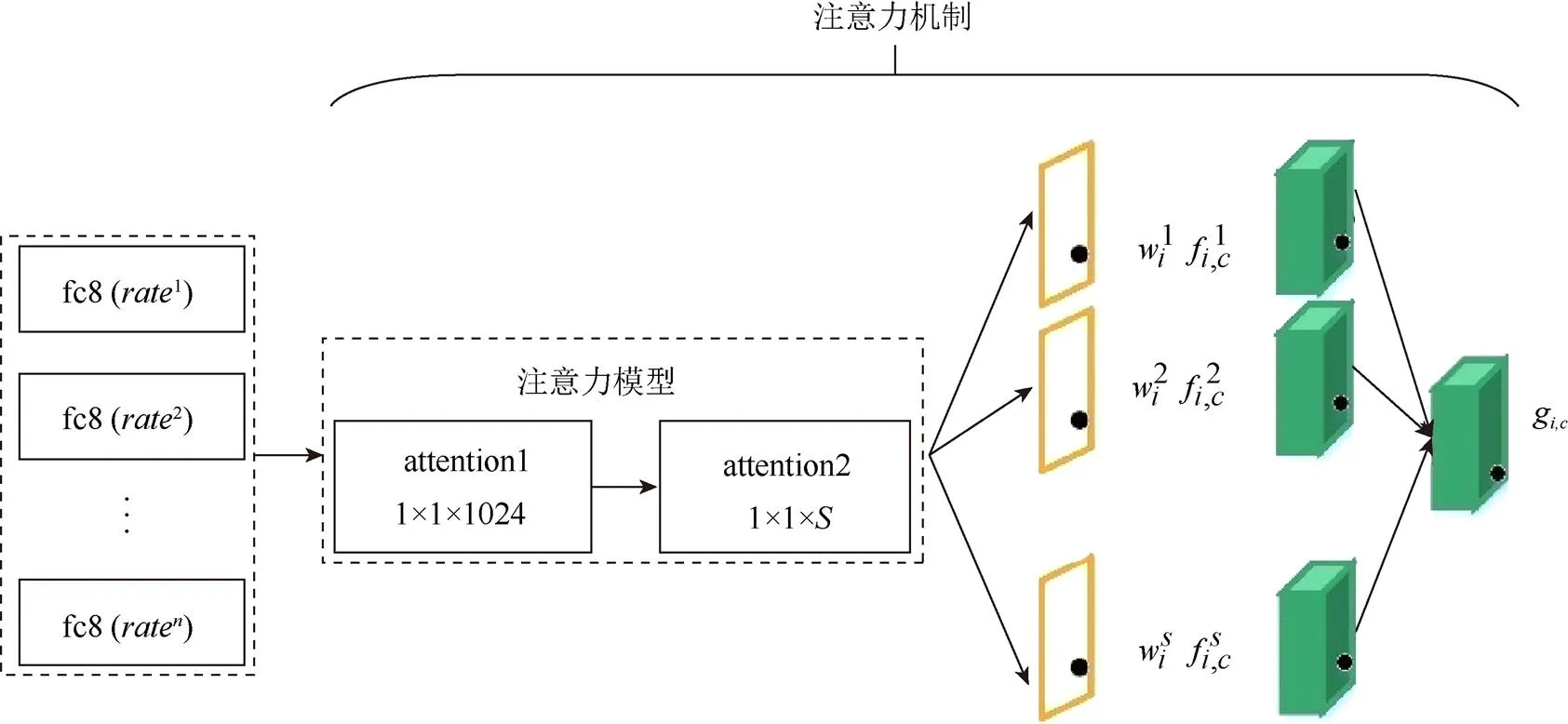
图5 基于注意力机制的多尺度特征融合结构
1.3.1 注意力模型的构建
注意力模型的目的是得到与尺度特征对应的可解释的权重图,用以表示各尺度及像素的重要性。本文通过引入额外的卷积神经网络来构建注意力模型,其具体构建及原因如下:
(1) 模型结构。仅包含一个卷积层的注意力模型只能通过个滤波器来学习特征,易导致特征学习不够充分。为了获取更丰富的关联信息以增加权重分配的准确率,将模型构建为两个卷积层,其中第一层包括1 024个滤波器,第二层包括个滤波器。
(2) 模型输入。fc8层相比于conv5_3、fc6和fc7层能够学习到更为全局性具有高层语义的尺度特征,包含的尺度信息更加丰富。因此将合并了各个分支的fc8层特征统一作为注意力模型的输入。
(3) 滤波器大小。注意力模型的任务是学习为尺度特征图的每个位置像素分配权重,而3×3的滤波器过多地考虑了周围像素对该位置像素的影响。因此两个卷积层均选用大小为1×1的滤波器进行卷积,使模型将关注点落在像素自身与分割结果的相关性。
1.3.2 注意力机制工作流程
基于AM的多尺度融合结构工作流程具体如下:
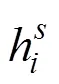
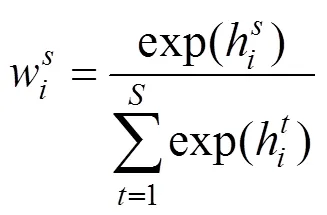
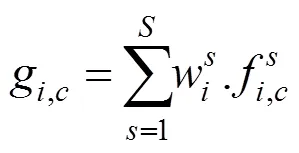
由上述过程可知,注意力机制的引入能够决定为不同尺度及不同位置像素赋予多少注意力,并且可以通过对每个尺度权重的可视化观察注意力的具体分配。
1.4 模型训练
该语义分割模型通过最优化多标签交叉熵函数进行模型训练。目标函数定义为

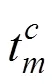
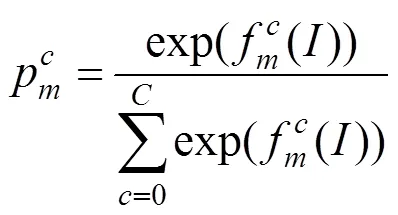
由于注意力模型能够通过反向传播计算损失进而更新其模型的权重参数,因此,可以采用端到端的方式训练整个网络。模型的DCNN部分直接使用VGG16网络的预训练参数进行微调,其他部分采用高斯随机分布初始化权重。
2 实验及结果分析
本实验软件平台为:Windows10 64位操作系统,TensorFlow深度学习框架;硬件平台:CPU为IntelCore i5-7300HQ,主频2.5 GHz;内存8 GB;GPU为GTX 1050ti。
2.1 实验数据
实验数据集使用Zurich_v1.0语义标注数据集,包含20对瑞士苏黎世地区大分辨率的航拍影像及对应的标签影像。为了简化模型最后对每个像素的分类过程,实验中将标签影像转换为像素值范围0~8的灰度图,以0~8的像素值依次代表背景、道路、建筑、树木、草坪、耕地、水域、铁路与泳池共9类语义标注。此外,本文将航拍影像及对应的标签影像均匀切割成224×224大小的图像块,并通过旋转、镜像翻转等操作对数据集进行提升,最终得到1 920对原始影像和标签数据,其中训练集1 520对,验证集100对,测试集300对。
模型通过随机梯度下降对网络的权重和偏置进行更新,训练批次大小为2,动量为0.9,训练阶段共迭代8 000次,每200次保存一次模型,网络初始学习率为0.001,每迭代4 000次学习率乘以0.1。
2.2 实验结果
本文采用像素准确率(pixel accuracy,PA)、平均交并比(mean intersection over union,MIOU)以及图像分割时间()作为模型的评价方法和准则。
2.2.1 模型中超参的影响与选取
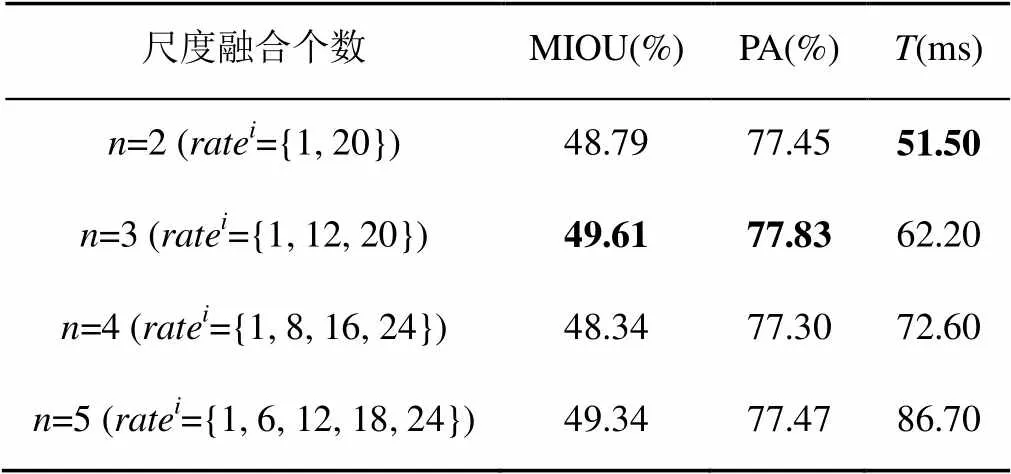
表1 ASPP尺度融合个数实验
2.2.2 不同的尺度融合方法对比
将本文的AM尺度融合方法与平均池化(Avg)、最大池化(Max)融合方法对比,结果见表3。由表3可知,在ASPP结构与(ASPP+MRSLC)结构上引入AM的融合方法具有更高的分割精度,且分割速度与Avg、Max方法相当,因此可以说明在ASPP和ASPP+MRSLC引入AM能够有效提升模型的语义分割性能。
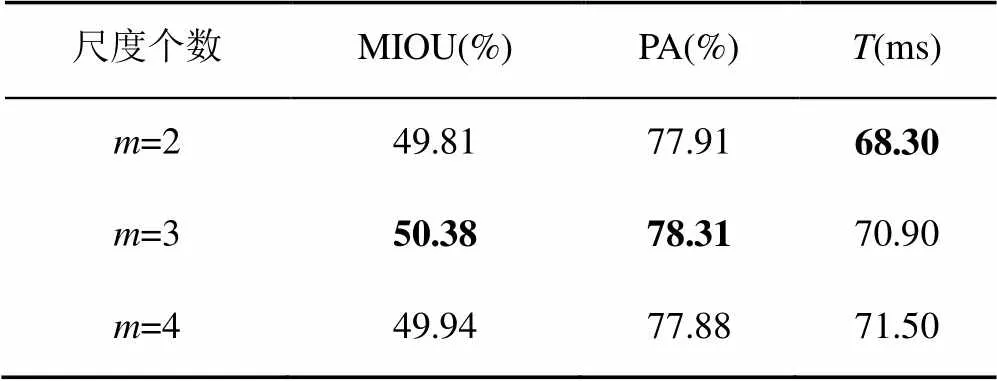
表2 MRSLC尺度个数实验
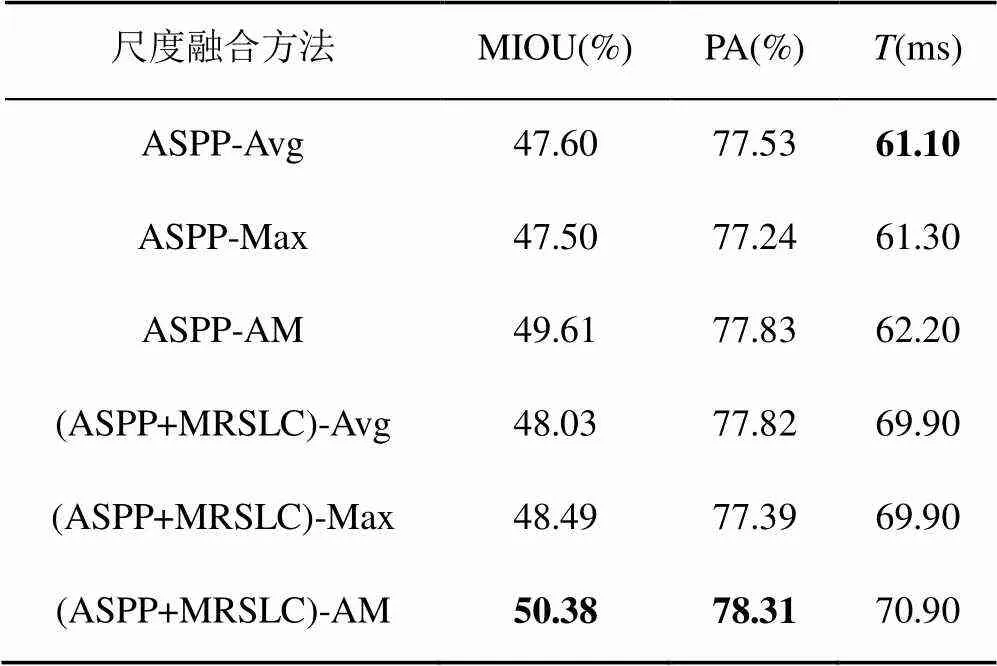
表3 尺度融合方法实验对比
为了直观地说明在尺度融合中引入AM的作用,本文可视化分析了由注意力模型得到的权重图,如图6所示,图中的(d)、(e)、(f)列分别代表小、中、大3种尺度特征对应的权重图。可以看到,在尺度层面,小尺度与中等尺度权重最高分别为0.4和0.5,最低仅为0.05,而大尺度权重范围为0.3~0.9之间,说明模型为大尺度特征赋予了相对更多的注意力;在像素层面,小尺度权重图为场景中的小尺度对象赋予相对较大的权重,为大尺度对象赋予了较小的权重;中等尺度权重图为中等尺度对象赋予相对较大的权重,为其他尺度赋予较小的权重;大尺度权重图则为大尺度对象赋予较大的权重,为小尺度对象赋予了较小的权重。由此可知,引入AM的尺度融合模型能够通过学习将小尺度特征的注意力聚焦于如零散的树木等小尺度对象,将中等尺度特征的注意力集中于耕地等中等尺度对象,而将大尺度特征的注意力集中于成片的树林、草坪等较大尺度对象,基于AM的尺度融合能够使模型有效地针对不同对象自适应地选取不同尺度特征。
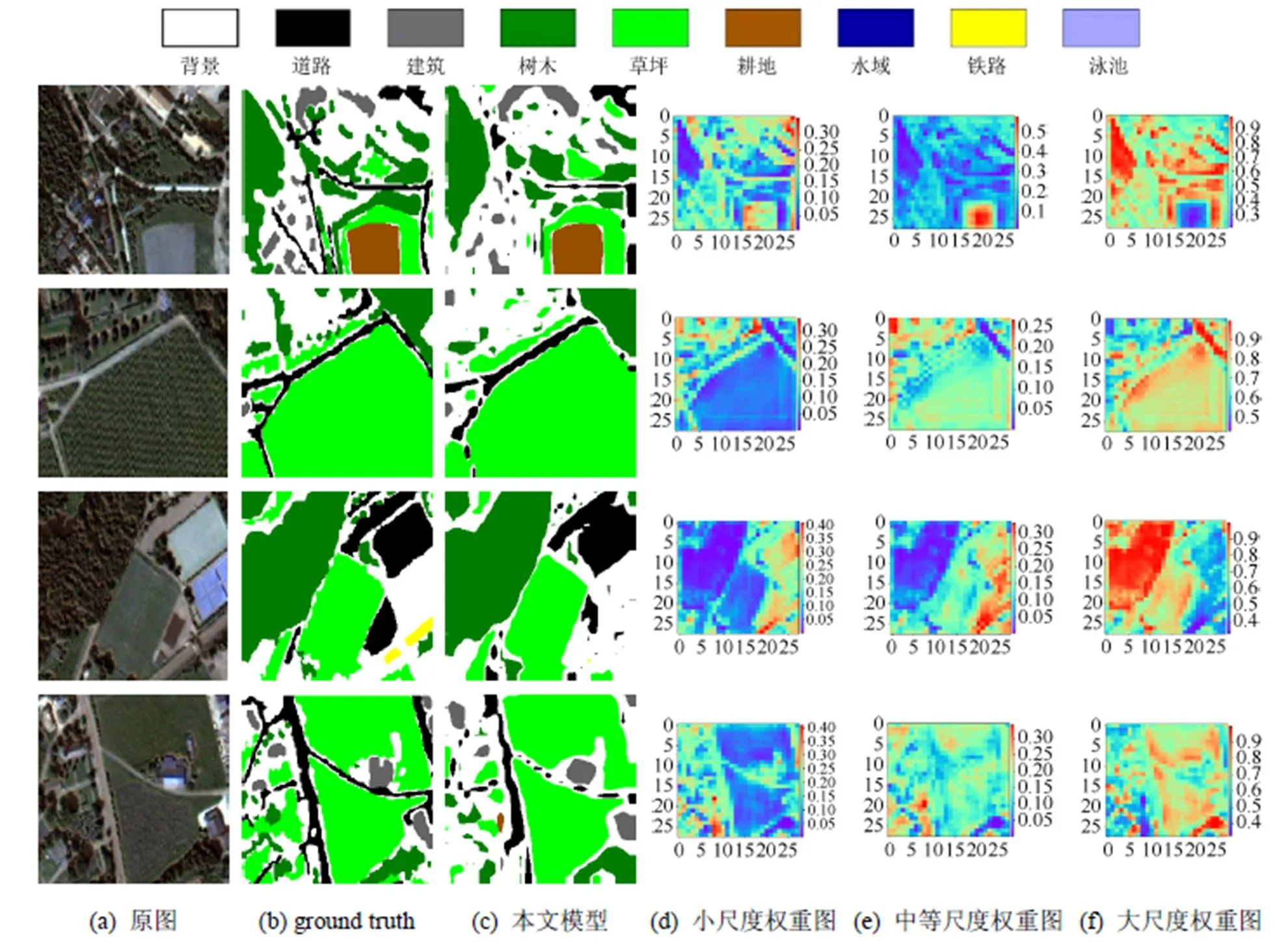
图6 航拍影像分割结果
2.2.3 与其他模型对比
本文用相同的评价指标对FCN、DeepLab语义分割模型以及文献[6-7]所提出的航拍影像分割模型进行衡量,实验结果见表4。由表4可知,本文提出的基于AM的多尺度融合模型在MIOU和PA指标上均高于其他模型,且分割速度较快,能够满足对模型的实时分割要求。在9个语义类别的识别率上,本文模型在6个类别上取得了最好的分割结果,体现了在不同语义对象上的整体优越性。另外,表4中各模型对航拍影像中背景、道路、建筑和水域的分割精度普遍较高,而对树木、耕地、铁路和泳池的分割精度较低。主要原因是该数据集中耕地、铁路和泳池这几类语义对象的样本过少,使得模型没有充分学习到其独有的特征,而树木在场景中的分布较为零散且边界区域过于粗糙,导致对其分割更为困难。
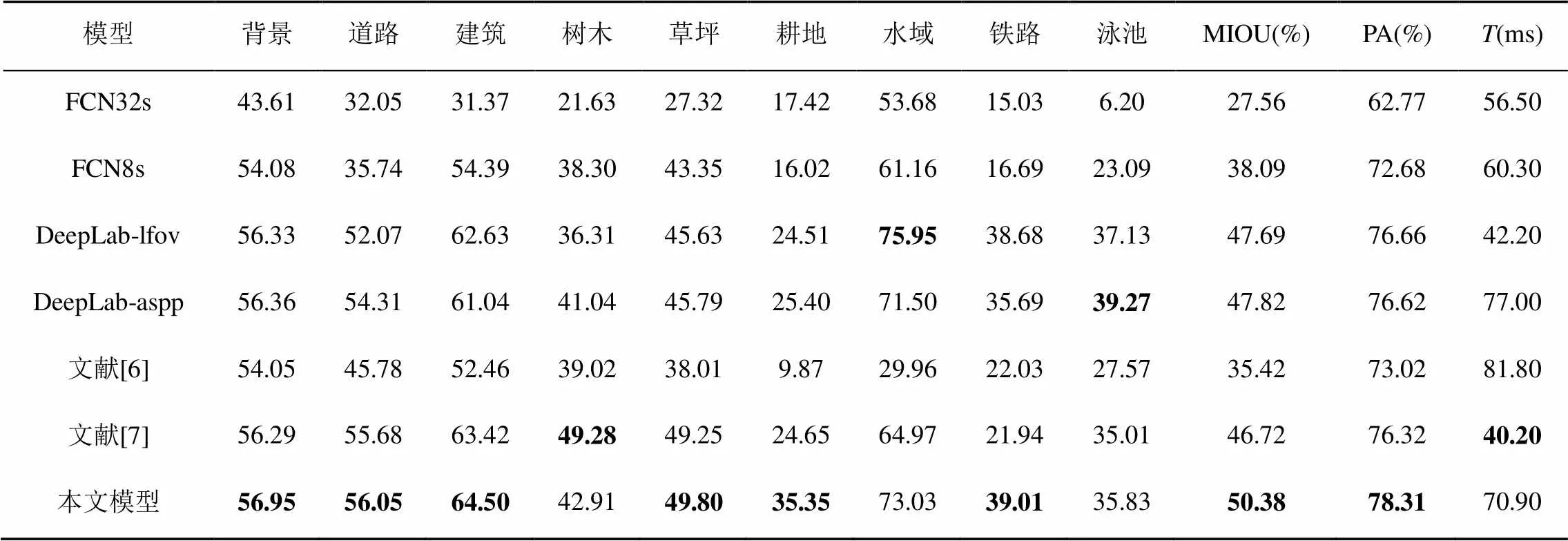
表4 本文模型与其他方法性能比较
图7给出了本文模型和其他模型在4幅航拍影像上的结果示例。从结果可以看到FCN32s分割的航拍影像较为粗糙,缺少大量的边缘细节,FCN8s的分割结果更加细致精确,捕获了更多的细节特征但对部分大尺度对象的分割过于细碎。这是由于FCN8s通过逐步的上采样方式融合前几层卷积层特征,学习到了更多的细节信息。两种DeepLab模型由于调整最后两个池化层的步长为1使得特征图分辨率更为密集从而包含了更多的信息,因此对大部分对象的分割相比于FCN更加精准,但对于树木、道路等形状较零碎区域的分割仍不够准确。文献[6]由于采用SegNet网络作为基础语义分割模型,更多地考虑了对像素的分类,缺乏邻近像素的整体一致性,因此导致分割结果边缘不够规整。文献[7]模型存在较多的误分割现象,例如将道路误分类为铁路,建筑误分类为耕地等。相比较之下,本文模型不仅能够对水域等大尺度对象以及单颗零散树木等小尺度对象都实现相对准确的分割,而且分割边缘较为平滑精确,对语义对象的误分割也较少。

图7 不同方法分割结果对比
3 结束语
针对航拍影像中对象尺度差异较大,单一尺度难以对其进行有效分割的问题,本文提出了一种基于AM的多尺度融合语义分割模型。在尺度特征提取阶段,将ASPP多尺度特征提取结构扩展为ASPP+MRSLC结构,在不增加模型复杂度的同时提取到更加多样的尺度特征。在特征融合过程中,通过AM的引入使得模型能够自适应地为场景中不同尺度对象选择最合适的尺度特征,对小尺度对象选择较小的尺度,为大尺度对象选择较大的尺度。实验结果表明,本文提出的模型有效地提高了图像分割精度,具有较好的航拍影像语义分割能力。
[1] CHEN L C, YANG Y, WANG J, et al. Attention to scale: scale-aware semantic image segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 3640-3649.
[2] SHELHAMER E, LONG J, DARRELL T. Fully convolutional networks for semantic segmentation [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 640-651.
[3] 王晨琛, 王业琳, 葛中芹, 等. 基于卷积神经网络的中国水墨画风格提取[J]. 图学学报, 2017, 38(5): 754-759.
[4] BADRINARAYANAN V, KENDALL A, CIPOLLA R. SegNet: A deep convolutional encoder-decoder architecture for scene segmentation [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481-2495.
[5] RONNEBRGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation [C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Berlin: Springer, 2015: 234-241.
[6] AUDEBERT N, SAUX B L, LEFÈVRE S. Semantic segmentation of earth observation data using multimodal and multi-scale deep networks [C]//Asian Conference on Computer Vision. Berlin: Springer, 2016: 180-196.
[7] MARMANIS D, WEGNER J D, GALLIANI S, et al. Semantic segmentation of aerial images with an ensemble of cnns [EP/OL]. [2018-01-15]. https://www. researchgate.net/publication/307530684_SEMANTIC_SEGMENTATION_OF_AERIAL_IMAGES_WITH_AN_ENSEMBLE_OF_CNNS.
[8] HARIHARAN B, ARBELAEZ P, GIRSHICK R, et al. Hypercolumns for object segmentation and fine-grained localization [J]. IEEE Transactions on Analysis and Machine Intelligence, 2017, 39(4): 627-639.
[9] MOSTAJABI M, YADOLLAHPOUR P, SHAKHNAROVICH G. Feedforward semantic segmentation with zoom-out features [C]//IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2015: 3376-3385.
[10] FARABET C, COUPRIE C, NAJMAN L, et al. Learning hierarchical features for scene labeling [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(8): 1915-1929.
[11] LIN G S, SHEN C H, VAN DEN HENGEL A, et al. Efficient piecewise training of deep structured models for semantic segmentation [C]//IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 3194-3203.
[12] CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848.
[13] DAI J F, HE K M, SUN J. BoxSup: exploiting bounding boxes to supervise convolutional networks for semantic segmentation [C]//IEEE International Conference on Computer Vision (ICCV). New York: IEEE Press, 2015: 1635-1643.
[14] PAPANDREOU G, KOKKINOS I, SAVALLEP A. Modeling local and global deformations in deep learning: epitomic convolution, multiple instance learning, and sliding window detection [C]//IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2015: 390-399.
[15] 刘全, 翟建伟, 钟珊, 等. 一种基于视觉注意力机制的深度循环Q网络模型[J]. 计算机学报, 2017, 40(6): 1353-1366.
[16] ITTI L, KOCH C, NIEBUR E. A model of saliency-based visual attention for rapid scene analysis [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(11): 1254-1259.
[17] SCHÖLKOPF B, PLATT J, HOFMANN T. Graph-based visual saliency [C]//International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2006: 545-552.
[18] HOU X D, ZHANG L Q. Saliency detection: a spectral residual approach [C]//IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2007: 1-8.
[19] 黎万义, 王鹏, 乔红. 引入视觉注意机制的目标跟踪方法综述[J]. 自动化学报, 2014, 40(4): 561-576.
Semantic Segmentation of Multi-Scale Fusion Aerial Image Based on Attention Mechanism
ZHENG Guping, WANG Min, LI Gang
(School of Computer and Control Engineering, North China Electric Power University, Baoding Hebei 071003, China)
In aerial images, there is significant difference between the scales of different objects in the same scene, single-scale segmentation often hardly achieves the best classification effect. In order to solve the problem, we proposes a multi-scale fusion model based on attention mechanism. Firstly, extract multi-scale features of the aerial image using dilated convolutions with different sampling rates; then utilize the attention mechanism in the multi-scale fusion stage, so that the model can automatically focus on the appropriate scale, and learn to put different weights on all scale and each pixel location; finally, the weighted sum of feature map is sampled to the original image size, and each pixel of aerial image is semantically labeled. The experiment demonstrates that compared with the traditional FCN and DeepLab method, and other aerial image segmentation model, the multi-scale fusion model based on attention mechanism not only has higher segmentation accuracy, but also can analyze the importance of different scales and pixel location by visualizing the weight map corresponding to each scale feature.
semantic segmentation; multi-scale fusion; attention mechanism; convolutional neural network
TP 391
10.11996/JG.j.2095-302X.2018061069
A
2095-302X(2018)06-1069-09
2018-04-15;
2018-06-17
国家自然科学基金项目(51407076);中央高校基本科研业务费专项资金(2018MS075)
郑顾平(1960-),男,河北保定人,博士,教授,硕士生导师。主要研究方向为图像理解。E-mail:zhengguping@126.com
李 刚(1980-),男,河北枣强人,博士,副教授,硕士生导师。主要研究方向为智能电网与大数据、信息物理能源系统、故障预测与健康管理等。E-mail:ququ_er2003@126.com
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
时代邮刊·下半月(2020年9期)2020-09-23
开放教育研究(2020年2期)2020-03-31
金桥(2018年6期)2018-09-22
小学生优秀作文(低年级)(2018年6期)2018-05-19
陕西画报(2017年1期)2017-02-11
中国修辞(2017年0期)2017-01-31
太空探索(2016年5期)2016-07-12
长江学术(2016年4期)2016-03-11
