
基于领域词典的网络商品评论情感分析
2018-02-09 07:19孔伟俊胡广朋
计算机与数字工程 2018年1期
孔伟俊 胡广朋
(江苏科技大学计算机科学与工程学院 镇江 212003)
1 引言
随着互联网和电子商务的不断发展,人们越来越热衷于网络购物,商品评论急剧增加。商品评论中包含了许多有用的信息,消费者可以通过评论了解商品的口碑,做出购买决策。品牌商家可以通过评论发现产品的优劣,对优点进行宣传,对缺点进行改进,进而更好地维护商品的品牌价值。随着线上交易的增长,网络评论数据也越来越多。商品评论不管是对消费者或者是品牌商家来说都是至关重要的数据,因此对网络商品评论进行情感分析有着重大的意义。
但是,目前电商平台上的评论仅仅分为好评和差评,传统的情感分析不能对情感强度进行量化分析,不同领域对情感分析的准确率影响也很大,此外中文语法的复杂性也大大增加了情感分析的难度[1]。因此,针对以上问题,目前急需一种情感分析技术来更好地对评论进行情感分析,帮助消费者以及品牌商家更好地做出正确的决策。
2 相关工作
情感分析中的重要的一个环节就是情感倾向性分类的研究[2~4]。在情感倾向性分类研究中目前有两类研究方向:第一类基于语义的文本倾向性分析技术[5],第二类是基于机器学习的文本倾向性分析方法[6]。
基于语义的文本倾向性分析技术主要是提取产品评论中的观点词,以词汇倾向性分类为基础,建立相应的含有极性值的观点词词典,对词汇进行倾向性评分,然后将倾向性得分进行加权平均来判断文本倾向性。通过对文本情感词的提取可以通过相应的算法或词典得到相应的极性。目前主要计算情感词极性的方法主要有两种,第一种是基于词典的方法[7],第二种是基于语料库的方法[8]。
第二类是基于机器学习的文本倾向性分析方法,利用支持向量机、粗糙集、模糊集和贝叶斯等分类技术实现对文本倾向性的识别[9]。
两类分类方法各有优缺点,相比于第二种,基于语义的文本倾向性分析方法更为通用,无需训练样本,对词汇倾向性分类技术依赖较小,而第二种基于机器学习的分类方法需要大量训练的样本,样本越大分类效果越好。本文选取第一种方法来对网络商品评论进行情感分析,通过构建能够自动扩展的情感词典并结合其它词典,来量化情感强度,通过情感强度判断情感极性。
3 情感词典构建
3.1 评论数据搜集
本文主要针对京东商城的评论进行分析,通过爬虫模块爬取某款笔记本电脑的商品评论页面,通过利用xPath技术获取页面中的评论数据,选取其中的1000条作为语料库,另取1000条作为测试库,将测试库通过人工标注分为正面评论和负面评论两个部分,经过人工标注获得正面评论864条,负面评论136条。
3.2 评论数据预处理
从互联网中获得的产品评论,要进行文本的特征提取,提取出具有代表性的属性词以及情感词,这个过程最开始的技术就是中文分词技术[10]。商品评论属于非结构化的文本,计算机是无法对这些句子进行处理的,无论是分类还是聚类,都需要对词汇进行处理[11]。本文选用中科院自主研发的Java版本的ICTCLAS2011,支持当前广泛承认的分词和词类标准,同时用户可以将自定义的情感词典加入分词词典中,也可以设置优先级,来提高系统分词的准确度。
通过分词系统可以对评论文本进行分词,将其中的形容词作为情感词,距离形容词最近的名词作为特征属性词,通过对特征属性词进行情感分析可以更细粒度地了解消费者对商品特征属性的意见。将语料库的1000条评论作为训练集,提取出其中所有的情感词作为领域词典的基准词库。
3.3 领域情感词典的构建
1)基准情感词构建
领域词典的构建首先要有基准情感词作为基准的褒贬词汇,需要的是具有明显褒贬情感倾向的词汇,相同的褒贬词汇在不同的领域内的褒贬倾向程度并不一定一样,在不同领域的情感强度可能会有所不同,本文所需要分析的是在领域内具有明确情感倾向且高灵敏度的词汇。基准情感词构建流程如图1所示。
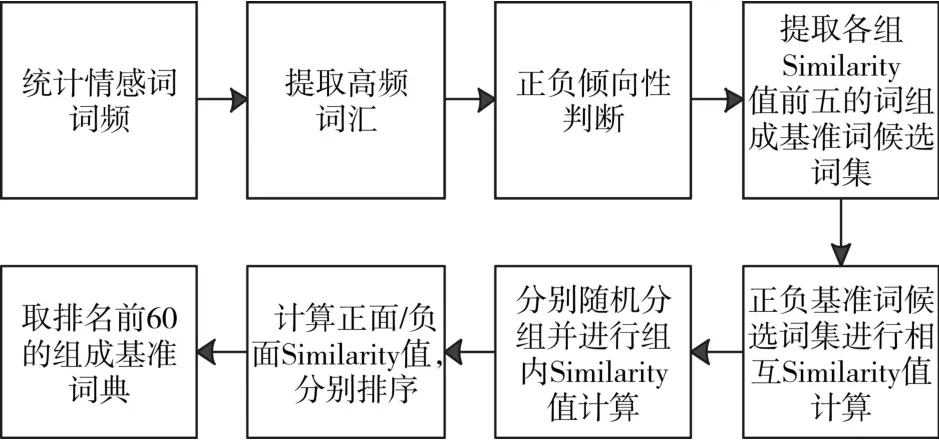
图1 基准情感词生成流程
Step1:对上文提取的基准词库中的情感词进行词频统计。
Step2:过滤掉低于设定阈值的词汇。
Step3:通过HowNet正负面词汇集判定高频词汇的正负情感倾向。
Step4:采用基于知网的语义相似度计算方法来计算词汇之间的Similarity值。
Step5:选取值靠前的词汇组成候选词集,并计算它们相互之间的Similarity值。
Step6:分别随机分组并进行组内Similarity值计算。
Step7:正负基准词集相互进行相似度计算是为了获得该领域情感倾向更为鲜明的词作为基准情感词集,更准确的识别情感倾向。
Step8:各取正负候选词前60个组成基准词。
2)领域词典自动扩充
在基准词的基础上,将用上文提取到的情感词对领域词典进行扩充。本文用基于知网语义相似度计算方法来计算词之间的语义相似性。计算公式如下所示:
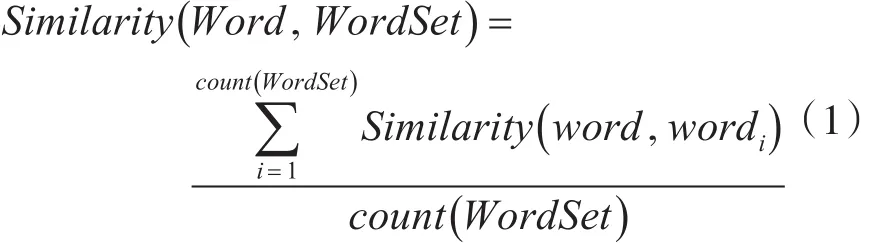
通过计算每个情感词与基准情感词的Similarity值。当与褒义情感词的Similarity值大于贬义情感词时,则判断为褒义情感词,反之则为贬义情感词。
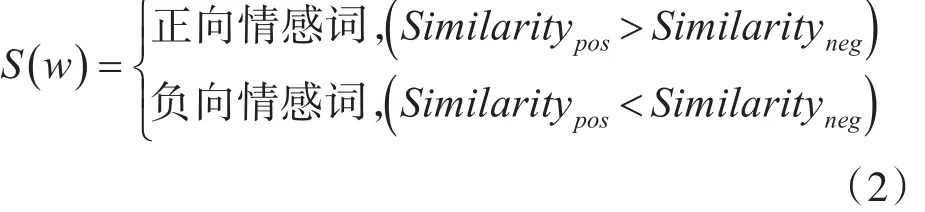
利用式(2)可以计算判断情感词的极性。之后可以加入领域词库中,过程如图2所示。

图2 领域情感词自动识别和标注
3.4 基础词典的构建
构建一个跨领域的极性词典是十分困难的,所以在上一节本文介绍了领域词典的构建以及自动扩展方法。由于用于提取情感词的语料库是有限的,不可能含有所有的情感词,所以本文需要一个基础词典来尽可能多的涵盖各个领域。HowNet是目前中文领域中比较经典且常用的极性词典,本文选取HowNet作为基础词典,并对该词典进行优化,并且结合了上文所构建的领域词典。基础情感词典构建流程如图3所示。
Step1:加入HowNet中的褒义词和贬义词情感词。
Step2:将Step1中的获得的情感词过滤掉领域词典中的词汇。
Step3:通过搜狗实验室互联网词库SougoW中的词频信息,过滤掉一个月内出现频率在15万次以下的低频词汇,获得基础情感词典。
Step4:对基础词汇进行人工标注,褒义的情感词汇情感强度设定为0.8,贬义的设定为-0.8。

图3 基础词典构建流程
通过以上基础词典构建流程获得正向情感词3558个,获得负向情感词3217个。
3.5 修饰副词词典的构建
在对评论进行情感分析时,除了考虑其情感词是褒义或是贬义的,还需要考虑情感强度,目前的大部分情感分析只对其进行情感倾向性分析,而忽略了情感强度,比如“还好”和“非常好”都是属于褒义词,但是修饰副词的不同导致了其情感强度的不同,所以分析其极性强度是非常有必要的。本文通过建立副词词典来计算极性强度。
本文对程度副词进行分类,首先把程度副词分为相对程度副词和绝对程度副词两类,并在此基础上再进行细分,细分的情感强度范围为(0.5,2.0),其中极量词汇的情感强度最高为2.0,之后依次为高量1.5,中量1.0,低量0.5,采用不同情感强度,能够有效区分情感词强度的大小。

表1 程度副词词典
3.6 否定词词典的构建
在对评论进行情感分析时,如果这句评论中存在否定词,那么该句子的极性可能就会完全相反。如“我非常不喜欢这款手机的背面”提取情感词为“喜欢”,通过情感词词典得出为褒义,但是由于这句话里面有否定词的存在,这句话的实际情感倾向是贬义的。所以提取否定词对于情感倾向性分析是十分重要的。
本文选取文献中否定副词范围的界定,选取“甭、别、不、白、白白、不必、非、干、不曾、不要、不用、何必、何须、何曾、何尝、空、没、没有、莫、徒、徒然、枉、未、未曾、未尝、无须(无须乎、无需、毋须)、毋庸(无庸)、勿、瞎、休、虚”等 31个否定副词,由于否定词表达的情感都是相反的,所以其情感强度为-1,表示相反的情感倾向。
4 商品评论情感分析策略
前文构建了本文所需要使用的词典,本文在该词典的基础上通过词典匹配计算情感词的强度,通过计算情感词的情感强度不仅可以区分情感倾向同时也可以更好的分析出评论表达的强烈程度。通过不同的情感值相乘可以得到更合理的情感强度。通过词典来计算特征属性的情感强度以及极性步骤如下:
Step1:通过3.2节介绍的特征提取方法提取评论中的特征词。对相同含义特征词进行合并。取出现次数最高的特征词作为表达该特征的特征词。
Step2:提取情感词、修饰副词以及否定副词提取组成四元组<特征词F,情感词E,修饰副词M,否定副词N>,若不存在副词则为空。
Step3:建立情感词典,获取每个特征词对应的情感词、修饰副词、否定副词的情感强度。将情感强度相乘,对相同的特征词求均值。计算公式如下所示:

式(3)中Se是情感词典中情感词的情感强度,Sm是程度副词的情感强度,若存在否定词则Sn的值为-1。
Step4:将获得的情感强度作为该特征的用户满意度,若情感强度大于0则为褒义,小于0则为贬义。
5 实验数据
本文利用3.1节所提取的测试集对本文提出的方法进行测试,通过对提取到的四元组进行计算,可以细粒度地对商品评论进行分析,通过判断情感强度可以得出消费者评论的情感倾向。
本实验对比基于基础词典和加入领域词典以及其他词典的情感分析。实验采用的评价指标有召回率R、准确率P和F值,公式如下:
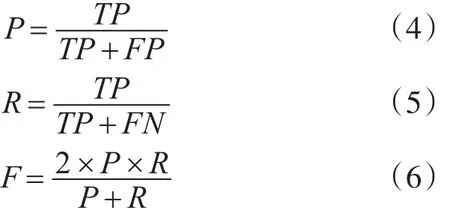
其中,TP表示实验结果中特征属性词的条数,FP表示不准确的条数,FN表示未被检测到的特征词的条数。

表2 实验结果
从表2中可以看出结合其他词典的方法相较于仅基于基础词典的方法在准确率、召回率和F均值方面都有较明显提高。通过实验表明本文提出的方法在网络商品评论情感分析方面具有良好表现并有一定的实用价值。
6 结语
本文为了更好地对网络商品评论进行细粒度地情感分析,构建领域词典并加入了其它词典,利用词典匹配的方法进行情感强度计算,和以前的仅仅依赖基础词典的方法相比,能够自动扩建情感词典,并且自动计算新加入的词汇的情感倾向,大大节约了时间,不需要人工标注,通过实验也证明了该方法的可行性。
在实验过程中也有一些不足的地方,现在网络越发发达,人们表达情感的方式更加个性化,不断有新的网络词汇会出现在商品评论中,在本文的方法中对网络词汇识别并不准确,所以在接下来的工作中,可以把网络词汇添加到词典中。同时由于中文语法的特殊性,句法依存、上下文环境也是需要研究的地方。
猜你喜欢
体育科技文献通报(2022年3期)2022-05-23
中学生报·教育教学研究(2022年1期)2022-04-18
有色金属(矿山部分)(2021年4期)2021-08-30
天津医科大学学报(2021年2期)2021-03-29
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
时代英语·高一(2019年5期)2019-09-03
英语文摘(2019年5期)2019-07-13
魅力中国(2018年11期)2018-08-06
中关村(2014年5期)2014-05-15
