
基于动态规划的序列情节告警挖掘
2018-02-09 07:18吴小雄
计算机与数字工程 2018年1期
吴小雄
(南京理工大学 南京 210094)
1 引言
随着数据挖掘技术的发展,将数据挖掘运用于网络安全领域是近来研究的热点[1~2]。其中,序列模式挖掘[3~4]是一个重要的研究方向。对告警日志进行序列模式挖掘一般有两种处理方式,一种是将原始告警日志转换为序列事务数据库,再使用序列关联规则[5~6]挖掘算法,如 GSP[7],FreeSpan[8],PrefixSpan[9]等;另一种直接使用滑动窗口挖掘原始序列中的频繁序列模式,该类处理方式也叫做序列情节发现[10~11]。第一类划分处理方式可能会将潜在的攻击序列人为割裂。第二类处理方式主要以基于自动机的WINEPI[12]算法为代表,但该算法存在挖掘效率低下的问题。
本文提出了一种新的基于动态规划的频繁序列情节挖掘算法,该算法采用第二种处理方式,并基于以下考虑:即长序列模式蕴含短序列模式,因此本文通过直接挖掘较长序列,从而精简了输出结果,也提高了挖掘效率。
2 基于动态规划的序列情节告警挖掘
2.1 序列情节告警
本文提出一种基于动态规划直接对较长序列进行计数求解的方法。如图1,频繁序列片段与按给定窗口进行划分的窗口对应的序列是一致的,因此可以对原始告警序列按事件分组,相同的事件为一组,再按照窗口长度进行截取,然后再对两两窗口内的事件序列求其所有的公共子序列并分别计数即可,计数采用前缀树实现。图1表示所有以B开始的分组,窗口大小为6的划分方法。

图1 原始序列与对应的划分序列
2.2 算法流程
Input:序列 S,最小支持数 minSupport,窗口大小window_size和情节长度episodeLen。
Output:满足最小支持数minSupport和最小情节长度episodeLen的序列情节模式。
1)扫描一遍原始序列S,用哈希表保存各个序列元素的出现在序列中的位置索引;
2)遍历哈希表,过滤索引数量(支持数)低于minSupport的表项;
3)遍历哈希表中剩余的项,对每项I进行4)~5)操作:
4)将I中的索引进行两两组合,记其分别记为Ia,Ib,根据Ia,Ib索引在原始序列S中从该位置开始,截取长度为window_size大小的子序列,记为Sa,Sb,然后利用动态规划求出Sa,Sb的所有的公共序列,记为集合Scommon,遍历集合Scommon中的每一个元素s,如果s的长度大于等于episodeLen,则将s和Ia,Ib参数带入,插入前缀树中;
5)遍历前缀树,结点计数值count大于等于minSupport的结点其为所有相关结点,输出从根结点到该结点的序列,这些序列即为频繁出现的序列情节。
3 实验分析
3.1 数据预处理
本节对本章提出新方法进行了实验,实验数据为Honeynet数据集。为了实现序列挖掘,先将实验数据进行预处理,变为时间轴上的流式数据,这里需要将日期格式转换为整数。处理方法是先将所有的时间转换为距离1900年00:00:00以来的秒数,然后再将每个时间减去最小的时间,并按时间升序排列,最终清洗合并过后的事件数为5733个。
3.2 实验内容
分别实现WINEPI算法[12]、和本文提出的算法(命名为FSP_DP,Frequent Sequential Pattern based on Dynamic Programming),对比实验均在完全相同的环境下。实验控制变量为窗口大小、规则长度、支持数三个维度,考察算法运行时间。
图2为本章的算法与WINEPI算法随窗口大小的运行时间情况,这里取最小情节长度episodeL-en=3,最小支持度minSupport为10,窗口大小为10秒到100秒的情况。
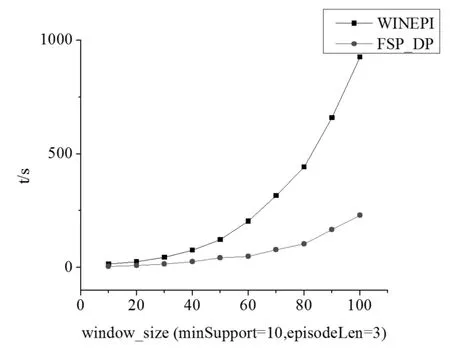
图2 算法运行时间随窗口大小变化情况
图3是WINEPI算法与FSP_DP算法的运行时间随子序列长度的变化情况,其中最小支持度设置为10,窗口大小为1分钟(60秒)。
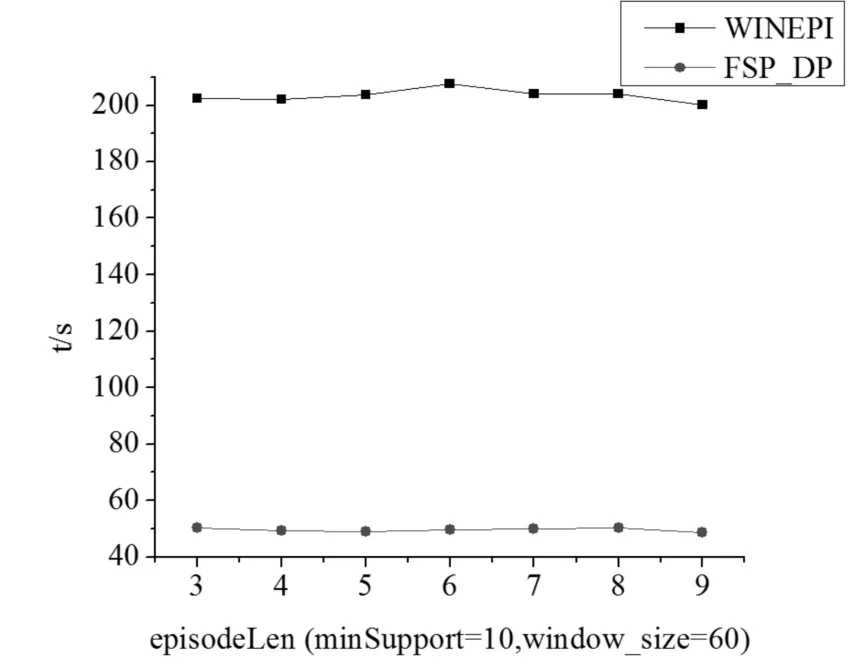
图3 算法运行时间随子序列长度变化情况
图4是在相同窗口大小和相同最小子情节长度的情况下,算法运行时间随支持度的变化情况。这里窗口大小window_size仍取1分钟(60秒),最小情节长度取3。
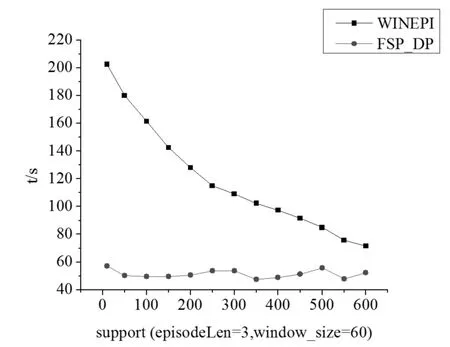
图4 算法运行时间随支持数的变化情况
总得来看,本文提出的算法效率高于WINEPI算法。WINEPI是基于自动机的频繁集搜索方法,其特点是逐级搜索。WINEPI是从支持度的角度进行直接求解,序列长度需要通过增长实现;FSP_DP是从序列长度直接求解,支持度通过累加实现。
4 结语
告警序列情节挖掘是网络安全领域一个热门的研究方法,可以发现潜在的攻击模式。本文提出一种基于动态规划结合前缀树的序列情节告警挖掘算法。实验表明该方法能有效挖掘出告警序列中的频繁情节,并且效率较之基于自动机的WINEPI更高。
猜你喜欢
卫星应用(2022年7期)2022-09-05
卫星应用(2022年3期)2022-05-23
卫星应用(2022年1期)2022-03-09
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
小学生学习指导(低年级)(2020年10期)2020-11-26
环球慈善(2019年6期)2019-09-25
作文大王·低年级(2017年11期)2017-12-05
学苑创造·A版(2017年1期)2017-01-19
西南学林(2013年2期)2013-11-12
