
临床生物样本库信息系统建设与发展
2018-02-02 08:03杨文航徐英春1
协和医学杂志 2018年1期
郭 丹,杨文航,徐英春1,
中国医学科学院 北京协和医学院 北京协和医院 1临床生物标本中心 2中心实验室 3检验科 ,北京 100730
近年来随着多组学及生物信息学、分子成像和人类疾病动物模型等技术的快速发展,各种大规模、高通量的生物医学研究得以开展,而这些研究对生物样本需求的数量和质量不断提升[1],促使各国政府、研究机构和生物医药企业越来越重视临床生物样本库的建设和应用,将其视为发展生物医药领域核心竞争力的战略举措。以美国为例,在过去10年间先后投入10亿美元建立179个生物样本库,收集大约34.5万例生物样本,总容量达3.07亿[2]。
同时,转化医学的快速发展促使生物样本库由不成熟、小规模的活动快速转变为复杂、多面、大规模的形式[3],并形成一整套独特的体系,如样本处理、信息注释、存储、运输、追踪和销毁,样本电子化管理,临床信息系统,数据库结构,质量控制,资质认证等。生物样本库已从原本单一的样本采集和处理逐步发展成为支持基础研究和临床试验的重要平台,而信息化建设是其中的关键环节,其建设应着眼于支撑样本库管理、服务和运营的全过程,实现从生物样本及临床信息资料的采集、储存、应用、产出和质量控制的全面信息化管理,对促进信息资源共享、提高研究效率具有重要作用。本文主要探讨临床医疗机构生物样本库信息化建设的发展现状、趋势与主要内容。
1 发展现状与趋势
1.1 发展现状
目前国内外生物样本库信息架构的主要模式可分为自下而上型和自上而下型。自上而下的模式为在建设前即给予顶层设计,建设较大规模的国家级生物样本库网络,通过制定通用数据元和网络接口方式,有效保证样本信息的质量并解决不断提升的信息容量。目前已有多个国家级生物样本库采用此方案,如美国癌症生物医学信息网络 (Cancer Biomedical Informatics Grid,CaBIG)[4]、美国生物存储和生物样本研究中心(Biorepositories and Bispecimen Research Branch, BBRB)[5]、加拿大肿瘤资源库协作网(Canadian Tumor Repository Network,CTRnet)[6]、英国的UK BIOBANK[7]、生物样本库和生物分子资源研究中心-欧洲研究基础设施联盟(Biobanking and BioMolecular resources Research Infrastructure-European Research Infrastructure Consortium, BBMRI-ERIC)[8]等。这种自上而下的模式不仅可以保障信息质量,还可有效促进资源共享,实施大规模、高通量的研究。北欧各国早在20世纪中期就开始建设基于健康人群的大规模生物样本库,并先后从芬兰、冰岛、挪威和瑞士的17个人群样本库招募200万捐赠者,获取400多万份样本及个人相关健康数据,通过长达几十年的随访进行系统全面的肿瘤分子流行病学研究[9]。
自下而上的模式为整合现有的信息资源建立协作网络,从知情同意管理、样本采集到存储和研究均利用现有的系统数据,形成集成共享资源。例如爱沙尼亚的人群生物样本库项目,从全国信息登记系统和医院数据库获取52 000名参加者的遗传和健康数据,再通过X-road技术连接基因组中心数据库与国家卫生信息系统,实时进行数据交换。这种模式可及时且低成本获取信息,有利于开展并提升以公共健康为目的的基因组学和流行病学研究[10]。我国2008年启动的“上海市组织样本库项目”[11]和2012年启动的“上海临床信息平台项目”[12]亦是从多个现有医院信息系统(hospital information system, HIS)中进行数据的获取、整合、分析和利用,为多中心HIS数据库和生物样本的对接、数据获取和二次挖掘利用开启了思路。
两种建设模式各有利弊,一个大规模的生物样本库从开始建设到可用状态,信息化建设需投入大量的经费和时间,虽然集成现有的信息数据进行协作高效且快速,但由于缺乏长远规划而使其发展受限。随着2016年国家精准医学重点研究专项计划的提出,陆续启动了一系列大型健康队列、重大疾病队列、多层次精准医学知识库体系和生物医学大数据共享平台建设项目。探索建立队列资源开放应用机制和样本与数据共享机制迫在眉睫,多元化临床研究样本库的信息建设亟待统一和规范[13]。
1.2 发展趋势
目前,快速发展的临床生物样本库正面临两个显著问题。第一,随着对疾病认识的加深,研究者需要多样化的生物样本及分子资源(包括抗体和亲和分子库、小干扰RNA文库、蛋白、细胞资源等);第二,新的研究技术如二代测序等将产生大量的数据需要存储,同时需要开展高通量分析及大数据深度挖掘,这种复杂化、多样化的信息交互和存储,以及容量不断扩展和分析挖掘的需求,使得仅以样本为中心将难以满足科研需要,临床生物样本库的发展战略需从以生物样本为中心转换为以信息为中心[14]。
国际生物与环境样本库协会(International Society for Biological and Environmental Repositories,ISBER)2017至2020年的战略规划显示,ISBER在未来3~5年将把信息、数据管理和共享作为3大战略任务之一,这表明全球样本库的信息化需求在不断提升。同时越来越多的样本库在对外共享和服务中发挥重要作用,如美国国家心肺和血液研究所生物样本和数据资源库信息协调中心[15]和华盛顿大学医学院生物样本库[16]等机构,通过建立信息化和基于网络的样本共享流程,有效增加了生物样本和数据库的可见性和利用率,使得样本申请更加便捷、快速。Windber研究中心样本库也建立了专业的数据库DW4TR,包括以患者为中心的临床数据模型和以样本为中心的分子数据模型(图1),为多数据的存储、整合和挖掘提供了较好模式[17]。此外,一些国际性的多中心研究,如美国1948年启动的Framingham心脏病研究[18],英国2005年发起的高通量测序鉴定人类基因组序列变异研究(Wellcome Trust Case Control Consortium, WTCCC)[19],均建立了公共网络平台,全球研究者通过界面访问即可分享数据、参与研究并了解最新进展。在欧洲,已建立起以BBMRI-ERIC为首的欧洲研究一体化网络数据库,其通过网络集线器和拓扑结构连接遍布欧洲各国的节点,建立了分布式枢纽结构信息系统,协调成员样本库之间的样本收集、管理、分配和数据分析等各项活动,然后通过网络开放,实现在欧洲乃至全球范围内的资源共享[20]。

图1Windber研究中心DW4TR数据库的结构[17]
2 信息化建设主要内容
2.1 信息管理系统构成及特点
临床生物样本库的多功能交互要求必须具备强大的信息管理系统,准确记录和跟踪样本的接收、运输、采集、处理、贮存和发放等流程[21]。一方面基于生物样本库的研究项目审批和管理需要实现电子化管理,如人员、设备、耗材等;另一方面随着大数据时代的来临,各研究机构间实现数据库互访和共享是未来的发展方向和实际需求,因此生物样本库信息管理系统应涵盖生物样本管理系统、临床数据管理系统、分子数据平台、科研项目以及仪器、人员、设备、财务等综合性管理系统(图2),并具备“两个中心,一个基本点,兼具延展性、开放性和密闭性”的特点。
2.1.1 以样本为中心的临床生物样本管理系统
以样本生命周期为主线,实现从样本入库核收、处理、分装、标识、冻存的全过程管理,可进行样本类型定义、注释、冻存空间分配、效期管理、动态库存统计、出入库管理、质控记录管理等,通过唯一标识或编码实现样本谱系化溯源管理。
2.1.2 以患者为中心的临床数据管理系统
面向临床研究者、研究型护士开放,可用于受试者临床病历和随访的管理,涵盖患者入组情况、健康信息、生活方式记录、病史、既往治疗情况、目前治疗情况及临床各项检查结果等,通过提示性的查询和完备的报告系统,对临床研究进行精细化管理、全程监测和适时提醒。
2.1.3 通用数据元标准化
通用数据元标准化是建设的基本点,也是数据能够实现共享的关键点。通用数据元是通过定义和标识来规定具有某些属性的通用数据单元,各种通用数据元共同组成数据元字典,其设定的目的是提高数据质量并促进共享。在生物样本库领域通用数据元是指样本类型字段、生物类型代码和疾病分类标准等,尽管目前在生物样本库的试行标准中规定了人体器官代码、生物类型代码等数据元[22],但目前尚未形成国际标准化统一方案,因此我国自2016年开始启动多项重点研发计划,拟通过建立标准化的通用数据元和数据元字典,以规范样本数据表达的一致性,提高数据质量,实现各队列、各样本库之间数据库联网。
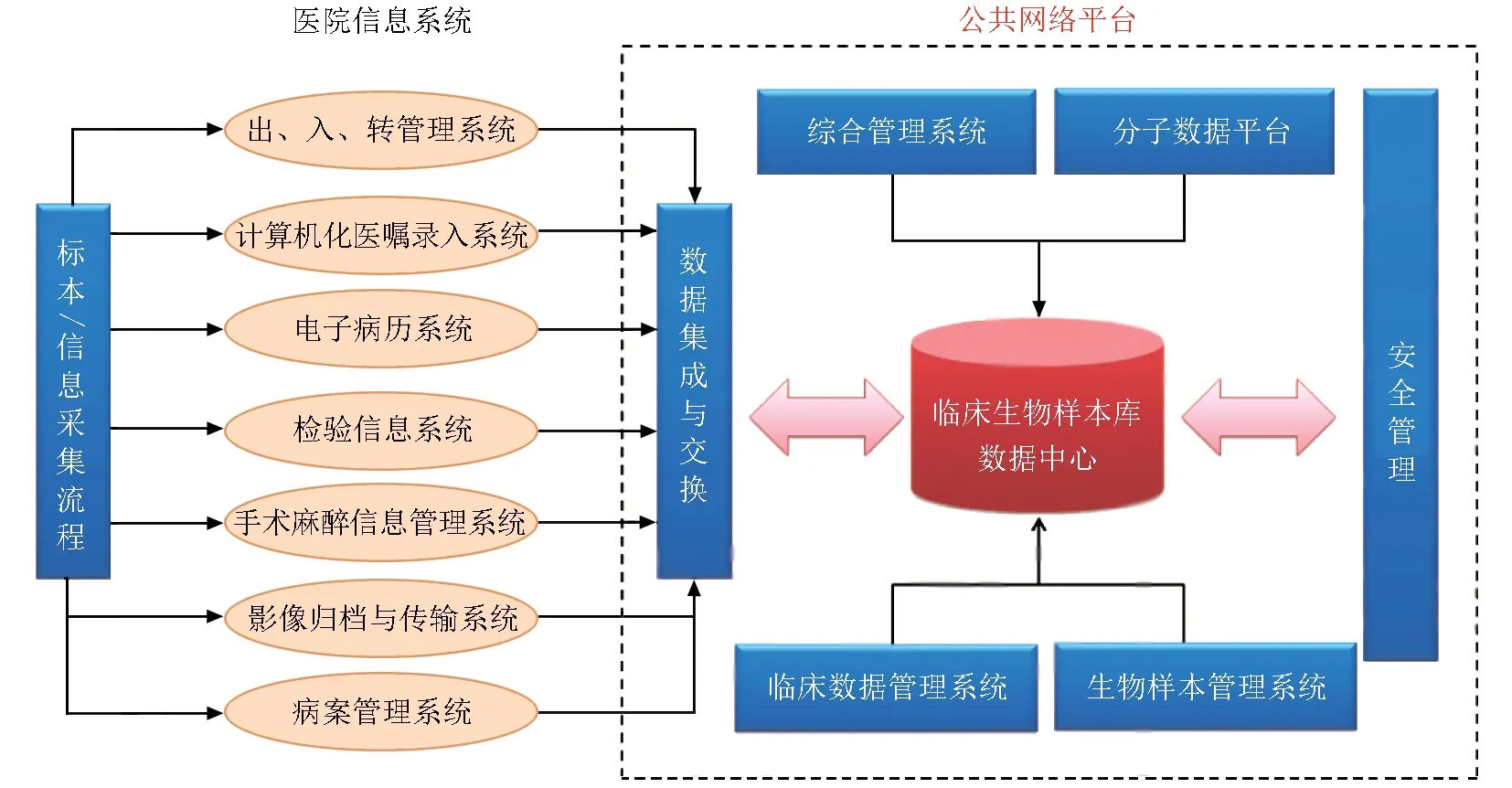
图2临床生物样本库信息系统架构
2.1.4 分子数据平台管理
包括基因组、蛋白质组、代谢组、转录组及各种疾病的临床表型数据的存储、交互和挖掘,便于开展高通量筛选、检测、功能分析以及临床验证,将多组学数据与疾病的临床数据相关联,进行深度信息分析和挖掘,提高样本携带生物大数据的利用和转化能力,从多角度探究疾病的发病机制及个性化诊疗。
2.1.5 综合性管理系统
科研项目管理系统实现对出入库科研项目的流程管理;人力资源管理系统实现人员资质及培训、考核管理;保障系统实现对中心各项运行设备、耗材和试剂的维护和过程记录;信息发布系统通过开放门户网站面向临床样本资源的各类访问者展示可用资源、申请流程和共享方式等,实现网上检索、递交申请和审批等功能。
各系统功能及其使用对象各有侧重,其中以生物样本管理系统和临床数据管理系统为核心,其他辅助系统可随临床生物样本库的发展相继建设,不断扩展,互通互享。目前国内外有多家较成熟的样本管理系统和实验室信息管理系统,在软件架构、数据库、语言环境、网络环境方面等各有特色和优势,既有成品化系统,也有个性化定制,各研究机构可按照自身需求进行选择和定制开发。
2.2 数据采集、传输和交换
数据是信息系统建立的基本要素,临床与样本数据的采集、集成与交换是信息系统的基本功能。目前国内部分生物样本库存在信息分散、数据非结构化的问题,各样本库需根据实际情况、工作流程建立样本和数据采集体系,以保证信息采集和传输的及时性、有效性和完整性。
与传统样本库依靠人工录入获得数据相比,新一代样本库更加注重样本和临床数据对接的质量及完整性,将样本和数据的采集流程与住院出、入、转管理系统(admission, discharge,transfer system, ADT)、计算机化医嘱录入系统(computerized physician order entry, CPOE)、电子病历系统(electronic medical record, EMR)、检验信息系统(laboratory information system,LIS)、手术麻醉信息管理系统(anesthesia information management system,AIMS)、病理信息系统(pathology information system, PIS)、影像归档与传输系统(picture archiving and communication systems, PACS)、病案管理系统(medical records management system, MRMS)等HIS系统相互交汇,实现自动抓取,节省劳动力的同时保证数据的可靠性及安全性[23](图2)。
以医院患者为主要采集来源的临床样本库为例,当患者通过ADT进入医院后,临床医生在诊疗过程中根据患者的临床表型将其纳入不同研究项目,与其签订知情同意书,同时通过医嘱管理系统开启各种样本和信息采集的流程,如麻醉医生采集术前血液标本(AIMS)、科室护士采集特殊体液和术后血液标本(EMR)、病理医生采集组织样本(PIS)、门诊护士采集随诊患者血液标本(随诊系统和EMR),采集后的样本通过低温快速转运至实验室进行处理、入库和信息录入(图3),整个过程实际上通过多系统交互和信息流传递完成,高效、准确、迅速,降低了人力资源成本和系统误差。
此外,为保证各系统数据集成、传输和交换的可靠性、稳定性和高效性,信息体系的建设需在网络结构模式、技术架构、数据传输、数据连接、浏览方式等方面进行全面深入的考虑。如在网络结构模式上可采用B/S(Browser/Server)结构;在技术架构方面创建支持信息访问、传递以及跨库的集成化应用环境,提高其兼容性、安全性和工作效能;对于多中心数据库尤其需考虑数据交换方面采用可扩展标记语言格式以进行数据定义,确保数据传输交换的一致性。同时,在数据连接方面采用对象关系映射框架,以便于集成多种数据库,并实现内存数据模型与存储模型之间的相互转换。
2.3 数据安全性
系统的建设应当兼顾延展性、开放性和密闭性。一方面使用开放性的数据库和语言,通过数据接口实现多系统对接;另一方面数据安全也是临床生物样本库信息化建设必须面对的重要问题之一,包括数据库、应用服务器、数据传输的安全性等。为保证系统整体安全,需通过多种方式设立各级安全保障措施,一方面充分利用操作系统提供的安全机制,如口令验证、存取控制、电子签名和加密,实现服务器、数据库、操作等多层安全控制;另一方面对敏感数据的存储进行加密及隐私保护,保证系统在用户认证、数据传输和数据储存等多方面的安全要求。建立完善的日志及跟踪功能,对系统内主要事件(如用户登录、文件及项目审批等)进行记录、审计和追溯,定期异地备份数据,并配备专用电脑,避免电脑感染病毒。同时,应建立权限分配制度,从超级管理员、一般管理员到各级访问人员均设定不同权限,既可支持不同样本、不同患者、不同项目、不同类型数据的加入,实现高效配合,又保证了数据访问的安全性。
3 小结
在我国全面迈向创新型国家的过程中,生物样本库发展迅速,其信息化建设对于支撑样本库的建设、运营、管理和服务全程具有极为重要的作用。对内可实现生物样本、临床资料、分子数据等各种资源的高效管理和全面共享;对外通过数据集成、交换和安全系统,形成一体化的整合数据库和公共门户网站,面向临床样本资源的各类访问者展示可用资源,实现网上检索、递交申请、网上审批等功能,借助大数据时代的优势,有效管理和使用生物样本及其衍生的各种信息,并使之最大限度地服务于转化医学研究和个体化诊疗。
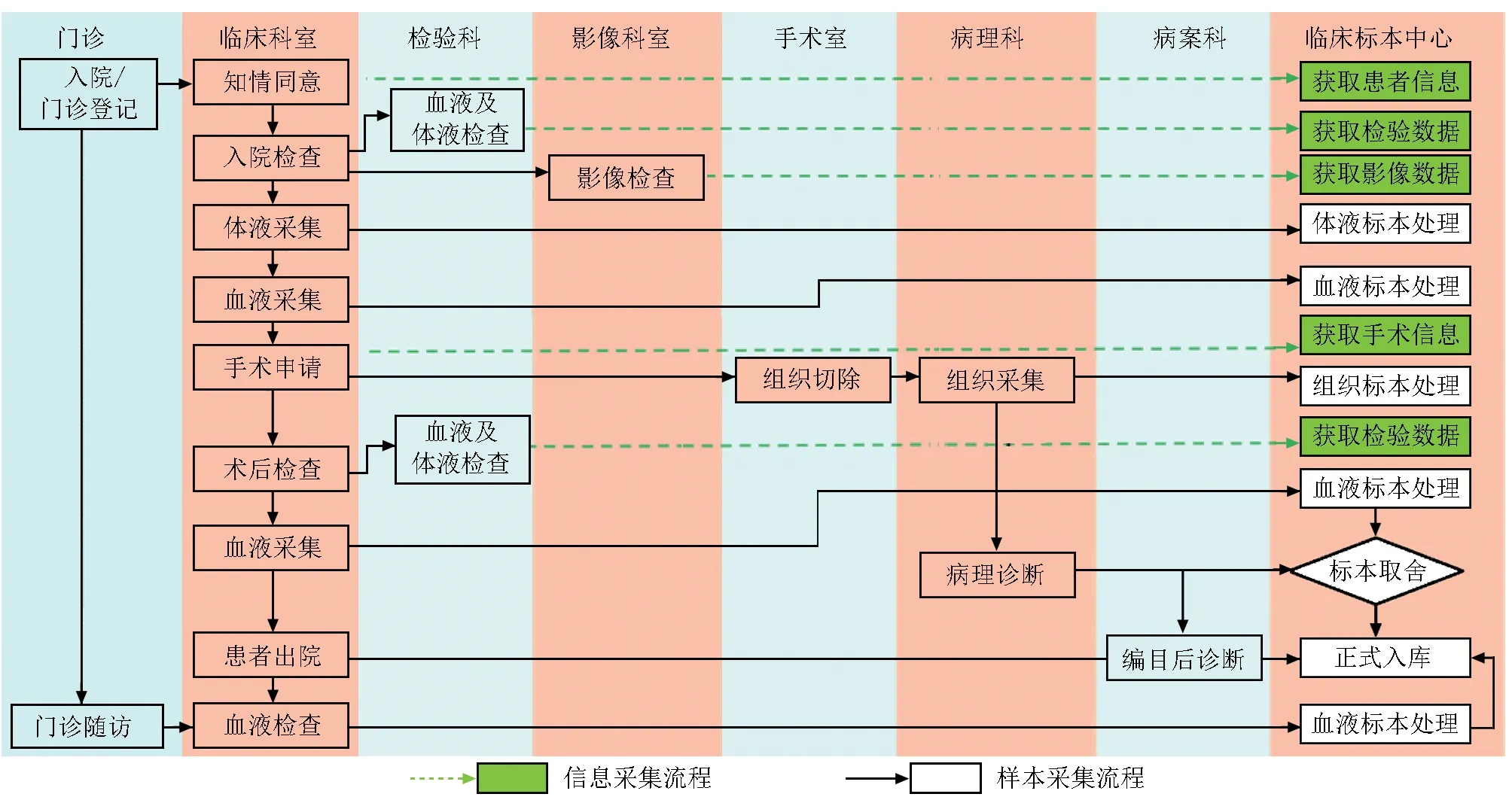
图3临床生物样本库样本/信息数据采集流程示意图
[1] Watson PH, Wilson-McManus JE, Barnes RO, et al. Evolutionary concepts in biobanking-the BC BioLibrary[J]. J Transl Med, 2009, 12:95.
[3] Ginsburg GS, Burke TW, Febbo P.Centralized bioreposi-tories for genetic and genomic research[J]. JAMA, 2008, 299:1359- 1361.
[4] caBIG Strategic Planning Workspace. The cancer biomedical informatics grid (caBIG): infrastructure and applications for a worldwide research community[J]. Stud Health Technol Inform, 2007, 129:330- 334.
[5] NCI/NIH BBRB. Biorepositories and bispecimen research branch[EB/OL].https://biospecimens.cancer.gov/default.asp.
[6] CTRNet. Canadian tumor repository network[EB/OL].http://www.ctrnet.ca/.
[7] UK BIOBANK[EB/OL]. http://www.ukbiobank.ac.uk/.
[8] BBMRI-ERIC.Biobanking and BioMolecular resources Research Infrastructure-European Research Infrastructure Consortium[EB/OL]. http://www.bbmri-eric.eu/.
[9] Pukkala E, Andersen A, Berglund G, et al. Nordic biological specimen banks as basis for studies of cancer causes and control-more than 2 million sample donors, 25 million person years and 100,000 prospective cancers[J]. Acta Oncol,2007, 46:286- 307.
[10] Leitsalu L, Alavere H, Tammesoo ML, et al. Linking a population biobank with national health registries-the estonian experience[J]. J Pers Med,2015, 5:96- 106.
[11] Cui W, Zheng P, Yang J, et al. Integrating clinical and biological information in a Shanghai biobank: introduction to the sample repository and information sharing platform project[J]. Biopreserv Biobank, 2015, 13:37- 42.
[12] Song Y, Wang P, Yu G, et al. Turning point: biobanking in China and the future of translational research[J]. Biopreserv Biobank, 2015, 13:2- 3.
[13] 王伟业,周君梅,蔡珍珍. 生物样本库的信息化管理与信息应用[J].中华临床实验室管理电子杂志, 2017, 5:24- 29.
[14] Quinlan PR, Gardner S, Groves M, et al. A data-centric strategy for modern biobanking[J]. Adv Exp Med Biol, 2015, 864:165- 169.
[15] Giffen CA, Carroll LE, Adams JT, et al. Providing contemporary access to historical biospecimen collections: development of the NHLBI biologic specimen and data repository information coordinating center (BioLINCC)[J]. Biopreserv Biobank, 2015, 13:271- 279.
[16] McDonald SA, Ryan BJ, Brink A, et al. Automted web-based request mechanism for workflow enhancement in an academic customer-focused biorepository[J]. Biopreserv Biobank,2012, 10:48- 54.
[17] Hu H, Correll M, Kvecher L, et al. DW4TR: a data warehouse for translational research[J]. J Biomed Inform, 2011, 44:1004- 1019.
[18] http://www.framinghamheartstudy.org/.
[19] http://www.wtccc.org.uk/.
[20] Tamminen S. Bio-objectifying European bodies: standardisa-tion of biobanks in the biobanking and biomolecular resources research infrastructure[J]. Life Sci Soc Policy, 2015,11:13.
[21] Vaught J. Biobanking comes of age: the transition to biospecimen science[J]. Annu Rev Pharmacol Toxicol, 2016, 56:211- 228.
[22] 中国医药生物技术协会生物样本库标准(试行)[J]. 中国医药生物技术,2011,6: 71- 80.
[23] 明星,周学迅. 自动化在生物样本库中的应用[J].中国医药生物技术, 2015,10: 498- 500.
猜你喜欢
承德医学院学报(2022年2期)2022-05-23
中学生数理化·高一版(2021年2期)2021-03-19
中国交通信息化(2018年8期)2018-11-09
中国船检(2017年3期)2017-05-18
财经(2017年2期)2017-03-10
数学学习与研究(2017年3期)2017-03-09
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
中国老区建设(2016年1期)2016-02-28
财经(2016年6期)2016-02-24
