
融合位置相似性度量的快消品电商网站推荐算法
2018-01-29 03:29王晨阳刘垣郭李华肖琳
福建工程学院学报 2017年6期
王晨阳, 刘垣, 郭李华, 肖琳
(福建工程学院 信息科学与工程学院, 福建 福州 350118)
近年来,互联网快消品市场迅速发展,涌现出一大批快消品电商网站,如阿里1688零售通、京东掌柜宝、掌合天下、惠民网、易酒批、便利宝、进货宝等。快消品电商网站主要为广大下游便利店提供一站式的采购进货服务,所以它的用户通常就是便利店。面对海量的信息,高效的推荐算法无疑将对快消品电商网站的成功起到至关重要的作用,它能够在信息过载的环境中帮助用户发现他们感兴趣的物品[1]。协同过滤推荐系统是一个已经在电子商务系统中广泛应用的一种个性化推荐算法[2]。该方法首先找到和目标用户兴趣相似的用户集合,然后根据这个集合的评分数据向目标用户推荐商品。算法的关键是用户的兴趣相似性度量准则。对用户相似性度量准则的研究有很多,如文献[1-2]在计算用户相似性度量中引入了位置信息,但是位置信息只是作为商品的一个属性,对推荐的作用较弱;文献[3]将位置信息聚类为位置簇,虽然强化了位置信息的推荐作用,但位置之间的距离所产生的推荐意义没有融入到推荐模型中。在快消品电商领域,因为快消品的流通具有区域的相似性,因此地理位置较近的便利店,他们的兴趣相似度也会相应更高。本文提出一种融合位置相似性度量的协同过滤推荐算法,根据用户的位置以及位置之间的距离算出用户的位置相似度,再与用户的兴趣相似性加权得到一个新的用户相似度,最后在一个真实的快消品电商网站数据集上验证了该算法的可行性。
1 传统的用户兴趣相似性度量方法
基于用户的协同过滤推荐算法是推荐系统中最古老的算法,包括2个步骤:1)找到与目标用户兴趣相似的最近邻居集合;2)根据最近邻居集合中用户对商品的评分向目标用户进行推荐。其中步骤1)的关键是用户相似性的计算方法。最常用的有Jaccard相似性、余弦相似性、修正余弦相似性和相关相似性[4-6]。
1.1 Jaccard相似性
给定用户u和v,令N(u)表示用户u有过评分的商品集合,N(v)表示用户v有过评分的商品集合。利用Jaccard公式计算用户u和v之间的相似度,Jaccard系数定义为N(u)与N(v)交集的大小与N(u)、N(v)并集的大小比值,定义如下。
(1)
1.2 余弦相似性
给定用户u和v,令A和B表示用户u和v对n个商品的评分向量。使用两个向量之间夹角的余弦值度量用户间的相似性。公式如下:
(2)
1.3 修正的余弦相似性
余弦相似性度量未考虑到用户评分尺度问题,如在评分区间[1-5]的情况下,对用户i来说评分3以上就是自己喜欢的,而对于用户j,评分4以上才是自己喜欢的。通过减去用户对商品的平均评分,修正的余弦相似性改善了用户评分尺度偏好问题。给定用户u和v,令I表示所有商品的集合,Ru和Rv分别表示用户u和v对商品的平均评分值,Ru,i和Rv,i分别表示用户u和v对商品i的评分,如果用户u对商品i没有评分,则Ru,i=0。使用修正余弦相似性度量用户u和用户v之间的相似性,公式如下。
(3)
1.4 相关相似性

(4)
2 融合位置相似性度量的推荐模型设计
2.1 模型概述
融合位置相似性度量的协同过滤推荐算法(collaborative filtering recommendation algorithm with the fusion of location similarity measurement,CF-FLSM)的推荐流程如图1。算法分为3步:第1步:根据目标用户的位置搜索出周边的用户集合near(N),即距离最近的用户集合,以缩小用户范围;第2步:

图1 CF-FLSM的推荐流程Fig.1 Recommendation process of CF-FLSM
在第1步中搜索出来的用户集合near(N)中,结合用户历史行为利用余弦相似性计算出用户之间的兴趣相似性,结合用户的位置信息算出用户之间的位置相似性;第3步:按照适当的权重将用户之间的兴趣相似性和位置相似性进行合并处理,得到一个新的用户相似性,用于产生最终的推荐结果。
2.2 用户位置相似性度量方法
本文分析了某快消品电商网站在福州地区的注册用户(因为快消品电商网站服务的对象是便利店,所以这里的用户就是便利店)的历史采购进货记录。图2是该地区注册用户的地理位置分布图。
随机选定N(本文实验过程中N取100)个用户,分别计算出与目标用户距离(单位:km)[0,1]、(1,2]、(2,3]、(3,5]、(5,8]、(8,10]内的用户有过共同评分商品的平均数量,得出的具有共同评分的商品数量与用户之间距离的关系如图3所示。

图2 注册用户的地理分布图Fig.2 Geographic distribution map of registered users

图3 兴趣相似性与距离的关系 Fig.3 Relationship between interest similarity and distance
从图3可知,用户之间共同评分的商品数量与用户之间的距离成反比。这说明在同一地区内,用户之间的偏好相似度对用户之间的距离是敏感的,这也符合快消品电商市场销售的现状。因此,本文提出如下度量方法计算用户之间的位置相似性:
(5)
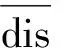
2.3 加权合并处理
将用户位置相似性度量融合到传统的用户兴趣相似性度量,两者进行加权合并处理得出一个新的用户相似性。
(6)
其中λ表示sim(u,v)dis的权重,可以根据实际情况适当调整λ的值。
2.4 推荐过程
算出用户之间的相似度后,可以根据与目标用户兴趣最相似的K个用户向目标用户推荐商品。首先可利用以下公式预测出目标用户对与目标用户最相似的K个用户有过评分但目标用户未曾评分的商品的评分预测值。
(7)
其中,S(u,k)是根据公式(6)计算出的与目标用户u兴趣最相似的K个用户的集合,N(i)是对商品i有过评分的用户集合,sim(u,v)为用户u和用户v的相似度;Rv,i为用户v对物品i的评分。
最后将评分预测值最高的前Top-N项商品向目标用户做推荐。
3 实验
3.1 实验数据
选取某快消品电商网站在福州地区的2016年真实数据来验证上面提出的算法。该数据集在该地区的每个用户都维护一个固定的地位经纬度坐标,各项数据统计值如表1所示。

表1 实验数据集Tab.1 Experimental dataset
将数据集按照用户对商品评分的时间倒序排序选取20%作为测试集,剩下的80%作为训练集。并随机选择test_U家用户作为测试用户,在训练集上计算用户的相似性,最后在测试集上分别对每个测试用户进行商品推荐预测。
3.2 评测指标
网站在做商品推荐时,通常是为用户提供一个个性化的推荐栏目,就是推荐系统里的Top-N推荐。对Top-N推荐结果进行评测的指标通常是采用准确率和召回率。
准确率评测的是最终的推荐结果中有多少比例是正确推荐的。
(8)
召回率评测的是推荐正确的商品占实际用户喜欢的商品集合的多少。
(9)
其中U为测试用户集合,就是3.1节中随机选择的测试用户数test_U;R(u)表示对测试用户u在测试集上的推荐商品集合;T(u)为测试用户u在测试集上实际喜欢的商品集合。
3.3 实验结果
在CF-FLSM和CF的实验过程中,测试用户数test_U取值为50,用户最近邻的数目near_N取值为200,用户之间的位置相似性度量权重λ取值为0.5,在推荐商品数目Top-N的不同取值下,分别算出测试用户集的平均准确率和召回率如表2、表3所示。

表2 CF-FLSM的推荐结果Tab.2 Recommendation results of CF-FLSM
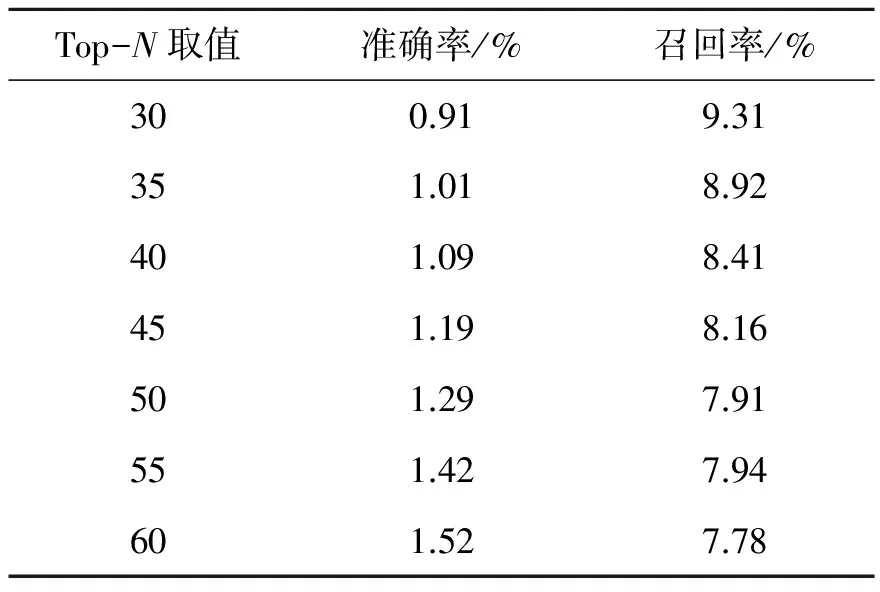
表3 CF的推荐结果Tab.3 Recommendation results of CF
两者的实验结果的比较如图4所示,本文提出的CF-FLSM相对于传统的协同过滤算法,准确率和召回率分别提高了3.74%和3.91%。

图4 CF-FLSM和CF的实验结果对比图 Fig.4 Comparison of experimental results of CF-FLSM and CF
4 结论
调研国内众多知名快消品电商平台,其注册用户通常是便利店,而便利店都有一个固定的地理位置。本文提出的融合位置相似性度量的协同过滤(CF-FLSM)推荐算法,能够有效利用位置以及位置之间的距离信息,从而提高快消品电商平台商品推荐的准确率和召回率。但是CF-FLSM在推荐的过程中并未考虑时间的因素,而快消品的流通活跃度通常和季节有关,比如啤酒饮料在夏季会相对比较活跃,而白酒红酒在冬季会相对比较活跃。在快消品电商网站推荐算法中加入时间维度,是将来的研究方向。
[1] 申园园,余文.一种基于位置服务信息的移动推荐模型[J].计算机应用与软件,2016,33(12):203-206.
[2] 王付强,彭甫镕,丁小焕,等.基于位置的非对称相似度量的协同过滤推荐算法[J].计算机应用,2016,36(1):171-174,180.
[3] 郑慧,李冰,陈冬林,等.基于位置簇的移动生活服务个性化推荐技术[J].计算机应用,2015,35(4):1148-1153.
[4] 项亮.推荐系统实践[M].北京:人民邮电出版社,2012:45-64.
[5] 李春,朱珍民,高晓芳,等.基于邻居决策的协同过滤推荐算法[J].计算机工程,2010,36(13):34-39.
[6] 彭德巍,胡斌.一种基于用户特征和时间的协同过滤算法[J].武汉理工大学学报,2009,31(3):24-28.
[7] 马胡双,石永革,高胜保.基于特征增益与多级优化的协同过滤个性化推荐算法[J].科学技术与工程,2016,16(21):272-277.
[8] 张春永,陈群.一种基于LBS的移动个性化推荐系统[J].科学技术与工程,2011,11(30):7439-7442,7447.
[9] Cacheda F, Formoso V, Femandez D, et al. Comparison of collaborative filtering algorithms: limitations of current techniques and proposals for scalable, high-performance recommender systems[J]. ACM Transactions on the Web,2011,5(1):1-33.
[10] Liu H, Hu Z, Mian A, et al. A new user similarity model to improve the accuracy of collaborative filtering[J].Knowledge-Based Systems,2014,56(3):156-166.
猜你喜欢
数学物理学报(2022年5期)2022-10-09
河北画报(2020年8期)2020-10-27
传媒评论(2019年6期)2019-10-14
中学数学杂志(高中版)(2016年6期)2017-03-01
生活用纸(2016年6期)2017-01-19
浙江大学学报(工学版)(2016年2期)2016-06-05
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
职业技术(2015年8期)2016-01-05
中国科技信息(2015年24期)2015-11-07
声学技术(2014年1期)2014-06-21
