
大学英语机考的多元概化理论分析
2018-01-25 10:02:09王天剑
商丘师范学院学报 2018年2期
王 天 剑
(贵州财经大学 外国语学院, 贵州 贵阳 550004)
一、 引言
随着计算机应用的逐渐普及,大学英语考试方式也开始向机考(计算机辅助考试)方向转变。机考不仅可以节约资源,节省阅卷工作量,而且可以通过随机组卷,减少学生舞弊的机会。为了保证生成大量不同试卷,机考测试前需要准备容量充足的题库。目前高校英语机考题库来源各不相同,部分学校采用的是商业机构提供的专用题库,更多学校采用的是任课教师集体创建的题库。题库的质量直接影响到考试的信度和效度,为考查某高校教师自建大学英语机考题库的质量,本研究借助概化理论,对一次英语机考成绩进行多元分析。
概化理论从本质上讲是一种信度理论[1]1。它是在方差分析(ANOVA)与经典测量(Classical Test Theory: CTT)技术基础上,逐步拓展而来的理论体系[2] [3]1。按照CTT,测量结果包含真分数与测量误差两部分。利用ANOVA,概化理论进一步将误差分解为不同来源成分,考查各自比重[4] [5]393-402,并估算概化系数以及可靠性指数。这两种参数类似于CTT的信度,其中概化系数用于显示,测量结果用于将对象排序时的稳定性(相对信度);可靠性指数用于衡量,测量结果用于了解对象绝对水平时的可靠性(绝对信度)。如下公式(1)(2)分别用于概化系数及可靠性指数计算:
(1)
(2)
ρ2和Ф代表概化系数与可靠性指数,σ2(τ)是测量对象的全域分方差,σ2(δ)系相对误差方差;σ2(Δ)系绝对误差方差[6]。
概化分析涉及一系列专业概念。主要包括:(1)侧面。它是构成测量条件的诸多因素(类似于方差分析中的自变量),例如,测量地点、测量时间、测量方式、评分员特征、受试者特征、测量题目等均可视为侧面,只要研究者有意探究这些因素的影响。(2)观察设计。它是指测量中,侧面之间形成的不同结构关系,如交叉关系(一个侧面的每个水平,均与其他侧面的每个水平相碰)、套嵌关系(一个侧面的不同水平,仅与另一个侧面的一个水平结合)、复杂的交叉套嵌组合关系,等等。(3)估计设计。估计设计回答的问题是,各个侧面是以多少个水平估计多大的全域(分三种情况:有限全域中的水平全部用于估计,有限全域中的水平被随机抽样用于估计,无限全域中的水平被随机抽样用于估计)。
在类型上,概化分析包括一元概化分析和多元概化分析,前者用于单变量研究,后者聚焦于多变量研究[7]。在程序步骤上,一元或者多元概化分析都涵盖G研究(概化研究)和D研究(决策研究)两部分。前者能在观测全域上展示各种方差来源及其比重;后者能在概化全域上,借助G研究的方差比重,通过调整测量条件,展示信度变化,从而探究优化测量设计的手段[8] [9] [10]。因其在测量中的重要意义,概化理论与经典测量理论和项目反应理论被一并称为三大高级测量理论。美国心理学学会、教育研究学会和国家教育测量委员会联合提出的《教育和心理测量标准》(Standards for Education and Psychology Testing)[11]15-17中明确提出,在建立观察和测量程序的效度与信度时,必需参照概化理论。
近年来,国外和国内有不少学者采用概化理论,考查语言测试的方法、语言测试概念的内在结构、测试的信度等。Lin[12]采用蒙特卡洛模拟数据,考查了评分员面试中,不同概化分析设计的适用性。结果显示,当评分员方差相对较小时,完全交叉设计和区组套嵌设计同样有效;当评分员方差相对较大时,只能采用区组套嵌,因为交叉设计倾向于高估信度。Sawaki[13]同时采用验证性因子分析与概化分析,探究了口语能力的内在结构。结果发现,口语能力是一种多元复合构念(涉及发音、词汇、连贯、组织、语法等子成分)。胡加圣、孙海洋[14] [15]等学者,利用概化理论考查了外语测试中的信度及其优化措施等问题。综观国内外研究可知,概化理论在语言测试研究中具有广泛的应用价值。面对不断普及的机考,有必要对其进行概化理论分析,及时披露问题并予以解决。本文借助多元概化理论,分析大学英语机考的质量问题。
二、研究设计
(一)数据
研究以某校400名学生的大学英语听力机考成绩为分析对象。每名学生的成绩包含10篇短对话听力理解分数(每篇5分,共计50分)和两篇短文听力理解分数(每篇25分,共计50分)。短对话考查的主要是基于短时记忆和简单思维的听力理解,短文考查的主要是基于长时记忆和综合思维的听力理解。
(二)分析方法
研究采用二变量、单侧面多元概化分析。观察设计为交叉设计:p×i,p表示考生,i表示试题(侧面)。考生和试题视为从无限全域中随机抽取的样本,用于估计该全域参数(估计设计)。数据处理借助mGENOVA 软件进行,它是Brennan[7]编写的多元概化分析专用工具。
(三)结果
1.成绩的分布特征
在进行概化分析之前,首先对400名学生在短对话和短文两个变量上的成绩进行描述统计,以展示其分布特征(表1)。

表1 学生成绩在不同变量上的描述统计(n=400)
观察表1中的最低分和最高分可知,各变量得分两极分化严重,这表明学生个体差异明显。
2.多元概化分析结果
多元概化分析主要在两种试题变量上展开,分析包括G研究以及D研究两部分。
(1)G研究结果
借助G研究,可以获得不同效应(考生、试题、考生与试题的交互作用)在短对话和短文两个变量上的方差等指标,结果如表2所示。
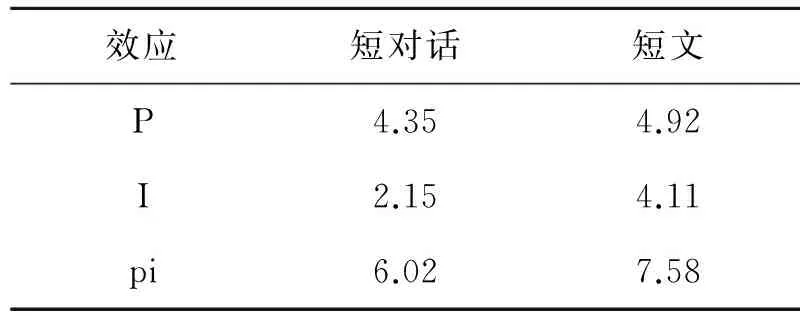
表2 学生、题目和交互作用在两个变量上的方差
根据表2可知,考生在两个变量上的方差分别是4.35和4.92,试题在二变量上的方差依次是2.15和4.11,交互作用的方差是6.02和7.58。由于方差大小标志着影响的大小,可以推断,交互作用对听力成绩的影响高于学生水平的影响。交互作用影响较大,意味着不同学生在不同试题上,得分或失分的倾向存在较大反差(如甲生在第一篇短对话上得分很高,在第二篇上很低,乙生在第一篇上得分很低,在第二篇上得分很高)。
题目难度在短对话上的方差虽然不大,但在短文上的方差与考生的对应方差接近,表明试题难度对短文成绩的影响不能忽略。考生对成绩的影响不占优势,表明考试未能有效反映学生的英语听力水平。
(2) D研究结果
第一,短对话和短文测量结果的精确度
根据其全域分方差、相对误差方差和绝对误差方差,可以检查短对话和短文的测量精确度。表3呈现的是相关结果。

表3 短对话和短文测量结果的精确度
观察表3可知,短对话的概化系数为0.63,可靠性指数为0.55;短文的概化系数为0.65,可靠性指数为0.57。这些指标反映着两个变量测量的精确度(信度),由于低于0.80这一理想标准,测量结果不够稳定。
第二,短对话和短文整合在一起的测量精确度
按照短对话和短文两变量所占比重(短对话分值比重为50%,短文为50%),设定权重系数,对测量结果进行整合,可得短对话和短文整合在一起(全域合成分)的测量精确度(表4)。

表4 短对话和短文全域合成分测量精确度
根据表4,全域合成分概化系数和可靠性指数分别为0.68和0.59,与单个变量测量精确度(表3)相比略有提高。这表明,短对话和短文两个变量得分合并起来代表听力水平,具有一定的合理性。但是两个信度指标仍未达到0.80。
第三,短对话和短文对全域合成分的贡献
虽然两变量的赋分显示,其权重均为50%,但两者对全域合成分方差的实际贡献如何仍需D研究检验。表5比较了赋分权重与实际贡献。
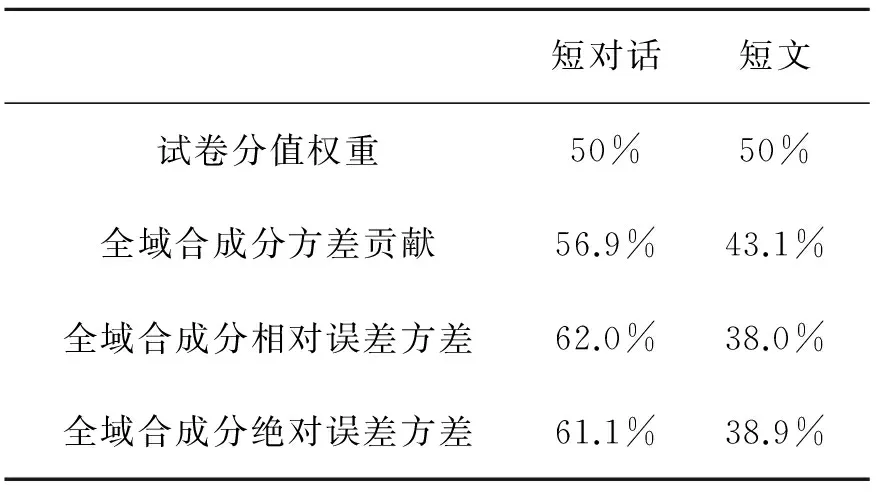
表5 短对话和短文对全域合成分的贡献
表5显示,短对话对全域合成分方差的贡献(56.9%)略微高于赋分,而短文的贡献(43.1%)稍微低于其赋分。短对话的测量误差所占比重也较大(相对和绝对误差方差分别为:62.0%和61.1%)。 这表明短对话和短文的权重有待调整。
第四,权重优化后的全域合成分测量精确度
鉴于短对话和短文赋分与实际贡献的差别,调整两变量权重,进一步分析信度变化,结果呈现于表6。
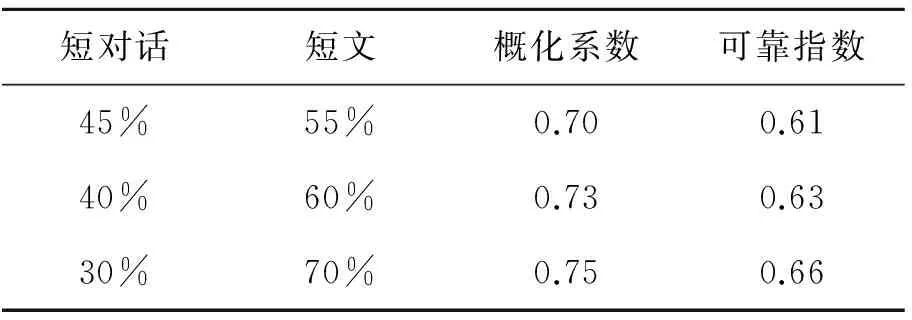
表6 调整权重对信度的影响
根据表6,在合理范围内,改变短对话和短文的权重,概化系数和可靠性指数虽有提升趋势,但变化很慢。由于两个变量是听力课程测试的两个平行特质,不易进一步改变权重。可见,通过调整赋分权重,不能走出测量不稳定的困境。
第五,优化试题数量后的全域合成分测量精确度
改变试题数量是尝试调整测量精确度的常用手段。表7展示的是短对话和短文在权重各保持30%和70%的情况下,调整任务数量后可预期的对应信度。
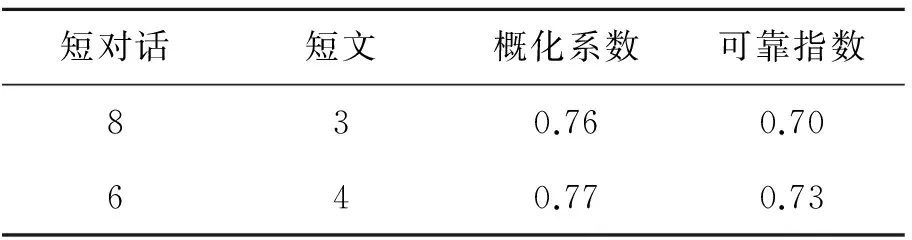
表7 调整题量对信度的影响
基于表7可知,在可操作范围内,适当调整试题数量结构,能够使信度有所提高。但即使在这种情况下,信度仍然低于理想水平。可见调整题量仍不能完全解决信度问题。
三、讨论
本文借助多元概化分析,考查了大学英语听力机考的信度。结果显示,对于成绩的影响,考生与试题的交互作用明显高于考生效应,试题难度效应也不容忽略。交互作用和题目难度效应的影响在短文方面尤为突出。无论是在短对话和短文两个变量层面,还是在整个听力测试层面,考试的信度都偏离了理想标准。在可操作范围内,适度调整试题权重和题量,虽然能在一定程度上弥补信度的不足,但不能从根本上解决测量信度问题。
本研究与其他相关研究存在分歧。在一般测试中,成绩的主要变异来源是考生,而不是试题或者交互效应。Bae[16]对双语儿童不同语言技能的概化分析中发现,考生水平对成绩变异的影响高于其他因素。在一项元分析研究中,In'nami等[17]考查了17项概化研究(涉及22个数据集),结果发现,平均而言考生是成绩变异的主要来源,其次是考生与试题的交互作用,试题效应是比较微小的变异来源。事实上,任何有效度和信度的测试中,成绩都应当反映被试技能,被试应属于最主要的成绩变异影响因素。
本研究披露的交互作用对于成绩的影响, 远远高于考生作用,题目难度效应不容小视。可能是因为采用机考时计算机系统随机生成的试卷缺乏同质性,不同学生在同一道试题中,接触的具体任务难度波动较大,不同试卷难度波动较大。试题难度的影响,主要表现在绝对测量信度方面;考生与试题交互作用的影响,同时降低相对测量信度以及绝对测量信度。当成绩信度较低时,考试的效度更无从谈起。
由于随机组卷的素材源于题库,本研究暴露的机考问题,深层原因可能是题库质量不合格。在缺乏可操作的标准以及必要的技术条件下,教师集体创建的题库,很容易出现同类任务难度不一的现象。这样的题库用于机考随机生成试卷,很容易引起较高的交互作用和试题难度效应,降低考试信度和效度。
四、结论
本研究考查了某高校大学英语听力机考的信度,结论如下:
1.在缺乏同质题库条件下,大学英语听力机考中采用随机组卷,会导致信度不足,无法客观反映学生听力水平;
2.在缺乏同质题库条件下,调整试题数量和赋分权重,可以在一定程度上缓解信度危机。
解决大学英语听力机考信度效度不足的问题,随机组卷需要以严格意义上的同质题库为依托。建议在建立大学英语听力题库时,命题者要通过定性、定量、实证研究结合的方法,对听力材料进行语料分析[18],对试题难度进行准确区分。在缺乏同质题库条件下,不宜使用计算机随机组卷,而应采用相同试卷。采用相同试卷,这样可以在一定程度上降低考生与试题的交互作用,减少变异来源,提高成绩的信度和效度,增加考试的公平公正性。
[1]Shavelson R J, Webb N M.Generalizability theory: A primer[M].Sage Publications, 1991.
[2]Brennan R L.A Perspective on the History of Generabability Theory [J].Educational Measurement Issues & Practice, 1997(4).
[3]Cardinet J, Johnson S, Pini G.Applying generalizability theory using EduG[M].Routledge, 2011.
[4]Klerk S D, Eggen T J H M, Veldkamp B P.A blending of computer-based assessment and performance-based assessment: Multimedia-Based Performance Assessment (MBPA).The introduction of a new method of assessment in Dutch Vocational Education and Training (VET)[J].Giornale Italiano Di Pedagogia Sperimentale, 2014(1).
[5]Urbano J, Marrero M, Martín D.On the measurement of test collection reliability[C]// International ACM SIGIR Conference on Research and Development in Information Retrieval.ACM, 2013.
[6]Robert L.Brennan.Generalizability Theory and Classical Test Theory[J].Applied Measurement in Education, 2010(1).
[7]Brennan R L.Manual for mGENOVA (Version 2.1)[J].Occasional Paper, 2001(50).
[8]黎光明.概化理论G研究方差分量及其变异量估计影响因素[J].心理学探新, 2016(5).
[9]Gebril A.Bringing reading-to-write and writing-only assessment tasks together: A generalizability analysis[J].Assessing Writing, 2010(2).
[10]Srikaew D, Tangdhanakanond K, Kanjanawasee S.English speaking skills assessment for grade 6 Thai students: an application of multivariate generalizability theory[J].International Journal of Psychology: A Biopsychosocial Approach, 2015 (16).
[11]American Education Research Association (AERA), American Psychological Association(APA), National Council on Measurement in Education (NCME).Standards for Education and Psychology Testing[M].Washington,DC: American Psychological Association, 2002.
[12]Lin C K.Working with Sparse Data in Rated Language Tests: Generalizability Theory Applications.[J].Language Testing, 2017(34).
[13]Sawaki Y.Construct Validation of Analytic Rating Scales in a Speaking Assessment: Reporting a Score Profile and a Composite.[J].Language Testing, 2007(3).
[14]胡加圣.最新概化理论工具EduG及其外语教学应用分析[J].外语学刊, 2014(6).
[15]孙海洋.概化理论和多层面Rasch模型在建立“职前中学英语教师口语考试模型”中的应用[J].外语与外语教学, 2011(5).
[16]Bae, Jungok|Bachman, Lyle F.An Investigation of Four Writing Traits and Two Tasks across Two Languages.[J].Language Testing, 2010(2).
[17]In'nami, Yo|Koizumi, Rie.Task and Rater Effects in L2 Speaking and Writing: A Synthesis of Generalizability Studies.[J].Language Testing, 2016(3).
[18]王天剑.基于语料库的中美企业英文简介文本特征研究[J].鲁东大学学报(哲学社会科学版), 2016(6).
猜你喜欢
中学生数理化·七年级数学人教版(2021年3期)2021-07-22 03:20:52
中国注册会计师(2020年7期)2020-11-26 17:45:38
中学生数理化·七年级数学人教版(2020年10期)2020-11-26 08:24:52
中学生数理化·七年级数学人教版(2019年10期)2019-11-25 07:34:00
中学生数理化·八年级数学人教版(2019年11期)2019-09-10 21:47:40
留学(2019年5期)2019-06-11 10:38:19
水利科技与经济(2017年2期)2017-04-22 02:34:24
留学生(2016年8期)2016-10-15 03:06:08
心理学探新(2015年4期)2015-12-10 12:54:02
江苏农业科学(2014年6期)2014-08-12 08:48:54
