
基于Hadoop的云教学资源平台
2018-01-17 00:52刘丹梁丽曾燕张泽天李莉
长春理工大学学报(自然科学版) 2017年6期
刘丹,梁丽,曾燕,张泽天,李莉
(长春理工大学 计算机科学技术学院,长春 130022)
目前,随着国家对教育信息化重视程度不断增加,教育资源量也迅猛增加,呈现爆炸式的增长。传统的教学资源平台在数据检索、存储以及数据分析等均面临着新的挑战。从事教学资源平台资源存储可扩展性及资源服务可靠性的研究工作是十分有意义的。云计算技术的出现,为教学资源的共享提供了更好的方式,同时也有效地降低了用户的硬件投入。利用Hadoop技术设计的云教学资源平台,具有教学资源存储可扩展、实时查询、高并发读写性、用户请求协调和强大的海量数据处理能力等优势,更好地为资源使用者和资源管理者服务和共享平台,最终达到提升辅助教学的能力。
1 Hadoop技术介绍
分布式文件系统HDFS和分布式计算框架MapReduce是Hadoop平台的两大核心构件。它们实现了数据的分布式存储和处理等重要操作。HDFS实现对数据的分布式存储,具有故障检测、流式读取数据以及高度容错性等特性。它采用Master/Slave架构,由控制节点NameNode和数据节点DataNode组成。其中,NameNode节点部署在物理机上,DataNode节点部署在集群中其他物理机上。当访问HDFS中的某文件时,需要从NameNode获取该文件的数据块位置,然后再从DataNode中获取所需数据。其中NameNode只负责存储DataNode的信息和映射关系,并不参与实际数据块的存储和传输。
MapReduce是一种数据处理的计算模型,实现对数据的分布式处理,用于大数据集的并行计算。在这个模型中,程序员主要完成Map和Reduce两个函数的编写,以键值对的形式输入到Map和Reduce函数,并且Map的输出就是Reduce的输入。Reduce的输出文件就是整个MapReduce编程模型计算的最后结果,并且存储在HDFS文件系统中。MapRe-duce执行流程如图1所示。
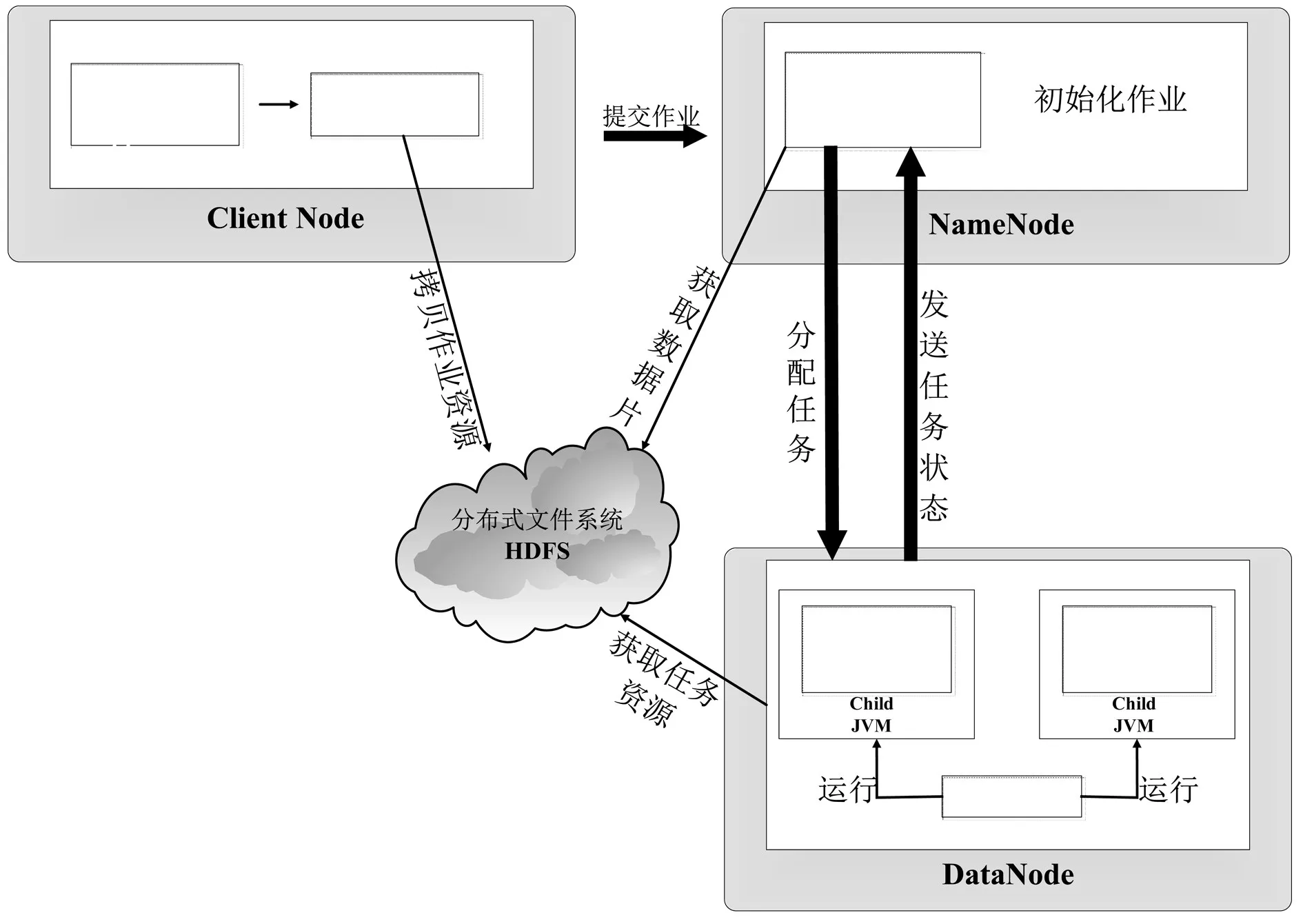
图1 MapReduce执行流程
另外,HBase、Zookeeper也分别是Hadoop的子项目。HBase依赖于HDFS和ZooKeeper,具有分布式、可扩展性和面向列而存储等特点,是一种非关系型数据库。ZooKeeper是Hadoop的分布式协调服务,为分布式应用程序提供一致性服务,并且采用松耦合交互方式,使得在交互过程中,参与者不需要彼此了解。
2 云教学资源平台设计
本文研究的基于Hadoop的云教学资源平台,其总体目标在于构建学生和老师之间沟通平台、学生自主学习平台。对上传的教学资源进行统一管理和分布式处理以及对平台日志进行分析统计,使资源使用者和资源管理者能够方便的利用各类资源进行学习和交流,使管理员能够更好的维护平台。
云教学资源平台中主要包含教学资源使用者、教学资源管理者和系统管理员三种角色。资源使用者通过在线学习、交流、问答和教学资源的下载从而进行课程的学习;资源管理者通过资源的上传进行高效授课和学术交流;管理员可以添加用户、删除用户以及查看日志分析统计结果,更好的掌握该平台的使用情况。基于Hadoop的云教学资源平台的总体架构如图2所示。
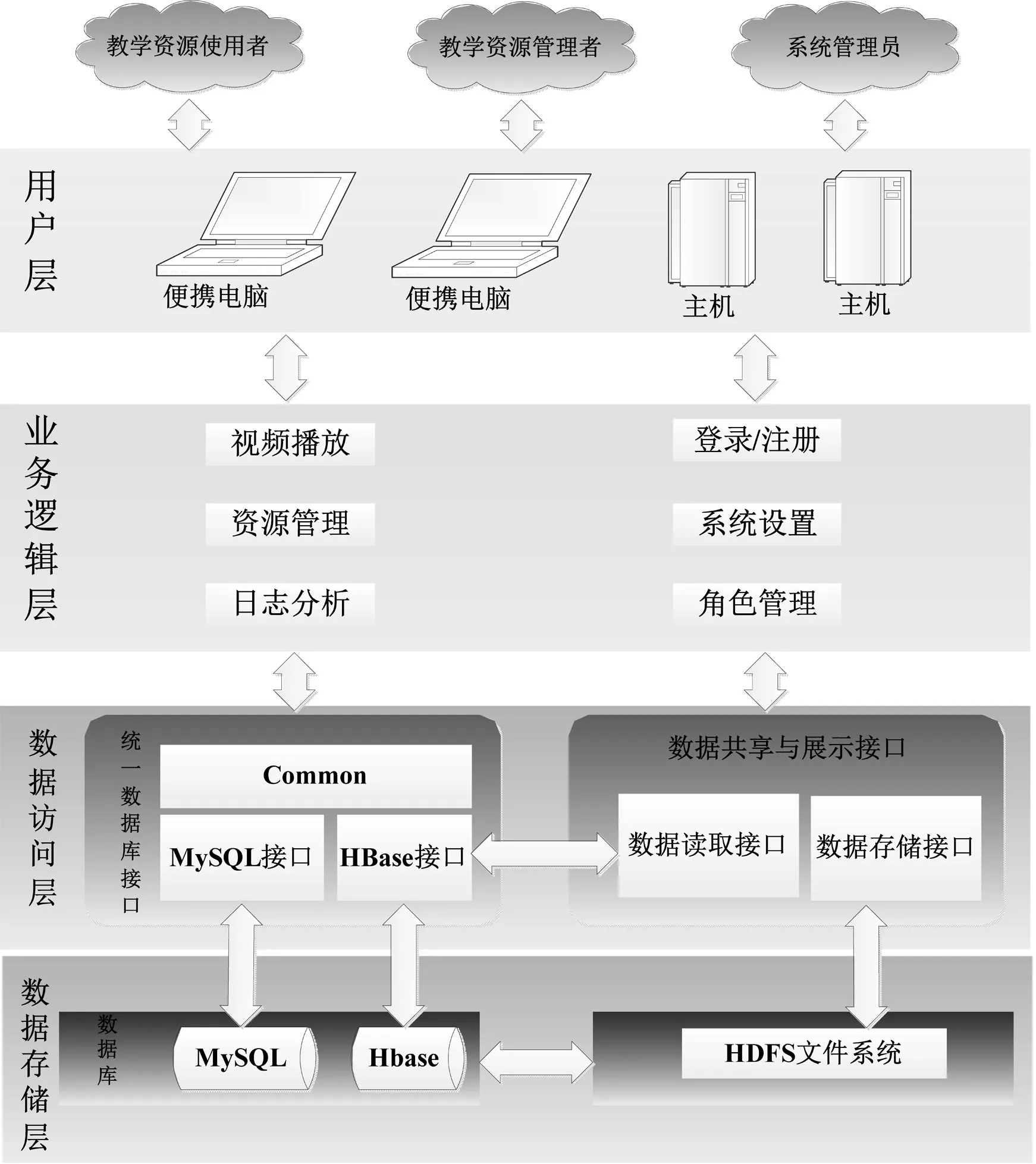
图2 云教学资源平台架构
该本平台的主要功能是存储并管理海量的教学资源,建立一个优质的教学资源环境,方便师生之间的教学互动和反馈,其功能模块结构图如图3所示。
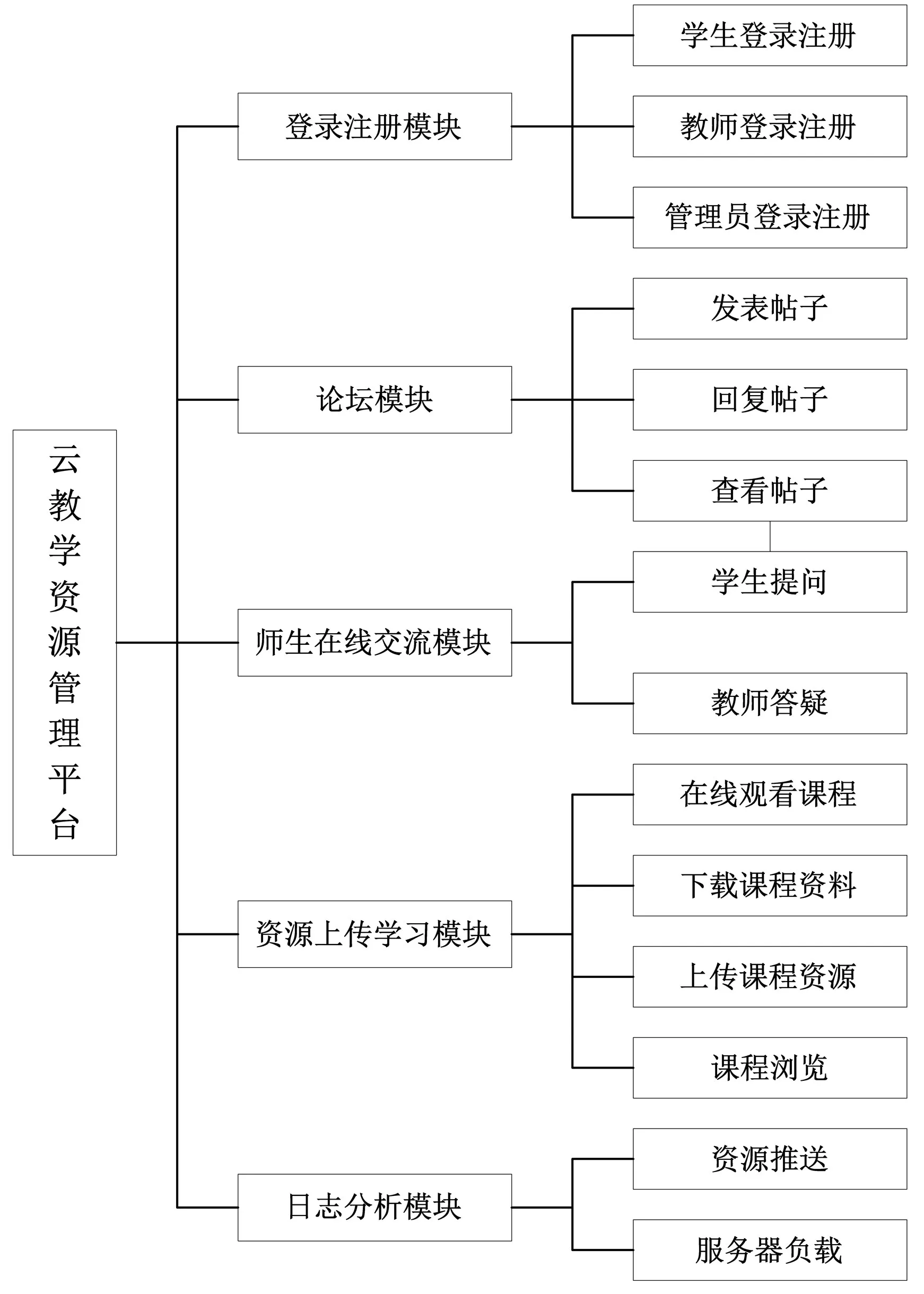
图3 云教学资源管理平台功能模块图
3 云教学资源平台实现
云教学资源平台实现的第一步,就是要搭建其集群环境。主搭建的主要过程为:集群软硬件环境准备和架构设计、SSH无密码验证配置、Hadoop集群配置和HBase及ZooKeeper安装配置。
3.1 软硬件环境参数设定
在云教学资源平台实现过程中,通过VMware Workstation 12 Pro创建了由三台服务器所构成的Hadoop集群。其中,一台服务器作为master,部署HDFS的NameNode节点、MapReduce的JobTracker节点和HBase的HMaster节点,另外两台服务器作为slave,部署HDFS的DataNode节点、MapReduce的TaskTracker节点和HBase的HReginServer节点,三台虚拟机的详细信息如表1所示。
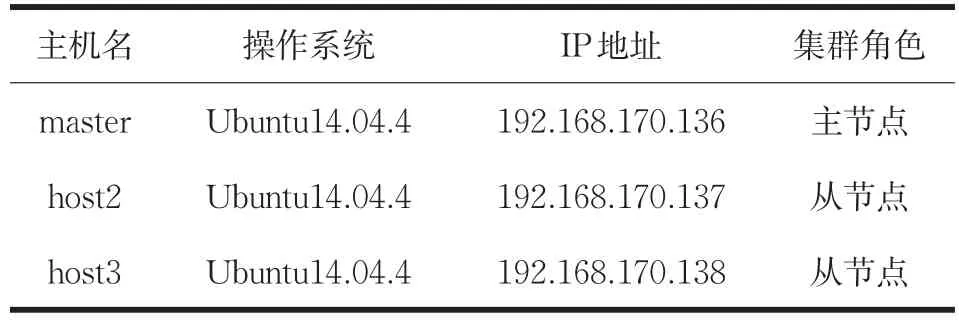
表1 虚拟机详细信息
本平台安装的集群相关软件如下表2所示。

表2 集群软件详细信息
为了保证每台机器的主机名和IP地址能正确解析,需要在hosts文件中加上集群中其他节点的IP地址和主机名的映射关系,以master节点为例,其配置如表3所示。

表3 hosts配置文件
3.2 SSH无密钥访问配置
Hadoop集群之间通过SSH协议传输数据[15],从而安全的控制整个集群的开启和关闭。登录master主机后,执行ssh-keygen-t rsa命令,生成id_rsa和id_rsa.pub两个文件。然后将id_rsa.pub文件中的内容放到authorized_keys中。依照此原理slave主机执行相同的操作,将id_rsa.pub拷贝到authorized_keys中。最后,使用scp生成authorized_keys的合并文件。这样就可以实现SSH无密码登录其他节点。
3.3 Hadoop集群配置
从Apache官网上下载hadoop-1.1.2.tar.gz安装包,并将其解压到/usr/目录下,修改配置文件hadoop-env.sh、 core-site.xml、 hdfs-site.xml、 mapred-site.xml、masters和slaves。
(1)hadoop-env.sh文件配置如表4所示。

表4 hadoop-env.sh文件配置
(2)core-site.xml文件配置如表5所示。

表5 core-site.xml文件配置
(3)hdfs-site.xml文件配置如表6所示。

表6 hdfs-site.xml文件配置
(4)mapred-site.xml文件配置如表7所示。
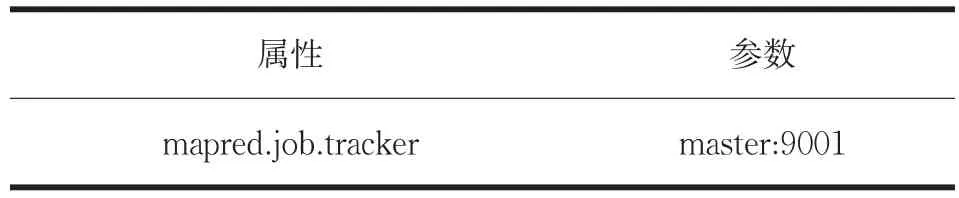
表7 mapred-site.xml文件配置
利用scp命令将NameNode中配置好的hadoop文件夹拷贝到另外两个DataNode中,实现数据同步。
scp-r/usr/hadoop/ hadoop@host2:/home/hadoop/hadoop
scp-r/usr/hadoop/ hadoop@host3:/home/hadoop/hadoop
3.4 HBase及ZooKeeper安装
ZooKeeper安装步骤如下:
(1)解压并配置zoo.cfg:解压安装文件到/usr/目录中,并拷贝一份zoo_sample.cfg文件作为zoo.cfg配置文件,如表8所示。
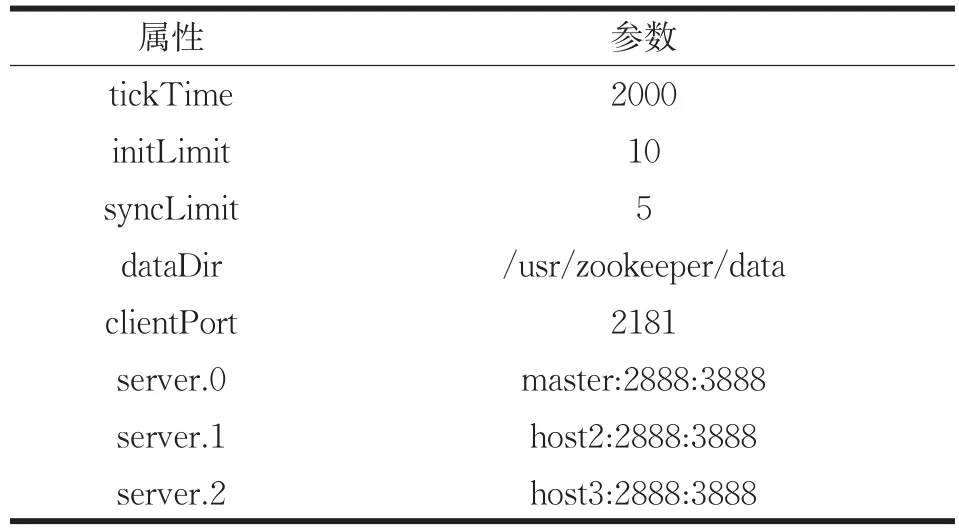
表8 zoo.cfg文件配置
(2)设置myid:在myid文件中,通过一正整数值,作为唯一标示。因此将NameNode的myid文件内容设置为0,DataNode的myid文件内容分别设置为1,2。
(3)利用scp命令将NameNode上配置好的ZooKeeper目录拷贝到其他两个节点,并修改myid文件中对应的标号。
scp-r/usr/zookeeper/hadoop@host2:/home/hadoop/zookeeper
scp-r/usr/zookeeper/hadoop@host3:/home/hadoop/zookeeper
(4)启动并查看状态:在/usr/zookeeper/bin目录下输入zkServer.sh start启动ZooKeeper集群。
HBase的安装步骤如下:
(1)解压并配置hbase-env.sh文件:将hbase安装包解压,配置安装目录下的conf/hbase-env.sh文件。文件配置如下:
export JAVA_HOME=/usr/java
export HBASE_MANAGES_ZK=false
(2)配置conf目录下的hbase-site.xml,文件配置如表9所示。
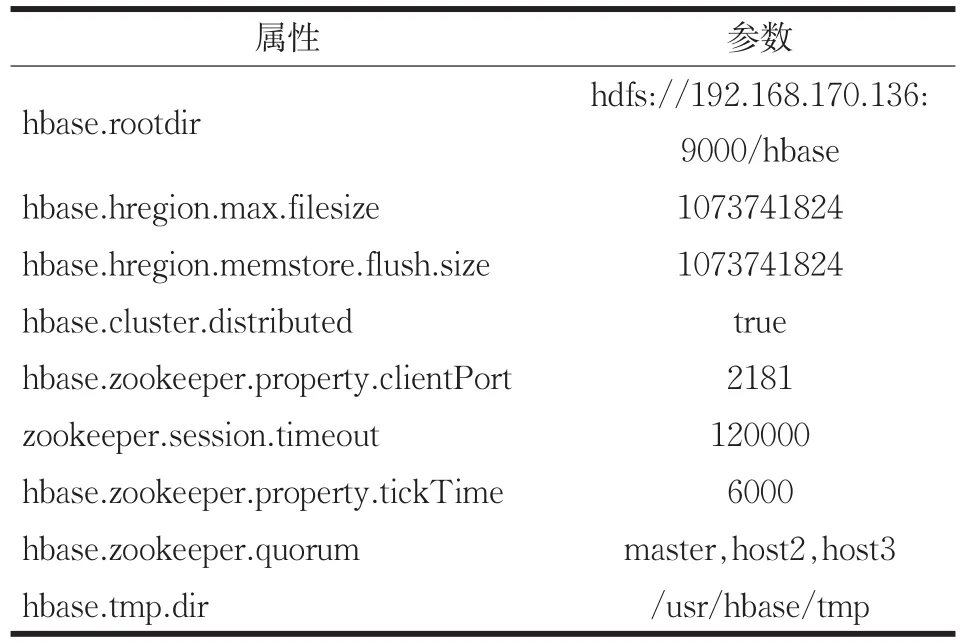
表9 hbase-site.xml文件配置
(3)配置conf目录下的regionservers文件,设置运行HBase的具体机器,一行指定一台机器。
(4)编辑/etc/profile文件,在文件末尾添加hbase安装目录。其配置过程如下:
export HBASE_HOME=/usr/hbase
export PATH=$PATH:$HBASE_HOME/bin
(5)将NameNode配置好的hbase通过scp命令拷贝到DataNode。
scp-r/usr/hbase/ hadoop@host2:/home/hadoop/
scp-r/usr/hbase/ hadoop@host3:/home/hadoop/
(6)启动hadoop和hbase来验证安装的正确性,首先启动hadoop集群,然后在hdfs中新建HBase的数据存储目录,最后在hbase安装目录的bin目录下输入./start-hbase.sh启动hbase。用jps命令查看启动的进程列表,分别如表10、11所示。

表10 NameNode进程列表

表11 DataNode进程列表
(7)使用hbase shell命令进入hbase,就可以使用hbase数据库了。
3.5 主要模块实现
(1)资源浏览模块
用户可以通过以下模式来浏览资源:顺序查看所有资源的详细信息;按照资源类别分别浏览资源的详细信息;根据自己的喜好内容进行相应资源的查找;浏览最热资源的详细信息;浏览最新资源的详细信息,如图4所示。

图4 教学资源资源浏览界面
(2)日志分析模块
日志管理模块可以查看每个页面的访问量、页面每小时的访问量以及用户的访问设备等信息。在服务器上设置定时任务,将平台日志文件定时上传到HDFS文件系统中,采用MapReduce计算模型对日志文件进行分析统计,最终以可视化界面展现给管理员,使管理员能够更加轻松的管理该平台。日志分析流程如图5所示。
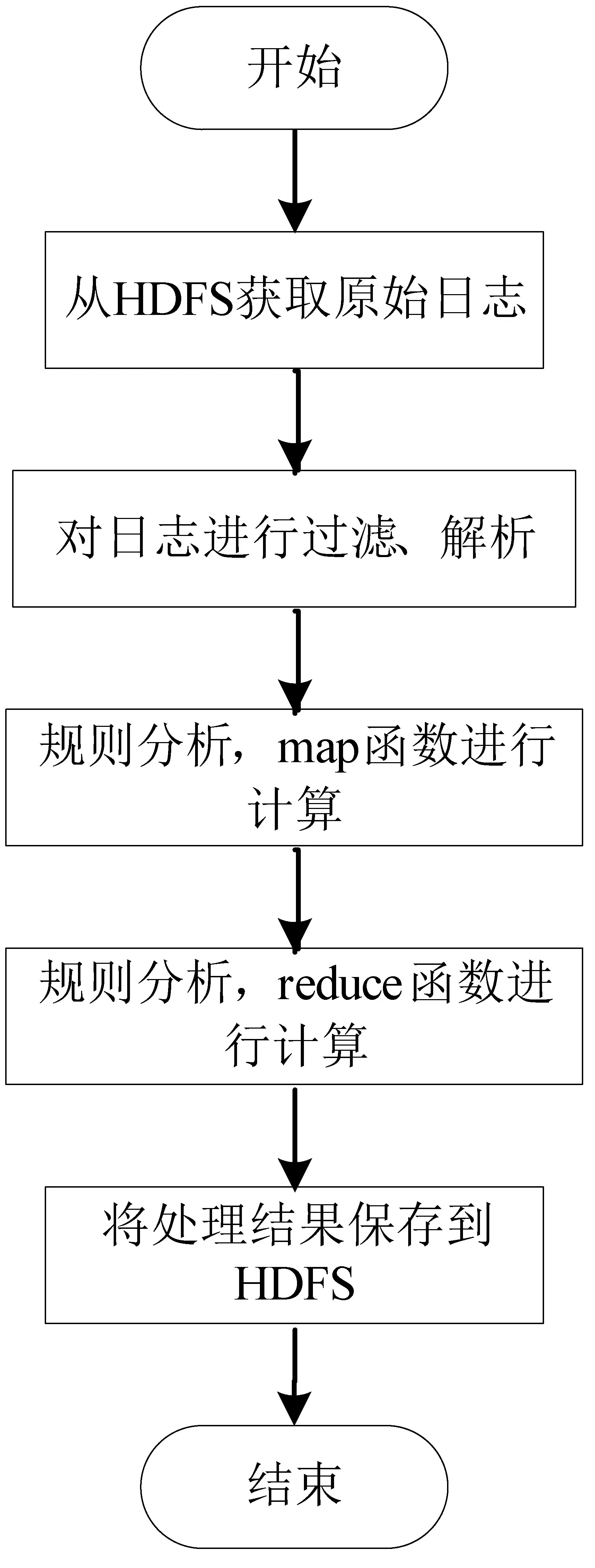
图5 日志分布式计算流程图
4 结语
本文将新兴的云计算引入高校教学中,设计并实现了基于Hadoop的云教学资源平台。该平台具有较强的实时性、良好的交互性,是一个开放式的资源管理平台,能够使教学资源使用者和教学资源管理者得到方便、快捷、稳定的服务,减轻系统的维护成本。这给高校存储、管理资源提供了新思路和新途径。
[1]Gantz J,Reinsel D.The digital universe in 2020:big data,bigger digital shadows,and biggest growth in the far east[M].IDC iView:IDCAnalyze the future,2012.
[2]崔园.基于HDFS的分布式存储系统的研究与实现[D].成都:电子科技大学,2016.
[3]Shvachko K,Kuang H,Radia S,et al.The Hadoop distributed file system[C].MASS Storage Systems and Technologies.IEEE,2010:1-10.
[4]Wang J,Wang T,Yang Z,et al.SEINA:A stealthy and effective internal attack in Hadoop systems[C].International Conference on Computing,NetWorking and Communications.IEEE,2017.
[5]Gupta M,Patwa F,Sandhu R.Object-tagged RBAC model for the Hadoop ecosystem[M].Data and Applications Security and Privacy XXXI,2017.
[6]Gupta M,Patwa F,Sandhu R.POSTER:Access control model for the Hadoop ecosystem[C].ACM on Symposium on AccessControlModels and Technologies.ACM,2017:125-127.
猜你喜欢
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
解放军医院管理杂志(2020年5期)2020-02-14
疯狂英语·爱英语(2020年9期)2020-01-07
军事运筹与系统工程(2019年4期)2019-09-11
思维与智慧·上半月(2018年9期)2018-09-22
电子制作(2018年11期)2018-08-04
安徽农业科学(2018年32期)2018-05-14
小学生(看图说画)(2017年6期)2017-11-06
中国交通信息化(2017年3期)2017-06-08
