
一种基于改进互信息的文本分类方法
2018-01-17 03:16:42董露露
合肥师范学院学报 2017年6期
董露露
(安徽广播电视大学 安徽继续教育网络园区管理中心,安徽 合肥 230022)
科技革命的不断深入、互联网的迅速发展为人们提供了越来越多的传播、获取信息的渠道,但同时也带来“信息爆炸”的巨大挑战[1]。虽然信息形式多种多样,但是80%的信息都是由文本组成的,因此文本成为高效地组织管理信息的关键,文本分类技术应运而生。文本分类是根据文档的内容及其属性将其划分到一个或多个预先定义的类别中的过程,作为文本信息挖掘领域的重要研究内容,其目前已被广泛应用于搜索引擎、网页分类、用户意图分析、抽取数据符号和邮件过滤等多个领域[2]。
文本分类中,通常采用VSM对文本信息进行结构化表示[3]。VSM将文本信息转化成更有利于计算机理解和处理的词条-文本矩阵,但该矩阵的高维稀疏性不仅增加了分类器计算开销,而且影响分类精度。因此,需要使用特征选择方法对文本集进行降维[4-6]。
特征选择是从原始特征集合中选出对分类最有效的一部分子集的过程,它能有效去除噪声特征,减少特征空间[7-8],从而提高分类精度。常用的特征选择方法有:互信息(Mutual Information, MI)、信息增益(Information Divergence, IG)、期望交叉熵(Expected Cross Entropy, ECE)、χ2检验(Chi-square, CHI)等[8-9],这些方法分别从不同角度衡量特征项对分类的重要程度。其中,MI是一种常用的特征选择方法,它将特征的存在与否给类别的正确判断所带来的信息量作为特征重要性的衡量标准,具有时间复杂度低、使用方便等优点。但传统互信息特征选择方法仅考虑了文档频,没有考虑词频因素,并且忽略了负相关特征的潜在影响,在平衡数据集上分类效果较好,但在不平衡数据集上的分类效果并不令人满意[10-15]。
本文对传统互信息特征选择方法进行深入分析,并提出一种改进的互信息特征选择方法,克服了传统互信息倾向于低频词、忽视负相关特征的缺陷。在不平衡语料集上的实验表明,改进的互信息特征选择方法能够有效改善分类性能,且明显优于目前主流的多数特征选择方法。
1 相关工作
自机器学习技术被成功应用于文本分类以来,自然语言处理领域的研究人员针对特征选择方法在文本分类中的应用进行了一系列的研究,这些研究主要集中在以下三个方面。
首先,对现有较成熟的特征选择方法进行性能对比。比较有代表性的是Yang Y[16]和Mladenic D[17]的工作。前者使用LISF和KNN分类器,分析并比较了文档频(Document Frequency, DF)、IG、MI、文本证据权(Weight of evidence for text, WET)、CHI和ECE共6种方法在平面文本分类问题中的性能。后者针对等级文本分类问题,使用Navie Bayes分类器,分析并比较了DF,ECE、WET及优势率等方法。由于特征选择算法对训练集和分类器的依赖性较大,因此不同研究者针对不同分类应用采用不同的训练过程和分类器可能会导致各个特征选择算法的性能评价结果差异较大。
其次,在传统特征选择方法的基础上引入新的因子作为改进。刘海峰等人[18]针对传统互信息的不足,引入权重因子、词频因素、特征项位置权重,分别基于特征与类别相关度、词频、位置对互信息进行改进。廖莎莎等人[19]将概念特征引入,提出基于概念屏蔽层的特征选择方法。樊小超等人[20]基于词频、文档频和类别相关度对传统互信息进行了改进。
再者,直接提出新的特征选择算法。徐燕等人[21]提出一种用概率分布刻画的基于区分类别能力的特征选择方法的表达形式。单晓丽等人[22]对ECE函数进行修改后对每个类别分别进行特征选择,然后再将各类特征项按相同或不同比例合并用于分类。
以上研究在文本分类实验中都被证明是合理有效的,但它们并未没有考虑数据集不平衡的情况。
在不均衡文本分类方面,针对特征选择的研究很多,多数是在现有特征选择方法的基础上进行改进。Zheng Z等人[23]将特征选择方法分为两种:只选择正例特征(单面方法)和正反例特征同时选择(两面方法),发现在不均衡数据集下,两面方法并不是最优的,然后提出一种从正例、反例中合理选择特征的方法,实验证明这种方法是有效的。陆玉昌等人[24]强调高频词的作用,即在特征选择方法中加入p(w)因子,进行特征权重的调整。
综上所述,在不平衡数据集上进行特征选择时需要考虑两方面因素,一个因素倾向于选择高频词,另一方面不倾向于高频词,注重包含类别信息较多的特征。本文从这两点出发,对传统互信息特征选择方法进行改进,强调词频作用的同时注重负相关特征的作用,选取包含类别信息较多的特征,从而提高不平衡语料集上的文本分类效果。
2 基于改进互信息的文本分类算法
2.1 传统互信息特征选择方法
作为信息论中的重要概念,MI衡量的是特征之间互相依赖的程度[25]。将此概念引入到特征选择,可用来度量特征项存在与否给类别的正确判断带来的信息量[26]。对于给定的特征项与类别c,它们之间的互信息计算公式如下:
(1)
其中,P(tj∩c)为特征项tj和类别c同时出现的概率,即类别c中包含tj的概率,P(tj)表示特征项tj在整个语料库中出现的概率,P(c)表示类别c出现的概率。互信息值越大,表明特征项所带来的信息量也就越大,其和类别之间的共存关系就越强。当特征项是判定类别归属的最佳特征时,互信息达到最大值,也就是说,当且仅当某篇文档属于当前类别时,词项出现在该文档中。
设c1,c2,...,cr表示文档集中类别的集合,则特征项与文档集的互信息计算公式如下:
(2)
其中,k表示类别总数。特征选择时,对每个特征计算其与文档集的互信息值并进行排序,可选取预定数目个度量值最高的特征项,或者设定阈值N,选取度量值大于N的特征项作为最终的特征子集,该子集可用来进行下一步的文本表示。
从公式可以看出,传统互信息特征选择方法具有如下不足:
(1)仅考虑了特征项在某个具体的类别以及整个训练集中的文档频率,忽略了词频因素,从而倾向于选择低频词,可能造成更具有代表性、与类别依存关系更强的特征项被过滤掉。
(2)特征项与某类别的互信息值为负数说明该特征项与当前类别负相关,即其在当前类别中很少或者不出现,而在其他类别中出现。这样的特征项对类别的正确判断具有重要作用,而公式却将正相关和负相关的作用中和了,最终影响到特征子集的选择。特别是在数据集不平衡的情况下,分类精度会受到很大影响。
(3)在文本分类中,文档集不平衡是一种常见现象,而互信息度量特征项的信息量是在假定训练集类别分布相对均匀的情况下进行的,因此,当类别分布不均匀时,互信息取得的分类效果偏低。
2.2 改进的互信息特征选择方法
2.2.1 基于词频的互信息改进
互信息特征选择方法在度量特征项的信息量时仅考虑了文档频,造成大量特征项的互信息值相同,同时倾向于选择低频词,使得对分类价值更大的特征项被过滤掉从而影响了分类效果。比如,分析公式(1)可知,当P(tk|ci)=P(tj|ci)时,如果P(tk)>p(tj),则MI(tk,ci)>MI(tj,ci)。但是,与低词频的特征项相比,具有高词频的特征项对于文本的正确分类而言具有更重要的作用,前者甚至可能是影响分类效果的噪声特征;当P(tk)=P(tj)时,若特征项tk在类ci的每篇文档中都只出现一次,tj在类ci的90%的文档中均出现了10次,则MI(tk,ci)>MI(tj,ci)。但很显然,tk和tj相比,后者与类别ci的相互依存关系更大,更能代表ci类。为解决上述问题,改善不平衡数据集上的分类效果,本文引入“平均词频率”因子,其计算公式如下:
(3)
其中,tfci,m表示特征项在类ci的第m篇文本中出现的次数;nci表示类ci的文本数;k表示类别总数;N表示文本总数。α值越大,说明特征项在相应类别中出现的频率越大,与该类别的相互依存关系也就越强,也就越能代表该类别。
2.2.2 基于绝对值最大的互信息改进
互信息忽视了负相关性特征项对分类的作用。若特征项在某类别上的互信息值为负,说明其与当前类别的相互依存关系较弱,但这并不代表该特征项对其他类别的区分不起作用或者起反作用。实际上,互信息值为负的特征项对于类别的正确区分所起的作用是不可忽视的。为了避免公式对正、负相关特征作用的中和,改善互信息在不平衡数据集上的分类效果,采用如下方法:
对选定的特征项t,取它和各个类别的互信息值中绝对值最大的那个为其最终的互信息值,计算公式如下:
(4)
综合考虑词频因素及正、负相关特征对文本分类的影响,引入平均词频率因子及绝对值最大,得到一种新型互信息特征选择方法NMI(New Mutal Information , NMI),其计算公式可以表示为:
(5)
(6)
2.3 基于改进互信息的文本分类算法
文本分类的一般流程为:首先,对语料库进行预处理,分词并去除对分类无用或作用较小的特征项;其次,使用特征选择方法,选择对分类最有价值的特征子集,对数据集进行降维操作;再次,将文档集向量化,得到文档-特征项矩阵;最后,使用分类器对未知文本进行类别预测。其中,特征选择和分类算法是分类系统的核心部分。
本文研究和实现的是一种基于改进互信息的文本分类方法,步骤如下:
步骤1文本预处理。
1.对文本进行分词。使用复旦大学的开源分词系统对训练集和测试集进行分词处理;
2.去除停用词。停用词是指代词和语气助词等常用词,它们出现频率很高但对分类而言作用不大甚至没有作用。本文采用停用词字典的方法将所有文档中的停用词去除;
3.删除低频词。统计词频,去除词频低于3的特征项。
步骤2特征选择。使用改进的互信息特征选择方法对训练集的每个特征进行评估,对所有的特征按照其评估分的大小进行排序,选取预定数目的最佳特征作为最终的特征子集。
步骤3文档向量化表示。利用特征子集分别对训练集和测试集进行向量表示,得到相应的文档-特征项矩阵。
步骤4训练分类器。使用训练集的文档-特征项矩阵进行分类训练,构建SVM分类器。由于本实验中的文档均用空间向量表示,本文选取基于向量空间模型的SVM分类器,具体使用的分类工具是LibSVM[27]。LibSVM是台湾大学林智仁(Lin Chih-Jen)教授等开发设计的一个操作简单、易于使用、快速有效的通用支持向量机软件包。
步骤5预测未知文本的类别。利用步骤4得到的SVM分类器进行类别预测,得到测试文本所属类别。
3 实验结果及分析
3.1 数据集
本文实验数据选自复旦大学中文文本分类语料库,该语料库分为训练集和测试集两个部分。从中选取8个类别共14265篇文档组成不平衡语料集,其中训练文档7190篇、测试文档7075篇,文档类别分布如下表所示:

表1 不平衡语料集分布
3.2 评估方法
本文选择查准率P、查全率R及F1值来衡量算法在每一个类别上的分类性能[28],选择宏平均查准率、宏平均查全率值、宏平均F1来衡量算法在整个数据集上的分类性能。
查准率P是分类器返回的结果中被正确分类的文本所占的比例,计算公式如下:
(7)
查全率是被分类器正确判为该类的文本在该类总文本中的比例,计算公式如下:
(8)
其中,A表示正确分类的文本数,B表示被判到该类的错误类别的文本数,C表示本属于该类却被分类器判为其它类的文本数。
F1值是对正确率和召回率的综合:
(9)
宏平均指对于每一个类别的性能指标的平均值,它将类别等同看待,避免了结果评测被大类支配的问题。
宏平均F1:
(10)
其中,Pi是分类器在类别i上的查准率,Ri是分类器在类别i上的查全率,|c|是类别总数。
3.3 实验结果比较与分析
为了证明本文所提方法的有效性,在相同的实验环境下,本文分别对NIM、MI、IG、ECE、CHI进行了文本分类实验,实验结果如表2和图1所示。
特征维数不同时,特征选择方法所取得的分类效果也不同。从表2和图1可以看出:当特征维数仅为1000时,传统互信息的效果最差,而改进的互信息最好,这说明即使选择的特征数目很少,本文所提方法也能够取得相对较好的效果。随着特征维数的增加,互信息、IG、CHI和ECE的宏平均F1值c呈缓慢上升趋势,但均低于NMI。当特征维数为7000时,NMI的宏平均F1值为90%,IG的宏平均F1值达到最大值88%,与NMI接近,ECE为83%,比NMI低7%。特征维数继续增加时,IG和ECE的宏平均F1值呈下降趋势,这是因为此时越来越多的不相关特征项被用来表示文本。当特征维数增至8000时,CHI的宏平均F1值取得最大值72%,但此时其与NMI仍有20%的差距。NMI在特征维数为10000时取得最大宏平均F1值95%,比MI高出27%。总体而言,本文提出的NMI的宏平均F1值呈上升趋势,且在10000维之后趋于稳定。

表2 不同特征选择方法的宏平均F1值
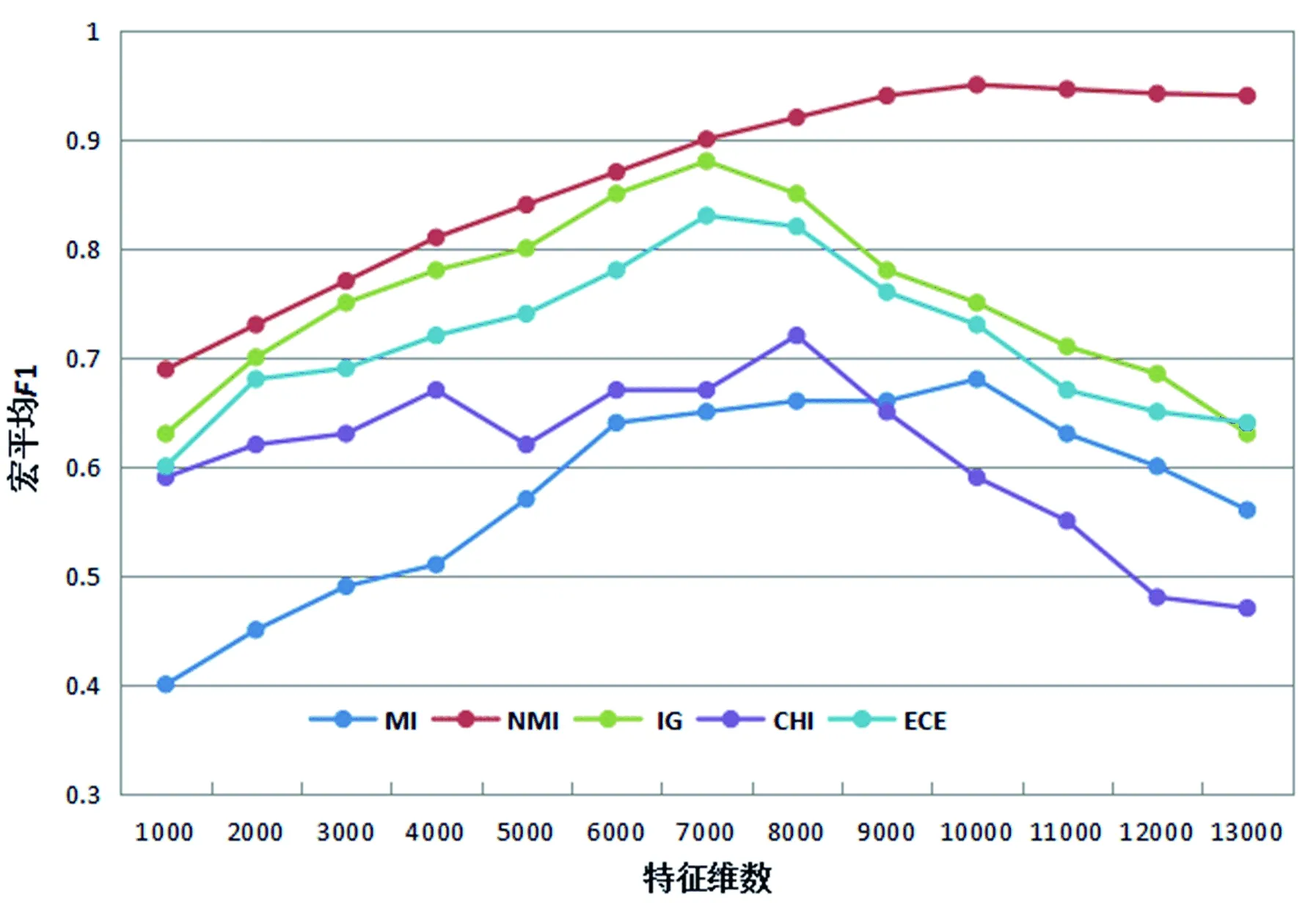
图1 NMI与传统特征选择方法宏平均F1值对比
表3列出了特征维数为1000时,传统互信息和NMI在各个类别上的查准率、查全率和F1值。其中,传统互信息在“历史”类别上的查准率和查全率以及F1值均最低,分析原因主要是传统互信息忽略了词频因素和负相关特征对分类的作用,导致其在数据集分布不平衡的情况下,在文本数最少的“历史”类别上效果最差。改进的互信息比传统互信息在查准率、查全率和F1值上都有非常大的提高,这说明本文对互信息的改进是合理可行的。
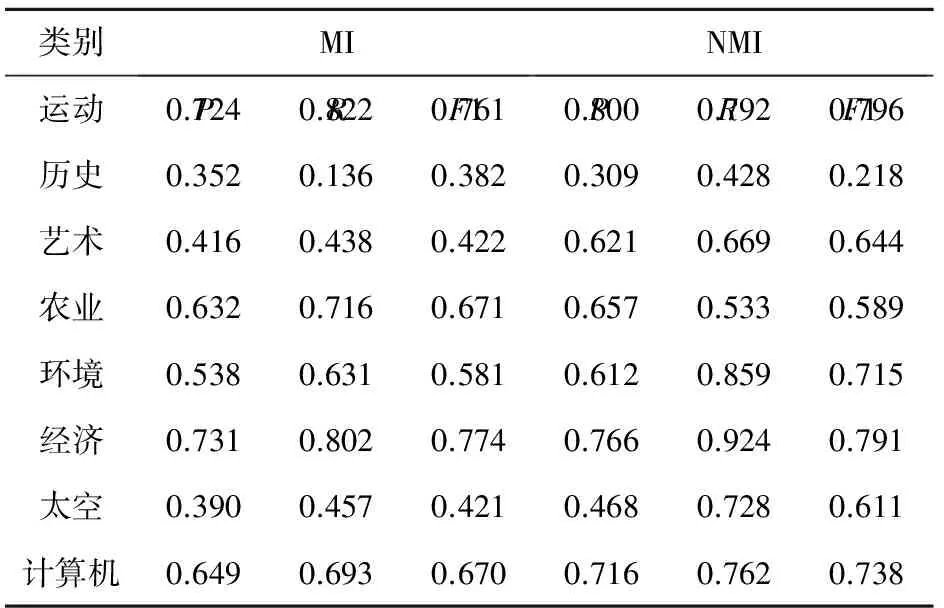
表3 MI和NMI在各个类别上的分类效果
由上述实验结果可以得出如下结论:
(1)和传统互信息相比,改进的互信息能显著提高分类性能;
(2)改进的互信息不仅明显优于传统互信息,而且能够取得比传统互信息、IG、CHI、ECE更好的分类结果,是一种有效的特征选择方法。
4 结束语
特征选择是文本分类的重要环节。作为一种常用的特征选择方法,互信息存在未考虑词频因素、忽视负相关特征对分类的作用等缺陷。本文针对传统互信息特征选择方法的不足,引入平均词频率因子以加强特征项的词频的作用,采用绝对值最大准则确定特征项的互信息值以加强负相关特征的作用。在不平衡数据集上的实验结果表明,改进的互信息能够明显改善分类效果。本文所提方法是基于统计的,下一步工作将研究如何从语义角度提取更有价值的特征项,并将其应用于文本分类、搜索引擎等多个领域。
[1] 何力,丁兆云,贾焰,等. 大规模层次分类中的候选类别搜索[J]. 计算机学报,2014,37(1):41-49.
[2] 刘露,彭涛,左万利,等. 一种基于聚类的PU主动文本分类方法[J]. 软件学报,2013,24(11):2571-2583.
[3] 张娇鹏,王峰,梁吉业. 特征选择:一种面向数据取值更新的批处理机制[J]. 小型微型计算机系统,2017, 38(2):264-267.
[4] 张进,丁胜,李波. 改进的基于例子群优化的支持向量机特征选择和参数联合优化算法[J]. 计算机应用,2016,36(5):1330-1335.
[5] Yi Guo, Zhiqing Shao, Nan Hua. Automatic text categorization based on content analysis with congnitive situation models[J]. Information Sciences, 2010, 180(5): 613-630.
[6] 张延祥,潘海侠. 一种基于区分能力的多类不平衡文本分类特征选择方法[J]. 中文信息学报,2015,29(4):111-119.
[7] Zhang N, Ruan S, Lebonvallet S, et al.Kernel feature selection to fuse multi-spectral MRI images for brain tumor segmentation[J].Computer Vision and Image Understanding, 2011, 115(2): 256-269.
[8] Azar A T, Elshazly H I, Hassanien A E, et al. A random forest classifier for lymph diseases[J]. Computer Methods and Programs in Biomedicine, 2014, 113(2): 465-473.
[9] Christopher D.Manning, Prabhakar Raghavan, Hinrich Schutze. Introduction to Information Retrieval[M]. Beijing: Posts&Telecom Press, 2010: 188-193.
[10] 林琪,张宏,李千目. 一种基于MA-LSSVM的封装式特征选择算法[J]. 南京理工大学学报,2016,40(1):10-16.
[11] Zhao Xi, Deng Wei, Shi Yong. Feature selection with attributes clustering by maximal information coefficient[J].Procedia Computer Science, 2013, 17: 70-79.
[12] Yamada M, Jitkrittum W, Sigal L, et al. High-dimensional feature selection by feature-wise kernelized lasso[J]. Neural computation, 2014, 26(1): 185-207.
[13] 段宏湘,张秋余,张墨逸. 基于归一化互信息的FCBF特征选择算法[J]. 华中科技大学学报:自然科学版,2017,45(1):93-100.
[14] 董红斌,滕旭阳,杨雪. 一种基于关联信息熵度量的特征选择方法[J]. 计算机研究与发展,2016,53(8):1684-1695.
[16] Yang Y, Pedersen J. A comparative study on feature selection in text categorization[C]//Proceedings of the ICML. 1997, 97: 412-420.
[17] Mlademnic, D., Grobelnik, M. Feature Selection for unbalanced class distribution and Naive Bayees[A]. Proceedings of the Sixteenth International Conference on Machine Learning[C]. Bled: Morgan Kaufmann,1999: 258-267.
[18] 刘海峰,陈琦,张以皓. 一种基于互信息的改进文本特征选择[J]. 计算机工程与应用,2012,48(25):1-4.
[19] 廖莎莎,江铭虎. 中文文本分类中基于概念屏蔽层的特征提取方法[J]. 中文信息学报,2006,20(3):22-28.
[20] 樊小超,张重阳,邓雄伟. 基于互信息的文本特征加权方法[J]. 计算机工程与应用,2015,51(13):145-148.
[21] 徐燕,李锦涛,王斌,等. 基于区分类别能力的高性能特征选择方法[J]. 软件学报,2008,19(1):191-201.
[22] 单丽莉,刘秉权,孙承杰. 文本分类中特征选择方法的比较与改进[J].哈尔滨工业大学学报,2011,43(1):320-324.
[23] Zheng Z, Wu X, R Srihari. Feature selection for text categorization on imbalanced data. SIGKDD Explorations, 2004, 6(1): 80-89.
[24] 陆玉昌,鲁明羽,李凡,等. 向量空间中单词权重函数的分析和构造[J]. 计算机研究与发展,2002,39(10):1205-1210.
[25] Lin Y. , Hu X., Wu X. Quality of information-based source assessment and selection[J]. Neurocomputing, 2014, 133(8): 95-102.
[26] 徐峻岭,周毓明,陈林,徐宝文. 基于互信息的无监督特征选择[J]. 计算机研究与发展,2012,49(2): 372-382.
[27] Chang C C, Lin C J. LIBSVM: a library for support vector machines[J]. ACM Trans on Intelligent Systems and Technology, 2011, 2(3): 27-65.
[28] 樊兴华,孙茂松. 一种高性能的两类中文文本分类方法[J]. 计算机学报,2006,29(1):124-131.
猜你喜欢
园林科技(2021年3期)2022-01-19 03:17:48
电子制作(2017年23期)2017-02-02 07:17:06
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
西北工业大学学报(2015年4期)2016-01-19 03:31:47
读者·校园版(2015年7期)2015-05-14 13:11:40
电测与仪表(2015年9期)2015-04-09 11:59:22
弹箭与制导学报(2015年1期)2015-03-11 15:32:31
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
图书馆论坛(2014年8期)2014-03-11 18:47:59
振动工程学报(2014年4期)2014-03-01 01:15:41
