
纠删码存储系统单磁盘错误重构优化方法综述
2018-01-12 07:19傅颖勋文士林舒继武
计算机研究与发展 2018年1期
傅颖勋 文士林 马 礼 舒继武
1(北方工业大学计算机学院 北京 100144)
2(清华大学计算机科学与技术系 北京 100084)
(mooncape1986@126.com)
随着云计算的迅猛发展,许多依托互联网的大数据应用开始涌现,数据量呈爆炸式地增长.已有调查报告显示,2015年全球服务器共产生了8.61 ZB的大数据,在此后的10年里,存储服务器的总量还将增长10倍[1].由于磁盘是当前云存储/数据中心中的主要存储介质,而它每年发生错误的概率在1.7%~13%之间[2],这意味着每年都有大量的磁盘发生错误.因此,现有存储系统需要在磁盘错误的情况下保障数据的可靠性,并继续提供存储服务.
目前,用于提升存储系统数据可靠性的技术主要有多副本技术和可靠性编码技术2种,其中多副本技术具有数据高可用性的特点,通常被用于数据访问密集型的存储系统中[3].可靠性编码技术包括网络编码和纠删码两大类.其中,网络编码主要应用于数据通信领域,直到近几年才开始被引入存储系统[4];纠删码则是存储系统中常用的可靠性编码技术.
随着存储系统的兴起,数据逐渐变得比存储介质更加重要,纠删码因高存储利用率、低存储开销等特点,被广泛应用于各种存储系统中.到了大数据时代,一方面,由于多副本机制要占用大量的存储空间,已逐渐不适应数据中心等大规模存储系统的需求,越来越多的存储系统开始采用纠删码技术,以保障数据的可靠性[5-7];另一方面,存储系统中磁盘错误的问题也越来越突出.当磁盘发生不可修复的错误后,存储系统需要利用其它磁盘中的冗余信息重构所有失效数据.在有一定规模的云存储/数据中心中,每天都有大量的磁盘发生错误,因此,如何快速重构错误磁盘中的失效数据,已成为当前存储系统中的核心问题之一.学术界和工业界对此非常重视,也产生了大量的研究成果,例如用于优化现有纠删码重构效率的RDOR方法[8]、SIOR方法[9]以及专门用于提升重构效率的LRC码[10]、zigzag码[11]等.由于单磁盘错误在所有磁盘错误中占据了99.75%以上的比例[12],现有的研究主要针对单磁盘错误下的数据重构效率进行优化.
本文从目前存储系统对纠删码技术的需求出发,首先介绍了纠删码的一些重要术语与定义[13],接着介绍了单磁盘错误重构技术的混合优化原理,并详细阐述了近几年关于单磁盘错误重构优化的研究成果,最后指出了未来的研究方向.
1 纠删码概述
1.1 重要术语与定义
1) 数据(data).由原始用户产生的一系列信息,通常以文件的形式存放在计算机系统中.
2) 冗余(redundant).为了提高计算机系统的可靠性,人们在存储数据信息的同时,也会额外存放一些由数据信息计算而来的校验信息,这些额外存放的信息则被称为冗余信息.
3) 元素(element).一簇固定大小的存储单元,用于存放数据内容或冗余信息.一般情况下,存放数据内容的元素被称为数据元素,存放冗余信息的元素则被称为校验元素,例如:图1中的d0,0是数据元素,p0,4是校验元素.

Fig. 1 An example of one stripe图1 条带的例子
4) 失效元素(lost element).当系统中存在磁盘错误时,错误磁盘中的所有元素均为失效元素.
5) 条带(stripe).在纠删码领域中,条带是最小的逻辑单位,它由一系列数据元素和校验元素组成,各条带之间的编码关系相互独立,即:在1个条带内,所有的校验元素均由当前条带中的数据/校验元素计算而来,且条带内的所有数据元素都不被用于计算其他条带中的校验元素.图1给出了包含6磁盘的RDP码的1个条带.
6) 条块(strip).条带中的每1列被称为1个条块(图1中的Di与Pi都是条块),当纠删码被应用到实际存储系统中时,各条块会被映射到不同的物理磁盘上.因此,存储系统中的磁盘错误,逻辑上可以看成是条块失效.
7) 存储利用率(storage usage rate).数据信息占当前已使用存储空间的比例.在纠删码中,存储利用率等于存储系统中的数据总量除以已使用的存储空间总量.
8) 容错能力(fault tolerance).能够容忍的最大失效条块数.若某纠删码在任意f个条块同时失效的情况下,能够还原所有数据信息,且至少存在一种f+1个条块失效的情况,使得该纠删码无法还原所有数据信息,则称该纠删码的容错能力为f.
9) 条带栈(stack).由于一些特殊的原因,存储系统在将各条块映射到物理磁盘时,通常会采用一些特殊的映射机制,条带栈是用来表示由条块映射到物理磁盘的完整机制.图2给出了一种常见的条带栈的例子.该条带栈采用循环左移的映射方式,以减轻横式编码校验盘读写负载过重的问题.

Fig. 2 An example of one typical stack图2 典型条带栈的例子
10) 磁盘错误(disk failure).磁盘因硬件故障等因素,导致数据失效的情况.
11) 单磁盘错误重构(single disk failure recovery).针对单个磁盘错误,利用剩余数据/冗余信息重构错误磁盘中的所有内容.
1.2 典型的纠删码
目前的主流纠删码可根据校验元素的生成方式分为2类:基于伽罗华域(GF(2n))运算[14]的纠删码和基于异或运算的纠删码.基于伽罗华域运算的纠删码的主要特征在于,其编码过程的所有运算都在伽罗华域中进行,包括RS (Reed-Solomon)码[15]、LRC (local reconstruction codes)码[10]、stair码[16]、SD (sector-disk)码[17]等.其中,RS码是最早的纠删码,其容错能力可以根据存储系统的需要无限扩充,且具有MDS (maximum distance separable)属性[13],即拥有理论最优的存储利用率;LRC码是一种被广泛应用在微软等企业级云存储的纠删码技术,可提升存储系统降级读性能;SD码和stair码是新型纠删码,它们不但考虑了磁盘错误,同时还针对磁盘的某些扇区错误进行了优化.
由于伽罗华域中的乘法运算具有很高的计算复杂度,因此,基于伽罗华域运算的纠删码的编/解码效率相对较低.相比之下,由于基于异或运算的纠删码在编/解码过程中仅使用“异或”运算,因此拥有很高的编/解码效率.根据校验元素的分布情况,基于“异或”运算的纠删码可分为横式编码和纵式编码2类.其中,横式编码的典型特征是数据元素和校验元素分别存放在不同的条块内,包括RDP (row -diagonal parity)码[18]、blaum-roth码[19]、evenodd码[20]、liberation码[21]、liber8tion码[22]、广义RDP码[23]、star码[24]、柯西RS码[25]等.其中,RDP码、evenodd码、liberation码、liber8tion码为RAID-6 (redundant array of independent disks)编码,能容任意2个磁盘错误;star码可以看成一种由evenodd码派生而成的编码,能容任意3个磁盘错误.广义RDP码的限制条件较多,但具有较好的容错能力,在某些特定的条件下甚至能容8个磁盘错误.横式编码通常能够构建于任意数量的磁盘之上,但是,它们通常无法获得理论最优的编/解码计算复杂度,以及理论最优的单数据元素更新复杂度.
纵式编码通常将数据元素和校验元素混合存放在相同条块中,典型的有X码[26]、HDP (horizontal- diagonal parity)码[27]、H码[28]、HV (horizontal-vertical)码[29]、D码[30]、hover码[31]、weaver码[32]等.其中,X码、HDP码、H码、HV码和D码都是RAID-6编码且拥有理论最优的存储利用率,但它们的容错能力相对较低,仅能容任意2个磁盘同时出错;hover码和weaver码是高容错编码,可以达到较高的容错能力,但存储利用率较低.相比于横式编码,纵式编码的编/解码计算复杂度、单个数据元素的更新复杂度通常能够达到理论最优,但难以构建于任意数量的磁盘之上[33].图3给出了1个包含5磁盘的liberation码的例子.

Fig. 3 5-disks Liberation code图3 5-磁盘Liberation码
1.3 纠删码的生成矩阵
在纠删码中,校验元素可以用数据元素乘1个矩阵来表示,这个矩阵也被称为纠删码的生成矩阵(generation matrix).在纠删码的编码过程中,矩阵加法用“异或”运算代替,乘法用伽罗华域中的“乘运算”代替.特别地,当生成矩阵中的所有元素均为“0”或者“1”时,伽罗华域“乘运算”可以转换为逻辑运算中的“与”操作,由此产生的生成矩阵也被称为“点阵(bitmatrix)”,相应的纠删码就是上文曾提到的基于“异或”运算的编码.一般来说,纠删码生成矩阵由上下2部分组成:上半部分是1个单位矩阵,下半部分则是编码矩阵.根据矩阵乘法原理,纠删码中数据元素与生成矩阵相乘所得到的积,便是存放在系统中所有的数据元素与校验元素.图4给出了图3所示的5磁盘liberation码的生成矩阵.

Fig. 4 Generation matrix for erasure code图4 纠删码的生成矩阵
2 混合重构思想
目前,单磁盘错误重构的优化主要基于混合重构思想.本节先介绍重构相关的等式,然后再给出混合重构思想的基本原理.
2.1 重构等式
在基于“异或”运算的纠删码中,由于生成矩阵每行中“1”所对应的数据元素与该行对应的校验元素的异或和为0,因此可以用“等式”表示.这些等式又称“原始等式”[34].例如图3所示的5磁盘Liberation码中共有6个原始等式:
d0,0⊕d0,1⊕d0,2⊕p0,3=0;
(1)
d1,0⊕d1,1⊕d1,2⊕p1,3=0;
(2)
d2,0⊕d2,1⊕d2,2⊕p2,3=0;
(3)
d0,0⊕d1,1⊕d2,2⊕p0,4=0;
(4)
d1,0⊕d1,1⊕d2,1⊕d0,2⊕p1,4=0;
(5)
d2,0⊕d0,1⊕d0,2⊕d1,2⊕p2,4=0.
(6)
出现磁盘错误时,纠删码的每个条带都存在一定数量的失效数据元素/校验元素,这些元素分别被包含在1个或多个原始等式中.若将原始等式中的某个元素移到等式的右边,并将该元素用其他元素的“异或和”表示,随后在其他原始等式中代入该元素,则会生成一些新的等式:
d0,0=d0,1⊕d0,2⊕p0,3,
(7)
将式(7)代入式(4),得:
d0,1⊕d0,2⊕p0,3⊕d1,1⊕d2,2⊕p0,4=0.
(8)
所产生的等式可以再次迭代,例如可将式(8)中的d2,2用其他元素的异或和表示,并代入式(3),从而形成新的等式.循环上述过程,将所有的元素都用所有潜在可能的方式表示(即对于每个等式中的每个元素,都用其他元素的异或和表示),并代入到其他所有包含此元素的等式中(含新产生的等式),直到不再产生新的等式为止(即所有新产生的等式都是之前出现过的).本文称这些由迭代变换所产生的等式为二次等式,并定义Eall为所有原始等式“并”所有二次等式的集合,定义F为所有失效元素的集合,Ei,j为能够直接计算出数据元素di,j或校验元素pi,j的重构等式.显然,对任意ei∈Eall,若ei∩F={di,j}或ei∩F={pi,j},则ei∈Ei,j.
重构等式是单磁盘错误重构的基础,这些等式既可以由数学推导生成,也可以由计算机枚举迭代获得.例如在图3的例子中,若D1发生错误,数据元素d0,1,d1,1,d2,1对应的重构等式为
d0,1⊕d0,0⊕d0,2⊕p0,3=0;
(9)
d0,1⊕d2,0⊕d0,2⊕d1,2⊕p2,4=0;
(10)
d1,1⊕d1,0⊕d1,2⊕p1,3=0;
(11)
d1,1⊕d0,0⊕d2,2⊕p0,4=0;
(12)
d1,1⊕d1,0⊕d2,0⊕d0,2⊕d2,2⊕p2,3⊕p1,4=0;
(13)
d2,1⊕d2,0⊕d2,2⊕p2,3=0;
(14)
d2,1⊕d0,2⊕d1,2⊕p1,3⊕p1,4=0;
(15)
d2,1⊕d0,0⊕d1,0⊕d0,2⊕d2,2⊕p0,4⊕p1,4=0.
(16)
2.2 优化原理
当基于异或运算的纠删码中出现单磁盘错误时,传统的重构方法首先寻找1块校验磁盘(横式编码)或一种类型的全部校验元素(纵式编码),然后用原始等式重构失效数据.特别地,若出错的是校验磁盘,则直接用所有的数据磁盘和原始等式重新计算校验元素.例如在图3所示的Liberation码中,当磁盘1发生错误时,传统方法将利用式(9)(11)(14),分别按3条规则进行重构:
d0,1=d0,0⊕d0,2⊕p0,3;
(17)
d1,1=d1,0⊕d1,2⊕p1,3;
(18)
d2,1=d2,0⊕d2,2⊕p2,3.
(19)
这种方法需要在D0,D2,P3中各读取3个元素,总共需要读取9个元素,再经过6次异或运算,才能重构所有的失效元素.然而,若适当利用磁盘P4中的一些校验元素,虽然异或运算的次数会增加,但需要读取的元素在总量上可能会减少.针对这一特点,文献[8]首次提出了一种基于RDP码的混合重构算法——RDOR算法,巧妙地利用了第2块校验盘中的一些元素,以提升数据重构的性能.本文将在3.1节中详细介绍RDOR算法,在此先以图3中的5磁盘Liberation码为例,介绍混合重构的基本原理.
在图3所示编码中,若D1发生错误,则用式(9)(11)(15)的重构过程为
d0,1=d0,0⊕d0,2⊕p0,3;
(20)
d1,1=d1,0⊕d1,2⊕p1,3;
(21)
d2,1=d0,2⊕d1,2⊕p1,3⊕p1,4.
(22)
显然,这种方法只需读取7个不同的元素;d0,2,d1,2,p1,3各参加了2次异或运算,总共运行了7次“异或”运算.由于磁盘I/O速度远低于“异或”运算速度,因此混合重构方法能够有效地提升单磁盘错误的重构效率.
3 基于构造的重构优化方法
随着混合重构原理的提出,学术界出现了大量基于混合重构思想的单磁盘错误重构优化方法.现有的单磁盘错误重构优化方法大致可分为2类:基于构造的优化算法和基于搜索的优化算法.其中,基于构造的重构算法主要以数学方法构造,包括针对RDP码的RDOR(row diagonal optimal recovery)算法[8]、evenodd码的重构优化算法[35]和X码的MDRR(minimum disk read recovery)算法与GMDRR(group-based minimum disk read recovery)算法[36]等.本节先详细介绍RDOR算法、MDRR算法和GMDRR算法,然后再从总体上对基于构造的重构算法进行对比与分析,最后给出各算法的意义与应用场景.
3.1 RDOR算法
RDOR算法是最早的基于纠删码的单磁盘错误重构优化算法.由于该算法针对RDP码进行优化,本文先介绍RDP码的基本结构.图5给出了1个6磁盘RDP码的例子,其中包含2种不同的校验元素,为了方便区分,本文称图5(a)所示的校验元素为水平校验元素,称图5(b)所示的校验元素为反对角校验元素.
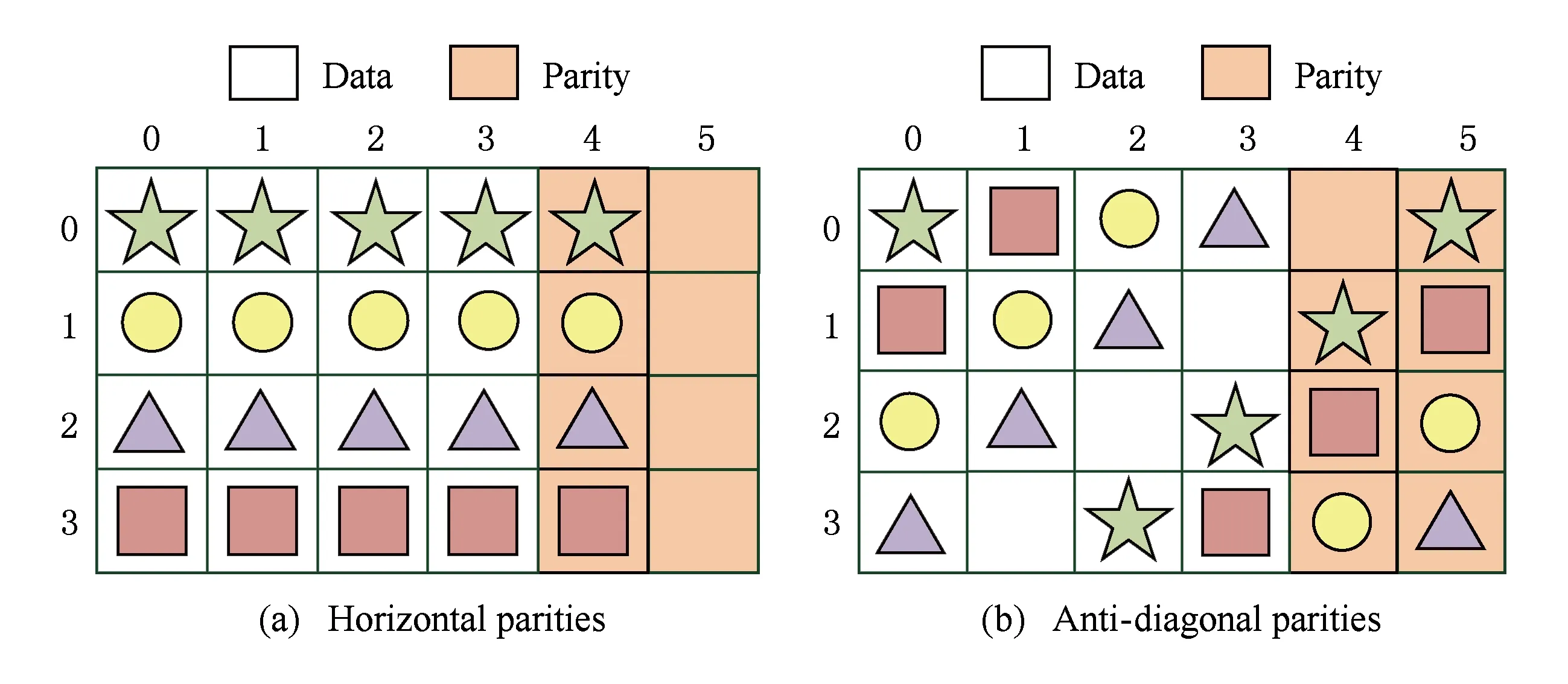
Fig. 5 6-disks RDP code图5 6-磁盘RDP码

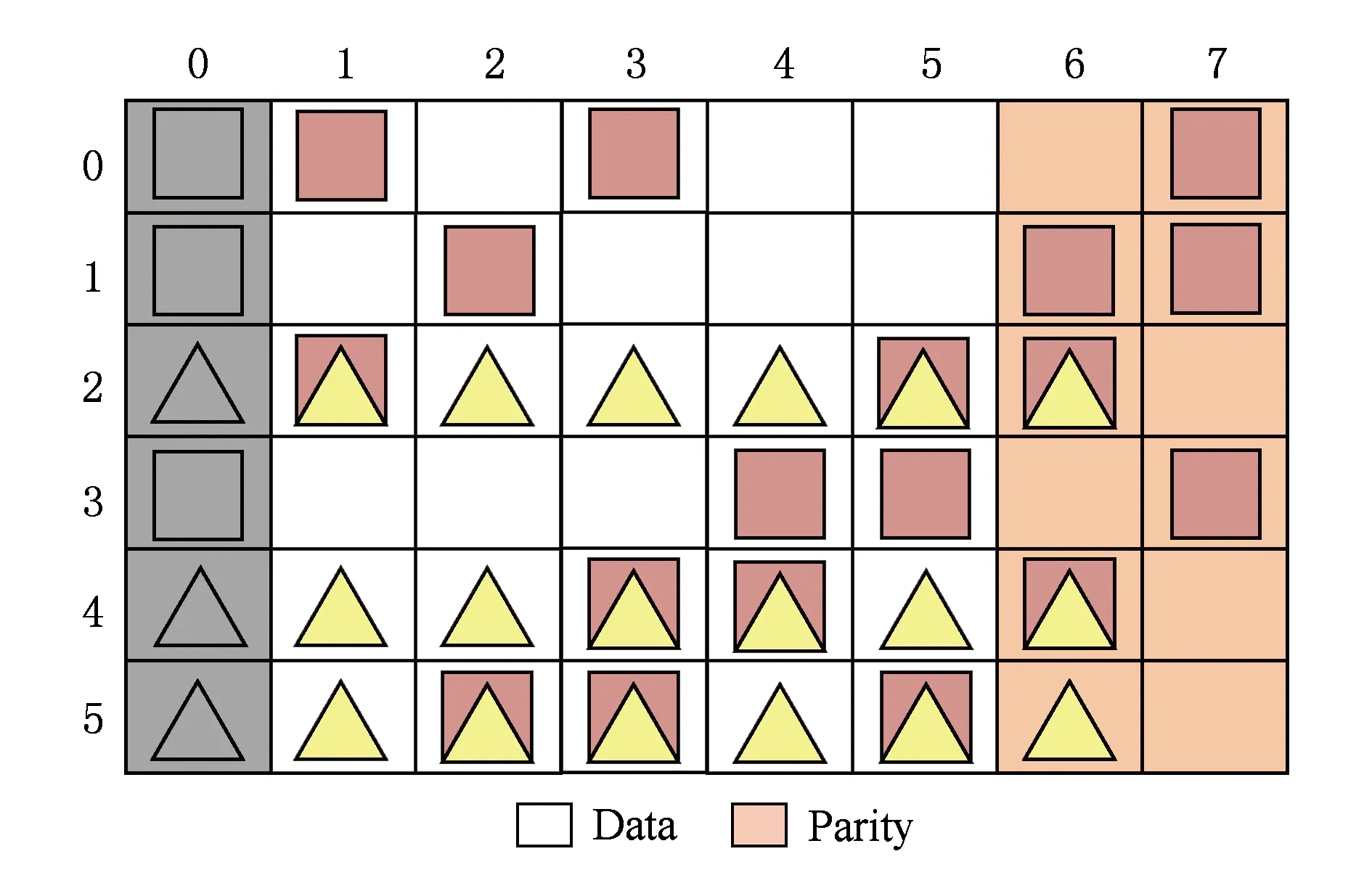
Fig. 6 An example of RDOR algorithm图6 RDOR算法的例子
3.2 MRDD算法与GMDRR算法
虽然RDOR算法仅针对RDP码,但由于横式编码的重构优化构造原理十分相似,因此针对其他横式编码基于构造的优化算法与RDOR算法十分接近,例如文献[35]中针对EVENODD码的优化算法等.此外,根据RDOR算法的思想,甚至可以较容易地推导出其他一些横式编码(例如Liberation码)的构造算法.然而,对于纵式编码,RDOR算法的思想则不完全适用.为此,文献[36]在典型纵式编码X码的基础上,首先提出了一种用于优化读取数据总量的MDRR算法,随后又提出了一种将条带映射到物理磁盘的方法,并以此为基础提出了能够达到磁盘间负载均衡的GMDRR算法.下面先介绍X码的基本结构:如图7所示,X码包含2种校验元素,其中,由斜率为1所在直线上的数据元素计算得来的校验元素被称为对角校验元素,由斜率为-1所在直线得数据元素计算而来得校验元素则被称为反对角校验元素.

Fig. 7 5-disks X-Code图7 5-磁盘X码
MDRR算法主要包含2个步骤:
1) 当0≤i≤(p-5)/2时,若i为奇数,则用反对角校验元素重构di,f,否则用对角校验元素重构di,f.
2) (p-3)/2≤i≤p-1当时,若i为偶数,则用反对角校验元素重构di,f,否则用对角校验元素重构di,f.
下面通过一个具体的案例,对MDRR算法的运行机制进行分析:在图7所示的X码中,若磁盘D0出错,根据MDRR算法,由于(p-5)/2=0,因此当i=0时,用对角校验元素所在的原始等式重构d0,0;当i=1,2,3,4时,用反对角校验元素所在的原始等式重构d1,0和p3,0,然后再用对角校验元素所在的原始等式重构d2,0和p4,0.
与RDOR算法相比,MDRR算法虽然也能够达到理论最少的数据读取总量,但无法达到磁盘间的负载均衡.为此,文献[36]进行了更深入的研究,并进一步证明:在保证读取数据量最少的前提下,X码的1个条带中不存在能够达到磁盘间负载均衡的算法(包含7块磁盘的X码除外).随后提出了GMDRR算法,该算法在MDRR算法的基础上,进一步提出了一种用于构造条带栈的方法,从而达到磁盘间的负载均衡.GMDRR算法的主要步骤如下:
1) 设置p-1个连续条带,记为条带1,条带2,…,条带p-1.
2) 在条带l(1≤l≤p-1)中,将D〈k×l〉p映射到第k块物理磁盘.
在图7所示的X码中,GMDRR需要设置4个连续条带,然后按照给定规则在各条带的内部,将各个条块(Dk)映射到不同的物理磁盘中.若用PDk来标识不同的物理磁盘,那么在条带3中,D4将被映射到PD2.各条块与物理磁盘的映射关系如图8所示(由于X码没有专门的校验条块,所有的条块都被认为是数据条块).
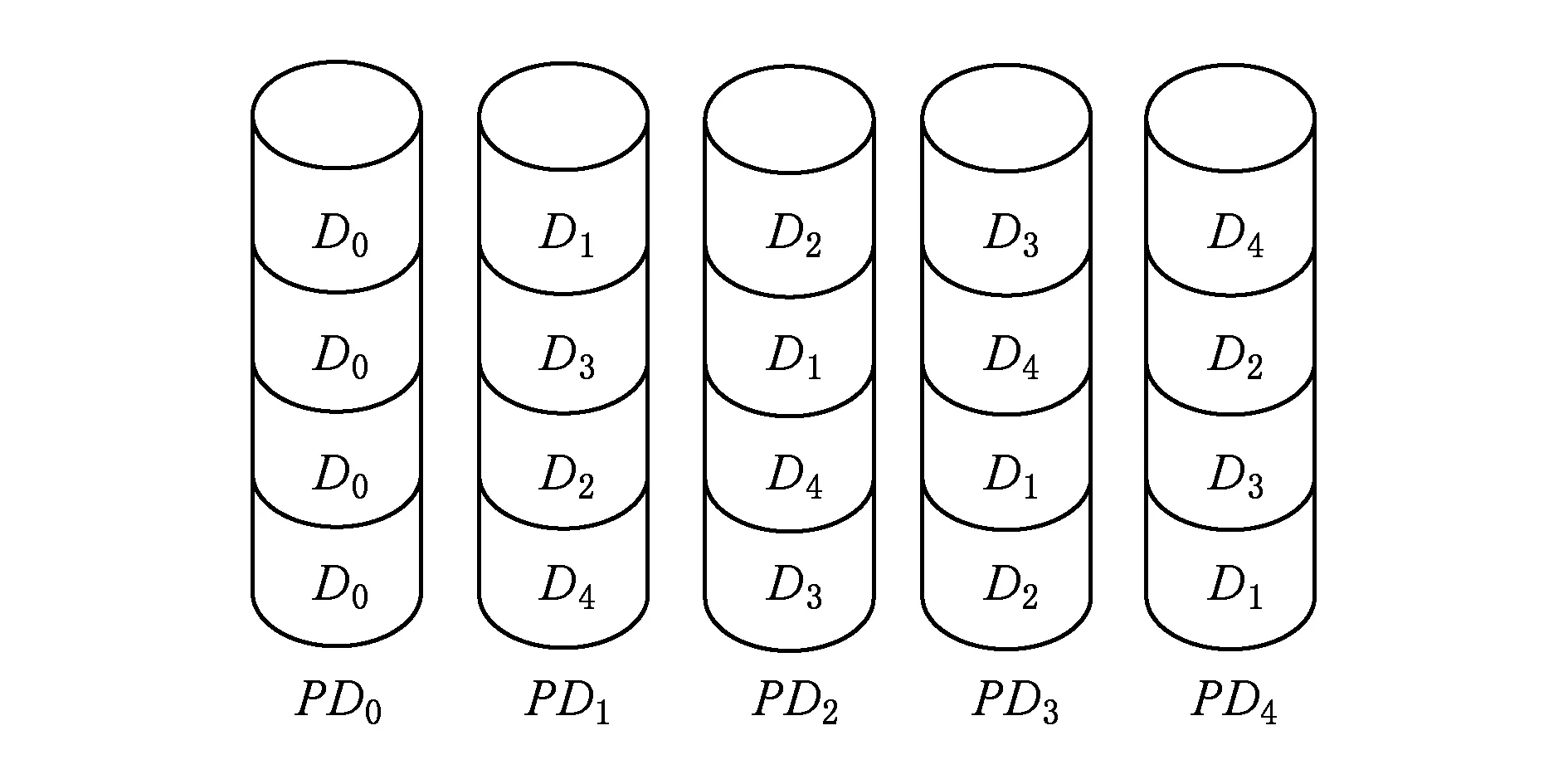
Fig. 8 Stack for GMRDD algorithm图8 GMDRR算法中的条带栈
GMDRR算法的实现原理与MDRR相同,在此不再赘述.理论推导证明:GMDRR算法不但能够达到最少的数据读取量,而且还能让各磁盘的I/O负载达到均衡.
3.3 构造算法对比
3.1~3.2节主要介绍了RDOR算法(基于横式编码的构造算法)、MDRR算法和GMDRR算法(基于纵式编码的构造算法)各自的构造细节.在实际应用中,它们也分别代表2类不同编码(即横式编码与纵式编码)的构造思路.横式编码的构造算法以RDOR算法为代表,通常先随机选择一些失效数据元素,并用水平校验元素进行重构,其他失效数据元素则用对角/反对角校验元素进行重构;随后,利用一些数学手段,通过构造的方式证明只要满足上述条件的可行解,其读取数据总量一定为理论最优;最后再建立一些辅助集合,从上述读取数据量最优的可行解中找到1个能够达到负载均衡的可行解.
与针对横式编码的重构方法相比,针对纵式编码的重构方法虽然也以读取数据总量和磁盘见负载均衡为优化目标,但构造读取数据总量最优的可行解的难度较大,主要体现在2个方面:
1) 在横式编码可行解的构造过程中,通常先用一定数量的水平校验元素重构部分失效元素,然后用对角/反对角校验元素重构其他失效元素.当这个数量为某一固定值时,所产生的所有重构方案所需读取的数据总量一致且最优,解空间相对较小;然而在纵式编码中,上述结论并不成立,因此构造难度较大,甚至有时候需要针对具体的磁盘数进行分析,才能找到读取数量总量最优的可行解.
2) 横式编码通常具有较好的负载均衡,然而在纵式编码中,有可能不存在能够达到磁盘间完全均衡的可行解,因此构造负载均衡的可行解的难度非常大,甚至可能要证明该编码不存在负载均衡的可行解,然后再通过一些数学手段,在条带栈级构造能够达到负载均衡的可行解.
总之,基于构造的单磁盘错误重构方法可根据其针对的编码类型分为2类,分别可针对一些典型的横式编码和纵式编码构造理论最优的重构方案.由于这些方案的构造难度较大,目前主要针对一些典型的RAID-6编码,且仅对编码的标准形态有效,因此普适性较差,主要适用于一些采用典型编码标准形态的存储系统,以及为基于搜索的单磁盘错误重构方法的理论分析提供重要依据.
4 基于搜索的重构优化方法
针对基于构造的优化方法普适性差的缺点,研究者们提出了许多基于搜索的优化方法,这些方法对所有基于异或运算的纠删码都有效.根据搜索复杂度的不同,基于搜索的单磁盘错误重构方法可分为NP-Hard级搜索算法和多项式级搜索算法2类.
4.1 NP-Hard级搜索算法
文献[37]首先提出了一种基于搜索的单磁盘错误重构方法,该方法用计算机作辅助工具,利用深度优先搜索原理,遍历解空间内所有可行的重构方案,从而找到读取数据总量最少的可行解.该方法主要包含3个步骤:
1) 利用纠删码的原始等式,为各失效元素构建重构等式,然后再构建能够重构所有失效元素的可行解.显然,若失效的条块中包含w个元素,则所有可行解都由w个重构等式构成,每个重构等式用于重构1个失效元素.在图3所示的编码中,由式(9)(12)(15)和式(10)(12)(16)构成的重构方案都是潜在的可行解.
2) 将所有的可行解构造成搜索树结构.首先设置起始节点S,然后将第1个失效元素的所有重构等式放置在第2层,作为起始节点的子节点;若第2层包含a个节点,则将第2个失效元素的所有重构等式复制a份,并放置在第3层,每份副本中的所有重构等式均连接相同的第2层节点;依此类推,直到最后1层的重构等式放置完毕为止.在图3所示的例子中,若D1发生错误,所形成的搜索树如图9所示:

Fig. 9 Search tree for recovery图9 用于重构的搜索树
3) 遍历搜索树中所有的可行解,并从中找到读取数据量最少的解;在搜索过程中可以利用启发式搜索算法的思想对搜索树进行剪枝处理,例如算法可以记录当前最优解的读取数据量,在搜索过程中,一旦某个方案的数据读取量大于或等于最优解的数据读取量,那么立即放弃该方案,不再向叶子节点继续搜索.在图3所示的编码中,该算法首先找到由等式(9)(11)(14)组成的可行解,其读取数据总量为9,记录下当前解;接着再搜索下一个可行解,由等式(9)(11)(15)构成,将它的读取数据总量与当前搜索结果中最小的读取数据总量进行对比,发现其读取数据总量为7,小于当前最小读取数据总量9,于是记录下这组可行解;接着再搜索下一组可行解,直到解空间搜索完毕.由于没有出现读取数据总量更小的解,由等式(9)(11)(15)构成的解决方案就是读取数据量最小的可行解.
文献[37]算法的核心思想在于让读取数据总量最小.然而,在云存储系统/磁盘阵列中,由于所有磁盘都支持并行读取,重构过程(利用重构等式计算出失效元素)通常要等待所有待读取元素都进入内存后才能开始,因此在各元素容量较大的情况下,系统设计者要考虑的首要问题是如何提高读速最慢磁盘的I/O效率.针对此问题,研究者们提出了一些优化磁盘间负载均衡的解决方案,具体可分为条带级负载均衡优化算法和条带栈级负载均衡优化算法2类.
条带级负载均衡优化算法以“条带”为基本重构单位,主要包括文献[38]提出的C算法、U算法等.其中,C算法核心步骤与文献[37]算法比较类似,其主要区别在于:在遍历所有可行解的过程中,C算法不但要记录当前读取数据总量最小的解决方案,而且还要记录该解中负载最大磁盘所需读取的数据量,若新搜索到的某个解决方案所需读取的数据总量与当前最优的解决方案相同,而此方案中负载最重磁盘所需读取的数据量更少,则用新搜索到的方案作为当前最优方案,例如若当前最优方案总共需要读取26个元素,其中负载最重磁盘需要读取6个元素,当搜索到某个解决方案需要读取26个元素,且负载最重磁盘仅需读取5个元素时,则用新搜索到的解决方案替换当前的最优解.U算法在搜索决策树的过程中以负载均衡为首要目标,例如,若当前最优解总共需要读取26个元素,负载最重磁盘需要读取5个元素,当出现某个解共需读取27个元素,而负载最重磁盘只需读取4个元素时,则用新搜索到的解决方案替换当前最优解.
条带栈级负载均衡优化算法主要针对循环移动的条带栈,以“条带栈”为最小重构单位,主要包括BP算法[39]等.BP算法分为2个主要部分:1)跟文献[37]方法类似,首先构建失效元素的重构等式,然后根据重构等式在各条带内部以搜索树的形式构建解空间;随后,BP算法将在各条带内部,按照文献[37]提出的方法进行搜索.不同的是,文献[37]方法仅记录读取数据总量最小的解,而BP算法会为读取数据总量设定阈值α,并记录所有在读取数据总量在(最小读取数据总量+α)范围内的解决方案.例如,若某个条带中读取数据总量最少的解决方案需要读取27个数据元素,α=1,BP算法则会在各个条带中记录读取数据总量小于或等于28的所有解决方案.2)利用模拟退火算法的思想,首先在1个条带栈的各条带中随机选择1个解决方案,所生成的条带栈级解决方案也被称之为初始解,并将当前最优解设定为该初始解;此后,根据整个条带栈中各磁盘的负载均衡程度,设定1个惩罚函数,并计算该条带栈级解决方案的惩罚因子;接着再随机选择1个或多个条带,用另一个条带级解替代该条带的解,并计算新产生条带栈级解的惩罚因子,若新产生的条带栈级解比当前最优解的惩罚因子更小,则用新产生的条带栈级解替代当前最优解,否则根据当前“温度”(模拟退火算法中的核心参数之一),选择是否替代当前最优解;最后利用模拟退火算法思想重复上述过程,直到出现连续M个解都没有替换最优解时算法结束,返回当前最优解作为条带栈级的解决方案.
4.2 多项式级搜索算法
由于NP-Hard级搜索算法需要搜索整个可行解空间,时间复杂度较高,当存储系统采用的编码复杂到一定的程度时(例如包含10块数据磁盘、6块校验磁盘的柯西RS码[25]),这些算法不一定能在规定时间内返回结果.针对此问题,研究者们提出了一些多项式级的搜索算法,根据搜索目标的不同,这些算法大致可归纳为基本搜索算法、优化磁盘I/O的搜索算法和条带栈级搜索算法3类.
基本搜索算法[40]主要针对云存储系统,利用贪心算法思想,先构建少量的重构等式,并设定1个初始解;随后逐步用其他重构等式替代初始解中的某些重构等式,并利用一些贪心算法(例如爬山法、模拟退火算法等)的思想,搜索读取数据总量最少的可行解,直到找到局部最优解为止.这类算法的时间复杂度通常为多项式级,能够在较短的时间内找到满意解.但由于该方法没有遍历整个可行解空间,所以不一定能够找到全局最优解.实验结果表明:这类算法找到的满意解与全局最优解在读取数据总量上非常接近.
优化磁盘I/O的搜索算法主要针对分布式文件系统,其典型特征在于网络带宽较充分,但由于各元素所包含的信息量较小,磁盘1次I/O操作可同时读取多个数据/校验元素的信息,重构算法可利用磁盘具有较好的“连续读”性能这一特点进行优化.为此,文献[9]在文献[40]方法的基础上,进一步提出了SIOR算法.SIOR算法在搜索的过程中不但要求读取数据总量最小,而且还要让待读取的数据块尽量连续.此外,SIOR算法还利用多个条带之间同时读取数据的思想,一次性读取多个条带中的信息进行重构,从而进一步提高读取效率.实验结果显示,SIOR算法的重构效率明显优于文献[40]算法.
条带栈级搜索算法主要针对循环移动的条带栈,例如文献[41]所提出的STP算法等.STP算法在BP算法的基础上,直接利用条带栈中所有失效元素的重构等式构造条带栈级解,然后再通过更换某些失效元素的重构等式,产生新的条带栈级解决方案,并利用模拟退火算法寻找令人满意的解决方案.实验结果显示,STP算法在条带栈的应用场景下,相比于文献[37]算法、C算法和U算法在重构效率上有较大幅度的提升.
4.3 搜索算法对比
基于搜索的重构算法能够适用于所有基于异或运算的纠删码,各算法的主要区别在于不同的优化目标与应用场景以及不同的搜索复杂度.
1) 基于搜索的重构算法可根据搜索过程的时间复杂度分为NP-Hard级算法和多项式级算法2类,其中NP-Hard级搜索算法主要针对磁盘规模较小的纠删码,而多项式级重构算法则主要针对磁盘规模较大的纠删码或需要实时重构的应用场景.在实际应用中,NP-Hard级算法的重构效率略高于多项式级算法.
2) 根据不同的应用场景,基于搜索的重构算法的优化目标主要有最小化读取数据总量、最大化磁盘间负载均衡、最大化磁盘的“连续读”的效果这3类,各算法通常最优化其中1个目标,或者在多个目标之间进行均衡.根据不同的优化目标,现有的搜索算法可分为3类:
① 以最小化读取数据总量为目标,主要包括文献[37]算法和文献[40]算法等.在实际应用中,这类算法主要针对网络传输带宽较小的云存储系统/数据中心.由于这些系统中每个数据元素包含的信息较大,其瓶颈在网络传输的时间,因此减少网络传输带宽有助于总体效率的提升.
② 以同时优化读取数据总量和磁盘间负载均衡为目标,包括文献[38]的C算法与U算法、BP算法、STP算法等.这些算法主要适用于网络带宽较好的云存储系统/磁盘阵列,其核心在于利用各磁盘能够并行读取数据的特点,将需要读取的数据元素尽量均匀地分散到不同磁盘中,从而利用数据并行读的特点减少磁盘I/O的时间,从而提升重构效率.各算法间的区别主要在于均衡点的不同.
③ 以同时优化读取数据总量和磁盘的“连续读”为目标,包括文献[9]的SIOR算法等.这类算法主要针对分布式文件系统,要求各数据元素所包含的信息量不能太大,磁盘的每次I/O操作能够读取多个数据/校验元素,从而利用磁盘的“连续读”性能远高于“随机读”性能的特点,减少磁盘I/O操作所需的时间,进一步提升重构效率.
各主流搜索算法之间的对比如表1所示:

Table 1 Comparison on Typical Search-Based Recovery Algorithms表1 基于搜索的重构算法对比
3) 根据算法的最小重构单位,基于搜索的重构算法可分为“条带级”重构算法和“条带栈级”重构算法2类.在上述的主流算法中,BP算法和STP算法属于“条带栈级”算法,其余算法均为“条带级”算法.在实际应用中,“条带栈级”算法的重构效率高于“条带级”算法,但由于“条带栈级”算法主要针对循环移动各条带与物理磁盘间映射的场景,适用范围相对较小.
总之,目前基于搜索的重构方法大都针对实际应用场景而设定优化目标,然后利用重构等式建立搜索树,最后选择具有合适复杂度的搜索策略并构建相应的算法.基于搜索的重构方法通常可支持任意基于异或运算的纠删码,并能够在其所针对的应用场景下大幅提升单磁盘错误重构性能.
5 用于优化重构效率的新型纠删码技术
上述优化方法主要针对已有的纠删码,利用混合重构原理进行优化.随着单磁盘错误重构效率问题的提出,研究者们逐渐设计了一些专门用于优化重构效率的新型纠删码技术,包括LRC码[10]、zigzag码[11]、S2-RAID[42]码、OI-RAID码等[43].下面将分类介绍这些新型纠删码技术.
1) 用于降低读取数据总量的纠删码技术
这类纠删码的主要特征在于:在编码设计时考虑如何降低单磁盘错误重构时所需读取的数据总量,包括LRC码、zigzag码等.其中,LRC码主要利用分组的思想,将1个条带中的所有逻辑磁盘分成多个不同的组,每个组内采用RAID-5[44]的方式进行编码,所产生的校验元素也被称为局部校验元素/组内校验元素.LRC码还为所有的数据磁盘构建了全局校验元素,以提升数据的可靠性.当单个磁盘发生错误时,LRC码只需在错误磁盘所在的组内,利用RAID-5的重构方法,就能够重构所有失效数据.若LRC码的1个条带中包含k个数据磁盘、r个校验磁盘和n个组,则重构每个失效元素所需读取的数据总量为n/k.
zigzag码利用混合重构的思想,首先用单位矩阵E生成一些zigzag排列,然后再利用数学手段,在伽罗华域中找出1组线性无关的系数,并利用这些排列和系数,通过伽罗华域中的计算进行编码.当单个磁盘发生错误时,首先根据用于生成编码排列的单位矩阵的各个行向量,利用一定的数学方法找到合适的原始重构等式,然后再利用伽罗华域中的计算,重构所有的失效元素.理论推导证明,包含k个数据磁盘和r个校验磁盘的zigzag码,重构各失效元素所需读取的数据总量的平均值,能够达到或接近MDS码的理论最优值r/k.
2) 用于提升重构并行度的纠删码技术
此类纠删码主要是在已有纠删码的基础上,通过分组/分层的方式,结合一些数学手段,将多个相同/不同的纠删码技术叠加构建.这类纠删码主要包括S2-RAID码、OI-RAID码等,其中,S2-RAID码是一种“斜交(skewed)”的RAID-5编码,它采用分组的方式,首先在各组中处于相同(逻辑)位置的磁盘之间构建RAID-5编码,然后再采用特定的移位方式,使各组之间的数据/校验元素产生“斜交”.当单个磁盘发生错误时,该编码可同时利用其他各组中的所有磁盘,并行重构失效元素,从而提升重构效率.
OI-RAID码则利用分层构造的思想,首先将所有磁盘分为v个组(group),每组内包含g×g个元素,每个条带共包含v×r个区域.该编码码首先参照BIBD(balanced incomplete block desigin[45])的思想对b个组进行编码,然后再在每个组内对各对角线上的所有元素做RAID-5编码.出现单磁盘错误时,OI-RAID码只需所有磁盘(不含错误磁盘)并行读取1个元素,即可重构1个条带内的所有失效元素.理论推导证明:OI-RAID不但能够在很大程度上提高重构过程的并行度,而且还能够容任意3个磁盘错误,从而提供很高的数据可靠性.
总之,当前用于优化重构效率的新型纠删码技术可根据具体的优化目标分为2类,其中,以降低读取数据总量为优化目标的纠删码具有较高的容错能力和较低的数据读取总量,有的还具有MDS属性,但它们的编/解码过程通常在伽罗华域中进行,因此编/解码效率较低.以提升重构并行度的纠删码技术采用让各组之间“斜交”的编码方式,通过一定的数学方法,让未出错的更多磁盘并行地参与到数据重构过程中,从而提升重构过程的并行度,进一步提升数据的重构效率.由于这类技术的编码过程仅使用异或运算,因此编/解码效率较高,但由于它们大都采用分组编码的方式,且各校验元素都由等量的数据元素生成,因此并没有在保证相同存储利用率的前提下降低重构过程中所需读取的数据总量.
6 总结与展望
本文对目前基于纠删码的单磁盘错误重构优化方法做了比较全面的总结.首先介绍了纠删码的基本概念,随后介绍了单磁盘错误重构的优化原理,接着详细介绍了现有主流单磁盘错误重构优化方法的工作原理.现有的单磁盘错误重构优化方法主要包含2类:基于构造的优化方法和基于搜索的优化方法.其中,基于构造的优化方法主要针对一些特定的编码,利用一些数学手段,以编码规则为出发点,直接构造能够达到理论最优的重构方案;基于搜索的优化方法大都通过构建搜索树的方式,在所有可行的解空间中搜索最优解或满意解.最后介绍了一些专门针对单磁盘错误重构进行优化的新型纠删码技术.我们认为,在当前基于纠删码的磁盘错误重构方法研究中,进一步的研究重点主要包含3个方面:
1) 针对多磁盘错误重构的优化技术.随着存储规模越来越大,多磁盘同时出错的概率也将增大,因此,研究多个磁盘同时出错情况下的数据快速重构技术具有重要意义.
2) 基于异构存储介质的优化技术.由于云存储发展的趋势是存储介质异构化,磁盘错误重构技术还应考虑如何在异构介质下提升重构效率.
3) 针对SSD等新型存储介质的优化技术.在新型存储器件中,一些传统的数据重构优化方法变得不再适用,例如优化数据的“连续读”等.因此,未来需要针对这些新型存储介质构建更加适用的重构方法.
[1] Zhiyan Consulting. 2016—2022 China’s big data industry in-depth analysis and investment strategy consulting report, R439946[R]. Beijing: Zhiyan Consulting Group, 2016 (in Chinese)
(智研咨询. 2016—2022年中国大数据行业深度分析及投资战略咨询报告, R439946 [R]. 北京: 智研集团, 2016)
[2] Pinheiro E, Weber W, Barroso L. Failure trends in a large disk drive population[C] //Proc of the 5th USENIX Conf on File and Storage Technologies. Berkeley, CA: USENIX Association, 2007: 17-28
[3] Borthakur D. The Hadoop distributed file system: Architecture and design [EB/OL]. [2017-02-21]. http://hadoop.apache.org/common /docs/current /hdfs-design.html
[4] Hu Yuchong, Chen Henry, Lee P, et al. NCCloud: Applying network coding for the storage repair in a cloud-of-clouds[C] //Proc of the 10th USENIX Conf on File and Storage Technologies. Berkeley, CA: USENIX Association, 2012: 1-8
[5] Ford D, Labelle F, Popovici F, et al. Availability in globally distributed storage systems[C] //Proc of the 10th USENIX Symp on Operating System Design and Implementation. Berkeley, CA: USENIX Association, 2010: 61-74
[6] Calder B, Wang Ju, Ogus A, et al. Windows azure system: A highly available cloud storage service with strong consistency[C] //Proc of the 23rd ACM Symp on Operating Systems Principles. New York: ACM, 2011: 143-157
[7] Facebook. HDFS RAID [EB/OL]. [2017-02-21]. https://wiki.apache.org/hadoop /HDFS-RAID
[8] Xiang Liping, Xu Yinlong, Lui John, et al. Optimal recovery of single disk failures in RDP code storage systems[C] //Proc of the ACM SIGMETRICS 2010. New York: ACM, 2010: 119-130
[9] Shen Zhirong, Shu Jiwu, Fu Yingxun. Seek-efficient I/O optimization in single failure recovery for XOR-coded storage systems[C] //Proc of the 34th Int Symp on Reliable Distributed Systems. Piscataway, NJ: IEEE, 2015: 228-237
[10] Huang Chen, Simitci H, Xu Yikang, et al. Erasure coding in windows azure storage[C] //Proc of the 2012 USENIX Annual Technical Conf. Berkeley, CA: USENIX Association, 2012: 15-26
[11] Tamo I, Wang Zhiying, Bruck J. Zigzag codes: MDS array codes with optimal rebuilding[J]. IEEE Trans on Information Theory, 2013, 59(3): 1597-1616
[12] Schroeder B, Gibson G. Disk failures in the real world: What does an MTTF of 1,000,000 hours mean to you?[C] //Proc of the 5th USENIX Conf on File and Storage Technologies. Berkeley, CA: USENIX Association, 2007: 1-16
[13] Hanfer J, Deenadhayalan V, Kanungo T, et al. Performance metrics for erasure codes in storage systems, RJ 10321[R]. San Jose: IBM Research, 2004
[14] MacWilliams F, Sloane N. The Theory of Error-Correcting Codes[M]. Amsterdam: North Holland, 1977
[15] Reed I, Solomon G. Polynomial codes over certain finite fields [J]. Journal of the Society for Industrial and Applied Mathematics, 1960, 8(2): 300-304
[16] Li Mingqiang, Lee P. STAIR codes: A general family of erasure codes for tolerating device and sector failures in practical storage systems[C] //Proc of the 12th USENIX Conf on File and Storage Technologies. Berkeley, CA: USENIX Association, 2014: 147-159
[17] Plank J, Blaum M, Hafner J. SD Codes: Erasure codes designed for how storage systems really fail[C] //Proc of the 11th USENIX Conf on File and Storage Technologies. Berkeley, CA: USENIX Association, 2013: 95-104
[18] Corbett P, English B, Goel A, et al. Row-diagonal parity for double disk failure correction[C] //Proc of the 3rd USENIX Conf on File and Storage Technologies. Berkeley, CA: USENIX Association, 2004: 1-14
[19] Blaum M, Roth R. On lowest density MDS codes[J]. IEEE Trans on Information Theory, 1999, 45(1): 46-59
[20] Blaum M, Bruck J, Nebib J. Evenodd: An efficient scheme for tolerating double disk failures in RAID architectures[J]. IEEE Trans on Information Theory, 1995, 44(2): 192-202
[21] Plank J. The RAID-6 liberation codes[C] //Proc of the 6th USENIX Conf on File and Storage Technologies. Berkeley, CA: USENIX Association, 2008: 97-110
[22] Plank J. A new minimum density RAID-6 code with a word size of eight[C] //Proc of the 7th IEEE Int Symp on Network Computing and Applications. Piscataway, NJ: IEEE, 2008: 85-92
[23] Blaum M. A family of MDS array codes with minimal number of encoding operations[C] //Proc of the 2006 IEEE Int Symp on Information Theory. Piscataway, NJ: IEEE, 2006: 2784-2788
[24] Huang Chen, Xu Lihao. STAR: An efficient coding scheme for correcting triple storage node failures[C] //Proc of the 4th USENIX Conf on File and Storage Technologies. Berkeley, CA: USENIX Association, 2005: 197-210
[25] Blomer J, Kalfane M, Krap R, et al. An XOR-based erasure-resilient coding scheme[R] Berkeley: International Computer Science Institute, 1995
[26] Xu Lihao, Bruck J. X-Code: MDS array codes with optimal encoding[J]. IEEE Trans on Information Theory, 1999, 45(1): 272-276
[27] Wu Chentao, He Xubin, Wu Guanying, et al. HDP Code: A horizontal-diagonal parity code to optimize I/O load balance in RAID-6[C] //Proc of the 41st Annual IEEE/IFTP Int Conf on Dependable Systems and Networks. Piscataway, NJ: IEEE, 2010: 209-220
[28] Wu Chentao, Wan Shenggang, He Xubin, et al. H-Code: A hybrid MDS array code to optimize large stripe writes in RAID-6[C] //Proc of the 2011 IEEE Int Parallel and Distributed Processing Symp. Piscataway, NJ: IEEE, 2011: 782-793
[29] Shen Zhirong, Shu Jiwu. HV code: An MDS code to improve efficiency and reliability of RAID-6 systems[C] //Proc of the 44th Annual IEEE/IFIP Int Conf on Dependable Systems and Networks. Piscataway, NJ: IEEE, 2014: 550-561
[30] Fu Yingxun, Shu Jiwu. D-Code: An efficient RAID-6 code to optimize I/O loads and read performance[C] //Proc of the 2015 IEEE Int Parallel and Distributed Processing Symp. Piscataway, NJ: IEEE, 2015: 603-612
[31] Hafner J. HoVer erasure codes for disk arrays[C] //Proc of the 2006 IEEE/IFIP Int Conf on Dependable Systems and Networks. Piscataway, NJ: IEEE, 2006: 217-226
[32] Hafner J. WEAVER codes: Highly fault tolerant erasure codes for storage systems[C] // Proc of the 4th USENIX Conf on File and Storage Technologies. Berkeley, CA: USENIX Association, 2005: 211-224
[33] Luo Xianghong, Shu Jiwu. Summary of research for erasure code in storage system[J]. Journal of Computer Research and Development, 2012, 49(1): 1-11 (in Chinese)
(罗象宏, 舒继武. 存储系统中的纠删码研究综述[J]. 计算机研究与发展, 2012, 49(1): 1-11)
[34] Greenan K, Li Xiaozhou, Wylie J. Flat XOR-based erasure codes in storage systems: Constructions, efficient recovery, and tradeoffs[C] //Proc of the 26th IEEE Symp on Mass Storage Systems and Technologies. Piscataway, NJ: IEEE, 2010: 1-14
[35] Wang Zhiying, Dimakis A, Bruck J. Rebuilding for array codes in distributed storage systems[C] //Proc of 2010 IEEE GLOBALCOM Workshops. Piscataway, NJ: IEEE, 2010: 1905-1909
[36] Xu Silei, Li Runhui, Lee P, et al. Single disk failure recovery for X-code-based parallel storage systems[J]. IEEE Trans on Computers, 2013, 63(4): 995-1007
[37] Khan O, Burns R, Plank J, et al. Rethinking erasure codes for cloud file systems: Minimizing I/O for recovery and degraded reads[C] //Proc of the 10th USENIX Conf on File and Storage Technologies. Berkeley, CA: USENIX Association, 2012: 1-14
[38] Luo Xianghong, Shu Jiwu. Load-balanced recovery schemes for single-disk failure in storage systems with any erasure code[C] //Proc of the 2013 Int Conf on Parallel Processing. Piscataway, NJ: IEEE, 2013: 552-561
[39] Fu Yingxun, Shu Jiwu, Luo Xianghong. A stack-based single disk failure recovery scheme for erasure coded storage systems[C] //Proc of the 33rd IEEE Symp on Reliable Distributed Systems. Piscataway, NJ: IEEE, 2014: 136-145
[40] Zhu Yunfeng, Lee P, Hu Yuchong, et al. On the speedup of single-disk failure recovery in XOR-coded storage systems: Theory and practice[C] //Proc of the 28th IEEE Symp on Mass Storage Systems and Technologies. Piscataway, NJ: IEEE, 2012: 1-12
[41] Fu Yingxun, Shu Jiwu, Shen Zhirong. Reconsidering single disk failure recovery for erasure coded storage systems: Optimizing load balancing in stack-level[J]. IEEE Trans on Parallel and Distributed Systems, 2017, 27(5): 1457-1469
[42] Wan Jiguang, Wang Jibin, Yang Qing, et al. S2-RAID: A new raid architecture for fast data recovery[C] //Proc of the 26th IEEE Symp on Mass Storage Systems and Technologies. Piscataway, NJ: IEEE, 2010: 1-9
[43] Wang Neng, Xu Yinlong, Li Yongkun, et al. OI-RAID: A two layer raid architecture towards fast recovery and high reliability[C] //Proc of the 2016 IEEE/IFIP Int Conf on Dependable Systems and Networks. Piscataway, NJ: IEEE, 2016: 61-72
[44] Patterson D, Gibson G, Katz R. A case for redundant arrays of inexpensive disks (RAID)[C] //Proc of the 1988 ACM Special Interest Group on Management of Data. New York: ACM, 1988: 109-116
[45] Hall M. Combinatorial Theory[M]. Hoboken, NJ: John Wiley & Sons, 1998
猜你喜欢
计算机应用与软件(2022年6期)2022-07-12
油气地质与采收率(2022年3期)2022-05-20
自然灾害学报(2022年2期)2022-05-10
中学生学习报(2022年15期)2022-04-17
中国学校体育(2021年10期)2021-04-26
电脑爱好者(2020年18期)2020-09-26
网络安全和信息化(2019年10期)2019-11-26
电脑爱好者(2019年2期)2019-10-30
电脑知识与技术(2017年14期)2017-07-10
山东工业技术(2016年10期)2016-09-06
