
文本文件差异对比算法研究
2018-01-02 08:44李明
软件 2017年12期
李 明
(北京邮电大学网络技术研究院,北京 100876)
文本文件差异对比算法研究
李 明
(北京邮电大学网络技术研究院,北京 100876)
如今各种项目的规模越来越大,而一个人的能力和精力是有限的,因此通常需要有一个团队进行协作开发。在协作开发时,不可避免的会产生工作交叉,甚至冲突。目前常见的多人协作工具如git、svn等,都提供了对不同版本的文件进行差异对比,由此来为开发人员提供帮助。在文本文件的差异对比算法中,它的核心是最长公共子序列算法。因此在这篇论文中,我们首先将对常见的最长公共子序列算法进行探讨,在之后将对一种优化后的LCS算法进行详细分析。
文件差异比较;最长公共子序列;最短编辑距离;NP算法
0 引言
文件间的差异对比是目前多人协作工具提供的一个重要功能,在一些软件开发工具中也有提供。主要目的是为了在多人协作的模式中,假设出现文件修改冲突,开发人员可以通过文件对比找出冲突原因并进行处理,从而降低开发人员的工作量。因此提供一个优秀的文本差异对比算法很有必要。
文件差异对比算法的本质其实是最长公共子序列算法,只不过文件差异对比可能会允许近似解。目前最长公共子序列算法的时间复杂度为O(n^2)。普通的 DP方法,无论是时间还是空间上,复杂度都是 O(n^2)。假设文件的行数很多,那么算法的效率将非常低。因此我们在对传统的最长公共子序列算法进行探讨和分析后,会对一种优化后的最长公共子序列算法进行分析,该算法的时间复杂度可以达到O(NP),近似于O(ND)算法的两倍,其中P为删除距离,D为编辑距离。
1 LCS算法对比
文件差异对比算法的本质其实是最长公共子序列算法,在实际实现的过程中,我们会对文件进行预处理,通常是以行为单位,为每一行数据通过哈希算法产生一个哈希值,从而将文件内容转化为了一个由每一行计算得来的哈希值组成的字符串,因此文件差异的比较转化为了求解LCS问题。
求解LCS问题,不能使用暴力搜索方法。一个长度为n的序列拥有 2的n次方个子序列,它的时间复杂度是指数级。因此解决LCS问题,需要借助动态规划的思想。动态规划算法通常用于求解具有某种最优性质的问题。在这类问题中,可能会有许多可行解。每一个解都对应于一个值,我们希望找到具有最优值的解。动态规划算法与分治法类似,其基本思想也是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到原问题的解。与分治法不同的是,适合于用动态规划求解的问题,经分解得到子问题往往不是互相独立的,从而会出现大量的重复计算。因此我们可以用一个表来记录所有已解的子问题的答案,从而避免重复计算这就是动态规划法的基本思路。
1.1 普通的动态规划求LCS
解决LCS问题,需要把原问题分解成若干个子问题,所以需要刻画LCS的特征。
设 A=“x0,x1,…,xm”,B=“y0,y1,…,yn”,且 Z=“z0,z1,…,zk”为它们的最长公共子序列。不难证明有以下性质:
如果 xm=yn,则 zk=xm=yn,且“z0,z1,…,z(k-1)”是“x0,x1,…,x(m-1)”和“y0,y1,…,y(n-1)”的一个最长公共子序列;
如果xm!=yn,则若zk!=xm,蕴涵“z0,z1,…,zk”是“x0,x1,…,x(m-1)”和“y0,y1,…,yn”的一个最长公共子序列;
如果xm!=yn,则若zk!=yn,蕴涵“z0,z1,…,zk”是“x0,x1,…,xm”和“y0,y1,…,y(n-1)”的一个最长公共子序列。
因此算法的递推公式为:

该算法的求解过程如图1所示:

图1 普通DP求解过程Fig.1 The general solving process of DP
在普通的动态规划求解LCS的过程中,并没有考虑到通常情况下,文件在进行比较时,两个文件的相似度应该是很高的,总是以最坏情况进行考虑,会将图1中的所有空白处填满,仍然增加了许多额外的计算过程,它的时间复杂度和空间复杂度均为O(N^2)。
1.2 O(ND)比较算法
O(ND)比较算法也是一种动态规划算法,它是由Myers提出的。与前面提到的动态规划算法的区别在于它考虑到了两个文件的相似度很高,从而采用了贪心设计的方式进行实现。
O(ND)比较算法采用了编辑图的形式。设两个序列分别为 A=“a1,a2,…,an”,B=“b1,b2,…,bm”,其中A和B的长度分别为N和M。因此我们可以得到一个和图2相似的编辑图,编辑图的顶点通过水平、垂直和对角有向边连接,形成有向无环图。水平边将每个顶点连接到它的右邻点,即(x-1,y)→(x,y),垂直边将每个顶点连接到它下面的相邻点,即(x,y-1)→(x,y),而对角有向边连接的(x-1,y-1)→(x,y)表示点(x,y)为匹配点,即 ax=by。一系列由xi< xi+l并且yi< yi+l的这些匹配点构成的序列即为最长公共子序列,而在连接过程中所经过的水平边和垂直边的和即为最短编辑距离。
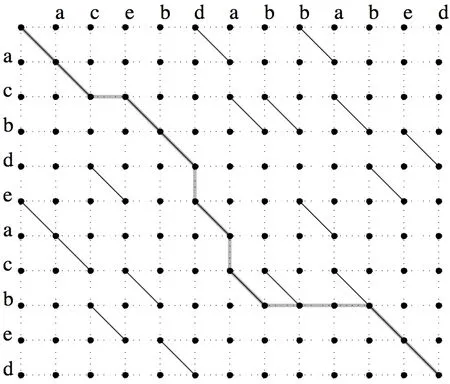
图 2 序列 A=‘a c b d e a c b e d’和序列 B=‘a c e b d a b b a b e d’的编辑图Fig.2 Edit graph for A=’a c b d e a c b e d’ and B=’a c e b d a b b a b e d’
在O(ND)算法中,将问题进一步转化为了在两个序列中寻找最短编辑距离问题。即是寻找从(0, 0)到(n,m)的最少的非对角边。定义对角边k为包含点(x,y)并且 x-y=k,因此 k的范围为[-M,N]。这里可以得到一个结论:一个编辑距离为D的编辑图中,它一定是在对角边 k上结束,其中 k∈{-D,-D+2,…,D-2,D}。这个结论可以通过归纳法进行证明:首先一个编辑距离为0的编辑图,一定是由对角线构成,即最终在对角边0上结束。假设一个编辑距离为D的编辑图,它是在对角边k上结束,其中k∈{-D,-D+2,…,D-2,D}。那么在编辑距离为D+1的编辑图中,它一定包含一个编辑距离为D的路径前缀的编辑图,即是说会在对角边k处结束,由编辑距离的定义来看,此时路径只能是向右或是向下移动一次,然后剩余路径必须全是对角边,因此最终会在对角边k+1或者k-1结束。因此它满足编辑距离为D+1的编辑图最终将在对角边k上结束,其中k∈{-D-1,-D+1…,D-1,D+1}。结论成立。
通过采用贪心原则:通过最大限度的延伸编辑距离为D-1的编辑图可以得到编辑距离为D的编辑图。编辑距离从0开始到M+N结束,当最终结束点为(N,M)时,算法结束。因此算法的伪代码如下:
For D←0 to M+N Do
For k←D to D in steps of 2 Do
Find the endpoint of the furthest reaching D-path in diagonal k.
If (N, M) is the endpoint Then
The D-path is an optimal solution.
Stop
该算法的求解过程如图3所示,其中虚斜线代表在当前的编辑距离D下,算法的边界条件k,即最终结束点的对角边 k,因此该算法的计算区域为编辑距离D的虚线区域中。而由于之前的计算结果都在从0到D的过程中计算完成,每次都是从上次的结果中直接使用,从而降低了计算次数。该算法的时间复杂度为O((M+N)D),最坏的的时间复杂度为O((M+N)^2),即D=M+N,也就是两个序列完全不同。

图3 O(ND)求解过程Fig.3 O (ND) solving process
1.3 O(NP)比较算法
O(NP)比较算法是在 O(ND)比较算法的基础上进行了优化,假设D为编辑图的编辑距离,则P= D/2- (N-M)/2,P表示编辑图的删除距离。该算法期望的时间复杂度为O(N + PD),它的速度大概是O(ND)比较算法的两倍。
假设两个序列分别为 A=“a1, a2,…,an”,B=“b1,b2,…,bm”,其中A和B的长度分别为N和M。因此我们也将得到一个和图1相似的网格。在这个编辑图中,水平边代表对应于插入,垂直边对应删除,对角边对应匹配点。因此寻找一个LCS的问题相当于在编辑图中找到一个最短的源到终点的路径。即是从(0,0)到(M,N)的路径。图2显示了对于序列 A=‘a c b d e a c b e d’和序列 B=‘a c e b d a b b a b e d’的编辑图,其中D=6,P=2。
在该算法中,定义对角边k为包含点(x,y)并且 y-x=k的对角边,k的范围为[-M,N]。同时定义Δ=N-M,将包含终点(N,M),在 O(ND)比较算法中,它的计算区域在对角边-D到对角边 D的区域中,如图4中D-band所示。而改进后的算法将计算区域缩小在对角边-P到对角边Δ+P的区域中,如图4中P-band所示。
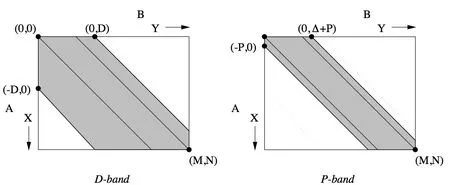
图4 编辑图的D-band和P-bandFig.4 D-band and P-band of an edit graph
定义V(x,y)为最短路径到达(x,y)的垂直边数,定义压缩距离为从点(0,0)到对角边所需的垂直边数,因此压缩距离的公式为:
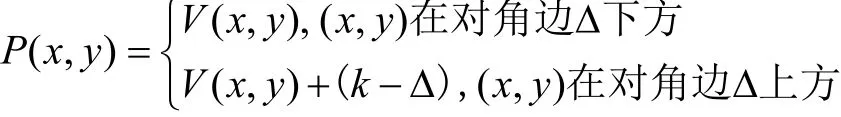
与O(ND)比较算法一样,该算法也集中于计算一组最远顶点的距离,直到到达终点为止。定义FP(p) = { (y-k,y) : y = fp(k,p) 并且-p≤k≤p+Δ},其中fp (k,p)=max{y : P(y-k,y) = p},该算法每次从集合 FP(p-1)中计算集合 FP(p),当 FP(p)中包含终点(M,N)时,算法结束。假设qk是在对角边k上删除距离为p-1的最远的点(例如点(y -k, y),因此y =fp(k, p-1))。令 gk是对角边 k上删除距离为 p的最远的点,假设FP(p-1) = {q-(p -1), q-(p -2),...,qΔ+(p-1)}已经求出,该算法将首先按照 g-p, g-(p-1), ..., gΔ-1的顺序求出g值,然后根据gk -1和qk +1求出 gk,最后由 gΔ-1和 gΔ+1 计算出 gΔ。定义 snake(k,y)表示在对角边k上从点(y-k, y)出发能到达的最远的点,则snake(k, y) = max { z : ay +1-k ... az -k =by +1 ...bz },最后得到fp(k, p)的公式如下:
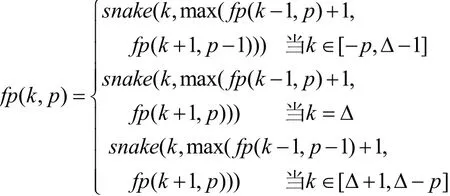
该算法最坏的时间复杂度为 O(NP),期望的时间复杂度为O(N+PD)。
2 实验
本文将改进后得到的 O(NP)算法进行了实现,并与梅尔斯提出的O(ND)算法进行了比较。实验环境为:Intel八核(单核主频3.4 GHz)计算机,8 GB内存,CentOS 6.5操作系统,用intellij idea采用java语言实现所有算法。通过在字母表上随机生成长度为4000和5000的字符串,并进行连续100次的测试取平均值得到最终测试结果,最终测试结果如表1所示。正如在表中所看到的,当 a和b长度不相同但非常相似时,提升是相当大的。当 a近似为 b的子序列时,改进后的算法是线性时间运行的。
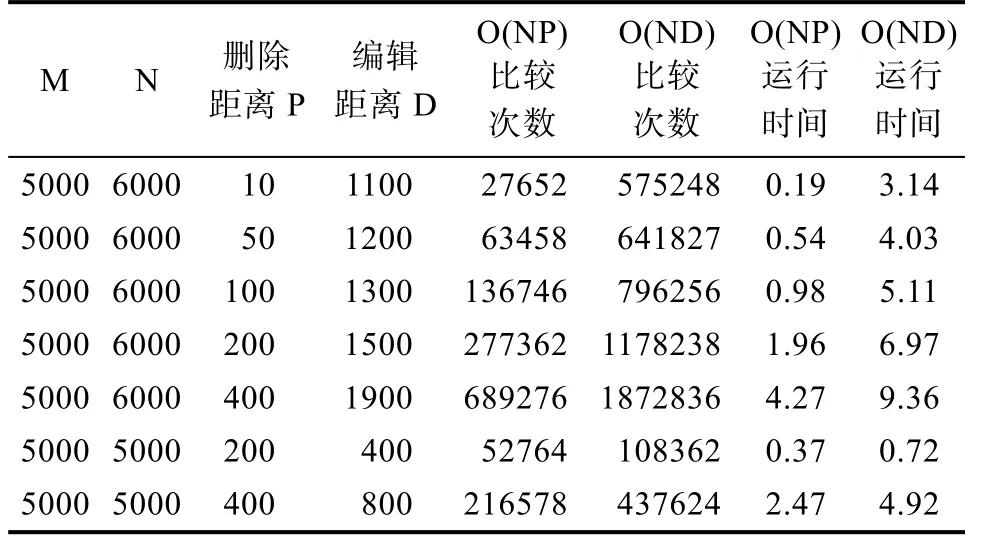
表1 实验结果Tab.1 Experimental results
3 结束语
本文对文本文件差异对比的核心算法LCS进行了分析和对比,包括普通DP算法,改进之后的O(ND)算法以及在 O(ND)算法的基础上改进得到的O(NP)算法。通过最终的实验结果可以看到,改进之后得到的 O(NP)算法在比较次数和时间上均远低于 O(ND)算法。由于综合考虑了两个序列间的相似度应该比较高,同时将原来计算的D-band区域缩小到了P-band区域,O(NP)算法可以大幅度降低计算量,提高运行效率。因此,O(NP)算法具有更强的稳定性和实用性。
[1] Myers E W. AnO(ND) difference algorithm and its variations[J]. Algorithmica, 1986, 1(1-4): 251-266.
[2] Hirschberg, Daniel S. Algorithms for the Longest Common Subsequence Problem[J]. Journal of the Acm, 1977, 24(4):664-675.
[3] Baker B S, Giancarlo R. Sparse Dynamic Programming for Longest Common Subsequence from Fragments ☆[J].Journal of Algorithms, 2002, 42(2): 231-254.
[4] Hunt J W, Szymanski T G. A fast algorithm for computing longest common subsequences[J]. Communications of the Acm, 1977, 20(5): 350-353.
[5] Bergroth L, Hakonen H, Raita T. A survey of longest common subsequence algorithms[C]// International Symposium on String Processing and Information Retrieval, 2000. Spire 2000. Proceedings. IEEE, 2002: 39-48.
[6] Jiang T, Li M. On the approximation of shortest common supersequences and longest common subsequences[J]. Siam Journal on Computing, 2006, 24(5): 191-202.
[7] Tsai Y T. The constrained longest common subsequence problem[J]. Information Processing Letters, 2003, 88(4):173-176.
[8] Wu S, Manber U, Myers G, et al. An O( NP ) sequence comparison algorithm[J]. Information Processing Letters,1990, 35(6): 317-323.
[9] Hsu W J, Du M W. Computing a longest common subsequence for a set of strings[J]. Bit Numerical Mathematics,1984, 24(1): 45-59.
[10] Miller W, Myers E W. A file comparison program[J].Software Practice & Experience, 1985, 15(11): 1025-1040.
[11] Hunt J W, Mcillroy M D. An algorithm for differential file comparison[J]. Cstr Bell Telephone Laboratories, 1975.
[12] Fanberg V V. Computer file comparison method: US,US6236993[P]. 2001.
[13] Marcelais M R, Sullivan S T, Hilke J C. Hash-based file comparison: US, US 8543543 B2[P]. 2013.
[14] Fuchs C. File comparison of locally synched files: US,US7228319[P]. 2007.
Research on Text File Difference Contrast Algorithm
LI Ming
(Beijing University of Posts and Telecommunications, Institute of Network Technology, Beijing 100876)
Today, the scale of projects is growing, and a person's ability and energy is limited, so usually need to have a team for collaborative development.In collaborative development, there will inevitably be work cross and even conflict. At present, common multi person collaboration tools, such as GIT, SVN, etc., provide different versions of the document contrast, thus providing help for developers.In the text file difference contrast algorithm, its core is the longest common subsequence algorithm.Therefore, in this paper, we will first explore the common longest subsequence algorithm, and then an optimized LCS algorithm is analyzed in detail.
File difference comparison; Longest common subsequence; Shortest edit scrip; NP algorithm
TP312
A
10.3969/j.issn.1003-6970.2017.12.042
本文著录格式:李明. 文本文件差异对比算法研究[J]. 软件,2017,38(12):216-219
猜你喜欢
卫星应用(2022年7期)2022-09-05
卫星应用(2022年3期)2022-05-23
卫星应用(2022年1期)2022-03-09
中国惯性技术学报(2019年6期)2019-03-04
数学年刊A辑(中文版)(2018年4期)2019-01-08
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
火控雷达技术(2016年3期)2016-02-06
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
文山学院学报(2012年6期)2012-03-25
小朋友·快乐手工(2009年1期)2009-02-07
