
大数据环境下的数据清洗框架研究
2018-01-02 08:44封富君姚俊萍李新社马俊春
软件 2017年12期
封富君,姚俊萍,李新社,马俊春
(西安高新技术研究所,陕西 西安 710025)
大数据环境下的数据清洗框架研究
封富君,姚俊萍,李新社,马俊春
(西安高新技术研究所,陕西 西安 710025)
在大数据环境下会不可避免的存在一些脏数据,严重的影响了数据质量,而数据清洗是提高数据质量的重要方法,对数据清洗框架的研究可以帮助大数据的系统决策。提出了一个大数据环境下数据清洗的一般框架,并对核心的数据清洗模块中的三个子模块进行详细的分析,包括不完整数据清洗子模块、不一致数据修复子模块和相似重复记录数据清洗子模块,且讨论了其清洗的具体流程。
大数据;数据质量;数据清洗;相似重复记录
0 引言
大数据环境呈现出“4V + 1C”的特点:数据量巨大(Volume)、数据类型繁多(Variety) 、价值密度低(Value)、处理速度快(Velocity) 和具有较强的复杂性(Complexity),原始大数据信息中混杂着许多不完整、错误和重复的“不清洁”数据,导致大数据存在着不一致、不完整性、低价值密度、不可控和不可用的特性[1-2]。面对如此庞大的数据量,人们希望从海量数据中挖掘出有价值的信息或知识,为决策者提供参考。由于数据录入错误、不同表示方法的数据源合并或迁移等原因,不可避免的使系统存在冗余数据、缺失数据、不确定数据和不一致数据等诸多情况,这样的数据称为“脏数据”,严重影响了数据利用的效率和决策质量。因此,为使系统中的数据更加准确、一致,并能够支持决策,数据清洗变得尤为重要,数据清洗的任务就是过滤或修改那些不符合要求的数据,输出符合系统要求的清洁数据。
大数据技术由传统的数据技术发展而来,继承了传统数据技术的概念与分析方法[3-4],例如数据清洗、数据仓库等。传统的数据清洗技术可以提供高质量的数据,并提高了数据分析的效率和正确性。大数据环境下的数据清洗同样是大数据分析的基础,是整个大数据处理的起始阶段,决定了大数据处理结果的数据质量。本文对大数据环境下的数据清洗技术进行分析,并提出一个一般性的数据清洗框架。
1 数据清洗定义
产生数据质量问题的原因很多,例如:缩写的滥用会造成数据的混乱;相似重复的数据记录会增加数据库的负荷,降低数据处理的效率;人为的失误或系统的故障会造成缺失数据、不完整数据或异常数据等,这些原因都会导致“脏数据”的产生。数据清洗是将数据库精简以除去重复记录,并使剩余部分转换成符合标准的过程;狭义上的数据清洗特指在构建数据仓库和实现数据挖掘前对数据源进行处理,使数据实现准确性(accuracy)、完整性(compliteness)、一致性(consistency)、适时性(timeliness)、有效性(validity)以适应后续操作的过程。从提高数据质量的角度来说,凡是有助于提高数据质量的数据处理过程,都可以认为是数据清洗。数据清洗是对数据进行处理以保证数据具有较好质量的过程,即得到干净数据的过程。
对数据清洗定义的理解需要注意以下问题[5]:
(1)数据清洗洗掉的是“数据错误”而不是“错误数据”,目的是要解决“脏数据”的问题,即不是将“脏数据”洗掉,而是将“脏数据”洗干净。
(2)数据清洗主要解决的是实例层数据质量问题,对一个给定的数据集,实例层数据质量问题是有限的、可检测的和可隔离的。
(3)数据清洗不能完全解决所有的数据质量问题,即通过数据清洗提高数据质量的程度是有限度的,如对缺失值的估计有不确定性。
因此,对数据清洗的正确理解应该是“在尽可能不破坏有用信息的前提下,尽可能多地去除数据错误”,数据清洗可能损失有用信息,也可能产生新的数据质量问题。
2 数据清洗的基本原理
数据清洗原理是利用数据挖掘相关技术, 按照设计好的清理规则或算法将未经清洗的数据,即脏数据,转化为满足数据挖掘所需要的数据,如图 1所示。数据清洗的一般过程是:对收集到的信息进行数据分析得到“脏数据”;定义数据清洗规则和清洗算法,对数据进行手工清洗或自动清洗,直到处理后的数据满足数据清洗的要求。
手工清洗的特点是速度慢,准确度高,一般适用于小规模的数据清洗,在较大规模的数据处理中,手工清洗的速度和准确性会明显下降,通常采用自动清洗方式。自动清洗的优点是清洗的完全自动化,但是需要根据特定的数据清洗算法和清洗方案,编写数据清洗程序,使其自动执行清洗过程。缺点是实现过程难度较大,后期维护困难。在大数据环境下,由于数据量的巨大,数据清洗通常采用自动清洗的方式来完成。

图1 数据清洗原理Fig.1 Data cleaning principle
3 数据清洗系统框架
对数据清洗框架的研究也较多,文献[6]将逻辑规范层和物理实现层分离,提出了一种描述性语言,可以在逻辑层上指定数据清洗过程所需采取的数据转化操作,要求用户的交互。文献[7]实现了一个可扩展的数据清洗工具 AJAX,文献[8]提出了数据清洗的一个交互式系统框架,它集成了数据转化和差异检测,具有良好的交互性。文献[9]提出了一个粗粒度的、紧耦合的自动化数据清洗框架。
本文提出了一个大数据环境下数据清洗的一般性系统框架,如图2所示。该框架分为三部分:外部的支持模块、数据清洗模块和内部的数据库模块。其中外部的支持模块主要包括系统日志、监控系统和访问接口;内部的数据库模块主要包括在数据清洗过程中需要调用的数据库,例如字典库、算法库和规则库等。数据清洗模块是数据清洗系统的主要模块,数据清洗模块根据制定的算法和规则在内部数据库中进行搜索和调用,并接受外部支持模块的访问和监控。数据清洗模块主要列出了在数据清洗过程中研究最多的不完整数据清洗、不一致数据清洗和重复数据清洗三个子模块。
3.1 不完整数据清洗子模块
在复杂网络环境下,当数据上报、接口调用时会产生大量的缺失值,因此不完整数据是不可避免的现象,而不完整的数据对大数据环境下的决策具有一定的影响。缺失值主要包括属性值错误和空值两个方面。属性错误值检测主要包括括统计法、聚类方法以及关联规则方法[10],这些方法都是以统计和总结规律的方式计算并查找错误值,进而修正错误数据;而空值检测主要采用人工填写空缺值法手工检测并填写属性值,也可以采用属性的平均值、中间值、最大值、最小值或更为复杂的概率统计函数值填充空缺值法。不完整数据清洗子模块流程如图3所示。
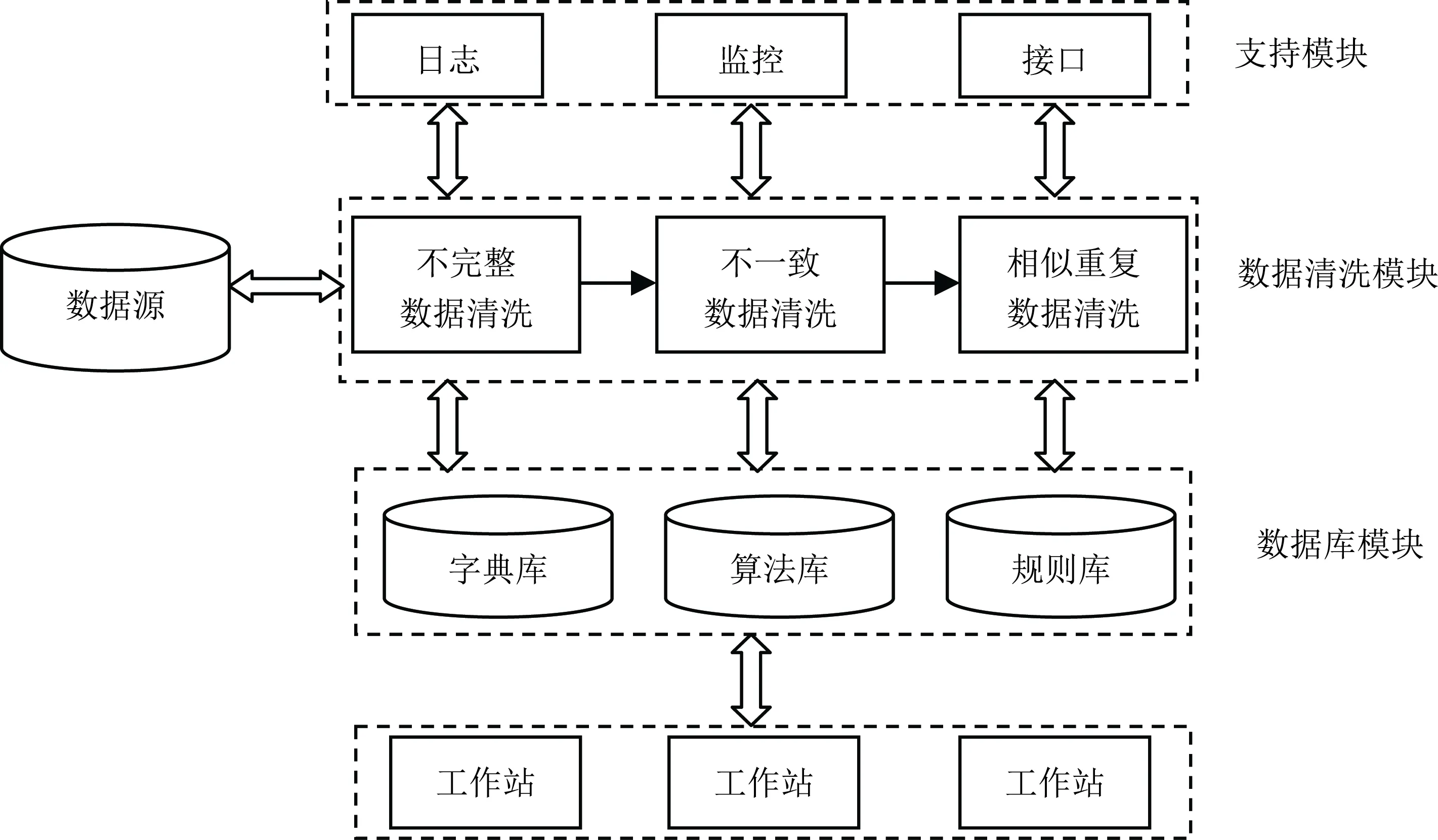
图2 数据清洗系统框架Fig.2 Data cleaning framework
主要过程为:
(1)对获得的数据源进行缺失值的参数估计,为后续的数据处理提供所需数据;
(2)根据数据填充算法对不完整数据进行缺失值的数据填充;
(3)输出填充后的完整数据。
3.2 不一致数据修复子模块
大数据环境下数据量的剧增使得获得的数据源会由于各种原因违反数据定义的完整性约束,存在大量的不一致数据。不一致数据修复子模块的功能就是将不一致的数据进行修复,使得其符合数据的完整性约束,保持数据的一致性,其流程如图4所示。

图4 不一致数据修复流程Fig.4 Inconsistent data repairing process
不一致数据修复子模块主要过程为:
(1)将数据源按照规定的数据格式进行检测,并执行预处理,方便后续的处理;
(2)对预处理后的数据进行数据不一致的检测,如果与原始的数据完整性约束不一致,则进行数据修复的过程,得到修复后的数据。通常修复后的数据有可能带来新的数据不一致,因此要将修复结果再次进行不一致的检测与修复,直到符合要求为止。
(3)最后将修复的数据结果还原为原格式,以方便其他系统的使用。
3.3 相似重复数据清洗子模块
相似重复数据在“脏数据”中占的比重较大,其产生的原因较多,例如数据录入时的拼写错误,缩写不同或存储类型不同等,通常表现为多条记录所表达的含义相同,或同一目标实体的记录虽然在形式上有所不同,但其描述的目标却相同。这些相似重复记录的数据特征并不明显,对数据识别和数据清洗造成了很大的难度。因此,对相似重复记录数据进行清洗,可以提高数据库的使用率,降低系统消耗,并提高数据质量。
重复数据检测主要分为基于字段和基于记录的重复检测。基于字段的重复检测算法主要包括编辑距离算法等。基于记录的重复检测算法主要包括排序邻居算法、优先队列算法、N-Gram 聚类算法[11]。重复数据清洗子模块采用排序合并算法,如图5所示。
重复数据清洗的主要过程为:
(1)通过对源数据库属性段的分析,找到属性的关键值,并根据关键值对源数据库中的数据记录进行排序,可以选择自上而下或者自下而上的顺序来排序;
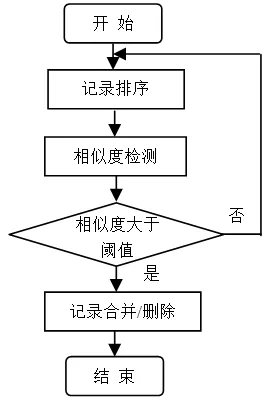
图5 相似重复数据清洗流程Fig.5 Approximate duplicate data cleaning process
(2)按顺序扫描数据库中的每一条记录,并将它与相邻的记录进行比较,进行记录的相似度匹配计算;
(3)如果计算出的相似度数值大于系统设定的阈值,说明该记录或连续的几条记录为相似重复记录,则进行数据记录的合并或删除操作;否则,扫描下一条数据记录,重复以上第2)和3)的步骤。
(4)当所有数据记录检测完毕,输出最后结果。
4 结语
大数据环境下数据具有数据量大、价值密度低等的特点,由于拼写错误、数据合并等原因导致信息中包含一些缺失数据、异常数据和不一致数据,这样的数据称为“脏数据”,严重影响了数据利用的效率和决策质量,而数据清洗技术则可以提高数据质量,使系统中的数据更加准确、一致,并能够支持决策。数据清洗技术在各个领域中应用较广泛,例如:银行、交通、水利[12]等。本文对数据清洗的定义和原理进行研究,提出大数据环境下的数据清洗的一般性框架,详细分析了不完整数据清洗子模块、不一致数据修复子模块和相似重复记录数据清洗子模块中的清洗流程,对相似重复记录清洗算法效率的优化是下一步的研究重点。
[1] 马晓亭. 基于大数据决策分析需求的图书馆大数据清洗系统设计[J]. 现代情报, 2016, 36(9): 107-111.
[2] 马凯航, 高永明, 吴止锾. 大数据时代数据管理技术研究综述[J]. 软件, 2015, 36(10): 46-49.
[3] 王书梦, 吴晓松. 大数据环境下基于MapReduce 的网络舆情热点发现[J]. 软件, 2015, 36(7): 108-113.
[4] S. Madden. From databases to big data[J]. IEEE Internet Computing, 2012: 4-6.
[5] 叶欧, 张璟, 李军怀. 中文数据清洗研究综述[J]. 计算机工程与应用, 2012, 48(14): 121-129.
[6] Galharda H, Florescu D, Shasha D. Declarative Data Cleaning: Language, Model and Algorithms[C]. Proceedings of the 27thInternational Conference on the Very Large Data Bases,Roma: Morgan Kaufmann, 2001: 371-380.
[7] Galhardas H, Florescu D, Shasha D. AJAX: an Extensible Data Cleaning Tool [C]. Proceedings of the ACM SIGMOD International Conference on Management of Data, 2000:590-598.
[8] Raman V, Hellerstein J. Potter’s Wheel: an Interactive Data Cleaning Systems [C]. Proceedings of the 27thInternational Conference on the Very Large Data Bases, 2001: 381-390.
[9] 王芳潇, 曹建军, 汪挺. 一种通用数据清洗框架的研究与应用[J]. 现代军事通信, 2010, 18(1): 60-63.
[10] Maletic J, Marcus A. Data cleansing: beyond integrity analysis[J]. Division of Computer Science, 2000.
[11] 邱越峰, 田增平, 周傲英. 一种高效的检测相似重复记录的方法[J]. 计算机学报, 2001, 24(1): 69-75.
[12] 王海沛, 冯军军, 贾如春. 水利云下的数据清洗策略研究与实现[J]. 软件, 2016, 37(10): 89-93.
Research on the Data Cleaning Framework in Big Data
FENG Fu-jun, YAO Jun-ping, LI Xin-she, MA Jun-chun
(Research Inst. of High-Tech, ShaanXi Xi'an, 710025, China)
Some dirty data exists inevitably under big data environment, and it seriously affects the data quality,while the technology of data cleaning is one of the most important mothes to improve data quality, and the researches on the data cleaning framework are helpful for big data decision. A general framework of data cleaning in big data is proposed, the core data cleaning module includes three submodules, which are imcompleted records cleaning, inconsistent data repairing and approximate duplicate records cleaning, and the processes of data cleaning are discussed specifically.
Big data; Data quality; Data cleaning; Approximate duplicate records
TP393
A
10.3969/j.issn.1003-6970.2017.12.037
本文著录格式:封富君,姚俊萍,李新社,等. 大数据环境下的数据清洗框架研究[J]. 软件,2017,38(12):193-196
封富君(1978-),女,讲师,主要研究方向:信息安全、大数据;姚俊萍(1978-),女,副教授,研究方向:信息安全、大数据;李新社(1965-),男,副教授,研究方向:信息安全、大数据;马俊春(1983-),女,讲师,研究方向:信息安全、大数据。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
数学物理学报(2020年3期)2020-07-27
法大研究生(2017年1期)2017-04-10
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
汽车与新动力(2012年1期)2012-03-25
