
多特征融合的新闻聚类相似度计算方法
2018-01-02 08:44李俊峰
软件 2017年12期
李俊峰
(北京邮电大学网络技术研究院,北京 100876)
多特征融合的新闻聚类相似度计算方法
李俊峰
(北京邮电大学网络技术研究院,北京 100876)
随着网络的发展,互联网已经成为了最重要的新闻媒介。网络上的新闻报道能广泛传播,对社会有着深刻的影响。因此互联网新闻事件的监督和挖掘分析,对政府,企业有着巨大的价值。在进行新闻报道分析的时候,最为重要的任务之一就是把网络上类别杂乱,来源广泛的新闻进行识别和归类。新闻归类主要是基于通用的聚类的方法,其中一项基本的技术就是新闻报道相似度计算。
根据需求不同,新闻聚类类别可以是一个事件,或者是一领域。本文针对事件的新闻报道聚类,提出了一种混合特征的相似度计算方法。采用了 Tf-Idf和n-gram结合的向量空间模型来得到文本相似度,再通过规则识别出新闻文本中的时间,地点等关键信息,进行关键信息匹配度计算,最后再把两个相似度结合作为最终匹配度。实验表明,混合特征的方法明显提高了事件聚类的准召率。
计算机应用技术;话题发现;聚类;文本相似度
0 引言
随着互联网的发展和普及,网络上信息体量呈指数增长,深刻影响了人们的生活的各方面。同时越来越多的媒体都利用互联网通过论坛、博客、微博等平台发表新闻和评论,事件经网络传播,能迅速得引起大量民众关注,形成网络热点。在这种情况下,对互联网新闻报道的监督和分析无疑对企业和政府有着巨大的用处。然而相对的,互联网上的信息大多是没有经过整合的,更为杂乱,不利于分析和整合。因此在做互联网新闻报道分析,挖掘的时候,往往需要利用一些技术对新闻报道,话题进行聚合,归并。
根据需求不同,聚类类别可以是一个事件[1],或者是一领域。本文针对事件的新闻报道聚类,提出了一种混合特征的相似度计算方法。新闻报道的聚合,即把报道内容,报道事件相同的事件聚集在一起,所使用的技术核心是基于文本的聚类技术。常用的话题聚类方法有k-means,single-pass。在特征挖掘方面,文献[2]则引入了凝聚层次聚类来提升聚类效果。文献[3]提出了了基于标签的话题发现方法,根据Twitter中的hashtag的变化趋势来发掘话题。无论使用哪种聚类方法,计算报道相似度都是聚类基础,需要深入地挖掘特征来计算。计算报道相似度的策略对聚类的精确度有着极大地影响,本文从特征挖掘的角度出发,提出了融合多种特征的报道相似度方法,提高聚类的精确度。
1 报道文本聚类方法
聚类,即将数据对象分组成为多个类或者簇,在同一个簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大。常用的聚类方法有混合高斯算法 GMM,k-means,层次聚类,single-pass聚类,谱聚类[4]。其中混合高斯算法GMM,k-means,谱聚类需要事先确定聚类类别 K。层次聚类,single-pass聚类则是通过相似度的阈值来划分类别。
在新闻报道文本聚类的场景下,聚类的目的是将报道事件对象相同的文本聚合在一起,这种情况下聚类的类别也就是事件的个数,是无法通过经验来事先估计得到的。因此在针对新闻报道做事件内容聚类的时候,采用HAC层次聚类,single-pass聚类这些基于相似度阈值,而不需要确定类别数量的方法更为合适。
1.1 Single-pass聚类
Single-Pass算法又称单通道法或单遍法,是一种增量聚类方法。Single-Pass算法需要按一定顺序依次读取数据,每次读取的新样本都和已有的类别进行比较,如果与其中的某一类匹配,则归到这一类中,否则创建新类[5]。
设新闻报道的样本集合为 D = {d1, d2, d3,…,dk,…, dn},初始类集合C为空集,具体步骤如下:
第一步:从数据集读入一个新的样本di
第二步:以这个样本构建一个新的类Ck
第三步:计算它与类集合中每个类之间的距离,并选择与它相似度最大的簇 Cj。如果 Ck和 Cj的相似度大于一定阈值F,合并Ck到类Cj中;否则,把Ck加入类集合C中。
第四步:重复一,二,三步直到所有数据处理完毕。
1.2 凝聚层次聚类模型
层次聚类算法(Hierarchical Clustering,简称HAC)又称为树聚类算法,它使用数据的联接规则,透过一种层次架构方式,反复将数据进行分裂或聚合,以形成一个层次序列的聚类问题解[6]。层次聚类可分为凝聚的,分裂的两种方案。凝聚的层次聚类,就是首先把每对象设为一个类别,再根据条件迭代合并。分裂的层次聚类则相反,首先把所有对象归为同一个类别,再迭代地去分裂类别。
在本文中采用凝聚层次聚类模型,设新闻报道的样本集合为D={d1, d2, d3,…, dk,…, dn}聚类的基本步骤[7]就是:
第一步:把每个样本自身归为一类,设类集合为C={C1, C2, C3,…, Ci,…, Cn},初始时每个类的元素只有一个,即Ci={di}。
第二步:计算两两之间的相似度分数,Sij=Sim{Ci,Cj}。
第三步:选择出结果中最大相似度分数Sij对应的两个类 Ci和 Cj,把他们合并为一个新类 C′=Ci∪Cj,此时类别集合变为 C={C1, C2, C3,…, Ci,…, Cn-1}。
第四步:重复二,三步直到所有样本点都归为一类,或者最大相似度Sij小于一定的阈值F。
Single-pass和凝聚层级聚类都使用于无法确定类别数量K的聚类的情况,都适合用于新闻报道的聚类,但是两者的使用场景也有所不同。Single-pass是增量聚类,适合用于进行实时的聚类,数据需要有一定的时序属性,方法简单但是聚类精确度不高。而层级聚类HAC则是非增量的聚类方法,计算复杂度高,但是一般情况下精确度也比较好。
2 新闻报道文本相似度计算
相似度的计算是聚类的基础,在本文主要考虑文本信息,根据文本提取特征计算相似度。提取文本特征最常用的处理方法就是建立基于 TF-IDF的向量空间模型。
2.1 向量空间模型
向量空间模型(Vector Space Model,简称VSM)的基本思想是以向量来表示文本,用空间距离体现语义相似度[8]。对一篇新闻文档 D,其向量可表示为式(1):
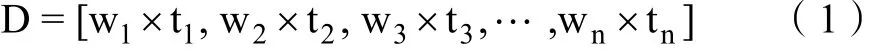
其中ti表示第i个特征,取值为0或1,wi则代表这个特征对应的特征权重。
对于向量化后的特征,最常用计算相似度方法就是余弦相似度,表示为式(2):
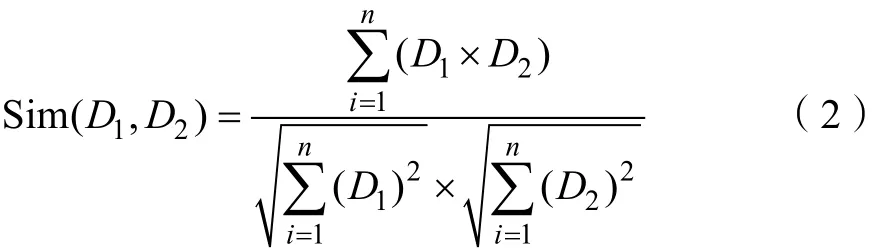
2.1.1 TF-IDF
TF-IDF(term frequency-inverse document frequency)是一种常用的文本处理中的权重计算方法[9],TF意思是词频(Term Frequency),IDF意思是逆向文件频率(Inverse Document Frequency)。其思想就是,在一篇文档中,某个字词的重要性和它在本文档出现的次数成正比,和它在语料库出现的总频率成反比。
词频(Term Frequency)计算公式如式(3)所示:

其中nij是词在文档中的出现次数,而分母则是在文档中包含的总字词数。
逆向文件频率(Inverse Document Frequency)计算公式如式(4)所示:

其中|D|为语料库中的文件总数。如果用TFIDF于计算新文档,且此文档时包含词语 如果该词语不在原语料库中,就会导致被除数为零。此时可以把分母项加1,做平滑处理,公式变为式(5):

最终的TF-IDF值为式(6):

在特定文档内的高词频,以及该在整个文件集合中的低文档频率的词语,能得到高权重的TF-IDF值。因此,TF-IDF倾向于过滤掉过于常见的词语,保留重要的词语。
TF-IDF是基于词频角度挖掘的文本特征,忽略了词之间的邻近顺序等重要信息,没有完全提取原有文档的语义特征,因此本文将n-gram语言模型也结合在一起,挖掘更多的特征。
2.1.2 n-gram语言模型
语言模型就是用来计算一个句子的概率的模型,即 P(W1, W2,…Wk)。n-gram 模型也称为 n-1阶马尔科夫模型,它有一个有限历史假设:当前词的出现概率仅仅与前面n-1个词相关。
n-gram在特征提取中,则可以看做提取当前词语与后继 n-1个词语所组成的短语[10]。例如使用2-gram,设文档为D = {w1, w2, w3},wi为其中的词,则可以提取出特征词组合T = {w1w2,w2w3}。
n-gram实质上枚举了所有可能的组合,但是其中有大量组合是非法的,这样直接使用会加大模型的空间复杂度,并且影响相似度计算,因此必须要做词组的过滤。通常的方法就是基于词频进行过滤,对于词组频率小于一定阈值的直接舍弃。
例如“现场浓烟滚滚,消防官兵到达后开始紧急救火,由于火势较大,多部门联合指挥灭火行动。事故原因和人员伤亡情况有待进一步调查。”,当使用n-gram提取时,可以提取出“事故原因”,“人员伤亡”,“灭火行动”,“浓烟滚滚”,“消防官兵”等词组特征。
2.1.3 向量空间特征组合
设原始分词后为,句子的词向量为:

n为语料库词数量,当ti=1,代表本句中包含这个词,ti=0则为不包含。
设通过公式(6)计算得到的特征的 TFIDF权重向量为(未出现的词直接置0):
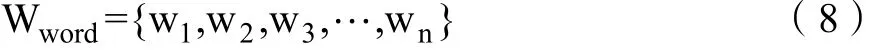
在n-gram提取和过滤处理后,得到句子的词组向量为:

n为语料库词数量,当ti=1,代表本句中包含这个词组,ti=0则为不包词组。对n-gram的词组也进行TFIDF值计算,得到得到TFIDF权重向量为:
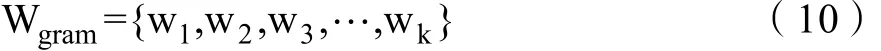
最后权重向量特征可以合并在一起,得到组合的特征向量,即为:
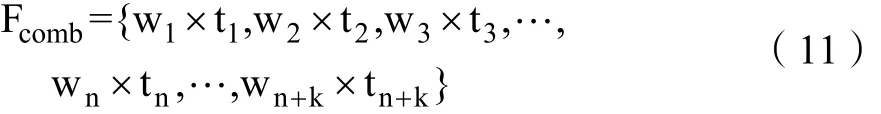
文本相似度则取特征向量的余弦值,表示为:
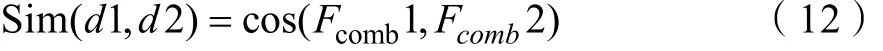
2.2 关键信息点匹配
部分描述的空间向量模型主要是基于词,词组特征进行建模,但是对于新闻报道类聚合的相似度计算,除了单纯的词,词组特征还有一些特有的信息点可以提取。新闻和报道一般都会包含时间,地点,人物等等要素,统一件事件,无论用什么方法去描述,它的这些要素都是不变的。因此这些关系的信息点可以看做比较显著特征,可以做单独处理,进行更为细致的匹配。本文主要对时间和地点进行匹配,在进行相应的相似度计算。
2.2.1 时间关键词匹配
在时间关键词匹配中,由于文本中的时间信息是非格式化的,无法直接去匹配,需要首先进行时间词识别,按一定的规则模板抽取出其中的时间信息。时间关键词可分为表示年月日的日期关键词Td,和表示小时或者时段的时刻关键词Tt,分别进行提取。
对于日期关键词,具体分为以下几类:
数字类,例如“12日”,“7月2日”:对于此类使用模板进行正则匹配提取,例如“*月*日”,其中“*”代表通配符。
相对日期,例如“昨天”,“明天”:对于此类的关键词不多,所以可以直接使用关键词匹配。
在抓取新闻文本的时候基本都可以得到新闻的发布时间,对于相对日期,可以通过简单的日期加运算得到具体的时间。
对于时刻关键词,分为以下几类:
数字类,例如“8点12分”,“十时十二分”:对于此类使用模板进行正则匹配提取,例如“*点*分”。
模糊时刻,例如“上午”,“下午”:对于此类的关键词不多,所以可以直接使用关键词匹配。在记录的时候同时归一化为一定的时间范围,例如上午对应8-12点。
在识别时间词后,根据时间词计算匹配。设文档集合为D = {D1, D2, D3,…,Dk,…,Dn},对其中两文档Di和Dj,对应的日期词,时刻词分别为Tdi和Tdj,Tti和Ttj。采用以下策略计算时间词匹配相似度St。
第一步:初始化St= 0。
第二步:如果日期词Tdi或者Tdj有一个缺省,直接到第三步。否则对日期词进行匹配,如果Tdi=Tdj,则匹配得分累加为St=St+St1;如果不匹配,这令St=St-St1,并直接结束。
第三步:如果时刻词 Tti或者 Ttj有一个缺省,直接结束。否则对时刻词进行匹配,如果 Tti=Ttj,则匹配得分累加为 St=St+St2;如果不匹配,这令St=St-St2。如果含有模糊时刻词,且匹配成功(即落在时刻段范围内),则匹配得分累加为St=St+St3;如果不匹配,这令St=St-St3。
其中St1,St2,St3,为三个匹配分数,本文中取0.4,0.4,0.2。
2.2.2 地点关键词匹配
地点关键词种类比较多,有“上海”,“北京”这类的省市地点词,也有“商场”,“工厂”等场所词,还可以是“101号公路”等等更具体的地点词。由于很多地点词存在歧义,而省市地点词一般比较固定,因此在本文只选择省市地点词做匹配。
地点关键词提取:首先根据中国省,市名,以及对应的区建立3层级词表。格式为:
北京(省级)-北京(市级)-海淀区(区级)
通过词匹配提取文中的地点词,得到3个层级的地点词,省Pp,市Pc和区Pa。如果匹配不到则设为空,如果省级信息为空,市级信息非空,则根据层级关系填充省信息。
设文档集合为 D = {D1, D2, D3,…, Dk,…, Dn},对其中两文档Di和Dj,对应的省,市,区关键词分别为 Ppi和 Ppj,Pci和 Pcj,Pdi和 Pdj。采用以下策略计算地点词匹配相似度St。
第一步:初始化Sp= 0
第二步:匹配省级,如果Ppi,Ppj都不缺省:如果 Ppi==Ppj,则 Sp=Sp+Sp1;否则 Sp=Sp-Sp1,直接结束;
第三步:匹配市级,如果Pci,Pcj都不缺省:如果 Pci==Pcj,则 Sp=Sp+Sp2;否则 Sp=Sp-Sp2,直接结束;
第四步:匹配区级,如果Pdi,Pdj都不缺省:如果 Pdi==Pdj,则 Sp=Sp+Sp3;否则 Sp=Sp-Sp3,其中 Sp1,Sp2,Sp3,为三个匹配分数,本文中取 0.2,0.5,0.3。
2.3 混合特征相似度计算
结合向量空间模型中的词和ngram特征,以及关键信息点匹配的特征,得到总的文本相似度公式为:

其中α,β,δ为权重参数,本文中取0.7,0.15,0.15。
3 实验
为了验证混合特征聚类方法的有效性,使用网络爬虫,基于微博的检索功能,抓取了新浪微博上面大约2000条关于电梯故障或事故的新闻报道,并进行人工标注,归类新闻。在实验中n-gram的n值取 2。在经过分词,去停用词处理后,分别使用基于TF-IDF的向量空间模型,TF-IDF和2-gram的向量空间模型,混合VSM和信息点匹配的策略进行报道相似度的计算。计算出相似度后,使用凝聚层次聚类HAC的方法进行聚类。
在评价聚类结果的时候,采用一般信息检索常用的标准:准确率,召回率。准确率,召回率计算方法可表示:
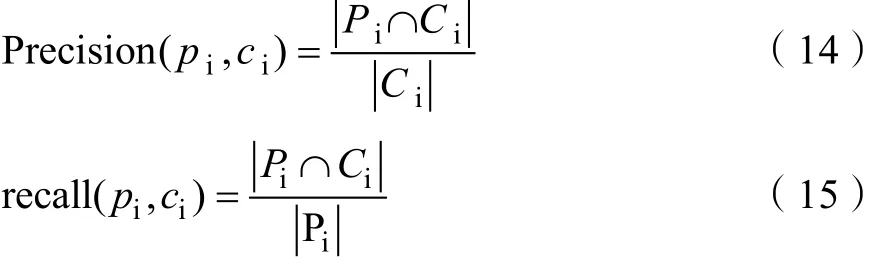
其中Pi为实际类标记为i样本,Ci为机器标记为i的样本。
在评价聚类的时候涉及一个标签对应的问题:在人工标注的时候标记的编号,和程序自动聚类时候打的编号需要一一对应。这里基于人工标签,采用贪心地方法进行对应,这时准召率计算方法如下:
标签匹配:设人工标签的类标签为 L={L1, L2,L3…},程序聚类的类标签为M={M1, M2, M3…},令L∩M={}。对于每一个人工标签的类Li,遍历其中的样本,找出其中数量最多的程序标注类Mk,然后把 Mk映射到 Li。例如,设第 Li个人工标注类中程序标注类标签为{1,2,3,2,2},其中样本数量最多的程序标注类对应的标签为 2,则人工标签 Li与程序标签2对齐,把程序类标签2映射到Li上。按此策略处理所有人工标签类,直到每个都找到匹配。每个程序标签的类不一定能匹配上人工标签类,这种情况会在计算召回率的时候受到惩罚。
计算准确率:Ci为人工标注类为i的样本个数,Pi∩Ci则为这些样本中映射为 i的程序标注类的样本数量,即准确率为一个人工标注类里面最大程序标注类数量的的占比。例如,设第 i个人工标注类中程序标注类标签为{1,2,3,2,2},人工标注类Ci数量为 5,其中样本数量最多的程序标注类对应的标签为2,即人工标签i与程序标签2对齐,程序标签2数量为3,因此准确率为3/5=60%。
计算召回率:设Pi为类标签映射为i程序标注类的样本个数,Pi∩Ci则为这些样本中人工标注类为i的样本个数。例如,设标签映射为2的程序标注类中人工标注类标签为{1,2,2,2,2},程序标注映射为2的类的样本总数量为5,其中人工标签为2的样本数量为 4,因此准确率为 4/5=80%。如果一个程序标注类没有映射,即没有匹配上人工标注类,则令召回率为0。
基于凝聚层次聚类的算法需要事先确定聚类阈值 T,因此实验中设置不同的阈值 T分别对基于TFIDF,基于TFIDF+2gram,基于混合特征的三种相似度计算方法进行实验,得到实验数据如表1所示.
在实验中阈值比较大时,准确率变得很高,因为当阈值过大的时候,划分为一个类的标准变得很严格,一个类的样本变得很小,准确率保持比较高,但是同时召回率会降低。
从实验可以看出,加入n-gram词组后的向量空间模型一定程度上提升了聚类效果,通过分析差异样本时发现n-gram提取的一些词组,类似于“购物中心”,”腰椎骨折”,”废弃工地”,比较起“购物”,“中心”,”腰椎”,“骨折”等词来看有更强的区别度,能对聚类有很大帮助。与基于单独的TFIDF模型相比,基于n-gram和TFIDF组合的模型随T曲线中,峰值出现比较早,这是因为2-gram的词组比单词匹配的频率要更低,而余弦值总是在0~1之间,所以基于n-gram和TFIDF组合的模型计算出来的相似度总体偏低,用比较小的阈值T可以得到更好的效果。

表1 聚类准确率Tab.1 Accuracy rate

表2 聚类召回率Tab.2 Recall rate
采用向量空间模型和信息点匹配结合的混合特征模型得到了最好的效果,对召回率的提升最为明显,另外受阈值影响产生的波动比较小,更有鲁棒性。因为基于词和基于信息点的特征匹配可以很好地互补:对于时间,地点这些信息点没有缺失的情况下,一旦匹配上相似度会很大,从而可以保证精准召回。而在这些特定信息缺少的情况下,向量空间模型可以从语义上进行补充。
4 结论
本文提出了一种使用混合特征进行新闻报道聚类的方法,在传统的基于TFIDF的向量空间特征上加入了n-gram特征;并针对新闻报道的特点提取了关键信息点,把信息点匹配和向量空间模型进行组合,从而可以使用多种特征计算相似度。实验结果表明,采用混合特征能明显地提高新闻报道聚类效果。
[1] Li B. Research on Topic Detection and Tracking[J].Computer Engineering & Applications, 2003.
[2] Cui A, Zhang M, Liu Y, et al. Discover breaking events with popular hashtags in twitter[C].
[3] Yang Y, Pierce T, Carbonell J. A study of retrospective and on-line event detection.
[4] Everitt B. Cluster analysis[J]. Quality & Quantity, 1980,14(1): 75-100.
[5] 税仪冬, 瞿有利, 黄厚宽. 周期分类和Single-Pass聚类相结合的话题识别与跟踪方法[J]. 北京交通大学学报, 2009,33(5): 85-89.Yi-Dong Shui, You-Li Qu, Hou-Kuan Huang. A New Topic Detection and Tracking Approach Combining Periodic Classification and Single-Pass Clustering. Journal of Beijing Jiaotong University [J] , 2009, 33(5): 85-89.
[6] 孙吉贵, 刘杰, 赵连宇. 聚类算法研究[J]. 软件学报, 2008,19(1):48-61.SUN Ji-Gui, LIU Jie, ZHAO Lian-Yu. Clustering Algorithms Research. Journal of Software, Vol.19, No.1, January 2008,pp. 48-61.
[7] Johnson S C. Hierarchical clustering schemes[J]. Psychometrika,1967, 32(3): 241-254.
[8] 庞剑锋, 卜东波. 基于向量空间模型的文本自动分类系统的研究与实现[J]. 计算机应用研究, 2001, 18(9): 23-26.PANG Jian-feng, BU Dong-bo, BAI Shuo. Research and Implementation of Text Categorization System Based on VSM[J].Application Research of Computers, 2001, 18(9): 23-26.
[9] Shi C Y, Chao-Jun X U, Yang X J. Study of TFIDF algorithm[J]. Journal of Computer Applications, 2009.
[10] Urnkranz J F. A Study Using n-gram Features for Text Categorization[J]. Oesterreichisches Forschungsinstitut Artificial Intelligence, 1998, 3.
A Similarity Calculation for News Clustering with Mixed
LI Jun-feng
(Institute of Network Technology, Beijing University of Posts and Telecommunications, Beijing 100876, China)
With the development of network technology,Internet have become the most important news media.The news in the Internet could be widespread and have profound influence on the society. Thus, the analysis and supervision of online news is valuable to government and company. One of the most important tasks in the analysis of online news and reports is identifying and classifying those news and reports. News and reports classifying base on general classification technologies, and a basic technology of them is the computation of news similarity.
The "class" in news classification could be an event or a field, according to different requirements. In the thesis, a algorithm of computing news and report similarity for events clustering with mixed feature is designed. This method apply both Tf-Idf and n-gram in vector space model (VSM). Furthermore, it abstracts some key information of news,such as time and place, calculating key information similarity using those information. In the end,combe those two similarity as final similarity. The experiment show that this method improve the accuracy and recall rate though mixing features.
Computer application technology; Topic detection; Clustering; Text similarity
TP391.3
A
10.3969/j.issn.1003-6970.2017.12.032
本文著录格式:李俊峰. 多特征融合的新闻聚类相似度计算方法[J]. 软件,2017,38(12):170-174
李俊峰(1992-),男,研究生,研究方向:自然语言处理。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
活力(2019年15期)2019-09-25
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
信息安全研究(2016年4期)2016-12-01
公民与法治(2016年10期)2016-05-17
新闻传播(2015年21期)2015-07-18
新闻传播(2015年9期)2015-07-18
