
二次近邻稀疏重构法及人脸识别
2017-12-20 01:07邵冬华施志刚史军杰
重庆邮电大学学报(自然科学版) 2017年6期
邵冬华,施志刚,史军杰
(1.南通航运职业技术学院 教育信息化管理中心,江苏 南通 226010;2.南通航运职业技术学院 管理信息系,江苏 南通 226010)

二次近邻稀疏重构法及人脸识别
邵冬华1,施志刚2,史军杰2
(1.南通航运职业技术学院 教育信息化管理中心,江苏 南通 226010;2.南通航运职业技术学院 管理信息系,江苏 南通 226010)
基于整个数据集的稀疏表示(sparse representation classification, SRC)用于人脸识别在很大程度上影响了运行效率。如何利用较少样本稀疏表示在保证计算效率的同时,识别率也有一定提升,尤其是面对光照、角度、姿态等非受控环境,目前仍是一个问题。考虑到协同表示(collaborative representation classification, CRC)基于l2范数稀疏求解的优势,为进一步提升CRC的整体分类性能,引入类内近邻,提出一种二次近邻稀疏重构表示法。该方法首先在原始训练集上选择各类训练样本中与待测样本距离相近的若干样本组成近邻样本集,并协同表示,接着分别用各类近邻样本重构待测样本,再次选择与待测样本相近的若干重构样本协同表示,最终实现模式分类。在ORL和FERET数据库上的仿真实验表明,相比现有的一些CRC算法,该方法在一定程度上缩短了运行时间,并使识别更精确。
稀疏表示;人脸识别;协同表示;二次近邻;稀疏重构
0 引 言
鲁棒性人脸识别是目前生物特征识别领域的热点和难点。这其中基于特征提取的方法[1-4],旨在寻找目标图像的低维特征与分类的相关性。虽然在一定程度上提升了人脸识别的性能,但至今还没有权威的高维图像到低维空间的变换准则。近年来,基于压缩感知编码理论的稀疏表示(sparse representation classification ,SRC) 因对图像噪声不敏感而引起广泛关注。此模型最先由WRIGHT等[5]提出,它通过在高维空间对人脸图像的表示来完成模式分类。进一步的,一些研究人员通过在稀疏求解中嵌入迭代加权系数,提出了鲁棒性更强的方法[6-7]。考虑到SRC过于强调范数的稀疏性,计算中需要迭代,致使复杂度较高。为此,YANG和ZHANG[8]提出基于Gabor变换提取图像局部方向性特征用于SRC,降低了算法的复杂度,且识别效果更佳。
SRC要求样本的完备性,但在实际应用中,往往并非如此。这样即使目标样本确定归属,有限的属类样本也很难线性表示。于是,ZHANG等[9]人通过分析指出类间样本的相似性对于稀疏表示的作用,提出协同表示分类(collaborative representation classification, CRC),此算法基于l2-范数的稀疏求解在大幅缩短运行时间的同时,依然保持和SRC相当的识别效果。文献[10]将图像通过Shearlet多尺度变换后进行融合,结合分块用均匀局部二值模式(uniform local binary pattern, ULBP)提取特征以协同表示,改善了识别效果,但算法的复杂度较高。WEI[11]提出将灰度图像8个位平面的有效识别信息进行加权,通过构造虚拟图像协同表示,有效提升了识别性能。文献[12]提出鲁棒协同表示(robust collaborative representation, RCR),相比文献[6-7]方法,此算法计算复杂度大大降低。另外,LU[13]和FAN[14]指出样本的有效局部信息对稀疏表示的重要性,分别提出加权稀疏表示(weighted sparse representation classification, WSRC),有效增强了分类性能。但此方法通过权衡各训练样本与目标样本的相似性构建加权矩阵,嵌入在基于整个数据集协同表示的系数求解中,很大程度上会降低运行效率。受此启发,并针对存在遮挡等非受控环境,文献[15]引入分块思想,通过提取各训练样本与测试样本对应子图像的最大相似信息嵌入在稀疏表示中,无论识别率还是运行效率都有不同程度的提升。鉴于样本中的光照、角度、姿态等信息不能有效利用对分类的干扰,文献[16]通过不同场景构造虚拟样本协同表示(virtual samples collaborative representation classification, VSCRC),虽然有较好的识别效果,但扩张的训练样本无疑会消耗系数求解的时间。文献[17]通过阶段性缩小目标类别的二级分类法(coarse to fine face recognition, CFFR)使识别更精确,但同样基于整个数据集的协同表示在运行时间上没有太大优势。
综合近年来流行的基于CRC算法的分析,均是基于整个数据集协同表示,这样在系数求解中势必会降低计算效率。此外,一些与目标样本相关性较小的训练样本参与稀疏表示,在一定程度上反而会影响到分类的实效。文献[18-20] 验证了适合数量且相似的样本协同表示不仅能获得更高的识别率,而且可以降低算法的复杂度。基于上述考虑,文章提出二次近邻稀疏重构表示法。通过在原始训练集中选择和目标样本更相似的各类样本协同表示,不仅可以降低运行时间,而且通过对目标样本的一次重构,从与原始样本类别数相同的重构样本中再次选择和目标样本相近的样本协同表示,可以进一步缩小分类目标,使识别更精确。在ORL及FERET数据库上的实验证明了本文方法的有效性。
1 协同表示分类原理
如果测试样本矢量y∈Rm×1属于某类,则有
y=Xα
(1)


‖α‖1,s.t.‖y-Xα‖2≤ε
(2)
ZHANG等在此基础上提出所有样本的CRC,以l2代替l1范数简化计算。引入正则化参数λ稳定重构误差和稀疏性,系数α的最优求解定义为
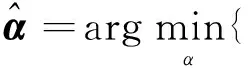
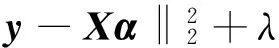
(3)
(3)式中,系数α可通过对(3)式求导得出,即
α=(XTX+λI)-1XTy
(4)
通过(5)式计算各类训练样本重构与测试样本y的残差ei,即
ei=‖y-Xiαi‖2
(5)
最后依据ei的最小值判断y的类别
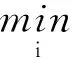
(6)
2 二次近邻稀疏重构人脸识别方法
首先选取每类训练样本中与待测样本近邻的样本协同表示;获取稀疏系数后,利用各类近邻样本分别重构待测样本,从而组成与原始训练样本类别数相同的重构样本集;然后再次选择与测试样本距离最近的若干重构样本协同表示,并进行二次重构;最终实现模式分类。具体算法步骤如下。
Step1原始训练样本集定义已在前文描述,对于任意待测样本y∈Rm×1,分别求其在第i类训练样本的K个近邻,组成新的近邻样本集。
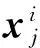
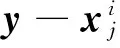
i=1,2,…,C;j=1,2,…,ni
(7)
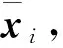
i=1,2,…,C,
j=1,2,…,ni,K≤ni
(8)

(9)
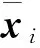
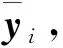
(10)


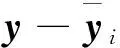
(11)

i=1,2,…,C,l=1,2,…,K′。
(12)

(13)
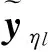
(14)
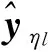

(15)

3 实验结果与分析
实验硬件环境为Intel Core i5-4210M处理器,2.60 GHz主频,4 GB内存, 用Matlab7仿真,在ORL和FERET人脸库上验证本文方法的有效性。本文实验中λ=0.01。
3.1 在ORL库上的实验
ORL数据库有40人,每人包含10幅不同表情、姿态、角度、光照等差异的人脸图片,大小均为112×92像素。图1为ORL库中某人图像实例。
本实验分4组进行,分别取每类训练样本前ni=4,5,6,7幅为训练样本,余下的用来测试。通过一次近邻K和二次近邻K′的选择来比较本文方法在ORL库上的识别效果。如图2所示。

图1 ORL库某人图像实例Fig.1 Examples of someone’s images in ORL database

图2 ORL库上ni不同时在K近邻下取不同K′的识别率Fig.2 Recognition rate of different K′ under the nearest K neighbors while ni is different on ORL database
从图2可见,当ni不同时,选择与测试样本更相似的若干样本协同表示,分别在K=2,3,3,4,即K=ceil(ni/2)时,近邻效果最优。这种通过在各类样本中选取K近邻的协同表示,可得到与类别数(C=40)相同的重构样本,再选择K′个近邻重构样本协同分类,可获得更高的识别率,分别在K′=6,9,3,13时,达到最高,依次是91.25%,91.50%,94.37%和95.83%。相比文献[20],在重构样本中选择近邻稀疏重构可以进一步缩小分类目标,使识别更精确。表1为ni=6时,各方法识别性能比较。表1中,CFFR方法第2阶段类别数取6,局部稀疏表示(local sparse representation classification, LSRC)和改进的局部稀疏表示(improved local sparse representation classification, ILSRC)方法基于所有训练样本的近邻数取40。
从表1中看出,本文方法在ORL库上,识别率相比WSRC和VSCRC分别提高了6.87%和6.25%。虽然本文方法与CFFR识别率相同,但在识别效率上有较大优势,平均识别时间提高了2倍多。原因在于CFFR和本文方法虽然均采用二级分类以缩小目标类别为目的,识别率相当,但是2个阶段系数求解效率不同,取决于总样本数。在第1阶段CFFR基于整个训练集,而本文方法则基于局部样本,数量仅为CFFR的1/2;到了第2阶段,CFFR用于计算系数的样本数为36,而本文方法为3。表2为ORL库上各方法系数求解时间对比。虽然本文方法在2次近邻选择中通过计算各训练样本及重构样本与测试样本的距离会消耗一定的运行时间,但在实验中发现其在整个识别时间中只有0.020 3 s,可见,系数计算效率在很大程度上决定了运行时间的长短。很明显,本文方法通过较少样本的稀疏表示在保持高识别率的同时算法效率进一步提升。WSRC通过构造加权矩阵嵌入到基于整个训练集的系数求解,运行效率与CFFR相当。还有VSCRC通过不同场景扩张每类样本数的做法,虽然能有效利用样本中的光照、表情等信息,识别率要好于WSRC,但样本数明显增多无疑使系数求解的效率下降,导致识别时间增加,显然不符合视觉系统中对人脸识别的实时性需求。另外,LSRC和ILSRC方法同样基于局部样本稀疏表示,其中,LSRC基于所有训练样本选择近邻,只需求解系数一次,相比本文方法计算复杂度稍低,并且由于ORL库图像质量较好,图片中几乎没有光照、人脸角度等差异,因此基于整个数据集选择近邻的效果相对较好。ILSRC由于近邻样本稀疏表示前需基于整个数据集计算每个训练样本的系数,若训练样本增多,运算复杂度就会提高,虽然识别率和本文方法相当,但运行效率没有任何优势。由此可以证明本文方法和LSRC方法整体性能更好。

表1 ORL库上各方法识别性能比较Tab.1 Recognition performance comparison of different methods on ORL database

表2 ORL库上各方法系数计算时间比较Tab.2 Time comparison of coefficient computation of different methods on ORL database
为降低运算的复杂度,通过主成份分析(principal component analysis, PCA)对图像降维比较不同维数各方法识别率,此时,ni=5,如图3所示。从图3看出,在不同维数下,本文方法识别效果明显好于VSCRC,CFFR和ILSRC,相比WSRC,随着维数增多,识别率也有所提高。因此,本文方法用于人脸识别有一定的实效。
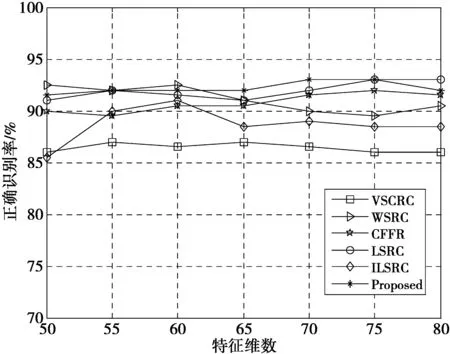
图3 ORL库上不同特征维数各方法识别率Fig.3 Recognition rate of different method under different feature dimensions on ORL database
3.2 在FERET库上的实验
FERET数据库比较庞大,实验选择50人,每人仅取7幅不同差异的人脸图像,这7幅图像的名称带有“ba”“bd”“be”“bf”“bg”“bj”“bk”字样。该数据库在姿态、角度、光照等方面差异明显,图片大小均为256×384像素,实验裁剪为80×80像素。图4为FERET库中某人图像实例。

图4 FERET库某人图像实例Fig.4 Examples of someone’s images in FERET database
本实验分3组进行,分别取每类训练样本前ni=3,4,5幅为训练样本,余下的用来测试。通过一次近邻K和二次近邻K′的选择来比较本文方法在FERET库上的识别效果,结果如图5所示。
从图5可见,当ni不同时,选择与测试样本更相似的若干样本协同表示,分别在K=2,2,3,即K=ceil(ni/2)时,近邻效果明显,这种通过在各类样本中选取K近邻的协同表示,可得到与类别数(C=50)相同的重构样本,再选择K′个近邻重构样本协同分类,识别性能更佳,分别在K′=6,39,37时,识别率最高,依次是87.00%,92.00%,94.00%。虽然在ni=4,5时,二次近邻K′值偏高,但从图5中看出,K′=2,6时,识别率也可分别达到91.33%和93.00%,和最高识别率相差无几。相比文献[20],在重构样本中选择近邻稀疏重构可以进一步缩小分类目标,使识别更精确。表3为ni=4时,各方法识别性能比较。表3中,CFFR方法第2阶段类别数取8,LSRC和ILSRC方法基于所有训练样本的近邻数取50。

图5 FERET库上ni不同时在K近邻下 取不同K′的识别率Fig.5 Recognition rate of different K′ under the nearest K neighbors while ni is different on ORL database
从表3中看出,本文方法在FERET库上,相比其他方法,识别率和CFFR相当,但平均识别时间仅是其一半,为0.176 6 s。相比LSRC方法,识别率提高了近5个百分点,虽然基于整个数据集选择近邻稀疏表示法在运行效率方面有一定优势,倘若图像中人脸的角度、姿态等差异较大,LSRC的近邻性能就下降了。与WSRC,VSCRC及ILSRC方法比较,识别时间优势明显,原因在于系数计算的复杂度,相比VSCRC,提高了近10倍,另外识别率还提高了近5个百分点。ILSRC和本文方法识别率相当,但基于每个训练样本和测试样本系数的相似性选择近邻,一旦训练样本数增多,系数计算的复杂度就会提高,因此识别时间是本文方法的近2倍。表4为FERET库上各方法系数计算时间对比。综合来看,在人脸角度、姿态甚至光照等变化更大的FERET库上,本文方法同样表现出较好的性能。

表3 FERET库上各方法识别性能比较Tab.3 Recognition performance comparison of different methods on FERET database

表4 FERET库上各方法系数计算时间比较Tab.4 Time comparison of coefficient computation of different methods on ORL database
为降低运算的复杂度,在FERET库上通过PCA对图像降维比较不同维数各方法识别率,此时,ni=4,结果如图6所示。可以看出,在不同维数下,本文方法识别效果明显好于VSCRC,WSRC和LSRC,但相比CFFR,随着维数增多,识别率不稳定。WSRC同样表现出随着维数增多,识别率下降明显。分析原因在于使用PCA降维虽然能较好提取图像的全局特征,但是人脸倘若在角度、姿态等方面变化明显,使用PCA就不能有效提取这些局部非线性成分。而本文方法和WSRC协同方法在表示前均要计算训练样本与测试样本的距离,这样在FERET库上基于PCA提取特征,由于破坏了图像的结构性信息,致使在选择近邻或构建加权系数矩阵时,会产生更多相似样本,进而对分类识别造成一定的干扰。但本文方法在某些特征维数下也可达到和CFFR同等的高识别率。因此,根据FERET库上的实验结果,本文提出的二次近邻稀疏重构法和CFFR方法用在人脸识别中有一定的效果,且各具优势。
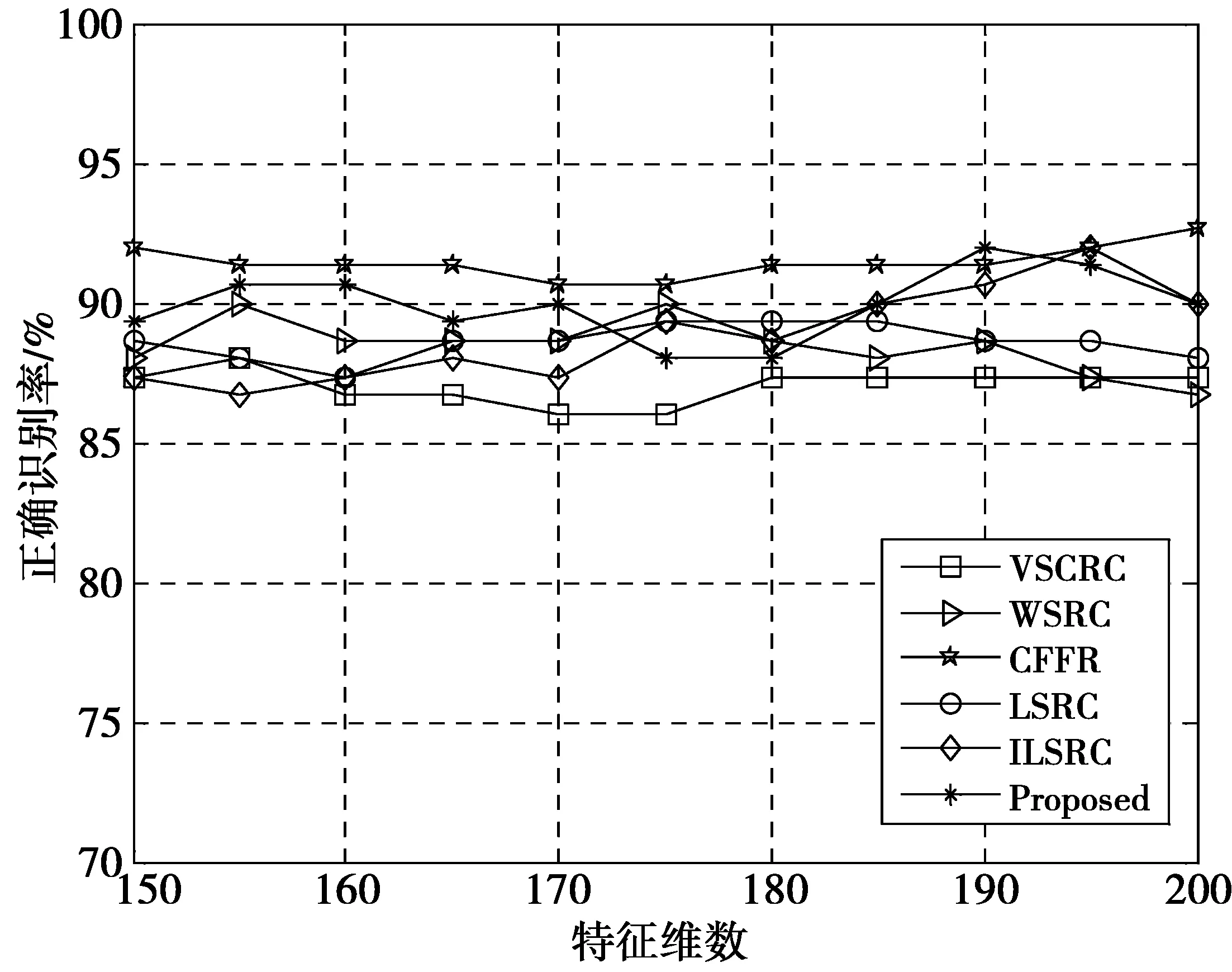
图6 FERET库上不同特征维数各方法识别率Fig.6 Recognition rate of different method under different feature dimensions on FERET database
4 结束语
基于整个数据集的稀疏表示在实际应用中存在一定的缺陷,为进一步提升CRC在人脸识别中的性能,本文提出基于二次近邻的稀疏重构法。该方法首先在原始样本集上寻找待测样本的近邻,即仅选择适合数量且有效的样本协同表示,在一定程度上提高了系数求解的效率;然后分别用各类近邻样本稀疏重构待测样本,得到与原始样本类别数相同的重构样本;接着基于重构样本集再次寻找待测样本的近邻,并协同表示,完成二次重构,最终实现模式分类。这种通过二次近邻选择更有效样本的稀疏重构法缩小了类别范围,使分类更精确。在ORL和FERET数据库上的实验验证了本文方法的有效性。
[1] TURK M, PENTLAND A. Eigenfaces for recognition[J].Cognitive Neuroscience,1991,3(1):71-86.
[2] BELHUMEUR V, HESPANHA J, KRIEGMAN D. Eigenfaces vs fisherfaces: recognition using class specific linear projection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997,19(7):711-720.
[3] 施志刚.一种基于分块差图像的2DPCA人脸识别方法[J].内蒙古师范大学学报:自然科学汉文版,2015,44(3):380-384.
SHI Zhigang. A Human Face Recognition Method of 2DPCA Based on Modular Residual Image[J]. Journal of Inner Mongolia Normal University : Natural Science Edition, 2015,44(3):380-384.
[4] 周丽芳,房斌,李伟生,等.一种自适应的EDTLBP人脸识别方法[J].重庆邮电大学学报:自然科学版,2013,25(2):192-196.
ZHOU Lifang, FANG Bin, LI Weisheng, et al. Adaptive EDTLBP Face Recognition Method[J]. Journal of Chongqing University of Posts and Telecommunications: Natural Science Edition , 2013,25(2):192-196.
[5] WRIGH T, YANG A Y, GANESH A, et al. Robust face recognition via sparse representation[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2009, 31(2):210-227.
[6] YANG Meng, ZHANG Lei, YANG Jian, et al. Robust sparse coding for face recognition[C] // Proc of IEEE Conference on Computer Vision and Pattern Recognition. Washington DC: IEEE, 2011:625-632.
[7] YANG Meng, ZHANG Lei, YANG Jian, et al. Regularized robust coding for face recognition[J]. IEEE Trans on Image Processing, 2013, 22( 5):1753-1766.
[8] YANG Meng, ZHANG Lei. Gabor feature based sparse representation for face recognition with Gabor occlusion dictionary[C]//Proc of the 11th European Conference on Computer Vision. Berlin Heidelberg, Germany: Springer, 2010:448-461.
[9] ZHANG Lei, YANG Meng, XIANG Chufeng. Sparse representation or collaborative Representation: which helps face recognition[C]//Proc of the IEEE International Conference on Computer Vision. Washington DC: IEEE, 2011:471-478.
[10] 谢佩,吴小俊.基于Shearlet变换和均匀局部二值模式特征的协作表示人脸识别算法[J].计算机应用,2015,35(7):2056-2061.
XIE Pei, WU Xiaojun. Face Recognition Algorithm of Collaborative Representation Based on Shearlet Transform and Uniform Local Binary Pattern[J]. Journal of Computer Application, 2015, 35(7):2056-2061.
[11] 魏冬梅,周卫冬.基于位平面和协作表示的人脸识别算法[J].北京理工大学学报,2014,34(9):966-971.
WEI Dongmei, ZHOU Weidong. Face Recognition Using Bit-Plane Images and Collaborative Representation[J]. Transactions of Beijing Institute of Technology, 2014, 34(9):966-971.
[12] 林国军,解梅.一种鲁棒协作表示的人脸识别算法[J].计算机应用研究,2014,31(8):2520-2522.
LIN Guojun, XIE Mei. Face Recognition Algorithm of Robust Collaborative Representation[J]. Application Research of Computers, 2014, 31(8): 2520-2522.
[13] LU Canyi,MIN Hai,GUI Jie,et al.Face recognition via weighted sparse representation[J].Journal of Visual Communication & Image Representation,2013,24(2):111-116.
[14] FAN Zizhu, NI Ming, ZHU Qi, et al. Weighted sparse representation for face recognition[J]. Neurocomputing, 2015, 151(1):304-309.
[15] 汪淑贤,熊承义,高志荣,等.分块最大相似性嵌入稀疏编码的人脸识别[J].模式识别与人工智能,2014,27(10):954-960.
WANG Shuxian, XIONG Chengyi, GAO Zhirong, et al. Face Recognition Using Sparse Coding by Embedding Maximum Block Similarity[J]. PR & AI, 2014, 27(10):954-960.
[16] 张哲来,马小虎.基于虚拟样本的协同表示人脸识别算法[J].计算机应用研究,2015,32(11):3518-3520.
ZHANG Zhelai,MA Xiaohu.Face Recognition of Collaborative Representation Based on Virtual Samples[J].Application Research of Computers,2015,32(11):3518-3520.
[17] XU Yong, ZHU Qi, FAN Zizhu, et al. Using the idea of the sparse representation to perform coarse-to-fine face recognition[J]. Information Sciences, 2013, 238(7):138-148.
[18] LI Chuguang, GUO Jun, ZHANG Honggang. Local sparse representation based classification[C] // International Conference on Pattern Recognition. Istanbul Turkey: IEEE, 2010:649-652.
[19] 尹贺峰,吴小俊,陈素根.改进的局部稀疏表示分类算法及其在人脸识别中的应用[J].计算机科学,2015,42(8):48-51.
YIN Hefeng, WU Xiaojun, CHEN Sugen. Improved LSRC and Its Application in Face Recognition[J]. Computer Science, 2015, 42(8):48-51.
[20] 施志刚,蒋玲.一种基于近邻稀疏表示的人脸识别新方法[J].重庆师范大学学报:自然科学版,2016,33(6):143-150.
SHI Zhigang, JIANG Ling. A New Method Based on the Nearest Neighbor Sparse Representation in Face Recognition[J]. Journal of Chongqing Normal University: Natural Science, 2016, 33(6):143-150.
The Key Project of Science and Technology Foundation of Nantong Shipping College(HYKJ/2016A02)
Sparsereconstructionalgorithmbasedonsecondarynearestneighborandfacerecognition
SHAO Donghua1, SHI Zhigang2, SHI Junjie2
1. Educational Information Management Center, Nantong Vocational & Technical Shipping College, Nantong 226010, P.R.China;2. Department of Management and Information, Nantong Vocational & Technical Shipping College, Nantong 226010, P.R. China)
Sparse representation classification (SRC) based on the entire data set for face recognition largely affect the running efficiency. How to use the few samples for sparse representation while ensuring the computing efficiency, the recognition rate also has a certain improvement, especially in the light, angle, attitude and other uncontrolled environment, it is still a problem. Taking into account the advantage of sparse solution based onl2norm in collaborative representation classification (CRC), on this basis, in order to further improve the overall classification performance of CRC, this article introduces the nearest neighbor of the inner class, a sparse reconstruction method based on secondary nearest neighbor is proposed. Firstly among the original training sample set, several samples of the inner class which are similar to the testing sample were chosen to construct the nearest neighbor sample set, and they collaboratively represent the testing sample, and the nearest neighbor samples in each class were used to reconstruct testing sample respectively, then some reconstructed samples which are similar to the testing sample were chosen to collaboratively represent again, finally pattern classification was realized. Experiments on the ORL and FERET database indicate that compared with some exitsing CRC algorithms, the proposed method partly makes the running time short, and the recognition rate more accurate.
sparse representation classification; face recognition; collaborative representation classification; secondary nearest neighbor; sparse reconstruction
10.3979/j.issn.1673-825X.2017.06.020
2016-08-06
2017-09-20
施志刚 benstiven@163.com
南通航运学院科技基金重点资助项目(HYKJ/2016A02)
TP391.41
A
1673-825X(2017)06-0844-07

邵冬华(1977 -),男,江苏宜兴人,副教授,硕士,主要研究方向为智能化信息处理等。E-mail:donghua@ntsc.edu.cn。

施志刚(1980 -),男,江苏南通人,讲师,硕士,主要研究方向为图像处理、模式识别等。E-mail:benstiven@163.com。

史军杰(1980 -),女,河南洛阳人,副教授,硕士,主要研究方向为信息融合、机器学习等。
(编辑:张 诚)
猜你喜欢
计算机工程(2020年3期)2020-03-19
科技创新与应用(2020年6期)2020-02-29
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国惯性技术学报(2019年6期)2019-03-04
中国交通信息化(2018年3期)2018-06-13
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
中国交通信息化(2016年2期)2016-06-06
