
基于DBSCAN的农机作业轨迹聚类研究
2017-12-16 02:52吐尔逊买买提谢建华
农机化研究 2017年4期
吐尔逊·买买提,谢建华
(新疆农业大学 机械交通学院,乌鲁木齐 830052)
基于DBSCAN的农机作业轨迹聚类研究
吐尔逊·买买提,谢建华
(新疆农业大学 机械交通学院,乌鲁木齐 830052)
农业机械在田间作业过程中,时间和空间维度上产生大量的作业数据,对农业机械作业轨迹数据进行聚类分析在农机作业状态分析和效率研究中具有重要意义。为此,应用DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法对模拟农业机械作业轨迹进行分析,设计了基于密度聚类的农机作业状态分类算法。对模拟数据的聚类结果表明:该方法正确分类农机作业班次内的有效作业轨迹、空行转移轨迹和停歇轨迹的精度达到98.33%、70%和100%。聚类作业轨迹反映的农机利用率为95.35%,为农机田间作业轨迹研究提供了依据。
农业机械;作业轨迹;密度聚类;轨迹识别
0 引言
数据挖掘技术提供了从海量数据中挖掘发展趋势、剖析其中隐藏的知识和模式的手段。针对农业机械在农业生产中产生的作业轨迹数据特征,挖掘其中隐含的知识并对其进行分析,在此基础上,设计相应预测、聚类、关联模型,为设计农机管理决策服务模型提供了基础,对促进农业机械化、提高生产效率、提高决策水平、健全调控和基层服务能力、促进农业机械化进入信息化领域的步伐有很大的推进作用[1-2]。
目前,生产要素轨迹特征研究主要有2种方法:①首先从空间维度出发,获取对象在不同时隙中的聚类模式,然后按时间顺序对获取的簇进行排序,从而获得研究对象的完整的轨迹聚类模式[3-5];②以时间维度为首要参数,挖掘可能出现有规律轨迹的时间区间,然后对挖掘得出的时间片段内的轨迹进行聚类,从而发现对象的完整轨迹模式[6-8]。
吴笛[9]等提出,在聚类过程中同时考虑轨迹包含的时间和空间信息,在空间轨迹聚类的基础上提出了轨迹线段时间距离的度量方法和阈值确定原则,对时空邻域密度进行聚类分析,挖掘物体的时空移动模式。农业机械轨迹方面的研究主要围绕着特定农业机械在局部作业环境中的作业轨迹聚类方面[10-12]。农业机械作业轨迹聚类方面的研究中提出了基于轨迹的作业状态识别方法[13],但引用传统的聚类算法对农业机械轨迹进行分析方面的研究较少。
本文应用数据挖掘中的基于密度的聚类(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)方法,结合农业机械作业状态的特征,提出了对作业状态轨迹点进行聚类的方法,并结合模拟作业数据的聚类分析,提出了基于密度聚类的农机作业状态识别方法,同时对农机利用率进行测度。
1 聚类的概念与过程
聚类算法又称群集分析,常用于将大量数据按照一定算法归类到不同的簇。其与分类算法的差异在于:聚类算法可在非监督模式下处理数据,不需要人为输入数据类标签。聚类算法发展至今约有60年余,其非监督的特性为处理大量非结构化数据提供了高效和便捷的途径,并且在大数据时代显示出更大的优势。
关于聚类,目前尚未有较统一的定义,但普遍认同的定义有:将物理或抽象对象,或样本空间中点组成的集合根据某种度量标准分成若干个互相尽可能不相似、但内部尽可能相似的类的过程称为聚类。同一簇中的两点(或对象)的相似度(或距离)高于(或小于)不同簇中两点之间的相似度(或距离)。类簇可以理解为高密度点集的高维连通区域,它们通过密度相对较低的点集组成的区域和其它类或簇相分离。
作为热门的研究领域,数据挖掘中聚类方法有5种:划分聚类方法、层次聚类方法、基于密度的方法、基于图的聚类方法和模型聚类方法。在研究和应用之中应该根据数据类型、数据的分布及聚类的目的,选择时间和空间效率能满足实际要求的高精度、简单易用的聚类算法。
本研究根据农业机械田间作业运行轨迹空间和时间数据的不规律性及数据量大等特征,选取基于密度的聚类方法。
2 研究方法
2.1 基于密度的聚类方法
依据样本空间中点的密度,对样本进行聚类的算法中,预期要发现的簇是由满足预定样本数量阈值要求的点集组成,并且不同的类簇由样本数阈值低于指定值的点集(离群点集合)分割。基于密度的算法最终要满足过滤密度低于阈值的样本区域,发现密度等于或高于指定阈值的区域。在此类算法中,无需指定簇的数量。基于密度聚类方法可以用于空间数据的聚类。
数据挖掘领域中典型的基于密度的算法有:
1)DBSCAN。依据用户给定参数,不断发现给定半径内的点数达到指定数量的高密度区域,并不断生长高密度区域。
2)DENCLUE。聚类过程中依据样本点在指定空间中的密度进行聚类。
3)OPTICS、DBCLASD、CURD。这些算法中,针对数据在数据集中呈现出的高密度区域的形状和密度,对DBSCAN做了些补充或修正。
以上3种基于密度的聚类算法中,DBSCAN聚类算法是一种常用的聚类算法。算法执行过程中,首先需要指定类簇的半径域Eps和最小对象数目MinPts;然后根据Eps和MinPts判断对象集中的对象的属性(即核心点、边界点、噪声);最后根据当前对象属性判断当前对象域是否构成一个类簇,并依据此方法判断数据集中每个点的属性。
DBSCAN算法可以对农业机械作业轨迹图像点进行密度识别,挖掘其分布特征,并找到轨迹点较密的区域,从而发现轨迹点较集中的簇,可以识别轨迹中离群点。该算法的特点是可以挖掘不同形状的类簇,可以有效地排除离群点,同时较适合空间和时间轨迹数据的聚类。
实践证明:算法对Eps和MinPts的设置较敏感,如设置不当可能造成聚类效果下降。依据农业机械田间作业轨迹数据的特征,本研究选择DBSCAN作为轨迹聚类算法。
农业机械轨迹聚类流程如下:
1)算法输入。作业周期内时空轨迹数据、半径Eps和最小轨迹数MinPts。
2)算法输出。农业机械作业轨迹类簇集。
方法:
1)放入所有轨迹点到DataPoint库,从DataPoint随机取出一个点。
2)IF Eps领域中至少包含MinPts个轨迹点,THEN 记当前点为核心轨迹点,并创建一个簇,放入其到簇库C中。ELSE IF 当前点是边界点,THEN 归入所属簇。ELSE 判断其为离群点。
3)从DataPoint库中随机取出下一个点。
4)并重复步骤2)和3),直到所有点处理完毕。
2.2 问题分解及轨迹数据
分析农业机械作业过程可发现:农业机械班次内的工作时间包括有效作业时间(t1)、田间空行时间(t2)、工艺所需时间(t3)、维修时间(t4)、转移时间(t5)和组织不善造成的停车时间(t6)等。班次内不同作业状态中,农业机械的移动速度有较大的差异,通过设定移动速度阈值,可以区分局部区域内的状态,但此方法对速度阈值的设定精度有一定的要求,如t2和t5之间差异不能很好地区分。应用GPS/北斗等手段获取轨迹信息时,其轨迹点的形态主要受到以下2个因素的影响。
1)采样频率的影响:在采样周期固定情况下,如果采样频率较大,则单位面积中的轨迹点数就较多,轨迹的空间聚集特征越明显,反之亦然。
2)采样周期的影响:农机轨迹采样的频率已知情况下,采样周期的长短与轨迹点的聚集程度成反比。另外,不同作业状态下的采样周期和频率也会对农机轨迹的聚集程度及性质的判断产生影响。
本文中假设农业机械轨迹采集过程中t1~t6采用相同的采样周期和采样频率。在此种假设下,可以判断t1和t2所对应的轨迹密度相似,计算时t2可以并入到t1。t3、t4和t6的作业轨迹呈现出高密度轨迹区,并高度相似,计算时可以并入t6。因此,对作业轨迹做聚类分析时需要考虑的轨迹类型有t1、t5和t6。本文模拟的农业机械轨迹点情况如表1所示,模拟轨迹的分配情况如图1所示。图1表明:班次作业时间内,相同的采样周期和频率下,农业机械作业空间轨迹聚集程度的顺序为:t6(图1中停歇轨迹),t1(图1中田地1、2、3),t5(图1转移轨迹1、2)。转移轨迹1和转移轨迹2的轨迹密度相似,并聚集程度最低;第1块、第2块和第3块田地中轨迹密度高度相似。停车维修点的停歇轨迹密度最高。

表1 农业机械模拟轨迹点分布
本研究根据农业机械在田间作业中轨迹的形态特征,采用基于密度的作业轨迹聚类方法。
DBSCAN对聚类参数Eps和MinPts较敏感,微小的误差会导致较大的聚类结果差异,算法中参数可以依据反复试验和类簇评估方法予以选取和确定。

图1 农业机械模拟作业轨迹分布
2.3 农机利用率评价
农机利用率是评价农业机械作业效率的重要指标。评价农机利用率时可以从时间和空间维度进行评价。从时间角度出发计算农机利用率,则计算公式为
(1)
其中,U为农机利用率;t有效作业时间;T为每班次时间。从空间维度出发,农机利用率为
(2)
其中,S为农机利用率;w为有效作业轨迹点;A为班次内轨迹点。
3 轨迹聚类及作业效率
3.1 轨迹聚类
本文应用MatLab2014a中编程实现了DBSCAN聚类算法。设定MinPts的取值范围为3~10,Eps的取值范围内为2~5,MatLab2014a平台中不同参数组合下进行聚类实验,并对聚类结果应用簇的凝聚度(cluster cohesion)和簇的分离度(cluster separation)等度量进行评估。根据评估结果最终确定:当MinPts=4、Eps=2.8时,可以得到较好的聚类效果。表2为聚类结果统计结果和正确率。

表2 农业机械模拟轨迹点分布
由表2可以看出:DBSCAN算法对农业机械轨迹聚类有较好的鲁棒性,可以较好地识别其不同的作业状态。
聚类结果说明:有效作业轨迹点的识别率较高,接近100%,停歇时间轨迹的识别率也较高,但转移轨迹的识别率为70%。主要原因是:①模拟轨迹数据未能较好地呈现出部分作业轨迹的合理状态;②DBSCAN算法本身对MinPts和Eps的选择比较敏感,有时候出现局部收敛,会影聚类的整体效果,本例中有30%的转移轨迹被识别为作业轨迹或停歇轨迹。图2为聚类后的轨迹分布情况。观察图2后可发现:被错误的识别为作业轨迹的点位于真实作业轨迹区域和转移轨迹区域的边界处,结合模拟轨迹数据聚类后呈现出的这种簇结构和农业机械田间作业速度变化特征,可以认为模拟数据能够较好地反映真实情况。
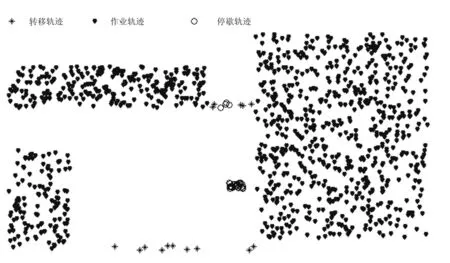
图2 农业机械模拟轨迹聚类结果
同时,结果也表明:转移轨迹中部分点被识别为停歇轨迹,模拟数据反映的这种趋势和真实数据的分布特征有一定的相似性。即农机作业过程中,农机转移时可能会出现短暂的停车修正过程,这种状态在模拟轨迹数据中反映出来,说明模拟数据一定程度具备实际数据的特征。
3.2 作业效率
因本文中根据轨迹点分布特征判断其作业状态(有效作业、转移和停歇),而未考虑作业状态的持续时长,所以计算其作业效率时可以用式(2)测度农机利用效率。计算结果显示,模拟作业轨迹所反映的农机利用率为95.35%。
4 结果与结论
本文首先根据农机作业状态的特征,对其作业时间进行人工分类,农机作业状态分为t1、t2、t3、t4、t5和t6等作业状态。
以农机模拟作业轨迹数据作为研究对象,应用数据挖掘中的传统聚类算法DBSCAN对其进行聚类分析。通过聚类试验,确定MinPts=4、Eps=2.8为最佳参数。同时,以此参数作为聚类参数对模拟轨迹数据进行聚类,结果表明:有效作业状态的识别率达到98.33%,停歇时间识别率100%,转移时间的识别率70%。通过计算模拟轨迹的农机利用率为95.35%。
本文应用基于密度的聚类算法对模拟农机作业轨迹数据进行聚类,为真实农机轨迹聚类研究提供参考。但DBSCAN算法对参数选择比较敏感,在模拟和真实轨迹作为研究对象时,如何找到MinPts和Eps的合理的搭配以及最优值需要进一步研究。
[1] 孟庆佳, 高波, 侯琳. 河北省农机化水平评价指标体系关联度分析[J]. 农机化研究, 2011, 33(5):31-34.
[2] 刘大有, 陈慧灵, 齐红,等. 时空数据挖掘研究进展[J]. 计算机研究与发展, 2013, 50(2):225-239.
[3] Benkert M, Djordjevic B, Gudmundsson J, et al. Finding Popular Places[M]. In: Tokuyama T. Algorithms and Computation. Berlin, Heidelberg: Springer, 2007:776-787.
[4] Shaw S- L, Yu H, Bombom L S. A space- time GIS approach to exploring large individual-based spatiotemporal datasets[J]. Transactions in GIS, 2008,12(4):425-441.
[5] Shoshany M, Even- Paz A, Bekhor S. Evolution of clusters in dynamic point patterns:with a case study of Ants' simulation[J]. International Journal of Geographical Information Science, 2007,21(7):777-797.
[6] 杨辰, 沈润平, 郁达威,等. 利用遥感指数时间序列轨迹监测森林扰动[J]. 遥感学报, 2013(5):1246-1263.
[7] Nanni M, Pedreschi D. Time-focused clustering of trajectories of moving objects[J].Journal of Intelligent Information Systems, 2006,27(3):267-289.
[8] Spaccapietra S, Parent C, Damiani M L, et al. A conceptual view on trajectories[J].Data & Knowledge Engineering,2008,65(1):126-146.
[9] 吴笛, 杜云艳, 易嘉伟,等. 基于密度的轨迹时空聚类分析[J].地球信息科学学报,2015,17(10):1162-1172.
[10] 李江,作立,瑞祥,等.零位移的膜上移栽装置运动轨迹设计与仿真[J].农机化研究,2016,38(7):147-150.
[11] 洪荣荣,孙文磊,陈勇.水平摘锭式采棉机摘锭轨迹特性研究-基于Adams与MatLab[J].农机化研究,2016,38(4):44:48.
[12] 谢建华,侯书林,张学军,等.基于预定轨迹的残膜脱卸机构的优化设计[J].农机化研究,2016,38(6):89-92.
[13] 王培,孟志军,尹彦鑫,等.基于农机空间运行轨迹的作业状态自动识别试验[J].农业工程学报,2015,31(3):56-61.
Research on Clustering of Agricultural Machinery Operation Trajectory Based on DBSCAN Algorithm
Tursun Mamat , Xie Jianhua

Recognizing the operation status is one of the most important issues in agricultural management. During the operation of agricultural machinery, the large scale data on spatiotemporal dimension will be provided by the operation by using GPS. The data mining technology, especially clustering is used for discover the knowledge and model from the historical data. On this paper ,we applying the DBSCAN(Density-Based Spatial Clustering of Applications with Noise) algorithm for clustering the simulation trajectory data ,design useful method for identification operation status of agricultural machinery .the clustering result on simulation data shows that, identification rate for operation time ,transfer time and stop time is 98.33%,70% and 100%. Use efficiency of agricultural machinery on the clustering result is 95.35%.Result of this paper will afford a way to analyze the real trajectory of agricultural machinery in future work.
agricultural machinery; trajectory of operation; density based clustering; trajectory identification
2016-03-11
国家自然科学基金项目(51465057)
吐尔逊·买买提(1975-),男(维吾尔族),新疆阿克苏人,讲师,博士,(E-mail)tursun@xjau.edu.cn。
S126;TP391
A
1003-188X(2017)04-0007-05
猜你喜欢
机械工业标准化与质量(2022年9期)2022-09-30
河北农机(2021年8期)2021-08-24
河北农机(2020年8期)2020-09-11
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
铁道通信信号(2019年6期)2019-10-08
农民致富之友(2019年17期)2019-07-01
现代装饰(2018年5期)2018-05-26
中国三峡(2017年2期)2017-06-09
雷达学报(2017年6期)2017-03-26
