
基于BIM云系统的数据分类与处理研究
2017-12-10 08:31:58陈曦
辽宁师专学报(自然科学版) 2017年2期
陈 曦
(抚顺职业技术学院,辽宁 抚顺113122)
关键字:云计算;建筑信息模型;MRU算法;数据分类与处理
0 引言
近年来,云计算的发展十分迅速,运用的范围也非常广泛,从原先的科研环境逐渐走向了各种行业,比如生物学、天文学、交通管理、BIM管理等.如何针对各种异构的分布式存储环境来保持其稳定性、快速响应,并且发挥硬件资源的高可用性,是目前研究的一个热点.
传统的云计算模式是利用HBase传送海量的数据给HDFS,分析后发送给服务器进行处理.但是每次运行都进行海量的数据传输,不仅造成BIM云平台的高负荷,也不利于提高资源的利用率.为减少数据的传输量,利用Most Recently Used算法[1]将数据分类为常用与不常用数据,并利用常用数据来预测用户下次使用的数据并提前进行处理,从而提升整体运算的效率.
1 相关技术介绍
1.1 BIM云系统
建筑信息模型 (Building Information Modeling,缩写为BIM)是利用信息技术对建筑生命周期各个阶段进行管理的工具,包括规划设计、建筑审查、工程施工、项目管理等,提供了最佳的应用载体和信息管理模式,对传统的建筑设计方法进行了创新[1].
现有的商业BIM系统,如Autodesk Revit、Bentley Architecture和Tekla Structures,都是专门用于建筑项目的集成和可视化开发的.但是这些商业BIM系统是在各自相对独立的平台上运行的,数据无法共享,给用户造成了一定的限制,建模实验对于硬件的要求较高,不利于推广普及.
基于云计算的BIM,以BIM建筑信息模型作为基础,利用云计算进行建筑效能分析 (Building Performance Analysis,BPA),从而得到符合环境效益的最佳设计方案.基于云计算的BIM具有以下优点:(1)与环境效益相匹配;(2)具有科学有效的评估建模过程;(3)BIM系统下的信息系统与可视化分析技术.基于云计算的BIM,在大数据计算、可视化设计、建模分析、硬件投资、操作界面风格等方面有着强大的优势,可以很好地节约项目实施时间和成本[2].
1.2 Hadoop系统
Hadoop集群作为系统的基础设施,它可以利用大量廉价的硬件设备搭建服务器集群,在底层可以实现对集群的管理,在上层可以很方便地构建企业级的应用.Hadoop系统的核心是HDFS、MapReduce和HBase,前者允许在多台普通机器上存储和复制文件,后两者分别用于执行并行程序任务和储存数据[3].
HDFS(Hadoop Distributed File System)具有高度容错性,可以在低价的硬件设备上部署.HDFS很适合对大量资料重复的数据进行读写.HDFS是一个Haster/Slave的结构,通常而言,只具有一个Master,上面运行一个Name node,可能具有多个Slave,在上面各自运行一个Data node.
MapReduce是来自Google的一项重要技术,它是用以进行大数据量计算的模型.MapReduc就是一种简化并行计算的模型,可以较为简单地对并行计算进行开发并且应用.它包括了两项核心操作:Map和Reduce.在Map操作中,主要是对一些独立元素组成的列表上的每个元素进行操作.Reduce操作中是对列表上的元素进行适当合并[4].
1.3 HBase数据库
HBase是一个开源的非关系型分布式数据库,采用与Google的BigTable相似设计的分布式结构化数据储存系统,其运行于HDFS之上,提供Hadoop类似BigTable规模的服务,有别于一般数据库系统使用规模的服务.利用HBase技术可在廉价PC Server上搭建起大规模结构化储存群集[5、6].
2 MRU算法模型设计与实现
2.1 MRU算法的实现策略
Most Recently Used(MRU)算法原本是为高速缓存而设计的算法,目的是为提升高速缓存中的Hit Rate,MRU算法的原理是依据数据被存取的频率高低来区分数据在高速缓存的存放顺序.
在BIM云系统的HBase中,以数据的使用次数及时间为筛选条件,并利用MRU算法将数据分成常用与不常用,并利用数据库进行分类及管理,之后将常用数据传输给分布式文件系统进行处理,以减少系统的处理量来达到效能的提升.其实现策略如图1所示.
2.2 MRU算法的设定与使用
运用MRU算法的原理,依据数据的存取次数及访问时间,判断出常用与不常用数据,并在下一次循环中将常用数据进行优先处理.在BIM云系统中主要是在HBase和HDFS中间加上一个判断模块来进行数据的分类处理.其架构如图2所示.
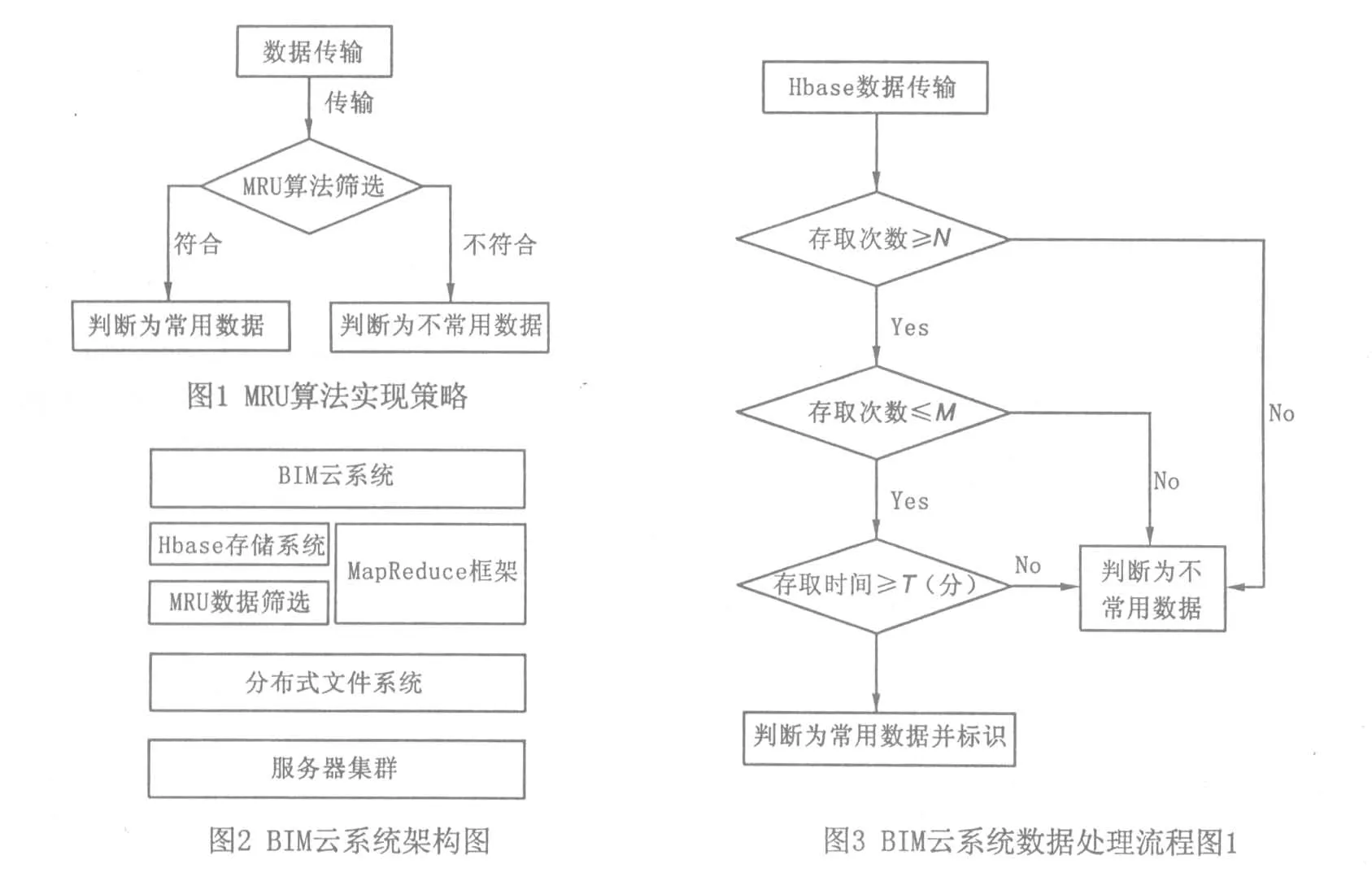
为了减少数据库中的数据一次性大量地传输给HDFS处理,我们利用MRU算法来解决这个问题.通过MRU算法来区分常用与不常用的数据,以数据的使用时间及次数来当作MRU算法的筛选条件.同时利用两个条件的原因在于:如果只设单一条件的话,对于判断数据是常用数据会有非常大的问题,例如,如果只采用次数来判断,可能会发生用户因为数据传输失败而重复请求的情况;同样,如果只采用时间的话,则会发生使用者只有这次要求传输但使用时间比平时长的情况.所以,设定一个循环时间内该数据的访问次数,并且使用时间设置在一定时间以上为筛选条件来判断该数据是否为常用数据.以30min为循环时间单位,存取次数N~M次,访问时间达到Tmin以上的数据会被标以常用数据,与其他数据进行区分,然后在下一个循环时间时会将常用数据优先传输给HDFS进行处理.其过程如图3(见 34页)所示.
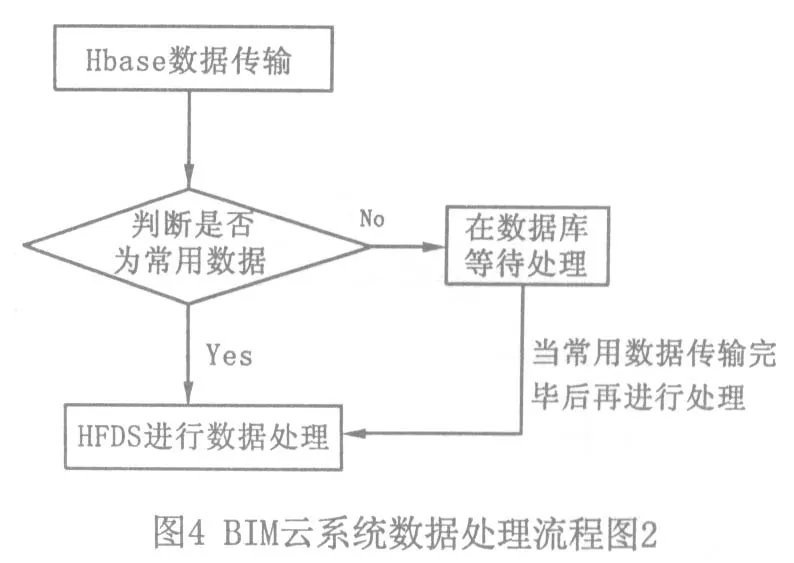
利用这个方法不仅可以减少数据处理的数量,也可以达到利用预判方式来加快数据在HDFS中的处理过程.其过程如图4所示.
3 BIM云系统实验分析
3.1 实验环境
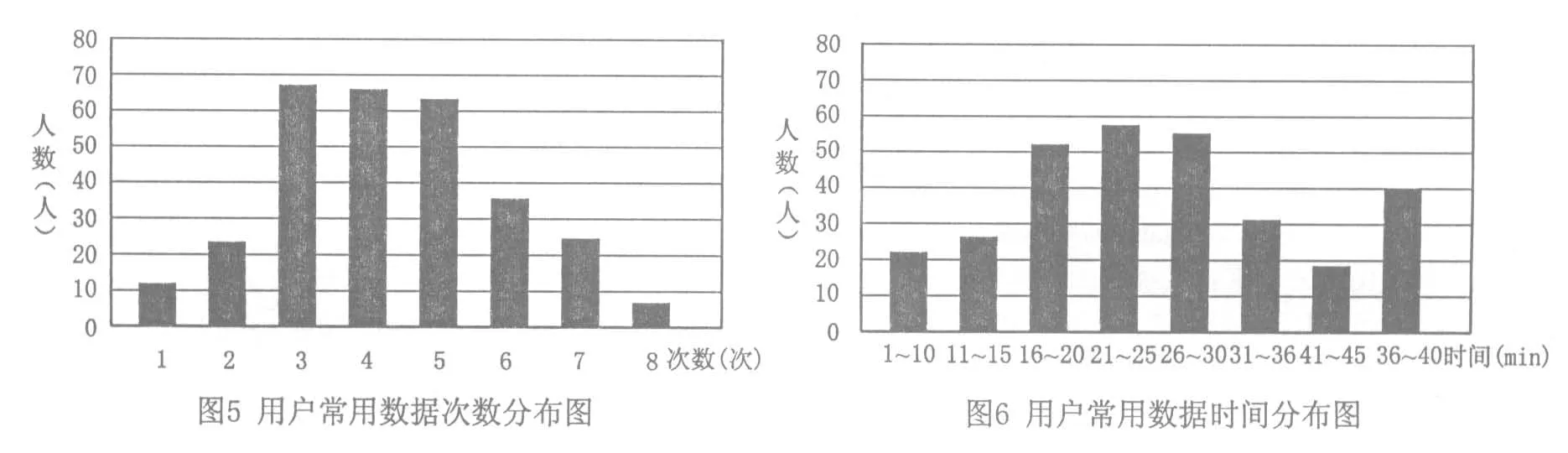
(1)用户常用数据次数分布.根据用户的使用情况,对于程序的使用次数会有很多种不同的情况,必须经过大量的样本统计后取得相关信息.本实验所采用的样本为抚顺职业技术学院建筑工程系的80位学生于实验室使用BIM云系统的情况,因为必须排除恶意或无效的情形,所以将最低与最高的10%设为无效样本,并在统计数据中舍弃.如图5所示,可得存取次数的阈值N=3,M=5,以此当作常用数据分类的标准.
(2)用户常用数据时间分布.仅以一个条件作为分类标准并不严谨,所以需要另外一个判断条件.因为必须排除恶意或无效的情形,所以将最低与最高的10%设为无效样本.如图6所示,可得超过15min为判断条件,然后以30min的时间当成一次循环.
(3)实验环境.平台主机2台,配置为E5-2687W八核处理器3.1GHz(两颗),内存容量为64GB 1600MH,硬盘容量为2TB,1个Quardo K5000图形卡,系统为Ubuntu-9.10-Server-Amd64,Hadoop版本为 Hadoop-2.2.0.
3.2 实验指标及分析
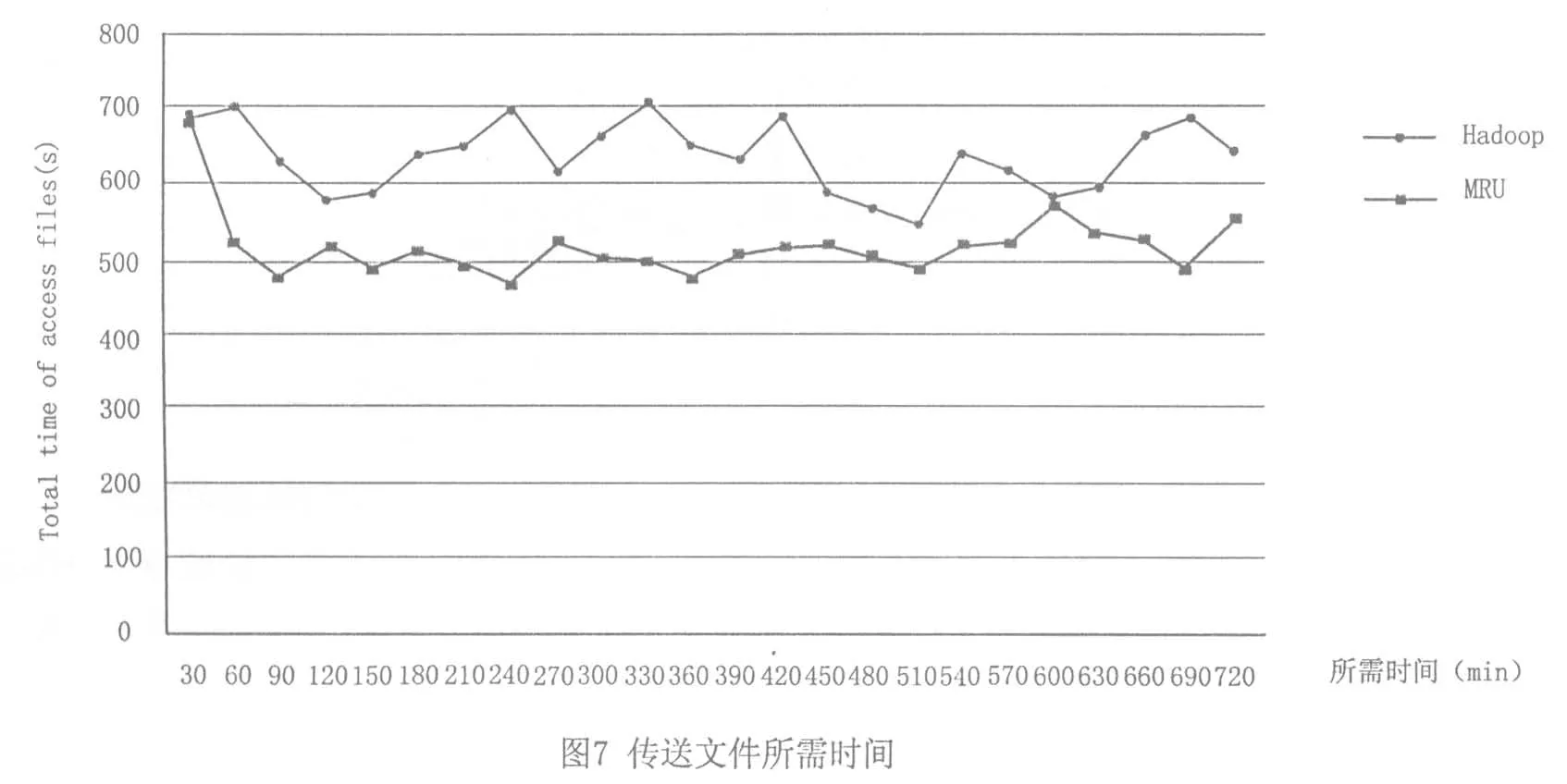
本实验每次传送1 000个数据当作测试样本,以30min为一次循环,一次实验为12h.如图7所示 (见 36页),基于MRU算法的方法比起传统Hadoop所需的时间明显下降,利用减少硬盘I/O的存取量与时间,达到整体硬件负荷量下降,可以有效地节省资源.
从表1中可以看到,本实验依照图7得到下列信息,分别可以得到两者完成时间的最小值、最大值和平均值,最大值减少了19.86%,最小值减少12.82%,整体平均时间减少了19.99%.

表1 效率提升表
4 结论
云计算技术在图形图像加速、建筑信息建模、大数据分析等领域具有广泛的应用.本文设计了在BIM云系统上的MRU算法,详细论述了MRU算法的框架和实现过程.通过实验表明,该系统是提升数据处理效率的实用工具.
猜你喜欢
中等数学(2022年2期)2022-06-05 07:10:50
智能建筑电气技术(2022年2期)2022-02-06 02:30:46
商用汽车(2021年4期)2021-10-13 07:16:02
数学物理学报(2020年6期)2021-01-14 01:00:14
小学生学习指导(低年级)(2020年6期)2020-07-25 02:31:36
成都信息工程大学学报(2019年4期)2019-11-04 00:56:02
阅读与作文(英语初中版)(2019年8期)2019-08-27 03:59:25
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:44
疯狂英语·新读写(2018年2期)2018-09-07 09:32:10
