
语料库视角下《北京折叠》译者风格分析
2017-11-28 04:32:39田晓芳
潍坊工程职业学院学报 2017年6期
田 晓 芳
(郑州大学 外国语学院,郑州 450001)
语料库视角下《北京折叠》译者风格分析
田 晓 芳
(郑州大学 外国语学院,郑州 450001)
《北京折叠》为一部科幻中短篇小说,该小说记叙现实的人情悲暖,创造了一个极端的世界。在未来的北京,空间被分成三层,分别被三个不同的阶层占据着。故事就以第三空间的垃圾工“老刀”穿越三个空间送信为框架。本研究利用Wordsmith和Antconc语料库检索软件对自建语料库从词汇和句法上进行量化,进而对文学作品译者风格进行定量和定性相结合的分析。研究发现,《北京折叠》译文在形符类符比、词汇密度、平均句长等方面接近于英语源语国家的风格,并且语言使用具有自身的作品风格。
北京折叠;语料库;量化
引言
中国女作家郝景芳凭借作品《北京折叠》于2016年获得第74届科幻界雨果奖最佳中短篇小说奖。这部小说的英文译者刘宇昆(以下简称刘译本)也是位科幻作家,虽然是中国人但是从小移居美国,在哈佛大学学习英美文学,具有典型的西方式写作与思维方式。刘宇昆凭借《手中纸、心中爱》(The Paper Menagerie),获得了星云奖短篇故事奖和雨果奖的最佳短片故事奖,他同时也是第一个获得星云奖和雨果奖两个世界科幻小说大奖的华裔作家。
《北京折叠》[1]这部小说中创造了一个三层空间的世界。第一空间居住的五百万人是名副其实的上层阶级;第一空间翻转后是第二空间和第三空间,第二空间有两千五百万人,拥有中等的权利;五千万人生活在第三空间,以处理另外两个阶层的垃圾为生。时间经过了精心规划和最优分配。每一时间段只能允许一个空间的人活动,相对应的另外两个空间的人进入睡眠,三个空间的居民禁止相互交集。故事以生活在在第三空间的垃圾工老刀为了能够送捡来的孩子糖糖上幼儿园,选择了穿越空间的冒险之旅为发展脉络。
Leech和Short认为文体是话语中标准化了的语言使用方式,文体是由某一个作者、某一特定作品等所作出的模式化的语言选择[2]。文学译本的最低要求是忠实于原文并且准确地进行翻译。成熟的作家有自身的语言风格,好的译本可以在阐述原文基本脉络结构,故事情节的基础上流露出自身特有的文体风格。这种风格体现在语言的运用及对于文化差异的处理上。好的译者在保留原文文化传统的基础上,也要让译入语国家的读者可以理解。以往对译者风格的研究方法主要局限于读者的主观欣赏和领悟,主观的、感性的认知明显多于客观的、理性的赏析。
语料库语言学对语言研究领域产生愈来愈大的影响。自20世纪80年代以来,计算机技术的迅猛发展加快了语料库的建设、普及及应用。将语料库应用于译者风格的研究是以文学作品为主要研究对象,以语料库分析工具为手段的研究方法。从宏观上可以进行词性分布状况的分析、句法分析、词频分布分析(Wordlist)。
微观上可以探讨主题词(Keyword )如何促进文本的情节发展,搭配、语义韵、重复性词汇的使用、常用句型等。不同维度的分析可以使人们了解作品究竟要传达哪些内容、文中的侧重点、作者的下意识或者无意识的表达手法,从而考察作者的写作风格或者鉴别作品的风格。语料库的研究方法改变了以往定性的文本分析现状,从一定程度上减少了分析的主观性,为译者风格的量化分析提供了一个具有可实施性的新视角。杨惠中[3]最早将语料库方法引入中国,这一方法大大促进我国二语教学的发展,并促进了语料库与其他学科的融合。王克非[4]致力于将语料库语言学和翻译学相结合,通过数据尝试发现总结翻译的共性。肖忠华[5]研究基于自建LCMC汉语译文语料库,促进了汉语研究的进步。秦洪武,王克非[6]通过自建对应语料库的英译汉语言特征分析结合语言实例的对比,加深读者理解。刘泽权[7]对于红楼梦的四个译本进行了词汇和句法进行量化分析,使得风格的对比更具有科学性。基于前人研究,本研究中借助语料库检索与处理工具对文学作品进行定量与定性相结合的研究,选取《北京折叠》作为数据来源,此方法将有助于对译者风格界定作出更为全面和科学的评价。
1 准备阶段
首先对所需要的电子文本进行收集。然后进行文本的清洁,在文本清洁过程中,可以使用Editplus软件处理工具删除多余的空格、文字乱码等,从而保持文本的规范。干净是文本最后的研究结果具有可信度的重要条件。在随后的文本处理中对文本进行分词标注和信息提取,在最后阶段获取文本的基本数据:标准化形符/类符比、高频词、词汇密度、平均句长等。
关于译者风格的具体分析,引入参照语料库CROWN。CROWN是布朗家族语料库(包括BROWN,LOB,FLOB,CROWN,CLOB)的一部分,是由北京外国语大学中国外语教育研究中心的许家金副教授和梁茂成教授在2012年建成的通用语料库。选用的文本来自于美式英语。其取样标准与布朗语料库下其他语料库取样标准一样。包括小说、学术、通用和新闻四部分。本研究以CROWN语料库下的小说部分为参照语料库,对《北京折叠》作品的译者风格进行分析,从而客观反映文学作品语言使用的基本特征。
2 数据分析
2.1 词汇方面
2.1.1 标准形符类符比
形符(token)是一个语言计量单位,是指文本中相邻空格间的连续字符串,文本一共有多少词就有多少个形符。
类符(type)是指文本中不同种类的词,针对英文的类符应忽略大小写形式和单词的屈折变换形式。

表1 标准形符类符比
Baker[8]指出,类符/形符比值的高低与词汇使用丰富程度相关。在进行具体文本的对比分析中,我们还应该考虑到文本长度,文本长度或者文本篇幅的大小等制约因素,本研究使用标准化的形符/类符比(Standardized Type/Token Ratio),以每千词为统计基础。高比率代表用词量丰富,词汇运用范围广泛,低比率体现词汇丰富度较低,词汇涉及范围有限。表一统计了《北京折叠》译本的标准 类符/形符比,将所得数据对比参照语料库。刘译本以及CROWN参照语料库标准化类符形符比值分别为45.05和46.65。两译本的比值相差不大,说明刘译本的语言使用习惯与英语本族语的词汇使用比率较为接近,译本词汇使用也较为丰富。
2.1.2 词汇密度
根据Baker的定义,词汇密度是文本中实词和总词数的比值,作为文本信息量大小:词汇丰富度的一个衡量标准[8]。此外,英语中词汇有实词和虚词之分,实词有动词、形容词、名词和副词;虚词有代词、连词、介词和冠词[8]。将词汇密度作为一项考核标准是因为标准类符/形符比在进行数据处理时将虚词也包含在内,虚词单纯具有语法意义,并不具备实际的意义倾向,不能准确反映出文本信息丰富程度的大小。因此就有必要引入词汇密度这一因素,从而使研究更加科学。利用语料库处理软件Antconc,基于正则表达式对词类信息进数据提取。得到如下表2所示信息:

表2 词汇密度表
从表2不难看出,刘译本相对于参照语料库 CROWN来说词汇密度不相上下,分别为55.01%,56.01%。进一步说明刘译本的词汇使用较为丰富。这与作者从小生活在美国并且受到美国教育有密不可分的关系。并且作者大学时期学习的是英美文化,因此对于美国语言表达思维有较为深刻的理解。从而使《北京折叠》这部作品翻译的词汇水平接近于英语源语国家水平。
2.1.3 词频表
词频表(Wordlist)是按照类符出现的频率高低而列出的类符表。词频表可以反映出作者用词倾向及文本的意境表达。词频统计提供作品词汇分布总体情况。获取文本之间的词汇使用差异性,词频统计有助于研究者们发现最基本的语言特征。
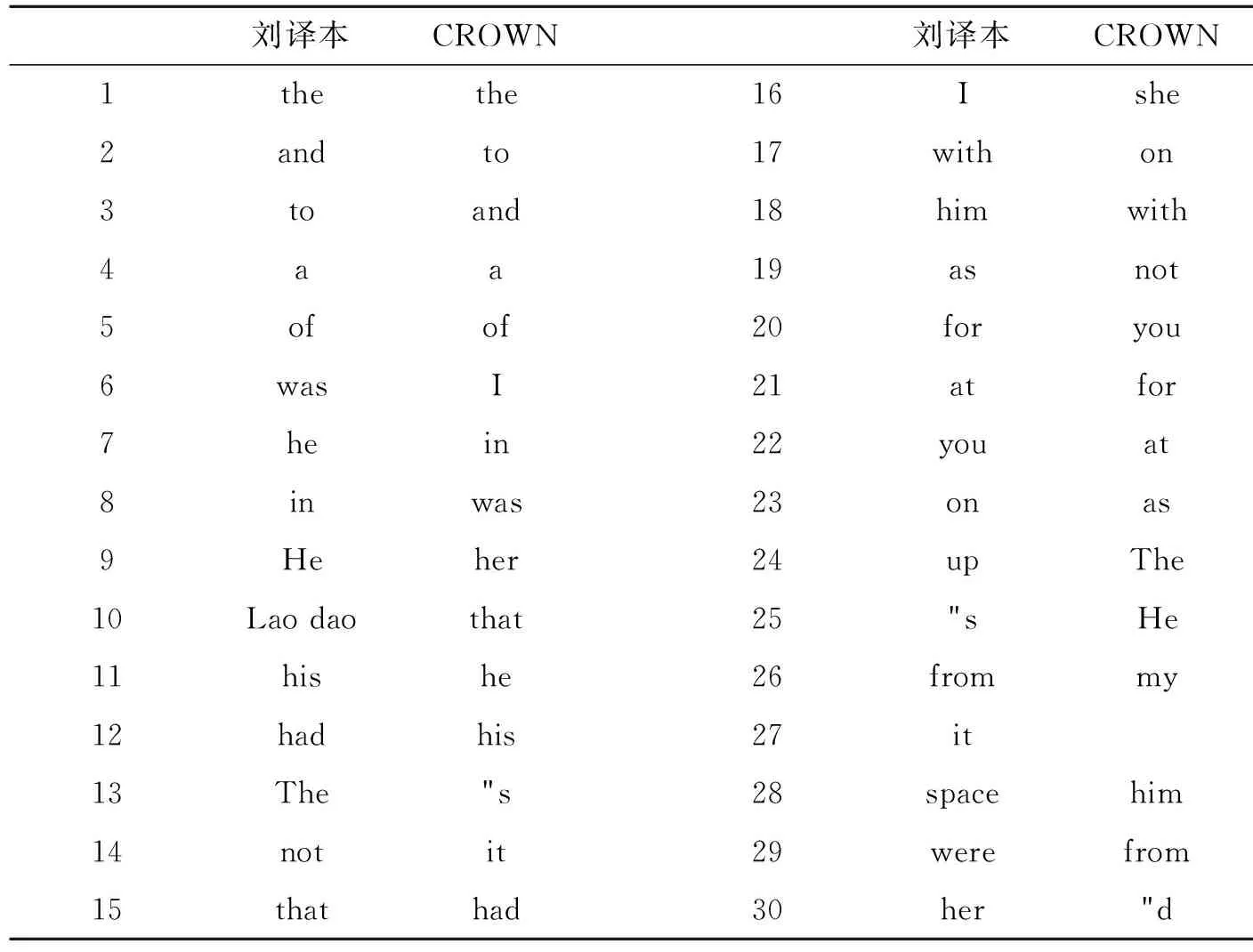
表3 语料前十名高频词
在表3中《北京折叠》和CROWN在代词、冠词、介词的分布上具有较强一致性。例如“the” “and” “to”等的使用。在前十位的高频词汇中,“He” “his” “Lao dao”相对于参照语料库CROWN频率比较高,这一特征受制于原作者的叙述方式——第三人称叙述模式,因此在译文的翻译中,“He” “his”出现的频率较高。代词“I” “you”的高频出现是由于作品中充斥着人物间对话。另外的“Lao dao”高频出现也说明Lao dao是这个文学作品的主人公,在《北京折叠》中“space”多次出现由于作者对于三个空间有较为详细的环境描写并且主人公多次在第一空间,第二空间,第三空间往返送信,所以相应频率较高。“had”相对于参照语料库来说也多次出现,并且结合上下语境发现除了作为时态的标志外,文本中多次使用“had to wait” “had to swing” “had to endure”等具有消极意义的搭配 ,表现出下层人生活的艰辛,在未来,下等人甚至没有被剥削的权利。阅读这部作品时发现文本中存在大量否定句,反映在词频表中就是“not”的多次使用。“He didn’ t dare to touch anything” “He wasn’t even as significant as dust.” “He couldn’t tell when his identity had been revealed.” “Things aren’t that simple”等句子在文中比比皆是。从侧面向读者传递出下层人无法掌握自己的命运,他们淳朴、善良,靠自己的能力吃饭。但是在科技飞速发展的现代,他们生存的空间是最拥挤肮脏的,时间是最短的。他们面对现实表现出的无奈和无力令人唏嘘。通过以上文本特征的数据分析,可以发现译者的翻译风格一方面受到原文故事情节发展的影响,另一方面,也必然会反映出译入语本身的语言特征。
2.1.4 主题词
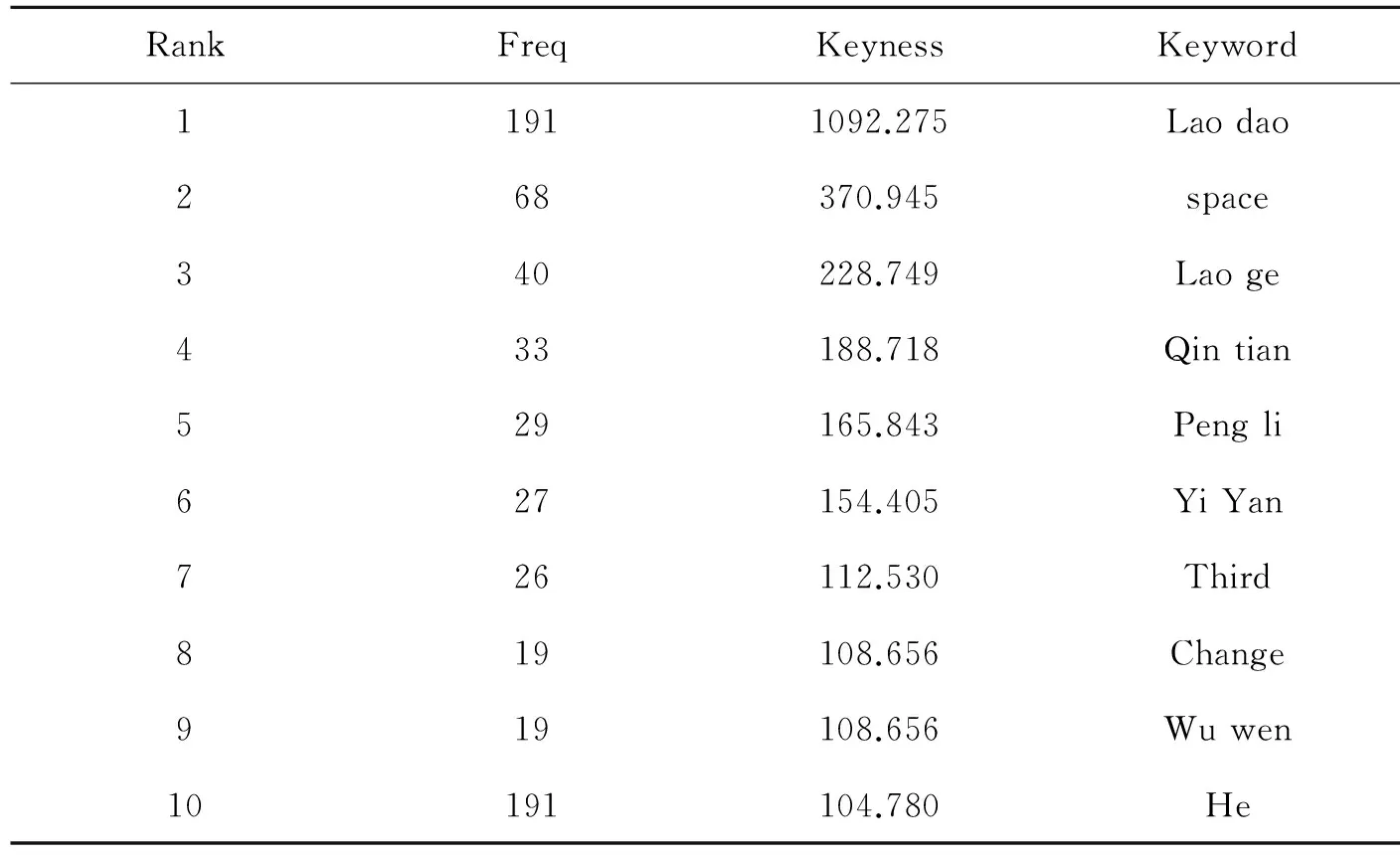
表4 主题词
通过表4可知:相对于参照语料库主题性较为显著的多是小说中的人物“Lao dao”“Lao ge”“Qin tian”“Peng li”“Yi Yan”“Wu wen”。根据Antconc的Concordance plot 我们可以得到各个人物在作品中的分布表,看各个人物是如何推动事物发展的。
Lao dao

Lao ge

Qin tian

Peng li

Yi Yan

Wu wen

图1 人物在作品中的分析
由词图可知Lao dao是这部作品的主人公,其他的人物在作品前半部分或者后半部分或多或少的参与了事件的发展。由彭蠡的指路-为秦天送信给依言-碰到依言的老公吴闻-获到老葛的帮助。Concordance plot 为故事的发展提供了清晰的脉络。其余的主题词如“space”和“change”其实是相互存在的,每一次的空间转换都依赖于“change”的使用。因此,主题词深刻反映了该文学作品情节发展的顺序以及使我们在没有深入了解作品时为我们提供了关键信息。
2.2 句子层面
2.2.1 平均句长
平均句长是译者风格的具体体现,指文本中的句子的平均长度。在考察译文时如果将文本体裁考虑在内,不同的文本体裁的平均句长考察结果不同,平均句长与文本体裁有很大关系,我们不能盲目地将平均句长作为衡量母语与译语间差异的标志。在汉语语言的使用中标志句子结束的符号通常是问号、句号、感叹号和分号,以这些符号结尾句子通常都是具有完整意义的结构,但是在语言使用中经常出现一逗到底的现象,它们也具有独立的意义。句子既可以是完整的小句也可以是独立的短语结构,它们组成的句子是一个“形散神聚”的句段流或者板块流,这种现象叫做句子片段。句子片段的数量相当于以问号、句号、感叹号,以分号结尾的句子数量加上以逗号结尾的数量,句子片段平均长度计算方式是文本总字数除以句子片段数量。

表5 平均句长

表6 平均句子片段长
在比较平均句长时,我们引入源语文本作为参照标准。参见表5:刘译本和CROWN语料库平均句长分别为14.20和12.23。而原文的平均句长高达23.57,说明作者在翻译时较少受到源语干扰,作品的风格接近于英语源语语料库。通过统计平均句子片段长汉语原文的数字由23.57变为9.92,说明汉语作品中逗号大量存在,这跟语体有密不可分的关系。而刘译本和CROWN则受逗号影响相对来说变化量较小。从以上两方面的对比可知在句子层面上刘译本接近于英语源语国家的风格。
2.3 具体层面特征
2.3.1 英译本句子主语的选择
《北京折叠》原文在语言方面一个明显的问题是主语的省略或者频繁转换从而导致的句子结构的混乱。
英语是注重形式的语言,在句义的表达上必须包含主语和谓语两个部分,是典型的“形合”语言。汉语注重内容的传递和意境的表现,对于语言的形式没有过多要求,是典型的“意合”语言。
比如小说的开篇部分,以下例句加粗的主语部分,从“老刀”“这”“衬衫袖口”再到“他”,主语来回跳跃了四次。相比之下,译文的翻译只用了两个主语,“Lao Dao”与“He”,并且指代是一致的,再配合破折号的解释,使得文章结构紧凑,句式简明流利。
(1)老刀回家洗了个澡,换了身衣服。白色衬衫和褐色裤子,这是他唯一一套体面的衣服,衬衫的袖口磨了边,他把袖子卷到胳膊肘。
Lao Dao had gone home, first to shower and then to change. He was wearing a white shirt and a pair of brown pants——the only decent clothes he owned. The shirt's cuffs were frayed, so he rolled them up to his elbows.
对比译本和原文可以发现,汉语的主语多用名词表示,英语的主语选取多为代词和介词。英语中充当主语的成分有we、you、he、they等人称代词,that、which等关系代词,还有this、that、these、those等表示指示概念的指示代词。在英语复杂句的表达形式中,为了使句子的语义清晰明确,避免意义表达上的重复,英语使用大量代词去指代事物。汉语虽然也有代词,但由于汉语结构相对松散,使用名词往往可以使语义更加清楚。
(2)他有一个月不吃清晨这顿饭了。一顿饭差不多一百块,一个月三千块,攒上一年就够糖糖两个月的幼儿园开销了。
It had been a month since he last had a morning meal. He used to spend about a hundred each day on this meal, which translated to three thousand for the month. If he could stick to his plan for a whole year, he'd be able to save enough to afford two months of tuition for Tang tang's kindergarten.
在汉语语言习惯中,无主句的句子形式广泛存在。然而在英语中,句子一般都有主语。在对文本进行翻译时需要补出主语或改变句型,使句子结构表达符合英语使用的规范。英语注重结构并且逻辑严密,所以进行翻译之前必须清楚各部分所做的成分,弄清楚句子的修饰成分以及修饰关系。作者在译文处理中分别使用It 做形式主语,并且用He来将缺失的主语补充完整,从而使得译文表达清晰,符合英语国家的理解与阅读习惯。
2.3.2 词汇短语选择
翻译讲究炼字,在翻译时,特别是文学翻译时更要从备选词语中提炼出最精确、简练 、最形象的表达。因为汉语和英语是不同的语系,所以在对汉语源语文本进行翻译时必须做到忠实准确生动。所以在进行文本的翻译时必须考虑到各自文化的不同以及语言的差异。灵活地选取适合的单词进行译本的撰写。
(1)他开始做准备。
He began to steel himself.
这里的steel用得恰到好处,steel做动词来讲一般指get ready for something difficult or unpleasant,即下定决心、硬着心肠做某事。结合上下语境不难发现在等待的彭蠡迟迟不回来的情况下,由于时间的紧迫,老刀下定决心自己行动了。虽然会带来不少困难,但时间不等人。译者精准的把握了原文作者想要传达的含义。
(2)彭蠡六十多了,变得懒散不修边幅,两颊像沙皮狗一样耷拉着,让嘴角显得总是不满意地撇着。
His cheeks drooped like the jowls of a Shar-Pei, giving him the appearance of being perpetually grumpy.
这里的jowl在西方国家多指宽厚的带肉的面颊并且多用来形容动物。区别于cheek,虽然在汉语原文中都是用“颊”表示,但是译者精准的抓住了其中的差异,使译文生动形象。此外grumpy的翻译没有采用直译的方法而是意译,作者没有译为unsatisfied。而是根据原文作者想表达的情绪,抓住彭蠡这个人物的准确特征把他描述为脾气不好的,做到了意义的忠实和语言的形象。
3 文本可读性
早期的作品易读性的测量多是手工计算,随着大数据时代的到来以及计算机技术的提升,易读性的计算变得简单易行。Readability Analyzer1.0是由中国外语教育研究中心的许家金博士和贾云龙先生于2009年研制的测量的文本难易程度的分析软件。基于这个统计工具对《北京折叠》进行量化分析,并参照表7、表8数据等级进行对比分析:

表7 Reading ease score

表8 Text difficulty
易读性指文本阅读的难易程度,英语易读性取决于多方面的共同作用:包括词长、句长、形符类符比值、词汇的抽象程度等。易读性对于文本的批评分析具有一定的价值,并且可以从侧面反映作者的语言风格。文本的易读性分为不同的等级,数值越大说明作品越容易被理解接受。为了更加客观反映数据的科学性,我们对作品分析增加了Text difficulty这一计算方式。Text difficulty=100-Reading ease score,文本阅读的困难程度也分为不同的等级,数值越大越不易理解接受。这两组数据分别揭示了译本的易读性及难易程度。 《北京折叠》数据反映在Reading ease score和Text difficulty分别是74.2和25.8,分别对应于可读性等级的Fairly easy和very easy。从侧面说明这部作品的译本词汇使用,句法结构较为简单,容易被大家理解,具有较强的可读性。
结语
通过上述数据分析发现,《北京折叠》刘译本在标准类符/形符比、词汇密度、高频词使用、句子片段长度等整体方面的分析结果均接近于英语源语国家的语言特征。词汇使用丰富、句子平均长度符合英语国家语言习惯、文本整体易读。在对文本具体方面考察的同时也验证了语料库在译者风格分析中的有效性。译者在作品中主语的选择增强了文本表达方式的逻辑性、简洁性、可读性。词汇的精确运用使译本在原文语义的基础上词汇表达实现了多样化。
本文用语料库的视角去分析译者风格,结合翻译分析的理论和语料库自身优势,旨在为译者风格的分析提供一个新的方法,即研究者可以从多层面多角度深度挖掘文本的具体语言特征。例如:作者常用句型、习惯性搭配、语义韵等。但是应该意识到一部作品的翻译受到主观和客观因素的共同制约,在将语料库应用于文学题材的分析时应意识到处理工具的片面性、局限性,在运用处理工具得出相应的数据基础之上应结合其他的研究方法理论对数据进行合理的解释和解读,从而更深层次挖掘译者风格的特征。
[1] Liu Ken.Invisible Planets [M].Tor Books,2016.
[2] Geoffrey N. Leech, Mick Short. Style in Fiction[M]. New York: Longman,1981.
[3] 杨惠中.语料库语言学导论[M].上海:上海外语教育出版社,2012.
[4] 王克非.语料库翻译学探索[M].上海:上海交通大学出版社,2011.
[5] 肖忠华.英汉翻译中的汉语译文语料库研究[M].上海:上海交通大学出版社,2012.
[6] 秦洪武,王克非.基于对应语料库的英译汉语言特征分析[J].外语教学与研究,2009,(3):131-136.
[7] 刘泽权.红楼梦四个英译本的译者风格初探[J].中国翻译,2011,(1):60-64.
[8] Mona Baker. Corpus Linguistics and Translation Studies: Implications and Applications [A]. Cobuild Birmingham,1993.
[9] Biber D.et al. Longman Grammar of spoken and Written English[M].Beijing:Foreign Language Teaching and Research Press,2009.
(责任编辑:刘学伟)
10.3969/j.issn.1009-2080.2017.06.014
H315.9
A
1009-2080(2017)06-0072-07
2017-10-29
田晓芳(1991-),女,河南洛阳人,郑州大学外国语学院在读硕士研究生。
是语料库能够提供的重要的数据类型。主题词和传统意义上的关键词不同,在语料库语言学中,主题词是在将研究语料库和参照语料库对比的基础上发现的具有高复现频率的词。主题词反映特定的表达方式,根据主题词的分布规律去解读语言现象,了解作品的主题情节,为分析提供更科学的方法。
猜你喜欢
语数外学习·高中版中旬(2023年7期)2023-08-25 09:04:58
疯狂英语·新阅版(2023年7期)2023-08-17 14:49:58
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
西夏研究(2019年1期)2019-03-12 00:58:16
疯狂英语(双语世界)(2017年4期)2017-04-28 09:10:28
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
语言与翻译(2015年4期)2015-07-18 11:07:45
青苹果(2014年2期)2014-04-29 20:31:27
渭南师范学院学报(2014年12期)2014-03-20 15:31:14
当代外语研究(2010年3期)2010-03-20 14:36:38
