
基于信息熵加权词包模型的扣件图像检测
2017-11-28 09:51:10李柏林狄仕磊罗建桥
中成药 2017年11期
李 爽,李柏林,狄仕磊,罗建桥
西南交通大学 机械工程学院,成都 610031
基于信息熵加权词包模型的扣件图像检测
李 爽,李柏林,狄仕磊,罗建桥
西南交通大学 机械工程学院,成都 610031
针对传统“视觉词包模型”在进行铁路扣件检测时忽略图像结构而导致的区分能力不强的问题,提出一种基于信息熵加权词包模型的扣件检测模型EW_BOW。在传统“视觉词包模型”的基础上,引入信息熵对扣件图像局部区域的词包模型的词频进行加权处理,加强词包模型对不同类别扣件的区分性,并利用潜在狄利克雷分布学习扣件图像的主题分布。最后,采用支持向量机对扣件进行分类识别。对四类扣件图像的分类实验证明该模型能够有效提高扣件分类精确度。
铁路扣件检测;词包模型;视觉单词;信息熵;潜在狄利克雷分布模型
1 引言
轨道设施的正常工作是维系铁路运营安全的重要保障。传统的轨道检测是人工巡检,这种检测方法缺乏实时性和准确性,无法满足铁路高速发展运行密度大的情况下对轨道检测提出的新需求。近年来,在车载轨道自动巡检方面的研究取得了丰硕的成果[1-4],但一直未能很好地解决铁路扣件的检测问题。扣件的损坏可能酿成列车脱轨等重大事故,已经引起了铁路部门的高度重视[5]。随着计算机技术的发展,计算机视觉技术逐渐应用到铁路扣件自动检测中[6-7]。
目前,扣件自动检测方法主要分为三类:(1)基于扣件图像全局特征的检测方法。如文献[8]利用主成分分析(Principle Component Analysis,PCA)检测扣件状态。此类方法忽略了局部信息,仅能描述扣件整体状态,因此分类效果不理想;(2)基于扣件图像局部目标区域的检测方法。如文献[9-10]将扣件图像划分为子块,并串联了图像子块特征,能够检测大部分失效扣件。但利用这类方法检测扣件时,子块特征串联后的维度较高,噪声和冗余严重,造成大量正常扣件被误检。前两类方法都是因为底层特征与图像内容之间存在语义鸿沟[11]制约了扣件状态检测算法的准确性。(3)基于“视觉词包模型”(Bag-Of-Words,BOW)的检测方法。此类方法首先利用局部特征向量定义图像块的不同语义概念(如轨枕,扣件等),称其为视觉单词,再统计这些视觉单词的出现频率,生成图像-单词词频矩阵,将其作为图像内容的表示,最后,使用机器学习算法来实现扣件图像分类。文献[12]在“视觉词包模型”的基础上,利用潜在狄利克雷分布模型(Latent Dirichlet Allocation,LDA)学习得到扣件图像的潜在主题分布,进一步提高了扣件检测性能。这类方法在将图像表示成视觉单词集合时,将每个局部特征映射为与其欧氏距离最近视觉单词。然而,这样的映射方法仅仅将图像看成若干视觉单词的集合,忽略了单词的位置信息,导致单词存在多义性。比如,当一幅图像出现表示“扣件”的单词时,该单词既可能表示扣件顶部某区域,也可能表示扣件端部某区域,而不同类别扣件间的差异仅存在于图像的某一局部区域内,这就导致模型对不同类别扣件的区分性不强。
针对传统“视觉词包模型”忽略扣件图像结构的缺点,本文提出一种基于信息熵加权词包模型(entropyweighted BOW,EW_BOW)的扣件检测模型。在传统“视觉词包模型”的基础上,引入信息熵来分析扣件局部区域所含的信息量,并将其作为权值系数,对各局部区域的图像-单词词频矩阵进行加权处理,以提高不同状态扣件在模型下的区分度。实验结果表明,信息熵加权后的“视觉词包模型”具有更高的分类性能。
2 基于EW_BOW的扣件检测模型
传统“视觉词包模型”通过对图像的底层特征向量进行聚类,生成“视觉词典”,利用生成的“视觉词典”将同一簇内的特征向量映射为同一视觉单词,从而将图像表示成无序的视觉单词集合——即“图像-单词词频矩阵”。但这样的词频矩阵的生成方式忽略了扣件的空间结构信息。
针对这一问题,本文首先根据扣件的对称结构划分局部区域,以克服视觉单词的多义性。在此基础上引入信息熵,对各局部区域的图像-单词词频矩阵进行加权,将图像量化为一个更具区分性的图像-单词词频矩阵。本文的模型框架如图1所示。图1中,实线部分表示训练过程,虚线部分表示测试过程。

图1 本文模型检测框架
2.1 生成局部区域的词频矩阵
从底层特征中得到图像-单词词频矩阵可以通过构造视觉单词来实现,但扣件图像左右区域对称,上下区域相似,导致了单词的多义性问题,造成语义表达的混乱。因此,将扣件图像均分为2×2的局部区域,分别用Z1,Z2,Z3,Z4表示。每个局部区域的特征向量仅对应本区域内的单词,其他局部区域的特征向量不能映射到本区域内的单词。扣件局部区域的构建方式如图2所示。

图2 扣件局部区域示例
在将扣件划分到四个独立的局部区域后,每个局部区域内没有相似的扣件结构,从而克服了单词的多义性问题。本文采用上述基于扣件局部区域的方法从底层特征生成图像-单词的词频矩阵。首先需要训练视觉词典,具体训练步骤如下:
(1)根据底层特征向量所在局部区域的位置,将训练集图像中全体特征向量S划分为4个部分S1,S2,S3,S4。
(2)使用K-means算法对Sn进行无监督聚类,每一个聚类中心向量wn,i就是一个视觉单词,从而得到4个容量为K的局部区域视觉词典Wn=[wn,1,…,wn,i,…,wn,K],n=1,2,…,4,i=1,2,…,K 。
局部区域词典训练流程如图3所示。

图3 局部区域词典的训练
根据局部区域词典与扣件底层特征向量的映射关系,将单词下标作为其对应特征向量的编码,并统计图像各局部区域不同单词出现次数,生成单词图像-单词的词频矩阵Dn(n=1,2,3,4),将其作为扣件图像局部区域的内容表示。编码底层特征生成局部区域的图像-单词词频矩阵的步骤如下:
(1)初始化词频矩阵 Dn(i)=0,n=1,2,…,4,i=1,2,…,K。
(2)根据图像中某一特征向量s所在局部区域位置Zn选择一个词典Wn。
(3)在Wn中检索与s欧氏距离最近的单词wn,i,将wn,i的下标作为s的编码,将词频矩阵中该编码值出现的次数加1。
(4)重复步骤(2)~(3),直到编码一幅图像中所有特征向量。
2.2 信息熵加权词频矩阵
信息熵[13]可以定量表达图像灰度分布的稀疏度和信息量。本文引入信息熵用于表示扣件图像局部区域的图像-单词的词频矩阵中所含的信息量。在一幅扣件图像中,Dn(n=1,2,…,4)是Zn区域对应的局部区域词频矩阵,其中单词wn,i(i=1,2,…,K)出现的概率为 pn,i,则该局部区域词频矩阵的熵值如式(1)所示:

实际工况下的扣件可分为正常、断裂、丢失以及被遮挡四种状态,不同状态的扣件图像如图4所示。抽取四种状态的扣件图像各100幅,并在每幅图像中选取最能表征当前状态的局部区域,比如,图4(b)中的Z2区域反映了当前断裂扣件的状态。以SIFT(Scale Invariant Feature Transform)特征为例,根据式(1)计算每幅图像中被选中局部区域的词频矩阵的熵值,得到四种状态扣件的平均熵值分别为5.138、4.993、4.124、4.692。可知不同状态扣件的局部区域的词频矩阵所含信息量存在明显差异,即信息熵对不同状态扣件具有区分性。

图4 不同状态的扣件图像
再根据式(2)、(3)计算各区域词频矩阵的权重系数τn,来对各局部区域词频矩阵进行加权,从而得到一幅扣件图像的EW_BOW表示。

本文采用上述基于信息熵加权“词包模型”的方法完成一幅扣件图像的EW_BOW表示,具体步骤如下:
(1)根据式(1)得到各区域词频矩阵的信息熵Hn。
(2)根据式(2)(3)得到各区域词频矩阵的权重系数 τn。
(3)对各局部区域的词频矩阵进行加权处理,得到局部区域的EW_BOW表示 D′n=[τn⋅Dn](n=1,2,3,4)。
(4)将 D′1~D′4首尾相接,构成一幅扣件图像的EW_BOW表示:

通过信息熵对扣件图像各局部区域的词频矩阵进行加权处理,可增加信息量较多的词频矩阵中视觉单词出现的次数,降低信息量较少的词频矩阵中视觉单词出现的次数,从而增加不同状态扣件的词频矩阵之间的差异,提高“视觉词包模型”对不同状态扣件的区分度。
2.3 学习扣件图像的主题分布
潜在狄利克雷分布(LDA)模型将一幅图像作为一篇文档,将文档描述成主题的集合,而主题通过视觉词汇的分布来表达,在自然语言处理、场景分类等领域已被广泛应用[14-15]。当局部特征向量聚类生成视觉词典时,若某特征向量处于多个视觉单词的边界附近,特征点的单词语义可能存在歧义,造成语义信息丢失,而单词背后的主题语义能够解决这个问题。此外,由于LDA对“视觉词包模型”进行总结,进一步整合了语义信息,所以主题分布是一种高层语义特征,对图像中扣件轻微的倾斜或歪曲具有较强的鲁棒性。LDA中一幅图像的生成步骤如下:
(1)选择 θ~Dirichlet(α),其中 θ 是一个C×T 的矩阵,行向量θi是第i幅图像的主题分布向量。
(2)对于每个图像块xi,从多项式分布θ抽样主题tk,tk~Multi(θ),以概率 p(ωm|tk,β)选择一个视觉单词ωm,β是一个K×V 的矩阵,其元素βi,j=p(ωi=1|tj=1)表示视觉单词ωi和主题tj同时出现的概率。
(3)重复步骤(1)(2),反复进行图像主题的选择,通过主题产生对应的单词,直到生成一幅完整的图像。
LDA模型的学习过程是其生成模型的逆过程,采用吉布斯采样可求解出模型中参数的近似值,从而获得每幅图像的主题分布。
2.4 算法描述
综上所述,基于EW_BOW的扣件检测算法的具体步骤如下:
(1)提取全体图像的底层特征向量S。
(2)利用K-means聚类方法对全体底层特征向量进行聚类,根据特征向量所在位置,生成4个局部区域的视觉词典Wn(n=1,2,3,4)。
(3)根据特征向量所在位置,将每个底层特征映射到相应视觉词典中的视觉单词,生成图像-单词词频矩阵Dn(n=1,2,3,4)。
(4)根据式(1)计算每个局部区域的词频矩阵的信息熵。
(5)对于每个局部区域的词频矩阵,根据式(2)、(3)进行加权处理,并利用式(4)进行连接。
(6)利用LDA模型学习扣件图像的潜在主题分布。
(7)构建SVM分类器,对新的扣件图像进行分类。
3 实验及结果分析
3.1 实验数据与配置
本文从采集的扣件图像中选取共800幅作为实验数据,其中正常、断裂、丢失以及被遮挡的4类扣件图像(如图4)各200幅,均为120像素×180像素的灰度图像。
实验PC处理器为AMD Sempron X2 190 Processor 2.5 GHz,内存4.0 GB,在Matlab2014a环境下进行实验。
3.2 实验及结果分析
(1)实验1
为了分析视觉词典容量对于分类性能的影响,本文改变视觉词典容量的设置进行多次重复的实验。图5展示了在 SIFT、LBP(Local Binary Pattern)以及 HOG(Histogram of Oriented Gradient)三种不同的底层特征下,词典容量的变化对正确率的影响。观察可知,随着词典容量的增加,不同底层特征下的测试结果正确率也在稳步提升。但当词典容量大于一定的值后,继续增加视觉单词数量,正确率不会继续提高。这是因为过小的词典容量造成了语义的丢失,而过大的词典容量则会导致语义的冗余,进而影响测试结果的正确率。因此在后续实验中选择测试结果正确率相对较高的视觉单词数目—80。

图5 词典容量对扣件分类性能的影响
(2)实验2
通过不同状态扣件在模型下的类间距离大小来评估当前模型对扣件的图像的描述能力。类间距离越大,表明模型对不同状态扣件的区分能力越强,对扣件状态的描述越精确。分别采用传统“视觉词包模型”和EW_BOW模型,度量正常扣件与各种失效扣件之间的类间距离。表1和表2分别为在SIFT特征和HOG特征的基础上,不同状态扣件在传统“视觉词包模型”和EW_BOW下的类间距离对比。

表1 不同模型下的类间距离对比(SIFT)

表2 不同模型下的类间距离对比(HOG)
从表1可以看出,在SIFT特征下,利用EW_BOW描述扣件图像时,正常扣件与各类失效扣件间的距离相对于采用传统“视觉词包模型”描述扣件时均有所提高。其中增长最多的为正常-丢失扣件的类间距。分析其原因为:不同类别扣件图像所属的图像-单词词频矩阵具有差异性较明显的信息熵,信息熵加权后的词频矩阵对于正常扣件和各类失效扣件具有更强的分辨能力。由表2可知,在HOG特征下,EW_BOW同样能够提高正常扣件与各类失效扣件间的距离。
实验结果表明,相比与传统“视觉词包模型”,EW_BOW模型能够更加准确地描述各种扣件的状态。
(3)实验3
一方面,分别采用SIFT特征、LBP特征和HOG特征作为底层特征,采用传统“视觉词包模型”方法[16]与本文方法进行比较,以评估本文方法的语义有效性;另一方面,通过将本文方法与文献[8]中的主成分分析方法、文献[9]中的方向场(Directional Field,DF)方法以及文献[10]中的LBP+SVM方法这几种主要的扣件检测方法对比,以综合评估本文方法的扣件检测性能。
各种方法的实验设置为:传统“视觉词包模型”与本文方法中,参数均已优化。文献[8-10]中各方法的参数设置均与原文献保持一致。实验样本采用本文创建的样本库。训练集为每种状态的扣件图像各100幅,共400幅图像,余下的作为测试集。训练集与测试集的大小均为400。选择LIBSVM[17]对扣件数据进行分类,实验结果为3折交叉验证(cross-validation)的平均值,并统计实验结果的误检率和漏检率。误检率=误检扣件数量/正常扣件总数量×100%,漏检率=漏检扣件数量/失效扣件总数量×100%,其中,丢失、断裂、被遮挡的扣件均被视为失效扣件。检测结果首先要求准确判断出失效扣件,降低漏检率;其次是降低误检率,减小浪费。各方法的检测结果如表3所示。
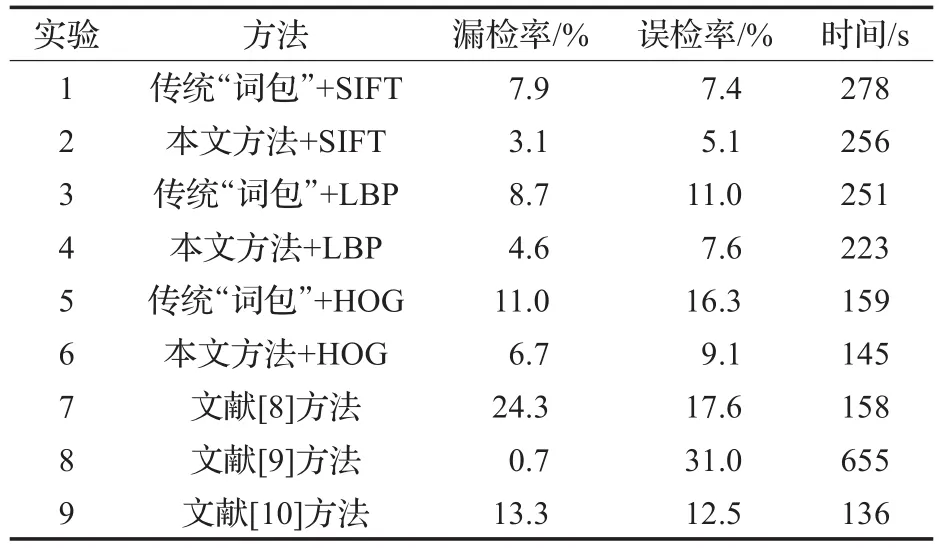
表3 本文方法与其他方法的比较
实验1、2表明,在SIFT特征下,本文方法显著提高了传统“视觉词包模型”的扣件检测性能。一方面,根据扣件的结构划分局部区域的方法克服了视觉单词多义性的问题;另一方面,通过信息熵加权后,各种类别扣件的视觉特征在模型下呈现了更大的差异性,使扣件检测结果更加准确。实验3、4和5、6这两组实验表明,在LBP特征和HOG特征下,本文方法同样能够降低“视觉词包模型”的漏检率和误检率。
从实验4、7、8、9中可以看到,文献[8]的主成分方法和文献[10]的LBP+SVM方法虽耗时较短,但误检率和漏检率均较高。文献[9]的方向场方法虽对失效扣件检测效果较好,但误检率过高,且耗时较长。与现有方法相比,本文方法能更加有效地检测扣件状态。
4 结语
通过引入信息熵,利用信息熵加权后的“视觉词包模型”对扣件状态进行检测,在一定程度上减小了底层特征与高层语义之间的“鸿沟”,提高了扣件检测精度。在四类扣件数据集上实验获得比传统“视觉词包模型”更低的漏检率和误检率,证明了本文模型的有效性和可行性。下一步的研究重点是如何更准确地定义视觉单词,以进一步增强扣件语义准确性。
[1]Singh M,Singh S,Jaiswal J,et al.Autonomous rail track inspection using vision based system[C]//IEEE International Conference on Computational Intelligence for Homeland Security and Personal Safety,2006:56-59.
[2]Marino F,Distante A,Mazzeo P L,et al.A real-time visual inspection system for railway maintenance:Automatic hexagonal-headed bolts detection[J].IEEE Transactions on Systems Manamp;Cybernetics Part C Applicationsamp;Reviews,2007,37(3):418-428.
[3]Yella S,Dougherty M,Gupta N K.Fuzzy logic approach for automating visual condition monitoring of railway sleepers[C]//Indian International Conference on Artificial Intelligence,2007:941-956.
[4]许贵阳,史天运,任盛伟,等.基于计算机视觉的车载轨道巡检系统研制[J].中国铁道科学,2013(1):139-144.
[5]肖新标,金学松,温泽峰.钢轨扣件失效对列车动态脱轨的影响[J].交通运输工程学报,2006,6(1):10-15.
[6]Xia Yiqi,Xie Fengying,Jiang Zhiguo.Broken railway fastener detection based on adaboost algorithm[C]//International Conference on Optoelectronics and Image Processing.IEEE Xplore,2010:313-316.
[7]Li Ying,Otto C,Haas N,et al.Component-based track inspection using machine-vision technology[C]//International Conference on Multimedia Retrieval(ICMR 2011),Trento,Italy,April,2011:60.
[8]王凌,张冰,陈锡爱.基于计算机视觉的钢轨扣件螺母缺失检测系统[J].计算机工程与设计,2011,32(12):4147-4150.
[9]Yang Jinfeng,Tao Wei,Liu Manhua,et al.An efficient direction field-based method for the detection of fasteners on high-speed railways[J].Sensors,2011,11(8):7364-7381.
[10]Dou Yunguang,Huang Yaping,Li Qingyong,et al.A fast template matching-based algorithm for railway bolts detection[J].International Journal of Machine Learning and Cybernetics,2014,5(6):835-844.
[11]Tang Jinhui,Zha Zhengjun,Tao Dacheng,et al.Semanticgap-oriented active learning for multilabel image annotation[J].IEEE Transactions on Image Processing,2012,21(4):2354-2360.
[12]罗建桥,刘甲甲,李柏林,等.基于局部特征和语义信息的扣件图像检测[J].计算机应用研究,2016,33(8):2514-2518.
[13]唐立力.基于信息熵与动态聚类的文本特征选择方法[J].计算机工程与应用,2015,51(19):152-157.
[14]Wang Ying,Li Jie,Gao Xinbo.Latent feature mining of spatial and marginal characteristics for mammographic mass classification[J].Neurocomputing,2014,144(1):107-118.
[15]Zhou Wengang,Li Houqiang,Lu Yijuan,et al.BSIFT:toward data-independent codebook for large scale image search[J].IEEE Transactions on Image Process,2015,24(3):967-979.
[16]董健.基于加权特征空间信息视觉词典的图像检索模型[J].计算机应用,2014,34(4):1172-1176.
[17]Chang C,Lin C.LIBSVM:a library for support vector machine[J].ACM Transactionson IntelligentSystems and Technology,2011,2(3):27.
LI Shuang,LI Bailin,DI Shilei,LUO Jianqiao
School of Mechanical Engineering,Southwest Jiaotong University,Chengdu 610031,China
Inspection for railway fasteners based on entropy-weighted BOW model.Computer Engineering and Applications,2017,53(21):185-189.
The traditional Bag Of Words(BOW)model ignores the structure of the image while conducting the inspection of railway fasteners.To overcome this defect,this paper proposes an Entropy-Weighted BOW(EW_BOW)model for identification of the image of fasteners.On the basis of the traditional BOW model,the entropy is introduced to weight word frequency of BOW model in the sub-image of fasteners,thus making the BOW model more distinguishable for different categories of fasteners.And then the Latent Dirichlet Allocation(LDA)is used to learn the topic distribution of the images.Finally,the Support Vector Machine(SVM)is applied to classify a new image.The experiment on four types of fasteners shows that the EW_BOW model can inspect fastener states more precisely.
railway fastener inspection;Bag Of Words(BOW)model;visual word;entropy;Latent Dirichlet Allocation(LDA)model
A
TP391.41
10.3778/j.issn.1002-8331.1703-0454
四川省科技支撑计划项目(No.2016GZ0194)。
李爽(1992—),男,硕士研究生,研究领域为:图像处理、机器视觉,E-mail:263725027@qq.com;李柏林(1962—),男,教授,博士生导师,博士,研究领域为:图像处理、优化技术;狄仕磊(1992—),男,硕士研究生,研究领域为:图像处理、目标检测;罗建桥(1991—),男,博士研究生,研究领域为:图像处理、优化技术。
2017-03-27
2017-06-20
1002-8331(2017)21-0185-05
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01 06:28:50
园林科技(2021年3期)2022-01-19 03:17:48
铁道建筑技术(2020年11期)2020-05-22 06:26:46
西南交通大学学报(2018年5期)2018-11-08 10:58:08
电子测试(2017年12期)2017-12-18 06:35:48
雷达学报(2017年6期)2017-03-26 07:52:58
西安建筑科技大学学报(自然科学版)(2016年5期)2016-11-10 02:39:20
池州学院学报(2015年3期)2016-01-05 01:13:00
读者·校园版(2015年7期)2015-05-14 13:11:40
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
