
维吾尔语名词短语待消解项识别
2017-11-27 08:58陶豆豆田生伟赵建国吐尔根依布拉音艾斯卡尔艾木都拉
中文信息学报 2017年5期
陶豆豆,禹 龙,田生伟,赵建国,吐尔根·依布拉音,艾斯卡尔·艾木都拉
(1. 新疆大学 软件学院,新疆 乌鲁木齐 830008;2. 新疆大学 网络中心,新疆 乌鲁木齐 830046; 3. 新疆大学 人文学院,新疆 乌鲁木齐 830046;4. 新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046)
维吾尔语名词短语待消解项识别
陶豆豆1,禹 龙2,田生伟1,赵建国3,吐尔根·依布拉音4,艾斯卡尔·艾木都拉1
(1. 新疆大学 软件学院,新疆 乌鲁木齐 830008;2. 新疆大学 网络中心,新疆 乌鲁木齐 830046; 3. 新疆大学 人文学院,新疆 乌鲁木齐 830046;4. 新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046)
针对维吾尔语名词短语待消解项识别任务,该文提出一种利用栈式非负约束自编码器(Stacked Nonnegative Constrained Autoencoder,SNCAE)完成基于语义特征的待消解项识别方法。为了提高自动编码器隐藏层激活度的稀疏性和重构数据的质量,利用NCAE非负约束算法,为连接权值施加非负性约束。通过分析维吾尔语名词短语语言指代现象,提取出15个特征,利用SNCAE提取出深层语义特征,引入Softmax分类器,进而完成待消解项识别任务。该方法在维吾尔语名词短语待消解项识别中,正例准确率和负例准确率分别比SVM高出8.259%和4.158%,比栈式自编码(SAE)高出1.884%和1.590%,表明基于SNCAE的维吾尔语名词短语待消解项识别方法比SVM和SAE更适合维吾尔文的待消解项识别任务。
待消解项识别;维吾尔语;非负约束算法; 栈式自编码; 支持向量机
1 引言
指代是一种普遍存在的语言现象,它使句子更加简洁明了,在保证文章连贯性的同时又减少冗余。指代消解是为篇章中指示性代词寻找指代的过程,由两个子任务构成: ①待消解项识别;②指代消解。待消解项识别作为指代消解的前期工作,是针对已经识别出来的人称代词、名词短语、实体零指代项,进一步确定哪些词或短语是真正的待消解项。
随着自然语言处理相关研究的不断深入(篇章理解、机器翻译、人机对话、信息抽取等),指代消解日益成为研究热点。Soon等人[1]提出一个完整的指代消解框架,把指代消解转化为一个二分类问题(但是忽略了待消解项的识别);钱伟等人[2]提出一种基于语料库的英文名词短语指代消解算法。在中文的指代消解领域,研究者们也尝试了将类似英文指代消解的算法应用到中文指代消解中,周俊生等人[3]提出一种无监督聚类算法实现对名词短语的指代消解,引入图对指代消解问题进行建模,将指代消解问题转化为图划分问题;孔芳等人[4]提出基于树核函数的中英文代词消解方法;奚雪峰等人[5]提出一种利用DBN模型的深度学习机制进行基于语义特征的指代消解方法。然而他们都忽略了作为指代消解关键任务之一的待消解项识别。
2 相关工作
2.1 待消解项识别
待消解项识别的研究方法有三种: ①基于规则的识别;②基于语料库统计结果的识别;③基于机器学习方法,利用标注的语料进行识别。
早期待消解项识别是基于规则的识别,代表性工作有: Lappin等人[7]在其指代消解平台中引入了用于识别“it”是否为待消解项的独立识别模块。但是,基于规则的识别可移植性较差,一旦改变语言,就需要更改对应的规则。随着指代消解的进一步研究,又出现了基于语料库统计结果的识别方法。如Bergsma等人[6]利用统计的方法对代词 “it”的上下文句式进行过滤识别, 在大型语料库中对句式的出现频率进行统计,再根据统计结果判断这个代词是否为待消解项。
近年来,随着指代消解研究的不断深入和大规模语料库的出现,研究者们开始利用机器学习方法进行待消解项识别。Ng等人[8]给出一种基于机器学习的待消解项识别的方法,使用MUC语料库,他们选取了多方面的37个特征(包括词法、句法、语义等),生成对所有指代词都进行识别的待消解项识别模型,并将其应用于已有的指代消解系统;周国栋等人[9]利用标记传播算法,在机器学习的基础上对待消解项识别进行全局优化;孔芳等人[10]给出了一个规则与机器学习方法相结合的待消解项识别方法,使用ACE语料库,将得到的待消解项识别模块应用于中英文的指代消解任务;张超等人[11]结合交互式问答的特点,运用了一个规则与机器学习方法相结合的方法,在交互式问答系统中的待消解项识别方面取得较好的效果。
2.2 深度学习
近年来深度学习成为机器学习的一个新领域,深度学习的概念源于人工神经网络的研究。深度学习通过组合低层特征形成更加抽象的高层表示(属性类别或特征),以发现数据的分布式特征表示[12]。通过构建具有很多隐层的机器学习模型和海量的训练数据,来学习更准确、有用的特征,从而提升分类或预测的准确性。随着深度学习的持续发展,深度学习的应用范围也越来越广,除了语音识别、图像识别,还被广泛应用在自然语言处理领域。
Glorot等[13]利用深度自编码算法完成文本分类,通过添加纠正激活函数,有效地提高了分类效果。Salahutdinov 等[14]在自动编码器的基础上扩展了 LSA 模型,成功地发现隐藏在查询和文档中的层次语义结构。刘勘[15]等人提出一种基于深层噪声自动编码器的特征提取及聚类算法,将高维、稀疏的短文本空间向量变换到新的低维、本质特征空间。由此可见,自编码算法具有很强的文本学习能力和预测能力,能较好地提取文本中隐含的特征。因此,本文通过引入非负约束权值,构建非负约束自编码算法,提高自编码隐藏层活跃度的稀疏性和重构输入数据的质量。为了提高特征学习能力,得到更精确的特征,本文通过堆叠多个非负约束自编码来提升分类和预测的准确性。
3 基于SNCAE的待消解项识别模型
3.1 维吾尔语名词的分类
维吾尔语属于黏着性语言,导致名词短语结构复杂多样,具有以下特性: ①“格”的变化形式;②能与数词或形容词结合;③能充当句子各种成分。在参考相关文献后,实验组维吾尔语语言学专家总结出维吾尔语中名词短语的大致分类,具体如下:
(1) 专有名词: 专有名词又称固定词组,表示某一特有事物名称;专有名词如表1 所示。
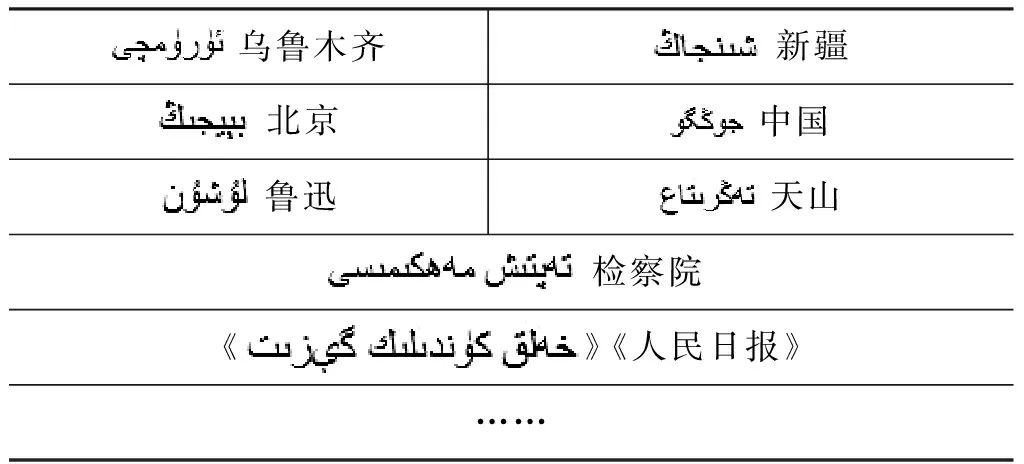
表1 专有名词
(2) 带领属性人称词尾的名词短语,如表2所示。
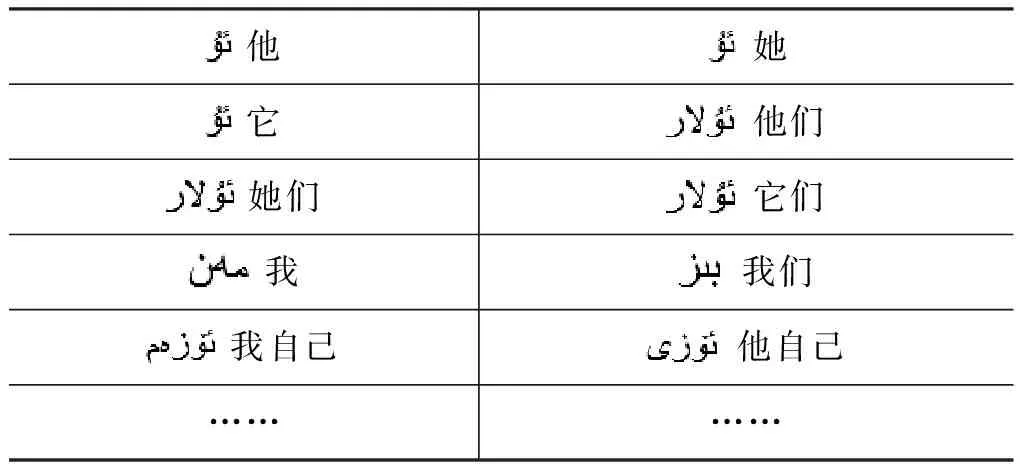
表2 带领属性人称词尾的名词短语
(3) 被指示词修饰的名词短语,如表3所示。
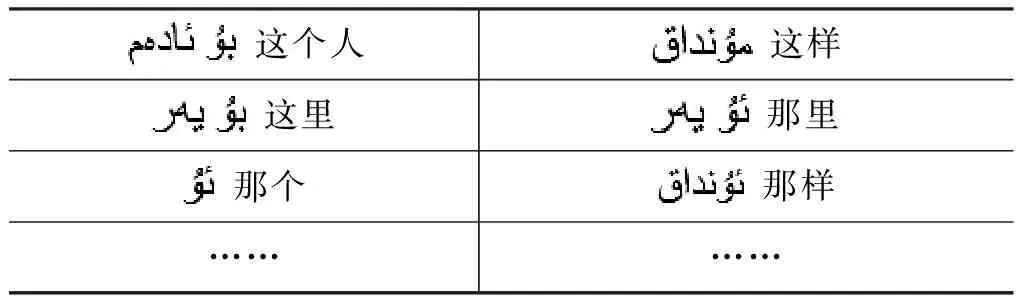
表3 被指示词修饰的名词短语
(4) 被形容词或形容词化的成分修饰的名词短语,如表4所示。
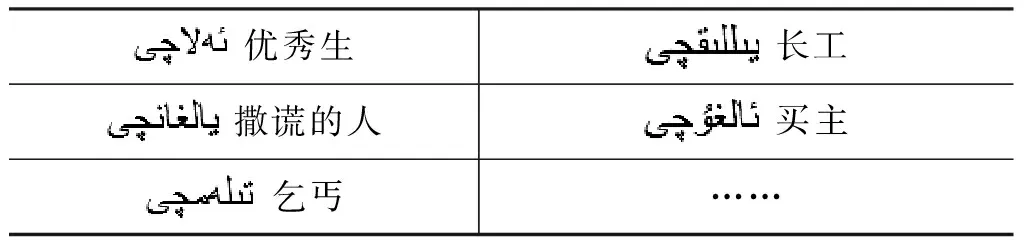
表4 被形容词或形容词化的成分修饰的名词短语
(5) 带宾格标志的名词短语,如表5所示。只有及物动词涉及的对象才可以带宾格词尾,通常要表达的事物已被限定或者已被确定将要出现。

表5 带宾格标志的名词短语
3.2 SAE模型
自编码是一种包括输入层、隐藏层、输出层的一个无监督学习模型,稀疏自编码在自编码的基础上添加了稀疏性约束条件,而SAE是一个由多层稀疏自编码器组成的神经网络。一个一层的SAE模型如图1所示。
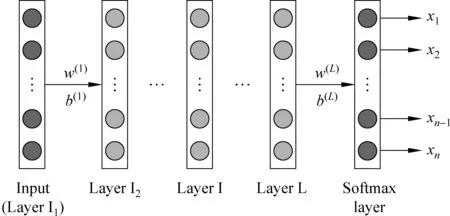
图1 SAE网络模型图
其中,w(l)和b(l)分别代表两层的权重参数和偏置 项;l是隐藏层数。对于一个包含m个样本的数据集,定义其代价函数为输出误差代价函数,如式(1)所示。
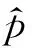
其中,β控制稀疏性惩罚因子的权重,λ控制惩罚因子的权重衰减,Sl和Sl+1为相邻层的大小。
3.3 非负约束自编码(NCAE)
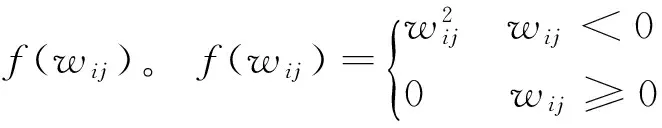
式(5)中,α是学习率,α≥0;通过最小化JNCAE(w,b)降低平均重构误差,同时增加隐藏层激活度的稀疏性,降低了各层非负权值,有效控制了学习速率过大导致的过拟合现象,进而提高了自动编码器的稀疏性和重构输入数据的质量。
使用反向传播算法更新权重和偏置项:
其中,η是学习速率。式(5)的相对权重由以下三个部分组成:
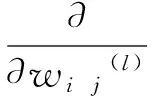
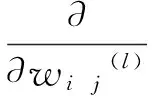
其中,
式(8)使用反向传播算法。
3.4 Softmax回归
利用逐层贪婪训练算法建立一个每一层预训练的无监督特征学习的深度学习网络。在本文中,预训练一个NCAE深度学习网络,其中前一阶段的输出作为下一阶段的输入,这是一个无监督学习的过程,最后一个隐藏层的输出作为Softmax的输入,进而有监督完成待消解项识别任务。在本文中,Softmax分类器的误分类代价函数如式(9)所示。
其中,m是样本数,k为y的取值个数,ω是Softmax层中所有节点的输入权值矩阵,ωl是Softmax第l个节点的输入量。我们定义了NCAE的Softmax的成本函数,如式(10)所示。
SL表示自编码的隐藏节点的数量,f(·)是激活函数。逐层贪婪训练方法在参数训练到逐渐收敛时,使用微调,对于调整的深度网络的成本代价函数(DN)[17],如式(11)所示。
在WDN包含输入权值的NCAE和Softmax层和BDN是NCAE层偏置输入。
SNCAE是由多个NCAE与Softmax分类器结合构建的一个包含多隐藏层与一个Softmax分类器深层神经网络。SNCAE利用无监督逐层贪婪训练法依次训练SNCAE网络的每一层,进而预训练整个深层神经网络。SNCAE结合NCAE无监督学习特征的方式和Softmax监督式算法,提高了深层神经网络的预测性能。SNCAE网络图如图2所示。
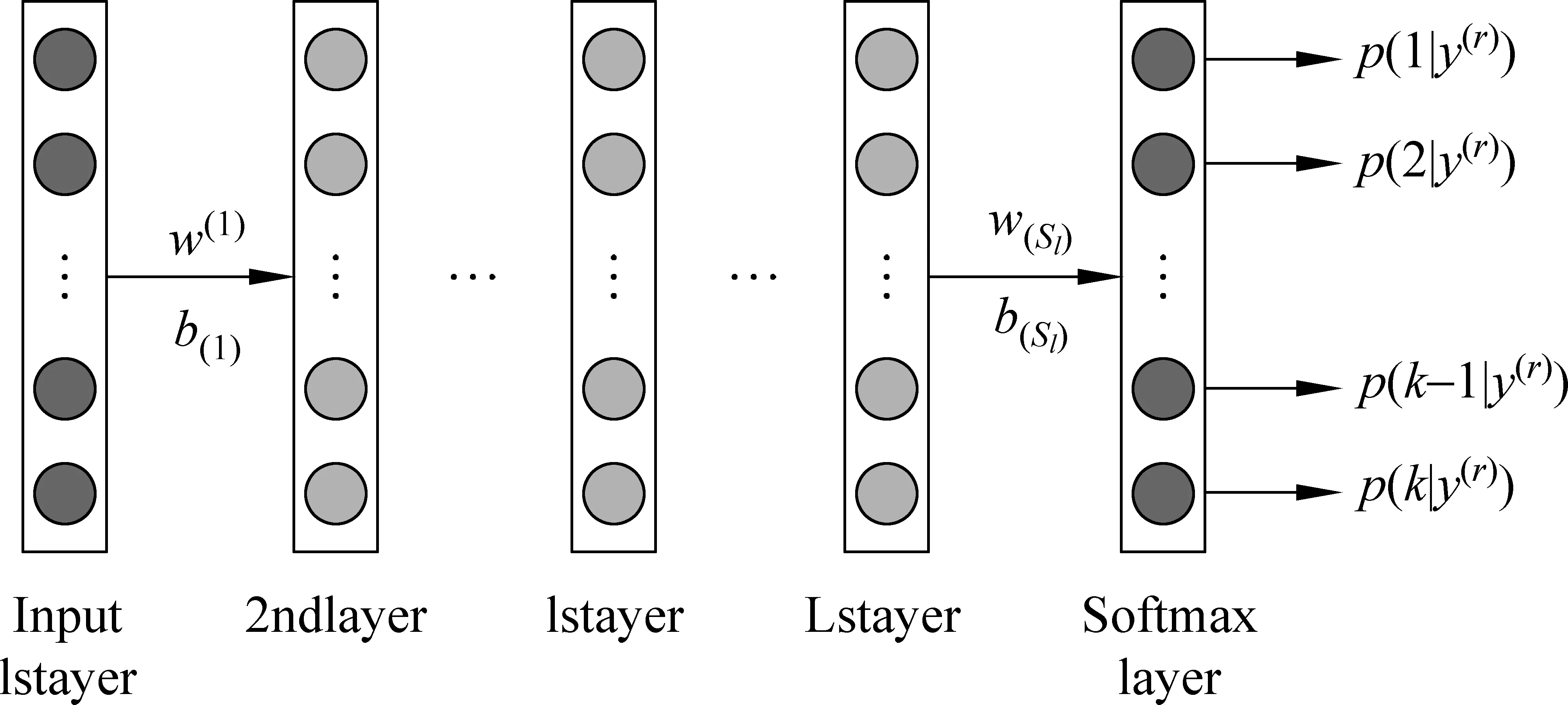
图2 SNCAE网络图
4 实验数据
周国栋等人[9]在对新闻语料统计后发现,能够成为指代词的语言单位主要有以下几类:代词、专有名词短语、有定名词短语、无定名词短语、指示性名词短语和未知类别名词短语。因此,本文在统计维吾尔语语料后,在实验组维吾尔语语言专家的指导下,以孔芳等人[10]基于ACE语料库提出的规则与机器学习方法相结合的待消解项识别方法为基础,同时参考前人的研究成果,对维吾尔语名词短语进行待消解项识别问题分析。
4.1 语料处理
目前国际上常用的中英文指代消解标注语料库有MUC和ACE,但针对维吾尔语指代消解的评测语料库还未见报道。因此,实验组针对维吾尔语待消解项识别任务,对语料进行了收集和筛选。
实验语料来源于天山网、人民网、论坛和博客等维吾尔语版网页,从中筛选出至少包含两条指代链信息以记人和叙事为题材的叙述文。在实验组维吾尔语专家的指导下,对语料进行分词、词性标注、命名实体识别、指代链信息标注等预处理。其中指代链信息包括名词短语、名词的类别、名词的数范畴、名词的格范畴等,处理后的语料选用XML文件进行存储。
4.2 特征提取
特征提取在指代消解和待消解项识别中都有重要作用,其结果直接影响待消解项识别的准确性,因为准确的特征才能够得到正确的实验结果和结论。本文参考孔芳[10]等人在中英文指代消解中待消解项识别中的特征集,并根据实验组维吾尔语语言专家归纳的维吾尔语名词短语类别,在维吾尔语语法的指导下,进行维吾尔语名词短语特征抽取。抽取以下特征集进行待消解项识别,特征如下。
(1) Alias:别名。正式的或规范的名称以外的名称;如果是则取1,不是取0。
(2) Personal-pronoun: 人称代词。这里指维吾尔语语言中含有第一、二、三词尾的名词;如果是则取1,不是取0。
(3) Proper-nouns: 专有名词。专有名词包括人名、地名、组织机构名等专用名词,这个特征值可直接根据命名实体识别的结果来确定;如果是则取1,不是取0。
(4) Semantic-role: 语义角色。在句子中充当一定句法角色,例如施事者、受事者、方法或者工具等;如果有则取1,无取0。
(5) Singular-plura: 单复数。如果是单数则取1,复数取0。
(6) Sex: 性别。如果是男则取0,女取1,未知0.5,没有取2。
(7) Indicative NP: 指示性代名词。如果是则取1,不是取0。
(8) FirstNP:当前对象是不是语句中的第一个名词短语;如果是则取1,不是取0。
(9) Arg0:施事者。如果是则取1,不是取0。
(10) Arg1:受事者。如果是则取1,不是取0。
(11) NestIn:是否有名词短语嵌套当前对象,如果是则取1,不是取0。
(12) NestoOut:是否嵌套在名词短语中,如果是则取1,不是取0。
(13) WordSense:该名词短语之前是否有相同语义类别的名词性短语。如果是则取1,不是取0。
(14) Str-Match:该名词短语之前是否有与之全串匹配的名词短语。如果是则取1,不是取0;
(15) Grammar:是否有格语法。如果有则取1,没有取0。
4.3 训练及测试样例提取
本文通过机器学习方法把待消解项识别看成是一个二分类问题,即判断待消解项是否在指代链内,判断名词短语是否是待消解项。本文对标注过的语料进行名词短语的提取(实验组共标注语料170篇,其中名词短语10 120个,随机抽取10 000个名词短语进行试验),使用4.2节的特征集提取特征,形成维吾尔语名词短语待消解项识别的训练和测试样例,如表6所示。

表6 训练及测试样例
5 实验分析
本文采用周国栋等人[9]提出的方法,使用了两个准确率来评估待消解项识别器的性能,分别是正例的准确率Acc+和负例的准确率Acc-。

(12)
这一准确率越高,说明被丢失的待消解项越少,指代消解在这一环节损失的召回率越低。

(13)
这一准确率越高,进行指代消解测试时,待消解项识别器正确滤去的不必要的测试实例越多,引入的噪声越少。
5.1 SAE和SVM的结果对比分析
先用SAEi(i表示 SAE包含的自编码器层数)和SVM 模型进行指代消解实验。SVM是处理非线性数据的浅层机器学习模型,与SAE 模型有较好的对比性,所以本文选用SVM 进行对比实验。结果如表7所示。
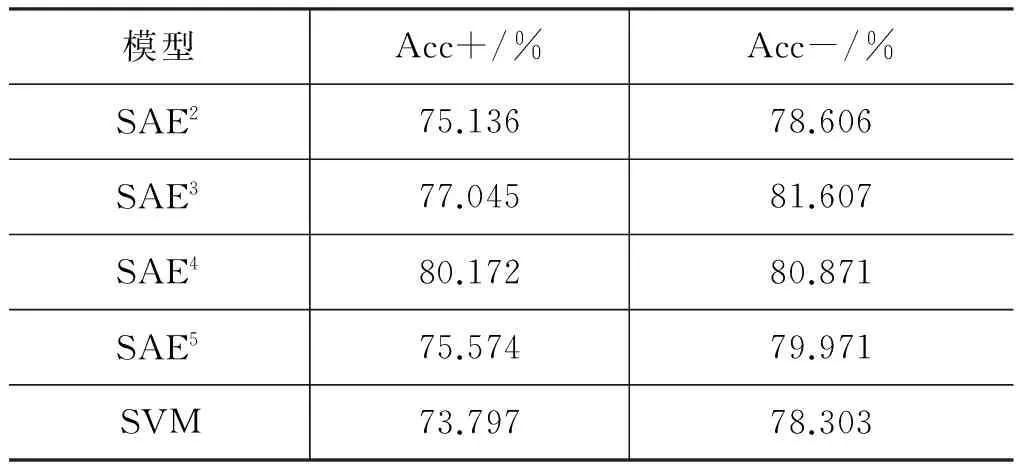
表7 SAEi与SVM实验结果对比
从表7中我们可以看到包含不同层的SAEi比SVM有效,使用SAE模型在待消解项识别的正例准确率Acc+和负例准确率Acc-都有提高,并且在SAEi模型自编码层数提高时待消解项识别的正例准确率Acc+也都有所提高。Acc-在三层模型后开始递减,负例识别率降低了0.736%~0.9%。SAE的性能最佳是四隐层,其结果比SVM在Acc+ 和Acc-上分别高出6.375%和2.568%。这是因为SAE通过学习一种深层非线性网络结构,实现复杂函数逼近,表征输入数据分布式表示,具有更好的泛化能力、更强大的学习能力。相比SVM单层神经网络,SAE通过多层稀疏自编码器能学习到更准确、更有用的特征,从而提升分类或预测的准确性。因此,SAE在指代消解中待消解项的识别方面优于SVM。
5.2 基于SNCAE的结果分析
为了对比SNCAEi(i表示 SAE包含的自编码器层数)的结果,本文选取SNCAEi与SAE最优结果SAE4做比对实验。SNCAE 模型由多个NCAE模型堆叠形成,NCAE模型是由SAE施加非负权重约束改进的算法,所以本文采用SAE作对比实验,结果如表8所示。
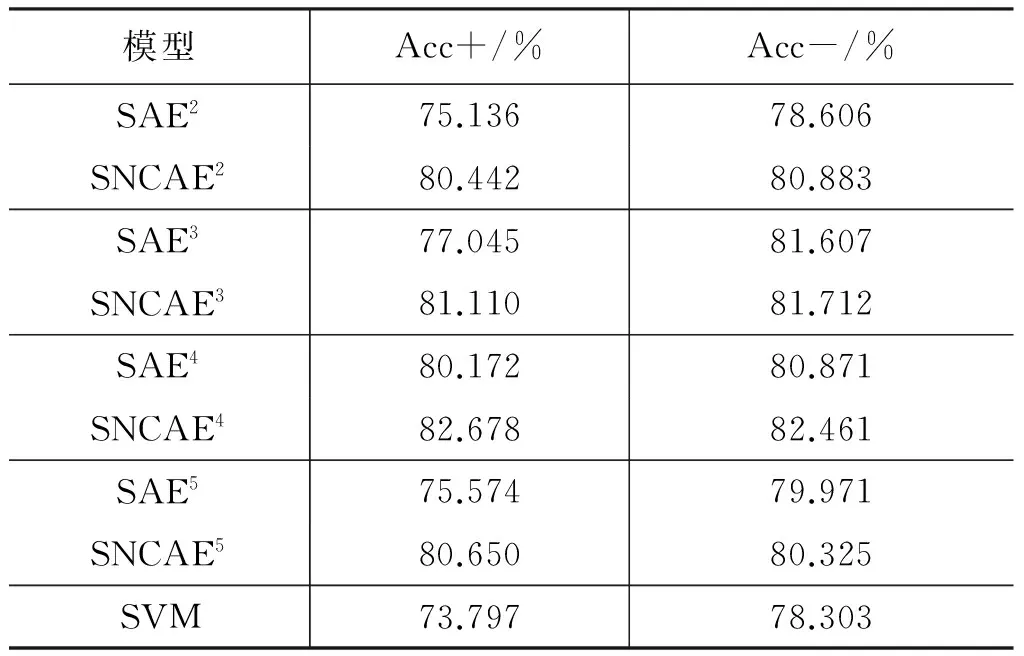
表8 NCAEi与SAEi、SVM实验结果对比
从表8中我们可以看出,SNCAEi在维吾尔语名词短语的待消解项识别中的性能优于SAEi和SVM。其中明显可以看出SNCAE的隐藏层数与SAE的隐藏层数相等时,SNCAE的实验结果优于SAE。其中待消解项识别的正例准确率Acc+和负例准确率Acc-在SNCAEi模型下的最优结果分别高于SAEi的最优结果1.884%和1.590%。通过表7 中SAE与SVM的对比实验验证了SAE在指代消解中待消解项的识别方面优于SVM。通过表8中SNCAEi与SAEi及SVM的对比实验验证了SNCAEi在指代消解中待消解项的识别方面优于SAEi及SVM。随着自编码层数的增加,待消解项识别的正确率也在提高,在四隐层时得到最佳结果,SNCAE通过施加非负约束权重,提高自编码网络隐藏层活跃度的稀疏性,产生了更好的重建数据。因此,SNCAE相比于SAE和SVM更适合本文的待消解项识别任务。
6 结论
本文深入研究了维吾尔语待消解项识别问题,在前人研究的基础上,提出基于栈式非负约束自编码(SNCAE)的维吾尔语名词短语待消解项识别方法。SNCAE利用非负约束权重,提高自编码隐藏层活跃度的稀疏性和重构输入数据的质量,从而提高了深层神经网络的预测性能。本文经过与SVM及SAE的对比,验证了SNCAE深度学习方法在维吾尔语待消解项识别任务中的有效性。
[1] Soon W M, Ng H T, Lim D. A machine learning approach to coreference resolution of noun phrase [J].Computational Linguistics,2001,27(4):521-544.
[2] 钱伟,郭以昆,周雅倩,等.基于最大熵模型的英文名词短语指代消解[J].计算机研究与发展,2003, 40(9):1337-1343.
[3] 周俊生,黄书剑,陈家骏,等.一种基于图划分的无监督汉语指代消解算法[J].中文信息学报,2007,21(2):77-82.
[4] 孔芳, 周国栋. 基于树核函数的中英文代词消解[J].软件学报, 2012, 23(5): 1085-1099.
[5] 奚雪峰,周国栋. 基于Deep Learning的代词指代消解[J].北京大学学报(自然科学版),2014,50(1):100-110.
[6] Bergsma S, Lin D. Bootstrapping path-based pronoun resolution[C]//Proceedings of the 21st International Conference on Computational Linguistics and the 4th annual meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2006: 33-40.
[7] Lappin S, Herbert J L. Analgorithm for Pronominal anaphora resolution [J]. Computational Linguistics,1994,20(4);535-561.
[8] Ng V, Cardie C.Improving machine learning approaches to coreference resolution [C]//Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL). Philadelphia: Association for Computational Linguistics, 2002:104-111.
[9] Zhou G D, Kong F. Global learning of noun phrase anaphoricity in coreference resolution via label propagetion[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing.Stroudsburg, USA: Association for Computational Linguistics,2009:978-986.
[10] 孔芳,朱巧明,周国栋. 中英文指代消解中待消解项识别的研究[J].计算机研究与发展,2012,49(5):1072-1085.
[11] 张 超,孔 芳,周国栋. 交互式问答系统中待消解项的识别方法研究. 中文信息学报,2014,28(4):111-116.
[12] Bengio Y,Delalleau O. On the expressive power of deep architectures[C]//Proceedings of the 14th International Conference on Discovery Science. Berlin: Springer-Verlag,2011: 18-36.
[13] Glorot X, Bordes A, Bengio Y. Deep sparse rectifier neural networks[C]//Proceedings of 14th International Conference on Artificial Intelligence and Statistics. Fort Lauderdale, USA : AISTATS, 2011: 315-323.
[14] Salakhutdinov R, Hinton G. Semantic hashing[J]. International Journal of Approximate Reasoning, 2009, 50(7): 969-978.
[15] Zhang K X, Zhou C L. Unsupervised feature learning for Chinese lexicon based on auto-encoder[J]. Journal of Chinese Information Processing,2013,27(5):85-92.
[16] 张开旭,周昌乐.基于自动编码器的中文词汇特征无监督学习[J].中文信息学报,2013,27(5):85-92.
[17] 刘勘,袁蕴英.基于自动编码器的短文本特征提取及聚类研究[J].北京大学学报(自然科学版),2015,51(2):282-288.
[18] G E Hinton, S Osindero, Y W Teh. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006,18(1): 1527-1554.

陶豆豆 (1992—),硕士研究生,主要研究领域为自然语言处理。
E-mail:tao__doudou@163.com

禹龙(1974—),硕士,教授,硕士生导师,主要研究领域为计算机智能技术与计算机网络。
E-mail: yul_xju@163.com

田生伟 (1973—),博士,教授,硕士生导师,主要研究领域为自然语言处理与计算机智能技术。
E-mail: tianshengwei@163.com
AnaphoricityDeterminationofUyghurNounPhrases
TAO Doudou1, YU Long2, TIAN Shengwei1, ZHAO Jianguo3, Turgun•Ibrahim4, Askar•Hamdulla1
(1. School of Software, Xinjiang University, Urumqi, Xinjiang 830008, China;2. Net Center, Xinjiang University, Urumqi, Xinjiang 830046, China;3. School of Humanities, Xinjiang University, Urumqi, Xinjiang 830046, China;4. School of Information Science and Engineering, Xinjiang University, Urumqi, Xinjiang 830046, China)
Focusedon Uyghur noun phrase coreference identification task, this paper proposed a Stacked Nonnegative Constrained Autoencoder( SNCAE) for anaphoricity determination based on semantic feature. Through the analysis of Uyghur noun phrase language phenomenon, 15 kinds of semantic features are extracted, and then input into SNCAE to extract the deep semantic features. Finally, the Softmax classifier is used to complete the recognition task. Compared with Support Vector Machine (SVM), the positive accuracy and negative accurate increased by 8.259% and 4.158%, respectively, and increased by 1.884% and 1.590%, respectively, than the Stacked Autoencoder (SAE).
anaphoricity determination; Uyghur; NCAE; SAE; SVM
1003-0077(2017)05-0092-07
TP391
A
2016-11-07定稿日期2017-03-27
国家自然科学基金(61563051, 61662074);国家自然科学基金(61262064); 国家自然科学基金(61331011);自治区科技人才培养项目(QN2016YX0051)
猜你喜欢
科学咨询(2022年19期)2022-11-24
通信技术(2021年12期)2022-01-25
考试与评价·八年级版(2020年1期)2020-10-26
中国民族博览(2019年10期)2019-11-29
计算机应用与软件(2018年9期)2018-09-26
知识文库(2018年16期)2018-05-14
电脑知识与技术(2018年3期)2018-03-21
北方文学(2018年2期)2018-01-27
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
东西南北(2016年19期)2016-11-01
