
基于部件组合的联机手写“藏文—梵文”样本生成
2017-11-27 08:57:49王维兰卢小宝蔡正琦沈文韬才科扎西
中文信息学报 2017年5期
王维兰 ,卢小宝 ,蔡正琦 ,沈文韬 ,付 吉,才科扎西
(1. 西北民族大学 数学与计算机科学学院,甘肃 兰州 730030;2. 中国人民银行 白银中心支行,甘肃 白银 730900)
基于部件组合的联机手写“藏文—梵文”样本生成
王维兰1,卢小宝2,蔡正琦1,沈文韬1,付 吉1,才科扎西1
(1. 西北民族大学 数学与计算机科学学院,甘肃 兰州 730030;2. 中国人民银行 白银中心支行,甘肃 白银 730900)
“藏文—梵文”包括500多个现代藏文、6 000多个梵音藏文,在文字识别领域属于大类别的字符集,所以联机手写样本采集是庞大而复杂的工程。鉴于此,提供了一种基于部件组合的“藏文—梵文”手写样本生成方法,主要包括: (1)确定“藏文—梵文”字符集和部件集;(2)获取“藏文—梵文”字丁的部件位置信息;(3)采集联机手写“藏文—梵文”部件的样本;(4)生成联机手写“藏文—梵文”字符集样本库。该文为联机手写“藏文—梵文”识别的研究提供字符训练样本库和测试样本库,提高了手写梵音藏文样本采集效率,解决了样本数量及多样性问题,降低了样本采集成本,为进一步联机手写梵音藏文识别的研究与系统开发奠定了基础。
联机手写;藏文—梵文;字符集;部件组合;样本生成
1 引言
藏文输入与其他文字一样,有键盘输入、手写识别输入和扫描识别输入等。现代藏文通常又称为藏文,有500多个字丁。梵音藏文是梵文的藏文转写形式,有6 000多个字丁。本文所述的联机手写识别字符集包括: ISO/IEC 10646-1: Tibetan Character Collection[1]即藏文基本集中42个字丁、《信息技术 藏文编码字符集(扩充集A)》[2]的1 536个字丁及《信息技术 藏文编码字符集(扩充集B)》[3]的5 662个字丁,以下分别简称为: 基本集、扩充集A和扩充集B,藏文和梵音藏文共计7 240个字丁,本文中统称为“藏文—梵文”识别字符集。“藏文—梵文”字符集的特点: 字符集大,在模式识别中就是 7 240 个类别。现代藏文和几十个常用梵音藏文共592个字丁的印刷体识别已有较多研究[4-6],所开发的多字体印刷藏文字符识别系统已经得到广泛的应用。近年来,我国少数民族文字的脱机手写识别、联机手写识别成为新的研究热点,在维吾尔文联机手写识别系统中分别使用GMM和HMM两种模型进行建模并对其合并,确定最优识别结果[7]、手写维吾尔文的预处理方法[8]。在脱机手写藏文识别方面,选择667个藏文字符作为识别对象,在样本库构建、预处理、特征提取、分类器设计及后处理等方面进行了深入研究[9]。2009年,我们完成了现代藏文517个字丁和常用梵音藏文45个共计562个字丁的联机手写输入研发,并获得“一种联机手写藏文字丁的识别方法”授权专利[10]。在近几年的藏文识别研究中,中科院在基于部件的联机手写藏文识别方面取得一定成果[11-14]。目前,涵盖扩充集A和扩充集B的梵音藏文的联机手写识别还未见相关报道。在实际应用过程中,现代藏文和梵音藏文混合使用,对于联机手写“藏文—梵文”识别软件系统的研究与开发至关重要,其中联机手写字符样本库是数据基础,且样本库的质量好坏也直接影响最后的识别效果。汉字的联机手写识别研究已有各类样本库[14-15],然而,目前还没有包含扩充集A、扩充集B的藏文及梵音藏文字丁的联机手写样本库。当字符集“藏文—梵文”以字丁作为识别单位时,采集手写样本将是一项非常庞大和复杂的工程。鉴于此,我们提出了一种基于部件组合的“藏文—梵文”联机手写样本生成的方法,生成了7 240个字符集的联机手写样本库。该方法不仅降低样本采集的成本,也解决了大字符集“藏文—梵文”联机手写识别样本的数量及样本的多样性问题,为进一步联机手写梵音藏文识别的研究与系统开发奠定了基础。
论文第二部分是基于部件组合的联机手写“藏文—梵文”样本生成构架;第三部分是字符集部件集的确定;第四部分为“藏文—梵文”字丁的部件位置信息获取方法;第五部分是联机手写“藏文—梵文”部件的样本采集;第六部分是最重要的部分,是联机手写“藏文—梵文”字丁样本库的生成;第七部分是训练与测试的初步实验分析;最后是结语。
2 基于部件组合的联机手写“藏文—梵文”样本生成构架
基于部件组合的“藏文—梵文”联机手写样本生成构架如图1所示。

图 1 基于部件组合的“藏文—梵文”联机手写样本生成构架图
根据图1,主要内容有四个部分:
(1) 确定“藏文—梵文”字符集和部件集。“藏文—梵文”字符集由7 240个字丁组成,部件集由81个基本集字符和89个构件组成,形成170个部件的部件集。
(2) “藏文—梵文”字丁的部件位置信息获取。将7 240个“藏文—梵文”的每一个字丁放置于xy平面的大小为M×N的框内,标注该字丁各个部件的外接矩形框,获取并存储该字丁各个部件的坐标数据信息。
(3) 联机手写“藏文—梵文”部件的样本采集。设计部件样本采集软件,书写者完成第1到第170个部件的采集和存储,形成一套样本,采集信息包括部件的BMP位图文件和部件笔迹信息文件。获取所有采集人员完成的样本,得到部件样本库。
(4) 联机手写“藏文—梵文”字丁样本库的生成。设计样本生成算法,根据步骤(2)所获取的字丁各个部件的坐标数据信息,将字丁的部件样本从部件样本库中取出,依次按照它们组成一个字丁的各部件位置信息,映射到对应的位置矩形,便得到字丁的样本。生成7 240个“藏文—梵文”字丁的4 000~7 000套样本。为联机手写“藏文—梵文”识别的研究与开发奠定字符集的样本库基础。
3 “藏文—梵文”字符集和部件集
3.1 “藏文—梵文”字符集
“藏文—梵文”包括基本集、扩充集A、扩充集B中的字丁。在我们整理字符集时发现,扩充集A与扩充集B有一些重复的字丁,它们是:



扩充集B内部有两个重复字丁,F1144和F1145完全一样,如图2所示。

图2 扩充集B中的两个重复梵音藏文
删除重复的字丁,最后确定“藏文—梵文”字符集包括基本集的42个、扩充集A的1 536个和扩充集B的5 662个,共计7 240个字丁。
3.2 “藏文—梵文”部件集
为了提高样本质量和生成效率,降低采样成本,本文提出了基于部件组合的联机手写“藏文—梵文”样本生成方法。而“藏文—梵文”部件集的确定遵循三个原则:
(1) 部件集越小越好。因为“藏文—梵文”字丁就是基本集中一个部件上下叠加组合而成。




部件集由81个基本集字符和89个相连部件组成,表1所示为“藏文—梵文”的170个部件。
表1“藏文—梵文”170个部件

3.3 “藏文—梵文”部件组合信息的数据库
扩充集A和扩充集B中的字丁都是基本集中的字符上下叠加组合而成的,字丁不等高,基于以上三个原则,根据所确定的部件集拆分“藏文—梵文”字符集,可将字丁拆分为由一至六个不等的部件构成,称为一个字丁的部件个数或层数。同时,基于藏文编码暨国际标准基本集ISO/IEC 10646-1和与之相一致的Unicode国际标准,使“藏文—梵文”字符集完全包括国际通用的内码,字符集字丁的拆分信息包括序号、Unicode码、藏文—梵文显现、部件个数、部件1到部件6的编号、部件1到部件6的显现等。表2所示为“藏文—梵文”字符集字丁的拆分信息表的格式及部分字符的拆分信息,分别列出了序号为1、2、43、853、4 619、7 240的藏文或梵音藏文,反映了这些字符从第一到第六个部件的拆分信息。

表2 “藏文—梵文”字符集字丁的拆分信息表
4 “藏文—梵文”的部件位置信息获取
4.1 “藏文—梵文”字丁的空间位置
部件集为“藏文—梵文”字丁的部件构成奠定基础,我们的思路是: 获取印刷体“藏文—梵文”字丁各个部件及部件的空间位置信息,将一个字丁的联机手写部件,映射到对应位置便可得到该字丁的手写样本。
对同一字体、字号的7 240个“藏文—梵文”字丁都放置于xy平面的大小为MN的框内,所有字丁以基线对齐,基线之上有元音或者没有。如图3所示为四个字丁放置于xy平面MN框内的示意图,这四个字丁只有第二个字丁有上元音。

图3 字符在xy平面、MN的框内
将待标注字丁显示在MN的标注平面上,实际标注中宽M=240、高N=480,单位为像素。如图4所示的字丁由两个部件组成,上面部件位置矩形表示为Z(hd1,vd1,hd2,vd2),也就是标注每一个部件的外接矩形,获得其左上角坐标(hd1,vd1)和右下角坐标(hd2,vd2),就获得了该部件的位置信息。

图4 标注平面示意图
4.2 “藏文—梵文”字丁的部件位置标注及其信息库


图5 部件标注过程
对7 240个“藏文—梵文”字丁进行部件位置信息的标注,并将标注过程中的信息存入数据库,该数据库存储的信息包括: ID(数据行号)、Tibetan(“藏文—梵文”显示)、Order(“藏文—梵文”序号)、Code(从上到下各部件的序号)、Sort(部件顺序号),以及每个部件的左上角横坐标X1和纵坐标Y1、右下角横坐标X2和纵坐标Y2。表3所示为字符信息库中

表3 字符信息库中的部件位置信息(首、尾两个字丁、)
5 联机手写“藏文—梵文”部件的样本采集
5.1 部件的样本采集设置、采集和存储
为获得自然、流畅、符合书写习惯的部件样本库,我们设计了部件样本采集软件。在Android平台的iPad上完成部件的样本采集,采集信息包括部件的BMP位图文件,图6所示为一个采集者的部分部件样本位图。

图6 一个采集者的部件位图(部分)样本
位图文件便于查看,另一个存储的是部件笔迹信息文件,笔迹信息文件中包含书写时笔迹经过的点、笔画结束和部件结束的标记信息:
(x11,y11) (x12,y12)…(x1n1,y1n1)(-1,-1),
(x21,y21) (x22,y22)…(x2n2,y2n2)(-1,-1),
……
(xt1,yt1) (xt2,yt2)…(xtnt,ytnt)(-1,-1)(-2,-2)
其中(xtnt,ytnt)表示第t个笔画的第nt个点的坐标,(-1,-1)表示从落笔到抬笔一个笔画的结束,(-2,-2)表示一个部件书写结束。
5.2 部件样本库
每个人完成第1到第170个部件的采集和存储,形成一套部件样本,样本的实际分布包括书写者所在的地域、年龄、学历等因素,共有300多人参加采集;为保证样本的质量,还需要对部件样本进行预处理,如去除或修正错误样本,甚至整套删除,以及去除孤立点、进行倾斜校正等,从而形成部件样本库。
6 联机手写“藏文—梵文”字丁样本库的生成
6.1 部件样本到字丁样本的映射
根据字丁拆分和位置矩形标注的结果,将构成字丁的部件样本逐一从部件样本库中取出,依次按照其位置信息映射到对应位置矩形,便得到字丁的样本;设“藏文—梵文”字丁Z由m个部件r1、r2、r3、…、rm-1、rm构成,构成字丁Z的部件中部件ri的样本数为ksi,则字丁Z可生成的样本有ks1×ks2×…×ksi×…×ksm种,实际中,部件样本是成套采集的,因此ks1=ks2=…=ksi=…=ksm=k,其中k为部件样本的套数。
“藏文—梵文”字丁(或其中的部件)相应位置如图7所示,图7(a)是部件样本的位置矩形,位置矩形表示为Z(hsc1,vsc1;hsc2,vsc2),其中hsc1和vsc1为矩形左上角的横坐标和纵坐标,hsc2和vsc2为矩形右下角的横坐标和纵坐标,M'×N'是部件采集平面;图7(b)是图7(a)所对应部件映射平面的位置矩形,M"×N"为部件映射平面,图7(b)中位置矩形,由“藏文—梵文”识别字符集信息库中的部件位置信息,通过线性变换计算获得,如式(1)所示。
这个变换确定了部件在映射平面中的位置,其中(hsc1,vsc1,hsc2,vsc2)为部件的位置信息。部件映射就是对采样平面中位置矩形内的部件做线性变换,然后复制到映射平面的过程,线性变换参数,如式(2)所示。

图7 部件样本映射到“藏文—梵文”字丁相应位置示意图
图8(a)、图8(b)和图8(c)是图7(a)的部件样本复制到映射平面的位置矩形后出现的三种情况,为了取得更好的字丁生成效果,需要校正部件在映射平面位置矩形内的数值。设部件样本上的任一点为(x,y),对应校正后的点为(x’,y’),校正可分为三种情况:
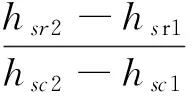

图8 部件样本到映射平面的位置情况示意图
6.2 7 240个字丁样本的生成
用于7 240个类别的识别问题,需要训练样本和测试样本4 000~7 000套,本次实施过程生成了5 000套。
对单部件字丁的样本,采用非同比伸缩变换、稀疏化的方法,通过改变字丁中点的空间位置信息来增加样本的数量,但是同比伸缩变换的长宽比必须控制在一定范围内,超出范围将造成字符严重扭曲变形以致无法识别;稀疏化是一种类似于数据丢包的方法,通过随机丢点的方法来改变字丁中笔画的轨迹信息,丢点太多则有可能完全失去字符的空间信息,丢点太少则不足以改变字符的空间信息,选择适当的范围也是关键所在。线性变换、稀疏化算法如下:
(1) 采用线性变换

(2) 稀疏化算法
稀疏化分四步:
① 读取所采集的字丁存入数组中;
② 设置丢点的数目υ并计算数组大小len,丢点的数目υ的范围是: 0.05len≤υ≤0.3len;
③ 产生υ个数组索引随机数rand,0≤rand≤len-1;
④ 删除υ个随机数索引对应的点,存储新生成的字丁样本。
“藏文—梵文”字丁样本生成的算法如下:
S1. 判断待生成字丁的部件层数;
S2. 如果字丁层数为1,则转S3,如果字丁层数为2,则转S4,如果字丁层数大于等于3,则转S5;
S3. 将通过线性变换和稀疏化得到的样本存放到一起,并随机地将其分配到每一套“藏文—梵文”样本中;
S4. 根据“藏文—梵文”字丁的部件位置信息标注结果,将一个字丁的两个部件从上到下按照其编号和位置信息从得到的信息数据库中读取,并映射到大小为M×N的位置矩形中;
S5. 根据“藏文—梵文”字丁的部件位置信息标注结果,将组成字丁的部件从上到下均匀地从部件样本库中取出,然后映射到大小为M×N的位置矩阵中。
上述算法中,所谓均匀地从部件样本库中取出部件,方式如下:
通过以上过程,我们完成了7 240个类别联机手写“藏文—梵文”字符集样本5 000套,共36 200 000个样本。这些样本再经过消除孤立点、笔速均匀化、归一化等预处理就可用于联机手写“藏文—梵文”识别的研究。

图9 不同层数“藏文—梵文”字丁合成的样本实例图
7 训练与测试的初步实验分析
7.1562个字丁在不同测试样本集上的识别结果比较
字丁预处理、特征提取与压缩、分类器设计等采用原有的方法[11],同时,原来562个藏文字丁,315个人手写完成315套作为训练集、60人书写的60套作为测试样本集,首选、三选、五选和十选识别率如表4的第一行所示。新的方法所生成的样本训练的分类器,同样取另外60套作为测试样本集,测试的结果如表4的第三行所示。新的样本集上测试识别率有较大幅度的提高。分析原因,一方面,可能原

表4 平均识别率比较
来采集样本时,每个采集者书写到后面相对都写得比较潦草。
另外,562个字丁十选识别率的分布情况如表5所示。由表5可见,现在识别率在99%以上的占总字数的35.76%;识别率在98%以上的占总字数的61.38%;识别率在97%以上的占总字数的77.94%;全部的字丁识别率都在90%以上。此外,虽然现在识别率100%的字丁比原来多3个,但识别率99%以上的字丁大幅增加。表6是一套测试样本中扩展集A的几个字丁识别的前十选排序情况,其中前三行都是首选正确,即选项为1;然后是四个字丁的正确识别结果为第二选;最后两行正确的识别结果分别在三选、四选。由表6可见,无论识别正确的是首选还是四选,前十个侯选序列基本都是极相似的字丁。
7.2 7 240个字丁的测试结果
7 240个字丁的5 000套样本,随意选取训练集4 500套样本、测试集500套。
对500套样本进行测试,首选、三选、五选、十选

表5 十选识别率的分布情况

表6 一些扩充集A中的字丁测试识别情况


表7 7 240个字丁500套样本的平均识别率

表8 7 240个字丁第十选识别率字分布情况
表9是十选识别率100%的45个字丁,前三个是扩充集A中的字丁,其余全部是扩展集B中的字丁,除第一个字丁是基字加元音笔划简单外,其他字丁都叠加层数多笔画较为复杂。初步的判断: 复杂字丁的识别率较简单字丁的识别率高。
表9十选识别率100%的45个字丁

8 结语
根据藏文、梵音藏文的书写习惯,确定170个部件的“藏文—梵文”部件集,以及“藏文—梵文”字符集7 240个类别;开发完成了“藏文—梵文”字丁的部件位置信息获取软件,形成该字符集各个字丁的部件位置信息数据库;开发了联机手写“藏文—梵文”部件的样本采集软件,已采集了300多套部件样本集;根据“藏文—梵文”部件位置信息数据库、部件样本集,设计字丁样本生成的算法,完成了联机手写“藏文—梵文”字符集样本库生成软件,现已生成7 240个联机手写“藏文—梵文”的样本库5 000套,用于联机手写“藏文—梵文”识别研究和开发的训练样本与测试样本,提高了手写样本采集效率和样本多样性,降低了样本采集成本。初步的训练和测试结果: 对562个(现代藏文517个和常用梵音藏文45个)字丁,在所生成的样本库上进行训练和测试,平均识别率有了较大的提高;7 240个字丁的十选识别率达到95.956 5%。在此基础上,将进一步完善相关内容,完成联机手写“藏文—梵文”的识别系统。
[1] ISO/IEC 10646-1:Tibetan Character Collection[S].ISO/IEC JTC1/SC2/WG2,2000.
[2] 国家质量技术监督局.GB 22323—2008 信息技术藏文编码字符集(基本集及扩充集A)[S].北京: 中国标准出版社,2008.
[3] 国家质量技术监督局.GB/T 25913—2010 信息技术 藏文编码字符集(扩充集B)[S].北京: 中国标准出版社,2010.
[4] 王维兰,丁晓青,祁坤钰.藏文识别中相似字丁的区分研究[J].中文信息学报,2002,16(4):60-65.
[5] 王华,丁晓青.多字体印刷藏文字符识别[J].中文信息学报,2003,17(6):47-52.
[6] 丁晓青,王华,刘长松,等.多字体多字号印刷体藏文字符识别方法[D].ZL200410034107.4,2004.
[7] 热依曼·吐尔逊,吾守尔·斯拉木.一种维吾尔语联机手写识别系统[J].中文信息学报,2014,28(3):112-115.
[8] 刘卫,李和成.基于多模板归一化的维吾尔文字母识别算法[J].中文信息学报,2016,30(1):156-161.
[9] Huang Heming, Da Feipeng, Hang Xiaoxu. Wavelet transform and gradient direction based feature extraction method for off-line handwritten Tibetan letter recognition[J].Journal of Southeast University,2014(1):27-31.
[10] 王维兰,钱建军,多杰卓玛,等.一种联机手写藏文字符的识别方法[P].中华人民共和国国家知识版权局. ZL200910128595.8, 2011.
[11] Ma L L,Wu J. Semi-automatic Tibetan component annotation from online handwritten Tibetan character database by optimizing segmentation hypotheses[C]//Proceedings of the International Conference on Document Analysis amp; Recognition, 2013:1340-1344.
[12] Ma L L, Wu J. A Tibetan component representation learning method for online handwritten Tibetan character recognition[C]//Proceedings of the International Conference on Frontiers in Handwriting Recognition, 2014:317-322.
[13] Ma L L, Wu J. Online handwritten Tibetan syllable recognition based on component segmentation method[C]//Proceedings of the International Conference on Document Analysis amp; Recognition,2015:46-50.
[14] Wang Dahan, Liu Chenglin, Yu Jinlun, et al. CASIA-OLHWDB1: A database of online handwritten Chinese characters[C]//Proceedings of the 10th International Conference on Document Analysis and Recognition, 2009:1206-1210.
[15] Jin L, Gao Y, Liu G, et al. SCUT-COUCH2009-A comprehensive online unconstrained Chinese handwriting database and benchmark evaluation[J]. International Journal on Document Analysis and Recognition,2011,14(1):53-64.

王维兰(1961—),学士,教授,主要研究领域为图像处理与模式识别、智能信息处理与应用软件和藏文信息处理等。
E-mail: wangweilan@xbmu.edu.cn

卢小宝(1984—),硕士,工程师,主要研究领域为图像处理与模式识别、网络数据库。
E-mail:lxb198416@163.com

蔡正琦(1974—),硕士,副教授,主要研究领域为图像处理与模式识别。
E-mail:caizhengqi@126.com
OnlineHandwrittenSampleGeneratedBasedonComponentCombinationforTibetan-Sanskrit
WANG Weilan1, LU Xiaobao2, CAI Zhengqi1, SHEN Wentao1, FU Ji1, CAIKE Zhaxi1
(1. Department of Math and Computer Science,Northwest University for Nationalities, Lanzhou, Gansu 730030, China;2. Baiyin Center Subbranch, People’s Bank of China, Baiyin, Gansu 730900, China)
Tibetan-Sanskrit includes more than 500 Tibetan characters, and more than 6000 Sanskrit. Belonging to the large class of character set, the sample collection of the online handwritten is a large and complex project. We present an online handwriting character sample generation method based on component combination for Tibetan-Sanskrit. The proposed method includes four main parts: (1) to determine the Tibetan-Sanskrit character set and component set; (2) to get location information of Tibetan-Sanskrit characters; (3) to collect online handwritten sample of component set for Tibetan-Sanskrit; and (4) to generate sample database of online handwritten Tibetan-Sanskrit character set. This provides the character's training sample set and test sample set for online handwritten Tibetan-Sanskrit.
online handwritten; Tibetan-Sanskrit; character set; component combination; sample generation
1003-0077(2017)05-0064-10
TP391
A
2016-11-26定稿日期2017-03-17
国家自然科学基金(61375029);国家民委领军人才计划;西北民族大学中央高校基本科研业务费专项资金(31920170142)。
猜你喜欢
建材发展导向(2023年4期)2023-03-14 07:20:48
电子技术与软件工程(2020年12期)2020-02-04 07:12:44
World Journal of Clinical Oncology(2019年5期)2019-08-22 12:13:54
科学与财富(2019年24期)2019-08-06 23:04:37
西域历史语言研究集刊(2018年0期)2018-11-09 01:01:32
西域历史语言研究集刊(2018年0期)2018-11-09 01:01:32
数码世界(2017年4期)2017-04-25 09:41:50
中国医学装备(2017年2期)2017-03-03 05:31:15
制冷技术(2016年4期)2016-08-21 12:40:28
图书馆学刊(2015年8期)2015-12-26 08:33:55
