
蒙古语固定短语识别算法的设计与实现
2017-11-27 09:05:41劳格劳
中文信息学报 2017年5期
斯·劳格劳
(内蒙古大学 蒙古学学院,内蒙古 呼和浩特 010021)
蒙古语固定短语识别算法的设计与实现
斯·劳格劳
(内蒙古大学 蒙古学学院,内蒙古 呼和浩特 010021)
固定短语的自动识别和标注是进行蒙古语文本处理的基础和前提条件。词类标注、短语标注、句法分析、语义分类及语义角色标注等基础研究和机器翻译、文本校对等应用系统的开发均以正确标注固定短语的文本为处理对象。该文在“蒙古语固定短语语法信息词典”的基础上采用基于有限状态自动机和规则的方法设计实现了固定短语识别和标注算法。经实验,其识别率已达到90%以上,在处理中,词均用时与基于字符串匹配的算法相比提高较多,达到0.005 0ms。
蒙古语;固定短语识别;有限状态自动机
1 引言
固定短语的自动识别和标注是蒙古语词法分析、句法分析和语义分析等基础研究的前提,并且在机器翻译、文本校对等应用系统的开发中起着重要作用。
在蒙古语传统语法研究中,对“固定短语”的研究非常少,只有大致分类而鲜有深入细致的研究,尤其是对各类“固定短语”的语法特点很少涉及。
在蒙古语信息处理研究中,内蒙古师范大学青格乐图老师科研团队通过两次国家社科基金项目“蒙古语固定短语语法属性库框架设计”(2002—2003)和“蒙古语固定短语语法信息词典的建立及调试”(2005—2007),完成了各类固定短语语法属性的设置和词语收集工作,词典条目已达到28 000多条。
固定短语的识别应属于词法分析的词切分问题,类型标注应属于词类标注领域。蒙古语属于拼音文字,词切分不像汉语那么复杂,主要依据词间的空格来切分,但这样的切分只能切分为单词,无法识别固定短语。在以往的蒙古语词法分析研究中几乎没有涉及固定短语的识别和标注问题。例如,目前在蒙古文信息处理领域被广泛应用的词语识别及词类标注软件MgLex[1]没有处理固定短语的切分和标注问题。还有文献[2-4]等词法分析或词类标注研究均没有涉及固定短语的切分和类型标注问题。文献[5]中虽然涉及固定短语识别问题,但只局限在命名实体的研究。
现阶段蒙古语词法分析或词类标注系统基本都采用基于统计的方法,而基准语料的缺乏(目前只有100万词词类标注语料)使这些方法在性能和效率上没有大的改进。为了克服基准语料不足的局限性,本文在已有资源——“现代蒙古语固定短语语法信息词典”的基础上采用基于词典和规则的方法实现了蒙古语固定短语识别及标注系统。在效率方面,为了提高查找速度,采用基于有限状态自动机的方法构造了蒙古语固定短语识别算法,最终词典查找速度比基于字符串查找的方法提高较多。经在100万词现代蒙古语语料库上的测试,固定短语召回率达到90%以上,类型标注准确率达到了99%以上。
需要说明的是,名词术语也属于固定短语,但其识别与标注属于人名识别、地名识别和机构名识别等命名实体的识别研究,因此本文所指的固定短语识别没有包含“名词术语”的识别。
2 蒙古语固定短语的定义及分类体系
2.1 蒙古语固定短语的定义
蒙古语固定短语,又叫固定词组,是指基本上由两个或两个以上的词组合而成的在形式和语义上结合紧密,表达一个词汇概念,构成一个词汇单位,充当一个句子成分或某一种附带成分的组合[6]。这个定义包含以下几方面的内容。
(1) 固定短语基本上由两个或两个以上的词组成。组成成分可以是实词,也可以是虚词,或者是附加成分,但其中一个成分必须是实词。
(2) 固定短语在结构形式或语义上结合紧密,一般固定成一个语法单位,像一个词。有些固定短语在语义上固定的,有些在形式上是固定的。
(3) 固定短语作为一个词汇单位,表示一个一般概念。
(4) 固定短语在句子中充当一个句子成分或辅助成分。
2.2 蒙古语固定短语分类体系
蒙古语固定短语分为复合词、习用语、成语、固定词和名词术语五大类[7-8]。固定短语的词类代码用一个大写英文字母表示,小写英文字母表示子类代码,这与“信息技术 信息处理用蒙古语词语标记集”一致,如表1所示。

表1 蒙古语固定短语分类体系
在不包含名词术语的情况下,蒙古语固定短语中复合词的比例占到95%以上,其中复合名词的比例最高,占到80%以上。因此,蒙古语固定短语识别的重点在复合词的识别上。
3 蒙古语固定短语识别及标注算法
基于词典的蒙古语单词识别常用文本-词典的匹配算法,即首先以空格、标点、非蒙文字符等作为边界标示从文本中截取一个字符串,然后在词典中查找,如果找到,则识别成功。但固定短语由两个或两个以上单词构成,并且其长度是变化不定的,用该方法无法实现识别任务。即便使用像中文分词常用的最大正向匹配或最大逆向匹配算法能够实现,但其效率也不高。如果采用词典-文本的匹配算法,可以解决已登录固定短语的识别,即依次读取词典中的词条,然后在文本中进行匹配。但这种算法也存在问题: 首先是识别速度非常慢,其次是对于固定短语的形态变化无法有效识别。
鉴于上述问题,我们在“蒙古语固定短语语法信息词典”和“变形附加成分词典”的基础上采用有限状态自动机的方法构造了固定短语识别器[9-14]。识别器由固定短语自动机(fixed phrase automata,FPA)和构形附加成分自动机(formation suffix automata,FSA)两部分构成。蒙古语具有丰富的形态变化,尤其是动词的形态变化非常多,有些词的形态变化甚至能达到几百种。因此,词典中一般只包含词干形式,形态变化的识别需要相应的附加成分词典。在识别字符串的过程中,如果词根自动机中没有状态转移,则回溯到最近的词根状态,并转移到附加成分自动机,继续进行识别。由于存在词根回溯的问题,FPA和FSA是一种不确定有限状态自动机。但词根回溯只在识别已登录固定短语形态变化形式时出现,因此可以认为该自动机是一种带词根回溯的确定有限状态自动机。
3.1 固定短语识别器的构造
在构造上,FPA和FSA完全一样,均为9元组, 形式如下:
FPA = FSA = (S,∑,δ,suffix,recall,stack,s0,U,F),
其中:S为有限的状态集合,∑为有限的输入字符集合,δ为状态转移函数,suffix为从固定短语词根自动机到附加成分自动机的状态转移函数,recall为词根回溯函数,stack为词根栈,s0为初始状态,U为词根状态集合,F为终结状态集合。FPA和FSA均为不确定有限状态自动机,但除词根回溯,状态转移都是确定的。
(1)S= {s0,s1,s2,…,sn-1,sn},包括初始状态s0、词根状态U、终结状态F。
(3)δ(si, ch)=sj(si∈S,sj∈S,ch∈∑),当sj∈U时,Push(sj,stack)。
(4) suffix(ci)=s0(ci∈U,s0∈FSA)
(5) recall (si)=sj(si∈S,si∈U,sj= Pop(stack))。
(6) stack为词根栈。保存每次固定短语识别过程中遇到的词根状态。
(7)s0∈S。

(9)F⊆S。
自动机的构造如图1、图2所示。
说明1图1中,s0、s1、s2、s3、si、si+1、si+2、sj、sj+1、sj+2、sk、sk+1、sk+2、sl、sl+1、sl+2、sm、sm+1、sm+2、sn、sn+1、sn+2表示状态,其中,s0为初始状态,纵向箭头表示指向孩子节点的指针,横向箭头表示指向兄弟节点的指针,“…”表示未画出的孩子节点和兄弟节点。每个节点可以有有限多个孩子节点,但为了构造上的方便,只设了一个Child指针,其余孩子节点作为第一个孩子节点的兄弟节点通过NextBrother与之相连。如果一个节点有n个孩子节点,那么构造自动机时,设n个Child指针和设一个Child指针、n-1个NextBrother指针在识别效率上是等价的。
说明2图2中,Char表示状态字符,Type表示词根节点中存放的固定短语类型代码,Stem表示词根字符串(固定短语),Child表示指向孩子节点的指针,NextBrother表示指向兄弟节点的指针。由于除词根回溯之外,FPA或FSA中状态转移是确定的,因此在节点结构中没有设Parent和PrevBrother指针。
3.2 固定短语识别算法
算法描述如下:

图1 FPA和FSA的状态转移图
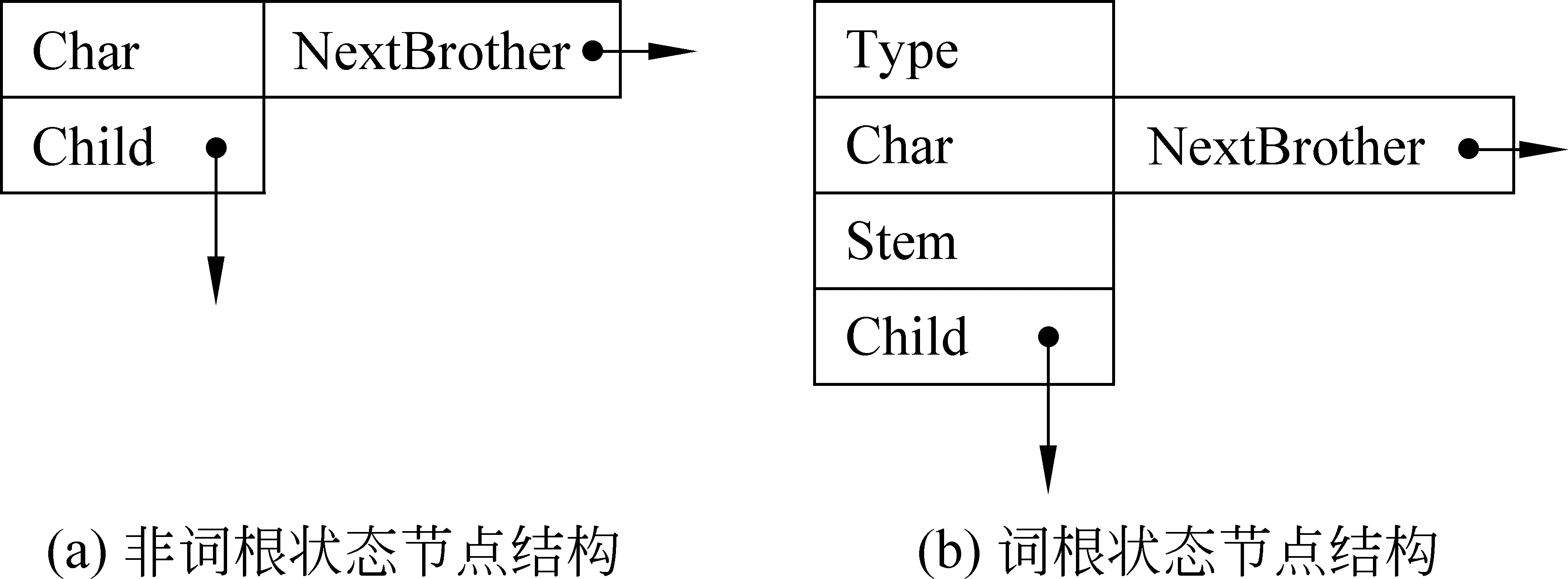
图2 状态节点结构
step1将文本输入给FPA(FSA)进行识别,如果在状态转移过程中遇到词根状态,则压入词根栈。
step2如果无法进行状态转移,则查看当前输入字符是否为“空格”,如果“是”,则转到step3,否则转到step4;
step3如果当前状态为词根状态,则找到固定短语,并进行标注,然后将当前状态设为FPAs0,并转到step1;否则直接将当前状态设为FPAs0,并转到step1;
step4如果词根栈不为空,则弹出并回溯到栈顶状态,然后通过Suffix函数转移到状态FSAs0,转到step1;否则转到step5;
step5将输入字符移到下一个空格,当前状态设为FPAs0,并转到step1;
具体实现过程如算法1所示。


3.3 固定短语识别实例
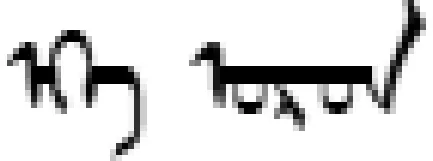
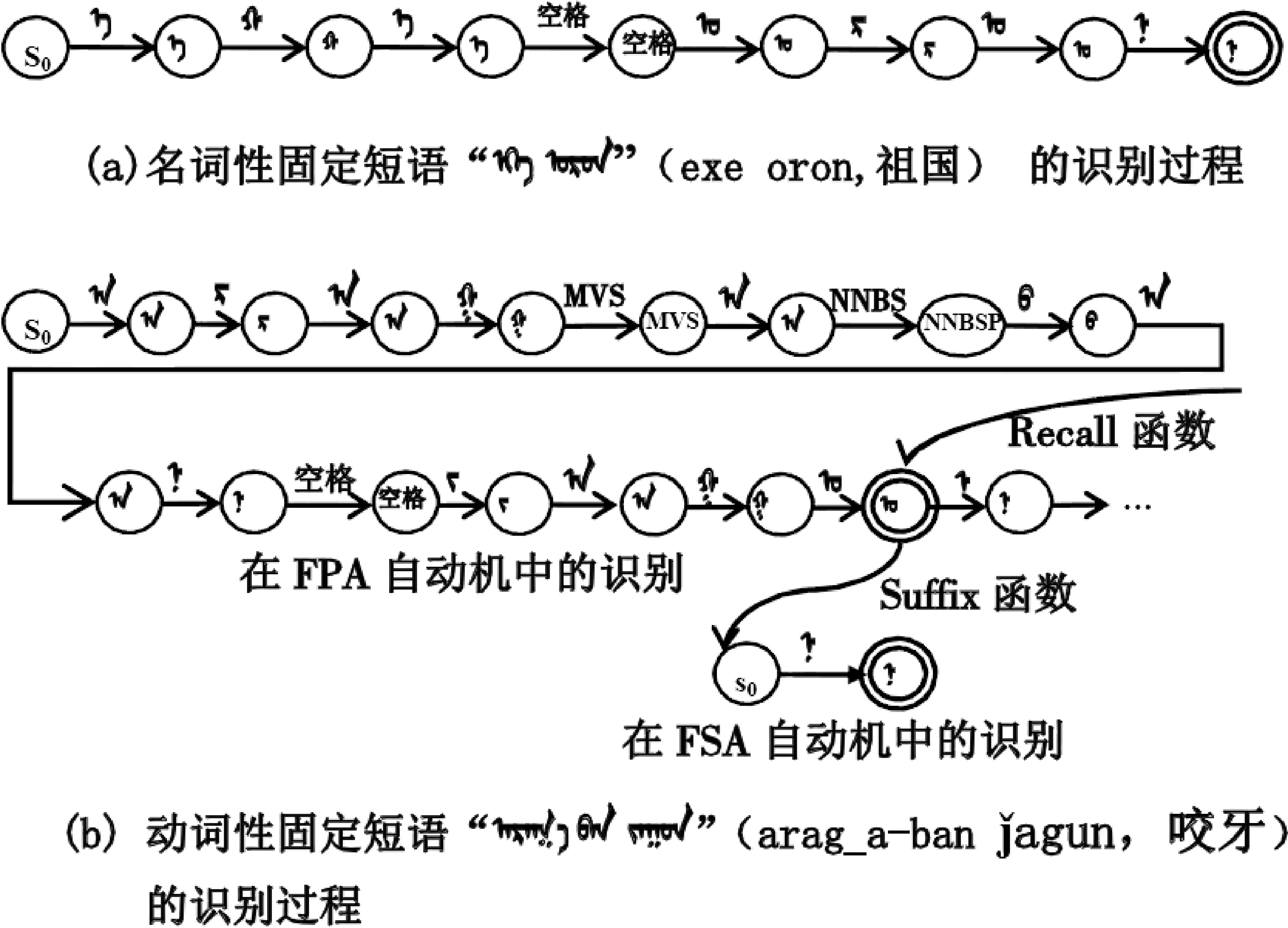
图3 固定短语识别过程状态转移图
说明: 图3中,圆圈表示状态,双线圈表示词根状态,圆圈里的字符表示状态字符,横向箭头表示一次状态转移(调用step函数),箭头上方的字符为输入字符。
3.4 未登录固定短语的识别

上述三种复合词的一部分已被收录到词典里,但不全,对于未登录的部分根据其构词规则归纳总结了相应的识别规则。在识别顺序上先用词典识别,再对结果文本进行第二次扫描,处理具有规律性的复合词。
3.5 算法的系统实现
我们用Visual C++7.1实现了蒙古语固定短语识别及标注算法[15-16],并将程序模块添加到了蒙古语多功能编辑处理系统Mongolian Editor 4.0中,软件界面如图4所示,图中用“=”连接的为固定短语。
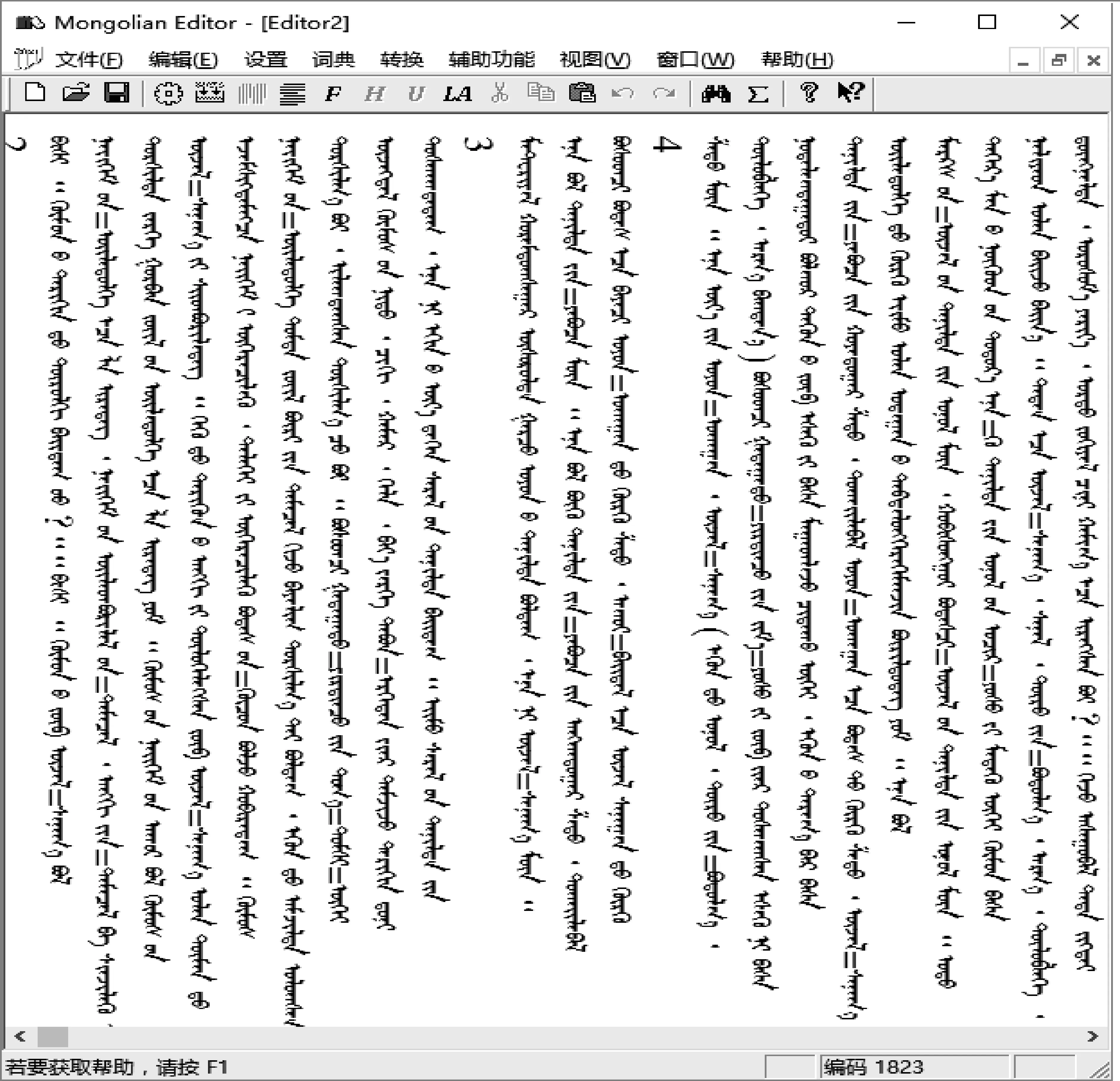
图4 蒙古语固定短语识别软件界面
4 结论

本算法的一个主要特点是,在固定短语识别中运用了有限状态自动机,其目的是为了克服字符串匹配算法中的时间消耗,提高算法的运行效率。因此,在试验中增加了衡量算法运行速度的指标T。程序运行时,算法对输入文本进行全文扫描,如果有固定短语则对其进行识别和标注。运行效率与文本长度和文本所含固定短语个数有关,而与固定短语词典大小无关,因此计算T时采用了式(2)。
目前,还没有标注固定短语的蒙古语基准语料,因此,我们先用人工标注的方法对测试语料添加了固定短语标记。测试时,首先从测试语料副本中去掉固定短语标记,然后采用识别和标注算法对文本进行标注。最后通过集成在固定短语标注软件中的评价函数对人工标注和自动标注结果进行对比,得到测试结果。测试结果如表2所示。
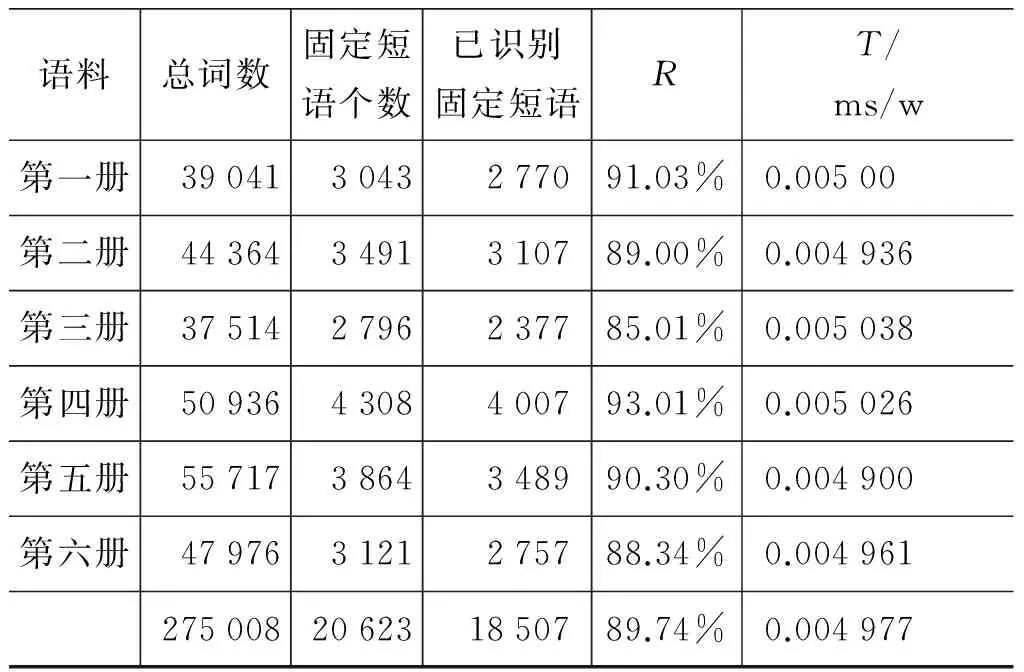
表2 实验结果
经测试发现,算法性能和效率已达到预期目标。但识别率还有待提高,需要通过人工或半自动方式从大规模文本语料中收集固定短语。我们正在构建蒙古语词语搭配网络,在该网络上采用无监督的机器学习方法可以发现一部分出现频率较高的固定短语,但出现频率较低的固定短语则需要通过人工方式进行收集。
顾名思义,固定短语是词语的一种固定的搭配形式,在蒙古语中,除形态上的变化外,其数量是有限的。因此,采用基于词典的方法进行识别和标注是最有效的。经过长期收集,固定短语词条数目目前已达到3万余词,基本上包含了90%以上的蒙古语固定短语,但覆盖率还不够高,今后还需要通过人工或半自动方式收集词条,扩充“蒙古与固定短语语法信息词典”,提高识别算法的召回率。
目前,蒙古语词法分析研究主要集中在词根词缀切分、单词识别和人名识别等领域,而复合词、习用语、成语、固定词、地名、机构名等多词单元的识别标注还处于空白状态。此外,蒙古语固定短语与单词一样具有丰富的形态变化(包括名词附加成分和动词附加成分),其他语种固定短语识别技术与蒙古语相应技术具有明显的差别,因此,在这里尚未做有关方法的对比分析。
本文介绍的基于不确定有限状态自动机的方法除了对固定短语的识别外,对蒙古语词根/词缀的切分、读音纠错、词类标注等基于词典的算法具有广泛的适应性,其主要特点是运行效率高,适合实时文本处理。
[1] 吴金星. 蒙古语词法标注语料库的构建及相关技术研究[D].内蒙古大学硕士学位论文,2011.
[2] 华沙宝.蒙古语语料库的词类标注系统——AYIMAG[J].内蒙古大学学报(人文社会科学版),1999,31(5):31-35.
[3] 张贯虹,斯·劳格劳,乌达巴拉. 融合形态特征的最大熵蒙古文词性标注模型[J].计算机研究与发展,2011,48(12): 2385-2390.
[4] 王斯日古楞. 蒙古语单词词性自动识别研究[J].内蒙古师范大学学报(自然科学汉文版),2007,36(3):319-321.
[5] 吴金星. 蒙古语语料库加工集成平台的构建[D],内蒙古大学博士学位论文,2015.
[6] 德·青格乐图. 现代蒙古语固定短语语法信息词典详解[M]. 呼和浩特: 内蒙古教育出版社,2005.
[7] 德·青格乐图. 面向信息处理的蒙古语固定词组研究[M].呼和浩特: 内蒙古教育出版社,2001.
[8] 德·青格乐图. 面向信息处理的蒙古语固定词组分类[J].内蒙古师范大学学报(哲学社会科学蒙文版),2000(3): 120-128.
[9] 斯·劳格劳. 基于不确定有限自动机的蒙古文校对算法[J].中文信息学报,2009,23(6): 110-115.
[10] 姜文斌,吴金星,乌日力嘎,等. 蒙古语有向图形态分析器的判别式词干词缀切分[J].中文信息学报, 2011,25(4): 30-34.
[11] Yael Cohen-Sygal. Finite-state registered automata for non-concatenative morphology[C]//Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics. Australia: Association for Computational Linguistics, 2006, 681-688.
[12] Yona S, Shuly Wintner. A fnite-state morphological grammar of Hebrew[J]. Natural Language Engineering, 2008,14(2): 173-190.
[13] Koskenniemi K. Two-level morphology: a general computational model for word-form recognition and production. The Department of General Linguistics, University of Helsinki, PUBLICATION, 1983(11).
[14] Kay M. Non-concatenative fnite-state morphology[C]//Proceedings of the Third Conference of the European Chapter of the Association for Computational Linguistics, Cpenhagen, Denmark, 1987: 2-10.
[15] Zoltán Juhász,dám Sipos , Implementation of anite state machine with active libraries in C++[C]//Proceedings of the 7th International Conference on Applied Informatics Eger, Hungary, 2007(2): 247-255.
[16] 阿孜古丽·夏力甫,早克热·卡德尔,吐尔根·依布拉音. 维吾尔语动词体范畴的有限状态自动机的构建[J]. 中文信息学报, 2012,26(4): 61-65.

斯·劳格劳(1972—),博士,副教授,主要研究领域为蒙古文信息处理。
E-mail: sloglo@sina.com
DesignandImplementationofMongolianFixedPhraseRecognitionAlgorithm
S Loglo
(College of Mongolian Studies, Inner Mongolia University, Hohhot,Inner Mongolia 010021,China )
Automatic identification and annotation of fixed phrases are esseential to the Mongolian text processing. On the basis of “Mongolian Fixed Phrase Grammatical Information Dictionary”, this paper designs and implements an algorithm for Mongolian fixed phrase recognition and labeling based on finite state automata and rules. Experiments reavel an recognition rate of more than 90%, and an average processing speed of 0.005 millisecond per word.
Mongolian language; fixed phrase recognition; finite state automata
1003-0077(2017)05-0085-07
TP391
A
2016-03-16定稿日期2017-04-26
国家自然科学基金(61662050);国家自然科学基金(61262046);国家社科基金(10CYY022);内蒙古大学高层次人才引进项目
猜你喜欢
西部蒙古论坛(2022年2期)2022-07-12 04:47:38
数学物理学报(2021年3期)2021-07-19 06:02:50
蒙古学问题与争论(2020年0期)2020-03-29 06:26:58
新世纪智能(英语备考)(2019年10期)2019-12-16 09:07:54
智富时代(2019年4期)2019-06-01 07:35:00
广东蚕业(2019年3期)2019-05-14 05:37:40
新世纪智能(语文备考)(2019年3期)2019-01-12 09:08:10
赤峰学院学报(蒙文哲学社会科学版)(2018年1期)2018-04-25 07:57:25
西北大学学报(自然科学版)(2018年2期)2018-04-18 06:53:55
卫拉特研究(2016年0期)2016-12-06 09:12:06
