
基于WMD距离与近邻传播的新闻评论聚类
2017-11-27 09:05:26官赛萍靳小龙徐学可伍大勇贾岩涛王元卓
中文信息学报 2017年5期
官赛萍,靳小龙,徐学可,伍大勇,贾岩涛,王元卓,刘 悦
(1. 中国科学院计算技术研究所 中国科学院网络数据科学与技术重点实验室,北京 100190;2. 中国科学院大学 计算机与控制学院,北京 100049)
基于WMD距离与近邻传播的新闻评论聚类
官赛萍1,2,靳小龙1,2,徐学可1,2,伍大勇1,2,贾岩涛1,2,王元卓1,2,刘 悦1,2
(1. 中国科学院计算技术研究所 中国科学院网络数据科学与技术重点实验室,北京 100190;2. 中国科学院大学 计算机与控制学院,北京 100049)
随着新闻网站的快速发展,网络新闻和评论数据激增,给人们带来了大量有价值的信息。新闻让人们了解发生在国内外的时事,而评论则体现了人们对事件的观点和看法,这对舆情分析和新闻评论推荐等应用很重要。然而,新闻评论数据又多又杂,而且通常比较简短,因此难以快速直观地从中发现评论者的关注点所在。为此,该文提出一种面向新闻评论的聚类方法EWMD-AP,用以自动挖掘社会大众对事件的关注点。该方法利用强化了权重向量的Word Mover’s Distance(WMD)计算评论之间的距离,进而用Affinity Propagation(AP)对评论进行聚类,从杂乱的新闻评论中得到关注点簇及其代表性评论。特别地,该文提出利用强化权重向量替代传统WMD中的词频权重向量。而强化权重由三部分组成,包括结合词性特征与文本表达特征的词重要度系数、新闻正文作为评论背景的去背景化系数和TFIDF系数。在24个新闻评论数据集上的对比实验表明,EWMD-AP相比Kmeans和Mean Shift等传统聚类算法以及Density Peaks等当前最新算法都具有更好的新闻评论聚类效果。
新闻评论聚类;强化权重向量;去背景化;Word Mover’s Distance;近邻传播
1 引言
互联网的快速发展使得各个领域的网络信息和用户评论迅速增长。用户评论中蕴含大量用户的看法和观点,这对各个领域来说都是很有价值的信息。譬如,对服务行业来说,用户评论既是用户做决策的重要参考,又是商家提升服务质量和用户体验的重要依据。对社交网络来说,用户评论可以用于代表性评论选择、话题检测和观点抽取等;对新闻来说,对用户评论的分析既可以让有关机构了解人们对新闻主体的关注点所在,又可以优化新闻推荐,针对特色需求,进行个性化推荐。因此,从大量评论数据中挖掘上述信息具有重要的研究意义和应用价值。近年来,服务行业网站(如购物网站、酒店等)与社交网络的评论等已受到广泛关注。
对于服务行业的评论,Hai等[1]提出联合属性和情感的有监督模型,在商品级和细粒度的商品属性级选择最有用的评论,这有助于顾客做出购买决策,同时有助于商家提升商品质量和服务。Dayan等[2]提出一种基于文本评论抽取特性信息的方法。该方法采用权重机制进行两轮迭代: 第一轮将提供相似食物类别的酒店聚在一起,第二轮在此基础上去除簇中的共同项,找出各酒店的特性,发现酒店之间有意思的关联。酒店评论网站可以根据这些特性提供个性化服务。Zhou等[3]提出一种表达学习方法,通过词向量上的神经网络得到深层和混合的特征,识别给定酒店评论讨论的主题,包括环境、食物、价格等。
对于社交网络的评论,Nguyen等[4-5]利用详细冗长的全文本评论和简短集中的微博评论寻找有效覆盖微博评论的全文本评论子集。整个过程包含两步: 第一步匹配全文本评论句子和微博评论,第二步选择覆盖尽可能多的微博评论,以及句子数少的全文本评论子集。Chong等[6]设计了一个话题模型SAMR(sparse additive micro-review),发现地点相关的微博评论话题,最终得到意想不到的微博评论,帮助业主进行事件发现、管理顾客关系、提升服务和识别竞争对象等。Lu等[7]提出基于LDA(latent dirichlet allocation)的概率模型,从用户到新地点的微博评论中抽取话题,进而在帮助其他用户做决策的同时,还能帮助业主个性化用户体验。
尽管目前已有大量针对服务行业网站和社交网络评论的研究,但还没有针对新闻评论的研究工作。而相比于服务行业评论,社交网络评论和新闻评论更加多元化。服务行业评论关注质量、价格、服务等相对比较有限的属性,而社交网络评论和新闻评论的关注点比较多样化,数据本身也没有明确的属性特征。但新闻评论又不同于社交网络评论,社交网络存在明确的用户关系(如朋友关系、关注关系等),这些用户关系在评论中常常有很好的体现。而在新闻评论中不存在显式的用户关系,所以文本信息成为最主要的分析依据。由于新闻评论具有自身的特点,所以现有针对服务行业网站与社交网络评论进行聚类的方法,不适用于新闻评论的聚类。
对于新闻评论,在杂乱的文本信息中,识别评论的关注点,可以更便捷地了解评论者的意见,提取有价值的信息。因此本文提出一种面向新闻评论聚类的方法EWMD-AP。该方法基于强化权重的Word Mover’s Distance(WMD)[8]来计算评论之间的距离,用近邻传播(affinity propagation,AP)算法[9]对新闻评论进行聚类。其中,WMD距离通过计算从一个文档表达到另一个文档表达所需要的最小代价得到。本文利用词性特征和文本表达特征制定规则得到词的重要度系数,由新闻正文信息得到去背景化系数,再结合TFIDF系数组成强化权重向量,有效计算评论文本之间的距离。进一步,通过将距离转化为相似度,再采用AP算法进行聚类最终得到评论关注点簇及各自的代表性评论。在人工标注的24个新闻评论数据集上的对比实验表明,EWMD-AP相比Kmeans和Mean Shift等传统聚类算法及Density Peaks等当前最新算法都具有更好的新闻评论聚类效果。
接下来本文将按以下展开,第二节描述本文的相关工作,第三节描述EWMD-AP方法,第四节展示实验及评估结果,第五节对全文进行总结及展望。
2 相关工作
本文针对还没有挖掘新闻评论关注点研究的现状,对新闻评论关注点进行聚类,相关工作主要包括文本表达、文档相似度计算和文档聚类。
文本表达最直观的是One-Hot词向量,这种表达方式非常稀疏,不考虑语义信息,存在“语义鸿沟”问题。因此将语义信息融入文本表达成为关注重点。Harris提出分布假说: 上下文相似的词,词义相似[10]。Hinton提出分布式词向量,引入词间距离概念,相似的词距离上更接近[11]。基于分布式表达的方法,从方法思路看发展为三类,基于聚类、基于统计信息和基于神经网络的分布式表达。目前这三类的代表性方法分别为: 布朗聚类、Global Vectors(Glove)和Word2vec。Brown等[12]提出布朗聚类,通过多层类别体系构建词与上下文的关系,根据词的公共类别层级判断语义相似度。Pennington等[13]提出Glove,Glove是基于计数的模型,引入了全局统计信息,通过维规约词共现矩阵,最小化重构误差建模得到词表达。Mikolov等[14-15]提出Word2vec,用一个浅层神经网络语言模型学习词的向量表达。在大规模数据集上训练的能力使得模型可以学习复杂的词间关系。
文档相似度计算基于词的相似度或距离进行。田堃等[16]通过语义角色标注、语义角色分析、标注句型的相似匹配、标注句型间相似度计算等步骤,以动词为分析核心,实现汉语句子的相似度计算。这一系列的步骤过于复杂,容易造成级联误差,即中间某个步骤的错误将传递到后续步骤,导致结果的严重错误。更直观、简单的方法是将文档表达为向量,通过向量相似度计算方法得到文档相似度。这种方法没有考虑单个词之间的语义相似度。如何通过词间语义相似度有效计算文档相似度?从模型结构看,目前代表性研究大致分为基于图、基于神经网络和基于词权重转移三类。Wang等[17]提出KnowSim,表达文档为类型异构信息网络,将文档相似度问题转化为图距离问题。该方法依赖外部实体、关系知识库。詹志建和杨小平[18]提出构建短文本的复杂网络模型,选取复杂网络特征,将短文本建模为特征向量,基于词语之间的相似度得到短文本之间的相似度。该方法容易受选取的特征的影响。Sun等[19]基于神经网络建立词向量模型,通过特征词的语义相似度计算文本语义相似度。该方法计算文档相似度时只考虑特征词,忽略了其他词。Kusner等[8]提出一种新的文档距离计算算法: WMD。该算法基于Word2vec词嵌入,表达文档为标准词袋向量,定义词权重,通过最小化词权重转移量和词间转移代价乘积的加和得到文档转移的最小代价,由此衡量文档距离。WMD是Earth Mover’s Distance(EMD)[20]的一个特例,EMD计算两个签名(分布)的距离,签名由特征量和权重表达。EMD主要用于图像处理等领域,而Kusner等巧妙地将EMD应用于文档距离提出WMD。
文档聚类在文本表达和相似度计算的基础上进行。早在1967年,MacQueen就提出了Kmeans算法[21],每个类别用该类中对象的平均值表示。Kmeans是仅支持球类聚类的基本聚类算法。对于非球类聚类,Comaniciu等[22]提出Mean Shift,它是基于核密度估计的爬山算法,适用于聚类数较多,簇样本大小不均匀的场景。从建模角度看,目前代表性研究大致分为基于空间分布、基于神经网络和基于信息传播三类。Rodriguez和Laio[23]提出Density Peaks聚类算法,假设同一类别的样本距离比较近,而且与其他类别的样本距离比较远,选取比邻居样本密度高同时与其他高密度样本距离比较远的样本作为聚类中心,其他样本根据选定的聚类中心指定簇。Density Peaks算法只需要计算数据点对之间的距离,不需要参数化一个概率分布。但该算法需要手动选择聚类中心。蒋旦等[24]提出基于语义和完全子图的短文本聚类算法。该算法将文档表示成节点,距离小于阈值的文档之间连边,同时距离作为边的权值构建图,然后不断从图中提取团(完全子图)作为自然簇。该算法基于图操作完成聚类,计算复杂。Xie等[25]提出DEC(deep embedded clustering),用深度神经网络学习特征表达和聚类。DEC学习从数据空间到更低维特征空间的映射,在特征空间中迭代优化聚类目标。该方法需要选定初始聚类中心和优化参数。Frey和Dueck[9]提出AP近邻传播聚类算法。AP是一种通过样本间消息传播不断迭代更新直至收敛的算法,最终数据集用少量的聚类中心样本表示,这些样本被认为最具代表性。AP算法不需要提供初值,不关注数据分布,可以处理非欧拉分布的数据集,允许各种相似度度量方法。
3 EWMD-AP方法
针对新闻评论多样化的特性,本文提出EWMD-AP新闻评论聚类方法,挖掘评论关注点。通过用强化权重向量替代传统WMD的词频权重向量,将词的“主体性”信息嵌入距离计算。进一步,用1减去WMD距离得到相似度,再采用AP算法进行新闻评论聚类,最终得到评论关注点簇及其代表性评论。
3.1 WMD算法及强化权重向量
本文基于新闻评论关注点聚类的目标,在原始WMD算法的基础上,制定新的权重机制,用强化权重向量替代传统WMD的词频权重向量。
3.1.1 WMD算法
WMD是计算文档间距离的算法,它通过文档表达的最小转移代价衡量文档之间的距离。这其中词间转移代价和权重转移量是文档表达转移的关键。词间转移代价用Word2vec嵌入空间的欧式距离度量,由此引入词间语义相似度。每个词可转移的总权重转移量为词的权重,由此引入词在文档中的贡献信息。算法中权重用词频度量。
令D和D′为分别有m和n个词的两个文本文档的标准词袋向量表达,文档D和D′之间的距离定义如下[8]:
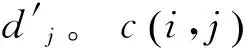
算法通过最小化文档表达D转移到文档表达D′的累积代价得到文档之间的距离。最小化文档表达转移代价是一个双向的过程,既要求D到D′的转移代价最小,又要求D′到D的转移代价最小。
本文的词间转移代价用1减去归一化Cosine相似度计算。
3.1.2 强化权重向量
Kusner等[8]在流量转移的过程中,对词的权重只考虑了词频,所有词同等对待,没有考虑不同词的贡献差别。显然,不同词对句子的贡献度不同。因此本文引入强化权重向量,包含三部分: 结合词性特征和文本表达特征的词重要度系数、参考新闻正文提取的去背景化系数及TFIDF系数。强化权重向量同时考虑词的数量特征和质量特征,引入了词的“主体性”信息。
根据本文评论关注点聚类的宗旨,将与主体相关联的词赋予更高的权重,这里的主体又包括事物和人物两大方面。因此某些与事物相关的名词、与人物相关的人名等具有更高的贡献度,而普通名词和其他词贡献度较低。本文根据词性及评论文本表达的特点,设置了四级优先级规则,优先级别、词t在评论D中的重要度系数It,D及规则如表1所示。
通常人们总是希望评论中的每个词都是最重要的词,不存在其他词,这样可以方便地直接利用评论进行各种应用,因此优先级最高的词重要度系数设为评论的有效长度,其他级别的词重要度系数根据经验设置,如表1所示,这里只是一个比例值,最终的权重将进行归一化。
计算词的权重时,将新闻正文看成评论短文本的扩展内容,赋予出现在正文中的词较低的权重,一方面利用了正文信息,另一方面在一定程度上去背景化,词t的去背景化系数αt定义如式(2)所示:
其中C1、C2、C3分别对应正文的1级、2级和3级优先级词集合。
由于新闻评论针对正文内容展开,评论中往往包含正文中重要度系数大的词,在正文这一大背景下,聚类效果受到很大影响。因此对于评论聚类,降低在正文中出现的重要度系数大的词的权重很有必要,一定程度上去背景化。在正文中出现的优先级越高的词,去背景化系数取值相对地越小,意味着它在评论中重要度相对地降低,实验中按式(2)进行设置。式(2)中的取值是一个经验性的比例关系。
计算词的TFIDF系数时,由于不同新闻主题的评论用词差异比较大,不适合用一个整体语料库计算词的权重,因此词的TFIDF系数基于该篇新闻的所有评论。计算时,不考虑正文,将每条新闻评论看成一篇文档。文档D中词t的TFIDF系数如式(3)所示:
词t在文档D中的权重wft,D采用式(4)进行计算:
其中tft,D表示词t在文档D中的词频率。
词t的逆文档频率idft采用式(5)进行计算:
其中N表示文档数目,dft表示词t的文档频率。
参考TFIDF的定义(如式(3)所示),本文的强化权重由词重要度系数、去背景化系数与TFIDF系数三者相乘得到。形式化地,词t在文档D中的强化权重Wt,D如式(6)所示。
3.2 EWMD-AP新闻评论聚类
本文提出的EWMD-AP方法基于强化权重向量的WMD计算新闻评论之间的距离,通过AP算法进行新闻评论聚类。用归一化的强化权重向量替代单独的归一化词频权重向量,通过WMD算法得到新闻评论之间的距离。AP是基于信息传播的文本聚类算法。将新闻评论看作网络节点,通过网络节点的信息传播不断迭代更新直至收敛,得到各新闻评论的聚类中心。传播的信息有两种: responsibilityr(i,k)——新闻评论k为新闻评论i的聚类中心的累积置信度;availabilitya(i,k)——新闻评论i选择新闻评论k为聚类中心的累积置信度。因此新闻评论被选为聚类中心需同时满足两个条件: 与许多新闻评论足够相似,被许多新闻评论选为代表。r(i,k)和a(i,k)的计算公式如式(7)所示。
其中s(i,k)是新闻评论i和新闻评论k的相似度,它通过1减去WMD距离得到。AP算法的两个重要参数是偏向参数和阻尼系数,前者控制了聚类数,默认选取新闻评论相似度的中值,后者控制算法的收敛速度。算法输入为新闻评论之间的两两相似度,不关注评论数据的分布情况。
WMD基于词间转移距离计算评论之间的距离,很容易嵌入词的权重信息,加大重要词的权重,使得得到的评论距离更好地体现语义距离。并且AP算法基于评论之间的信息传播聚类,评论之间传递信息,很好地进行语义“交互”,使得聚类更好地考虑语义信息,得到理想的聚类结果。
4 实验及评估
4.1 数据集
原始数据集为各大中文新闻网站2015年4月12日至2016年1月18日随机爬取的一批新闻及评论数据。在原始数据集的基础上进行筛选,剔除全标点、全英文的评论后选出评论字数大于等于10个字、合并文字完全相同的评论为一条评论后评论数超过100条的新闻。字数过少的评论一方面可能是评论者随意评论,如“呵呵。。。”等,另一方面字数过少的评论价值不高,不能很好地代表评论者的意见,因此本文过滤评论长度小于10个字的评论。将得到的新闻及评论数据进行繁简转换。在这些预处理后的新闻及评论中,选取四大中文新闻网站: 网易新闻网、新浪新闻网、腾讯新闻网和凤凰新闻网各六条新闻的评论共24个数据集进行人工标注,标注的评论数达5 989条,内容涉及政治、政策、生活、娱乐、体育、旅游、交通、气候、医疗、科研等方面,每条新闻的评论数从155到386不等。
替换评论中的表情符为汉字后用NLP分词,根据词性去除助词、介词、量词,得到有效词。NLP分词把一些单字副词和紧接着的动词/形容词分成了两个词,本文将它们合并成一个有效词。
为了将有效词映射到向量空间,需要进行词向量学习,本文结合中文维基百科数据和搜狗全网新闻数据进行训练,互为补充,同时在实验中添加缺少的数据信息。实验中分别训练Word2vec、Glove模型,得到有效词400维的词向量。
4.2 评估标准
本文采用两个指标评估聚类结果,一个是同质性(纯度)指标和完整性指标的调和平均V-measure,另一个是标准互信息NMI。
同质性(homogeneity)衡量每个簇只包含单一类别成员的程度,完整性(completeness)则衡量一个给定类的所有成员分配到单一簇的程度。形式地有:
其中H(C|K)是给定簇,类的条件熵:
H(C)是类的熵:
这里n是样本总数,nc和nk分别表示属于类c和簇k的样本数,nc,k为类c中的样本分配给簇k的数量。
给定类,簇的条件熵H(K|C)及簇的熵H(K)定义类似。
Vmeasure为同质性和完整性指标的调和平均:
标准互信息衡量预测标签和标注标签的一致程度,是一种能在聚类质量和簇数目之间维持均衡的指标,假定n个样本的两组标签为U和V,U和V的标准互信息定义如下:
其中MI是互信息:
H(U)和H(V)分别是U和V的熵:
H(V)的定义类似。其中P(i)=|Ui|/n表示从U中随机选择的样本落在类Ui的概率,P′(j)定义类似。P(i,j)=|Ui∩Vj|/n表示随机选择的样本同时落在类Ui和Vj的概率。
4.3 实验设置及结果评估
本文提出的面向新闻评论的聚类方法EWMD-AP由三个主要部分组成: AP聚类、WMD距离和强化权重,为了说明EWMD-AP方法的有效性,本文设置三组对比实验,依次替换三个组成部分,分别用于比较不同聚类方法,比较不同相似度度量及不同权重组成方法。本节将展示三组对比实验的实验设置及实验结果,并列举两个聚类实例。
4.3.1 不同聚类方法对比实验
该组实验涉及的方法及说明如表2所示。其中涉及评论向量表达的方法,如Kmeans和Mean Shift,每条评论的向量表达通过评论中每个有效词的400维词向量和对应的强化权重的乘积加和得到。对于Density Peaks算法,参考Zhang等[26]给出的参数的设置,通过参数调优设置距离阈值为0.36。
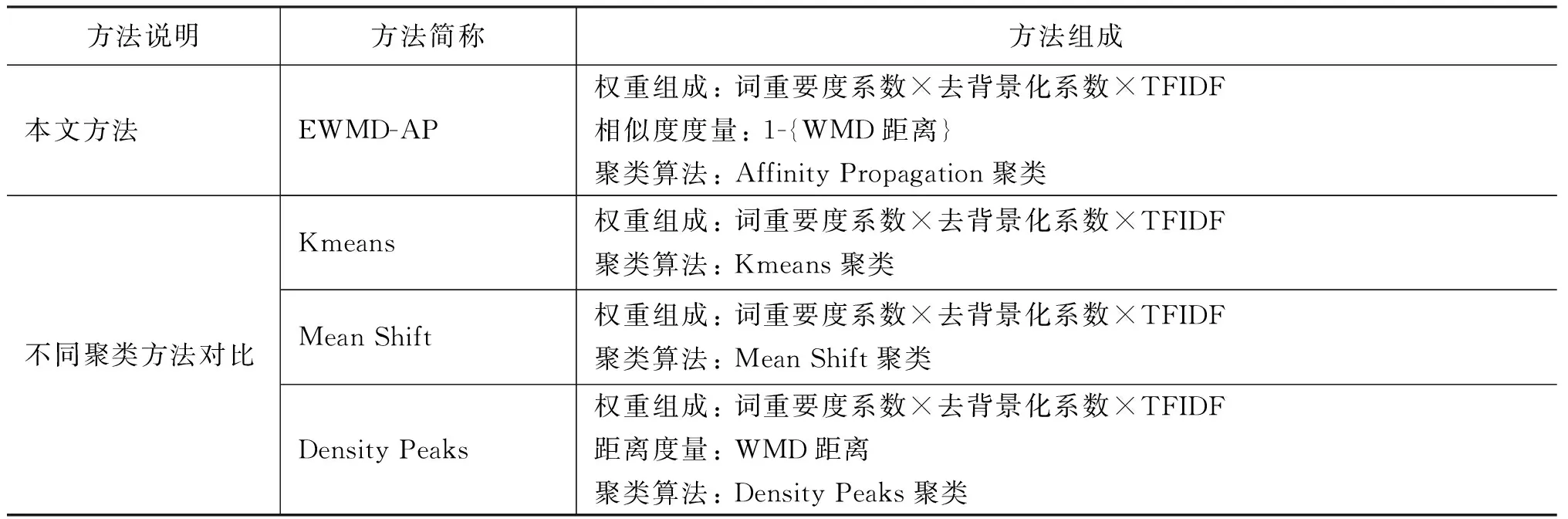
表2 不同聚类方法说明及简称
各聚类方法在24个数据集上Vmeasure和NMI指标的均值与方差结果如图1所示。图(a)为Vmeasure指标结果,图(b)为NMI指标结果。
图1 不同聚类方法的Vmeasure和NMI均值与方差
从图1中可以看出本文EWMD-AP方法在Vmeasure和NMI指标上均表现最优。同样基于强化权重,EWMD-AP优于传统的Kmeans和Mean Shift等算法,以及Density Peaks等当前最新算法。各方法的方差很小,说明各方法的稳定性较好。针对本文的新闻评论数据集,除了Density Peaks方法Glove词表达的结果略优于Word2vec词表达的结果,其他方法Word2vec词表达的结果比Glove更优,说明本文的数据集更适合采用Word2vec词表达。这可能是因为新闻评论之间往往没有明显的关系,较为独立,因此引入全局统计信息的Glove不一定能优化结果,反而甚至对结果造成影响。
4.3.2 不同相似度度量对比实验
该组实验通过替换本文EWMD-AP方法中的相似度度量: 1减去WMD距离构造对比方法。对比方法的相似度度量分别为负的平方欧式距离和归一化Cosine相似度,分别记为Euclidean-AP和Cosine-AP。
各相似度度量在24个数据集上Vmeasure和NMI指标的均值与方差结果如图2所示。图(a)为Vmeasure指标结果,子图(b)为NMI指标结果。
从图2中可以看出各方法比较稳定,同样Word2vec词表达优于Glove词表达。EWMD-AP方法在两个指标上均取得最大值,表明WMD距离算法优于传统的欧式距离和Cosine计算方法,WMD与AP结合有效地提高了聚类质量。
4.3.3 不同权重组成对比实验
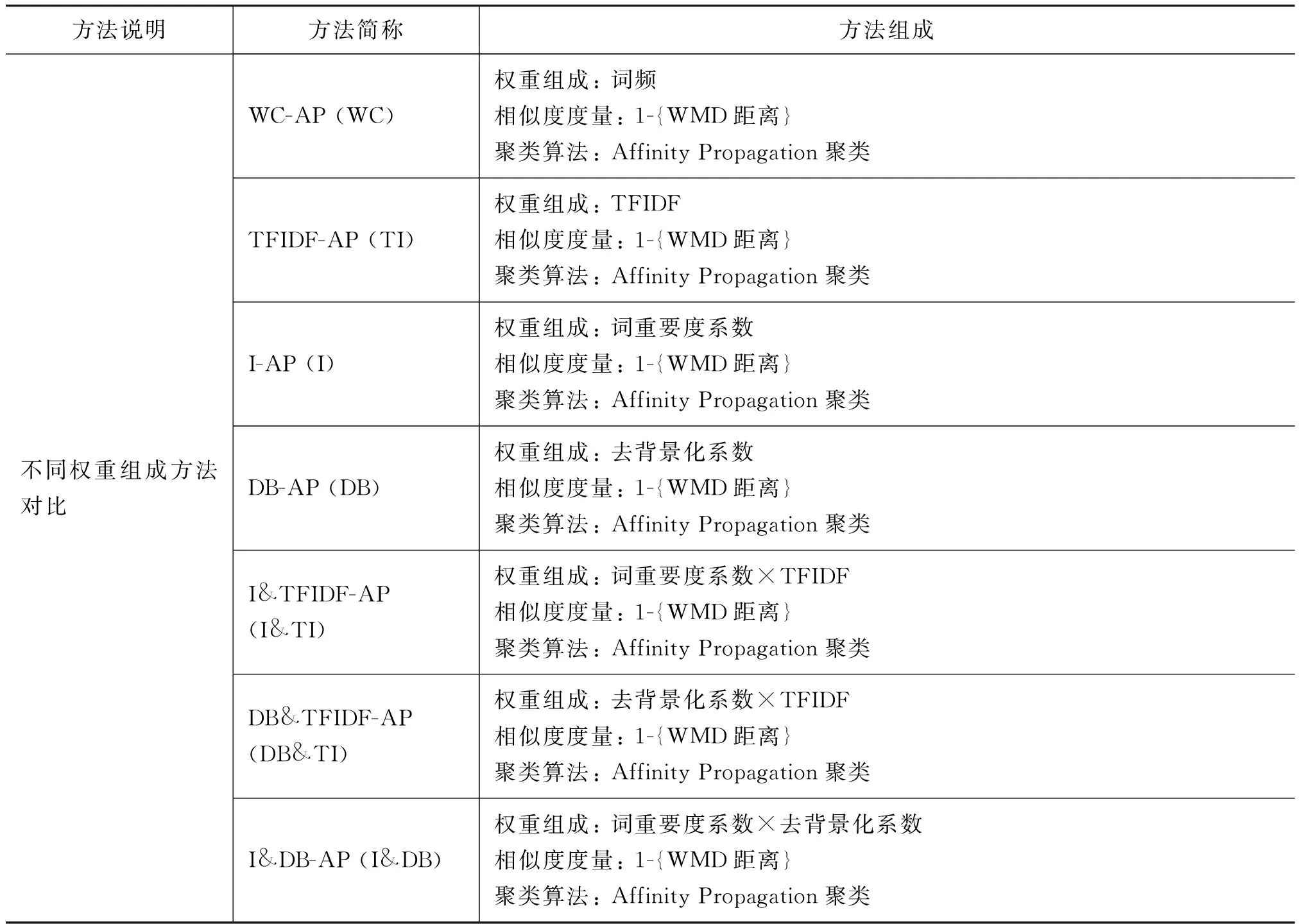
该组实验涉及的方法及说明如表3所示。

表3 不同权重组成方法说明及简称
续表
图2 不同相似度度量的Vmeasure和NMI均值与方差
由于针对本文的新闻评论数据集,Word2vec词表达的结果比Glove更优,因此该组实验只用Word2vec词表达进行。由于各方法比较稳定,为了更清晰地展示各方法的差别,该组实验省去了稳定性分析。各方法在24个数据集上Vmeasure和NMI指标的均值与方差结果如图3所示。
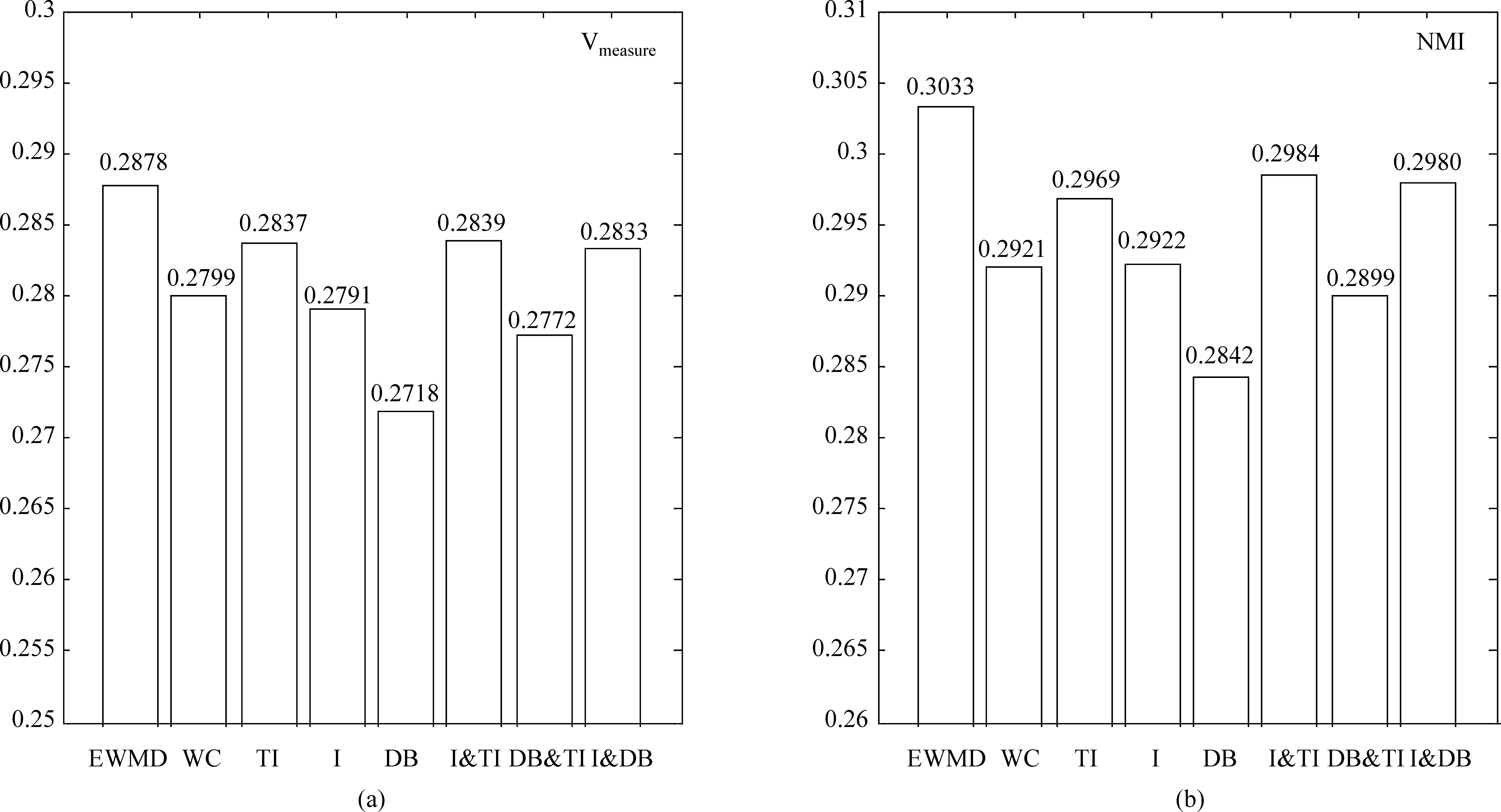
图3 不同权重组成方法的Vmeasure和NMI指标的均值与方差
从图3中可以看出TFIDF权重一定程度上优于词频权重,而强化权重优于传统的TFIDF权重和词频权重,优于单独的词重要度系数和去背景化系数,同时优于TFIDF权重、词重要度系数和去背景化系数的两两乘积,说明本文提出的强化权重向量的有效性,三个组成要素都不可或缺。
进一步,可以观察到在TFIDF系数的基础上乘以词重要度系数可以使结果得到少量的提升;在TFIDF系数的基础上乘以去背景化系数,结果比单独的TFIDF更差,然而词重要度系数、去背景化系数和TFIDF系数三者乘积使得结果有了相对显著的提升。这说明词重要度系数虽然考虑了词的“主体性”信息,但是可能过分强调了那些对正文来说重要的词,加大了背景的影响,使得结果的提升并不明显。去背景化系数虽然降低了正文背景的影响,但是把这些词的权重降得比一般词都低,致使一些无关紧要的词的权重就显得相对高了,使得去背景化的优势并没有体现出来,造成结果比单独的TFIDF还要差。而三者乘积,即强化权重,很好地考虑了词的重要度信息,同时不过分强调背景词的重要度,使得结果得到较大的提升。
4.3.4 聚类实例展示
从上述三组实验结果我们观察到,替换EWMD-AP聚类方法的任何一部分(即AP聚类、WMD距离和强化权重)所得方法相较EWMD-AP其性能都有下降,说明AP聚类、WMD距离和强化权重三个部分在EWMD-AP方法中缺一不可。为了进一步说明EWMD-AP方法的有效性,下面展示两个聚类实例。
某条新浪新闻(评论数373条)及某条凤凰新闻(评论数235),用Word2vec表达词向量,进而用EWMD-AP方法进行评论聚类,部分聚类结果分别如表4和表5所示。
表中第一列表示新闻,这里取标题进行展示,第二列为各个簇的聚类中心评论,即代表性评论,第三列为各个簇对应的其他评论。在表中一方面可以从全局的角度查看评论的关注点(第二列),另一方面可以更细致地查看各个关注点簇的具体情况(第三列),聚焦到某一个关注点,查看该关注点的其他评论。
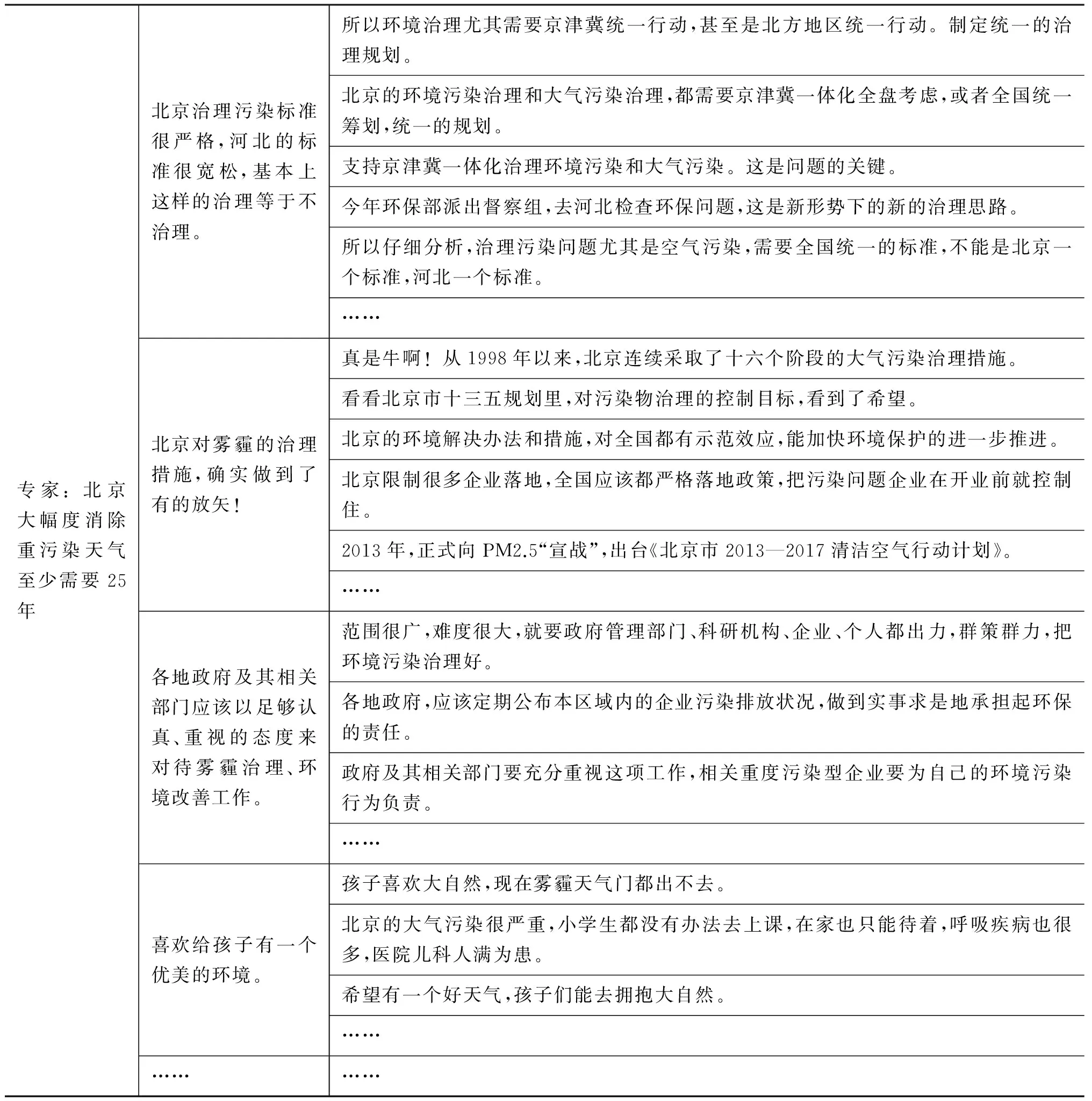
表4 某条新浪新闻的评论的聚类结果

表5 某条凤凰新闻的评论的聚类结果
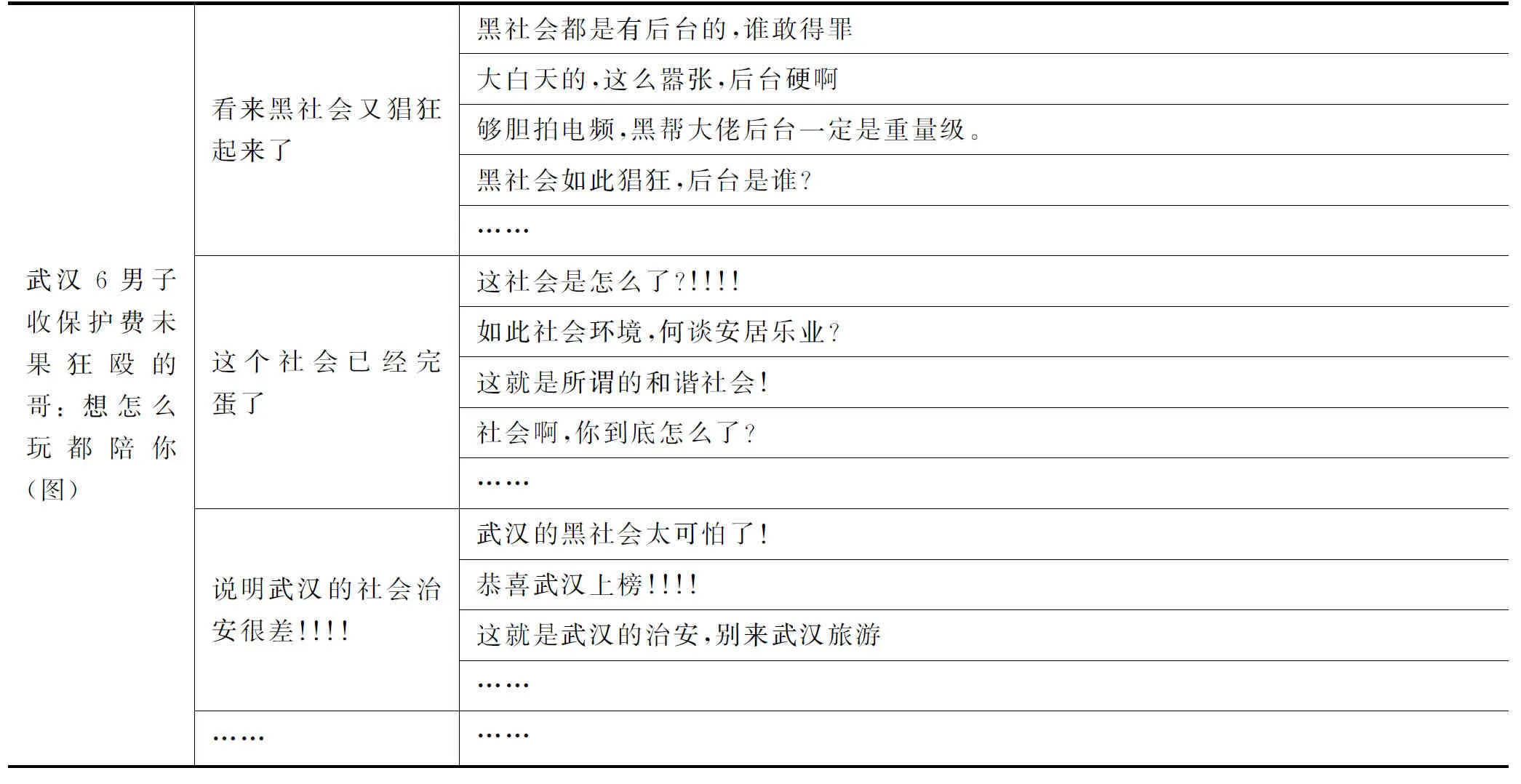
续表
5 结论及展望
面对日益增长的新闻和评论数据,本文旨在从杂乱的新闻评论中得到关注点簇和对应的代表性评论。传统的相似度计算方法和聚类方法即使在向量表达中嵌入强化权重也不能很好地利用词信息,获得理想的聚类结果。因此本文提出一种面向新闻评论的聚类方法EWMD-AP。该方法基于强化权重向量的WMD计算评论之间的距离,进而用AP算法对评论进行聚类。传统的WMD距离计算算法,对于权重只考虑词频信息,只在数量角度考虑权重。本文的强化权重向量由三部分组成: 基于词性及文本表达特征的词重要度系数、新闻正文作为评论背景的去背景化系数和TFIDF系数。该强化权重向量从数量和质量方面较全面地考虑了词信息。结合强化权重向量和WMD文本距离计算考虑语义的优点,以及AP算法基于文本特征聚类的优点,本文方法EWMD-AP在四大中文新闻网站的24个新闻评论数据集上取得了很好的效果。聚类结果优于Kmeans和Mean Shift等传统聚类算法,以及Density Peaks等当前最新算法,得到的聚类中心也是很好的代表性评论。
本文直接将得到的聚类中心作为代表性评论,没有考虑评论者行为,下一步将结合评论者特征、回复数、点赞数及与聚类中心的距离等信息,由它们共同决定代表性评论。
[1] HAI Z, CONG G, CHANG K, et al. Coarse-to-fine review selection via supervised joint aspect and sentiment model [C]//Proceedings of the 37th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2014: 617-626.
[2] DAYAN A, MOKRYN O, KUFLIK T. A two-iteration clustering method to reveal unique and hidden characteristics of items based on text reviews [C]//Proceedings of the 24th International Conference on World Wide Web. New York: ACM, 2015: 637-642.
[3] ZHOU X, WAN X, XIAO J. Representation learning for aspect category detection in online reviews [C]//Proceedings of the 29th AAAI Conference on Artificial Intelligence. Menlo Park, CA: AAAI, 2015: 417-423.
[4] NGUYEN T-S, LAUW H W, TSAPARAS P. Using micro-reviews to select an efficient set of reviews [C]//Proceedings of the 22nd ACM International Conference on Information and Knowledge Management. New York: ACM, 2013: 1067-1076.
[5] NGUYEN T S, LAUW H W, TSAPARAS P. Review selection using micro-reviews [J]. IEEE Transactions on Knowledge and Data Engineering, 2015, 27(4): 1098-1111.
[6] CHONG W-H, DAI B T, LIM E-P. Did you expect your users to say this?: Distilling unexpected micro-reviews for venue owners [C]//Proceedings of the 26th ACM Conference on Hypertext and Social Media. New York: ACM, 2015: 13-22.
[7] LU Z, MAMOULIS N, PITOURA E, et al. Sentiment-based topic suggestion for micro-reviews [C]//Proceedings of the 10th International AAAI Conference on Web and Social Media. Menlo Park, CA: AAAI, 2016: 231-240.
[8] KUSNER M, SUN Y, KOLKIN N, et al. From word embeddings to document distances [C]//Proceedings of the 32nd International Conference on Machine Learning. New York: ACM, 2015: 957-966.
[9] FREY B J, DUECK D. Clustering by passing messages between data points[J]. Science, 2007, 315(5814): 972-976.
[10] HARRIS Z S. Distributional structure [J]. Word, 1954, 10:146-162.
[11] HINTON G E. Learning distributed representation of concepts [C]//Proceedings of the 8th Annual Conference of the Cognitive Science Society. Mahwah, New Jersey: Lawrence Erlbaum Associates, 1986: 1-12.
[12] BROWN P F, DESOUZA P V, MERCER R L, et al. Class-based n-gram models of natural language [J]. Computational Linguistics, 1992, 18(4): 467-479.
[13] JEFFREY P, RICHARD S, MANNING C D. GloVe: Global vectors for word representation[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2014: 1532-1543.
[14] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space [J]. arXiv preprint arXiv:13013781, 2013.
[15] MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality[C]//Proceedings of Advances in Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc, 2013: 3111-3119.
[16] 田堃, 柯永红, 穗志方. 基于语义角色标注的汉语句子相似度算法 [J]. 中文信息学报, 2016, 30(6): 126-132.
[17] WANG C, SONG Y, LI H, et al. KnowSim: A document similarity measure on structured heterogeneous information networks [C]//Proceedings of IEEE 15th International Conference on Data Mining. New Jersey: IEEE, 2015: 1015-1020.
[18] 詹志建, 杨小平. 一种基于复杂网络的短文本语义相似度计算 [J]. 中文信息学报, 2016, 30(4): 71-80+9.
[19] SUN Y, LI W, DONG P. Research on text similarity computing based on word vector model of neural networks [C]//Proceedings of IEEE 6th International Conference on Software Engineering and Service Science (ICSESS). New Jersey: IEEE, 2015: 994-997.
[20] RUBNER Y, TOMASI C, GUIBAS L J. A metric for distributions with applications to image databases[C]//Proceedings of the 6th International Conference on Computer Vision. New Jersey: IEEE, 1998: 59-66.
[21] MACQUEEN J. Some methods for classification and analysis of multivariate observations[C]//Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability: Volume 1 Statistics. Oakland, CA University of California Press, 1967: 281-297.
[22] COMANICIU D, MEER P. Mean shift: a robust approach toward feature space analysis [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(5): 603-619.
[23] RODRIGUEZ A, LAIO A. Clustering by fast search and find of density peaks [J]. Science, 2014, 344(6191): 1492-1496.
[24] 蒋旦, 周文乐, 朱明. 基于语义和图的文本聚类算法研究 [J]. 中文信息学报, 2016, 30(5): 121-128.
[25] XIE J, GIRSHICK R, FARHADI A. Unsupervised deep embedding for clustering analysis [C]//Proceedings of the 33rd International Conference on Machine Learning. New York: ACM, 2016: 478-487.
[26] ZHANG Y, XIA Y, LIU Y, et al. Clustering sentences with density peaks for multi-document summarization [C]//Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2015: 1262.

官赛萍(1991—),博士研究生,主要研究领域为知识图谱。
E-mail: guansaiping@software.ict.ac.cn

靳小龙(1976—),博士,副研究员,主要研究领域为知识图谱、社会计算、大数据等。
E-mail: jinxiaolong@ict.ac.cn

徐学可(1983—),博士,助理研究员,主要研究领域为情感分析、自然语言处理、机器学习等。
E-mail: haudor@163.com
NewsCommentsClusteringBasedonWMDDistanceandAffinityPropagation
GUAN Saiping1,2, JIN Xiaolong1,2, XU Xueke1,2, WU Dayong1,2, JIA Yantao1,2, WANG Yuanzhuo1,2, LIU Yue1,2
(1. CAS Key Lab of Network Data Science and Technology, Institute of Computing Technology,Chinese Academy of Sciences, Beijing 100090, China;2. School of Computer and Control Engineering, University of Chinese Academy of Sciences, Beijing 100049, China)
With the rapid development of news websites, the news comments increase sharply, which are very important to public opinion analysis and news comments recommendation. This paper proposes a news comments clustering method, called EWMD-AP, to automatically mine the focuses of the public on the news. This method employs Word Mover’s Distance (WMD) with enhanced weight vectors to calculate the distances between news comments. It also adopts Affinity Propagation (AP) to cluster comments, and finally obtains the clusters and their representative comments corresponding to the focuses of the public. Particularly, this paper proposes to replace the traditional word frequency based weight vectors in WMD with enhanced weight vectors, which consist of three components: the importance coefficient of words, the de-contextualization coefficient, and the traditional TFIDF coefficient. Experimental results on 24 news comments datasets demonstrate that EWMD-AP performs much better than both traditional clustering methods (e.g. Kmeans, Mean Shift, etc) and the state-of-the-art ones (e.g. Density Peaks, etc).
news comments clustering; enhanced weight vectors; de-contextualization; Word Mover’s Distance; affinity propagation
1003-0077(2017)05-0203-12
TP391
A
2016-03-16定稿日期2017-05-31
国家重点研发计划(2016YFB1000902);973计划(2014CB340406);国家自然科学基金(61772501,61572473,61572469,61402442,91646120)
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
当代陕西(2020年17期)2020-10-28 08:18:18
人大建设(2018年5期)2018-08-16 07:09:00
电子测试(2017年15期)2017-12-18 07:19:27
电信科学(2017年6期)2017-07-01 15:44:57
信息安全研究(2016年4期)2016-12-01 06:06:54
智能系统学报(2015年4期)2015-12-27 09:38:39
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
电子设计工程(2015年6期)2015-02-27 12:04:53
河南科技(2014年15期)2014-02-27 14:12:51
